一、说明
本文简要而简明地介绍了 Python 编程语言中的多处理(多进程)。解释多处理的基本信息,如什么是多处理?为什么用多处理?在python中怎么办等。
二、什么是多处理?
多处理是指系统同时支持多个处理器的能力。多处理系统中的应用程序被分解为独立运行的较小例程。操作系统将这些线程分配给处理器,从而提高系统的性能。
三、为什么选择多处理?
考虑具有单个处理器的计算机系统。如果同时为它分配了多个进程,它将不得不中断每个任务并短暂切换到另一个任务,以保持所有进程的运行。
这种情况就像一个厨师独自在厨房工作一样。他必须做几项任务,如烘烤、搅拌、揉面团等。
因此,要点是:您必须同时完成的任务越多,跟踪所有任务就越困难,并且保持正确的时间安排变得更加具有挑战性。
这就是多处理概念的由来!
多处理系统可以具有:
- 多处理器,即具有多个中央处理器的计算机。
- 多核处理器,即具有两个或多个独立实际处理单元(称为“内核”)的单个计算组件。
在这里,CPU 可以轻松地一次执行多个任务,每个任务都使用自己的处理器。
这就像最后一种情况下的厨师得到助手的帮助一样。现在,他们可以在他们之间分配任务,厨师不需要在他的任务之间切换。
四、Python 中的多处理
在 Python 中,multiprocessing 模块包含一个非常简单直观的 API,用于在多个进程之间划分工作。
让我们考虑一个使用多处理模块的简单示例:
# importing the multiprocessing module
import multiprocessing
def print_cube(num):
"""
function to print cube of given num
"""
print("Cube: {}".format(num * num * num))
def print_square(num):
"""
function to print square of given num
"""
print("Square: {}".format(num * num))
if __name__ == "__main__":
# creating processes
p1 = multiprocessing.Process(target=print_square, args=(10, ))
p2 = multiprocessing.Process(target=print_cube, args=(10, ))
# starting process 1
p1.start()
# starting process 2
p2.start()
# wait until process 1 is finished
p1.join()
# wait until process 2 is finished
p2.join()
# both processes finished
print("Done!")
|
Square: 100
Cube: 1000
Done!
让我们试着理解上面的代码:
- 要导入多处理模块,我们执行以下操作:
import multiprocessing
- 为了创建一个进程,我们创建了一个 Process 类的对象。它需要以下参数:
- target:进程要执行的功能
- args:要传递给目标函数的参数
注意:进程构造函数还采用许多其他参数,稍后将讨论这些参数。在上面的示例中,我们创建了 2 个具有不同目标函数的进程:
p1 = multiprocessing.Process(target=print_square, args=(10, )) p2 = multiprocessing.Process(target=print_cube, args=(10, ))
- 为了启动一个进程,我们使用 Process 类的 start 方法。
p1.start() p2.start()
- 一旦进程启动,当前程序也会继续执行。为了在进程完成之前停止当前程序的执行,我们使用 join 方法。
p1.join() p2.join()
因此,当前程序将首先等待 p1 的完成,然后是 p2。一旦它们完成,就会执行当前程序的下一个语句。
让我们考虑另一个程序来理解在同一 python 脚本上运行的不同进程的概念。在下面的示例中,我们打印运行目标函数的进程的 ID:
# importing the multiprocessing module
import multiprocessing
import os
def worker1():
# printing process id
print("ID of process running worker1: {}".format(os.getpid()))
def worker2():
# printing process id
print("ID of process running worker2: {}".format(os.getpid()))
if __name__ == "__main__":
# printing main program process id
print("ID of main process: {}".format(os.getpid()))
# creating processes
p1 = multiprocessing.Process(target=worker1)
p2 = multiprocessing.Process(target=worker2)
# starting processes
p1.start()
p2.start()
# process IDs
print("ID of process p1: {}".format(p1.pid))
print("ID of process p2: {}".format(p2.pid))
# wait until processes are finished
p1.join()
p2.join()
# both processes finished
print("Both processes finished execution!")
# check if processes are alive
print("Process p1 is alive: {}".format(p1.is_alive()))
print("Process p2 is alive: {}".format(p2.is_alive()))
|
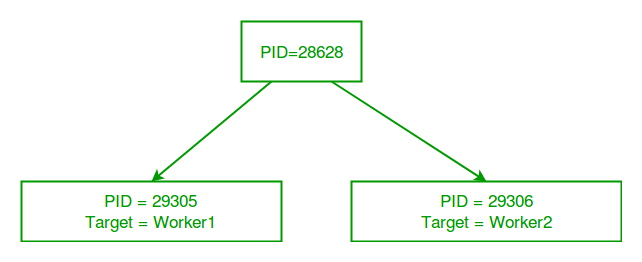
ID of main process: 28628
ID of process running worker1: 29305
ID of process running worker2: 29306
ID of process p1: 29305
ID of process p2: 29306
Both processes finished execution!
Process p1 is alive: False
Process p2 is alive: False
- 主 python 脚本具有不同的进程 ID,当我们创建进程对象 p1 和 p2 时,multiprocessing 模块会生成具有不同进程 ID 的新进程。在上面的程序中,我们使用 os.getpid() 函数来获取运行当前目标函数的进程的 ID。
请注意,它与 p1 和 p2 的进程 ID 匹配,我们使用 Process 类的 pid 属性获取这些 ID。
- 每个进程独立运行,并有自己的内存空间。
- 一旦目标函数的执行完成,进程就会终止。在上面的程序中is_alive我们使用了 Process 类的方法来检查进程是否仍处于活动状态。
请考虑下图,了解新进程与主 Python 脚本有何不同?:
所以,这是对 Python 中多处理的简要介绍。接下来的几篇文章将介绍以下与多处理相关的主题:
- 使用 Array、value 和 queues 在进程之间共享数据。
- 多处理中的锁和池概念