Day 12
01. 二叉树的理论基础
1.1 二叉树的种类
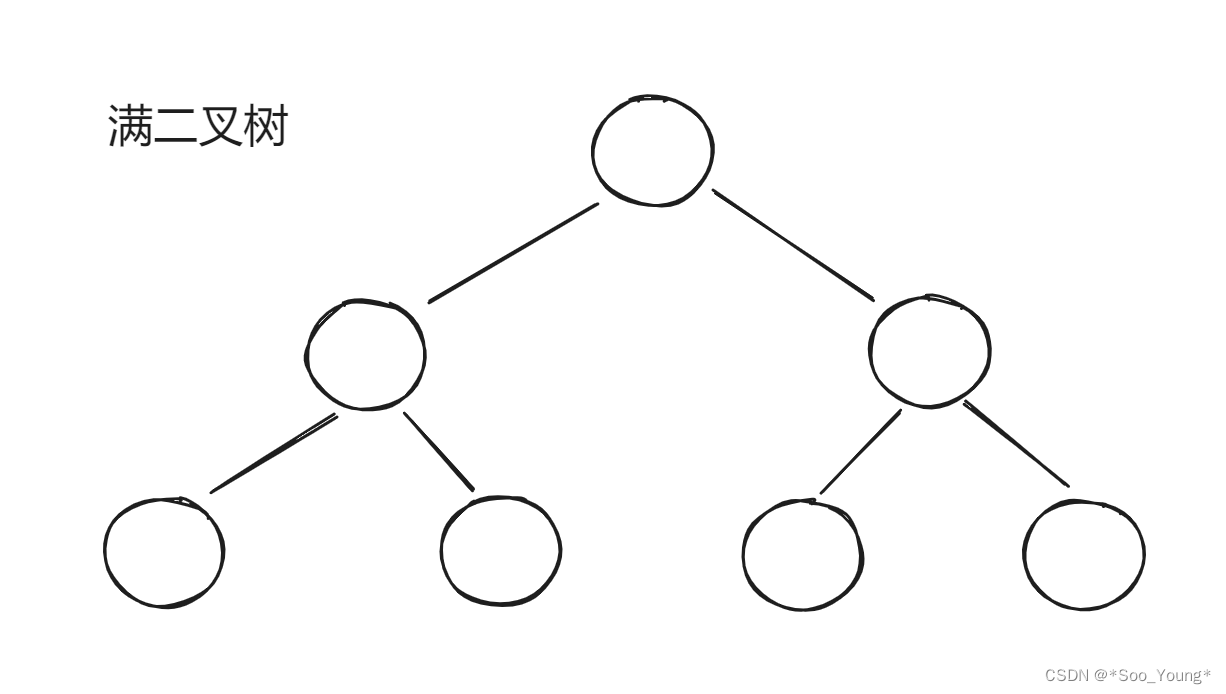
- 满二叉树:除了叶子节点以外,每个节点都有两个子节点,整个树是被完全填满的
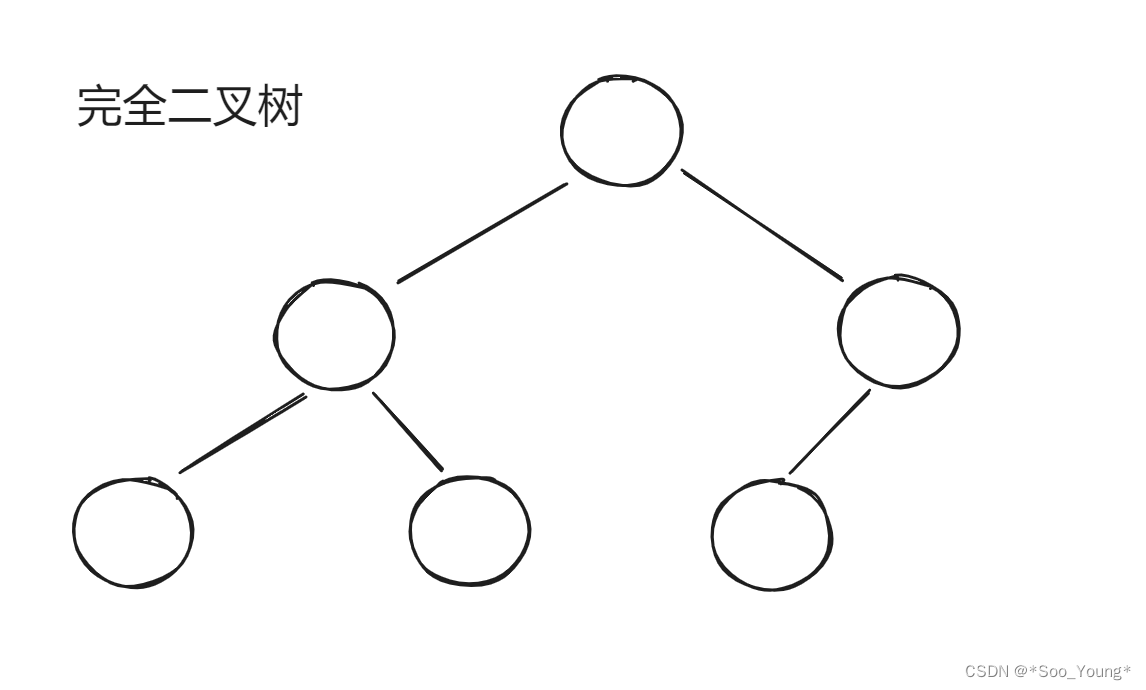
- 完全二叉树:除了底层以外,其他部分是满的,底部可以不是满的但是必须是从左到右连续的

- 二叉搜索树:节点是有顺序的,可查找的
- 平衡二叉搜索树:左子树和右子树的高度值不能超过 1
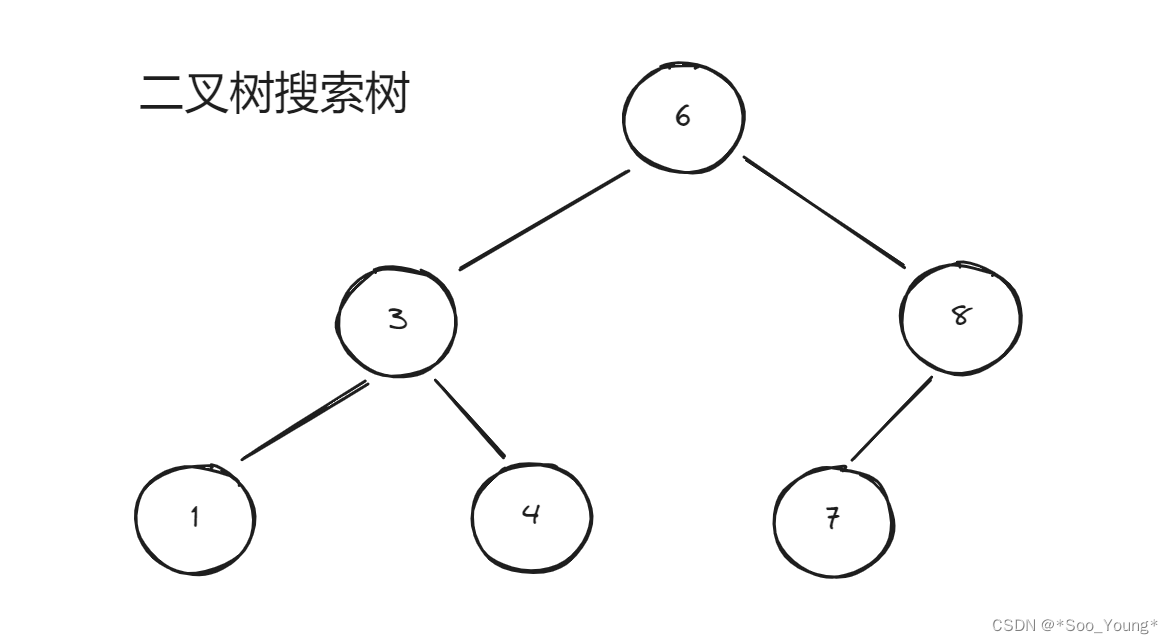
比如上面的树,比 6 大的在左边,小的在右边,且每个节点都是这样的,有顺序的,查询时间复杂度为 logn
很显然我们中间节点的选择会影响左子树和右子树的高度,左子树和右子树高度不超过 1 的被称为平衡二叉搜索树。
1.2 二叉树的存储方式
链式存储:顺序存储即采用链表的方式来存储,是我们常用的存储方式,即使用链表的方式来存储:一个树节点分别有它的左节点和右节点,他们的左节点和右节点又连接着其他的树节点。
顺序存储(了解即可):
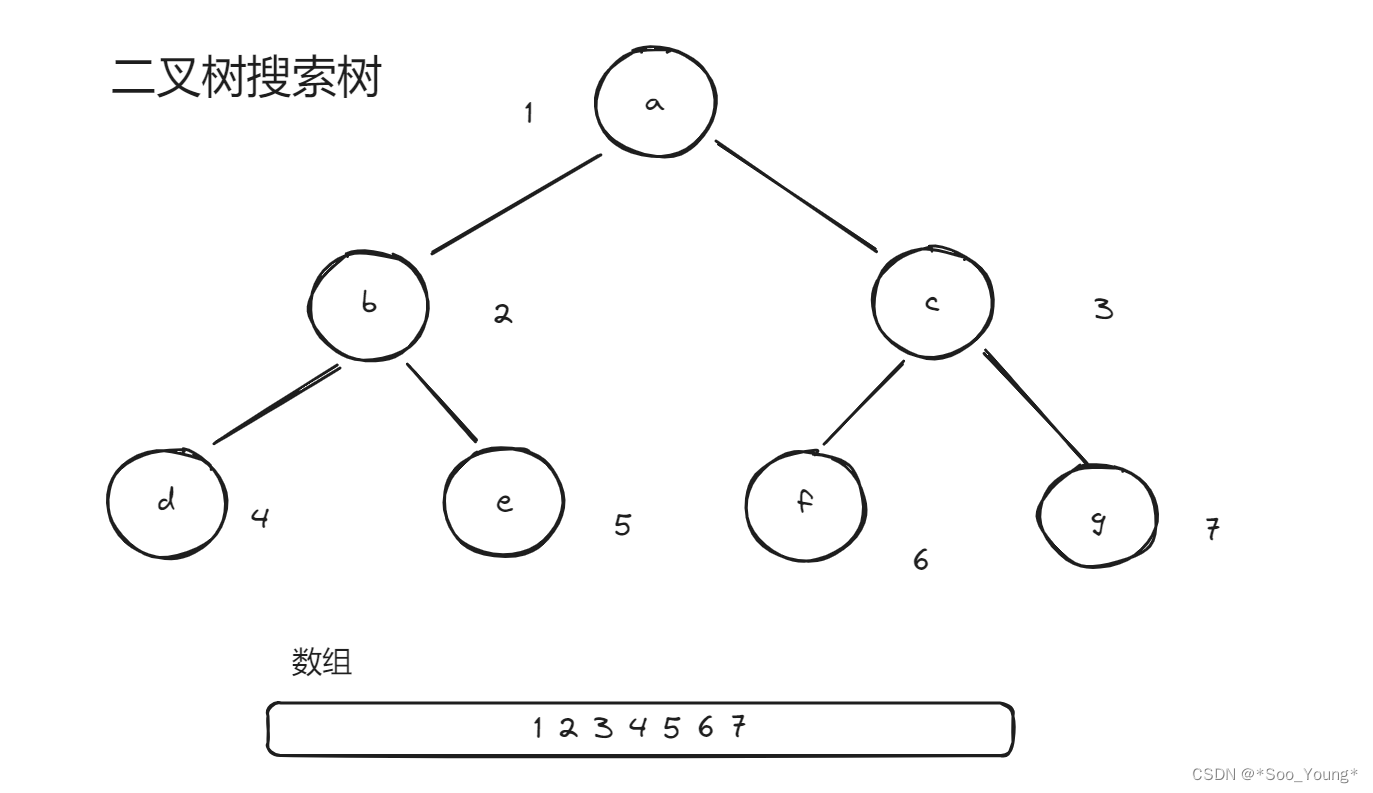
我们给每个节点编号,节点的左节点就是 2n 右节点就是 2n - 1
1.3 遍历方式
深度优先搜索:即先一路搜索到最底部再递归返回,我们常见的前序、中序、后序遍历都是深度优先搜索。
可以使用递归的方式和非递归的方式,迭代的方式有可能在面试中会考察
广度优先搜索:一层一层的去遍历,使用队列先进先出的特性实现广度优先搜索。
1.4 定义方式
class TreeNode {
int val;
TreeNode rightNode;
TreeNode leftNode;
}
和我们上面说的相同,和链表的定义方式相同,但分为左子树和右子树。
02. 二叉树的递归遍历
这一部分应该是很多朋友一开始学算法十分困惑的一个点,总是想不明白递归的题也看不明白递归的解法,我大一刚开始刷算法的时候也是这样,当时真是一入递归深似海,之后有一篇文章启发了我
东哥带你刷二叉树(纲领篇)
拉不拉东老师的这篇关于二叉树文章。
我来借用一下里面的思维方式
我们之所以无法理解递归是因为我们还是利用之前读代码和写代码的方式:“将自己的脑子当作计算机来执行一遍代码”,这在前面那些简单的顺序结构的题目中当然是可行而且有效的,但当我们解决的题目复杂起来,就比如现在的二叉树遍历的题目,我们的脑子能装下几个栈呢?能跑几层递归呢?
所谓理解和读懂递归就是要将它当作自己编写代码、解决问题的一种工具,而不是尝试去用脑子执行它,弄懂它的执行步骤,我们先来看一段二叉树 前序 遍历的代码
class Solution {
List<Integer> res = new ArrayList();
public List<Integer> preorderTraversal(TreeNode root) {
reverse(root);
return res;
}
public void reverse(TreeNode root) {
if (root == null) {
return;
}
res.add(root.val);
reverse(root.left);
reverse(root.right);
}
}
我们将重点放在第二段的代码上,如果单单的问你我不看递归,我这一次做了什么?
- 首先我先判断当前的节点是否为空节点,这就是我们常说的递归的出口
- 然后我们将当前节点的值放到了
res的list中作为结果 - 然后我们去递归遍历左子树
- 然后我们去递归遍历右子树
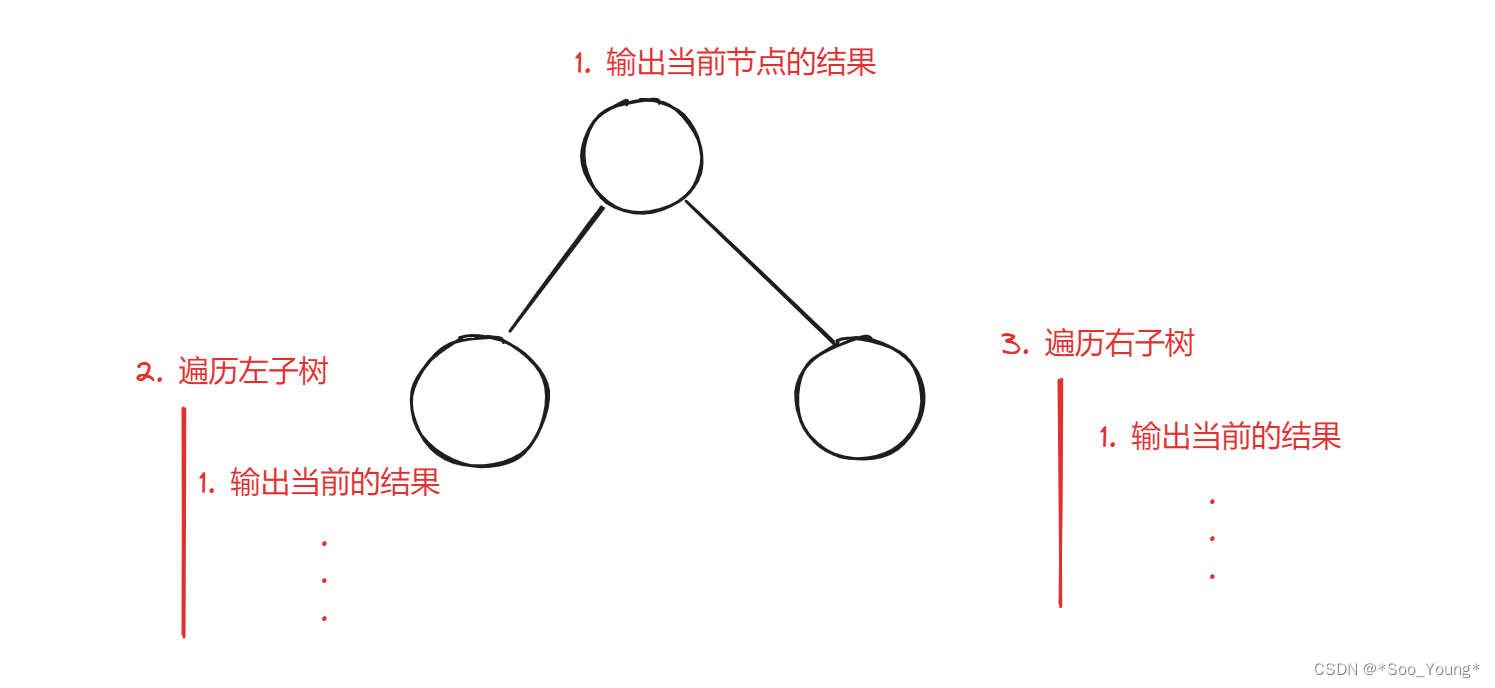
看我们上面的图是不是非常熟悉,这不就是前序遍历的遍历顺序吗?先中间再左边再右边,前序遍历无非就是对每个节点执行如上的相同的操作,那如何对每个节点操作呢?
递归的作用就是 帮助我们为每一个节点做相同的操作
我们只需要关注一个节点做的事情然后写到递归中,让递归帮我们去执行即可。
所有的递归都可以套用二叉树的模型来理解,我们知道,二叉树除了前序遍历,还有后序遍历和中序遍历:
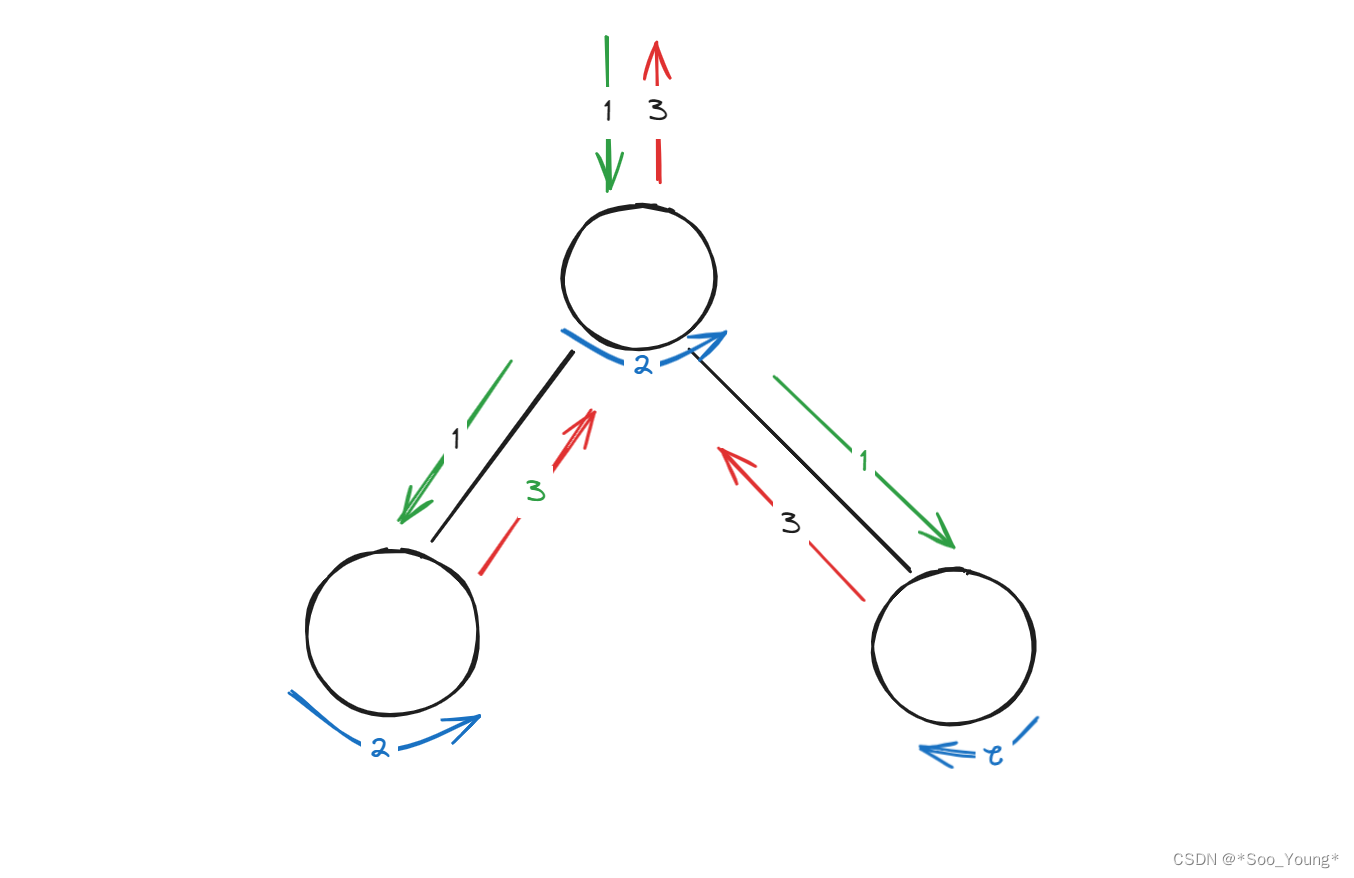
我们每次进入一个节点都可以分为三个位置:
- 前序位置
- 中序位置
- 后序位置
对应着上图中的 1 2 3 三个部分
前序中的操作即是我们进入这个节点后立马执行的操作,这不就是我们上面的前序遍历吗?进入节点后立马输出
中序就是在节点中执行的结果,即上图中的 2 ,这不就是左子树返回东西的地方吗?
那中序遍历的代码该怎么写?
public void reverse(TreeNode root) {
if (root == null) {
return;
}
reverse(root.left);
res.add(root.val);
reverse(root.right);
}
}
到这里是不是对递归主键的清晰起来了?
后序遍历的代码我们也可以很轻松的写出来
public void reverse(TreeNode root) {
if (root == null) {
return;
}
reverse(root.left);
res.add(root.val);
reverse(root.right);
}
}
如果上面的内容都能看懂,那么恭喜你已经解决了力扣上的三道题目:
No.144 二叉树的前序遍历
No.94 二叉树的中序遍历
No.145 二叉树的后序遍历
这里我们来看一个小小的问题:使用递归实现链表的倒序输出
如果将上面的部分看懂,那这道题相信对你来说很简单了
链表就是简化的二叉树,上面的每一个节点就可以通过上面的思路来处理
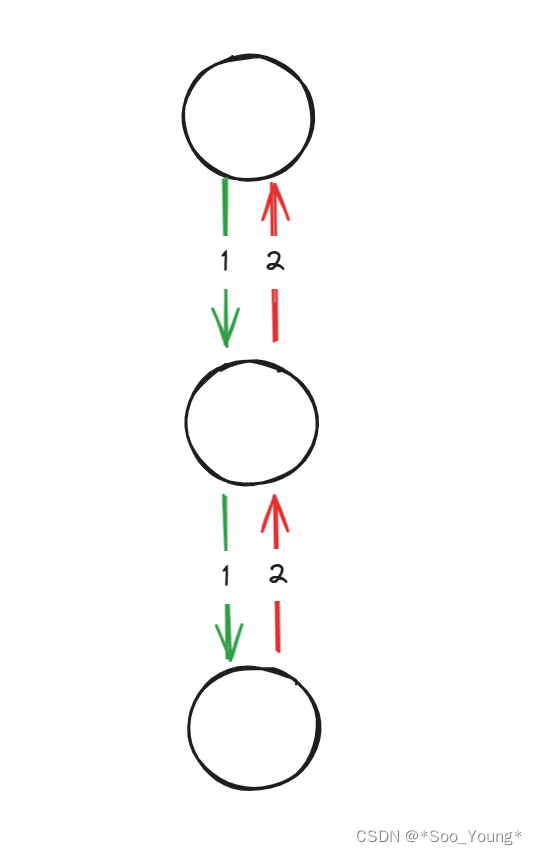
链表没有中序位置,只有前序和后序,既然要倒序输出链表,那我们要考虑的是我们的输出语句放在哪里
非常简单的二选一题目,肯定是放在后序的位置,呈现在代码中就是这样的:
public void reverse(ListNode head) {
if (head == null) {
return;
}
reverse(head.next);
System.out.println(head.val);
}
03. 二叉树的非递归遍历
3.1 非递归实现前序遍历
二叉树的递归遍历上面已经提到过了,代码实现也非常容易,但如果让我们使用非递归的方式来模拟前序遍历就比较困难了。
递归的实现是通过栈来完成的,所以我们自然的去想使用栈来模拟前序遍历,之前刷关于栈的题目的时候总结过,一道题能否用栈去解决关键在于能否满足先进后出的特点。
前序遍历是对 每个节点 进行 中 左 右 顺序的遍历,我们要对每个节点都进行这种操作,就会出现将节点放入又取出来,就会有先进后出的特性。
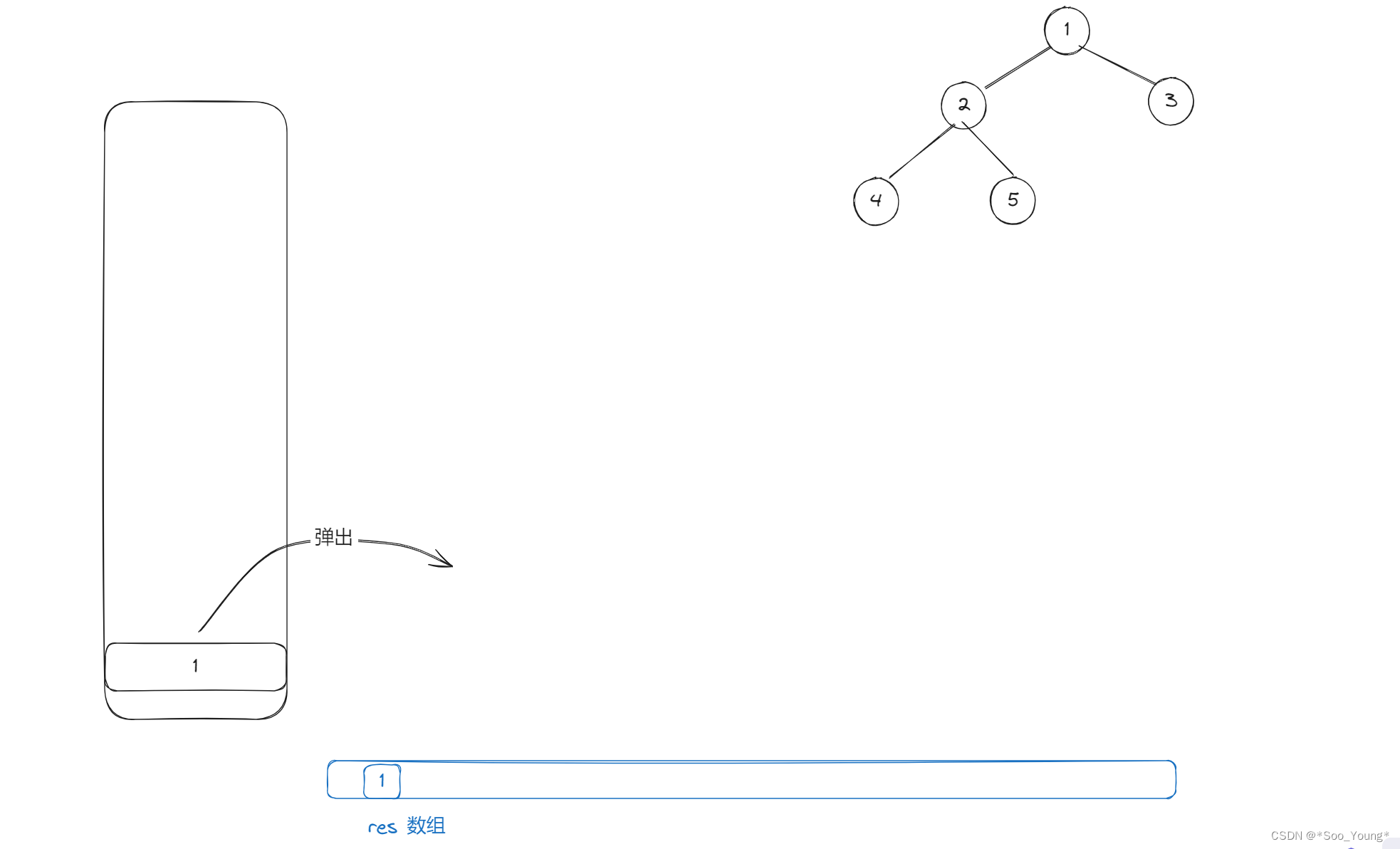
比如我们来模拟一下对这个二叉树的遍历
step 1
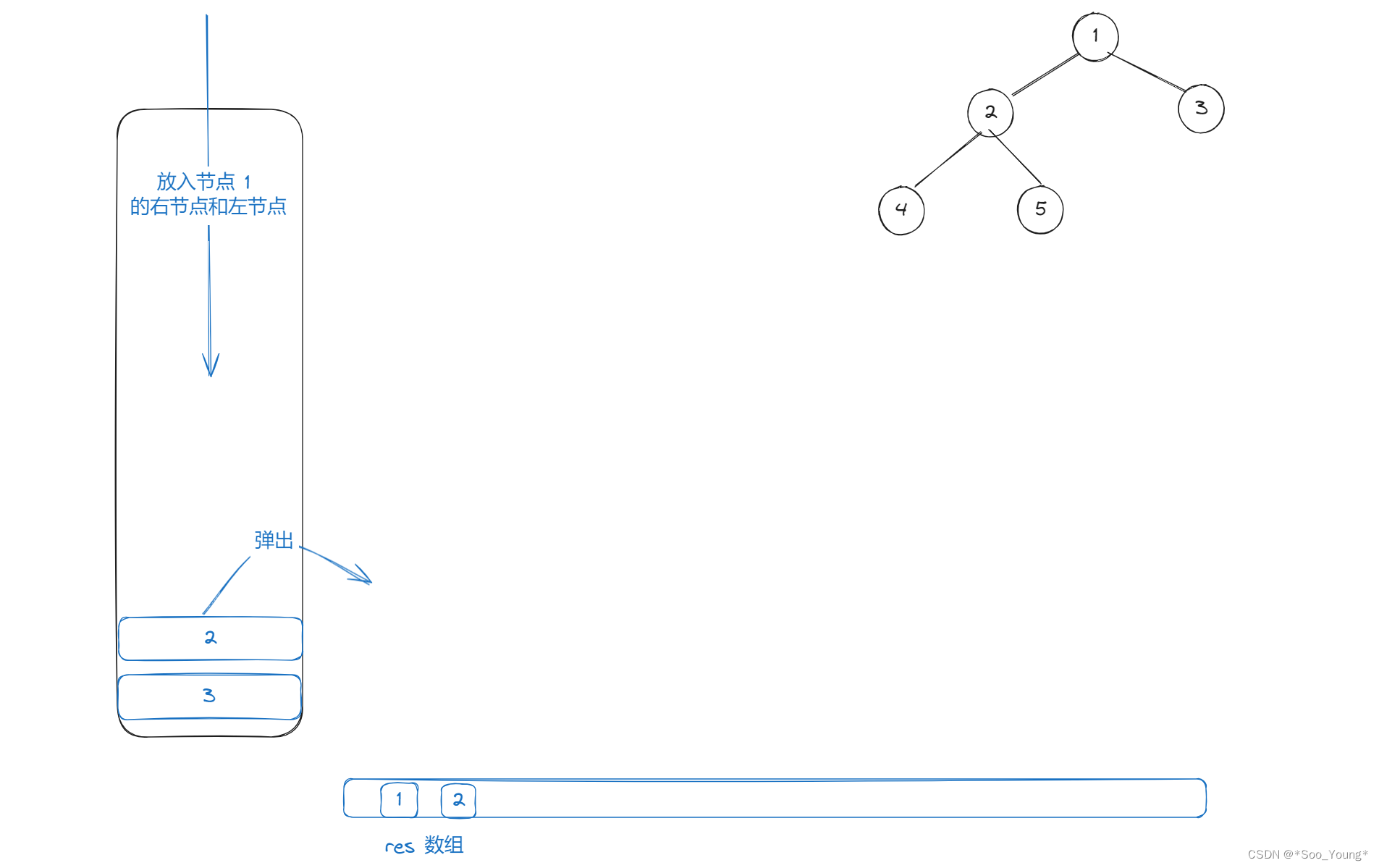
step2
step3
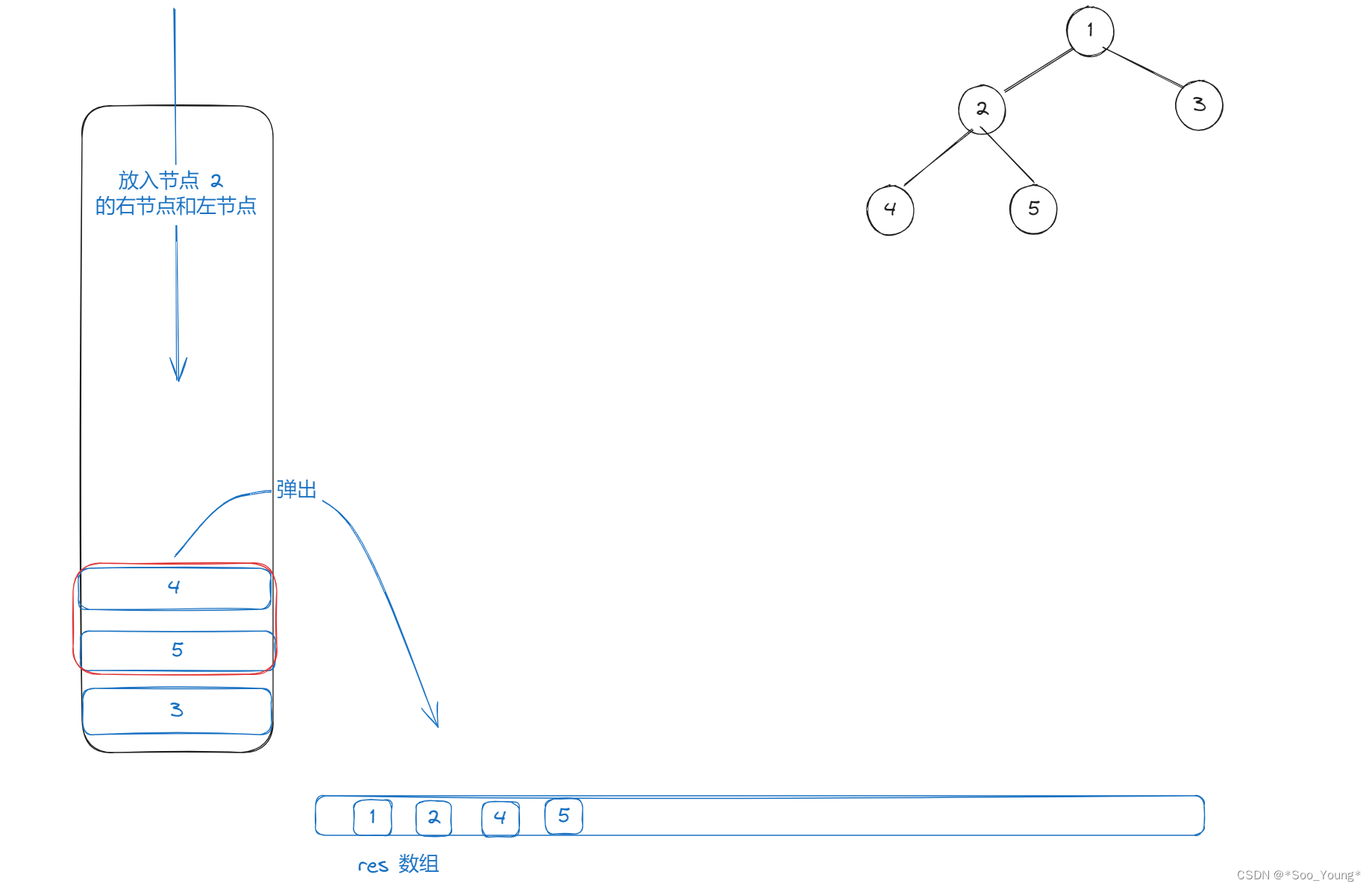
step4

和上面提到的一样,我们不用去模拟整个遍历的过程,我们只需要对每个节点进行的操作熟悉即可,再来总结一下上面的步骤:
- 将节点放入栈中
- 取出节点,存入结果数组
- 将节点的左节点放入栈中
- 将节点的右节点放入栈中
这样我们就用 非递归 的方式实现了前序遍历
这边给出代码,题目还是
No.144 二叉树的前序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
Stack<TreeNode> stack = new Stack<>(); // 栈
List<Integer> res = new ArrayList<>(); // 结果数组
public List<Integer> preorderTraversal(TreeNode root) {
stack.push(root);
// 在 while 中持续执行上面提到的顺序
while(!stack.isEmpty()) {
TreeNode node = stack.pop();
if (node != null) {
res.add(node.val);
stack.push(node.right);
stack.push(node.left);
}
}
return res;
}
}
3.2 非递归实现二叉树的后序遍历
后序遍历的顺序是 左 右 中,而我们上面前序遍历的顺序是 中 左 右,如果我们入栈的时候先放入 左节点,也就是让右节点先弹出,遍历的顺序就变成了 中 右 左,这不就是后序遍历的逆序吗?
对入栈的元素进行上述处理后,再反转数组就可以实现后序遍历的效果
No.145 二叉树的后序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
Stack<TreeNode> stack = new Stack<>(); // 栈
List<Integer> res = new ArrayList<>(); // 结果数组
public List<Integer> postorderTraversal(TreeNode root) {
stack.push(root);
// 在 while 中持续执行上面提到的顺序
while(!stack.isEmpty()) {
TreeNode node = stack.pop();
if (node != null) {
res.add(node.val);
stack.push(node.left); // 先放入右节点
stack.push(node.right);
}
}
Collections.reverse(res);
return res;
}
}
3.3 非递归实现中序遍历
中序遍历的顺序是 右 中 左,但这不像上面的后序遍历可以通过调整顺序再倒置的方式解出。
对于这种遍历顺序和输出次序不同的方式,给出另一个思路,可以通过指针加栈的方式
因为中序遍历是深度优先遍历,我们输出的第一个元素是遍历到左边最底部再输出的,所以我们指定一个指针一直持续向左遍历,直到 current.left 指向 null 的时候,也就是所有的左节点全都遍历完,这就是我们要输出的第一个元素,此时将栈中的元素弹出放入数组中。
然后我们来单独看 current 此时指向这个节点,这是我们要 输出 的第一个节点,再次来回顾一下中序遍历的过程
- 进入节点一直向左遍历
- 左边没有元素的时候直接输出当前节点
- 向右边遍历,对右边的节点执行相同的操作
当我们将当前的节点放入结果数组的时候,就已经执行完了前两个步骤,接下来就是去遍历右节点,并且对右节点执行相同的操作。
这道题的重点仍然是将中心放在某一个节点上,因为我们用栈记录了遍历的节点,通过弹栈就可以实现对每个节点实现相同的操作,接下来只需要将思路翻译成代码即可。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
List<Integer> res = new ArrayList();
TreeNode current;
Stack<TreeNode> stack = new Stack<>();
public List<Integer> inorderTraversal(TreeNode root) {
if (root == null){
return res;
}
current = root;
while (current != null || !stack.isEmpty()) {
if (current != null) {
stack.push(current);
current = current.left;
} else {
current = stack.pop();
res.add(current.val);
current = current.right;
}
}
return res;
}
}
04. 二叉树的广度优先搜索
层序遍历需要借助队列来实现,我们将每一层的元素一个个放到队列中,再逐一输出即可
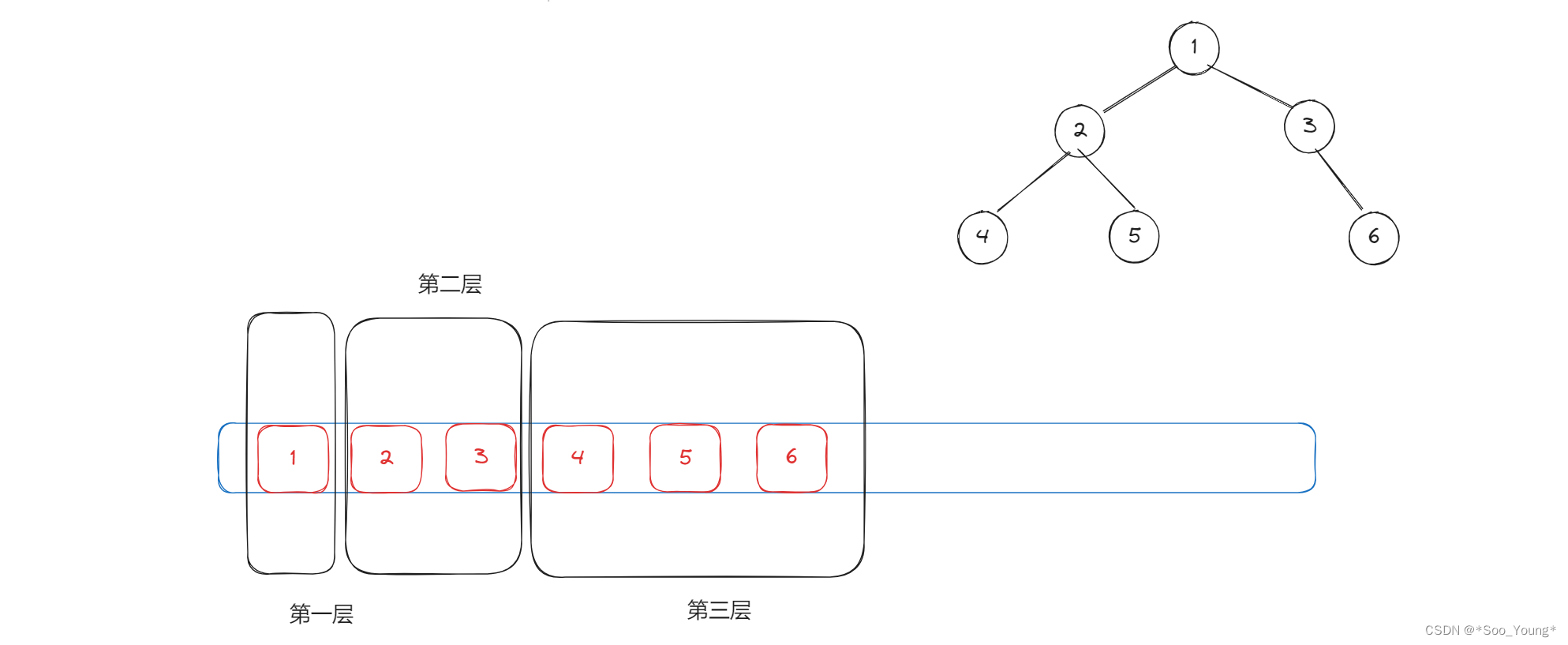
重要的就是要区分每一层有哪些元素,因为下一层元素的 add 是可以通过上一层元素弹出后再将其左右节点加入来实现的,所以我们需要一个变量 size 来记录每一层的元素个数。
利用 for 循环来输出每层的元素,此时 栈内剩下的元素 便是下一层的所有元素,此时更新我们的 size ,比如上图中的第二层中的元素遍历完后,栈内剩余的元素就是第三层的元素
No.102 二叉树的层序遍历
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
Queue<TreeNode> queue = new LinkedList<>();
List<List<Integer>> res = new ArrayList<>();
public List<List<Integer>> levelOrder(TreeNode root) {
if (root == null) {
return res;
}
int size = 1; // 记录每层的元素个数
queue.add(root);
while (!queue.isEmpty()) {
List<Integer> tempList = new ArrayList<>();
// 对每一层进行遍历
for (int i = size; i > 0; i--) {
TreeNode tempNode = queue.poll();// 弹出队列中的元素
if (tempNode != null) {
tempList.add(tempNode.val);
queue.add(tempNode.left);
queue.add(tempNode.right);
}
}
if (!tempList.isEmpty()){
res.add(new ArrayList(tempList));
}
size = queue.size();// 更新 size 的长度
}
return res;
}
}
1