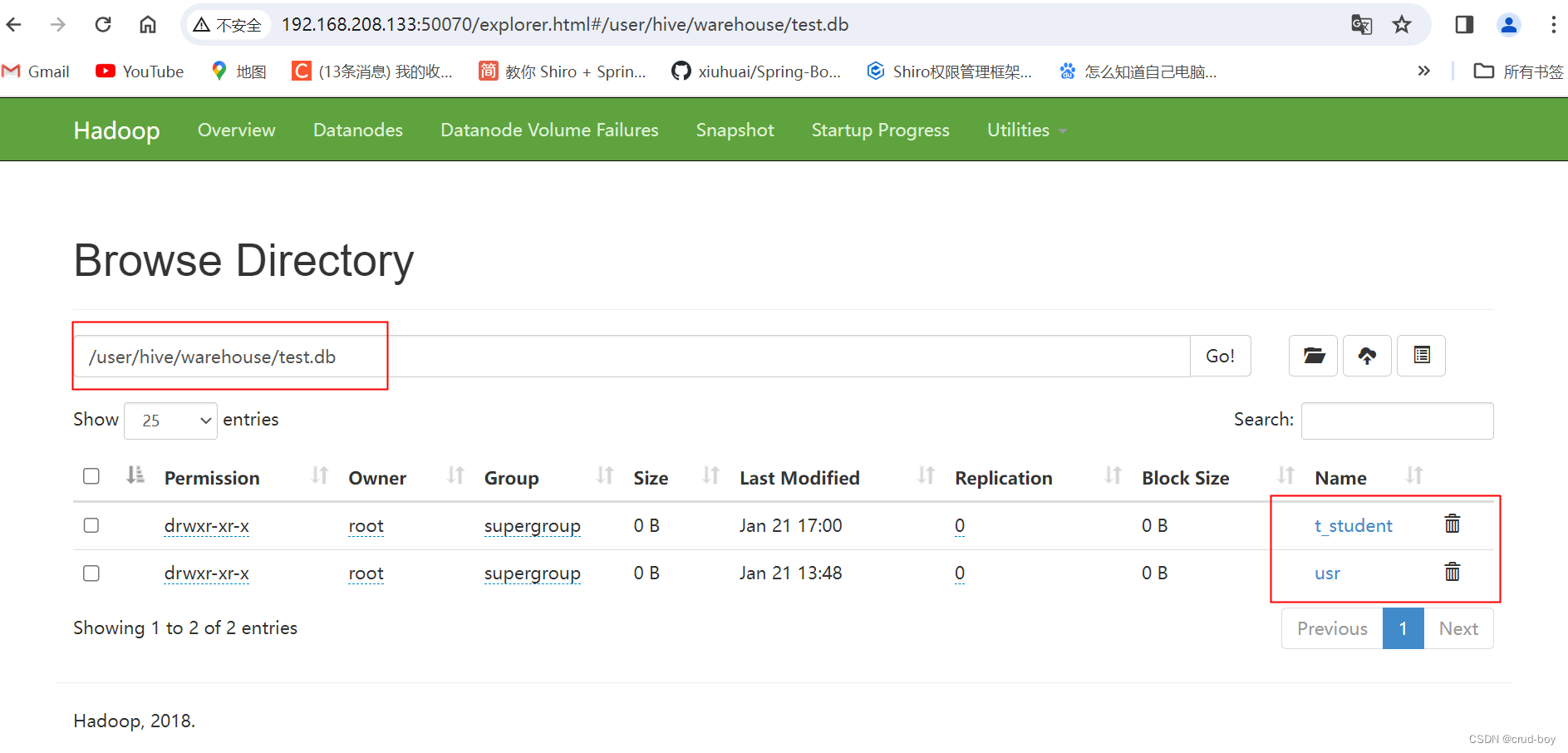
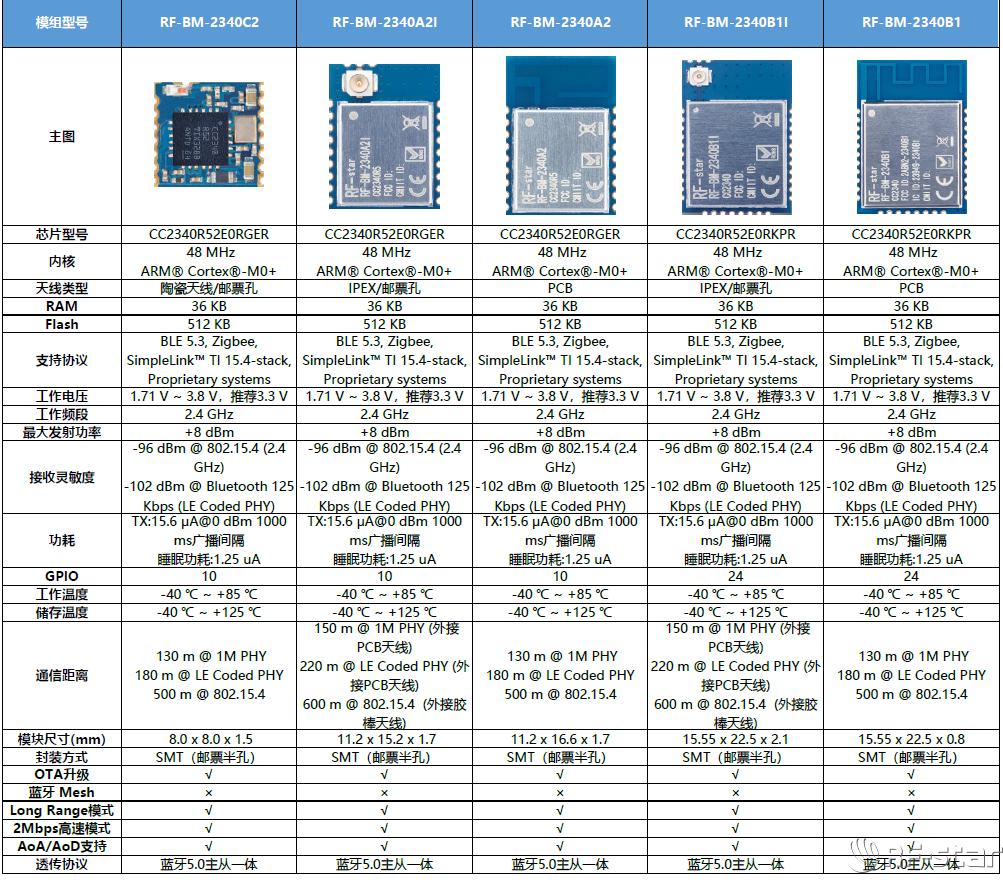
JDK
1 jdk1.8版本后的新特性有哪些?
Java Development Kit (JDK) 1.8(也称为Java 8)在2014年3月发布,引入了许多重要的新特性,以下是其中的一些关键特性:
-
Lambda表达式:
- Java 8引入了lambda表达式,这是一种简洁的函数式编程方式,允许将行为作为方法参数传递或创建匿名函数。通过
->操作符可以定义简短的、可传递的匿名函数。
- Java 8引入了lambda表达式,这是一种简洁的函数式编程方式,允许将行为作为方法参数传递或创建匿名函数。通过
-
函数式接口:
- 函数式接口只有一个抽象方法,它们是lambda表达式的目标类型。Java 8新增了一个名为
java.util.function的包,其中包含许多预定义的函数式接口,如Supplier,Consumer,Function,Predicate, 和UnaryOperator等。
- 函数式接口只有一个抽象方法,它们是lambda表达式的目标类型。Java 8新增了一个名为
-
Stream API:
- Stream API提供了一种新的数据处理方式,可以对集合进行高效、声明式的批量操作。它支持并行流处理,从而能够在多核处理器上利用并发来提高性能。
-
Optional类:
- 新增了
java.util.Optional类,用于表示可能为null的值,以鼓励程序员编写更健壮、避免空指针异常的代码。
- 新增了
-
默认方法和静态方法:
- 接口中现在可以有默认方法(使用default关键字修饰),以及静态方法。这一变化使得接口可以在不打破向后兼容性的前提下增加新的功能。
-
日期与时间API改进:
- 引入了全新的日期和时间API(
java.time包),包括LocalDate、LocalTime、LocalDateTime、ZonedDateTime和Instant等类,提供了更好的日期和时间处理能力,并且这些类是线程安全的。
- 引入了全新的日期和时间API(
-
方法引用和构造器引用:
- 方法引用是对已有方法的直接引用,可以和lambda表达式一起使用,使代码更加简洁易读。构造器引用则是指向类构造器的方法引用。
-
重复注解:
- 现在可以通过
@Repeatable注解来定义可重复使用的注解,简化了多次应用相同注解的情况。
- 现在可以通过
-
元空间(MetaSpace)替代永久代(PermGen):
- JVM内存区域中,移除了永久代,并引入了元空间,用于存储类的元数据信息,解决了 PermGen 内存溢出的问题。
-
** Nashorn JavaScript引擎**:
- JDK 8中包含了Nashorn JavaScript引擎,它允许JavaScript脚本在Java应用程序中执行。
以上列举的是JDK 1.8中最为突出的新特性,它们极大地丰富了Java语言的功能,提升了开发效率,并促进了Java向函数式编程范式的转变
2.如何避免空指针异常?
避免Java中的空指针异常(NullPointerException,简称NPE)是编写健壮代码的重要一环。以下是一些常见的避免空指针异常的方法:
-
对象初始化:
- 确保变量在使用前已经初始化。声明变量时或者在使用前就分配一个非null值。
-
条件检查:
- 在调用对象的方法或访问成员变量之前,先进行非空判断。
1if (object != null) { 2 object.method(); 3} -
Optional类(Java 8及以上版本):
- 使用
java.util.Optional来封装可能为null的对象引用,通过其提供的方法如isPresent()、orElse()和orElseGet()等安全地处理潜在的null值。
1Optional<String> optional = Optional.ofNullable(someString); 2String value = optional.orElse("default"); - 使用
-
Objects.requireNonNull():
- Java 7引入了
Objects类,其中包含requireNonNull()方法,可以在方法参数或字段赋值时抛出明确的异常,而不是在后续操作中引发NPE。
1public void someMethod(String param) { 2 Objects.requireNonNull(param, "param must not be null"); 3 // ... 4} - Java 7引入了
-
@NonNull注解:
- 在IDEA、Eclipse等现代IDE中可以使用
@NonNull注解来标记某个变量或方法参数不允许为null,IDE会根据注解提供编译期或运行时的检查。
1public void someMethod(@NonNull String nonNullParam) { 2 // ... 3} - 在IDEA、Eclipse等现代IDE中可以使用
-
设计模式与API设计:
- 设计接口和方法时考虑是否允许null作为合法输入,如果不能接受null,则应在文档中明确指出,并在方法内部进行适当的校验。
-
防御性编程:
- 在编写getter方法时,可以返回一个默认值或者抛出异常,当内部状态为null时。
1public String getName() { 2 return name == null ? "" : name; 3} -
构造函数:
- 确保构造函数能够初始化所有必需的实例变量,避免创建出不完整的对象实例。
-
String.equals() 和 String.equalsIgnoreCase() 的使用:
- 永远不要对可能为null的字符串直接调用equals(),而应该确保已知非null的字符串作为调用者,这样即使被比较的对象为null也不会抛出空指针异常。
Java
1// 安全的做法
2if ("knownString".equals(variableThatCouldBeNull)) {
3 // ...
4}总之,良好的编程习惯、充分的前置条件验证以及利用现代Java工具和特性都是有效避免空指针异常的关键手段
3 Dubbo是什么?
Dubbo是阿里巴巴公司开源的一个高性能、轻量级的Java RPC(Remote Procedure Call,远程过程调用)框架,它主要用于构建分布式服务。Dubbo使得应用可以更加容易地以面向接口的方式定义、实现和调用远程服务,并提供了智能容错、负载均衡以及服务自动注册与发现等核心功能。
具体来说,Dubbo主要特性包括:
-
RPC服务调用:支持跨网络进行服务间的透明调用,就像本地方法调用一样,开发者只需关注接口定义,无需关心底层通信细节。
-
服务治理:提供丰富的服务治理能力,如服务注册中心、动态服务发现、软负载均衡、流量控制、熔断降级、超时重试、状态监控等。
-
高可用性与扩展性:通过集群部署和服务分组等机制确保服务高可用,同时可以根据业务需求水平或垂直扩展服务节点。
-
多协议支持:支持多种通信协议,如dubbo、rmi、hessian2、http、webservice等。
-
透明化接口调用:基于接口代理方式对用户屏蔽远程调用的细节,使调用远程服务就像调用本地服务一样简单。
-
多语言支持:尽管原生为Java设计,但通过集成其他框架和工具,Dubbo也能支持多语言的服务调用。
总之,Dubbo是一个全方位服务于分布式系统架构的服务框架,旨在简化分布式系统开发,并帮助开发者构建可伸缩、易维护的微服务架构。
Dubbo需要 Web 容器吗?
Dubbo本身不需要Web容器来运行服务提供方和消费方。Dubbo的服务提供者(Provider)和服务消费者(Consumer)可以作为独立Java应用程序启动,它们使用Dubbo内置的服务发布与引用机制,并结合注册中心进行服务发现。
在传统的部署方式下,Dubbo服务可以直接打包为可执行的jar文件并通过Java命令行启动,无需依赖Tomcat、Jetty等Web容器。这样的部署方式更加轻量级,减少了资源消耗并简化了部署流程。
当然,在某些场景下,如果服务提供者本身就是Web应用的一部分,或者需要通过Servlet容器提供的其他功能(如HTTP服务、Session管理等),那么可以选择将Dubbo服务部署在Web容器内。但这并不是Dubbo运行所必需的条件
4.Dubbo内置了哪几种服务容器?
Dubbo内置的服务容器主要包括:
Spring Container:Dubbo支持与Spring框架深度集成,因此可以将服务以Spring Bean的形式管理,使用Spring作为其默认的服务容器。
Jetty Container(混淆信息):在早期的资料中提到了Jetty Container,但实际上Dubbo本身并不直接内置Jetty作为服务容器。Jetty是一个开源的HTTP服务器和Servlet容器,通常用于处理HTTP请求。在Dubbo中,虽然不直接作为服务容器,但可以通过嵌入Jetty提供REST风格的服务调用或者管理界面。
Log4j Container(混淆信息):同样,在上述旧资料中提到的Log4j Container并不是严格意义上的服务容器。Log4j是Java日志记录工具,并非用于承载服务的运行时环境。
实际上,Dubbo主要依赖于Java自身的线程模型以及SPI(Service Provider Interface)机制来加载、管理和运行服务提供者和消费者,而不是像传统Web容器那样管理组件生命周期。后来的Dubbo版本(如Dubbo 2.x之后)引入了微容器的概念,但是它并非指代传统的“服务容器”,而是指Dubbo自身实现的一个轻量级扩展点加载和管理模块,例如ExtensionLoader机制。
4.Dubbo里面有哪几种节点角色?
Dubbo框架中的主要节点角色包括:
服务容器(Container):
负责启动、加载并运行服务提供者,服务消费者也可以部署在服务容器中。服务容器用于托管和管理服务生命周期。
服务提供者(Provider):
在启动时,服务提供者向注册中心注册自己提供的服务,并暴露接口来提供服务。
服务提供者会将自己的服务信息如接口名、版本号、地址等注册到注册中心。
服务消费者(Consumer):
在启动时,服务消费者向注册中心订阅它所需的服务,并从注册中心获取远程服务的注册信息。
消费者根据这些信息进行远程过程调用(RPC),调用远程服务提供者的方法。
注册中心(Registry):
是一个独立的服务,用来存储和管理所有可用服务提供者的地址列表以及元数据信息。
提供者和消费者通过与注册中心交互来进行服务注册和发现。
监控中心(Monitor)(虽然不是严格意义上的“节点”):
监控中心是一个可选组件,用于收集服务调用统计数据,例如调用次数、耗时等信息,以支持对分布式系统进行性能监控和故障排查。
总结起来,在Dubbo体系结构中,Provider、Consumer和Registry是核心的角色,而Monitor则提供了可选的附加功能。每个角色各司其职,共同构成了分布式服务化架构的基础。
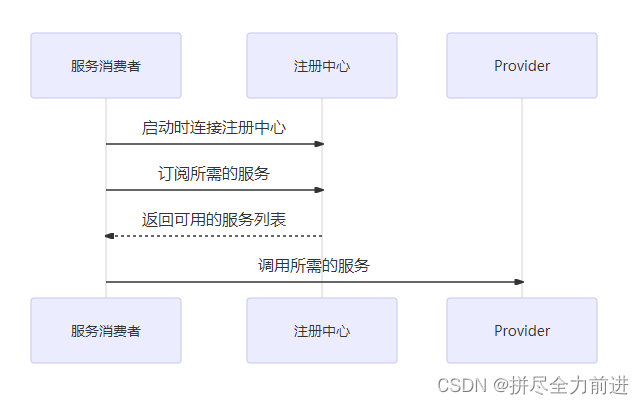
4.Dubbo的服务注册与发现的流程图是怎样的?
Dubbo服务注册与发现的流程可以概括为以下几个步骤:
-
服务提供者(Provider)启动并注册服务:
- 服务提供者在启动时,会通过
ServiceConfig配置类连接到注册中心(如Zookeeper、Nacos等)。 - 提供者将自身信息(包括IP地址、端口号、接口名、版本号等元数据)发送给注册中心进行注册。
- 服务提供者在启动时,会通过
-
服务注册中心存储服务信息:
- 注册中心接收到提供者发来的服务信息后,将其持久化存储,以便消费者查询和订阅。
-
服务消费者(Consumer)启动并订阅服务:
- 消费者启动时同样连接到注册中心,并根据其配置订阅所需要的服务。
- 消费者会定期从注册中心拉取或接收推送的对应服务提供者的地址列表。
-
服务发现与负载均衡:
- 当注册中心有服务提供者的信息更新时,会通知已订阅的服务消费者。
- 消费者拿到最新的服务列表后,在调用服务时,通过
Registry实现服务路由选择,结合Cluster模块进行集群容错和负载均衡策略处理,最终找到一个可用的服务提供者实例发起远程调用。
-
服务调用:
- 根据获取到的提供者地址信息,消费者通过Dubbo的代理机制生成服务接口的代理对象,执行方法调用时实际上是请求被转发至选定的提供者节点上。
流程图通常会包含以下关键组件和交互过程:
- Provider
- Consumer
- Registry (注册中心)
- Protocol (通信协议层)
- Proxy (服务代理层)
- Invoker (调用器)
- Cluster (集群策略)
各个组件之间通过箭头表示信息流向,清晰展示服务注册、订阅、发现以及调用的具体逻辑流转。由于当前文本环境下无法直接显示图像,请参考相关文档或在线资源以获得可视化流程图
Dubbo高手之路5,Dubbo服务注册与发现(文末送书)_dubbo服务注册有顺序-CSDN博客
5.Dubbo默认使用什么注册中心,还有别的选择吗?
Dubbo默认使用的注册中心是Zookeeper,这是因为Zookeeper在分布式系统中作为服务注册与发现组件有广泛的应用和良好的性能表现。除了Zookeeper之外,Dubbo还支持其他注册中心选项,例如Redis、Multicast和Simple注册中心:
- Multicast:基于组播协议的服务发现方式,不需要额外的中心节点,但依赖于网络环境对组播的支持。
- Redis:利用Redis作为注册中心存储服务提供者信息,适合已经使用Redis做为基础设施的场景。
- Simple:一种简单的内存注册中心,通常用于测试环境,因为它不会持久化任何数据且不支持集群。
不过,在实际生产环境中,Zookeeper依然是Dubbo推荐的注册中心方案,因为其稳定性和成熟度较高。随着Dubbo的发展,后续可能还会增加对更多注册中心类型的原生支持,具体支持情况可以参考最新的官方文档。
6 Dubbo有哪几种配置方式?
Dubbo支持以下几种配置方式:
-
XML 配置文件方式
- 在XML配置文件中,服务提供者和服务消费者通过
<dubbo:service>和<dubbo:reference>标签来定义接口、实现类以及相关参数。
- 在XML配置文件中,服务提供者和服务消费者通过
-
properties 配置文件方式
- 通过properties格式的配置文件进行服务配置,这种方式相对较少直接使用,但可以通过Spring框架的支持加载属性配置。
-
Annotation(注解)配置方式
- 通过在Java代码中添加Dubbo提供的注解,如@Service、@Reference等,可以直接在类或方法级别上声明服务接口、实现类以及相关属性。
-
API 配置方式
- 在Java代码中,通过编程方式创建和初始化
ServiceConfig、ReferenceConfig等配置对象,并设置相关属性来配置服务。
- 在Java代码中,通过编程方式创建和初始化
-
Spring Boot 自动配置
- 对于Spring Boot项目,可以利用Dubbo的Spring Boot Starter自动配置特性简化配置过程,只需要在application.properties或application.yml中指定相应的配置项即可。
这些配置方式可以根据实际项目需求和开发团队的偏好灵活选择和组合使用。
7 Dubbo 核心的配置有哪些?
Dubbo的核心配置非常丰富,涵盖了服务提供者、消费者、协议、注册中心等多个层面。以下是一些核心的配置项:
-
服务级别配置:
interface:接口名称,定义了暴露或引用的服务接口。version:服务版本,用于不同版本的服务隔离。group:服务分组,同一接口在不同分组中可以有多个实现。timeout:调用超时时间(毫秒)。retries:失败重试次数。loadbalance:负载均衡策略,如random随机、roundrobin轮询等。actives:并发请求数量限制。async:是否开启异步调用模式。
-
提供者(Provider)配置:
registry:注册中心地址,例如zookeeper://127.0.0.1:2181。protocol:服务暴露使用的协议,如dubbo、rmi等,并设置相应协议的端口和线程池大小等参数。threads:服务线程池大小。server:指定服务端容器类型,如netty服务器。export:服务导出配置,包括IP、端口号等。
-
消费者(Consumer)配置:
check:是否检查服务提供者是否存在。subscribe:订阅服务信息。cluster:集群方式,如failover、failsafe等。mock:当服务不可用时,可配置一个Mock对象或返回值。
-
注册中心相关配置:
register:是否向注册中心注册。subscribe:是否从注册中心订阅服务提供者列表。registry.id:注册中心Bean的ID。
-
路由规则与过滤器配置:
router:路由规则配置,可以根据条件将请求转发到不同的服务提供者。filter:链路过滤器配置,用于添加自定义拦截逻辑。
-
高级特性配置:
hash.arguments:决定使用哪些方法参数参与一致性哈希算法。hash.nodes:一致性哈希虚拟节点数量。
这些配置可以通过XML文件、注解或者API编程方式进行设置。实际使用时,根据具体业务需求和系统架构进行灵活调整和扩展。由于Dubbo框架持续更新和发展,具体的配置项和细节可能随版本变化,请以最新官方文档为准
8. Dubbo启动时如果依赖的服务不可用会怎样?
Dubbo启动时,如果检测到依赖的服务不可用(例如服务提供者未启动或网络不通等),按照Dubbo的默认配置行为:
默认检查:Dubbo会尝试在启动阶段检查依赖的服务是否可用。若服务不可用,它将会抛出异常,并阻止Spring容器的初始化完成。
配置控制:可以通过设置check="false"来关闭这个启动时的检查行为。这意味着即使依赖的服务在应用启动时不可用,Dubbo也不会抛出异常阻止应用启动,而是会在消费者尝试调用服务时进行动态发现和连接。
因此,默认情况下,为了避免由于依赖的服务缺失导致应用程序无法正常启动,Dubbo会确保所有依赖的服务在启动阶段是可达并且可用的。如果希望在服务不可用时仍然启动消费方应用,则需要手动调整配置以适应相应场景的需求。
9.Dubbo推荐使用什么序列化框架,你知道的还有哪些?
Dubbo推荐使用Hessian作为序列化框架,因为它具有较快的性能和较小的体积,并且在早期版本中是默认的选择。不过随着技术发展,Dubbo也支持并推荐了其他序列化框架:
Hessian:轻量级、快速的Java对象序列化实现,跨语言兼容性较好。
FST:Fast Serialization的简称,以高性能著称,特别适合大数据量传输场景。
Kryo:高效的Java对象图形序列化库,用于快速地将Java对象转换为字节流。
Java原生序列化(Java Serializable):Java自带的序列化机制,但相比Hessian、FST或Kryo,其效率较低且存在一些限制。
Protobuf(Protocol Buffers):Google开发的一种高效、平台无关、可扩展的序列化框架,能提供更小的序列化数据和更快的速度,同时支持版本兼容性和跨语言互操作性。
Thrift:由Apache开发的另一个高效的跨语言服务开发框架,其中包括一个序列化组件,适用于构建高性能的服务。
JSON:通过Jackson、Fastjson等库支持JSON格式的序列化与反序列化,易于阅读和处理,但相对二进制序列化方案而言,数据体积较大,性能稍逊。
开发者可以根据不同的业务需求(如性能、跨语言需求、数据大小等)选择合适的序列化框架配置到Dubbo中。
10.Dubbo默认使用的是什么通信框架,还有别的选择吗?
Dubbo默认使用Netty作为底层通信框架,它是一个高性能、异步事件驱动的网络通信框架。除了Netty之外,Dubbo还提供了对其他NIO框架的支持,比如Mina和Grizzly等。这意味着开发者可以根据项目需求和团队熟悉的技术栈选择合适的通信框架集成到Dubbo中。在配置Dubbo时,可以通过调整相关配置来指定使用不同的通信框架。
11.Dubbo有哪几种负载均衡策略,默认是哪种
Random LoadBalance(随机):这是Dubbo默认的负载均衡策略。它按照权重设置随机概率,即服务提供者可以根据权重获得不同比例的调用请求。
RoundRobin LoadBalance(轮询):基于权重的轮询机制,会根据每个服务提供者的权重来进行循环分配请求。
LeastActive LoadBalance(最少活跃调用数):优先将请求分发给当前处理请求数量最少的服务提供者,这样可以避免某一服务节点过载,实现更均匀的负载分配。
ConsistentHash LoadBalance(一致性哈希):根据请求参数进行虚拟节点映射,相同的请求会被转发到同一个服务提供者上,保证了在服务提供者列表变更时仍能尽可能地维持原有的请求分布,对于有状态或需要会话保持的场景特别有用。
总结起来,默认情况下,Dubbo使用的是Random LoadBalance作为负载均衡策略
12 Dubbo支持服务多协议吗?
是的,Dubbo支持服务多协议。开发人员可以根据需求在同一个服务上配置不同的协议或者在不同服务上使用不同的协议。默认情况下,Dubbo使用的是自定义的Dubbo协议,它采用单一长连接和NIO异步通讯,适合于大并发小数据量的服务调用场景。
除了Dubbo协议外,Dubbo还支持其他多种通信协议,包括但不限于:
Hessian协议:基于HTTP传输,轻量级远程调用协议。
HTTP协议:基于HTTP进行服务调用,方便与其他HTTP客户端和服务集成。
RMI协议:Java原生的远程方法调用协议。
Thrift协议:跨语言、跨平台的服务接口定义与序列化协议,基于TCP传输。
gRPC协议:Google开发的高性能、开源、通用的RPC框架,基于HTTP/2协议提供服务。
通过配置,开发者可以选择适合项目特性的协议来优化服务间的通信性能和兼容性。
13.Dubbo可以对结果进行缓存吗?
是的,Dubbo可以对结果进行缓存。Dubbo提供了一种声明式缓存机制,允许服务消费者在调用远程服务时将返回结果缓存起来,以便于后续相同的请求能够快速获取结果,从而提高热门数据的访问速度,并减少对服务提供者的压力。
具体实现上,Dubbo通过自定义CacheFilter(或类似功能组件)来实现结果缓存,开发者可以通过配置启用缓存功能并设置相应的缓存策略,如缓存时间、缓存条件等。不过需要注意的是,Dubbo本身并不内置一个完整的高性能缓存解决方案,而是提供了与第三方缓存系统的集成能力,比如可以结合Redis、Memcached等外部缓存系统来实现更高效的结果缓存。
14 Dubbo服务之间的调用是阻塞的吗?
Dubbo服务之间的调用默认是同步阻塞的。在默认情况下,当一个服务消费者发起对提供者的服务调用时,它会等待请求结果返回后才会继续执行后续操作。
然而,Dubbo也支持异步调用模式,在这种模式下,调用不会立即阻塞等待结果,而是返回一个Future对象,消费者可以通过这个Future对象在未来某个时刻获取实际的结果。这样一来,消费者线程可以继续执行其他任务,而不需要一直等待服务调用完成,从而实现非阻塞式调用。
15、Dubbo支持分布式事务吗?
Dubbo框架本身不直接支持分布式事务,但它可以通过集成第三方的分布式事务解决方案来实现分布式事务管理。例如:
TCC(Try-Confirm-Cancel)模式:Dubbo可以与开源的TCC补偿型分布式事务框架如tcc-transaction结合使用,通过在服务中定义try、confirm和cancel三个阶段的方法来处理分布式事务。
Saga模式:通过集成诸如Seata这样的分布式事务解决方案,支持Saga分布式事务模型。
XA两阶段提交:虽然Dubbo本身不支持,但可通过集成支持XA协议的分布式事务协调器(如Atomikos或Bitronix),配合JTA事务管理器实现在数据库层面的分布式事务。
本地消息表/最终一致性方案:对于部分场景,也可以采用基于消息队列或者其他最终一致性策略来保证分布式事务的一致性要求。
因此,尽管Dubbo本身并不内置完整的分布式事务功能,但它能够很好地与其他分布式事务中间件协同工作,为开发者提供分布式事务的支持
16 Dubbo支持服务降级吗?
是的,Dubbo支持服务降级(Service Degradation)。当服务提供者出现故障或者由于某些原因需要限制流量时,可以通过配置实现服务降级策略,以保护整个系统在极端情况下依然能够稳定运行。具体表现为:
Mock功能:Dubbo允许为服务消费者设置Mock实现类或返回值,在调用失败或者服务不可用时,可以快速地返回预设的模拟数据,避免抛出异常影响上层业务流程。
服务熔断与限流:结合Hystrix等第三方组件,Dubbo可以实现服务熔断机制,即在一段时间内请求错误率达到一定阈值后,后续请求不再转发到实际的服务提供者,而是直接返回错误信息或者mock数据,达到服务降级的目的。同时,通过配置限流规则,可以在流量过大时限制对服务提供者的请求频率,从而进行服务降级处理。
自定义降级逻辑:开发者可以根据实际情况定制服务降级逻辑,比如通过Dubbo的Filter机制,在特定条件下执行不同的fallback操作。
这些措施确保了在遇到服务不稳定、资源紧张等情况时,系统能优先保证核心业务正常运行,并对外提供一定的可用性保障。
17 服务提供者能实现失效踢出是什么原理?
Dubbo的通信采用基于NIO(非阻塞I/O)技术,底层通信框架默认使用Netty来实现服务之间的远程过程调用(RPC)。通过封装请求和响应消息,并将其在客户端和服务端之间进行序列化和反序列化传输,从而完成分布式服务间的高效、可靠通信。同时,Dubbo支持多种协议,如Dubbo协议、HTTP、Hessian、RMI等,可以根据实际应用场景选择不同的通信协议
18.Dubbo的管理控制台能做什么?
Dubbo管理控制台是一个用于管理和监控Dubbo服务的可视化工具,它提供了丰富的功能来帮助运维和开发人员更好地控制和理解分布式环境中的服务状态和服务治理。具体可以实现以下操作:
-
服务查询:
- 查看当前注册到注册中心的所有服务列表及其详细信息,包括服务名、版本、分组、接口、方法等。
- 查询各个服务提供者的在线状态、元数据以及调用统计信息。
-
服务治理:
- 路由规则管理:设置和修改路由策略,比如根据条件过滤调用、动态切换服务版本等。
- 动态配置:实时更新服务的配置参数,无需重启服务即可生效。
- 服务降级:在特定条件下禁用或启用某些服务,以防止雪崩效应或者进行灰度发布。
- 访问控制:实施黑白名单机制,限制服务调用者权限。
- 权重调整:根据业务需求动态调整不同服务提供者的权重,影响负载均衡的效果。
- 负载均衡策略管理:选择并配置不同的负载均衡算法。
-
服务测试:
- 直接通过控制台对指定的服务进行远程调用,并查看返回结果,方便验证服务接口是否可用及响应内容。
-
监控与统计:
- 实时展示服务调用情况,包括但不限于调用量、成功率、耗时、TPS(每秒事务数)等指标。
- 提供日志跟踪和异常监控能力,便于排查问题。
-
集群管理:
- 管理多个服务实例之间的关系和配置,确保整个集群的健康运行。
总之,Dubbo管理控制台是一个全方位的服务治理工具,能够协助用户有效地管理和优化微服务架构中的各种组件和服务交互过程
19.Dobbo的调用流程是什么?
Dubbo的调用流程涉及服务提供者(Provider)和服务消费者(Consumer)两个主要角色,以及注册中心(Registry)、监控中心(Monitor)等组件之间的交互。以下是一个简化的Dubbo调用流程:
服务提供者启动与注册:
服务提供者在启动时,通过ServiceConfig的export方法开始对外暴露服务。
export过程中会经过一系列适配器,如通过RegistryProtocol将服务信息注册到注册中心。
注册中心可以有多个,服务会在每个注册中心进行注册,包含服务接口、版本、地址(IP:Port)等元数据。
服务消费者订阅与发现:
服务消费者启动时,创建ReferenceConfig并配置要引用的服务接口及版本等信息。
消费者向注册中心订阅对应的服务,获取并缓存可用的服务提供者列表。
当注册中心的服务提供者列表发生变化时,注册中心会异步通知消费者更新本地缓存。
服务路由与负载均衡:
消费者根据从注册中心获取的服务列表,结合配置的路由规则和负载均衡策略,选择一个或多个服务提供者生成Invoker对象。
Cluster层负责合并多个服务提供者的Invoker,形成集群视图,并可能在此阶段执行容错处理。
远程调用:
根据选择的Invoker,通过Protocol层(如DubboProtocol)封装请求并发送给实际的服务提供者。
使用客户端传输框架(如Netty)建立网络连接,发起远程调用请求。
响应处理:
服务提供者接收到请求后,通过反向代理找到具体的服务实现类并执行业务逻辑。
执行完成后,服务提供者将结果返回给消费者。
监控与治理:
在整个调用过程中,Dubbo可集成监控中心收集调用统计数据,支持服务治理功能,例如动态调整配置、限流熔断等。
以上流程概括了Dubbo的核心调用机制,具体的实现细节可能会因版本和配置的不同而有所差异。
19.Dobbo支持动态添加服务吗?
是的,Dubbo支持动态添加服务。在Dubbo框架中,服务提供者(Provider)可以动态地向注册中心注册新的服务实例,而服务消费者(Consumer)则能够实时感知到这些服务的变化并进行调用。
具体实现上:
- 当一个新的服务提供者启动时,它会将自身的服务元信息(包括接口、版本、地址等)注册到注册中心(如ZooKeeper、Nacos或Eureka等)。
- 服务消费者通过订阅服务接口相关的配置节点,能够自动发现和更新可用的服务提供者列表。
- 这样,当服务提供者集群增加新节点(即添加新的服务提供者实例)时,消费者无需重启即可知道并开始调用新提供的服务。
此外,Dubbo也支持服务治理特性,允许在运行时动态调整服务配置、路由规则、权重等属性,从而实现对服务的灵活管理和控制,这也间接支持了服务的动态添加与管理。
zookeeper
1. zookeeper是什么?
ZooKeeper 是一个分布式的、开源的分布式应用程序协调服务,由Apache软件基金会开发和维护。它设计用于大型分布式系统中提供一致性服务,尤其是那些需要高可用性、数据一致性和协调机制的应用程序。
ZooKeeper 提供的主要功能包括但不限于:
- 配置维护:在集群环境中存储和管理共享配置信息。
- 命名服务:为分布式环境中的资源分配全局唯一标识符(ID)或名称。
- 分布式同步:通过锁和其他同步原语支持分布式应用程序间的协调和同步操作。
- 组服务:支持组成员管理,例如监控成员状态变化、选举主节点等。
在技术层面,ZooKeeper 采用一种层次化的命名空间来存储数据,并使用Zab协议保证其强一致性。客户端可以通过简单的API与ZooKeeper进行交互,以实现诸如 leader election(领导者选举)、distributed locking(分布式锁)、queueing(队列)等功能。
许多大数据框架,如Hadoop和HBase,都依赖于ZooKeeper来管理集群状态和服务发现。ZooKeeper 被设计成高效且可靠的,能够处理大量的并发请求并快速响应客户端的变化通知。
2. zookeeper都有哪些功能?
ZooKeeper具有以下核心功能:
-
数据节点(ZNode)管理:
- 提供类似于文件系统的命名空间,支持创建、读取、更新和删除操作(CRUD)。
- 每个ZNode都可以存储数据,并且有版本号,可以进行原子性的数据变更。
-
分布式协调服务:
- 通过监控(watch)机制,客户端可以在数据或子节点发生变化时收到通知,实现事件驱动的分布式系统设计。
- 支持临时节点,当创建该节点的会话结束时,节点自动被删除,常用于服务存活检测和服务注册注销。
-
集群管理和选主选举:
- ZooKeeper提供了一种简单可靠的机制来进行分布式环境下的主节点选举,例如在Hadoop中选择NameNode或ResourceManager等。
- 集群成员可以通过ZooKeeper进行动态加入和离开,同时其他成员能够实时感知这些变化。
-
配置管理与同步:
- 在分布式系统中,应用程序可以将共享配置信息存放在ZooKeeper中,从而实现集中化管理和实时同步。
-
分布式锁与队列:
- ZooKeeper可以作为基础构建块来实现高级分布式同步原语,如互斥锁、读写锁、条件变量、有序并发执行控制等。
- 可以用来构建分布式队列,如生产者-消费者模型中的先进先出队列或屏障同步等。
-
命名服务:
- 提供全局唯一ID分配,或者为分布式系统中的资源提供可解析的名称。
-
状态一致性保证:
- 使用Zab协议保证从客户端看到的数据视图是一致的,即在一个事务被提交后,所有的客户端都会看到这个更新。
总之,ZooKeeper作为一个强大的服务协调工具,在大规模分布式环境中起到关键作用,帮助解决诸如数据同步、集群协调、命名服务等问题。
3.zookeeper有哪几种部署方式?
ZooKeeper有以下几种部署方式:
-
单机模式(Standalone Mode)
- 在这种模式下,ZooKeeper只在一台服务器上运行一个实例。主要用于开发测试环境,因为在这种配置中,如果该服务器出现故障,服务将不可用,无法提供高可用性保障。
-
集群模式(Cluster Mode / Replicated Mode)
- 在生产环境中,ZooKeeper通常以集群形式部署,包含多个ZooKeeper服务器实例。这些实例组成一个集群,共同维护一份相同的数据状态,并通过内部选举机制动态选择一个Leader节点进行写操作,其他节点作为Follower参与数据同步和投票。这样即使部分服务器宕机,只要集群中的大多数服务器存活,整个系统仍然可以对外提供服务,保证了高可用性和容错性。
-
伪集群模式(Pseudo-Distributed Mode)
- 这种模式在一个物理机器上启动多个ZooKeeper实例,模拟分布式集群的部署情况。每个实例使用不同的端口和数据目录,它们之间通过配置文件相互连接并形成一个集群。这种方式同样适用于测试环境,便于在单机上模拟多节点集群的行为。
-
多数据中心模式(Multi-Datacenter Replication)
- 虽然ZooKeeper本身不直接支持跨数据中心的主从复制或者多活模式,但是可以通过一些额外的工具或扩展实现跨数据中心的部署方案,确保在不同地理位置的数据中心之间保持数据一致性。在实际应用中,需要结合网络延迟、带宽、数据同步策略等因素进行定制化设计和部署。
4. zookeeper使用什么协议?
ZooKeeper使用了两种主要的协议:
内部通信协议:
ZooKeeper集群中的服务器之间通过一种基于TCP/IP的私有协议进行通信,以保证数据在集群内的高效同步和一致性。这种协议主要用于选举、数据复制、心跳检测等操作。
ZooKeeper原子广播协议(ZAB, Zookeeper Atomic Broadcast):
ZAB是专门为ZooKeeper设计的一种支持崩溃恢复的原子广播协议,它确保了即使在部分系统失败的情况下,分布式系统依然能够实现一致性和有序性。ZAB协议不仅处理消息广播,还包括了在系统启动或出现故障时的关键状态同步阶段,即崩溃恢复模式。ZAB协议是ZooKeeper实现高可用性和数据一致性的核心算法。
注意:虽然在一些资料中可能会提到ZooKeeper与Paxos算法的关系,但实际上ZAB协议并不是直接基于Paxos算法,而是受其启发,并针对ZooKeeper自身的应用场景进行了简化和优化,旨在提供一种更加适合ZooKeeper服务特性的共识机制。
5 zookeeper的通知机制是怎样的?
ZooKeeper的通知机制是一种基于事件监听(Watcher)的机制,允许客户端注册对特定ZNode节点或事件的兴趣。当这些节点的数据发生变化、被创建、删除或者子节点发生改变时,ZooKeeper服务端会向相应的客户端发送异步通知。
具体流程如下:
-
客户端注册Watcher:
- 客户端在读取某个ZNode或者执行操作(如getData, exists等)时可以设置一个Watcher。
- Watcher可以是一次性的,即触发一次后就会被移除;也可以是持久的,但ZooKeeper仅保证数据变更时的一次触发通知,之后如果还需要继续监控变化,客户端需要重新注册Watcher。
-
服务器处理Watcher事件:
- 当ZooKeeper服务端检测到与已注册Watcher相关的事件发生时,例如数据内容改变、节点被删除或新增子节点等,它会将该事件添加到事件队列中。
-
服务器发送通知:
- ZooKeeper服务端通过TCP连接将事件通知推送给客户端。
- 注意,事件通知是异步且一次性推送,意味着对于同一个Watcher,即使目标节点多次变化,客户端只会收到一次通知,因此在实际应用中,通常需要循环注册Watcher来持续监听。
-
客户端回调Watcher:
- 客户端接收到事件通知后,根据预先定义的回调函数进行响应处理。
-
Watch事件类型:
- 数据变更(DataWatch)
- 子节点变更(ChildWatch)
- 会话状态变更(SessionWatch)
通过这种灵活的通知机制,ZooKeeper使得分布式系统中的各个组件能够快速响应集群中配置和服务状态的变化,从而实现诸如服务发现、分布式锁、协调选举等多种分布式系统协调功能。
6 zookeeper是如何实现分布式锁的?
ZooKeeper实现分布式锁的过程主要包括以下几个关键步骤:
-
创建临时有序节点:
- 当一个客户端需要获取分布式锁时,它会在ZooKeeper中指定的一个父节点下创建一个临时有序节点。例如,所有客户端都在
/locks/my_lock路径下创建临时有序节点,如/locks/my_lock/lock-0000000001、/locks/my_lock/lock-0000000002等,ZooKeeper会自动为这些节点添加递增的序列号。
- 当一个客户端需要获取分布式锁时,它会在ZooKeeper中指定的一个父节点下创建一个临时有序节点。例如,所有客户端都在
-
判断是否获得锁:
- 客户端通过比较自己创建节点的序号与其他已存在的节点序号来决定是否获取到锁。
- 如果当前客户端创建的节点序号是最小的(即没有比其更小的节点),则认为该客户端获得了锁。
-
监听前驱节点:
- 如果当前客户端未能获取到锁(即其节点不是最小序号的节点),那么它会对其前面的那个序号最小的节点(即下一个可能释放锁的节点)设置Watcher监听器。
- 这样当持有锁的客户端完成任务并删除自己的节点时,ZooKeeper会通知等待中的客户端。
-
获取锁:
- 当被监听的节点被删除时,ZooKeeper会向之前注册了Watcher的客户端发送通知。
- 收到通知的客户端再次检查当前序号最小的节点,如果发现自己现在是序号最小的节点,则可以认为获取到了锁,并开始执行临界区代码。
-
释放锁:
- 完成操作后,持有锁的客户端会主动删除自己在ZooKeeper中创建的临时有序节点。
- 删除节点后,ZooKeeper会通知下一个等待者,从而继续将锁传递给下一个客户端。
这种基于临时有序节点和Watcher机制的分布式锁实现方式具有高度容错性,因为临时节点会随着客户端会话结束而自动清理,能够有效防止死锁和资源泄漏问题。同时,由于ZooKeeper提供的强一致性保证,分布式锁的获取和释放操作是线性一致的
7 zookeeper的选举机制及流程是什么?
ZooKeeper的选举机制是一个用于确定集群中哪个节点作为Leader的过程,它是基于ZooKeeper内部的原子广播协议(ZAB, Zookeeper Atomic Broadcast)设计实现的。在ZooKeeper集群中,有一个Leader节点负责处理写请求并复制更新到Follower节点,而Follower节点则接收客户端读请求和从Leader同步数据。
选举机制概述:
- 集群中的每个服务器(Server)在启动后都会尝试进行一次选举。
- 选举的目标是选择一个具有最高zxid(事务ID)或epoch(纪元号)的节点作为Leader。
- 每个Server都有一票,并通过投票来决定Leader。
- 当Leader出现故障、网络分区或其他原因导致失去多数节点的支持时,会触发新一轮的选举。
选举流程详细步骤:
-
初始化选举阶段(LOOKING状态):
- 所有ZooKeeper服务器在启动时进入LOOKING状态,开始发起一轮选举。
- 每个服务器首先给自己投票,并将投票信息发送给其他服务器。
-
第一轮投票与统计票数:
- 接收到投票信息的服务器比较接收到的投票和自身的投票:
- 如果对方的zxid更大,则更新自己的投票为对方的投票。
- 如果对方的zxid相同但其myid(服务器编号)更小,那么按照最小myid的原则,也会更新投票。
- 如果对方的投票不优于当前投票,则忽略之。
- 接收到投票信息的服务器比较接收到的投票和自身的投票:
-
等待与重新投票:
- 服务器收集来自其他服务器的投票,并根据投票结果判断是否满足过半数原则。
- 如果某个服务器收到了超过半数服务器的投票,并且这些投票中大多数都投给了它自己,那么这个服务器就认为自己获得了足够的支持,可以成为Leader。
- 若在规定时间内没有服务器达到法定数量的投票,则所有服务器重新进入投票过程,直到选举出Leader。
-
Leader确认与追随者同步:
- 当选举出Leader之后,该Leader会向所有Follower发送确认消息,并开始接受客户端请求以及管理事务。
- Follower接收到Leader的消息后,会切换至FOLLOWING状态,开始从Leader那里接收事务日志和快照进行数据同步。
-
恢复与重新同步:
- 在后续运行过程中,如果发生网络分区恢复或者新的服务器加入,可能会再次触发选举流程,确保任何时候都有一个有效的Leader。
总之,ZooKeeper选举的核心思想是通过多轮投票达成共识,并且优先选择具有最新数据状态(高zxid值)和/或较低标识符(myid)的节点作为Leader,以保证数据的一致性和服务的连续性。
8 zookeeper集群最少要几台机器,集群规则是怎样的?
ZooKeeper集群最少需要3台机器。这是因为在ZooKeeper中,为了保证数据一致性以及在部分服务器宕机时仍然能够正常提供服务,采用了过半数(Quorum)机制来达成共识。
集群规则是基于“2N+1”原则,其中N为正整数,这意味着要容忍N台服务器故障,集群至少需要2N + 1台服务器。例如,如果要容忍1台服务器故障(即最多允许1台服务器宕机),那么至少需要3台服务器(2 * 1 + 1 = 3)。如果要容忍2台服务器故障,则至少需要5台服务器(2 * 2 + 1 = 5),以此类推。
在实际运行中,只要集群中有超过一半的服务器节点存活并能进行通信,那么整个ZooKeeper集群就可以继续对外提供服务,并通过内部选举机制确定一个新的Leader节点以处理写操作。因此,对于任何大小的集群来说,必须确保任何时候都有过半数的节点在线才能保持系统的可用性。
9 zookeeper集群中有几种角色
ZooKeeper集群中有三种角色:
Leader (领导者)
Leader节点是ZooKeeper集群的核心,负责处理客户端的所有写操作请求(事务请求)。
它确保了所有事务按照全局有序的方式进行提交,并将更新的事务信息广播给所有的Follower节点。
Follower (跟随者)
Follower节点接收客户端的读请求,并且会从Leader那里复制最新的数据和事务日志。
在选举过程中,Follower参与投票来选出新的Leader,同时也会在Leader出现故障时成为潜在的Leader候选人。
Observer (观察者)
Observer节点是一种特殊的非投票成员,它与Follower类似,也是从Leader那里复制数据并提供读服务。
不同之处在于Observer不参与Leader选举过程中的投票,这使得Observer可以在不影响集群决策能力的前提下提高系统的读性能,尤其是在大型部署中,可以减轻Leader的压力并减少网络带宽消耗。
因此,在ZooKeeper集群中,节点主要分为有投票权的角色(Leader和Follower)以及无投票权但能提供扩展读取能力的角色(Observer)。
10 zookeeper集群支持动态添加机器吗?
ZooKeeper集群支持动态添加机器,即在集群运行过程中增加或减少节点。从ZooKeeper 3.5版本开始,引入了动态重新配置(Dynamic Reconfiguration)的功能,使得在不影响集群服务的情况下进行节点的添加和删除成为可能。
具体步骤包括:
-
准备新节点:
- 在新的服务器上安装并配置ZooKeeper。
- 更新
zoo.cfg文件以包含新节点信息,并确保新节点与其他节点之间能正常通信。
-
启动新节点:
- 启动新节点作为Follower或Observer(如果启用观察者模式)。
-
执行动态重新配置:
- 对于ZooKeeper 3.5及更高版本,可以通过调用
reconfig命令或者使用客户端API来更新集群配置。 - 使用现有的Leader节点或者其他有权限的节点执行
reconfig命令,将新的服务器信息加入到集群配置中。
- 对于ZooKeeper 3.5及更高版本,可以通过调用
-
集群同步与确认:
- 集群会根据新的配置信息自动调整角色,新增节点将与集群中的其他节点进行数据同步。
- 完成同步后,新节点将成为集群的有效组成部分,提供服务。
注意:在执行动态添加或删除操作时,必须遵循“过半数”原则,即任何时候在线节点数量必须大于等于(N/2 + 1),其中N为初始集群设定的总节点数,这样才能保证集群始终可以选举出Leader并保持可用状态。同时,在进行动态配置更改之前,请务必阅读相关文档以了解具体的步骤和注意事项。
11 zookeeper集群中怎么保证主从节点的状态同步?
ZooKeeper集群中主从节点的状态同步是通过ZooKeeper自研的原子广播协议ZooKeeper Atomic Broadcast (ZAB)来实现的。ZAB协议确保了即使在部分系统失败的情况下,整个ZooKeeper集群依然能够达到数据的一致性和有序性。
ZAB协议的核心机制包括两种模式:
-
恢复模式(Recovery Mode):
- 当ZooKeeper集群启动或者Leader服务器出现故障时,集群进入恢复模式。
- 在此模式下,所有Follower(以及Observer,如果存在的话)会尝试进行Leader选举。
- 当新的Leader被选举出来后,它会将自身的事务日志提交到过半数以上的Follower节点上,直到这些Follower节点的状态与Leader同步。
- 同步完成后,集群退出恢复模式,进入广播模式。
-
广播模式(Broadcast Mode):
- 在广播模式下,Leader接收客户端请求,并将每一个写操作转换为一个事务提议(Proposal)。
- Leader会将这个提议发送给所有的Follower节点。
- 当超过半数的Follower确认接收到并接受了这个提议后(形成法定多数),Leader会提交这个事务,并通知所有的Follower节点也提交该事务。
- 所有Follower节点会按照相同的顺序执行这些事务,从而保证集群内所有节点的数据状态一致。
通过这样的设计和协议,ZooKeeper集群中的每个节点都能够保持一致的数据视图,即便在网络分区或节点失效等复杂场景下也能确保最终一致性
12. zookeeper集群中中为什么要有主节点?
在ZooKeeper集群中,主节点(Leader)的存在是为了确保整个系统的数据一致性、事务处理的有序性和高效性。以下是主要原因:
-
全局数据一致性:
- ZooKeeper作为一个分布式协调服务,需要为客户端提供强一致性的数据视图。Leader节点负责管理所有的更新操作(写操作),它将收到的写请求转化为事务,并确保这些事务按照全局有序的方式被所有服务器执行和提交。
-
事务处理:
- 所有的数据变更事务都必须由Leader节点发起并协调完成。Leader会将事务提议发送给Follower节点,只有当超过半数以上的Follower节点确认了该事务后,事务才会被提交。这种机制保证了即使在网络分区的情况下,也能避免数据不一致的问题。
-
性能优化:
- 将读写操作分离可以提高系统性能。Leader专门处理写操作以及同步数据到其他Follower节点,而Follower节点则主要负责处理读请求,这样能够减轻单个节点的压力,提高响应速度。
-
简化设计与实现:
- 通过集中式的决策者(Leader),可以简化分布式系统的设计和实现复杂度。在复杂的分布式环境下,只有一个节点进行事务管理和冲突解决,使得系统行为更加确定且易于理解和调试。
-
容错恢复:
- 当Leader出现故障时,集群能够自动触发选举过程选出新的Leader,从而维持系统的高可用性。同时,由于ZooKeeper采用了原子广播协议ZAB,新当选的Leader能确保继续从上一个已知的好状态开始服务,从而保障数据的一致性。
总之,ZooKeeper中的主节点是确保整个集群在各种情况下都能对外提供一致性和可靠服务的核心组件。
13 zookeeper的java客户端都有哪些?
ZooKeeper官方提供了Java客户端API,开发者可以直接使用这些API来与ZooKeeper服务进行交互。以下是与ZooKeeper配合的Java客户端主要形式:
-
官方原生客户端库:
org.apache.zookeeper.ZooKeeper:这是Apache ZooKeeper项目提供的核心Java客户端API。它提供了一系列方法用于连接、创建节点、读取数据、更新数据、监听事件等操作。
-
基于官方客户端封装的第三方库:
- Curator:Curator是Netflix开源的一个ZooKeeper客户端库,对ZooKeeper原生API进行了高度抽象和简化,提供了更加高级的服务发现、分布式锁、领导选举等功能,使得开发者可以更简单地使用ZooKeeper。
- Kazoo:另一个流行的ZooKeeper Java客户端库,提供了易于使用的API以及一些额外的功能和工具类。
-
Spring Cloud Zookeeper:
- Spring Cloud Zookeeper为Spring Cloud框架下的ZooKeeper客户端实现,它将ZooKeeper集成到了Spring Boot应用中,为微服务架构提供了服务注册与发现、配置管理等功能。
-
其他企业级或社区扩展的客户端:
- 不同公司和社区可能根据自身需求开发了特定的ZooKeeper客户端实现,这些客户端通常会提供额外的企业级特性,如更好的容错处理、性能优化、便捷的编程模型等。
总之,尽管有多种不同的Java客户端可供选择,但大多数情况下,开发者首先接触并使用的将是Apache ZooKeeper自带的标准Java API,对于复杂的场景或者需要更高级功能时,则可能会考虑使用如Curator这样的封装库。
14 zookeeper常用的命令有哪些?
ZooKeeper的常用命令分为客户端命令和服务器端命令两部分。以下是它们的一些基本操作:
ZooKeeper客户端命令(通过zkCli.sh工具):
-
启动客户端连接到ZooKeeper服务:
Shell1./zkCli.sh -server ip:port如果是本地ZooKeeper服务,可以省略
-server参数。 -
退出客户端:
Shell1quit 或者 exit -
查看指定节点下的子节点列表:
Shell1ls /path/to/node -
创建节点并设置数据:
Shell1create /path/to/node data其中
data是要存储在节点上的内容,如果不指定,默认为空。 -
获取节点的数据内容:
Shell1get /path/to/node -
删除节点:
Shell1delete /path/to/node -
设置节点数据:
Shell1set /path/to/node data -
设置临时节点:
Shell1create -e /ephemeral-node data -
注册Watcher监听器:
Shell1get /path/to/node watch -
取消注册Watcher监听器: 由于Watcher是一次性的,需要重新设置才能再次监听,因此不能直接取消已注册的Watcher,而是需要重新调用带有watch参数的方法来覆盖之前注册的Watcher。
ZooKeeper服务器端命令(通常通过zkServer.sh脚本):
-
启动ZooKeeper服务:
Shell1bin/zkServer.sh start -
查看ZooKeeper服务状态:
Shell1bin/zkServer.sh status -
停止ZooKeeper服务:
Shell1bin/zkServer.sh stop -
重启ZooKeeper服务:
Shell1bin/zkServer.sh restart
这些是基础的命令行操作,实际使用时根据具体版本和需求可能会有一些变种或扩展。对于更复杂的管理和运维任务,可能需要结合配置文件、系统环境变量等进行操作。
Spring系列
1 spring的IOC和AOP原理是什么?
Spring框架中的Inversion of Control (IOC) 和 Aspect-Oriented Programming (AOP) 是两种关键的编程范式和设计原则,它们在Spring中被实现为强大的容器和服务支持。
Inversion of Control (IoC):
- 原理:在传统的编程方式中,对象的创建、初始化以及管理通常由程序自身控制。而在IoC模式下,这种控制权被反转给了一个第三方容器(如Spring容器)。应用程序不再直接实例化依赖的对象,而是定义需要哪些接口或类,并通过配置文件或者注解声明依赖关系。Spring容器负责根据这些配置信息创建并组装所有对象,并在整个应用生命周期内管理它们之间的依赖关系。
- 实现机制:Spring IoC容器使用BeanFactory来加载、解析bean的定义(XML配置或注解),并通过工厂模式或其他机制(如默认的ApplicationContext)来实例化bean,并处理其依赖注入(DI,Dependency Injection)。
Aspect-Oriented Programming (AOP):
- 原理:AOP是一种编程范式,它允许开发者从横切关注点的角度来模块化代码,将那些与业务逻辑无关但又广泛应用于系统各处的功能(例如日志记录、事务管理、权限检查等)抽取出来作为“切面”(Aspect)。这些切面可以在不修改原始业务逻辑代码的前提下,在运行时以动态织入的方式对目标方法进行增强。
- 实现机制:Spring AOP基于代理模式实现。当客户端请求到达目标方法时,首先会经过代理层。代理对象在调用真实业务方法前执行前置通知(Before advice),之后执行实际的方法体,完成后再执行后置通知(After advice)、返回通知(After-returning advice)、异常通知(After-throwing advice)等。环绕通知(Around advice)则可以完整地包裹方法执行前后的行为。
总结来说,Spring通过IoC实现了组件的松耦合和灵活配置管理,而通过AOP则提供了面向切面的编程能力,增强了系统的可维护性和扩展性。
2 spring的启动加载流程是怎样的?
Spring的启动加载流程在不同的应用场景中略有差异,这里主要描述Spring框架在基于XML配置和基于Java配置(包括Spring Boot)两种常见情况下的大致启动加载流程:
1. Spring基于XML配置的传统应用启动流程:
- 读取配置文件:Spring首先会读取
applicationContext.xml或自定义命名的XML配置文件,解析其中的bean定义、组件扫描路径等信息。 - 创建BeanFactory容器:根据配置文件构建一个
DefaultListableBeanFactory或其他类型的BeanFactory实例,它是IoC容器的核心实现。 - 载入Bean定义:通过
BeanDefinitionReader读取并解析XML配置中的bean定义,并将它们注册到BeanFactory中。 - 完成依赖注入(DI)准备:BeanFactory处理好所有的bean定义后,可以识别出bean之间的依赖关系。
- 初始化ApplicationContext:创建
ApplicationContext,它继承自BeanFactory,并提供了更多高级功能,如事件发布、国际化支持、AOP代理等功能。 - 调用refresh()方法:调用
ApplicationContext的refresh()方法来启动整个容器的刷新过程:- 预实例化单例bean:根据bean定义加载并实例化所有singleton作用域的bean。
- 应用BeanPostProcessor:对已实例化的bean执行任何已经定义的
BeanPostProcessor的前置和后置处理逻辑。 - 解决依赖关系:按需解决bean之间的依赖关系,并注入属性值。
- 触发初始化回调:对于实现了
InitializingBean接口或者声明了init-method方法的bean,执行相应的初始化操作。 - 发布ContextRefreshedEvent:最后,发布
ContextRefreshedEvent事件通知所有监听者容器刷新完毕。
2. Spring Boot应用启动流程:
- 引导类加载:从带有
@SpringBootApplication注解的主类开始,该注解包含了@Configuration、@EnableAutoConfiguration和@ComponentScan三个注解的功能,指示Spring Boot如何进行自动配置和组件扫描。 - SpringApplication.run():运行
SpringApplication.run(Application.class, args)方法启动应用程序。- 初始化环境:创建
ApplicationContext前先初始化SpringApplicationRunListeners和应用环境(Environment)。 - 加载sources:根据用户的应用类和其他配置来源(如@EnableAutoConfiguration注解标记的类、额外的@Configuration类等)加载Bean定义资源。
- 创建ApplicationContext:创建合适的
ApplicationContext类型(通常为AnnotationConfigApplicationContext或XmlWebApplicationContext),并将配置信息注入。 - 注册监听器与处理器:注册各种监听器、处理器以及BeanPostProcessor等扩展点。
- 加载自动化配置:基于当前环境和classpath下的jar包自动配置Bean。
- 实例化Bean:按照依赖关系顺序初始化和实例化所有Bean。
- 启动失败处理器:如果在启动过程中发生异常,将调用
FailureAnalyzer分析错误,并可能尝试修复。 - 触发ApplicationReadyEvent:当所有bean都初始化完成后,发布
ApplicationReadyEvent事件,表明应用已完全准备好对外提供服务。
- 初始化环境:创建
无论是哪种方式,最终目标都是为了创建一个完整的Spring IoC容器,使得应用程序可以通过依赖注入的方式获取并使用所需的Bean。
3 springMVC的底层执行流程是怎样的?重要的类有哪些?
Spring MVC的底层执行流程可以分为以下几个主要步骤,并涉及到多个关键类:
-
请求接收:
- 请求首先由Web服务器(如Tomcat、Jetty)接收,然后转发给DispatcherServlet。
- 关键类:
org.springframework.web.servlet.DispatcherServlet
-
前端控制器初始化与调度:
- DispatcherServlet初始化时会加载配置文件(如:web.xml或Java配置类),创建并初始化各种组件。
- 当接收到HTTP请求时,DispatcherServlet作为前端控制器,负责调度整个处理过程。
-
处理器映射器(HandlerMapping):
- DispatcherServlet调用HandlerMapping来查找能够处理当前请求的处理器(Controller)。
- 关键类:
org.springframework.web.servlet.HandlerMapping - 具体实现类:
RequestMappingHandlerMapping(基于注解的映射)和SimpleUrlHandlerMapping(基于XML配置的URL映射)等。
-
处理器适配器(HandlerAdapter):
- 找到合适的处理器后,通过HandlerAdapter调用其方法执行业务逻辑。
- 关键类:
org.springframework.web.servlet.HandlerAdapter - 具体实现类:
HttpRequestHandlerAdapter、AnnotationMethodHandlerAdapter(对于@Controller注解的方法)以及RequestMappingHandlerAdapter等。
-
控制器(Controller)执行:
- 控制器处理请求,执行业务逻辑,通常返回一个模型和视图名称(ModelAndView)或者直接响应数据(如RESTful服务中的ResponseBody)。
- 关键类:应用中定义的各种Controller类
-
模型与视图解析器(ModelAndViewResolver):
- 如果控制器返回的是ModelAndView,DispatcherServlet将把控制权交给ModelAndViewResolver进行视图解析。
- 关键类:
org.springframework.web.servlet.ViewResolver - 具体实现类:
InternalResourceViewResolver(用于JSP)、ThymeleafViewResolver(用于Thymeleaf模板引擎)等。
-
视图渲染:
- 视图解析器根据视图名称找到具体的视图技术实现,并渲染视图,生成最终要发送给客户端的响应内容。
- 视图层的关键类取决于使用的视图技术。
-
响应结果输出:
- 渲染后的结果通过HttpServletResponse对象输出到客户端。
在整个过程中,还有其他一些重要的辅助组件:
HandlerExceptionResolver:用于全局异常处理。LocaleResolver和ThemeResolver:用于国际化和主题切换支持。MultipartResolver:处理文件上传请求。
以上流程描述了一个典型的Spring MVC请求处理过程及其相关的核心类。实际应用中可能会有更复杂的拦截器(Interceptor)和其他自定义扩展点参与其中。
4 springboot支持的日志有哪些?默认的是什么?怎么配置
Spring Boot 支持多种日志框架,并默认集成了 Logback 作为其日志实现。以下是一些 Spring Boot 支持的日志库:
- Logback:这是 Spring Boot 默认的日志系统,基于 SLF4J(Simple Logging Facade for Java)接口实现。
- Java Util Logging ( JUL):Java 标准日志API。
- Log4j2:一个流行的日志框架,如果在类路径中发现了 Log4j2 的相关依赖,Spring Boot 也可以使用它。
- Log4j(较老版本):虽然较旧,但在特定场景下依然可用。
- SLF4J:只是一个抽象层,不是具体的日志实现,Spring Boot 通过 SLF4J 提供对各种日志系统的桥接。
默认配置下,Spring Boot 应用程序会将 ERROR、WARN 和 INFO 级别的日志输出到控制台。如果你想要更详细的日志记录,可以按照以下方式配置:
-
启动参数:
- 在命令行中添加
--debug参数来启动应用以启用 DEBUG 级别日志: Code1java -jar myapp.jar --debug
- 在命令行中添加
-
application.properties 或 application.yml 配置文件:
- 若要全局启用 DEBUG 级别日志,可以在
application.properties文件中设置: Properties
这样会将根日志级别设为 DEBUG,所有日志器都将输出 DEBUG 及以上级别的日志信息。1logging.level.root=DEBUG
- 若要全局启用 DEBUG 级别日志,可以在
-
自定义配置: 如果你想对特定包或类进行单独的配置,可以指定它们的日志级别:
Properties1logging.level.org.springframework.web=DEBUG -
外部配置文件: Spring Boot 允许你通过 logback.xml 或 logback-spring.xml 来提供自定义的日志配置。将此文件放在 classpath 中,例如 resources 目录下,Spring Boot 将自动检测并使用这些配置。
-
高级配置: 对于更复杂的日志格式和输出目标(如文件、数据库等),可以通过编写完整的 Logback 配置文件来实现。
注意,如果你希望切换到 Log4j2 或其他日志框架,需要排除 Spring Boot 默认提供的 Logback 依赖,并引入相应的日志实现依赖。同时,提供对应的日志框架配置文件
5 springboot的数据源有哪些?怎么配置?
Spring Boot 支持多种数据源,包括但不限于以下几种常见的数据库连接池:
- HikariCP
- Tomcat JDBC Pool
- Apache DBCP2
- Apache Commons Pool2 with Tomcat JDBC
- H2 (内存数据库)
- Oracle、MySQL、PostgreSQL、SQL Server 等关系型数据库的数据源
配置 Spring Boot 数据源的方法通常包括在 application.properties 或 application.yml 配置文件中设置相关属性。以 MySQL 为例,使用 HikariCP 连接池进行配置的示例:
Properties
1# application.properties 文件
2spring.datasource.type=com.zaxxer.hikari.HikariDataSource
3spring.datasource.url=jdbc:mysql://localhost:3306/mydatabase
4spring.datasource.username=myuser
5spring.datasource.password=mypassword
6spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
7spring.datasource.hikari.maximum-pool-size=10 # 可选,设置连接池大小
8
9# 如果不指定 spring.datasource.type,Spring Boot 将自动根据类路径选择一个可用的连接池实现。或者,在 application.yml 中配置:
Yaml
1# application.yml 文件
2spring:
3 datasource:
4 url: jdbc:mysql://localhost:3306/mydatabase
5 username: myuser
6 password: mypassword
7 driver-class-name: com.mysql.cj.jdbc.Driver
8 hikari:
9 maximum-pool-size: 10对于其他类型的数据源,只需要更改相应的 URL、用户名、密码以及可能需要的特定连接池属性即可。
如果需要配置多数据源,可以为每个数据源定义一个独立的 bean,并通过 @Qualifier 注解在需要注入数据源的地方指明具体要使用的那个数据源bean。例如:
Java
1@Configuration
2public class MultipleDataSourcesConfig {
3
4 @Bean(name = "dataSourceOne")
5 @ConfigurationProperties(prefix = "spring.datasource.one") // 对应 properties 中 spring.datasource.one.*
6 public DataSource dataSourceOne() {
7 return DataSourceBuilder.create().build();
8 }
9
10 @Bean(name = "dataSourceTwo")
11 @ConfigurationProperties(prefix = "spring.datasource.two") // 对应 properties 中 spring.datasource.two.*
12 public DataSource dataSourceTwo() {
13 return DataSourceBuilder.create().build();
14 }
15}然后在需要用到的数据访问层或服务层中注入对应的数据源:
6 springcloud的常用开发框架有哪些?
Java Spring Cloud是一套基于Spring Boot实现的微服务开发工具集,它提供了多种用于构建云原生应用和服务治理的开发框架。以下是一些Spring Cloud中常用的开发框架和服务组件:
-
服务注册与发现:
- Eureka:Netflix开源的服务注册中心。
- Consul:HashiCorp提供的分布式服务发现和配置共享工具。
- Zookeeper:Apache ZooKeeper可以作为服务注册与发现的后端存储。
-
服务调用:
- Feign:一个声明式HTTP客户端,简化了服务间API的调用过程。
- Ribbon:客户端负载均衡器,提供服务调用时的负载均衡策略。
- OpenFeign:Spring Cloud OpenFeign是Feign的Spring Boot封装版本,更好地集成到Spring环境中。
-
服务网关:
- Zuul:Netflix开源的边缘服务,用作微服务架构中的API网关。
- Spring Cloud Gateway:Spring团队推出的第二代服务网关,功能更强大且性能优越。
-
配置管理:
- Spring Cloud Config:集中化的外部配置管理,支持Git仓库或本地文件系统作为配置源。
- Spring Cloud Config Server:提供配置服务器功能,统一管理所有微服务的配置信息。
-
服务熔断与降级:
- Hystrix:Netflix提供的容错管理工具,实现服务熔断、降级和隔离功能。
- Resilience4j:轻量级故障恢复库,作为Hystrix的替代方案,逐渐被更多开发者采纳。
-
消息总线:
- Spring Cloud Bus:利用消息代理(如RabbitMQ或Kafka)对分布式系统的配置进行刷新和监控。
-
分布式跟踪:
- Sleuth:提供分布式的追踪解决方案,并能够与Zipkin等可视化工具整合以查看请求链路。
-
服务安全:
- Spring Cloud Security:为OAuth2和JWT等安全机制提供了简单易用的抽象层。
-
服务部署与运维:
- Spring Cloud Kubernetes:针对Kubernetes环境提供了服务发现、配置绑定等功能的支持。
- Spring Cloud CLI:命令行工具,用于快速搭建和管理Spring Cloud应用。
随着技术发展,部分早期使用的组件已经进入维护模式或者被新组件取代,例如Eureka在Spring Cloud Hoxton.SR10及之后的版本已被弃用,推荐使用Spring Cloud LoadBalancer结合服务发现组件。在实际项目中,根据项目的具体需求和技术栈选择合适的Spring Cloud组件是非常重要的。
7 springcloud的熔断是怎么实现的?原理是什么?
Spring Cloud在实现熔断机制时,早期版本主要依赖Netflix开源的Hystrix组件。Hystrix通过以下原理来实现服务熔断:
原理:
-
服务调用监控: Hystrix为每个依赖服务的调用创建一个单独的线程池或者信号量(具体取决于配置)。每次服务调用都会被封装在一个命令对象(HystrixCommand)中执行,该命令对象负责执行实际的服务调用并监视其执行情况。
-
熔断器(Circuit Breaker): 熔断器根据一段时间内请求的成功率、失败率或超时率等指标来判断是否触发熔断。当达到预设阈值时(例如,在10秒内有超过5次请求失败),熔断器会切换到“开路”状态,即开启熔断。
-
降级策略(Fallback): 开启熔断后,后续对同一依赖服务的所有请求都将不再转发给实际服务,而是直接执行用户定义的fallback逻辑,返回预先设置好的默认值或错误提示,避免因故障服务拖慢整个系统的响应速度和可用性。
-
半开状态(Half-Open): 在一定时间窗口(如5秒)后,熔断器将尝试进入半开状态,允许有限数量的请求穿透到实际服务。如果这些请求成功,则认为服务恢复健康,关闭熔断;否则,继续维持熔断状态。
-
统计与监控: Hystrix还提供了实时统计和监控功能,可以收集并展示各命令的执行结果、延迟、成功率以及熔断状态等信息,帮助开发者更好地理解和优化系统性能。
随着技术发展,Spring Cloud从Hoxton.SR1之后开始推荐使用Spring Cloud Gateway或Resilience4j等替代方案来实现熔断功能。Resilience4j作为轻量级容错库同样提供了熔断器(CircuitBreaker)功能,并且与Spring Boot和Spring Cloud生态体系有更好的集成支持。
8 springcloud的eureka和zoopeeker的区别是什么
Spring Cloud Eureka 和 ZooKeeper 都是分布式服务治理框架中用于服务注册与发现的组件,但它们的设计目标和实现细节有所不同:
Spring Cloud Eureka:
-
设计目标:Eureka 是 Netflix 开源的服务注册与发现组件,专为微服务架构设计。
-
功能特点:
- 提供了服务注册表,各个微服务启动时会向 Eureka 注册自身服务实例信息(如IP、端口等)。
- 支持健康检查和服务实例状态管理,包括服务实例上下线通知。
- 使用 REST API 进行通信,简单易用且支持高可用集群部署。
- 原生支持 Spring Cloud 生态系统,集成方便。
-
数据一致性:Eureka 默认牺牲了一定的一致性以提高可用性和响应速度,在网络分区或故障情况下,可能会出现短暂的数据不一致,但在大多数场景下能够满足需求。Eureka采用AP(Available, Partition-tolerant)模型。
Apache ZooKeeper:
-
设计目标:ZooKeeper 是一个分布式的、开放源码的分布式应用程序协调服务,它不是专门为服务发现而设计,而是提供了一个通用的协调平台,可以应用于多种分布式场景,如配置管理、命名服务、分布式锁等。
-
功能特点:
- 提供了类似文件系统的数据节点(ZNode),可以存储数据并监听节点变化。
- 强调强一致性,使用ZAB协议保证事务处理的原子性和顺序性。
- 适用于需要强一致性的服务发现和其他协调任务。
-
数据一致性:ZooKeeper 优先保证数据一致性(C),在正常网络环境下可以做到CP(Consistent, Partition-tolerant),在网络分区的情况下也尽量保持数据一致性。
总结来说,Eureka 更偏向于轻量级、专门针对服务注册与发现优化的解决方案,强调高可用和响应速度;而 ZooKeeper 是一个更通用的分布式协调工具,适合对一致性要求较高的场景。在实际项目选择时,可以根据业务需求和技术栈来决定使用哪种服务注册与发现方案。
9 springcloud的网关的主要做了哪些
Spring Cloud Gateway作为Spring Cloud生态中的微服务API网关,主要负责以下几个方面的工作:
-
统一入口:
- 所有客户端对内部微服务的请求都通过Gateway进行路由和转发,成为系统对外暴露的唯一入口。
-
路由功能(Routing):
- 根据定义的路由规则动态地将不同请求分发到不同的后端服务。这些规则可以基于路径、HTTP方法、Header、Host等多种条件。
-
过滤器链(Filter Chain):
- Spring Cloud Gateway内置了一系列过滤器,可以实现权限校验、日志记录、限流、熔断、重试、添加响应头等操作。同时允许自定义过滤器以满足特定业务需求。
-
安全控制:
- 网关层可以集成OAuth2、JWT等身份验证和授权机制,提供统一的安全管控策略,例如在进入微服务集群前进行鉴权。
-
负载均衡:
- 在找到目标服务实例后,网关可以通过配置实现负载均衡,支持轮询、随机、权重分配等策略。
-
服务降级与熔断:
- 通过集成Hystrix或Resilience4j等库,可以在网关层面设置服务熔断和降级策略,当后端服务不可用时,快速返回默认响应或错误页面。
-
缓存管理:
- 对于某些高访问量且变化不频繁的服务接口,Gateway可以设置缓存策略,减少对后端服务的压力并提高响应速度。
-
监控与统计:
- 提供各种指标统计和健康检查,可与Prometheus、Zipkin等工具集成,便于进行系统的性能监控和故障排查。
总之,Spring Cloud Gateway的核心职责是作为系统的边缘服务,承担起流量控制、安全性保障、服务调用优化、以及对外统一交互窗口的角色,使得整个微服务体系更稳定、安全和易管理。
10 springcloud里bus的底层通信是用的什么?
Spring Cloud Bus 的底层通信机制支持多种消息中间件实现,最常用的有 RabbitMQ 和 Apache Kafka。
-
RabbitMQ:
- Spring Cloud Bus 默认支持 RabbitMQ 作为其消息总线的底层传输工具。RabbitMQ 是一个开源的消息代理(message broker)系统,基于AMQP(Advanced Message Queuing Protocol)协议,能够可靠地在分布式应用之间发送消息。
-
Apache Kafka:
- Spring Cloud Bus 同样支持 Apache Kafka 作为消息中间件。Kafka 是一个高吞吐量、低延迟的分布式流处理平台,它同时提供了发布订阅和队列两种模型,适用于大规模实时数据处理的应用场景。
在使用 Spring Cloud Bus 进行配置刷新或事件广播时,具体选择哪种消息中间件取决于项目的实际需求和技术栈偏好。通过集成相应的客户端库,Spring Cloud Bus 能够利用这些中间件来实现集群中节点间的通信与协调工作。
1.Redis你们用的是单机还是集群?集群如何搭建?
在实际应用中,Redis的使用可以根据业务需求选择单机部署或者集群部署。如果要搭建Redis集群,以下是一个简化的步骤描述:
Redis系列
1 Redis你们用的是单机还是集群?集群如何搭建?
1. Redis集群搭建步骤(基于Redis 3.0及以上版本):
-
准备环境:
- 确保至少有6台服务器或虚拟机(为了保证高可用和数据分布,通常推荐奇数个节点如3、5、7等)。
- 在每台机器上安装 Redis 并配置好对应的 redis.conf 文件。
-
配置文件调整:
- 修改每个redis.conf中的
cluster-enabled yes以启用集群模式。 - 设置集群配置端口
cluster-config-file nodes.conf,用于存储集群状态信息。 - 如果需要持久化数据,配置AOF或RDB持久化方式。
- 可能还需要修改其他配置项,比如客户端连接端口、数据目录、最大内存大小等。
- 修改每个redis.conf中的
-
启动Redis实例:
- 分别在各个节点上执行命令启动Redis服务,并指定配置文件路径,例如: Code
1redis-server /path/to/redis.conf
- 分别在各个节点上执行命令启动Redis服务,并指定配置文件路径,例如: Code
-
创建集群:
- 使用Redis自带的
redis-trib.rb工具(对于Redis 3.x版本)或者redis-cli工具(对于Redis 6.x版本及以上)来创建集群。
对于Redis 3.x:
Shell1redis-trib.rb create --replicas 1 host1:port1 host2:port2 host3:port3 ...对于Redis 6.x及更高版本:
Shell1redis-cli --cluster create host1:port1 host2:port2 host3:port3 ... --cluster-replicas 1其中
--replicas 1表示为每个主节点分配一个从节点,根据实际情况调整。 - 使用Redis自带的
-
验证集群状态:
- 运行
redis-cli并连接到任意一个节点,使用CLUSTER NODES命令查看集群节点状态,确认集群是否成功创建并且所有节点都已加入。
- 运行
通过以上步骤,您可以建立一个基础的Redis集群。注意,在生产环境中,还需考虑网络配置、防火墙设置、安全性、监控报警等问题。此外,不同的Redis版本可能会有不同的集群管理细节,请参考具体版本文档进行操作。
2 Redis是什么?都有哪些使用场景?
Redis是什么?都有哪些使用场景?
Redis 是一个开源的、基于内存且支持持久化的高性能键值对(Key-Value)存储系统,它可以用作数据库、缓存和消息中间件。Redis 支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合等,并提供了丰富的数据操作命令。
Redis的主要特点:
高性能:由于数据主要存储在内存中,Redis 可以提供极高的读写速度。
多种数据结构:除了基本的键值对之外,还支持复杂的数据结构,如集合、有序集合、哈希表等,这使得 Redis 能够适应更多元化的需求场景。
持久化选项:Redis 提供两种持久化方式 - RDB(快照)和 AOF(日志追加),可以将内存中的数据定期保存到磁盘,防止因服务器故障导致数据丢失。
主从复制与集群:Redis 支持主从模式复制以及通过 Redis Cluster 实现的分布式集群部署,提高系统的可用性和扩展性。
Redis的主要使用场景:
缓存服务:由于其高性能,Redis 常被用于减轻后端数据库的压力,将热点数据存储在内存中快速响应客户端请求。
会话存储:可用来存储Web应用的用户会话信息,加快用户登录状态和其他会话相关数据的访问速度。
排行榜系统:利用有序集合(Sorted Set)实现实时统计并排序各类榜单,例如网站热门排行、游戏积分排行榜等。
队列系统:Redis 的发布订阅(Pub/Sub)机制可用于构建消息队列系统,也可以利用列表(List)作为工作队列处理异步任务。
计数器系统:Redis 支持原子性的自增/自减操作,适合于实现高并发环境下的计数器功能,例如统计网页点击量、点赞数等。
社交网络:如粉丝关注关系、共同好友计算等可以通过集合(Set)或有序集合(Sorted Set)高效实现。
地理位置索引:Redis Geo 数据类型可用于存储地理位置信息,并能根据经纬度查询附近的点。
总之,Redis 因为其灵活多样的数据结构和卓越的性能表现,在现代互联网架构中有着广泛的应用,尤其适用于需要低延迟、高吞吐量以及数据实时性的场景。
3 Redis的基本数据类型都有哪些?
Redis的基本数据类型都有哪些?
Redis 提供了多种基本数据类型以满足不同场景的数据存储和操作需求。以下是 Redis 的五种主要数据类型:
String(字符串)
最基础的数据类型,可以存储任何类型的字符串,包括整数值、文本字符串或其他序列化后的数据。
支持的操作命令有 SET、GET、INCR(自增)、DECR(自减)等。
Hash(哈希表)
用于存储键值对集合,一个键对应多个字段-值对(field-value)。
操作命令如 HSET、HGET、HGETALL、HDEL 等。
List(列表)
双向链表结构,可以将元素插入头部或尾部,也可以在列表中指定位置插入/删除元素。
支持的操作命令有 LPUSH(左推入)、RPUSH(右推入)、LPOP(左弹出)、RPOP(右弹出)、LRANGE(获取范围内的元素)等。
Set(集合)
不重复的字符串集合,不保证内部元素有序。
支持的操作命令有 SADD(添加元素)、SREM(移除元素)、SMEMBERS(获取所有元素)、SCARD(获取集合大小)以及交集、并集、差集运算等。
Sorted Set(有序集合)
类似于集合,但每个元素都关联一个分数,根据这个分数进行排序。
支持的操作命令有 ZADD(添加元素并指定分数)、ZREM(移除元素)、ZRANGE(按照排序顺序获取范围内的元素)、ZCARD(获取集合大小)、ZSCORE(获取成员的分数)以及带分数运算的交集、并集、差集等操作。
此外,Redis 还提供了其他高级特性,如 Bitmaps(位图)、HyperLogLogs(基数估算)、Geospatial Indexes(地理位置索引)和 Streams(流)等数据结构。
4.Redis的Hash数据结构在特定条件下会使用ziplist(压缩列表)代替hashtable进行存储?
Redis的Hash数据结构在特定条件下会使用ziplist(压缩列表)代替hashtable进行存储,这些条件包括:
-
元素数量较少:
- 当哈希中包含的字段-值对的数量小于512个时,Redis会选择使用ziplist来存储。
-
元素大小较小:
- 字段名和值都需要满足以下条件:
- 字符串类型的字段名长度小于64字节。
- 字符串类型的值长度小于64字节(对于Redis 3.2及以前版本),或者小于512字节(对于Redis 4.0及以后版本)。
- 字段名和值都需要满足以下条件:
满足以上两个条件时,Redis会优先选择ziplist作为底层数据结构,因为ziplist相比hashtable有更紧凑的内存占用。它通过连续内存存储,并且可以将多个小尺寸的数据编码为一个连续的序列,从而节省内存空间。
当Hash中的元素数量或单个元素大小超过上述限制时,Redis会自动转换为hashtable数据结构,以保证操作效率,如查找、插入、删除等操作的时间复杂度都是O(1)。
5 Redis集群数据不同步有可能是什么原因
Redis集群数据不同步有可能是什么原因
Redis集群数据不同步可能由以下原因造成:
网络问题:
集群节点间的网络连接不稳定或中断,导致主从节点间的数据同步失败。
数据包丢失、延迟或者拥塞也可能导致部分命令未能正确传播到其他节点。
配置错误:
Redis Cluster配置不当,例如节点的cluster-require-full-coverage选项设置为yes时,在部分节点不可达的情况下,整个集群可能会拒绝写操作以防止数据不一致。
节点的appendonly持久化模式未开启或AOF文件损坏,这可能导致在节点重启后数据不同步。
主从切换过程中数据丢失:
在故障转移过程中,如果新的主节点尚未完全接收完旧主节点的所有事务日志,而旧主节点已经下线,则新主节点上的数据可能与原主节点不一致。
复制积压缓冲区不足:
当主从节点之间网络断开时间较长,主节点继续接收写请求,其复制积压缓冲区不足以保存这段时间内的所有写命令。恢复连接后,部分写入的数据无法同步给从节点。
slot迁移中的数据同步:
Redis Cluster使用槽(slot)进行数据分片管理,当槽正在迁移过程中,可能出现短暂的数据不同步现象。
客户端问题:
客户端应用程序错误地将写请求发送到了持有过期数据副本的节点上,而不是正确的主节点。
Redis集群内部问题:
Redis集群中存在Bug或版本兼容性问题,可能导致节点间通信异常,进而影响数据同步。
哨兵模式下的配置和监控问题:
如果使用了哨兵模式,哨兵系统对主从状态判断有误,或者主从切换通知没有及时送达,都可能导致数据同步问题。
解决Redis集群数据不同步的问题通常需要检查网络状况、集群配置、节点健康状况以及客户端行为等多方面因素,并结合Redis的监控信息来定位具体原因并采取相应措施修复
6 请实现用Redis做登录,错误次数为最多五次,时间为60秒 go
在Go语言中,你可以使用go-redis/redis库来实现这个功能。以下是一个简单的示例:
Go
1package main
2
3import (
4 "context"
5 "fmt"
6 "time"
7
8 "github.com/go-redis/redis/v8"
9)
10
11func main() {
12 rdb := redis.NewClient(&redis.Options{
13 Addr: "localhost:6379",
14 Password: "", // no password set
15 DB: 0, // use default DB
16 })
17
18 username := "testuser" // 用户名
19
20 loginAttempts(username, rdb)
21}
22
23func loginAttempts(username string, rdb *redis.Client) {
24 key := fmt.Sprintf("login_attempts:%s", username)
25
26 ctx := context.Background()
27
28 val, err := rdb.Get(ctx, key).Result()
29 attempts, _ := strconv.Atoi(val) // 如果键不存在,则默认尝试次数为0
30
31 if err != nil && err != redis.Nil {
32 fmt.Println("Error getting attempts:", err)
33 return
34 }
35
36 if attempts >= 5 {
37 fmt.Println("登录失败,您已经超过最大尝试次数,请稍后再试。")
38 return
39 }
40
41 // 这里应包含实际的账号密码验证逻辑,此处假设登录成功或失败的判断
42 var loginSuccess bool = false // 假设登录失败
43
44 if !loginSuccess {
45 pipe := rdb.Pipeline()
46 pipe.Incr(ctx, key)
47 pipe.Expire(ctx, key, time.Second*60)
48 _, err := pipe.Exec(ctx)
49 if err != nil {
50 fmt.Println("Error incrementing and setting expire on key:", err)
51 return
52 }
53 fmt.Printf("登录失败,您还有%d次尝试机会。\n", 5-attempts)
54 } else { // 登录成功
55 rdb.Del(ctx, key)
56 fmt.Println("登录成功!")
57 }
58}在这个示例中,我们创建了一个Redis客户端,并为每个用户使用login_attempts:前缀作为键存储登录尝试次数。当登录失败时,尝试次数递增,并设置键的有效期为60秒。如果登录成功或达到最大尝试次数,则删除该计数键。
注意:在实际项目中,需要根据实际情况调整和封装这部分逻辑,确保在并发环境下操作的原子性和安全性。此外,这里的登录验证逻辑仅为示例,实际项目中应替换为真正的账号密码验证方法。
7 Redis的哨兵机制原理是什么?
Redis Sentinel(哨兵)机制是一种在Redis集群中实现高可用性和故障转移的解决方案。其主要原理和功能包括:
-
监控:
- 哨兵是一组运行在特殊模式下的Redis服务器进程,它们持续不断地监控主从服务器集群中的各个节点。
- 每个哨兵定期向被监控的主服务器、从服务器以及其他哨兵发送心跳命令以检测它们是否在线以及角色是否正常。
-
自动故障发现与通知:
- 当哨兵检测到主服务器下线或者出现故障时,会通过投票机制达成一致意见,确定主服务器确实处于不可用状态。
- 在确认主服务器故障后,哨兵系统会将此信息通知给其他哨兵节点和客户端。
-
自动故障转移:
- 一旦主服务器被标记为下线,哨兵系统会根据配置选举出一个从服务器作为新的主服务器(领导者哨兵负责执行这一操作)。
- 新主服务器会被提升为主,并且其他的从服务器也会被重新配置为复制新的主服务器。
- 整个过程是自动完成的,无需人工干预。
-
配置更新与通知:
- 哨兵在完成故障转移后,会将新的主服务器地址写入到自身的配置中,并将其传播给其他哨兵和连接到集群的客户端应用程序。
- 客户端可以通过订阅+哨兵通知的方式获取最新的主服务器地址信息,从而实现无缝切换至新的主服务器进行读写操作。
-
健康检查与主观/客观下线判定:
- 哨兵对每个Redis实例有主观下线和客观下线两种状态判断:主观下线是指单个哨兵无法从某个服务器上获得响应;客观下线则是多个哨兵经过协商一致认为该服务器不可达。
总的来说,Redis Sentinel通过分布式系统设计实现了对Redis集群的服务状态监控、故障发现、自动故障转移和配置更新等功能,从而确保了即使主服务器发生故障也能保持服务的连续性与数据一致性。
8 Redis 支持的机制类型
Redis 支持的机制类型主要包括以下几个方面:
-
数据持久化机制:
- RDB (Redis Database):快照持久化,定期将内存中的数据以二进制的形式保存到磁盘中。可以通过配置自动执行,如
save命令设置条件触发。 - AOF (Append Only File):追加式日志持久化,每次写操作都会被追加到单独的日志文件中,并且可以设置不同的日志同步策略。在重启时,Redis 会重新执行AOF文件中的所有命令来恢复数据。
- RDB (Redis Database):快照持久化,定期将内存中的数据以二进制的形式保存到磁盘中。可以通过配置自动执行,如
-
主从复制(Replication):
- Redis支持单向或双向的主从复制模式,一个Master节点可以有多个Slave节点。Slave节点通过连接Master并接收其发送的数据更新进行数据同步,从而实现高可用性和读写分离。
-
哨兵(Sentinel)系统:
- Redis Sentinel提供监控和故障转移功能,用于管理一组Redis服务器实例(包括主从结构)。当主服务器出现故障时,Sentinel集群能够自动地进行主服务器切换,并通知客户端新的主服务器地址。
-
集群(Cluster):
- Redis Cluster实现了分布式存储,将数据分片分布在多个Redis节点上,每个节点独立处理一部分数据。客户端通过哈希槽(slot)映射规则访问正确的节点进行读写操作,实现了水平扩展能力。
-
发布/订阅(Pub/Sub):
- Redis支持发布/订阅模型,允许客户端订阅频道或者模式,然后发布者可以向指定的频道发送消息,所有订阅了该频道的客户端都会收到消息。
-
事务(Transactions):
- Redis提供了简单的多命令事务执行机制,通过
MULTI、EXEC等命令包裹一系列原子性的操作。
- Redis提供了简单的多命令事务执行机制,通过
-
Lua脚本支持:
- Redis支持在服务端运行Lua脚本,可以在服务器端执行一系列命令序列,保证这些命令的原子性执行。
-
缓存淘汰策略:
- Redis提供了多种缓存淘汰策略,例如LRU(Least Recently Used)、LFU(Least Frequently Used)以及设置最大内存限制后的键驱逐策略。
-
其他特性:
- Lua脚本调用及Keyspace事件通知机制
- 高级数据结构:除了基本的key-value之外,还支持字符串、哈希表、列表、集合、有序集合等多种数据结构
9 LRU与LFU的区别
LRU(Least Recently Used,最近最少使用)和LFU(Least Frequently Used,最不经常使用)是两种常见的内存管理与缓存淘汰策略,它们的主要区别在于决定哪些数据应该被淘汰的依据不同:
LRU(最近最少使用):
- LRU算法基于时间局部性原理,它假设最近被访问过的数据在未来更有可能被再次访问。
- 在一个有限大小的缓存空间中,当新的数据需要加入而缓存已满时,LRU会优先移除最近最少被访问的数据。
- 每次数据被访问时,都会将其移动到缓存列表的头部或更新其访问时间戳,这样在列表尾部的就是最近最少使用的数据。
LFU(最不经常使用):
- LFU算法则是基于频率局部性原理,它认为过去被访问次数最少的数据在未来被访问的可能性也最小。
- LFU通常维护一个计数器来记录每个数据项的访问频次。当缓存满且有新的数据要加入时,LFU会移除访问频次最低的数据。
- 访问某个数据时,不仅会返回该数据,还会增加其访问频次。随着时间推移,如果某数据不再频繁访问,它的访问频次将逐渐减少,最终可能成为淘汰对象。
总结来说,LRU关注的是“最近”被访问的历史信息,而LFU更注重整个历史期间内数据的访问“频率”。在实际应用中,例如数据库缓存、操作系统内存管理和网页缓存等场景下,可以根据业务需求选择合适的淘汰策略。
10 Redis的持久化方法有哪些
Redis提供了两种主要的持久化方法,以确保数据在服务器重启或故障后能够恢复:
-
RDB (Redis Database) 持久化:
- RDB是Redis默认的持久化方式之一。它通过在指定的时间间隔内将当前内存中的数据生成快照(snapshot)保存到磁盘上。这些快照文件通常称为
.rdb文件。 - 你可以配置Redis自动触发RDB持久化的条件,例如当满足特定时间内有N次写入操作、或者自上次持久化以来过了M秒时自动执行。
- RDB是Redis默认的持久化方式之一。它通过在指定的时间间隔内将当前内存中的数据生成快照(snapshot)保存到磁盘上。这些快照文件通常称为
-
AOF (Append Only File) 持久化:
- AOF持久化记录每一次对数据库进行修改的命令操作,并将它们追加到一个日志文件中。
- 你可以选择不同的AOF重写策略来控制日志文件的增长速度和恢复效率,例如每秒钟fsync一次、每次写入后立即fsync等。
- Redis还支持AOF重写功能,即定期对AOF日志进行压缩,合并无效命令,减小日志文件大小。
用户可以根据业务需求选择使用其中的一种持久化方式,也可以同时开启两种持久化机制,以获得更高的数据安全性,但同时也会牺牲一定的性能。在实际应用中,通常需要根据系统对数据丢失的容忍度、存储空间和读写性能要求等因素综合考虑选择合适的持久化方案。
11 Redis的缓存穿透是什么?怎么解决?
Redis的缓存穿透是指查询请求到达缓存系统(如Redis),但缓存中并没有该数据,并且在后端数据库中也不存在该数据的情况。正常情况下,当从缓存中未找到数据时,系统会去后端数据库查询,然后将查询结果写入缓存以供后续请求使用。然而,对于缓存穿透场景,由于数据库中也找不到对应的数据,因此不会有任何数据被写入缓存,下次同样的请求来时,依然需要再次穿透到数据库,这就导致了缓存失去了应有的作用,同时大量这样的请求可能会对数据库造成不必要的压力。
解决Redis缓存穿透问题通常有以下几种方法:
-
缓存空对象:
- 当数据库查询结果为空时,仍然将一个特殊的值(例如“null”或一个标记)作为缓存结果存储起来,设置一个较短的有效期。这样下一次相同的查询请求过来时,可以从缓存中获取结果,避免直接穿透到数据库。
-
布隆过滤器(Bloom Filter):
- 使用布隆过滤器可以在一定程度上预判一个查询请求是否可能命中数据库。布隆过滤器是一种空间效率极高的概率型数据结构,它可以用来测试一个元素是否在一个集合中。即使数据库中没有某项数据,在布隆过滤器中也可以预先记录所有可能存在的key,如果布隆过滤器表示某个key很可能不存在,则可以直接返回,从而防止了对数据库的无效查询。
-
预加载或主动更新缓存:
- 对于已知的一系列合法的查询范围,可以提前将这些可能的查询key和对应的空值放入缓存。
- 或者在数据变更时,如果涉及到某些不存在的数据ID列表,可以主动将这些ID添加到缓存中并设置为特殊值。
-
权限与访问控制:
- 在应用层面对用户的请求进行校验,拒绝非法或者恶意的请求,减少因大量无效查询导致的缓存穿透。
综合来说,选用哪种方案取决于具体的应用场景和业务需求,常见的实践是结合使用缓存空对象和布隆过滤器来达到良好的效果。
12 Redis怎么实现分布式锁?
Redis实现分布式锁通常基于其命令的原子性来保证互斥性和避免死锁,以下是基本步骤和原理:
使用SETNX命令获取锁:
SETNX key value(Set if Not eXists)如果键key不存在,则设置key为value,并返回1表示设置成功。这个操作是原子性的,因此在多客户端环境下,只有一个客户端能成功设置。
通常,key可以是代表锁资源标识符的字符串,而value则是一个过期时间戳或者一个随机生成的UUID等信息,用于在后续释放锁时验证锁的有效性。
设置锁的超时时间:
单纯依赖SETNX可能会导致锁在客户端崩溃后无法释放,形成死锁。为了解决这个问题,在获取到锁之后,可以通过EXPIRE命令给锁设置一个合理的过期时间,如EXPIRE key timeout,这样即使客户端未正常释放锁,锁也会在过期时间到达后自动删除。
检查锁是否仍由当前客户端持有:
在某些更复杂的实现中,为了防止锁过期后被其他客户端获取,一种改进的方法是在获取锁后再进行一次检查,即通过GET命令获取锁的值并确保与设置时的value一致,如果不一致说明锁已被其他客户端抢占,这时可以执行重试逻辑或直接失败。
释放锁:
当客户端完成临界区操作后,需要释放锁。传统的做法可能并不足够安全,因为直接DEL key会忽略锁的所有权问题。一个更加安全的方式是使用Lua脚本来同时检查和删除锁,例如,脚本可以检查key的value是否与预期值匹配,若匹配则删除key,从而确保只有真正的锁持有者才能释放锁。
可重入锁支持:
如果需要支持可重入特性,可以在获取锁时记录当前持有锁的客户端ID,再次请求时检查是否已持有时增加锁计数,释放锁时根据计数减少直至归零时才真正释放。
综上所述,一个简单的Redis分布式锁的基本实现流程包括:尝试使用SETNX获取锁,设置锁的过期时间,并在操作完成后正确地释放锁。高级的实现还会引入lua脚本、Redlock算法等技术手段来增强锁的安全性和可靠性。