EMIT-Diff:扩散模型 + 医学图像生成
- 提出背景
- 方法步骤
- 优化目标
- 如何将不同的条件输入(例如文本或边界框)整合到模型中?
- 如何提高边缘检测的准确性,从而生成真实和有意义的医学图像?
- 如何使用自动编码器架构和大规模数据集的预训练检查点,实现稳定的扩散模型?
提出背景
论文链接:https://arxiv.org/abs/2310.12868
医学领域大规模、高质量标注数据稀缺问题。
稀缺性是因为数据收集的劳动密集性、高成本和隐私问题,特别是在罕见疾病的背景下。
只能通过数据增强解决,受到高质量数据集稀缺的限制。
数据增强的类型:
- 基于变换的方法:这些涉及对原始数据进行基本变换,如旋转、缩放和强度调整、切割-拼接。它们以简单和计算效率而著称。
- 生成方法:如GANs(生成对抗网络)和DDPMs(去噪扩散概率模型)。
在生成方面,扩散模型比GAN、VAE要好。
- 扩散模型内容:Diffusion 扩散模型:论生成领先多样性,GAN太单一;论尊贵清晰度独占鳌头,VAE常失真
扩散模型,生成既真实又多样的合成医学图像数据,同时保留原始医学图像的关键特征,并通过融入对象的边缘信息来指导合成过程。
-
合成样本需遵循医学相关约束,保持成像数据的基本结构。
-
通过扩散模型的随机采样过程,可以生成数量不限、外观多样的合成图像。

使用RadImageNet训练的扩散模型生成结果:
-
第一行(Original):使用大规模医学图像数据集 RadImageNet 训练扩散模型,涵盖多种成像方式。
预训练包含1.35 百万张 的 MRI(磁共振成像)的髋关节正常图像、CT(计算机断层扫描)的腹部正常图像、MRI 的踝关节带骨折的图像、MRI 的正常脑部图像、超声波的甲状腺图像以及 MRI 的带有椎间盘病理的脊柱图像。
-
第二行(Edge):采用先进的全景嵌套边缘检测(HED)算法,从原始图像中提取的边缘信息。
这些边缘图像强调了原始图像中的解剖结构轮廓,为生成过程提供了结构信息。
生成训练提示 - 使用数据模态、器官名称和病理类别的组合作为训练提示,确保准确医学术语的使用。
在生成过程中利用准确的医学术语和边缘信息作为条件输入,保证了生成图像的医学准确性。
作为模型生成图像时的一个条件输入,帮助模型理解图像中的主要结构。
-
第三行(Generated):通过微调后的 ControlNet 生成的图像。
这些图像是由扩散模型根据原始图像和边缘图像生成的,旨在展示扩散模型可以如何生成各种不同类型的医学图像。
虽然生成的图像在样式上与原始图像有稍稍不同,但它们保持了解剖学上的一致性和结构的准确性。
这表明扩散模型能够理解和重现医学图像中的关键解剖结构,在图像模态(如MRI、CT、超声)不同时也是如此。
这种增强有助于创建更多样化的数据集,帮助模型更好地理解和解释医学图像,提高实际应用中的性能和准确性。
性能比较:
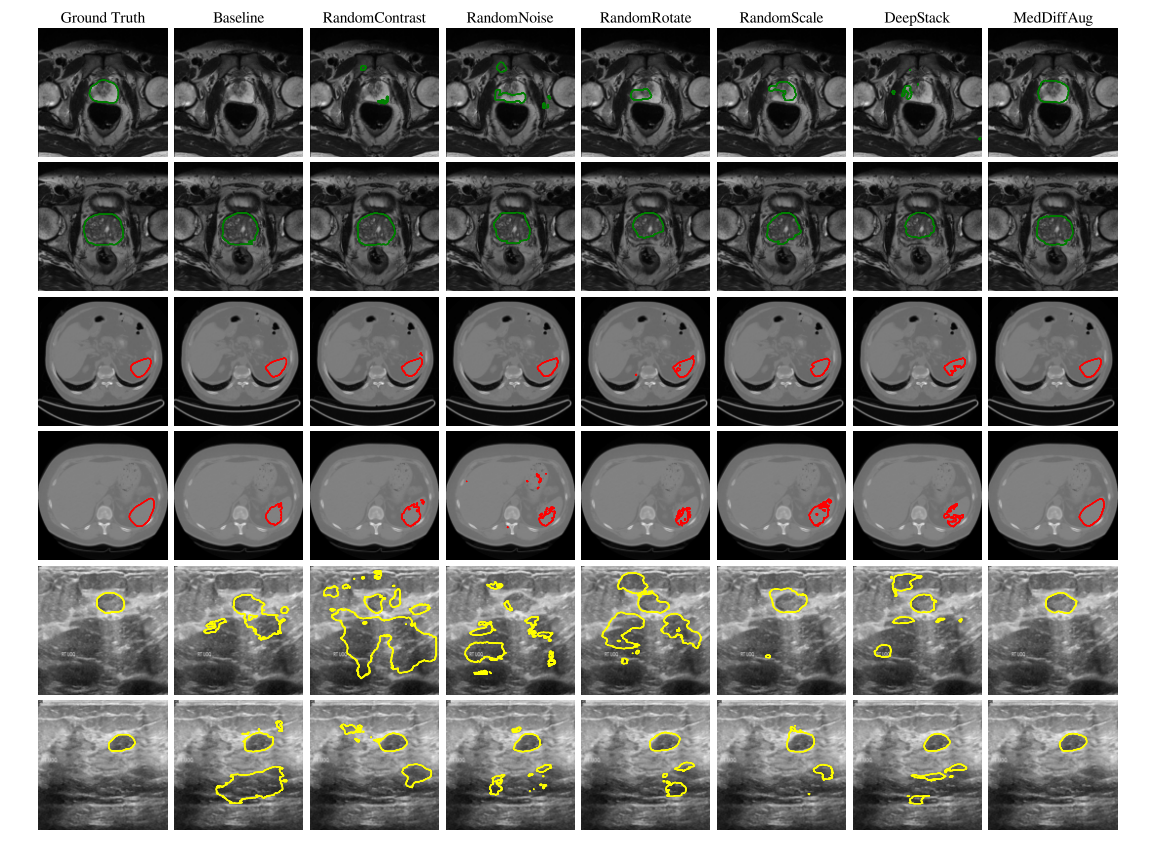
每列与第一列的真实轮廓(Ground Truth)进行了对比,以显示每种方法的准确性。
轮廓线的匹配程度越高,说明分割模型的性能越好。
这张图用到的方法以及它们的英文名、中文名和各自的目的如下:
-
Baseline
- 英文名:Baseline
- 中文名:基线方法
- 目的:未应用任何数据增强技术的基本分割模型性能,作为对比基准。
-
Random Contrast
- 英文名:Random Contrast
- 中文名:随机对比度调整
- 目的:通过随机改变图像对比度来增加数据多样性。
-
Random Noise
- 英文名:Random Noise
- 中文名:随机噪声添加
- 目的:通过加入随机噪声来模拟图像在不同条件下的变化,增强模型的鲁棒性。
-
Random Rotate
- 英文名:Random Rotate
- 中文名:随机旋转
- 目的:通过随机旋转图像来增强模型对位置变化的适应能力。
-
Random Scale
- 英文名:Random Scale
- 中文名:随机缩放
- 目的:通过改变图像的大小来增加训练数据的尺度变化。
-
DeepStack
- 英文名:DeepStack
- 中文名:深度堆叠
- 目的:可能是指使用多个网络模型或技术堆叠来提高性能
-
MedDiff Aug
- 英文名:MedDiff Aug (likely shorthand for Medical Diffusion Augmentation)
- 中文名:医学扩散增强
- 目的:利用扩散模型生成的增强样本来提高分割模型的性能和泛化能力。
很明显,EMIT-Diff方法(右边第一列)在多个案例中都能生成与真实轮廓更为一致的分割结果。
表明,形成解剖结构的一致性上优于其他数据增强方法。
方法步骤
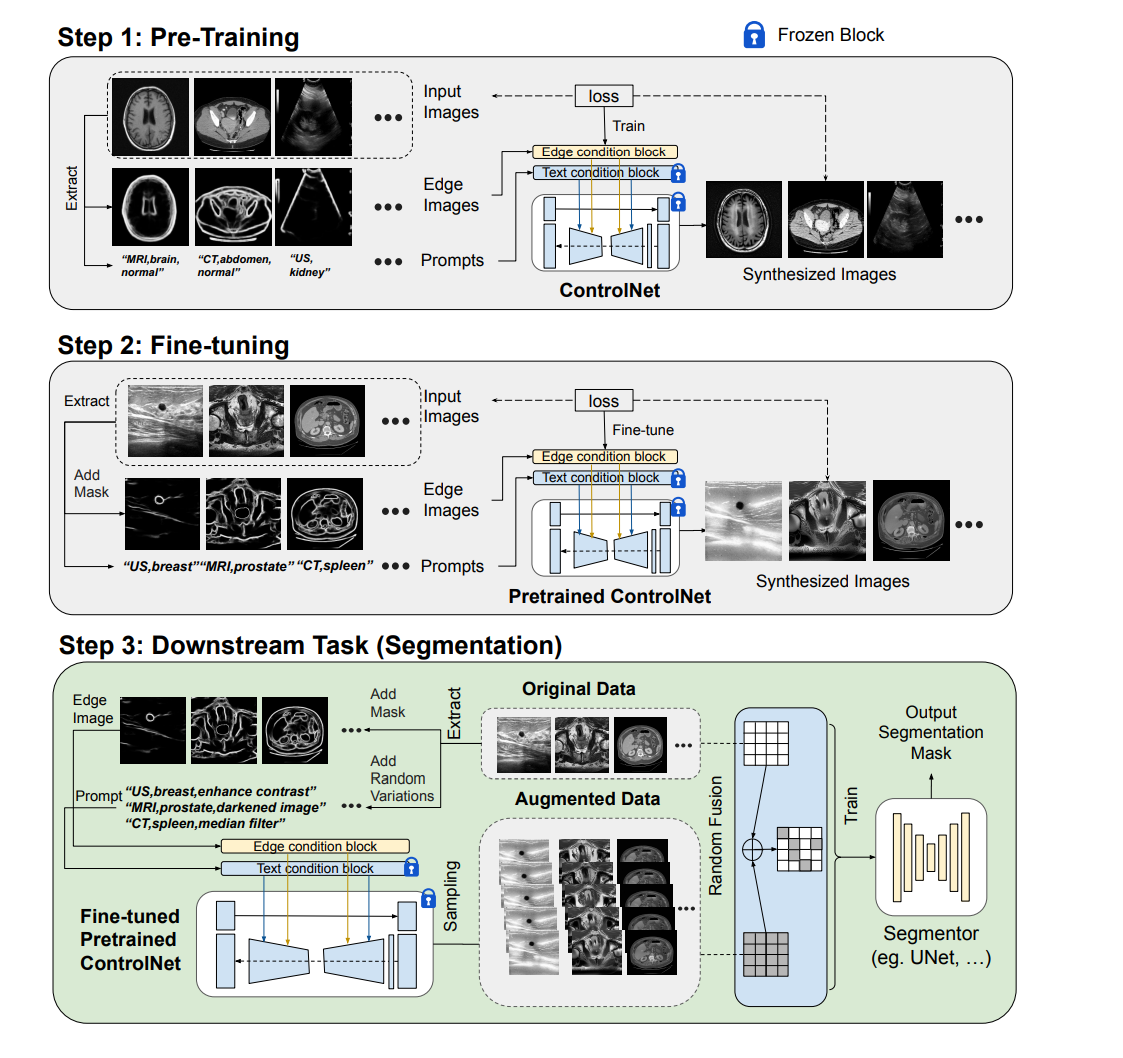
这幅图展示的是一个使用扩散模型进行数据增强以改善医学图像分割任务性能的三步:
第一步:预训练(Pre-Training)
- 这个阶段包括在一个综合性的医学图像数据集(如 RadImageNet)上训练扩散模型(在图中称为ControlNet)。
- 输入图像包括MRI、CT和超声等不同类型的医学图像,以及相应的边缘图像和文本提示(可能用于描述图像或指导生成过程)。
- 这个模型被训练以生成合成图像,这些图像保留了原始输入图像的重要医学属性和结构。
- 训练过程中,某些网络部分可能被“冻结”以保持在后续步骤中的特定特征或性能。
第二步:微调(Fine-tuning)
- 这一步骤涉及将预训练的扩散模型微调到特定的下游任务数据集上。
- 微调的目的是使模型能够捕捉到目标任务数据的独特特征和变化。
- 为保持一致性和准确性,微调过程中继续使用文本和边缘条件输入,特别是将分割掩膜的边缘信息融入生成条件,以确保解剖结构的准确表达。
- 微调过程包括为输入图像添加掩模(mask),以及使用文本提示来进一步指导合成图像的生成。
- 生成的合成图像应更贴近目标任务(如乳腺超声、前列腺MRI、脾脏CT)的特定要求。
第三步:下游任务(Segmentation)
- 在这一阶段,微调后的扩散模型被用于生成新的、增强的数据,用于提高图像分割模型(例如U-Net)的性能。
- 生成的增强数据与原始数据一起被用于训练分割模型。
- 这可以帮助分割模型学习更复杂的图像特征和变体,从而在实际的医学图像分割任务中实现更好的泛化和性能。
创新点:
- 在潜在特征空间中的训练
- 将条件输入融入模型架构来控制生成步骤
- 潜在特征空间中的训练:
- 使用自编码器结构中的编码器将原始数据映射到一个潜在的特征空间中去。
- 这个潜在空间的数据点,通常称为潜在变量,捕获了数据的本质特征和抽象表示。
- 即通过编码器产生的潜在空间中的特征 ( z ) 进行扩散训练,而解码器用于从潜在特征空间生成或重建图像。
- 条件输入的融合:
- 在生成模型中,条件输入(如文本提示、边缘信息)通常用于指导和控制生成过程,使得生成的图像符合特定的条件或特性。
- 在上述的DDPM框架中,文本或其他信息可以作为条件嵌入到模型中,通过交叉注意力层,影响模型在每一步生成的图像的特征。
- 这允许模型在生成过程中考虑到这些外部信息,从而生成与之相匹配的图像。
俩者结合,具体步骤:
- 编码器:将输入图像编码为潜在变量,这些变量捕获了图像的关键信息和结构。
- 条件模块:将条件信息(如文本描述)编码到同一潜在空间,或者作为网络中的附加输入。
- 扩散模型的训练:在潜在空间进行扩散过程的训练,这涉及到用模型学习如何在给定条件下从高斯噪声中重建潜在变量。
- 解码器:从训练好的潜在变量生成或重建图像,这些图像应当满足给定的条件。
优化目标

比如,去噪扩散概率模型(DDPM)生成磁共振成像(MRI)图像的流程可以这样描述:
-
初始化: 从RadImageNet数据集中选取一个MRI图像作为起始点( x 0 x_0 x0 ),这是我们想要模型学会生成的目标图像。
-
前向过程: 对选定的MRI图像(x_0)添加高斯噪声,生成一系列逐渐增加噪声的图像序列。
这个过程是通过迭代应用公式(1)和(2)来完成的。
在每一步(t),按照噪声方案 β t \beta_t βt 的计划,从之前的图像 x t − 1 x_{t-1} xt−1 生成新的更噪声的图像 x t x_t xt。
-
逆向过程: 当噪声水平足够高时(比如经过足够多的时间步骤(T)),我们的目标是从最噪声的图像 x T x_T xT 开始,逐步去除噪声,恢复出原始的清晰MRI图像。
这个逆向过程是通过公式(3)来近似的,但因为直接计算很困难,所以需要用到一个神经网络。
-
神经网络预测: 神经网络的作用是预测在每一步去噪时应该去除多少噪声。
这里,网络不是直接预测去噪后的图像,而是预测噪声本身,这是通过公式(6)来实现的。
网络 ϵ θ ( x t , t ) \epsilon_{\theta}(x_t, t) ϵθ(xt,t) 的输出告诉我们每个像素位置上噪声的估计值。
-
训练噪声预测网络: 为了训练这个神经网络,我们会优化一个目标函数,这个目标函数是变分下界(VLB),如公式(7)所示。
简化后的目标函数如公式(11),使得训练更高效。
-
生成MRI图像: 经过训练后,我们可以使用这个模型来生成新的MRI图像。
给定一些条件输入(如疾病的文本描述或边缘信息),模型可以生成具有这些特征的MRI图像。
这个过程的关键在于逆向过程的神经网络预测,它允许模型生成与训练数据分布相匹配的新图像,即使是在数据集中原本不存在的图像。
通过这种方式,我们可以增加用于训练其他下游任务(如分割或分类)模型的数据多样性和数量。
如何将不同的条件输入(例如文本或边界框)整合到模型中?
条件编码: 先将条件输入,如文本描述或边界框信息,编码为模型能理解的形式。
例如,文本输入可以通过自然语言处理模型(如BERT或GPT)编码成向量。
对于边界框,可以使用卷积神经网络(CNN)来提取特征。
整合编码: 将这些编码的条件输入作为附加信息整合到 DDPM 的输入中。
在生成过程中,这些条件信息会指导模型重点关注某些特征,比如增强对比度的文本提示可能会让模型生成更对比度更强的图像。
模型训练: 在训练模型时,这些条件输入会和图像一起输入到网络中。
网络学会将条件信息和图像信息相结合,生成与条件相匹配的输出。
如何提高边缘检测的准确性,从而生成真实和有意义的医学图像?
使用高级算法: 比如全景嵌套边缘检测(HED)算法,它可以通过深度学习技术提取图像的边缘信息。
HED通过深度监督学习丰富的层次表示,这有助于精确地识别图像边界。
多尺度特征: HED考虑多尺度的图像特征来检测边缘,这允许在不同的解析度下捕捉边缘信息,增加了边缘检测的准确性。
深度监督: 在每一层中使用深度监督确保学习到的特征在所有层次上都与边缘信息对齐,从而提高了整体的边缘检测性能。
如何使用自动编码器架构和大规模数据集的预训练检查点,实现稳定的扩散模型?
自动编码器架构: 使用编码器(Encoder)将图像编码到一个潜在空间,解码器(Decoder)从潜在空间重建图像。
这种结构有助于学习数据的内在表示,是生成任务的基础。
预训练: 在大规模数据集上预训练编码器和解码器。
这样做可以让模型学习到从大量数据中提取关键特征的能力。
检查点: 保存预训练的模型状态作为检查点。
这些检查点可以在后续任务中加载,以快速适应新的任务需求,从而避免从零开始训练。
微调: 载入预训练的检查点,并在特定的医学图像数据集上微调模型。
微调可以使模型更好地适应特定的医学图像特征和分布。


![[晓理紫]每日论文分享(有中文摘要,源码或项目地址)-机器人、强化学习](https://img-blog.csdnimg.cn/direct/def83647fe744e5492a88baa5445d67d.jpeg#pic_center)
![[C++开发 03_2/2 _ STL(185)]](https://img-blog.csdnimg.cn/direct/54c7d20062084fa3839f5ab347ed5fd1.png)