创作不易,友友们点个三连吧!
在博主的上一篇文章中,很详细地介绍了顺序表实现的过程以及如何去书写代码,如果没看过的友友们建议先去看看哦!
DS:顺序表的实现(超详细!!)
顺序表是线性表的一种,而本文将会介绍另外一种线性表——链表(single linked list)。
一、顺便表存在的问题
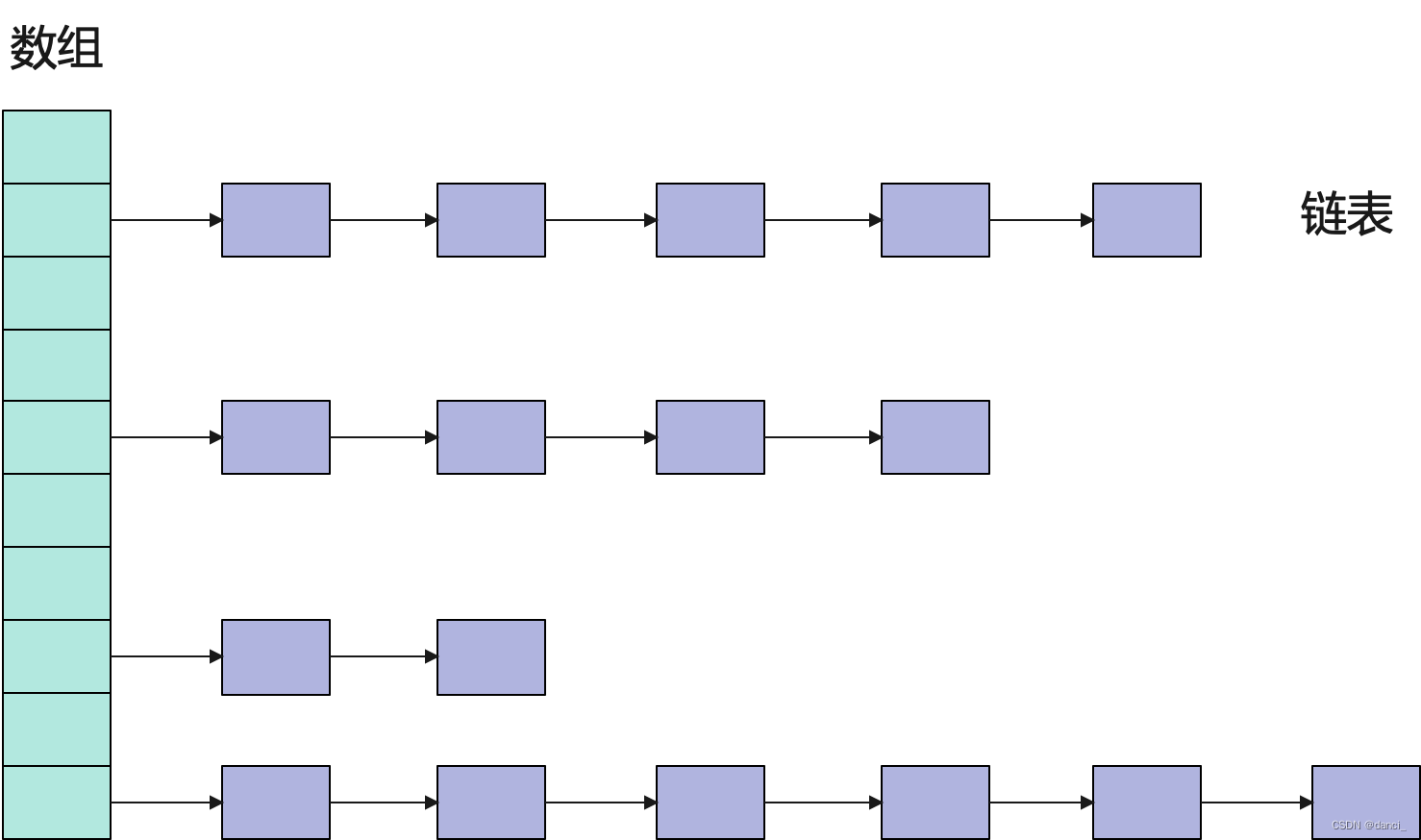
数组作为最基础的顺序结构,无法满足我们存储和管理数据的需求,因此我们通过对数组的封装,实现了常用的增删查改等操作,使数组摇身一变成为了顺序表,相比单纯的数组能够更有效的帮助我们储存数据和管理数据,但是他本身也存在着一下问题:
1、中间/头部的插入和删除,需要涉及到数据的多次挪动,效率不高。
2、增容需要申请新空间,拷贝数据,释放就空间,也会有不小的消耗。
3、增容一般是1.5倍或者是2倍增长,势必也是会存在空间浪费。例如当前地容量为100,满了以后增容到200,如果我们再插入5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
所以是否存在一种数据结构,能够解决以上问题??答案就是——链表!!
二、链表的概念及结构
概念:链表是⼀种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
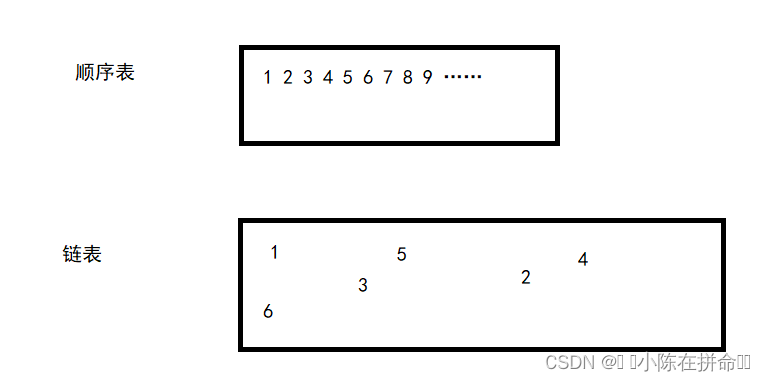
如上图,顺序表在物理结构上是连续的,即他们的数据有在内存中连续存放的特点,但是链表的物理结构是不连续的,即他的两个数据之间的内存地址可能相差十万八千里。为了更好地理解链表,下面举个例子: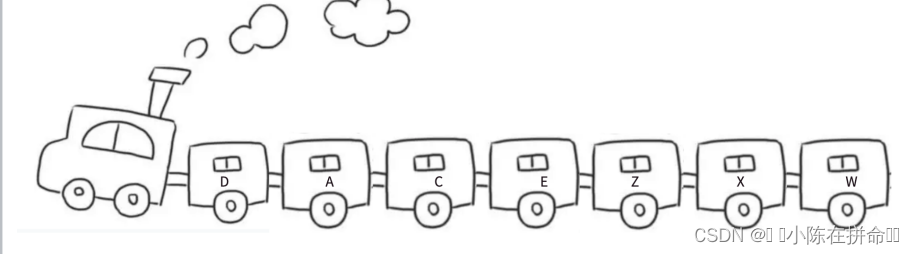
链表的结构跟火车类似,淡季的时候火车会相应减少,旺季时车次的车厢会额外增加几节。只需要将火车里的某节车厢去掉/加上,不会影响到其他的车厢,每节车厢都是独立存在的个体!!
⻋厢是独⽴存在的,且每节⻋厢都有⻋⻔。想象⼀下这样的场景,假设每节⻋厢的⻋⻔都是锁上的状态,需要不同的钥匙才能解锁,每次只能携带⼀把钥匙的情况下如何从⻋头⾛到⻋尾?
最简单的做法:每节车厢里都放⼀把下⼀节车厢的钥匙。
在链表里,每节“车厢”是这样的:

链表的每节“车厢”都是独立申请下来的空间,我们称之为链表的结点。
每节“结点”保存了自己的数据,同时保存了下一个“结点”的地址(指针变量)。
也就是说,由于每个链表都是独立申请的,为了让他们之间建立联系,就需要通过保存下一个结点的地址,这样可以方便我们去找到下一个结点
图中指针变量 plist保存的是第⼀个节点的地址,我们称plist此时“指向”第⼀个节点,如果我们希 望plist“指向”第⼆个节点时,只需要修改plist保存的内容为0x0012FFA0。
三、单链表结点结构体的创建
通过结构体的知识,我们要创建一个链表节点的结构体,这其中需要包含自己的数据,以及下一个结点的地址。
typedef int SLTDataType;//方便以后该链表可以修改用来存储其他的数据
typedef struct SListNode
{
SLTDataType data;//当前结点存储的数据
SListNode* next;//当前结点保存的下一个结点的地址
}SLTNode;结合之前顺序表的思路,我们一样对int类型进行重命名,这样是为了以后想要通过链表存储其他数据类型时,直接在这里进行修改即可。
当我们想要保存⼀个整型数据时,实际是向操作系统申请了⼀块内存,这个内存不仅要保存整型数据,也需要保存下⼀个节点的地址(当下⼀个节点为空时保存的地址为空)。
当我们想要从第⼀个节点⾛到最后⼀个节点时,只需要在前⼀个节点拿上下⼀个节点的地址(下⼀个 节点的钥匙)就可以了。
四、单链表的实现
有了链表结点的结构体,我们就可以去实现单链表(single linked list)了。
4.1 新节点的申请
涉及到尾插、头插、指定位置插入的情况下,都需要申请一个新的结点,并且还要对该结点动态申请一块空间,所以我们封装一个函数实现这个功能。
SLTNode* SLTBuyNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)//动态开辟失败,返回
{
perror("malloc fail");
exit(1);
}
//开辟成功
newnode->data = x;
newnode->next = NULL;
return newnode;
}为什么链表结点开辟空间使用malloc?
我们在顺序表中使用realloc,是因为我们经常需要在原有空间的基础上进行成倍地扩容,所以realloc会更加地灵活,而对于链表结点来说,一次开辟一次内存就可以了,且没有连续存放的要求,不需要在原有的空间基础上申请,因此malloc就可以了。
4.2 尾插
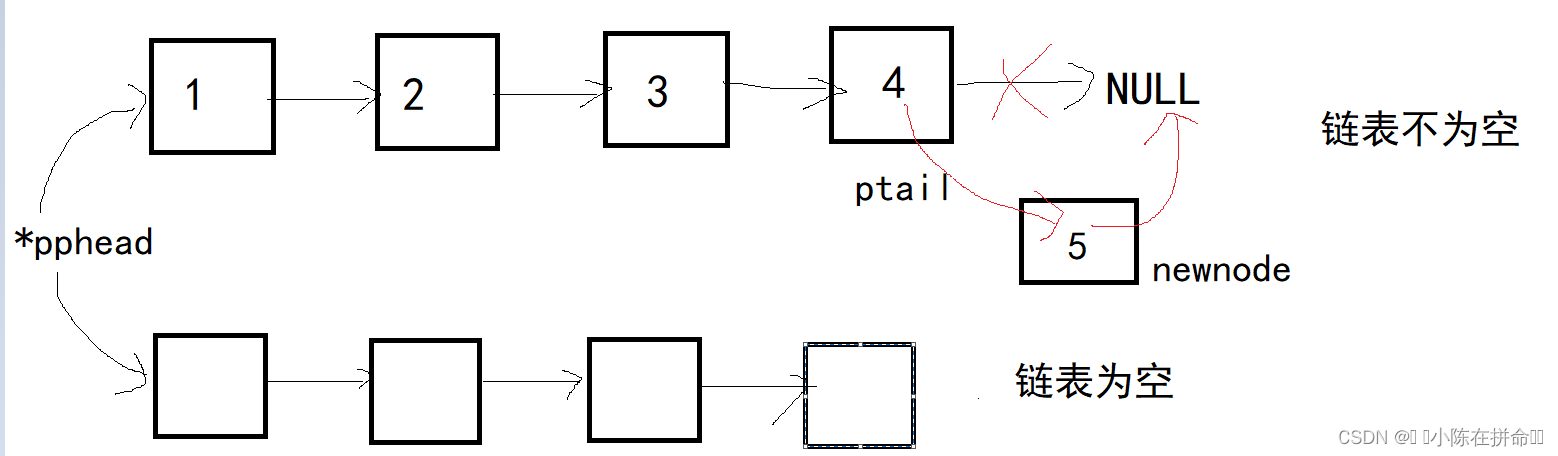
一般情况下,当链表不为空,找到最后一个结点ptail,让最后一个结点的next指针指向新的结点。
因为我们需要去寻找最后一个结点,所以如果当链表为空的时候,是没有最后一个结点的,所以我们需要单独讨论链表为空的情况,此时就让新的结点担任头节点。
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);//保证传入的参数不是NULL
SLTNode* newnode = SLTBuyNode(x);//创建新结点
//链表为空时
if (*pphead == NULL)
{
*pphead = newnode;
return;
}
//链表不为空时,寻找尾结点
SLTNode* ptail = *pphead;//先记录头结点
while (ptail->next)
{
ptail = ptail->next;
}
//遍历完后,此时ptail就是尾结点
ptail->next = newnode;
}1、为什么需要参数要用SLTNode** pphead?
我们在这里需要传入的是指向头节点的指针,该指针本身已经是一个一级指针了,如果这里的参数只用一级指针类型去接收,相当于是值传递,形参的改变不会影响实参,所以在这里,为了能够接收一级指针的同时又希望影响实参,这里就需要用二级指针去接收该一级指针的地址,假设我们指向头节点的一级指针是plist,如下图:
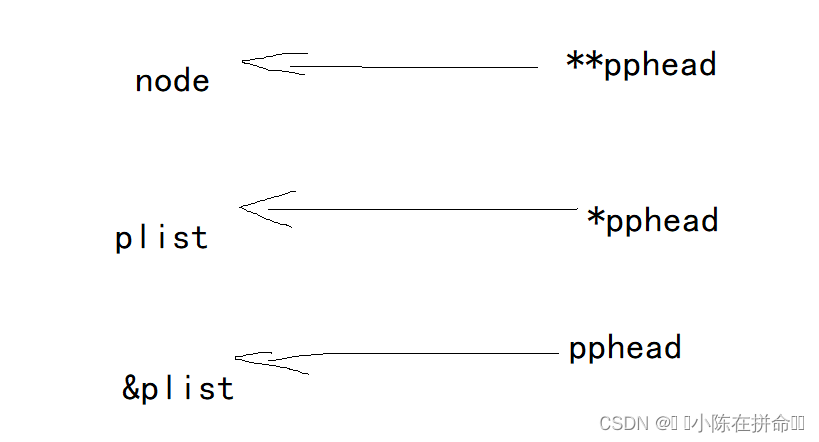
pphead是二级指针,接收一级指针的地址(&plist),如果解引用一次,得到一级指针plist,如果解引用两次,得到plist指向的结点node。
2、为什么需要assert(pphead)??
如果传入的是一个NULL指针,操作后会造成程序崩溃,断言是为了避免该函数被误用和滥用造成不可估计的后果。
3、寻找尾结点时,为什么还需要创建一个指针ptail去接收*pphead,而不直接使用*pphead??
*pphead是指向头节点的一级指针,我们是通过二级指针去接收该一级指针的地址,所以*pphead是会被改变的,如果我们在寻找尾结点的时候直接用*pphead,虽然也可以找到尾结点,但是头结点也会因此而丢失,所以我们在利用头结点去遍历链表时,一定要创建一个临时变量去接收头节点再去遍历!!
4.3 头插
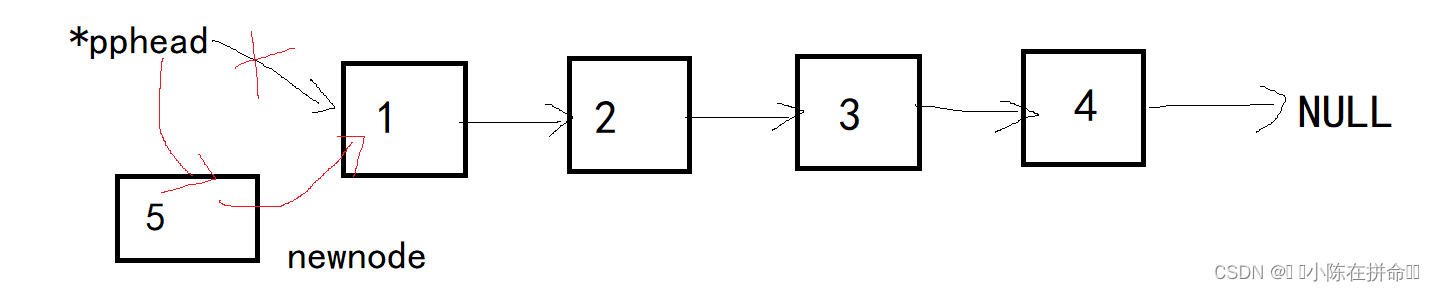
一般情况下,我们只需要让newnode的next指针指向原来的头节点,再让newnode成为新的头节点,当链表为空时也是人newnode为新的头节点,所以不需要分开讨论
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);//保证传入的参数不是NULL
SLTNode* newnode = SLTBuyNode(x);//创建新结点
newnode->next= *pphead;//新节点的next指针指向原来的头节点
*pphead = newnode;//newnode成为新的头节点
}注:newnode->next= *pphead和*pphead = newnode不能调换顺序,否则原头节点的数据会丢失!!
4.4 打印
我们希望封装一个打印链表的函数来检测我们写的代码是否正确。
void SLTPrint(SLTNode** pphead)//保持接口一致性
{
SLTNode* pcur = *pphead;
while (pcur)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}注:这里其实不需要传地址,因为打印函数只不过是展示,并没有对链表的数据进行处理,值传递也可以(SLTNode*phead),但是我们为了保持接口一致性,还是使用二级指针接收参数。
4.5 尾删
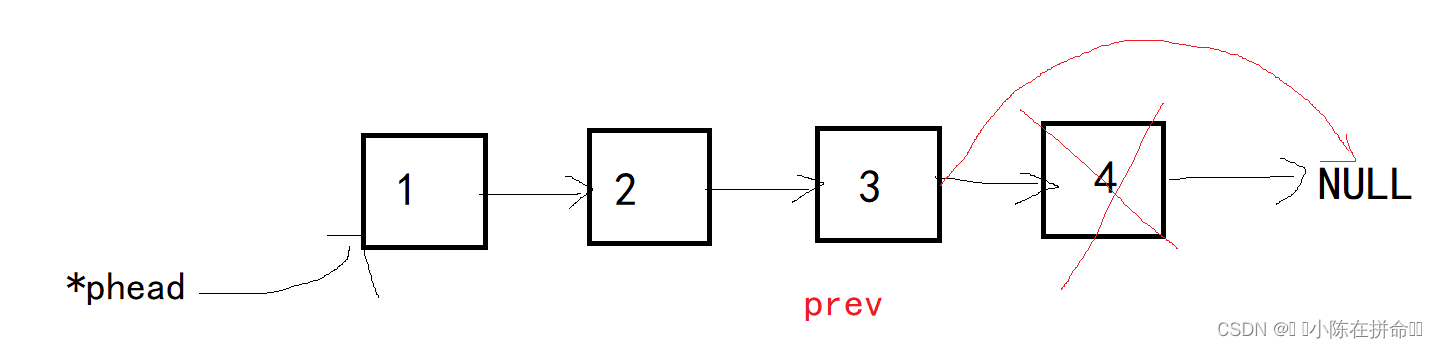
在一般情况下,我们需要找到尾节点的前一个结点prev,让他的next指针指向NULL,然后再释放尾结点并置空,因为我们需要找尾结点的前一个结点,如果该链表恰好只有一个结点时,是没有前结点的,所以单独讨论,该情况下直接将唯一的结点释放掉即可。当链表为空的时候,删除操作是没有意义的,所以要直接使用断言制止这种情况!
void SLTPopBack(SLTNode** pphead)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
//链表中只有一个结点的时候
if ((*pphead)->next == NULL)//->的优先级大于* 所以要在*pphead上加括号
{
free(*pphead);
*pphead = NULL;
return;
}
//链表中有多个结点的时候
SLTNode* ptail= *pphead;//用来遍历链表,最后释放尾结点
SLTNode* prev = NULL;//用来记录尾结点的前一个结点
while (ptail->next)
{
prev = ptail;
ptail = ptail->next;
}
//此时prev恰好是尾结点的前一个结点
prev->next = NULL;
//此时ptail恰好是尾结点,将其释放并置空
free(ptail);
ptail = NULL;
}
注:->的优先级大于*,所以一定要用括号将*ppead括起来!
4.6 头删
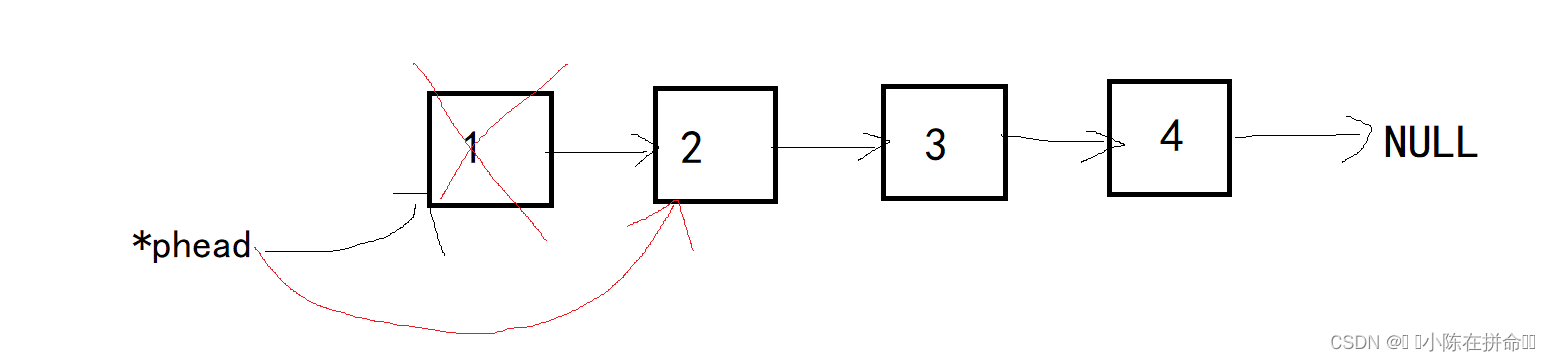
一般情况下,令*pphead指向第二个结点,然后释放掉第一个结点即可,链表只有一个结点的情况,也是释放掉第一个结点,所以不需要分开讨论,链表为空时头删没有意义!!所以必须通过断言来制止!!
void SLTPopFront(SLTNode** pphead)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
SLTNode* next = (*pphead)->next;//释放头节点前,先让next接收头节点的下一个结点
free(*pphead);//释放头节点
*pphead = next;//让next(原来的第二个结点)成为新的头节点
}4.7 查找
指定位置之前插入、指定位置之后插入、删除指定位置结点、删除指定位置之后的结点,都涉及到指定位置,所以我们封装一个查找函数,根据我们需要查找的数据,返回该数据所在的结点。
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x)
{
SLTNode* pcur = *pphead;
while (pcur)
{
if (pcur->data == x)
return pcur;//找到,则返回该结点
pcur = pcur->next;
}
//循环结束了还没找到,则返回NULL
return NULL;
}4.8 指定位置之前插入
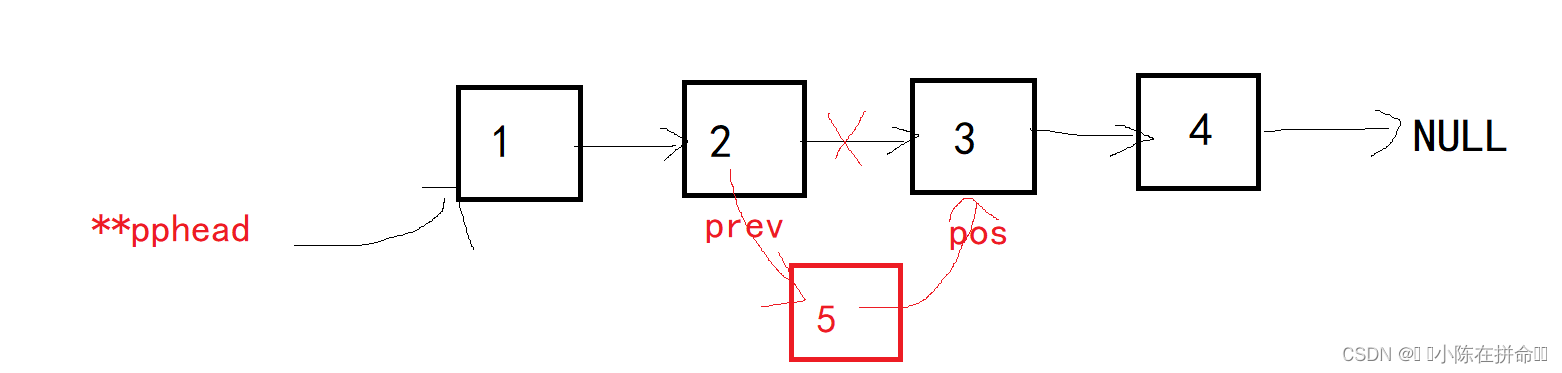
一般情况下,要找到pos的前一个结点prev,让prev的next指向新结点,而新节点的next指向pos,因为该函数要实现在指定位置之前插入,所以pos传空则没有意义,所以pos不能为空,因为pos不能为空,所以链表也不可能为空,因为要找pos的前一个结点,如果pos恰好就是头结点,那么就相当于是头插了,直接调用之前封装的头插函数。
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
assert(pos);//保证pos不为空
//当pos就是头结点的时候,相当于头插
if (*pphead = pos)
{
SLTPushFront(pphead, x);
return;
}
//当pos不是头节点的时候,要找pos的前一个结点
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//此时prev指向pos之前的一个结点
SLTNode* newnode = SLTBuyNode(x);//创建一个新结点
prev->next = newnode;
newnode->next = pos;
}4.9 指定位置之后插入
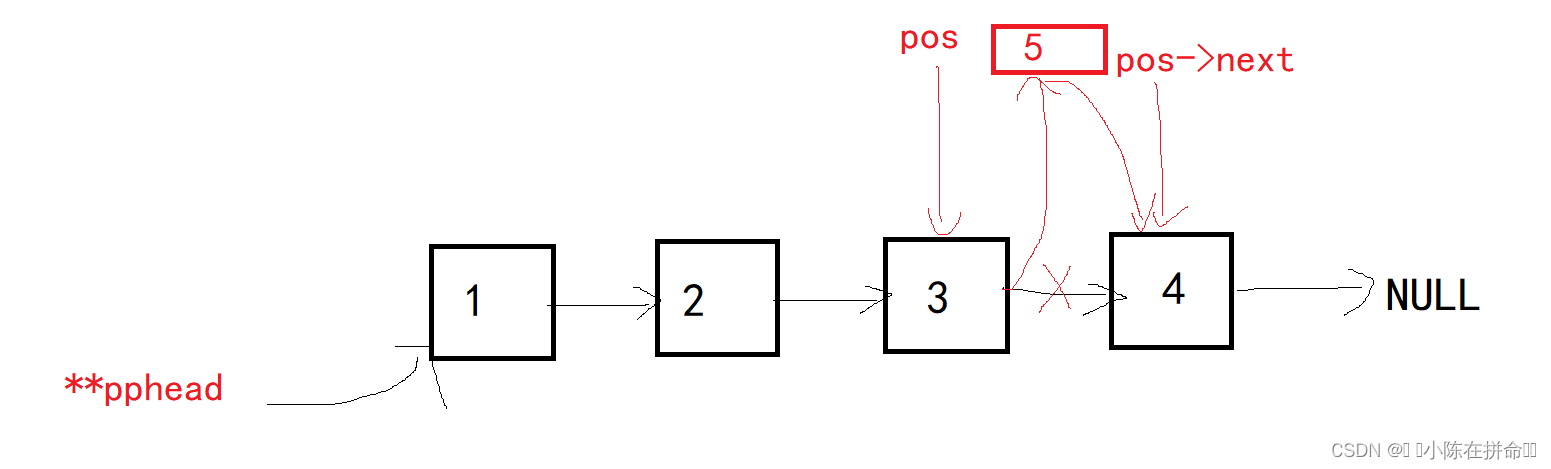
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);//保证pos不为空
SLTNode* newnode = SLTBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}注:newnode->next = pos->next和pos->next = newnode不能调换顺序!!
4.10 删除指定位置结点
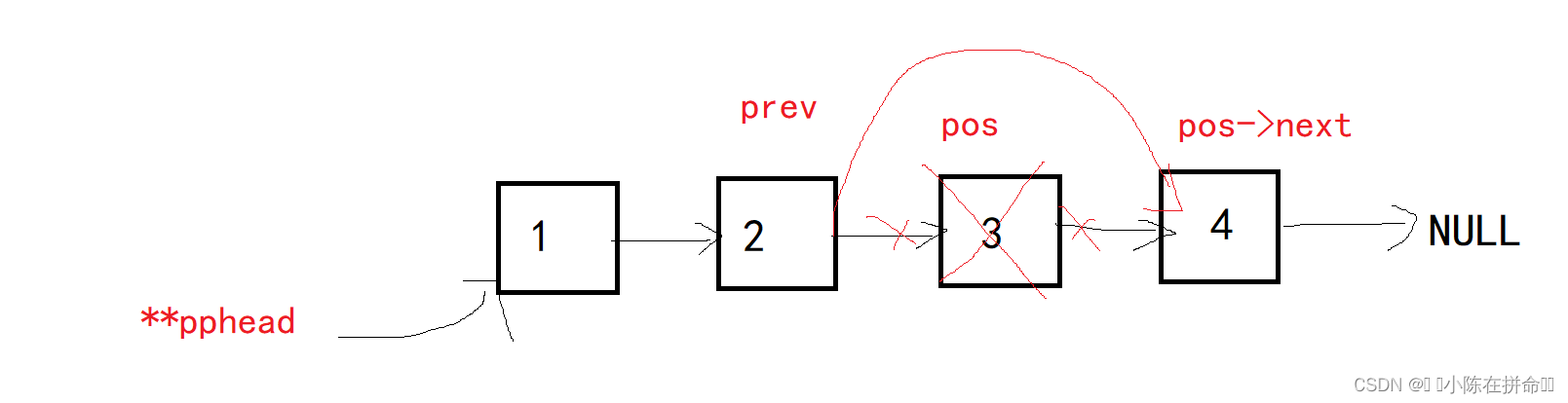
一般情况下,要找到pos的前一个结点prev,然后让他的next指针指向pos->next,然后再释放pos并置空,因为需要找pos的前一个元素,所以还需要考虑pos恰好就是头结点的情况!且链表为空时,删除没有意义
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
assert(pos);//保证pos不为空
//pos恰好是头节点的时候,相当于头删,直接调用头删函数
if (*pphead == pos)
{
SLTPopFront(pphead);
return;
}
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//此时prev恰好是pos的前一个结点
prev->next = pos->next;
free(pos);
pos = NULL;
}4.11 删除指定位置之后的结点
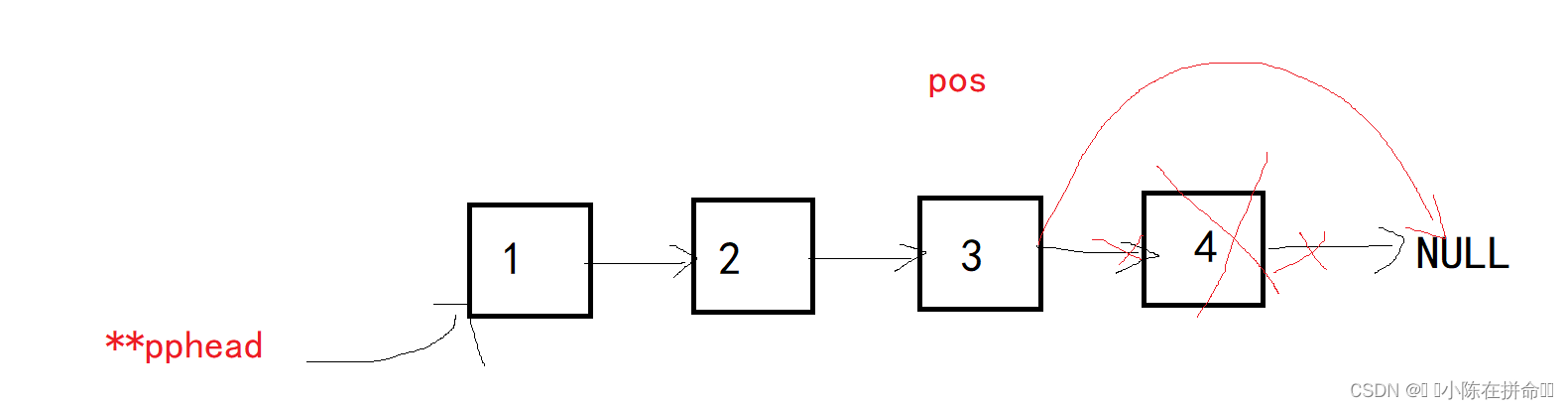
一般情况下,令pos->next=pos->next->next因为是删除指定位置之后的结点,所以必须保证pos的后一个结点存在,要使用断言!!
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* del = pos->next;//接收需要释放的结点
pos->next = pos->next->next;
free(del);
del = NULL;
}4.12 销毁链表
在顺序表中,由于其连续存放的特点,所以我们一次性就可以销毁完毕,但链表不一样,每一个结点都是独立的空间,所以需要一个结点一个结点的销毁!!
void SLTDesTory(SLTNode** pphead)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
SLTNode* pcur = *pphead;//用来删除
SLTNode* next = NULL;//用来遍历
while (pcur)
{
next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;//告诉编译器此时*pphead不能用了
//相当于毁了第一把钥匙,那后面的即使不置空也不会被使用到!
}为什么最后只把*pphead置空,而不把他后面的其他结点置空??
我们平时在动态内存释放的时候,其实空间已经返还给操作系统了,即使里面存在数据,也不影响别人的使用,因为直接覆盖就行了,所以我们之所以要置NULL,是为了防止我们写了很多代码后,忘记了其已经被释放,再去使用的话其实就是相当于使用了野指针,此时直接就会导致程序崩溃,所以置NULL,是为了让编译器提醒我们,这块空间不能被使用,在编译的时候,就可以即使地发现自己的问题。所以在这里,*pphead是找到后续链表其他结点的关键,只要*pphead被置空了,就相当于第一把钥匙丢了,那么后续的结点是不可能会被我们误用的!!!
4.13 总结
1、多次运用assert
assert是非常暴力的,我们运用他来避免我们的错误,其实我们在实现函数接口的时候,首要的任务是分析该函数要怎么去实现,其次需要分析的就是需要传入什么参数,而在思考传入什么参数的同时,你要思考这个传进的参数有没有可能会存在导致程序崩溃的参数,或者是一个没有意义的参数,比如说assert(pphead),就是为了防止该二级指针接收了NULL,对NULL解引用的话就会崩溃,比如在涉及到需要删除操作的时候,我们必须要避免这个链表是空的,否则就没有意义了!!而且也可能会崩溃,我们用assert(*pphead),而我们需要指定位置的时候,也需要确保指定位置是存在结点的!!这样我们写的代码才会更严谨,一方面是防止自己不小心误用,更重要的一方面是防止用户的滥用去导致程序的崩溃!!
2、链表的通用性
与顺序表一样,由于我们对存储的数据类型进行了重命名,所以我们可以直接修改就能让该链表不仅可以实现int类型的存储,还可以是char、double、float甚至是一些自定义的结构体类型,函数接口也是基本上可以无缝衔接的,但是呢,跟顺序表一样,查找函数和打印函数是不通用的,需要需要根据具体的数据类型去修改。
五、单链表实现的所有代码
SList.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
typedef int SLTDataType;//方便以后该链表可以修改用来存储其他的数据
typedef struct SListNode
{
SLTDataType data;//当前结点存储的数据
struct SListNode* next;//当前结点保存的下一个结点的地址
}SLTNode;
SLTNode* SLTBuyNode(SLTDataType x);//新节点的申请
void SLTPushBack(SLTNode** pphead, SLTDataType x);//尾插
void SLTPushFront(SLTNode** pphead, SLTDataType x);//头插
void SLTPrint(SLTNode** pphead);//打印
void SLTPopBack(SLTNode** pphead);//尾删
void SLTPopFront(SLTNode** pphead);//头删
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x);//查找
void SLTInsert(SLTNode** pphead, SLTNode* pos,SLTDataType x);//指定位置之前插入
void SLTInsertAfter(SLTNode* pos, SLTDataType x);//指定位置之后插入
void SLTErase(SLTNode** pphead, SLTNode* pos);//删除pos结点
void SLTEraseAfter(SLTNode* pos);//删除pos之后的结点
void SLTDesTory(SLTNode** pphead);//销毁链表SList.c
#include"SList.h"
SLTNode* SLTBuyNode(SLTDataType x)
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)//动态开辟失败,返回
{
perror("malloc fail");
exit(1);
}
//开辟成功
newnode->data = x;
newnode->next = NULL;
return newnode;
}
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);//保证传入的参数不是NULL
SLTNode* newnode = SLTBuyNode(x);//创建新结点
//链表为空时
if (*pphead == NULL)
{
*pphead = newnode;
return;
}
//链表不为空时,寻找尾结点
SLTNode* ptail = *pphead;//先记录头结点
while (ptail->next)
{
ptail = ptail->next;
}
//遍历完后,此时ptail就是尾结点
ptail->next = newnode;
}
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);//保证传入的参数不是NULL
SLTNode* newnode = SLTBuyNode(x);//创建新结点
newnode->next= *pphead;//新节点的next指针指向原来的头节点
*pphead = newnode;//newnode成为新的头节点
}
void SLTPrint(SLTNode** pphead)//保持接口一致性
{
SLTNode* pcur = *pphead;
while (pcur)
{
printf("%d->", pcur->data);
pcur = pcur->next;
}
printf("NULL\n");
}
void SLTPopBack(SLTNode** pphead)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
//链表中只有一个结点的时候
if ((*pphead)->next == NULL)//->的优先级大于* 所以要在*pphead上加括号
{
free(*pphead);
*pphead = NULL;
return;
}
//链表中有多个结点的时候
SLTNode* ptail= *pphead;//用来遍历链表,最后释放尾结点
SLTNode* prev = NULL;//用来记录尾结点的前一个结点
while (ptail->next)
{
prev = ptail;
ptail = ptail->next;
}
//此时prev恰好是尾结点的前一个结点
prev->next = NULL;
//此时ptail恰好是尾结点,将其释放并置空
free(ptail);
ptail = NULL;
}
void SLTPopFront(SLTNode** pphead)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
SLTNode* next = (*pphead)->next;//释放头节点前,先让next接收头节点的下一个结点
free(*pphead);//释放头节点
*pphead = next;//让next(原来的第二个结点)成为新的头节点
}
SLTNode* SLTFind(SLTNode** pphead, SLTDataType x)
{
SLTNode* pcur = *pphead;
while (pcur)
{
if (pcur->data == x)
return pcur;//找到,则返回该结点
pcur = pcur->next;
}
//循环结束了还没找到,则返回NULL
return NULL;
}
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
assert(pos);//保证pos不为空
//当pos就是头结点的时候,相当于头插
if (*pphead = pos)
{
SLTPushFront(pphead, x);
return;
}
//当pos不是头节点的时候,要找pos的前一个结点
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//此时prev指向pos之前的一个结点
SLTNode* newnode = SLTBuyNode(x);//创建一个新结点
prev->next = newnode;
newnode->next = pos;
}
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);//保证pos不为空
SLTNode* newnode = SLTBuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
assert(pos);//保证pos不为空
//pos恰好是头节点的时候,相当于头删,直接调用头删函数
if (*pphead == pos)
{
SLTPopFront(pphead);
return;
}
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
//此时prev恰好是pos的前一个结点
prev->next = pos->next;
free(pos);
pos = NULL;
}
void SLTEraseAfter(SLTNode* pos)
{
assert(pos);
assert(pos->next);
SLTNode* del = pos->next;//接收需要释放的结点
pos->next = pos->next->next;
free(del);
del = NULL;
}
void SLTDesTory(SLTNode** pphead)
{
assert(pphead);//保证传入的参数不是NULL
assert(*pphead);//保证链表不为空
SLTNode* pcur = *pphead;//用来删除
SLTNode* next = NULL;//用来遍历
while (pcur)
{
next = pcur->next;
free(pcur);
pcur = next;
}
*pphead = NULL;//告诉编译器此时*pphead不能用了
}在封装每一个函数的时候尽量自己去写,然后创建一个test.c去测试,自己找问题效果会更好哦!!!