一、股票数据基本分类
可分为(1)技术面数据和(2)基本面数据
(1)技术面数据
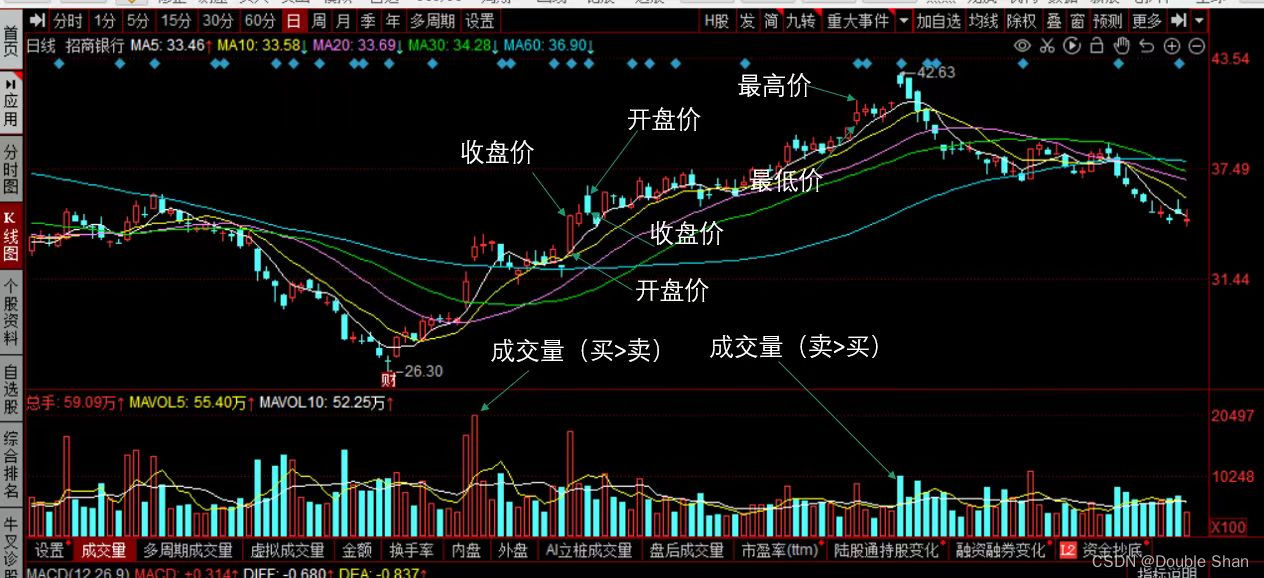
技术面数据是通过股票的历史价格和交易量等市场数据进行计算和分析得出的指标。常用的技术指标包括移动平均线、相对强弱指标、MACD指标等。技术面分析认为市场上已有的信息都会反映在股票价格中,因此通过分析股票价格图表和技术指标,可以尽可能准确地判断价格的走势和市场趋势。
(2)基本面数据
基本面数据是通过分析公司的财务状况、业绩表现、竞争力等基本信息得出的评估。常用的基本面指标包括市盈率、市净率、股息率等。基本面数据通常需要通过公司公开的财务报告和公告来获取。

二、股票基础数据获取
使用工具:Baostock,证券宝(www.baostock.com) 是一个免费、开源的证券数据平台,无需注册即可获取大量准确、完整的证券历史行情数据和上市公司财务数据。通过Python API获取数据信息,满足量化交易投资者、数量金融爱好者、计量经济从业者的数据需求。该工具包返回的数据格式为pandas DataFrame类型,方便使用pandas/NumPy/Matplotlib进行数据分析和可视化。此外,还支持将数据保存到本地进行分析,提供了更多的灵活性和便利性。
Baostock使用文档
接口:
query_history_k_data()
这个方法可以通过API接口获取A股的历史交易数据,你可以根据需要设置参数来获得日线、周线、月线以及5分钟、15分钟、30分钟和60分钟线的数据。这些数据可以结合均线数据进行选股和分析。返回的数据是pandas库中DataFrame类型的格式。数据范围从1990年12月19日至今,可以查询不复权、前复权或后复权数据。
(1)日线使用示例
import baostock as bs
import pandas as pd
from IPython.display import display
#### 登陆系统 ####
lg = bs.login()
# 显示登陆返回信息
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
#### 获取沪深A股历史K线数据 ####
# 详细指标参数,参见“历史行情指标参数”章节;“分钟线”参数与“日线”参数不同。“分钟线”不包含指数。
# 分钟线指标:date,time,code,open,high,low,close,volume,amount,adjustflag
# 周月线指标:date,code,open,high,low,close,volume,amount,adjustflag,turn,pctChg
#
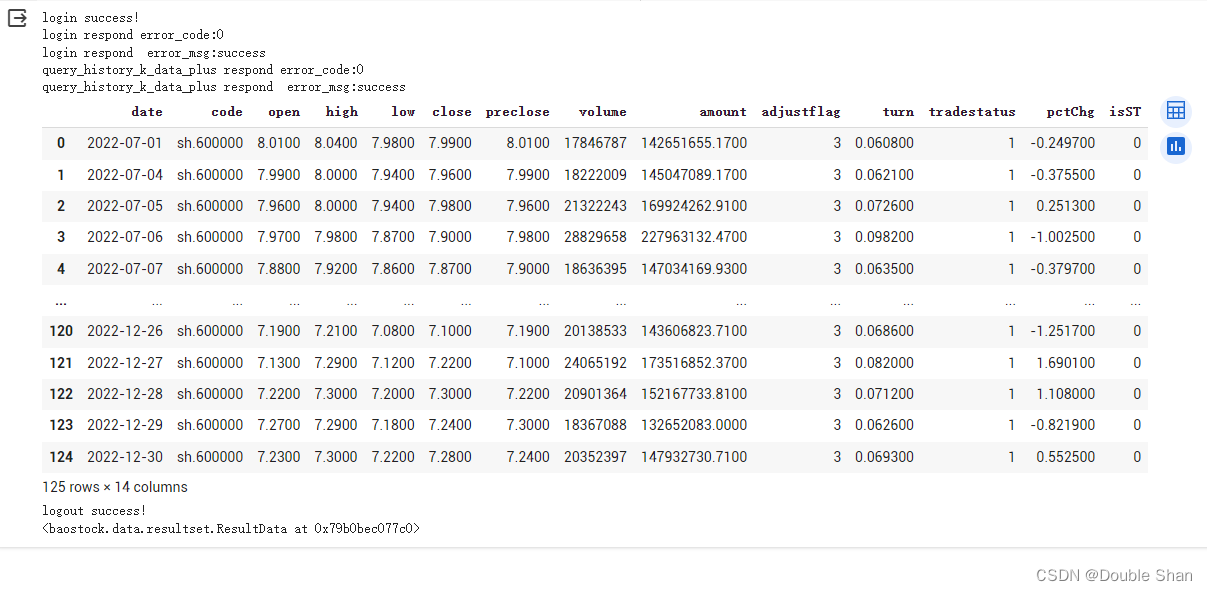
rs = bs.query_history_k_data_plus("sh.600000",
"date,code,open,high,low,close,preclose,volume,amount,adjustflag,turn,tradestatus,pctChg,isST",
start_date='2022-07-01', end_date='2022-12-31',
frequency="d", adjustflag="3")
print('query_history_k_data_plus respond error_code:'+rs.error_code)
print('query_history_k_data_plus respond error_msg:'+rs.error_msg)
#### 打印结果集 ####
data_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
#### 结果集输出到csv文件 ####
result.to_csv("./history_A_stock_k_data.csv", index=False)
display(result)
#### 登出系统 ####
bs.logout()
具体步骤如下:
首先导入需要用到的 baostock 和 pandas 库。
使用 bs.login() 函数登录 Baostock 系统,并输出登录返回信息。该函数返回一个对象 lg,其中包含了登录返回的错误代码和错误信息。
使用 bs.query_history_k_data_plus() 函数查询指定股票在指定时间范围内的 K 线数据,其中第一个参数为要查询的股票代码,第二个参数为要查询的 K 线数据字段列表,第三个参数为开始日期,第四个参数为结束日期,第五个参数为查询频率,第六个参数为复权类型。该函数返回一个对象 rs,其中包含了查询返回的错误代码和错误信息以及查询结果集。
将查询结果集转换成 Pandas DataFrame 格式,并输出到 CSV 文件中。首先创建一个空列表 data_list,然后使用 rs.next() 循环获取查询结果集里的每一行数据,将每一行数据存入 data_list 列表中。最后使用 Pandas 的 DataFrame 函数将 data_list 转换成 DataFrame 格式并输出到 CSV 文件中。
最后使用 bs.logout() 函数退出 Baostock 系统。
(2)分钟线使用示例
分钟线指的是股票或其他交易品种的价格走势图,每根蜡烛图表示一定时间间隔内的开盘价、收盘价、最高价和最低价。例如,1分钟线表示每根蜡烛图代表1分钟的价格走势。分钟线对于交易者来说具有重要意义,可以帮助他们快速分析市场趋势和价格波动,做出更明智的交易决策。以下是通过调用
query_history_k_data_plus()
方法来对分钟线进行数据获取。
import baostock as bs
import pandas as pd
from IPython.display import display
#### 登陆系统 ####
lg = bs.login()
# 显示登陆返回信息
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
#### 获取沪深A股历史K线数据 ####
# 详细指标参数,参见“历史行情指标参数”章节;“分钟线”参数与“日线”参数不同。“分钟线”不包含指数。
# 分钟线指标:date,time,code,open,high,low,close,volume,amount,adjustflag
# 周月线指标:date,code,open,high,low,close,volume,amount,adjustflag,turn,pctChg
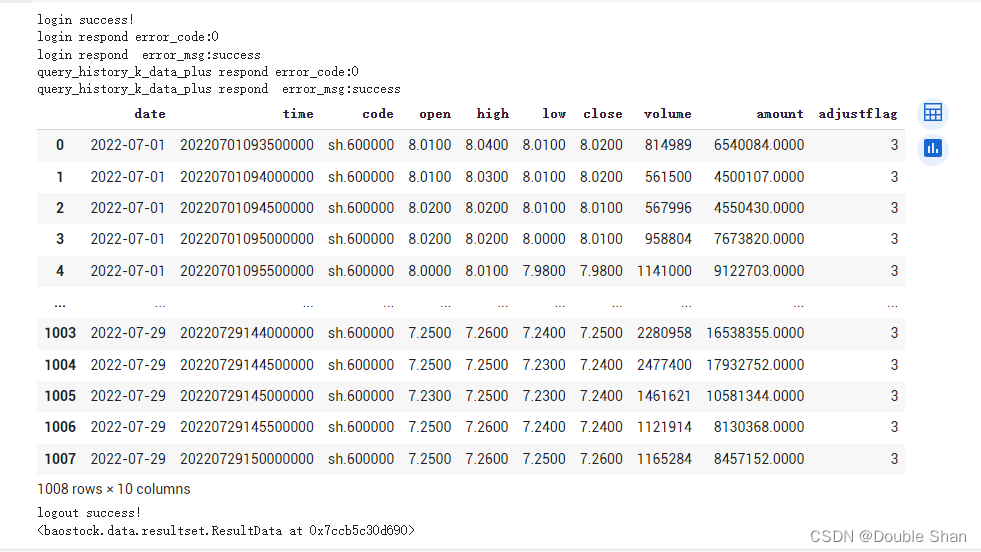
rs = bs.query_history_k_data_plus("sh.600000",
"date,time,code,open,high,low,close,volume,amount,adjustflag",
start_date='2022-07-01', end_date='2022-07-31',
frequency="5", adjustflag="3")
print('query_history_k_data_plus respond error_code:'+rs.error_code)
print('query_history_k_data_plus respond error_msg:'+rs.error_msg)
#### 打印结果集 ####
data_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
#### 结果集输出到csv文件 ####
result.to_csv("./history_A_stock_k_data.csv", index=False)
display(result)
#### 登出系统 ####
bs.logout()
技术面参数解释
code:股票代码,这个参数用于指定查询的股票或指数代码,以及所在交易所。输入格式为 “交易所代码.股票代码” 或 “交易所代码.指数代码”。其中,交易所代码"sh"代表上海证券交易所,"sz"代表深圳证券交易所。如:sh.601398,此参数不可为空。
fields:这个参数用于指定返回数据中包含哪些指标,支持多指标输入,以半角逗号分隔,填写内容作为返回类型的列。详细指标列表见历史行情指标参数章节,日线与分钟线参数不同。此参数不可为空;
start:这个参数用于指定查询的起始日期,格式“YYYY-MM-DD”,如果不指定,则默认从2015-01-01开始查询。
end:这个参数用于指定查询的结束日期,格式为“YYYY-MM-DD”。如果不指定,则默认查询最近一个交易日的数据。
frequency:这个参数用于指定查询的数据类型。可以选择返回日线、周线、月线或分钟线的K线数据。其中,大写字母表示周期,如"D"代表日线,"W"代表周线,"M"代表月线,数字表示分钟线的周期,如"5"代表5分钟线,"15"代表15分钟线等。指数只支持日线数据。周线数据只能选择每周最后一个交易日查询,月线数据只能选择每月最后一个交易日查询。
adjustflag:这个参数用于指定查询数据是否需要进行复权处理。如果需要进行复权处理,则可以选择前复权或后复权。复权类型,默认不复权:3;1:后复权;2:前复权。已支持分钟线、日线、周线、月线前后复权。
注意
对于日线数据的处理方法。因为在停牌期间没有交易,因此开盘价、最高价、最低价和收盘价都与前一个交易日的收盘价相同,成交量和成交额为0,换手率为空。
如果想将换手率转换为浮点数类型,则可以使用列表推导式,并将空字符串转换为0,最终将结果存储在"dataframe"(名为result)中的"turn"列中: result[“turn”] = [0 if x == “” else float(x) for x in result[“turn”]]
返回数据说明
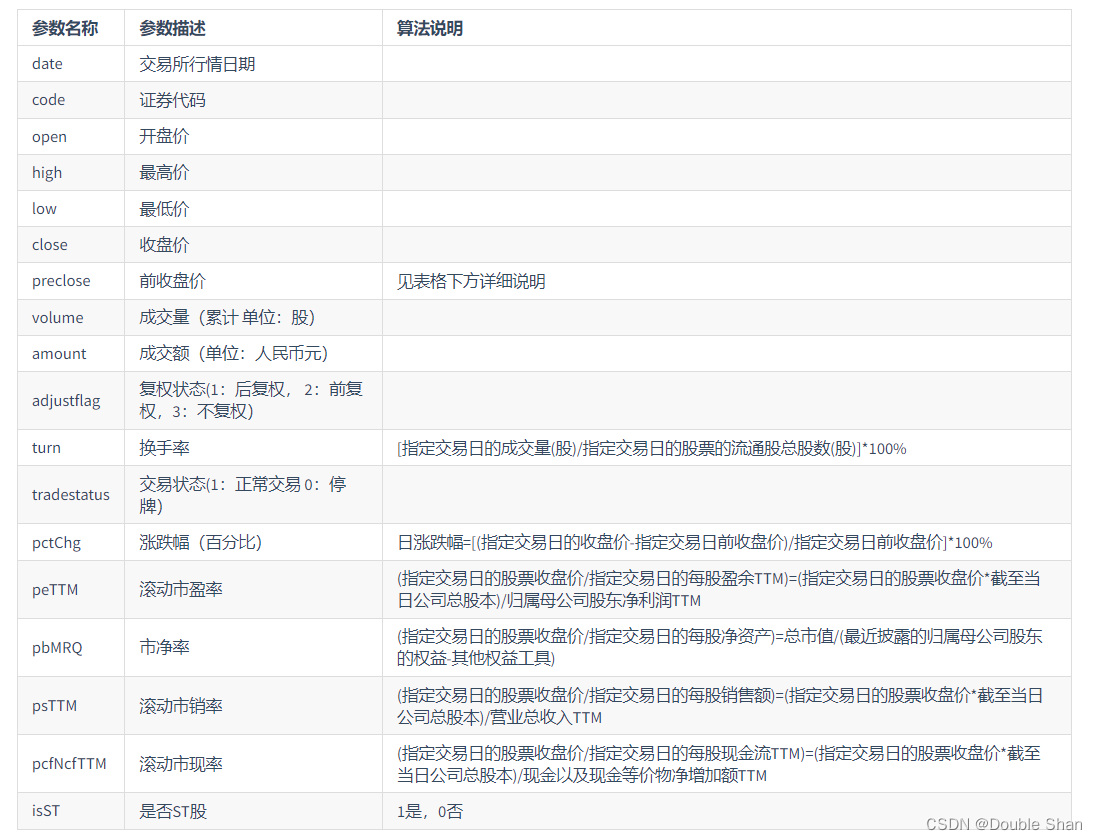
注意“前收盘价”说明:
当股票在指定交易日发生除权除息时,其前收盘价的计算方法有所不同。一般而言,前收盘价是指前一个交易日的实际收盘价,但当股权登记日与分红现金数量、配送股数和配股价等因素相结合时,前收盘价需要根据一定的计算方法得出。具体来说,需要先计算除息价,然后再计算送红股后的除权价和配股后的除权价,最后得出除权除息价。这个除权除息价就是指定交易日的前收盘价。该价格由交易所计算并公布,而在首发日,则将首发价格作为前收盘价。
具体计算方法如下:
1、计算除息价: 除息价=股息登记日的收盘价-每股所分红利现金额
2、计算除权价: 送红股后的除权价=股权登记日的收盘价/(1+每股送红股数) 配股后的除权价=(股权登记日的收盘价+配股价*每股配股数)/(1+每股配股数)
3、计算除权除息价 :除权除息价=(股权登记日的收盘价-每股所分红利现金额+配股价*每股配股数)/(1+每股送红股数+每股配股数)
关于复权数据说明
复权数据是在股票交易中调整历史价格和成交量的数据,以考虑除权、除息等事件对价格和成交量的影响。复权数据的意义在于能够更准确地反映股票的实际表现,避免因为除权、除息等事件造成的误导性信息。通过使用复权数据,投资者可以更好地了解股票的历史价格走势和成交量变化,以做出更明智的投资决策。
BaoStock使用“涨跌幅复权法”对历史股价数据进行复权处理,以便更准确地计算资金收益率。该方法的优点是可以保证初始投入的资金运用率为100%,从而避免分红或配股对投资额的影响。
然而,不同的系统可能采用不同的复权方式,因此在比较不同系统提供的股票数据时,可能会发现存在差异。例如,同花顺、通达信等软件可能采用其他的复权方式,导致与BaoStock提供的数据不一致。
(3)上证50成分股获取
上证50成分股指的是上海证券交易所(Shanghai Stock Exchange)挑选出来的50家规模最大、流动性最好的公司,这些公司在中国A股市场中具有较高的影响力和代表性。上证50指数是由这些50家公司的股票组成的指数。这个指数通常被视为中国股市的核心指标之一,因为它覆盖了50家规模大、具有代表性的公司,在市场风险和涨跌幅方面具有重要的参考意义。此外,由于该指数的成分股通常由市值较大、经营稳定的公司组成,因此被认为是一种相对较为稳健的投资方式。
query_sz50_stocks()
:这个方法通过API接口获取上证50成分股的信息,更新频率为每周一更新。这个方法返回一个pandas的DataFrame类型,即一个二维表格数据结构,其中包含了上证50成分股的详细信息。下面将结合代码对该方法进行讲解:
import baostock as bs # 导入 baostock 库
import pandas as pd # 导入 pandas 库
from IPython.display import display
# 登陆系统
lg = bs.login() # 调用 login 方法进行登陆
# 显示登陆返回信息
print('login respond error_code:'+lg.error_code) # 打印登陆返回错误码
print('login respond error_msg:'+lg.error_msg) # 打印登陆返回错误信息
# 获取上证50成分股
rs = bs.query_sz50_stocks() # 调用 query_sz50_stocks 方法获取上证50成分股信息
print('query_sz50 error_code:'+rs.error_code) # 打印方法返回错误码
print('query_sz50 error_msg:'+rs.error_msg) # 打印方法返回错误信息
# 打印结果集
sz50_stocks = [] # 创建一个空列表,用于存储查询结果
while (rs.error_code == '0') & rs.next():
# 如果查询没有出错且还有数据
sz50_stocks.append(rs.get_row_data()) # 将获取到的数据添加到列表中
result = pd.DataFrame(sz50_stocks, columns=rs.fields) # 使用 pandas 将数据转换为 DataFrame 格式
# 结果集输出到csv文件
result.to_csv("sz50_stocks.csv", encoding="gbk", index=False) # 将结果保存为 csv 文件
display(result) # 打印结果
# 登出系统
bs.logout() # 调用 logout 方法进行登出
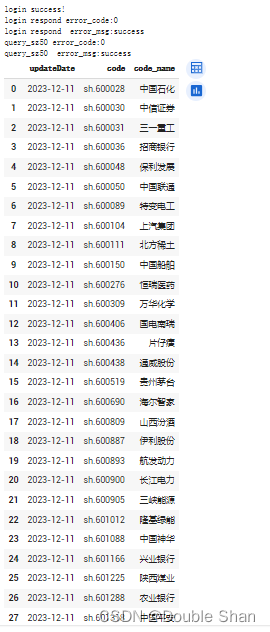
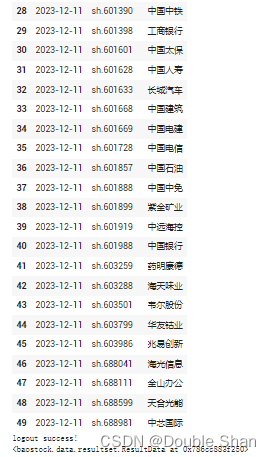
参数含义
date:查询日期,格式XXXX-XX-XX,为空时默认最新日期。
返回数据说明
参数名称 参数描述
updateDate 更新日期
code 证券代码
code_name 证券名称
(4)基本面数据获取
BaoStock 除了可以获取技术面数据,还可以获取基本面数据。BaoStock 可以获取的基本面数据主要有季频盈利能力、季频营运能力、季频成长能力、季频偿债能力等。
和技术面类似,BaoStock 通过 API 获取基本面数据。指定入参后,不同的 BaoStock API 会根据入参返回相应的数据。返回的数据类型是 pandas 的 DataFrame。
基本面数据入参说明如下:
code:股票代码,sz.+6位数字代码(0.8.8版本仅支持这一种格式),如:sh.601398。sh:上海;sz:深圳。此参数不可为空;
year:统计年份,为空时默认当前年;
quarter:统计季度,可为空,为空时默认取当前季度。不为空时只有4个取值:1,2,3,4。
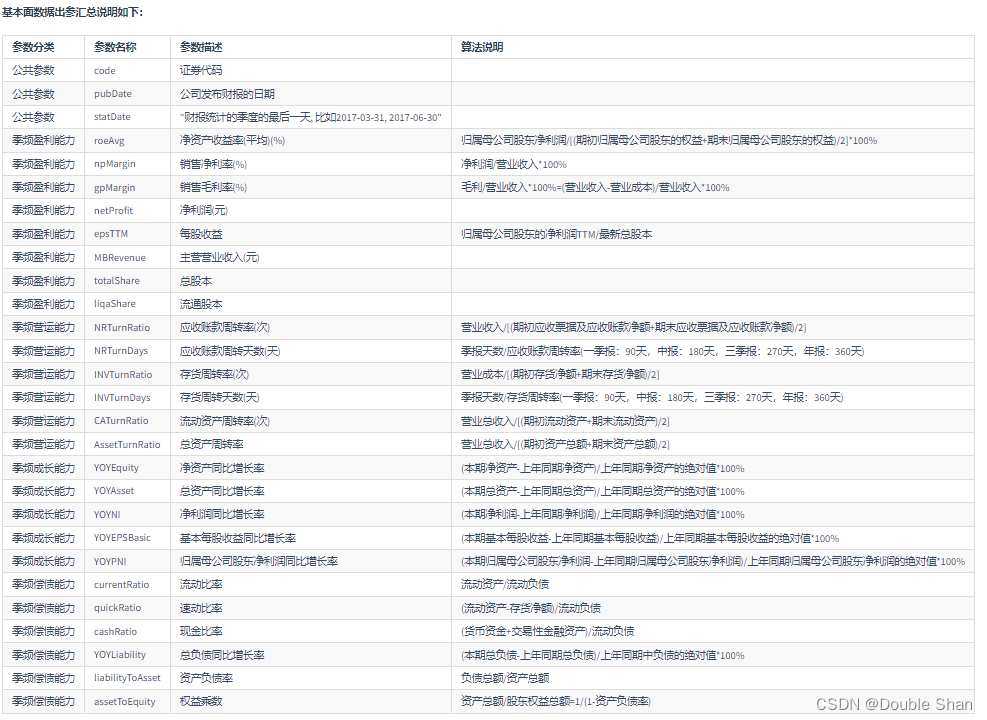
季频盈利能力
是指公司在每个季度内所实现的盈利水平和能力。这通常涉及到一些财务指标和比率,例如每股收益(EPS)、净利润率、毛利润率等等。这些指标可以用来评估公司的经营状况和盈利能力,对投资者来说是非常重要的参考数据之一。通过了解公司的季度盈利能力,投资者可以更好地了解公司的财务状况,从而做出更明智的投资决策。
import baostock as bs
import pandas as pd
from IPython.display import display
# 登录 BaoStock 系统
lg = bs.login()
# 显示登陆返回信息
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
# 获取600036招商银行季频盈利能力数据
profit_list = []
rs_profit = bs.query_profit_data(code="sh.600036", year=2022, quarter=4)
while (rs_profit.error_code == '0') & rs_profit.next():
profit_list.append(rs_profit.get_row_data())
# 转换为DataFrame格式
df_profit = pd.DataFrame(profit_list, columns=rs_profit.fields)
# 打印结果
display(df_profit)
# 将结果集输出到csv文件
df_profit.to_csv("D:\\profit_data.csv", encoding="gbk", index=False)
# 退出 BaoStock 系统
bs.logout()

为了计算从“2020-01-06”到“2020-01-10”的平均价格:
我们可以使用日期列表找到第一个和最后一个日期的索引。列表方法index(item)接受一个参数item,Python将搜索列表以找到第一个元素等于item的值,并返回其从零开始的索引位置。
我们可以使用切片将价格子集化以对这些日期的价格进行计算。
我们可以通过将所有元素的总和除以元素数量来计算平均值。Python的sum(iterable)函数可以用于将浮点数列表中的值相。
# ----------------------------------------------------------------------------
# The dates and prices lists
# ----------------------------------------------------------------------------
dates = [
'2020-01-02',
'2020-01-03',
'2020-01-06',
'2020-01-07',
'2020-01-08',
'2020-01-09',
'2020-01-10',
'2020-01-13',
'2020-01-14',
'2020-01-15',
]
# Close prices
prices = [
7.1600,
7.1900,
7.0000,
7.1000,
6.8600,
6.9500,
7.0000,
7.0200,
7.1100,
7.0400,
]
# Remember to uncomment the statements below and complete the part with '?'
start = dates.index('2020-01-06')
end = dates.index('2020-01-10')
print(start, end)
# Now, slice the `prices` list.
# Remember that slices do not include endpoints
prcs_w1 = prices[start:end+1]
# Finally, calculate the average of the prices in the slice
avgprc = sum(prcs_w1)/len(prcs_w1)
print(avgprc)