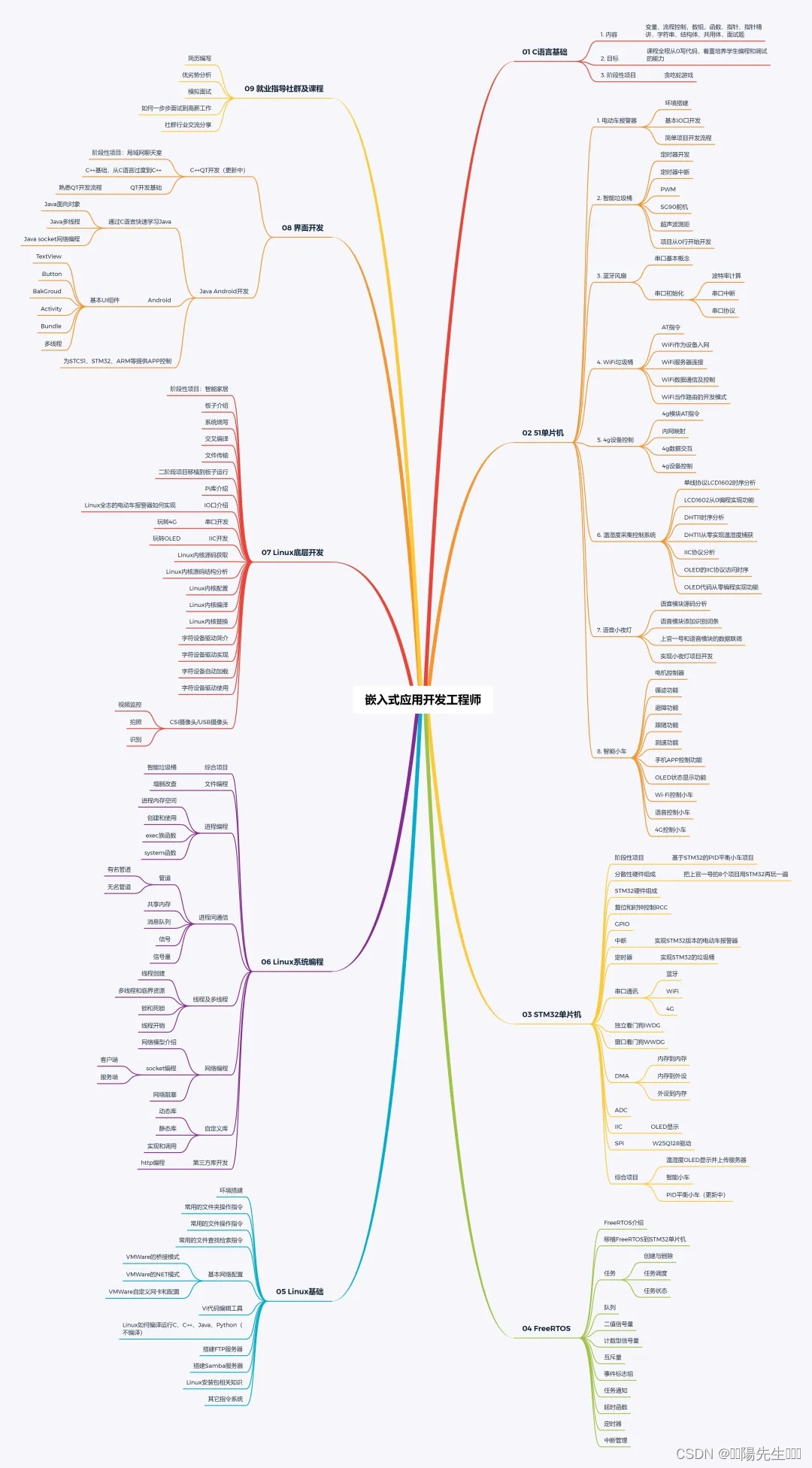
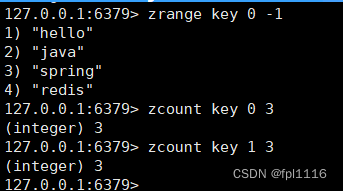
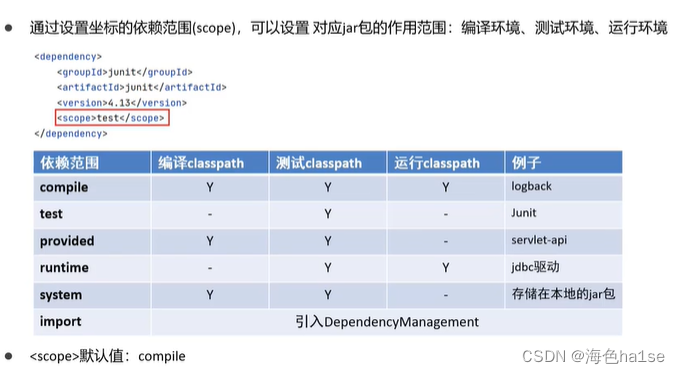
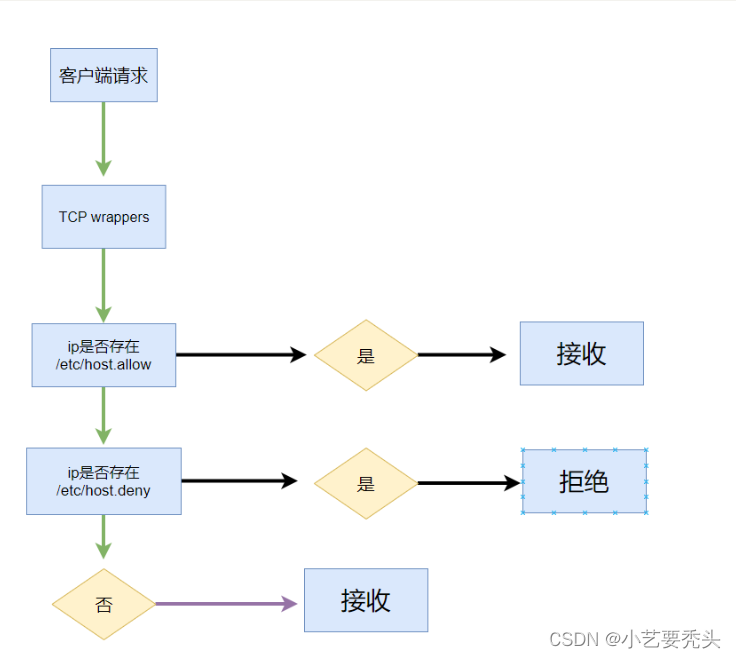
Hive和Hadoop的关系
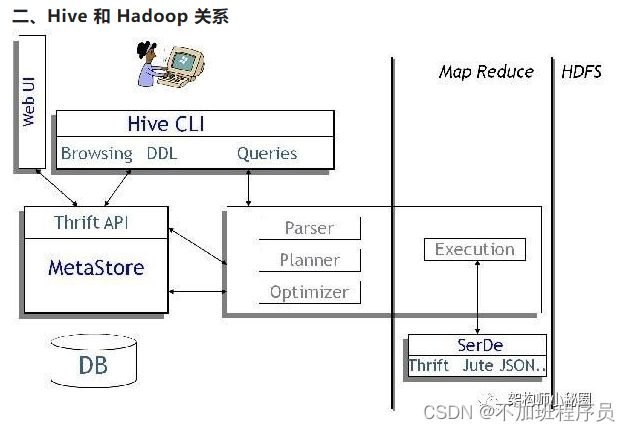
Hive 构建在 Hadoop 之上,
- HQL 中对查询语句的解释、优化、生成查询计划是由 Hive 完成的
- 所有的数据都是存储在 Hadoop 中
- 查询计划被转化为 MapReduce 任务,在 Hadoop 中执行(有些查询没有 MR 任务,如:select * from table)
- Hadoop和Hive都是用UTF-8编码的
hive与关系数据库的区别
- hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
- hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型;
- 关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致hive的应用场景和关系数据库有很大的不同;
- Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比数据库差很多。
Hive的优缺点
优点
1)操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
2)避免了去写MapReduce,减少开发人员的学习成本。
3)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。
4)Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
5)Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
1.Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2.Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
Hive的基本数据类型
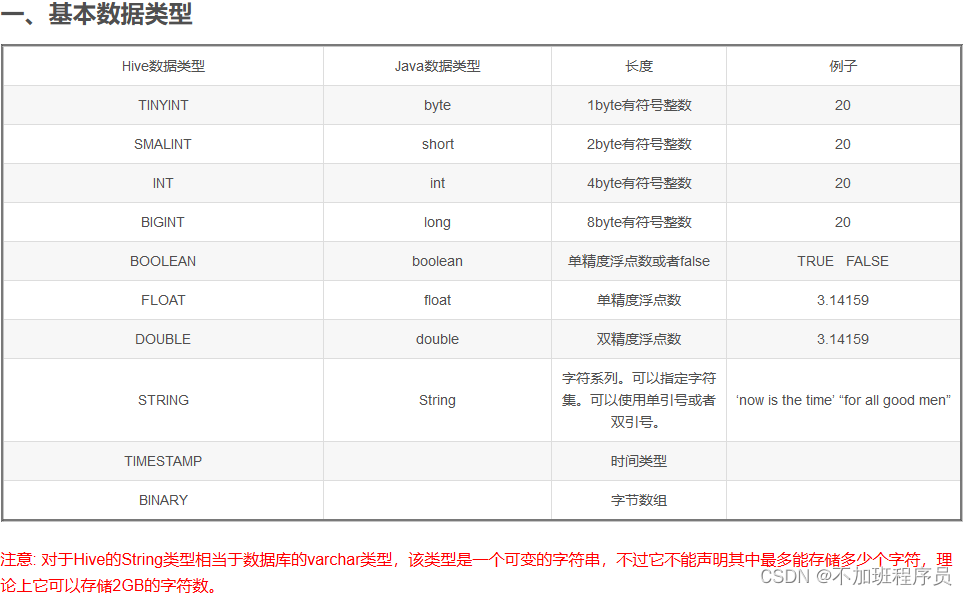
Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。



内部表和外部表的区别
在Hive中,内部表和外部表的区别在于数据的存储位置和管理方式。
内部表是指Hive将数据存储在其默认的HDFS数据目录中,并由Hive来管理这些数据。如果删除一个内部表,Hive会自动删除与该表相关联的所有数据。内部表适用于那些需要完全由Hive管理的数据,如中间结果或临时数据。
而外部表是指Hive仅对HDFS中的数据进行管理,不会对数据进行修改或移动。如果删除一个外部表,数据仍然保留在HDFS上。外部表适用于那些需要与其他系统共享数据或需要长期保存数据的情况,如ETL过程中的源数据。
一般来说,当需要对数据进行修改和删除时,使用内部表;当需要长期保存数据并与其他系统共享时,使用外部表。
-
sort by:sort by是将数据按照指定的列排序输出,但不改变数据的分区,也就是说,sort by只保证每个分区内的数据有序,但不保证分区之间的顺序。sort by可以用于对数据进行全局排序,但是比较耗费资源。
-
order by:order by是将数据按照指定的列排序输出,并且会改变数据的分区。在order by语句后面指定的列将作为排序关键字,优先级从左到右递减。order by可以用于对整个结果集进行排序,但是需要将所有数据进行归约,因此耗费的资源要比sort by更多。
-
distribute by:distribute by用于将数据按照指定的列分区,但不保证每个分区内的数据有序。如果只需要进行分组聚合操作,那么使用distribute by即可,这样能够提高查询效率。
-
cluster by:cluster by是对表进行分桶,每个分桶内的数据按照指定的列排序,并且会根据指定的列生成对应的分区文件。cluster by是一种更加高效的分区方式,因为它可以减少数据的扫描量,提高查询效率。
总之,sort by和order by都是用来对数据进行排序的,区别在于是否改变数据的分区;distribute by用于对数据进行分区,不保证每个分区内的数据有序;而cluster by则是一种更加高效的分区方式,它可以减少数据扫描量,提高查询效率
数据倾斜
在Hive中,数据倾斜是指数据在分布式环境下不均匀地分布在不同的节点上,导致某些节点负载过重而影响整个作业的性能。为了解决这个问题,以下是一些常见的解决方案:
-
使用随机数:对于数据倾斜比较严重的情况,可以在SQL语句中使用随机数函数,将数据随机分配到不同的Reduce任务中。
-
采用多级聚合:在分组聚合时,可以采用多级聚合的方式,即先将数据按照一定的规则划分成多个子集,然后对每个子集进行聚合,最后再将结果合并。
-
使用Map-Side Join:如果数据倾斜出现在Join操作中,可以使用Map-Side Join来避免数据倾斜。Map-Side Join是利用Map任务将两个表的数据按照Join条件连接起来,然后将结果写入HDFS中,这样可以避免Reduce任务中的数据倾斜。
-
增加Reduce数量:对于数据倾斜比较严重的情况,可以增加Reduce任务的数量,将数据划分到更多的节点上处理,从而减轻单个节点的负担。
-
使用Combiner:Combiner是在Map任务本地进行Merge的过程,它可以减少数据传输量,从而减轻Reduce任务的负担。在数据倾斜的情况下,使用Combiner可以将数据合并为更小的部分,从而避免某个Reduce任务的数据过多。
总之,针对不同的场景,可以采用不同的解决方案。需要根据具体情况选择最适合的方法来解决Hive数据倾斜问题。


![[IO复用] IO复用问答](https://img-blog.csdnimg.cn/direct/37a9c2d2ed794442a4cc60adebc879b5.png)