一、算 法 简 史
算法可以追溯到古代埃及人和古希腊人使用的算术方法。在古代埃及,人们使用简单的加减法来解决基本的数学问题,而在古希腊,人们开始使用更加复杂的算术方法,比如平方、立方、平方根和立方根。
随着数学的发展,算法也在不断演进。在中世纪,欧拉和斐波那契发明了许多新的算法,为人类的计算能力提供了更大的支持。在近代,科学家们发明了许多新的计算机算法,比如快速排序、哈希算法和图论算法。
今天,算法仍然在不断发展,并且在各个领域得到了广泛的应用。从基本的数学计算到复杂的机器学习算法,算法已经成为我们生活中不可或缺的一部分。
二、算 法 概 论
算法,这个词对于许多人来说可能有些抽象,但它却是计算机科学领域的基石。从日常生活中的搜索引擎、社交网络、购物推荐,到复杂的人工智能系统,几乎所有计算机应用背后都有着精心设计的算法在支撑。
那么,一个算法是如何发明出来的呢?
首先,我们需要明确的是,算法并不是一蹴而就的,而是在不断的探索、实践、总结、改进中逐渐形成的。算法的发明往往源于解决实际问题的需求,比如我们要快速地生成文本摘要,就可能会想到开发一款文本摘要生成算法。
在解决问题的过程中,我们需要先明确问题的定义,确定目标与输入输出。比如在开发心力算法的过程中,我们需要明确这样几点:
目标:生成精准的文本摘要
输入:原文本、摘要样本
输出:文本摘要
然后我们就可以开始思考如何解决这个问题了。
在解决问题的过程中,我们可能会用到各种不同的方法,比如关键词提取、模式建立、模式匹配等。在这些方法中,我们可能需要用到高数知识,比如线性代数、微积分、概率统计等,来帮助我们更准确地处理数据。
接下来,我们可以尝试用 Python 语言来实现这些方法。Python 是一门易学、易用的编程语言,在科学计算、数据分析、机器学习等领域有广泛应用。我们可以借助 Python 中的各种库,比如 NumPy、SciPy、Pandas 等,来帮助我们实现算法。
最后,我们就可以将所有的方法整合起来,形成我们的算法。但这并不意味着算法的开发就结束了,相反,这只是算法的开端。我们需要不断地测试、优化、改进算法,使其更加完善、高效。
举个例子,我们可以回到心力算法的开发过程中。我们可以使用大量的文本数据,测试心力算法的准确性、效率、可读性等方面。我们可以将算法进行优化,比如使用更高效的算法实现关键词提取、使用更简洁的代码实现模式建立、使用更加灵活的方
法实现模式匹配等。我们还可以加入一些新的功能,使得心力算法更加强大。比如我们可以考虑增加文本分类功能,使心力算法不仅能够生成文本摘要,还能够帮助用户快速地将文本分类。
通过不断的探索、实践、总结、改进,我们就可以逐步完善心力算法,使其成为一款高效、可靠、易用的文本摘要生成算法。
在算法的开发过程中,我们还需要注意一些其他的因素,比如算法的可读性、可维护性、可扩展性等。一个算法如果代码冗长、难以理解、难以维护、难以扩展,就很难被人们接受、使用。因此,我们还需要努力做到代码简洁、易读、易维护、易扩展,使得算法能够得到广泛的应用。
最后,我们可以将我们的算法发布到网上,让更多的人可以使用。这样,我们的算法就可以被广泛应用,为人们带来更多的便利。
总之,算法的开发是一个漫长而复杂的过程,需要我们不断地探索、实践、总结、改进,才能形成一个完善、高效、可靠的算法。在这个过程中,我们需要用到各种不同的知识,比如高数、统计学、机器学习等。同时,我们还需要注意代码的可读性、可维护性、可扩展性,使得算法能够得到广泛的应用。通过不断的努力,我们就可以炼成一颗算法之秀,为人类带来更多的便利!
三、心力算法开发中的数学知识与代码实现
在心力算法中,我们可能会用到如下的数学知识:
线性代数:我们可能需要用到矩阵运算、矩阵分解、特征值分解等方法来帮助我们处理数据。
微积分:我们可能需要用到微积分的知识来帮助我们求解优化问题,比如求解最小二乘法。
概率统计:我们可能需要用到概率分布、随机过程、高斯分布等知识来帮助我们对数据进行建模。
此外,在实现心力算法的过程中,我们还可能用到如下的代码:
NumPy:我们可能会用到 NumPy 库中的各种函数来帮助我们进行数值运算、矩阵运算等。
SciPy:我们可能会用到 SciPy 库中的各种函数来帮助我们求解数值优化问题、求解微积分方程等。
Pandas:我们可能会用到 Pandas 库中的各种函数来帮助我们处理数据、清洗数据、统计数据以及建立数据模型等。
在使用这些库时,我们需要先在代码中导入这些库,然后就可以使用它们提供的各种函数了。比如我们可以使用 NumPy 库中的 linalg.svd 函数来求解矩阵的奇异值分解,使用 SciPy 库中的 optimize.minimize 函数来求解最小二乘法,使用 Pandas 库中的 DataFrame.corr 函数来计算两个变量之间的相关系数等。
通过使用这些数学知识和代码,我们就可以实现心力算法的各种功能,比如关键词提取、模式建立、模式匹配、摘要生成等。这些功能的实现需要我们不断地探索、实践、总结、改进,使得心力算法能够变得更加完善、高效、可靠。
四、心力算法实例
示例一:心里算法中摘要生成的简单实现
我预想中的心力算法中摘要生成的数学公式是这样的:
其中, 是生成的摘要, 是文本中句子的数量, 表示第 个句子的权重, 表示第 个句子的内容。
而在 Python 代码中,我们可能会使用如下的方式来实现摘要生成:
def generate_summary(sentences, weights):
summary = ""
for i in range(len(sentences)):
summary += weights[i] * sentences[i]
return summary在这段代码中,我们首先定义了一个 generate_summary 函数,接受两个参数:sentences 和 weights。然后我们遍历 sentences 列表中的所有句子,按照权重计算生成的摘要。最后,我们返回生成的摘要。
示例二:心里算法中模式匹配的简单实现
心力算法中模式匹配的数学公式可能会是这样的:
其中 表示两个向量 和 的相似度, 是向量的维度, 表示 向量的第 个元素, 表示 向量的第 个元素。
而在 Python 代码中,我们可能会使用如下的方式来实现模式匹配:
def match_pattern(pattern, text):
# 将模式和文本向量化
pattern_vec = vectorize(pattern)
text_vec = vectorize(text)
# 计算模式向量和文本向量的相似度
sim = similarity(pattern_vec, text_vec)
# 返回相似度
return sim
def vectorize(s):
# 对字符串进行分词
words = tokenize(s)
# 统计词频
frequency = {}
for word in words:
if word in frequency:
frequency[word] += 1
else:
frequency[word] = 1
# 将词频转化为向量
vector = []
for word in vocabulary:
if word in frequency:
vector.append(frequency[word])
else:
vector.append(0)
# 返回向量
return vector
def similarity(vec1, vec2):
# 计算内积
dot = sum([x * y for x, y in zip(vec1, vec2)])
# 计算模长
norm1 = math.sqrt(sum([x ** 2 for x in vec1]))
norm2 = math.sqrt(sum([y ** 2 for y in vec2]))
# 计算相似度
sim = dot / (norm1 * norm2)
# 返回相似度
return sim
在这段代码中,我们首先计算出两个向量的内积,然后计算出这两个向量的模长。最后,我们通过将内积除以模长的乘积,就能得到两个向量的相似度了。
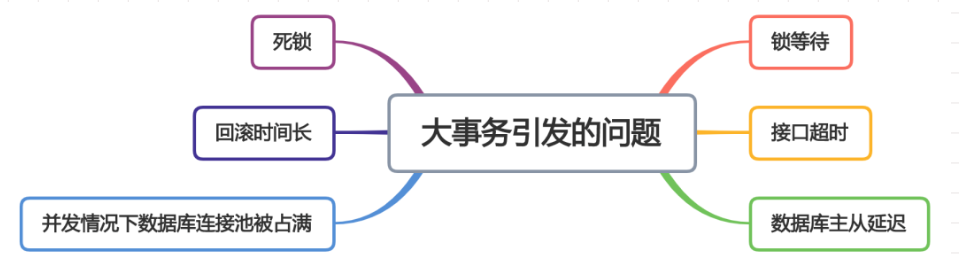
五、心力算法思维导图展示
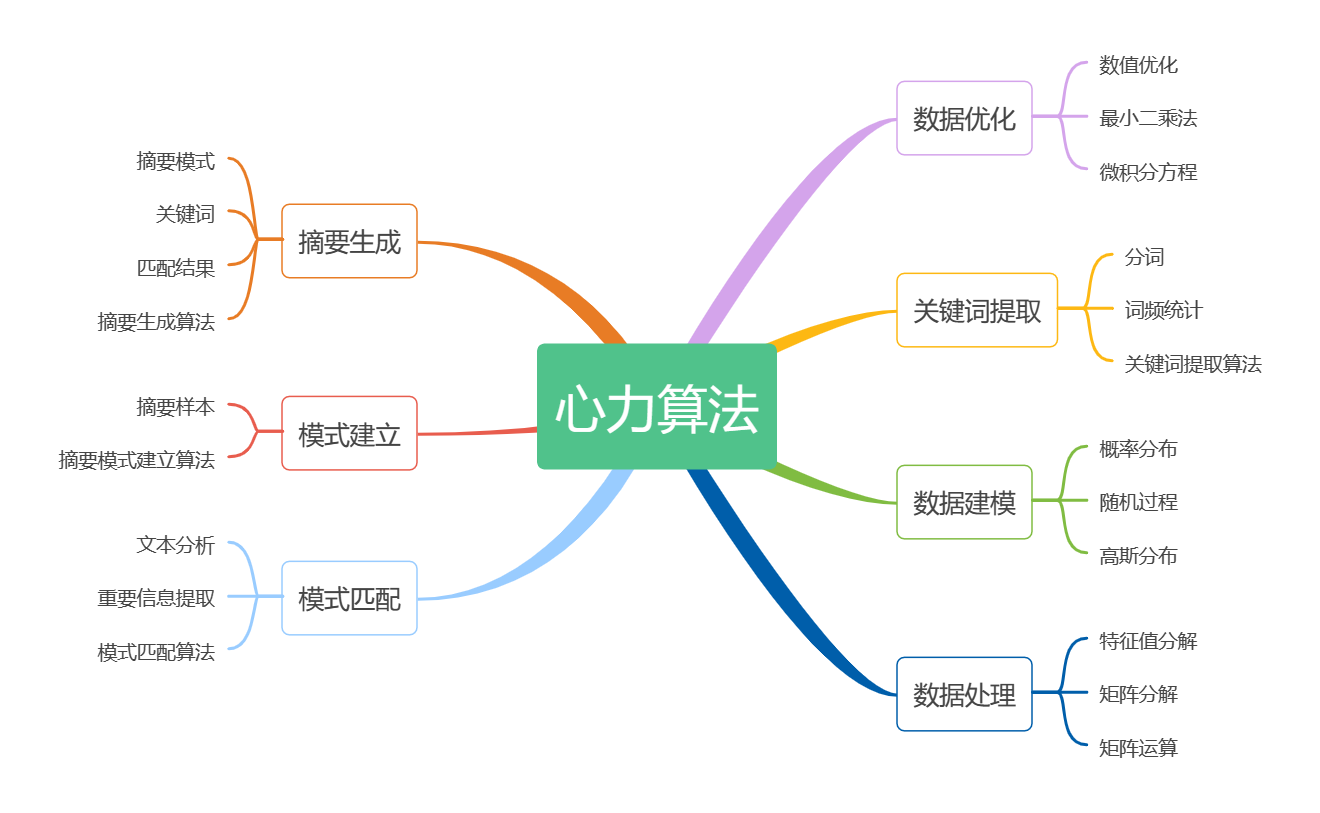
在这个思维导图中,我们可以看到心力算法包含了数据处理、数据建模、数据优化、关键词提取、模式建立、模式匹配、摘要生成等几个步骤。在每一步中,我们都会使用到各种数学知识和代码实现来帮助我们完成算法的开发。
六、总 结
在本文中,我们讨论了算法是如何发明出来的,并且结合了心力算法的发明来说明这一点。
我们还列举了一些在心力算法中的数学知识和代码,并给出了这个算法实现摘要生成和模式匹配时使用的具体的数学公式和 Python 代码。
此外,我们还提到了算法的简史,讨论了算法在古代和近代的发展。