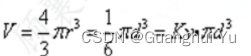专属领域论文订阅
关注{晓理紫},每日更新论文,如感兴趣,请转发给有需要的同学,谢谢支持
如果你感觉对你有所帮助,请关注我,每日准时为你推送最新论文。

分类:
- 具身智能,机器人
- 强化学习
- 开放词汇,检测分割
== robotic agent ==
标题: Learning to navigate efficiently and precisely in real environments
作者: Guillaume Bono, Hervé Poirier, Leonid Antsfeld
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2401.14349v1
中文摘要: 在地面机器人自主导航的背景下,为代理动力学和传感创建真实模型是机器人文献和商业应用中的普遍习惯,其中它们用于基于模型的控制和/或定位和绘图。另一方面,最近具体化的人工智能文献专注于在Habitat或AI-Thor等模拟器中训练的模块化或端到端代理,其中重点放在照片逼真的渲染和场景多样性上,但高保真机器人运动被分配了一个不太重要的角色。由此产生的sim2real差距显著影响训练模型到真实机器人平台的转移。在这项工作中,我们探索了在传感和驱动中最小化模拟真实差距的设置中模拟代理的端到端训练。我们的代理直接预测(离散化的)速度命令,这些命令通过真实机器人中的闭环控制来维持。真实机器人(包括底层低级控制器)的行为在改进的栖息地模拟器中被识别和模拟。里程计和定位的噪声模型进一步有助于降低sim2real差距。我们对真实导航场景进行了评估,探索了不同的定位和点目标计算方法,并报告了与之前的工作相比在性能和鲁棒性方面的显著收益。
摘要: In the context of autonomous navigation of terrestrial robots, the creation of realistic models for agent dynamics and sensing is a widespread habit in the robotics literature and in commercial applications, where they are used for model based control and/or for localization and mapping. The more recent Embodied AI literature, on the other hand, focuses on modular or end-to-end agents trained in simulators like Habitat or AI-Thor, where the emphasis is put on photo-realistic rendering and scene diversity, but high-fidelity robot motion is assigned a less privileged role. The resulting sim2real gap significantly impacts transfer of the trained models to real robotic platforms. In this work we explore end-to-end training of agents in simulation in settings which minimize the sim2real gap both, in sensing and in actuation. Our agent directly predicts (discretized) velocity commands, which are maintained through closed-loop control in the real robot. The behavior of the real robot (including the underlying low-level controller) is identified and simulated in a modified Habitat simulator. Noise models for odometry and localization further contribute in lowering the sim2real gap. We evaluate on real navigation scenarios, explore different localization and point goal calculation methods and report significant gains in performance and robustness compared to prior work.
标题: IA-LSTM: Interaction-Aware LSTM for Pedestrian Trajectory Prediction
作者: Yuehai Chen
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2311.15193v2
中文摘要: 预测人群场景中行人的轨迹在自动驾驶或自主移动机器人领域是不可或缺的,因为估计周围行人的未来位置有利于避免碰撞的政策决策。这是一个具有挑战性的问题,因为人类有不同的行走运动,在当前环境中,人类与物体之间的相互作用,特别是人类自身之间的相互作用,是复杂的。以前的研究人员专注于如何模拟人与人之间的互动,但忽略了互动的相对重要性。为了解决这一问题,引入了一种基于正向性的新机制。所提出的机制不仅可以测量人与人之间互动的相对重要性,还可以为每个行人建立个人空间。进一步提出了包括该数据驱动机制的交互模块。在所提出的模块中,数据驱动机制可以有效地提取场景中动态人机交互的特征表示,并计算相应的权重来表示不同交互的重要性。为了在行人之间共享这样的社会信息,设计了一种基于长短期记忆网络的交互感知结构用于轨迹预测。实验在两个公共数据集上进行。实验结果表明,我们的模型可以比最近几种性能良好的方法取得更好的性能。
摘要: Predicting the trajectory of pedestrians in crowd scenarios is indispensable in self-driving or autonomous mobile robot field because estimating the future locations of pedestrians around is beneficial for policy decision to avoid collision. It is a challenging issue because humans have different walking motions, and the interactions between humans and objects in the current environment, especially between humans themselves, are complex. Previous researchers focused on how to model human-human interactions but neglected the relative importance of interactions. To address this issue, a novel mechanism based on correntropy is introduced. The proposed mechanism not only can measure the relative importance of human-human interactions but also can build personal space for each pedestrian. An interaction module including this data-driven mechanism is further proposed. In the proposed module, the data-driven mechanism can effectively extract the feature representations of dynamic human-human interactions in the scene and calculate the corresponding weights to represent the importance of different interactions. To share such social messages among pedestrians, an interaction-aware architecture based on long short-term memory network for trajectory prediction is designed. Experiments are conducted on two public datasets. Experimental results demonstrate that our model can achieve better performance than several latest methods with good performance.
标题: Workspace Optimization Techniques to Improve Prediction of Human Motion During Human-Robot Collaboration
作者: Yi-Shiuan Tung, Matthew B. Luebbers, Alessandro Roncone
PubTime: 2024-01-23
Downlink: http://arxiv.org/abs/2401.12965v1
中文摘要: 理解人类的意图对于安全有效的人机协作至关重要。虽然人类目标预测的最新方法利用学习模型来解释人类运动数据的不确定性,但该数据本质上是随机和高方差的,阻碍了这些模型在需要协调的交互中的效用,包括安全关键或近距离任务。我们的关键见解是,机器人队友可以在交互之前故意配置共享工作空间,以减少人类运动的方差,实现目标预测中与分类器无关的改进。在这项工作中,我们提出了一种算法方法,让机器人在共享的人机工作空间中使用增强现实来安排物理对象和投影“虚拟障碍”,优化给定任务集的人类易读性。我们使用两个人类受试者研究将我们的方法与其他工作空间安排策略进行了比较,一个在虚拟2D导航领域,另一个在涉及机器人机械手的实时桌面操作领域。我们评估了从每种情况下学习的人体运动预测模型的准确性,证明了我们的虚拟障碍工作空间优化技术使用更少的训练数据导致更高的机器人预测精度。
摘要: Understanding human intentions is critical for safe and effective human-robot collaboration. While state of the art methods for human goal prediction utilize learned models to account for the uncertainty of human motion data, that data is inherently stochastic and high variance, hindering those models’ utility for interactions requiring coordination, including safety-critical or close-proximity tasks. Our key insight is that robot teammates can deliberately configure shared workspaces prior to interaction in order to reduce the variance in human motion, realizing classifier-agnostic improvements in goal prediction. In this work, we present an algorithmic approach for a robot to arrange physical objects and project “virtual obstacles” using augmented reality in shared human-robot workspaces, optimizing for human legibility over a given set of tasks. We compare our approach against other workspace arrangement strategies using two human-subjects studies, one in a virtual 2D navigation domain and the other in a live tabletop manipulation domain involving a robotic manipulator arm. We evaluate the accuracy of human motion prediction models learned from each condition, demonstrating that our workspace optimization technique with virtual obstacles leads to higher robot prediction accuracy using less training data.
标题: Integrating Human Expertise in Continuous Spaces: A Novel Interactive Bayesian Optimization Framework with Preference Expected Improvement
作者: Nikolaus Feith, Elmar Rueckert
PubTime: 2024-01-23
Downlink: http://arxiv.org/abs/2401.12662v1
中文摘要: 交互式机器学习(IML)寻求将人类专业知识整合到机器学习过程中。然而,大多数现有的算法不能应用于现实世界的场景,因为它们的状态空间和/或动作空间被限制为离散值。此外,所有现有方法的交互仅限于在多个方案之间做出决定。因此,我们提出了一种基于贝叶斯优化(BO)的新框架。交互式贝叶斯优化(IBO)支持机器学习算法和人类之间的协作。该框架捕获用户偏好,并为用户提供一个界面来手动制定策略。此外,我们还整合了一个新的采集功能,偏好预期改善(PEI),使用用户偏好的概率模型来提高系统的效率。我们的方法旨在确保机器能够从人类的专业知识中受益,旨在实现更加一致和有效的学习过程。在这项工作的过程中,我们将我们的方法应用于模拟和真实世界的任务中,使用Franka熊猫机器人来展示人机协作。
摘要: Interactive Machine Learning (IML) seeks to integrate human expertise into machine learning processes. However, most existing algorithms cannot be applied to Realworld Scenarios because their state spaces and/or action spaces are limited to discrete values. Furthermore, the interaction of all existing methods is restricted to deciding between multiple proposals. We therefore propose a novel framework based on Bayesian Optimization (BO). Interactive Bayesian Optimization (IBO) enables collaboration between machine learning algorithms and humans. This framework captures user preferences and provides an interface for users to shape the strategy by hand. Additionally, we’ve incorporated a new acquisition function, Preference Expected Improvement (PEI), to refine the system’s efficiency using a probabilistic model of the user preferences. Our approach is geared towards ensuring that machines can benefit from human expertise, aiming for a more aligned and effective learning process. In the course of this work, we applied our method to simulations and in a real world task using a Franka Panda robot to show human-robot collaboration.
标题: Modeling Resilience of Collaborative AI Systems
作者: Diaeddin Rimawi, Antonio Liotta, Marco Todescato
PubTime: 2024-01-23
Downlink: http://arxiv.org/abs/2401.12632v1
中文摘要: 协作人工智能系统(CAIS)与人类协作执行动作,以实现共同的目标。CAISs可以使用经过训练的人工智能模型来控制人类与系统的交互,或者他们可以使用人类交互以在线方式动态地向人类学习。在具有人类反馈的在线学习中,AI模型在学习状态下通过系统传感器监控人类交互来进化,并在操作状态下基于学习来驱动CAIS的自主组件。因此,任何影响这些传感器的破坏性事件都可能影响人工智能模型做出准确决策的能力,并降低CAIS的性能。因此,对于CAIS管理者来说,能够自动跟踪系统性能以了解CAIS在此类破坏性事件中的恢复能力是至关重要的。在本文中,我们提供了一个新的框架来模拟系统经历破坏性事件时的CAIS性能。在此框架下,我们引入了一个CAIS性能演化模型。该模型配备了一套措施,旨在支持CAIS管理人员在决策过程中实现系统所需的弹性。我们在一个真实世界的案例研究中测试了我们的框架,当系统经历破坏性事件时,机器人与人类在线合作。案例研究表明,我们的框架可以在CAIS中采用,并集成到CAIS活动的在线执行中。
摘要: A Collaborative Artificial Intelligence System (CAIS) performs actions in collaboration with the human to achieve a common goal. CAISs can use a trained AI model to control human-system interaction, or they can use human interaction to dynamically learn from humans in an online fashion. In online learning with human feedback, the AI model evolves by monitoring human interaction through the system sensors in the learning state, and actuates the autonomous components of the CAIS based on the learning in the operational state. Therefore, any disruptive event affecting these sensors may affect the AI model’s ability to make accurate decisions and degrade the CAIS performance. Consequently, it is of paramount importance for CAIS managers to be able to automatically track the system performance to understand the resilience of the CAIS upon such disruptive events. In this paper, we provide a new framework to model CAIS performance when the system experiences a disruptive event. With our framework, we introduce a model of performance evolution of CAIS. The model is equipped with a set of measures that aim to support CAIS managers in the decision process to achieve the required resilience of the system. We tested our framework on a real-world case study of a robot collaborating online with the human, when the system is experiencing a disruptive event. The case study shows that our framework can be adopted in CAIS and integrated into the online execution of the CAIS activities.
== Reinforcement Learning ==
标题: Domain Randomization for Robust, Affordable and Effective Closed-loop Control of Soft Robots
作者: Gabriele Tiboni, Andrea Protopapa, Tatiana Tommasi
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2303.04136v2
Project: https://andreaprotopapa.github.io/dr-soro/|
中文摘要: 软机器人由于其接触的内在安全性和适应性而越来越受欢迎。然而,潜在的无限数量的自由度使它们的建模成为一项艰巨的任务,并且在许多情况下只有近似的描述可用。由于模型和真实平台之间的巨大领域差距,这一挑战使得基于强化学习(RL)的方法在部署到现实场景时效率低下。在这项工作中,我们首次证明了域随机化(DR)如何通过增强软机器人的RL策略来解决这个问题:i)鲁棒性w.r.t。未知动力学参数;ii)通过利用非常简单的动态模型进行学习来减少训练时间;iii)更好的环境探索,这可以导致利用环境约束来获得最佳性能。此外,我们引入了一种新的算法扩展到以前的自适应域随机化方法,用于自动推断可变形物体的动力学参数。我们在模拟中对四种不同的任务和两种软机器人设计进行了广泛的评估,为闭环软机器人控制的强化学习的未来研究开辟了有趣的前景。
摘要: Soft robots are gaining popularity thanks to their intrinsic safety to contacts and adaptability. However, the potentially infinite number of Degrees of Freedom makes their modeling a daunting task, and in many cases only an approximated description is available. This challenge makes reinforcement learning (RL) based approaches inefficient when deployed on a realistic scenario, due to the large domain gap between models and the real platform. In this work, we demonstrate, for the first time, how Domain Randomization (DR) can solve this problem by enhancing RL policies for soft robots with: i) robustness w.r.t. unknown dynamics parameters; ii) reduced training times by exploiting drastically simpler dynamic models for learning; iii) better environment exploration, which can lead to exploitation of environmental constraints for optimal performance. Moreover, we introduce a novel algorithmic extension to previous adaptive domain randomization methods for the automatic inference of dynamics parameters for deformable objects. We provide an extensive evaluation in simulation on four different tasks and two soft robot designs, opening interesting perspectives for future research on Reinforcement Learning for closed-loop soft robot control.
标题: Successor-Predecessor Intrinsic Exploration
作者: Changmin Yu, Neil Burgess, Maneesh Sahani
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2305.15277v3
中文摘要: 探索在强化学习中至关重要,尤其是在外部奖励稀疏的环境中。这里我们关注的是具有内在回报的探索,在哪里代理人用自我产生的内在奖励暂时增加外部奖励。虽然内在奖励的研究有着悠久的历史,但现有的方法侧重于根据状态未来前景的测量来构成内在奖励,而忽略了转换序列的追溯结构中包含的信息。在这里,我们认为代理可以利用回顾性信息来产生具有结构意识的探索行为,促进基于全局而不是局部信息的有效探索。我们提出了后继——前任内在探索(SPIE),一种基于结合前瞻性和回顾性信息的新型内在奖励的探索算法。我们表明,在奖励稀疏和瓶颈状态的环境中,SPIE比竞争方法产生更有效和行为学上合理的探索行为。我们还在深度强化学习代理中实现了SPIE,并表明所产生的代理在稀疏奖励Atari游戏上实现了比现有方法更强的经验性能。
摘要: Exploration is essential in reinforcement learning, particularly in environments where external rewards are sparse. Here we focus on exploration with intrinsic rewards, where the agent transiently augments the external rewards with self-generated intrinsic rewards. Although the study of intrinsic rewards has a long history, existing methods focus on composing the intrinsic reward based on measures of future prospects of states, ignoring the information contained in the retrospective structure of transition sequences. Here we argue that the agent can utilise retrospective information to generate explorative behaviour with structure-awareness, facilitating efficient exploration based on global instead of local information. We propose Successor-Predecessor Intrinsic Exploration (SPIE), an exploration algorithm based on a novel intrinsic reward combining prospective and retrospective information. We show that SPIE yields more efficient and ethologically plausible exploratory behaviour in environments with sparse rewards and bottleneck states than competing methods. We also implement SPIE in deep reinforcement learning agents, and show that the resulting agent achieves stronger empirical performance than existing methods on sparse-reward Atari games.
标题: Sample Efficient Reinforcement Learning by Automatically Learning to Compose Subtasks
作者: Shuai Han, Mehdi Dastani, Shihan Wang
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2401.14226v1
中文摘要: 提高样本效率是强化学习(RL)的核心,尤其是在回报稀疏的环境中。一些最近的方法已经提出将奖励函数指定为手动设计或学习的奖励结构,其在RL算法中的集成被声称显著提高了学习效率。手动设计的奖励结构可能存在不准确性,并且现有的自动学习方法对于复杂的任务通常在计算上难以处理。RL算法中不准确或部分奖励结构的整合无法学习最优策略。在这项工作中,我们提出了一个RL算法,可以自动构建样本效率的奖励函数,给定一组表示子任务的标签。给定如此少的关于任务的知识,我们训练一个在每个状态下选择最佳子任务的高级策略和一个有效学习完成每个子任务的低级策略。我们在各种稀疏奖励环境中评估我们的算法。实验结果表明,随着任务难度的增加,我们的方法明显优于现有的基线方法。
摘要: Improving sample efficiency is central to Reinforcement Learning (RL), especially in environments where the rewards are sparse. Some recent approaches have proposed to specify reward functions as manually designed or learned reward structures whose integrations in the RL algorithms are claimed to significantly improve the learning efficiency. Manually designed reward structures can suffer from inaccuracy and existing automatically learning methods are often computationally intractable for complex tasks. The integration of inaccurate or partial reward structures in RL algorithms fail to learn optimal policies. In this work, we propose an RL algorithm that can automatically structure the reward function for sample efficiency, given a set of labels that signify subtasks. Given such minimal knowledge about the task, we train a high-level policy that selects optimal sub-tasks in each state together with a low-level policy that efficiently learns to complete each sub-task. We evaluate our algorithm in a variety of sparse-reward environments. The experiment results show that our approach significantly outperforms the state-of-art baselines as the difficulty of the task increases.
标题: Not All Tasks Are Equally Difficult: Multi-Task Deep Reinforcement Learning with Dynamic Depth Routing
作者: Jinmin He, Kai Li, Yifan Zang
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2312.14472v2
中文摘要: 多任务强化学习努力用单一策略完成一组不同的任务。为了通过在多个任务之间共享参数来提高数据效率,通常的做法是将网络分割成不同的模块,并训练路由网络将这些模块重新组合成特定于任务的策略。然而,现有的路由方法对所有任务采用固定数量的模块,忽略了具有不同难度的任务通常需要不同数量的知识。本工作提出了一个动态深度路由(D2R)框架,该框架学习某些中间模块的策略跳过,从而为每个任务灵活地选择不同数量的模块。在此框架下,我们进一步引入了一种重路由方法来解决非策略训练期间行为策略和目标策略之间不同路由路径的问题。此外,我们设计了一个自动路由平衡机制,以鼓励对未控制任务的持续路由探索,而不干扰已控制任务的路由。我们在元世界基准测试中对各种机器人操纵任务进行了广泛的实验,其中D2R实现了最先进的性能,显著提高了学习效率。
摘要: Multi-task reinforcement learning endeavors to accomplish a set of different tasks with a single policy. To enhance data efficiency by sharing parameters across multiple tasks, a common practice segments the network into distinct modules and trains a routing network to recombine these modules into task-specific policies. However, existing routing approaches employ a fixed number of modules for all tasks, neglecting that tasks with varying difficulties commonly require varying amounts of knowledge. This work presents a Dynamic Depth Routing (D2R) framework, which learns strategic skipping of certain intermediate modules, thereby flexibly choosing different numbers of modules for each task. Under this framework, we further introduce a ResRouting method to address the issue of disparate routing paths between behavior and target policies during off-policy training. In addition, we design an automatic route-balancing mechanism to encourage continued routing exploration for unmastered tasks without disturbing the routing of mastered ones. We conduct extensive experiments on various robotics manipulation tasks in the Meta-World benchmark, where D2R achieves state-of-the-art performance with significantly improved learning efficiency.
标题: Bridging Distributional and Risk-sensitive Reinforcement Learning with Provable Regret Bounds
作者: Hao Liang, Zhi-Quan Luo
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2210.14051v3
中文摘要: 我们通过分布式强化学习(DRL)方法研究了风险敏感强化学习(RSRL)的后悔保证。特别地,我们考虑有限的情节马尔可夫决策过程,其目标是回报的熵风险度量(EntRM)。通过利用EntRM的一个关键属性——独立性属性,我们建立了风险敏感的分布动态规划框架。然后,我们提出了两个新的DRL算法,通过两种不同的方案实现乐观,包括一个无模型的和一个基于模型的。我们证明它们都达到 O ~ ( exp ( β H ) − 1 β H S 2 A K ) \tilde{\mathcal{O}}(\frac{\exp(\beta H)-1}{\beta}H\sqrt{S^2AK}) O~(βexp(βH)−1HS2AK)regre万亿上限,其中 S S S、 a a a、 K K K和 H H H分别表示万亿状态、动作、情节和时间范围的数量。它与\cite{fei2021exponential}中提出的RSVI2相匹配,具有新颖的分布分析。据我们所知,这是第一个在样本复杂性方面连接DRL和RSRL的遗憾分析。承认与无模型DRL算法相关的计算低效率,我们提出了一种具有分布表示的替代DRL算法。这种方法不仅保持了已建立的遗憾界限,而且显著提高了计算效率。对于 β > 0 \beta>0 β>0的情况,我们还证明了 Ω ( exp ( β H / 6 ) − 1 β H H S A T ) \Omega(\frac{\exp(\beta H/6)-1}{\beta H}H\sqrt{SAT}) Ω(βHexp(βH/6)−1HSAT)的一个更紧的极小极大下界,这恢复了风险中性设置下 Ω ( H S A T ) \Omega(H\sqrt{SAT}) Ω(HSAT)的紧下界。
摘要: We study the regret guarantee for risk-sensitive reinforcement learning (RSRL) via distributional reinforcement learning (DRL) methods. In particular, we consider finite episodic Markov decision processes whose objective is the entropic risk measure (EntRM) of return. By leveraging a key property of the EntRM, the independence property, we establish the risk-sensitive distributional dynamic programming framework. We then propose two novel DRL algorithms that implement optimism through two different schemes, including a model-free one and a model-based one. We prove that they both attain O ~ ( exp ( ∣ β ∣ H ) − 1 ∣ β ∣ H S 2 A K ) \tilde{\mathcal{O}}(\frac{\exp(|\beta| H)-1}{|\beta|}H\sqrt{S^2AK}) O~(∣β∣exp(∣β∣H)−1HS2AK) regret upper bound, where S S S, A A A, K K K, and H H H represent the number of states, actions, episodes, and the time horizon, respectively. It matches RSVI2 proposed in \cite{fei2021exponential}, with novel distributional analysis. To the best of our knowledge, this is the first regret analysis that bridges DRL and RSRL in terms of sample complexity. Acknowledging the computational inefficiency associated with the model-free DRL algorithm, we propose an alternative DRL algorithm with distribution representation. This approach not only maintains the established regret bounds but also significantly amplifies computational efficiency. We also prove a tighter minimax lower bound of Ω ( exp ( β H / 6 ) − 1 β H H S A T ) \Omega(\frac{\exp(\beta H/6)-1}{\beta H}H\sqrt{SAT}) Ω(βHexp(βH/6)−1HSAT) for the β > 0 \beta>0 β>0 case, which recovers the tight lower bound Ω ( H S A T ) \Omega(H\sqrt{SAT}) Ω(HSAT) in the risk-neutral setting.
标题: True Knowledge Comes from Practice: Aligning LLMs with Embodied Environments via Reinforcement Learning
作者: Weihao Tan, Wentao Zhang, Shanqi Liu
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2401.14151v1
中文摘要: 尽管大型语言模型(LLMs)在许多任务中表现出色,但由于LLMs中的知识与环境不一致,它在解决简单的决策任务时经常失败。相反,强化学习(RL)代理从零开始学习策略,这使得它们总是与环境保持一致,但很难整合先验知识以进行有效的探索。为了缩小差距,我们提出了TWOSOME,这是一个新颖的通用在线框架,它将LLMs部署为决策代理,通过RL有效地与具体化的环境进行交互和调整,而不需要任何准备好的数据集或环境的先验知识。首先,我们用LLMs查询每个有效动作的联合概率,以形成行为策略。然后,为了增强策略的稳定性和鲁棒性,我们提出了两种规范化方法,并总结了四个快速设计原则。最后,我们设计了一个新颖的参数有效的训练架构,其中演员和评论家共享一个配备有由PPO更新的低秩适配器(LoRA)的冻结LLM。我们进行了广泛的实验来评估二体。i)TWOSOME在经典决策环境(过度烹饪)和模拟家庭环境(虚拟家庭)中,与传统的RL方法PPO和即时调整方法SayCan相比,表现出明显更好的样本效率和性能。ii)得益于LLMs的开放词汇特性,TWOSOME对未知任务表现出优越的泛化能力。iii)在我们的框架下,LLMs在在线PPO微调过程中没有明显的原始能力损失。
摘要: Despite the impressive performance across numerous tasks, large language models (LLMs) often fail in solving simple decision-making tasks due to the misalignment of the knowledge in LLMs with environments. On the contrary, reinforcement learning (RL) agents learn policies from scratch, which makes them always align with environments but difficult to incorporate prior knowledge for efficient explorations. To narrow the gap, we propose TWOSOME, a novel general online framework that deploys LLMs as decision-making agents to efficiently interact and align with embodied environments via RL without requiring any prepared datasets or prior knowledge of the environments. Firstly, we query the joint probabilities of each valid action with LLMs to form behavior policies. Then, to enhance the stability and robustness of the policies, we propose two normalization methods and summarize four prompt design principles. Finally, we design a novel parameter-efficient training architecture where the actor and critic share one frozen LLM equipped with low-rank adapters (LoRA) updated by PPO. We conduct extensive experiments to evaluate TWOSOME. i) TWOSOME exhibits significantly better sample efficiency and performance compared to the conventional RL method, PPO, and prompt tuning method, SayCan, in both classical decision-making environment, Overcooked, and simulated household environment, VirtualHome. ii) Benefiting from LLMs’ open-vocabulary feature, TWOSOME shows superior generalization ability to unseen tasks. iii) Under our framework, there is no significant loss of the LLMs’ original ability during online PPO finetuning.
== Object Detectio ==
标题: pix2gestalt: Amodal Segmentation by Synthesizing Wholes
作者: Ege Ozguroglu, Ruoshi Liu, Dídac Surís
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2401.14398v1
Project: https://gestalt.cs.columbia.edu/|
中文摘要: 我们介绍了pix2gestalt,这是一个用于零镜头无模态分割的框架,它学习估计在遮挡后仅部分可见的整个对象的形状和外观。通过利用大规模扩散模型并将它们的表示转移到这项任务中,我们学习了一种条件扩散模型,用于在具有挑战性的零镜头情况下重建整个对象,包括打破自然和物理先验的例子,如art。作为训练数据,我们使用一个综合策划的数据集,该数据集包含与它们的整个对应物配对的遮挡对象。实验表明,我们的方法在已建立的基准上优于监督基线。我们的模型还可以用于在存在遮挡的情况下显著提高现有对象识别和3D重建方法的性能。
摘要: We introduce pix2gestalt, a framework for zero-shot amodal segmentation, which learns to estimate the shape and appearance of whole objects that are only partially visible behind occlusions. By capitalizing on large-scale diffusion models and transferring their representations to this task, we learn a conditional diffusion model for reconstructing whole objects in challenging zero-shot cases, including examples that break natural and physical priors, such as art. As training data, we use a synthetically curated dataset containing occluded objects paired with their whole counterparts. Experiments show that our approach outperforms supervised baselines on established benchmarks. Our model can furthermore be used to significantly improve the performance of existing object recognition and 3D reconstruction methods in the presence of occlusions.
标题: Rethinking Patch Dependence for Masked Autoencoders
作者: Letian Fu, Long Lian, Renhao Wang
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2401.14391v1
Project: https://crossmae.github.io|
中文摘要: 在这项工作中,我们重新检查了屏蔽自动编码器(MAE)解码机制中的补丁间依赖性。我们将MAE中屏蔽补丁重建的解码机制分解为自我注意和交叉注意。我们的研究表明,面具贴片之间的自我关注对于学习良好的表征并不重要。为此,我们提出了一种新的预训练框架:交叉注意屏蔽自动编码器(CrossMAE)。CrossMAE的解码器仅利用屏蔽令牌和可见令牌之间的交叉注意力,下游性能不会下降。这种设计还能够仅解码掩码令牌的一小部分,从而提高效率。此外,每个解码器块现在可以利用不同的编码器特征,从而改进表示学习。CrossMAE在性能上与MAE相当,解码计算量减少了2.5到3.7KaTeX parse error: Undefined control sequence: \倍 at position 1: \̲倍̲。在相同的计算下,它在ImageNet分类和COCO实例分割方面也超过了MAE。代码和模型:https://cross mae.github.io
摘要: In this work, we re-examine inter-patch dependencies in the decoding mechanism of masked autoencoders (MAE). We decompose this decoding mechanism for masked patch reconstruction in MAE into self-attention and cross-attention. Our investigations suggest that self-attention between mask patches is not essential for learning good representations. To this end, we propose a novel pretraining framework: Cross-Attention Masked Autoencoders (CrossMAE). CrossMAE’s decoder leverages only cross-attention between masked and visible tokens, with no degradation in downstream performance. This design also enables decoding only a small subset of mask tokens, boosting efficiency. Furthermore, each decoder block can now leverage different encoder features, resulting in improved representation learning. CrossMAE matches MAE in performance with 2.5 to 3.7 × \times × less decoding compute. It also surpasses MAE on ImageNet classification and COCO instance segmentation under the same compute. Code and models: https://crossmae.github.io
标题: Inconsistency Masks: Removing the Uncertainty from Input-Pseudo-Label Pairs
作者: Michael R. H. Vorndran, Bernhard F. Roeck
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2401.14387v1
GitHub: https://github.com/MichaelVorndran/InconsistencyMasks|
中文摘要: 生成足够的标记数据是深度学习项目高效执行的一个重大障碍,特别是在图像分割的未知领域,标记需要大量时间,不像分类任务。我们的研究面临这一挑战,在受有限硬件资源和缺乏大量数据集或预训练模型限制的环境中运行。我们介绍了不一致性掩模(IM)的新用途,以有效地过滤图像——伪标签对中的不确定性,大大提高了分割质量,超越了传统的半监督学习技术。通过将IM与其他方法相结合,我们在ISIC 2018数据集上展示了卓越的二进制分割性能,从仅10%的标记数据开始。值得注意的是,我们的三个混合模型优于那些在完全标记的数据集上训练的模型。我们的方法在另外三个数据集上持续取得优异的结果,并在与其他技术结合时显示出进一步的改进。为了全面和稳健的评估,本文包括对流行的半监督学习策略的广泛分析,所有这些策略都是在相同的起始条件下训练的。完整代码可从以下网址获得:https://github.com/MichaelVorndran/inconsistency masks
摘要: Generating sufficient labeled data is a significant hurdle in the efficient execution of deep learning projects, especially in uncharted territories of image segmentation where labeling demands extensive time, unlike classification tasks. Our study confronts this challenge, operating in an environment constrained by limited hardware resources and the lack of extensive datasets or pre-trained models. We introduce the novel use of Inconsistency Masks (IM) to effectively filter uncertainty in image-pseudo-label pairs, substantially elevating segmentation quality beyond traditional semi-supervised learning techniques. By integrating IM with other methods, we demonstrate remarkable binary segmentation performance on the ISIC 2018 dataset, starting with just 10% labeled data. Notably, three of our hybrid models outperform those trained on the fully labeled dataset. Our approach consistently achieves exceptional results across three additional datasets and shows further improvement when combined with other techniques. For comprehensive and robust evaluation, this paper includes an extensive analysis of prevalent semi-supervised learning strategies, all trained under identical starting conditions. The full code is available at: https://github.com/MichaelVorndran/InconsistencyMasks
标题: MGAug: Multimodal Geometric Augmentation in Latent Spaces of Image Deformations
作者: Tonmoy Hossain, Miaomiao Zhang
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2312.13440v2
GitHub: https://github.com/tonmoy-hossain/MGAug|
中文摘要: 几何变换已被广泛用于增加训练图像的大小。现有的方法通常假设图像之间的基础变换是单峰分布的,这限制了当数据具有多峰分布时它们的能力。在本文中,我们提出了一个新的模型,多模态几何增强(MGAug),首次在几何变形的多模态潜在空间中生成增强变换。为了实现这一点,我们首先开发了一个深度网络,将微分同胚变换(也称为微分同胚)的潜在几何空间的学习嵌入到变分自动编码器(VAE)中。多元高斯的混合在微分同胚的切空间中被公式化,并作为逼近图像变换的隐藏分布的先验。然后,我们通过使用来自VAE的学习的多模态潜在空间的随机采样变换来变形图像,从而扩充原始训练数据集。为了验证我们模型的效率,我们联合学习了两个不同领域特定任务的增强策略:2D合成数据集上的多类分类和真实3D大脑磁共振图像(MRIs)上的分割。我们还将MGAug与最先进的基于变换的图像增强算法进行了比较。实验结果表明,我们提出的方法通过显著提高预测精度优于所有基线。我们的代码可在https://github.com/tonmoy-hossain/MGAug公开获得。
摘要: Geometric transformations have been widely used to augment the size of training images. Existing methods often assume a unimodal distribution of the underlying transformations between images, which limits their power when data with multimodal distributions occur. In this paper, we propose a novel model, Multimodal Geometric Augmentation (MGAug), that for the first time generates augmenting transformations in a multimodal latent space of geometric deformations. To achieve this, we first develop a deep network that embeds the learning of latent geometric spaces of diffeomorphic transformations (a.k.a. diffeomorphisms) in a variational autoencoder (VAE). A mixture of multivariate Gaussians is formulated in the tangent space of diffeomorphisms and serves as a prior to approximate the hidden distribution of image transformations. We then augment the original training dataset by deforming images using randomly sampled transformations from the learned multimodal latent space of VAE. To validate the efficiency of our model, we jointly learn the augmentation strategy with two distinct domain-specific tasks: multi-class classification on 2D synthetic datasets and segmentation on real 3D brain magnetic resonance images (MRIs). We also compare MGAug with state-of-the-art transformation-based image augmentation algorithms. Experimental results show that our proposed approach outperforms all baselines by significantly improved prediction accuracy. Our code is publicly available at https://github.com/tonmoy-hossain/MGAug.
标题: SymTC: A Symbiotic Transformer-CNN Net for Instance Segmentation of Lumbar Spine MRI
作者: Jiasong Chen, Linchen Qian, Linhai Ma
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2401.09627v2
GitHub: https://github.com/jiasongchen/SymTC|
中文摘要: 椎间盘疾病是一种常见疾病,经常导致间歇性或持续性腰痛,这种疾病的诊断和评估依赖于从腰椎MR图像中精确测量脊椎骨和椎间盘几何形状。深度神经网络(DNN)模型可以帮助临床医生以自动化的方式对腰椎的单个实例(椎间盘和椎骨)进行更有效的图像分割,这被称为实例图像分割。在这项工作中,我们提出了SymTC,这是一种创新的腰椎MR图像分割模型,结合了Transformer model和卷积神经网络(CNN)的优势。具体来说,我们设计了一种并行的双路径架构来合并CNN层和Transformer model层,并且我们将一种新颖的位置嵌入集成到Transformer model的自我注意模块中,增强了位置信息的利用,以实现更准确的分割。为了进一步提高模型性能,我们引入了一种新的数据增强技术来创建合成而真实的MR图像数据集,命名为SSMSpine,并公开提供。我们在我们的私有内部数据集和公共SSMSpine数据集上评估了我们的SymTC和其他15个现有的图像分割模型,使用了两个指标,Dice相似系数和95%Hausdorff距离。结果表明,我们的SymTC在腰椎MR图像中具有最好的脊椎骨和椎间盘分割性能。SymTC代码和SSMSpine数据集可从以下网址获得:https://github.com/jiasongchen/SymTC。
摘要: Intervertebral disc disease, a prevalent ailment, frequently leads to intermittent or persistent low back pain, and diagnosing and assessing of this disease rely on accurate measurement of vertebral bone and intervertebral disc geometries from lumbar MR images. Deep neural network (DNN) models may assist clinicians with more efficient image segmentation of individual instances (disks and vertebrae) of the lumbar spine in an automated way, which is termed as instance image segmentation. In this work, we proposed SymTC, an innovative lumbar spine MR image segmentation model that combines the strengths of Transformer and Convolutional Neural Network (CNN). Specifically, we designed a parallel dual-path architecture to merge CNN layers and Transformer layers, and we integrated a novel position embedding into the self-attention module of Transformer, enhancing the utilization of positional information for more accurate segmentation. To further improves model performance, we introduced a new data augmentation technique to create synthetic yet realistic MR image dataset, named SSMSpine, which is made publicly available. We evaluated our SymTC and the other 15 existing image segmentation models on our private in-house dataset and the public SSMSpine dataset, using two metrics, Dice Similarity Coefficient and 95% Hausdorff Distance. The results show that our SymTC has the best performance for segmenting vertebral bones and intervertebral discs in lumbar spine MR images. The SymTC code and SSMSpine dataset are available at https://github.com/jiasongchen/SymTC.
标题: Efficient Visual Computing with Camera RAW Snapshots
作者: Zhihao Li, Ming Lu, Xu Zhang
PubTime: 2024-01-25
Downlink: http://arxiv.org/abs/2212.07778v2
Project: https://njuvision.github.io/rho-vision|
中文摘要: 传统相机在传感器上捕捉图像辐照度,并使用图像信号处理器(ISP)将其转换为RGB图像。这些图像可以用于各种应用中的摄影或视觉计算任务,如公共安全监控和自动驾驶。有人可能会说,由于RAW图像包含所有捕获的信息,因此使用ISP将RAW转换为RGB对于视觉计算来说是不必要的。在本文中,我们提出了一个新的 ρ \rho ρ-Vision框架,可以使用原始图像进行高级语义理解和低级压缩,而无需使用几十年的ISP子系统。考虑到可用原始图像数据集的稀缺,我们首先开发了一个基于无监督CycleGAN的不成对CycleR2R网络,以使用不成对RAW和RGB图像训练模块化展开ISP和逆ISP(invISP)模型。然后,我们可以使用任何现有的RGB图像数据集灵活地生成模拟原始图像(simRAW),并微调最初为RGB域训练的不同模型,以处理真实世界的相机原始图像。我们使用原始域YOLOv3和原始图像压缩器(RIC)在来自各种相机的快照上演示了原始域中的对象检测和图像压缩功能。定量结果表明,与RGB域处理相比,原始域任务推理提供了更好的检测精度和压缩。此外,所提出的\r{ho}-Vision可以推广到各种相机传感器和不同的特定任务模型。建议的 ρ \rho ρ-Vision消除ISP的其他优点是计算和处理时间的潜在减少。
摘要: Conventional cameras capture image irradiance on a sensor and convert it to RGB images using an image signal processor (ISP). The images can then be used for photography or visual computing tasks in a variety of applications, such as public safety surveillance and autonomous driving. One can argue that since RAW images contain all the captured information, the conversion of RAW to RGB using an ISP is not necessary for visual computing. In this paper, we propose a novel ρ \rho ρ-Vision framework to perform high-level semantic understanding and low-level compression using RAW images without the ISP subsystem used for decades. Considering the scarcity of available RAW image datasets, we first develop an unpaired CycleR2R network based on unsupervised CycleGAN to train modular unrolled ISP and inverse ISP (invISP) models using unpaired RAW and RGB images. We can then flexibly generate simulated RAW images (simRAW) using any existing RGB image dataset and finetune different models originally trained for the RGB domain to process real-world camera RAW images. We demonstrate object detection and image compression capabilities in RAW-domain using RAW-domain YOLOv3 and RAW image compressor (RIC) on snapshots from various cameras. Quantitative results reveal that RAW-domain task inference provides better detection accuracy and compression compared to RGB-domain processing. Furthermore, the proposed \r{ho}-Vision generalizes across various camera sensors and different task-specific models. Additional advantages of the proposed ρ \rho ρ-Vision that eliminates the ISP are the potential reductions in computations and processing times.
专属领域论文订阅
关注{晓理紫},每日更新论文,如感兴趣,请转发给有需要的同学,谢谢支持。谢谢提供建议
如果你感觉对你有所帮助,请关注我,每日准时为你推送最新论文

![[C++开发 03_2/2 _ STL(185)]](https://img-blog.csdnimg.cn/direct/54c7d20062084fa3839f5ab347ed5fd1.png)