爬虫js逆向分析——x平台(实现)
(仅供学习,本案例只是分析流程没有账号)网址:https://xuexi.chinabett.com/

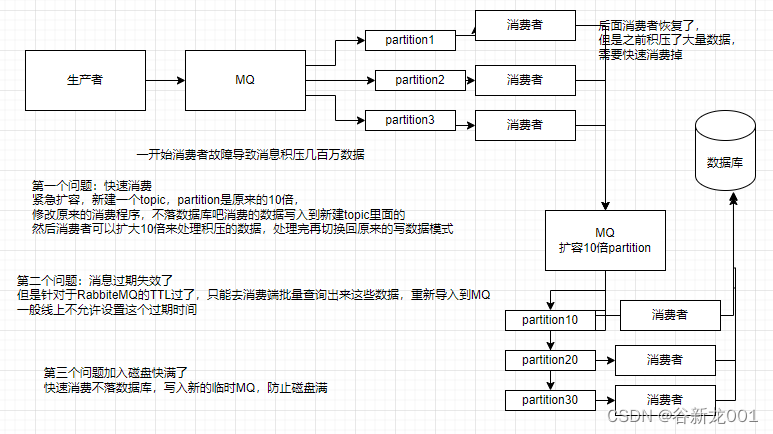
1.分析请求包格式
打开控制台,并勾选保存日志,然后点击登录看发送了什么请求。点击Fetch/XHR筛选出ajax请求。分析发送的数据包。

2.逆向js代码
先逆向出来用到的js代码,之后用python执行它,把下面文件保存为v1.js文件,与python文件在同一个目录。

function s1() {
var data = ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "K", "L", "M", "N", "O", "P", "Q", "R", "S", "T", "U", "V", "W", "X", "Y", "Z", "a", "b", "c", "d", "e", "f", "g", "h", "i", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s", "t", "u", "v", "w", "x", "y", "z"];
var r = Math.floor(Math.random() * 62);
return data[r];
}
function base64encode(str) {
var base64EncodeChars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
var base64DecodeChars = new Array(
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);
var out, i, len;
var c1, c2, c3;
len = str.length;
i = 0;
out = "";
while (i < len) {
c1 = str.charCodeAt(i++) & 0xff;
if (i == len) {
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt((c1 & 0x3) << 4);
out += "==";
break;
}
c2 = str.charCodeAt(i++);
if (i == len) {
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt(((c1 & 0x3) << 4) | ((c2 & 0xF0) >> 4));
out += base64EncodeChars.charAt((c2 & 0xF) << 2);
out += "=";
break;
}
c3 = str.charCodeAt(i++);
out += base64EncodeChars.charAt(c1 >> 2);
out += base64EncodeChars.charAt(((c1 & 0x3) << 4) | ((c2 & 0xF0) >> 4));
out += base64EncodeChars.charAt(((c2 & 0xF) << 2) | ((c3 & 0xC0) >> 6));
out += base64EncodeChars.charAt(c3 & 0x3F);
}
return out;
}
function encryptPwd(password) {
var newPwd = [];
var pwdlength = password.length;
for (i = 0; i < pwdlength; i++) {
newPwd.push(password[i]);
if (i < pwdlength - 1)
newPwd.push(s1());
}
password = newPwd.join('');
return password;
}
3.编写python代码
import requests
import ddddocr
import bs4
import base64
import execjs
# 1.获取返回来的cookie,之后携带者这个cookie再去登录
cookie_dict = {}
res = requests.get(url='https://xuexi.chinabett.com/')
cookie_dict.update(res.cookies.get_dict())
# 2.获取验证码,每次生成验证码的网址不确定,使用bs4获取src属性
# <img id="imgVerifity" src="/Login/GetValidateCode/1706184412747">
soup = bs4.BeautifulSoup(res.text, 'html.parser')
img_tag = soup.find(name='img', attrs={'id': 'imgVerifity'})
img_src = img_tag.attrs['src']
# 3.读取第二步获取到的验证码
res = requests.get(
url='https://xuexi.chinabett.com{}'.format(img_src),
cookies=cookie_dict,
)
cookie_dict.update(res.cookies.get_dict())
ocr = ddddocr.DdddOcr(show_ad=False)
code = ocr.classification(res.content)
# 4.用户名和密码
with open('v1.js', mode='r', encoding='utf-8') as f:
js_string = f.read()
JS = execjs.compile(js_string)
username = JS.call('base64encode', 'fangyiqi')
pwd = JS.call('base64encode', '123123')
pwd = JS.call('encryptPwd', pwd)
print(username, pwd)
# 5.登录
res = requests.post(
url='https://xuexi.chinabett.com/Login/Entry',
data={
'userAccount': username,
'password': pwd,
'userAccount': '/PersonalCenter',
'proVing': code,
}
)
print(res.text)
发送请求后,发现与浏览器登录返回的错误信息一样,成功。