import os
import requests
import zipfile
from tqdm import tqdm
import tkinter as tk
filename = '名侦探柯南\\'
if not os.path.exists(filename):
os.mkdir(filename)
# https://vip.ffzy-online6.com/20231129/22304_740e70d0/2000k/hls/cedd2dc1ecb000001.ts
# https://vip.ffzy-online6.com/20231129/22304_740e70d0/2000k/hls/cedd2dc1ecb001618.ts
# https://vip.ffzyread1.com/20231022/19937_de64aeb3/2000k/hls/cb51ce9c9db000008.ts
for i in range(1,101):
if i < 10:
url = f'https://vip.ffzy-online6.com/20231129/22304_740e70d0/2000k/hls/cedd2dc1ecb00000{i}.ts'
if 10 <= i < 100:
url = f'https://vip.ffzy-online6.com/20231129/22304_740e70d0/2000k/hls/cedd2dc1ecb0000{i}.ts'
if 100 <= i < 1000:
url = f'https://vip.ffzy-online6.com/20231129/22304_740e70d0/2000k/hls/cedd2dc1ecb000{i}.ts'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
with open(filename+str(i)+'.ts',mode='wb') as f:
f.write(response.content)
print(f'正在下载第{i}个片段')
with zipfile.ZipFile(filename+'名侦探柯南'+'.mp4',mode='w') as f:
for i in tqdm(range(1,101)):
path = filename+f'{i}.ts'
f.write(path)
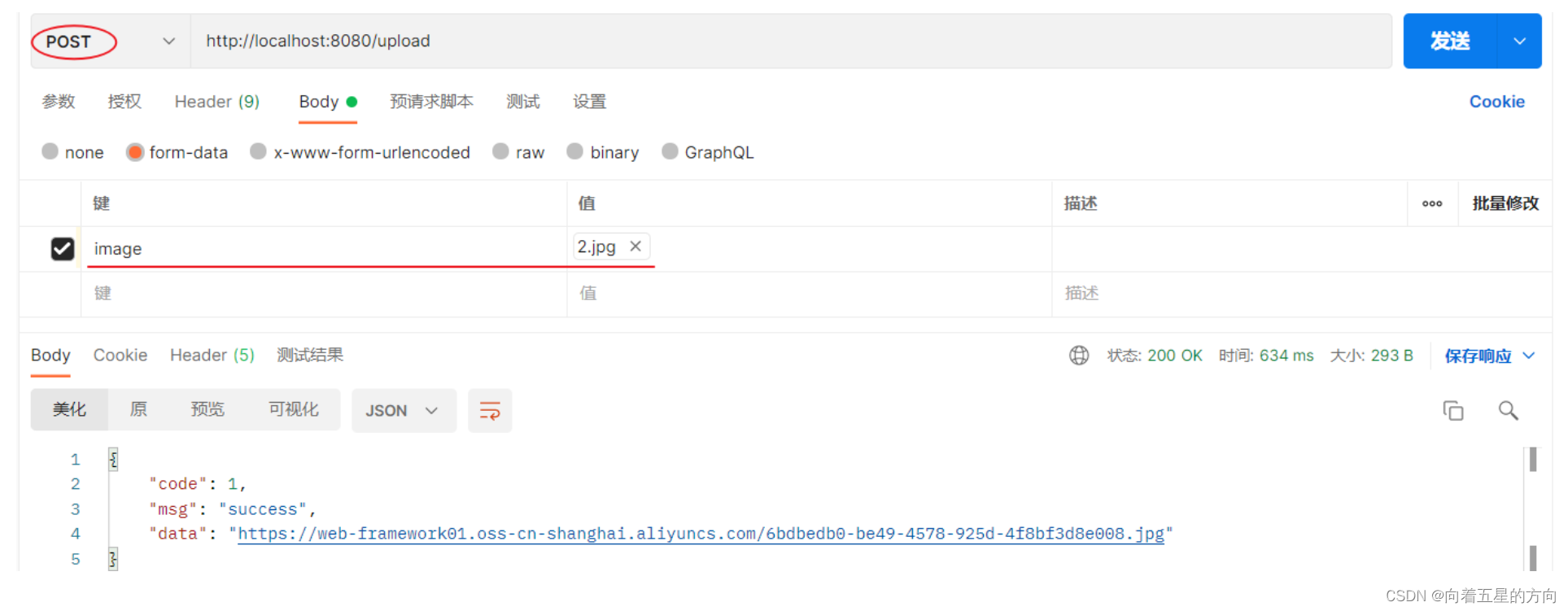
部分结果展现:
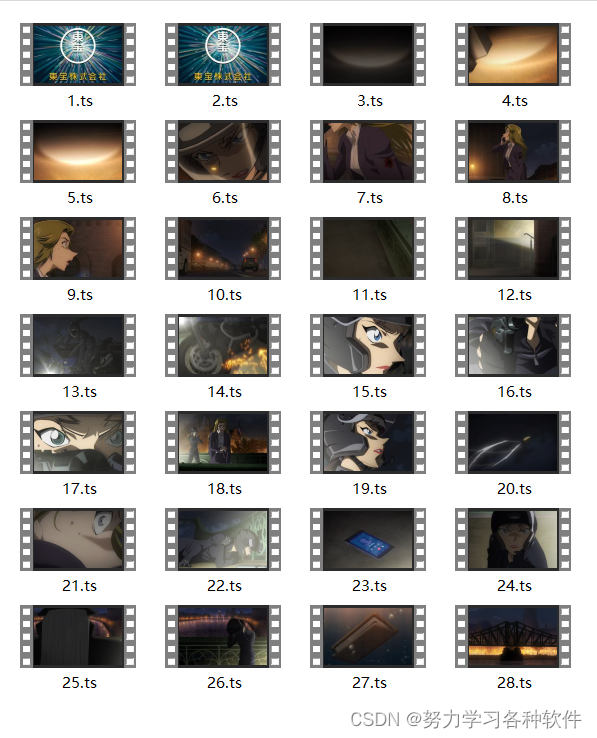

只爬取了一部分数据,樱花动漫网的ts的url地址规律太清楚了,一下子就弄到了。