本文字数:6240;估计阅读时间:16 分钟
作者:ClickHouse Team
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发
介绍
作为一家以开源为根基的公司,我们发现用户通常是第一个识别并运用新的架构模式或应用的人。虽然我们可能是ClickHouse的专家,但要尝试所有可能的集成技术,或对所有用例代表性的数据集都进行实验,几乎是不可能的。因此,每当我们进行客户访谈时,我们总是很兴奋地听到新兴的部署模式,尤其是与其他流行的开源项目一起使用的模式。在与我们的客户Goldsky交流,并听到这样一种模式后,我们决定分享他们对Redpanda、Apache Flink和ClickHouse的部署架构。我们认为这对于那些需要将数据集的转换子集传递给多个最终客户的用户,可能具有广泛应用价值。
为了突显这种架构的能力,Goldsky慷慨地分享了来自广泛使用的区块链的数据,该数据基于一个公开可访问的ClickHouse实例。这使得有兴趣使用此免费且持续更新的数据源创建基于区块链数据的功能、产品或平台的用户,可以轻松地使用Goldsky平台进行概念验证。通过消除有关摄取管道、基础架构设置或通过BigQuery直接使用此数据时管理成本的担忧,我们希望此概念验证能够作为使用ClickHouse和Goldsky进行区块链分析时实现效率的宝贵示例。
Goldsky
Goldsky提供加密数据服务,将来自超过15个最受欢迎的区块链的数据交付给客户的数据存储。这包括区块链索引、子图和数据流水线。通过提供开发人员创建简单API的能力,这些数据可以在强大的dApps(去中心化应用程序)中公开,而无需关注所需基础设施、数据管理和提取有用信息的逻辑的复杂性。通常,前者涉及远程过程调用(RPC)提供程序和复杂且难以建模的API。
通过提供“数据管道即服务-data-pipelines-as-a-service”,Goldsky允许开发人员使用客户特定的逻辑对区块链数据进行过滤和转换,以便只将区块链的特定子集传递到智能API端点。虽然用户通常在Goldsky提供的数据上公开API端点,但如果需要更复杂的查询,则ClickHouse越来越被视为首选的分析数据库。在这种情况下,Goldsky需要将区块链数据交付到专用的ClickHouse(通常是Cloud)集群。该数据集通常是特定区块链的子集,例如与特定地址相关的所有区块或钱包的余额。除了过滤或仅从特定时间点开始流,用户还需要在插入到ClickHouse之前对数据进行预聚合的能力。
虽然这些处理能力都内置在Goldsky服务中,但从数据工程的角度来看,这提出了一个挑战 - 如何有效地将相同的TB数据流式传输到可能有数万个ClickHouse实例,同时提供面向客户的处理,可能仅针对子集。
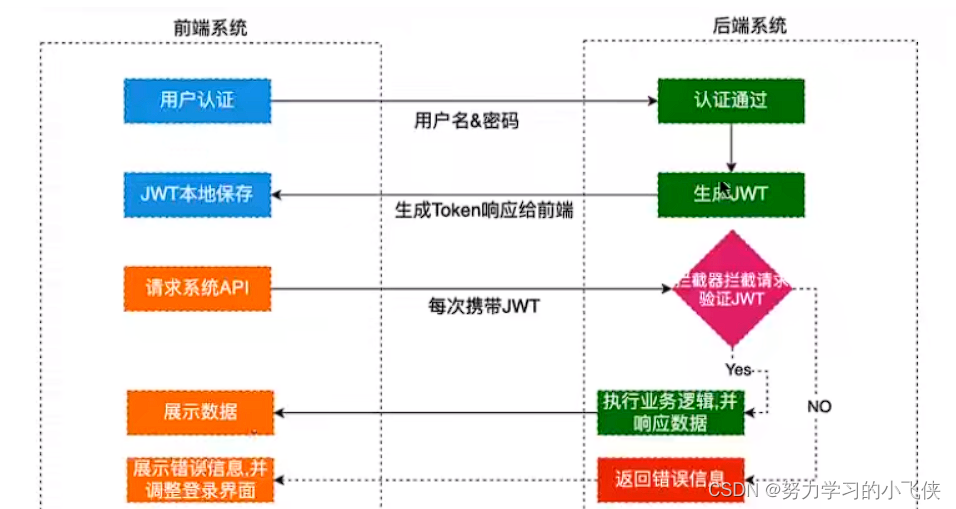
架构
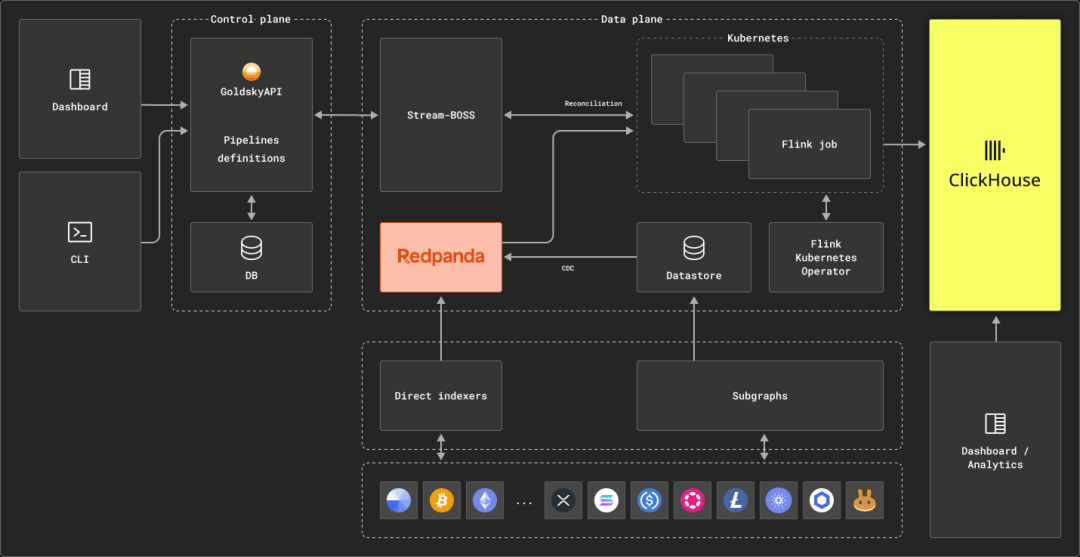
Goldsky架构包括Redpanda、Apache Flink和ClickHouse。数据通过直接索引器推送到Redpanda,这些索引器可以提取结构,例如块、交易、跟踪和日志。每个区块链在Redpanda上存在为多个主题(每个数据类型一个主题),Apache Flink可以从中消费和转换事件。用户编写FlinkSQL来转换特定的数据集,可能从主题上的特定位置开始,以限制数据的时间。在将数据交付给ClickHouse进行分析之前,会在流中应用转换。这种多租户架构允许Goldsky有效地处理和交付任何加密数据集,以潜在地传递到数千个ClickHouse集群。所有这些都通过一个简单的接口或API暴露出来,抽象出复杂性,使用户可以在SQL中自然地编写转换。
读者可能会注意到上面的子图模块。子图是一种单线程的索引方法,允许用户编写使用typescript顺序处理区块链的webassembly逻辑。这允许通过读取和写入状态进行自定义聚合,这可能是一个更容易开始的范例。这还允许在索引过程中进行对以太坊网络的其他HTTP调用,以拉取合同状态。这些子图反过来可以用于公开API或插入到ClickHouse进行分析。更多详细信息请查看此处。
我们将在下面详细探讨每种技术选择。
Redpanda作为后备存储
Goldsky在确保所有流行的区块链都转换为其他服务(如ClickHouse)可以实际轻松消费的格式上付出了很大的努力。基于模式的Avro格式代表了他们当前首选的格式。一旦区块链被转换,就会有几个主要挑战:
1. 高效存储转换后的数据,以便客户以后能够轻松访问。在这里,保留期是无限的。
2. 保持数据的最更新性,以便用户可以访问最新的交易和区块。
3. 确保数据可以以最小的端到端延迟传递到任意数量的目的地,包括ClickHouse。
由于所有区块链数据本质上是时间序列的、有序的和不可变的,并且有了使用Kafka的先前经验,Goldsky团队确定Redpanda是首选的Kafka实现。这个选择背后的主要动机是它的分层存储架构。这使得数据可以在对象存储上以经济高效的方式保留,同时仍然以每秒GiB字节的速度传递到下游目的地,而不是在传统的Kafka共享无存储体系结构中支付不必要的硬件成本。当结合高耐久性,通过最近的Jepsen测试验证时,此功能特别符合Goldsky典型的访问模式,即最近的区块是主要关注的,数据需要按顺序流式传输。
有关Goldsky选择Redpanda的更多详细信息,我们建议阅读博客文章"How Goldsky democratizes streaming data for Web3 developers with Redpanda"。(https://redpanda.com/blog/democratize-streaming-data-web3-goldsky-redpanda)
用于处理的Apache Flink
为了满足用户对能够过滤和转换数据的要求,Goldsky利用了Apache Flink® - 向用户公开FlinkSQL。虽然后续的转换很简单,例如将数据过滤到特定的合同,但Flink提供了更复杂的流处理功能,例如流内连接、TopN计数,甚至如果需要的话,模式识别。这些功能在保持对ClickHouse高插入性能的同时提供,速率可达每秒500,000事件。
有关Goldsky选择Flink的更多详细信息,我们建议阅读博客文章“Using Changelogs and Streams to Solve Blockchain Data Challenges”(https://goldsky.com/blog/changelogs-streams-blockchain-data),特别是关于如何高效处理区块链重组的方面。
用于分析的ClickHouse
虽然ClickHouse不是用户要求事件传递的唯一数据库,但一旦需要对大型数据集执行查询分析,它就成为首选选择。ClickHouse在加密分析领域的应用是众所周知的,用户利用其无与伦比的查询性能、成本效益和对大型数据集的增强SQL。使用SQL查询区块链数据是直观的,并且得到了诸如dune等服务的推广。
用于回填的ClickHouse
最近,Goldsky开始探索使用ClickHouse进行数据回填。这通常是客户需要完整或经过筛选的数据集的要求。在这些情况下,可以使用ClickHouse有效地识别子集并重定向到Goldsky管道。Redpanda可用于后续更新。这是使用自定义混合源实现的,该源能够从两个源(ClickHouse用于回填,Redpanda用于增量)中消耗数据。在不需要用户知道数据来自何处的情况下,流水线中定义的任何聚合都可以在ClickHouse和Redpanda之间起作用。
挑战和教训
Goldsky在使用ReplacingMergeTree引擎类型时与ClickHouse的主要挑战涉及学习如何最优地使用它。此引擎选择确保可以有效处理更新(或重复事件)。出于优化目的,Goldsky特别利用了:
1. 模拟ReplacingMergeTree的PREWHERE条件的能力(https://clickhouse.com/blog/clickhouse-postgresql-change-data-capture-cdc-part-1#final-performance)
2. 使用分区进行高效查询(https://clickhouse.com/blog/clickhouse-postgresql-change-data-capture-cdc-part-1#exploiting-partitions)
3. 最近版本的允许控制用于FINAL操作符的线程数(https://clickhouse.com/docs/en/operations/settings/settings#max-final-threads)
此外,Goldsky提供了让用户自定义ORDER BY键的能力,以使其与其访问模式保持一致。这通常是块时间戳或地址。在将来,他们希望利用支持ReplacingMergeTree引擎的投影的功能。
一个示例数据集
在ClickHouse,我们始终在寻找大型数据集用于公共实例中展示。为了测试Goldsky服务,我们对Goldsky提供将一个区块链发送到我们的公共实例的提议感到兴奋。在寻找一个被广泛采用且具有大量交易的链时,我们选择了Base。
Base区块链是基于Ethereum L2的分散账本。它采用了一种称为“Proof of Participation”的独特共识机制,结合了股权证明和工作证明的元素,从而实现了高效的交易处理和共识,同时保持了强大的安全性。这个区块链包含了智能合约和去中心化应用程序(DApps)等功能,以支持各种用例,使其成为基于区块链的应用程序和服务的多功能平台。由Coinbase推广,截至撰写本文时,该链的交易数量已接近7200万。
用户可以在sql.clickhouse.com上实时访问这个数据集。我们提供的表涵盖了块、日志、交易和跟踪,行数从不到1000万行和几GB到超过10亿行和近1TB的非压缩数据。
SELECT
table,
formatReadableQuantity(sum(rows)) AS total_rows,
round(sum(rows) / 42) AS events_per_day,
formatReadableSize(sum(data_compressed_bytes)) AS compressed_size,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size,
round(sum(data_uncompressed_bytes) / sum(data_compressed_bytes), 2) AS ratio
FROM system.parts
WHERE (database = 'base') AND active
GROUP BY table
ORDER BY sum(rows) ASC
┌─table───────────────┬─total_rows─────┬─events_per_day─┬─compressed_size─┬─uncompressed_size─┬─ratio─┐
│ base_blocks │ 7.46 million │ 177546 │ 2.11 GiB │ 7.60 GiB │ 3.61 │
│ base_transactions │ 72.89 million │ 1735559 │ 7.02 GiB │ 56.19 GiB │ 8 │
│ base_decoded_logs │ 405.76 million │ 9660852 │ 22.03 GiB │ 336.46 GiB │ 15.27 │
│ base_raw_logs │ 408.87 million │ 9734901 │ 13.53 GiB │ 216.64 GiB │ 16.01 │
│ base_decoded_traces │ 1.14 billion │ 27151103 │ 51.70 GiB │ 1.04 TiB │ 20.64 │
│ base_raw_traces │ 1.25 billion │ 29687205 │ 38.38 GiB │ 816.71 GiB │ 21.28 │
└─────────────────────┴────────────────┴────────────────┴─────────────────┴───────────────────┴───────┘
6 rows in set. Elapsed: 0.008 sec.用户可以在集群上执行实时响应的分析查询。例如,可以统计自6月以来每天的交易数量。
SELECT
toStartOfDay(block_timestamp) AS day,
COUNT(*) AS txns,
ROUND(AVG(txns) OVER (ORDER BY day ASC ROWS BETWEEN 6 PRECEDING AND CURRENT ROW)) AS `7d avg`
FROM base_transactions
WHERE day > '2023-07-12'
GROUP BY 1
ORDER BY 1 DESC
┌─────────────────day─┬────txns─┬──7d avg─┐
│ 2023-12-04 00:00:00 │ 165727 │ 252691 │
│ 2023-12-03 00:00:00 │ 283293 │ 270246 │
│ 2023-12-02 00:00:00 │ 302197 │ 275016 │
│ 2023-12-01 00:00:00 │ 236117 │ 277115 │
│ 2023-11-30 00:00:00 │ 263169 │ 286202 │
│ 2023-11-29 00:00:00 │ 265525 │ 290758 │
...
│ 2023-07-17 00:00:00 │ 59162 │ 62133 │
│ 2023-07-16 00:00:00 │ 67629 │ 62876 │
│ 2023-07-15 00:00:00 │ 77912 │ 61291 │
│ 2023-07-14 00:00:00 │ 61859 │ 52981 │
│ 2023-07-13 00:00:00 │ 44103 │ 44103 │
└─────────────────────┴─────────┴─────────┘
145 rows in set. Elapsed: 0.070 sec. Processed 72.90 million rows, 291.58 MB (1.04 billion rows/s., 4.15 GB/s.)
我们建议用户在这里探索Dune仪表板(https://dune.com/watermeloncrypto/base),以获取查询灵感。虽然Dune不能提供实时查询能力(以上查询为0.070秒),但其查询可以轻松转换为ClickHouse语法,并在上述服务上执行。
结论
在本文中,我们介绍了Goldsky的架构,探讨了他们为什么选择在ClickHouse的多租户部署中使用Redpanda、Apache Flink和ClickHouse。虽然流处理的概念自然地与区块链数据和诸如Top-N、撤回和有时间限制的连接等问题相吻合,但ClickHouse可以通过在子集或整个区块链上提供实时查询能力来进一步增强这种架构。这些技术之间相互补充,并允许Goldsky提供一流的区块链分析服务。作为对该服务的证明,并为了使我们的社区受益,我们利用Goldsky免费为Base区块链提供分析。请关注我们努力为其他区块链提供免费服务的进展!

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求