文章目录
- Grasp-Anything: Large-scale Grasp Dataset from Foundation Models
- 针对痛点和贡献
- 摘要和结论
- 引言
- 相关工作
- Grasp-Anything 数据集
- 实验 - 零镜头抓取检测
- 实验 - 机器人评估
- 总结
Grasp-Anything: Large-scale Grasp Dataset from Foundation Models
Project page:Grasp-Anything: Large-scale Grasp Dataset from Foundation Models
针对痛点和贡献
痛点:
- 尽管有许多抓取数据集,但与现实世界的数据相比,它们的对象多样性仍然有限。
贡献:
- 因此,解决先前抓取数据集中有限表示的一个解决方案是嵌入这些Foundation Models(GhatGPT)中的通用知识。
- 语言驱动的抓取检测是一个有前途的研究领域。该数据集将推动这一领域的发展。(sim2real 抓取 [65]、人机交互 [66] 或语言驱动的移动操作 [42] 等相关任务中很有用。)
摘要和结论
我们提出了“Grasp-Anything”,这是一个由基础模型合成的新的大规模抓取数据集,用于机器人抓取检测的新的大规模语言驱动数据集。
Grasp-Anything 在多样性和数量上都很出色,拥有100万个带有文本描述的样本和超过300万个对象,超过了以前的数据集。根据经验,我们证明了在基于视觉的任务和真实世界的机器人实验中,抓取任何东西都能成功地促进零镜头抓取检测。
a new large-scale language-driven dataset for robotic grasp detection
引言
- 第一段【动机】:之前的方法都是model-centric,专注于修改网络模型。但Platt等认为在物理机器人上进行的结果在很大程度上取决于训练数据。因此,我们探索了 data-centric 方法,旨在提高抓取数据的质量,以在抓取检测中实现更稳健的泛化。
- 第二段【现存的不足与挑战】:虽然近年来提出了许多数据集,但是共同局限在:①对象数量有限;(不同数据集之间分布差异大,导致代码迁移性差)②没有考虑每个场景安排的自然语言描述;(限制人机交互)③对物体摆放位置(排列)和环境设置可能做了假设;(无法还原真实世界的场景)
- 第三段【基础模型】:大规模基础模型的使用促进了全知知识与机器人系统的集成[39],克服了传统方法在对非结构化和新颖环境进行稳健建模方面面临的挑战[40]。
相关工作
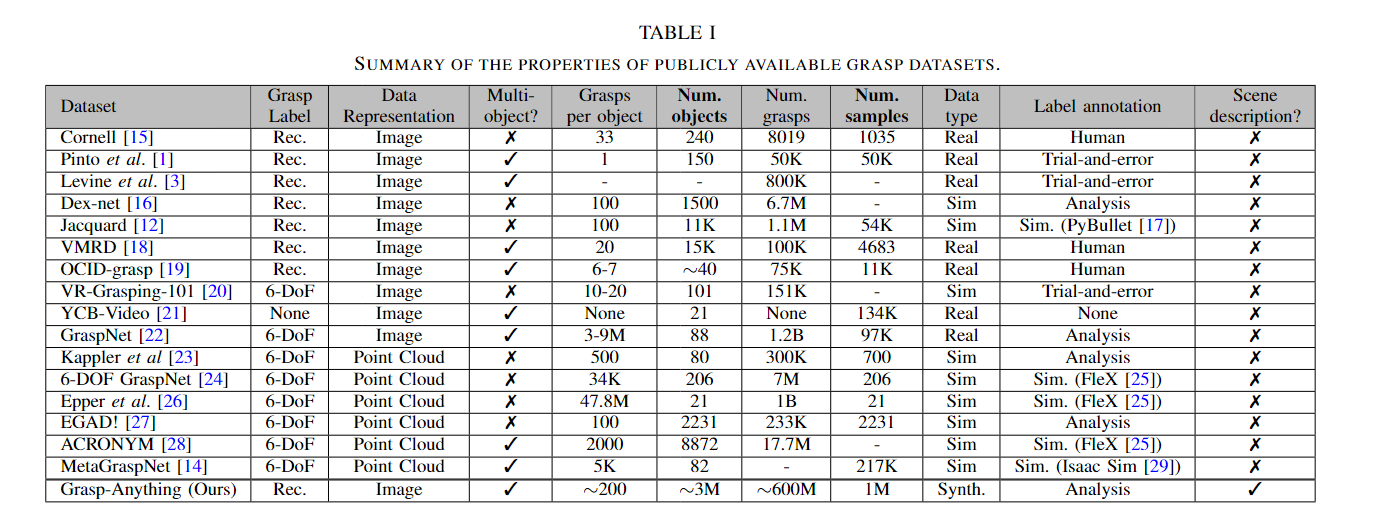
设计抓取数据集时可以考虑许多因素,如数据表示(RGB-D或3D点云)、抓取标签(基于矩形或6-DoF)和数量。
我们的Grasp-Anything数据集与其对应数据集的关键区别在于其普遍性universality。与其他数据集在类别上的限制相比,Grasp-Anything包含在我们的自然生活中观察到的各种对象。
Grasp-Anything 数据集
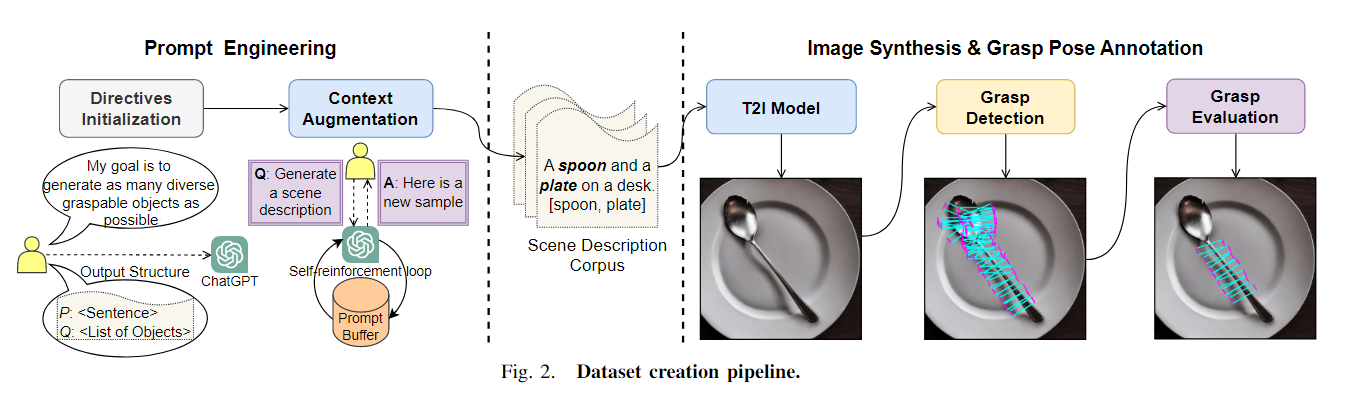
- Scene Generation场景生成:我们利用ChatGPT并执行prompt engineering technique来指导ChatGPT生成不同的场景描述。

生成描述场景排列的文本和指示文本中可抓取对象的列表。the text describing the scene arrangement and a list indicating graspable objects in the text.
给定ChatGPT生成的场景描述,我们使用Stable Diffusion2.1来生成与场景描述一致的图像。然后,我们使用最先进的视觉基础和实例分割模型(OFA [13] 和 SegmentAnything [54])为抓取列表中出现的每个对象收集实例分割掩码。在图像合成阶段结束时,我们为每个参考对象获得一个定位掩码。 - Grasp Pose Annotation掌握姿势注释:
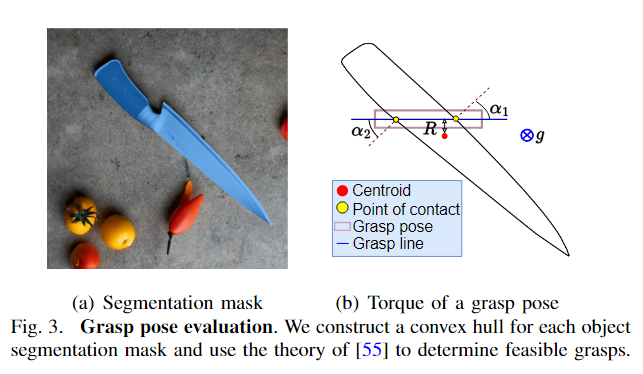
通过计算与抓取相关的净扭矩(表示为T)来确定每个姿势的抓取质量,如下所示:
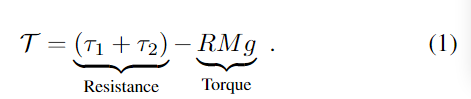
物理公式和内容,后续需要再补充。
- Grasp-Anything Statistics数据集统计:
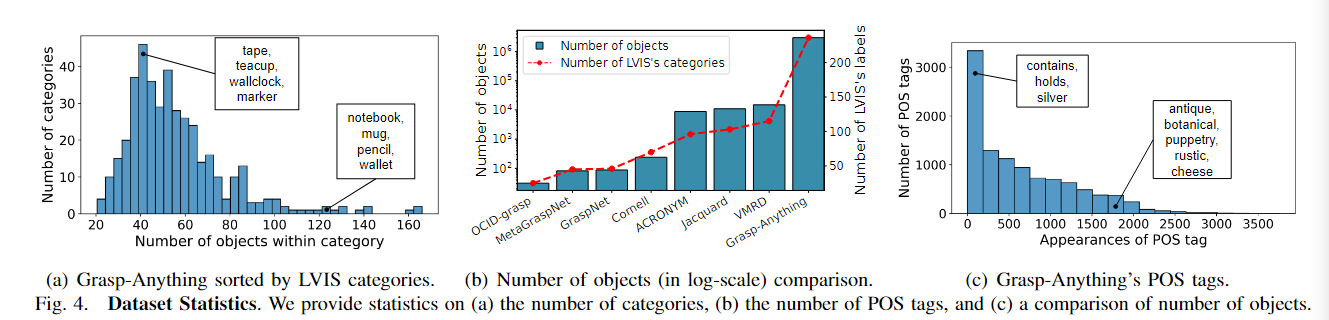
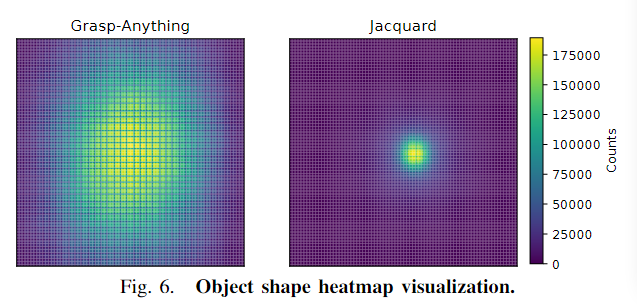
- Grasp Anything 数据集比其他数据集具有更多的对象数量。
- Grasp-Anything 形状多样性程度更大。
实验 - 零镜头抓取检测
-
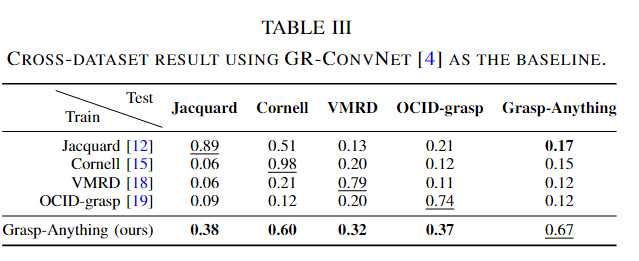
五个数据集上训练三个深度学习抓取网络:GRConvNet[4]、Det-Seg-Refine[19]和GG-CNN[58],数据集:Grasp-Anything、Jacquard[12]、Cornell[15]、VMRD[18]和OCID-Grasp[19]。主要指标是成功率。按出现识别前 70% 的标签。这些标签形成了“Base”类,而其余 30% 成为“New”类。

基础到新的泛化。我们在表II中报告了基础到新的抓取检测结果。结果有两个中心的观察结果。首先,三个基线 GRConvNet、Det-Seg-Refine 和 GG-CNN 在五个数据集上表现出令人满意的性能,这意味着以模型为中心的方法在每个分离的数据集上改进抓取检测结果的空间较少。其次,Grasp-Anything 更具挑战性,因为我们的检测结果低于使用相同方法的相关数据集,因为在测试阶段对看不见的对象的覆盖范围更大。 -
可迁移性大于其他数据集。
-
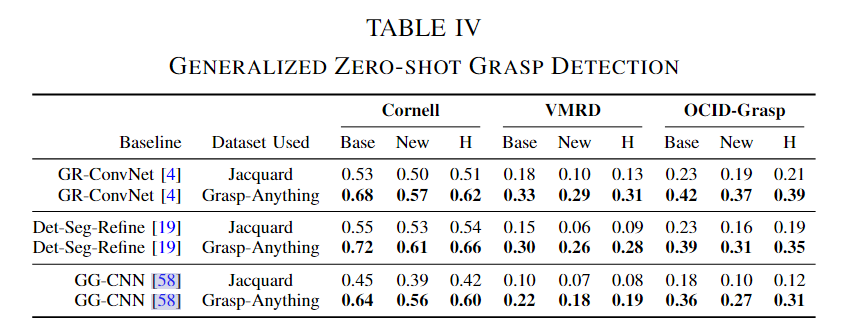
Generalized Zero-shot Learning 广义的无样本学习。在所有情况下,Grasp-Anything 都显着提高了所有基线的性能。
实验 - 机器人评估
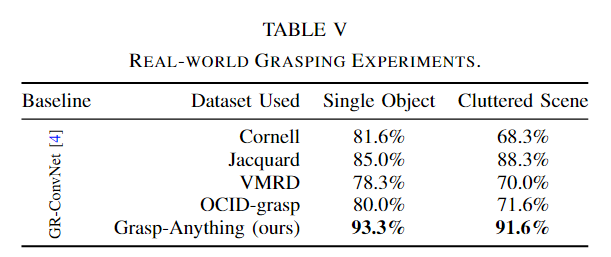
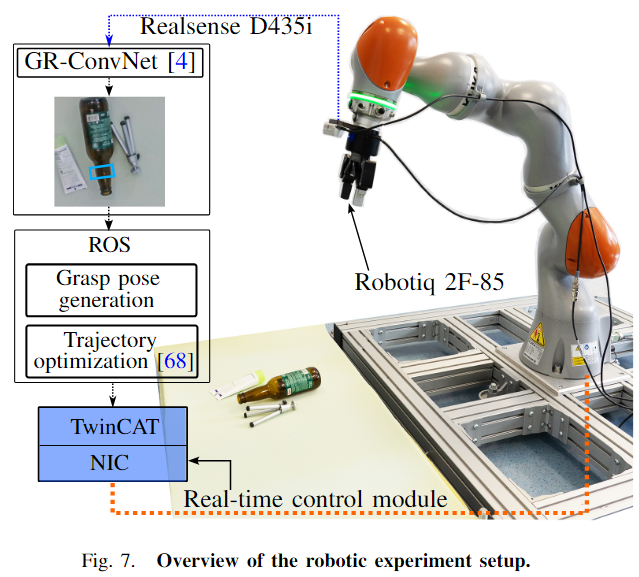
- 对KUKA机器人的机器人评估如图7,使用GR-ConvNet[4]作为抓取检测网络。抓取检测结果使用来自RealSense相机的深度图像转换为6DOF抓取姿态,如[4]所示。评估是针对单个对象和利用一组 15 个对象的杂乱场景进行的。
在图 8 中可视化了由不同数据集的 GR-ConvNet 训练的每日办公布置图像的抓取检测。Grasp-Anything 可以提高相关数据集的抓取检测质量。

图 9 展示了在来自互联网和不同数据集的随机图像上的 Grasp-Anything 数据集上使用预训练的 GR-ConvNet 的抓取检测示例。我们可以看到检测到的抓取姿势在质量和数量上都足够了。

总结
本文主要提出了语言为驱动的抓取数据集Grasp-Anything,其在数量和类别上碾压了之前的数据集,并且希望可以在现实世界中进行zero-shot抓取。【一个数据集论文,看看就行】


![VSCode Vue项目中报错 [vue/require-v-for-key]](https://img-blog.csdnimg.cn/direct/5c4e0c3573d643a9a04b6ae200221f90.png)