文章目录
- 前言
- 一、OFDM描述
- 二、本系统的实现参照
- 1.IEEE 802.11a协议主要参数
- 2.不同调制方式与速率
- 3. IFFT映射关系
- 4. IEEE 802.11a物理层规范
- 5. PPDU帧格式
- 三、设计与实现
- 1.扰码
- 2.卷积编码与删余
- 3.数据交织
- 4.符号调制
- 5.导频插入
- 6.IFFT变换
- 7.循环前缀&加窗
- 8.训练序列生成
- 9.发射主控MCU
- 四、仿真
- 1.modelsim仿真
- 2.ILA在线测试结果
- 附录
- Vivado工程文件
前言
本系统是参照了《基于Xilinx FPGA的OFDM通信系统基带设计》,结合了自己的理解,在Xilinx的zynq 7000系列FPGA芯片上实现了一个基于IEEE 802.11a协议的OFDM基带处理发射机的功能。包含了整个发射机的所有功能,序列训练符号、Siganl符号和Data符号等的实现过程,附Vivado工程文件和仿真测试文件。如有侵权,请告知!
一、OFDM描述
正交频分复用(OFDM)是一种特殊的多载波传输方案,它可以被看作一种调制技术,也可以被看作一种复用技术。最早起源于20世纪50年代中期,60年代形成了使用并行数据传输和频分复用的概念。1970年1月,首次公开发表了有关OFDM的专利。
在传统的并行数据传输系统中,整个信号频段被划分为N个相互不重叠的频率子信道,每个子信道传输不同的调制符号,然后再将N个子信道进行展频率复用。这种防止信道频谱重叠的做法虽然有利于消除信道间的干扰,但是这样有不能有效利用珍贵的频谱资源。为了解决这种低效利用频谱资源的问题,OFDM技术由此诞生了。
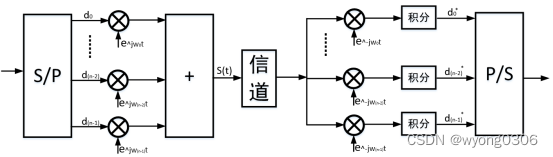
OFDM的基本原理就是把高速的数据流通过串并转换,变换成低速率的 N 路并行数据流,然后用 N 个相互正交的载波进行调制,将 N 路调制后的信号相加即得发射信号。它可以被看做一种调制技术,也可以被当做一种复用技术,一个OFDM符号包括多个经过调制的子载波。下图给出了OFDM系统的基本模型:
由于每个OFDM符号在其周期T内都包含多个非零的子载波,故其频谱可以看做是周期为T的矩形脉冲的频谱与一组位于各个子载波频率上的δ函数的卷积。矩形脉冲的频谱值为sinc(fT)函数,该函数在频谱为1/T的整数倍处均为零点。如下图所示为相互覆盖的各个子信道内经过矩形波形成型得到的符号的sinc函数频谱。可以发现,在每一个子载波的最大值处,所有其它子载波的频谱幅度恰好为零。由于在对OFDM符号进行解调的过程中,需要计算的正是每一个子载波频谱的最大值,因此可以从这些相互重叠的子信道符号频谱中提取出每个子信道符号而不会收到其它子信道的干扰。

OFDM的优点:
频谱利用率高
传统的FDM通常都采用在相邻的子载波之间保留一定的保护间隔的方法来避免载波之间干扰,降低了频谱利用率。而OFDM的各个子载波重叠排列,同时通过FFT技术实现了子载波之间的正交性,从而使数量更多的子载波能够在相同带宽内容纳,进而提高频谱利用率。
(2)有效对抗多径效应所造成的ISI和ICI
码间干扰(ICI)是数字通讯体系中除噪声干扰之外最重要的干扰,它与加性的噪声干扰不同,它是一种乘性的干扰,造成ICI的原因有很多, 实现上,只要传输信道的频带是有限的,就会造成必定的ICI,而OFDM能够通过循环前缀消除码间干扰(ICI)和符号间干扰(ISI)。
(3)有效对抗频率选择性衰落
通常情况下,无线信道都具有一定的频率选择性,而OFDM动态比特 分配以及动态子信道分配的方法,充分利用信噪比较高的子信道,从而提 高系统的性能,另一方面可以通过信道编码的方式,利用宽带信道的频率分集,用信噪比较高子信道传输的数据恢复低信噪比子信道传输的数据。
易于实现
硬件结构简单,发射机与接收机易于实现,复杂度低。可直接采用基于IFFT和FFT的OFDM方法实现。
OFDM的缺点:
(1)对频率偏移比较敏感
在OFDM系统中,只有先保证载波间的正交性,才能正确接收信号,任何频率偏移都会破坏载波间的正交性。在实现中,对于无线信道而言,其通常都存在一定的时变性,会导致信号的频率偏移现象,而且发射端与接收端的本地时钟(晶体振荡器)也无法完全相同。这会降低OFDM系统不同子载波彼此之间存在的正交性,虽然可以在接收端采用频率同步来获取 频偏并进行校正,但由于频偏估计的不精确而引起的残留频偏将会使信号 检测性能下降。
(2)较高的峰值平均功率比(PAPR)
在OFDM系统中,一个OFDM符号是由多个独立的、经过调制的子载波信号互相结合组成的,如果多个子载波由具有相同的相位,在时域中波形又直接叠加,这会导致此时的瞬间功率信号非常的大,所得峰值平均功率比较高,调制信号的动态范围大,发射机增加了功放成本,而且功耗较大。
二、本系统的实现参照
1.IEEE 802.11a协议主要参数

2.不同调制方式与速率
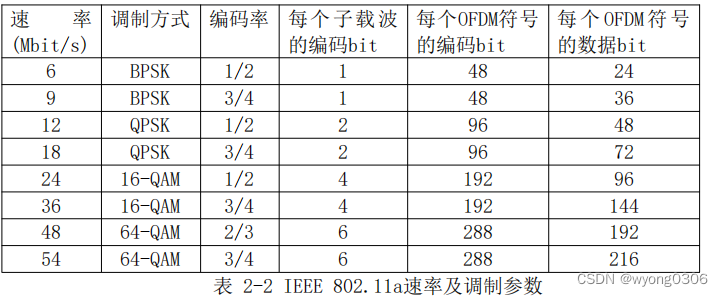
为了兼顾传输速率与可靠性的要求,系统可以根据信道的状况采用不同效率的纠错编码在各个子载波间进行信道编码,再配合不同的调制方式即可获得6~54Mb/s的编码数据速率。其中基本的编码方式的约束长度为7,编码效率为1/2的卷积编码(Convolutional Encoding),再通过对1/2编码方式进行删余(Puncturing)操作,可以获得码率为2/3、3/4的卷积编码。1/2码率的编码与BPSK、QPSK、16-QAM调制分别可以提供6、12、24Mb/s的数据传输速率;2/3码率的编码与64-QAM调制可以提供48Mb/s的数据传输速率;3/4码率的编码与BPSK、QPSK、16-QAM和64-QAM调制可以提供9、18、36和54Mb/s的传输速率。
3. IFFT映射关系
子载波实际可用数量有64个(基于2^N点的IFFT算法),但IEEE 802.11a中只使用了53个子载波(包括直流的0值),与之IFFT映射关系如下图所示,53个子载波在频率分配时分别在编号低端和高端留有6个和5个空符号,这样就可以保证系统的子载波频谱集中,从而使得系统占用的频谱带宽尽可能窄,以节约频谱资源,减少信道间干扰。

4. IEEE 802.11a物理层规范
IEEE 802.11a是针对OFDM系统的无线局域网标准,ISO结构如图2-1所示,在PHY层上采用OFDM调制,可分为两部分:
(1)PLCP子层:实现PHY层汇聚功能,把与具体物理实现有关的PMD子层功能转换为标准物理层服务,然后提供给MAC层。这使MAC层不关心PMD子层实现细节。在两端PHY层间交换的数据单元是包含物理层服务数据单元(Physical Service Data Unit,PSDU)的PPDU。而两端MAC层间交换的数据单元是MPDU,每个MPDU对应于PPDU中的PSDU。
(2)PMD子层:实现物理层协议数据单元(Physical Protocol Data Unit,PPDU)与无线电信号之间的转换,提供调制解调功能。利用OFDM技术在两端MAC层之间传送MAC层协议数据单元(MAC Protocol Data Unit,MPDU)。

5. PPDU帧格式
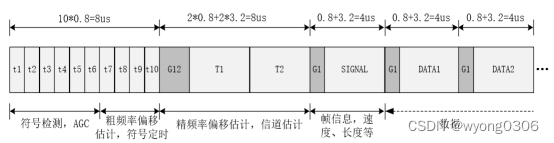
物理层协议数据单元(Physical Protocol Data Unit,PPDU)帧结构,也就是基带发射处理器所要生成的数据结构。PPUD由PSDU、前导码(PLCP-Preamble)和帧头(PLCP-Header)组成,如下图所示。
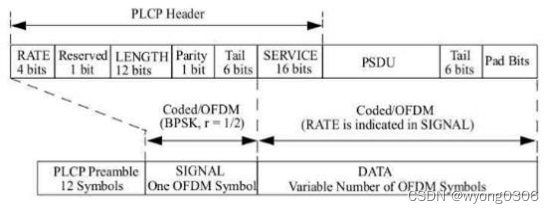
从中可以看出,前置的两个训练符号主要用于接收机的定时同步,载波频偏估计以及信道估计等。训练符号由10个周期重复的短训练符号(Short Training Symbol,STS)和两个周期重复的长训练符号(Long Training Symbol,LST)组成,总的训练序列时间长度为16us,训练序列符号后面为“SIGNAL”域,长度为一个正常OFDM符号长度,其中包含有后续数据的调制类型、编码速率和数据长度等。 PPDU帧详细结构如下:
三、设计与实现
整个基带处理器发送机系统架构为:
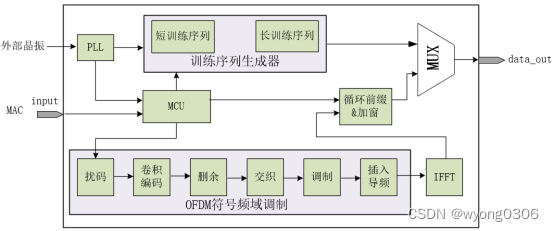
该系统分为训练序列生成器、MCU、OFDM符号频域调制、IFFT和循环前缀&加窗。 序列主要为后续接收端的时域同步和信道估计及均衡提供算法支撑,训练序列包括长、短训练序列两部分,短训练序列主要用来进行信号检测帧同步,长训练序列用来进行信道估计从而对接收信号进行补偿。PLL模块主要负责各种频率的时钟信号生成,MCU主要负责产生发射机所需要的各种控制信号,保证各个子模块按照一定的时序进行工作,并且能彼此协调和同步。MCU主要控制整个系统时序的对齐,以及保证各个子模块的正常工作,同时还与MAC层交互,向MAC层请求数据等。最终的OFDM符号存在严格的时序要求,训练序列后紧跟Signal域和Data域,Data域OFDM符号之间不能存在空闲时序。
代码如下:
clk_wiz_0 u_pll
(
// Clock out ports
.clk_80m ( cb_clk ),
.clk_60m ( din_clk ),
.clk_20m ( sys_clk ),
.clk_7_5m( mac_clk ),
// Status and control signals
.reset (~sys_rst_n),
.locked ( locked ),
// Clock in ports
.clk_in1(sys_clk_in)
);
//长、短序列码训练
symbol_train u_train (
.clk (sys_clk ),
.rst_n (rst_n ),
.Tx_Clr (Tx_Clr ),
.Start_En (Train_Start_En ),
.Train_Im (Train_Im ),
.Train_Re (Train_Re ),
.Train_Vld (Train_Vld ),
.Train_Index (Train_Index ),
.Train_Done (Train_Done )
);
OFDM_Data_Modem u_Modem(
.din_clk (din_clk ),//60M
.cb_clk (cb_clk ),
.sys_clk (sys_clk ),
.rst_n (rst_n ),
.Tx_Clr (Tx_Clr ),
.Rate_Con (Rate_Con ),
.Signal_Flag (Signal_Flag ),
.Scram_Seed (Scram_Seed ),
.Data_Bit (Modem_Bit ),
.Data_Bit_Vld (Modem_Bit_Vld ),
.Dout_Re (M_Dout_Re ),
.Dout_Im (M_Dout_Im ),
.Dout_Vld (M_Dout_Vld )
);
IFFT u_ifft(
.clk_80m (cb_clk ),//80M
.sys_clk (sys_clk ),//20M
.rst_n (rst_n ),
.Dout_Index (IFFT_Out_Index ),
.Dout_Re (IFFT_Out_Re ),
.Dout_Im (IFFT_Out_Im ),
.Dout_Vld (IFFT_Out_Vld ),
.Din_Re (M_Dout_Re ),
.Din_Im (M_Dout_Im ),
.Din_En (M_Dout_Vld )
);
cp_add u_cp_add(
.clk (sys_clk ),
.rst_n (rst_n ),
.Din_Re (IFFT_Out_Re ),
.Din_Im (IFFT_Out_Im ),
.Din_En (IFFT_Out_Vld ),
.Din_Index (IFFT_Out_Index ),
.Dout_Re (Cp_Out_Re ),
.Dout_Im (Cp_Out_Im ),
.Dout_Vld (Cp_Out_Vld )
);
//MCU control module
Trans_MCU u_Trans_MCU(
.rst_n (rst_n ),
.mac_clk (mac_clk ),
.clk_20m (sys_clk ),
.clk_60m (din_clk ),
.Phy_Status (Phy_Status ),
.Txstart_Req (Txstart_Req ),
.Tx_Param (Tx_Param ),
.Din (Din ),
.Din_Vld (Din_Vld ),
.Din_Req (Din_Req ),
.Tx_Clr (Tx_Clr ),
.Train_Start_En (Train_Start_En ),//序列训练输出使能
.Modem_Bit (Modem_Bit ),//输出bit数据流
.Modem_Bit_Vld (Modem_Bit_Vld ),//signa域、data域数据调制使能
.Signal_Flag (Signal_Flag ),//singal域数据标志信号
.Rate_Con (Rate_Con ),//数据速率控制信号
.TxPWR (Dout_TxPwr ),//功率级数
.Scram_Seed (Scram_Seed )
);
assign Dout_Im = ~Train_Done ? Train_Re : Cp_Out_Re ;
assign Dout_Re = ~Train_Done ? Train_Im : Cp_Out_Im ;
assign Dout_Vld = ~Train_Done ? Train_Vld : Cp_Out_Vld ;1.扰码
根据IEEE 802.11a协议规定, 扰码器的伪随机码生成多项式为:
![]()
其结构如下:
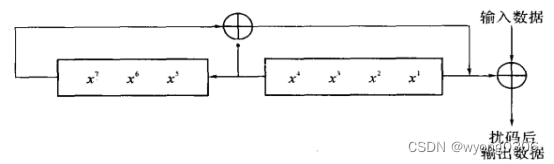
发送比特的扰码和接收比特的解码使用的扰码器完全一致。当发送时,扰码器通常将被设置为伪随机非零状态。同时,在扰码前Service域的最低7位将设为零,以便在接收端估计扰码器的初始状态。
设计上,通过一个7位移位寄存器,在输入信号有效时,每个时钟周期扰码状态左移位一次,并且第7位与第4位进行异或运算,再作为移位寄存器的输入,另一方面与输入的信号进行加扰处理,后输出数据,同时拉高输出有效。
扰码模块代码如下,Signal_Flag为Signal符号标志信号,由于Signal符号只进行卷积编码、交织、BPSK映射、插入导频,不扰码、删余。因此,需要对Signal符号数据作标志。
代码如下:
always@(posedge clk or negedge rst_n ) begin
if(!rst_n) begin
shift_reg <= 0;
Scram_Dout <= 0;
Scram_Vld <= 0;
end
else if( Scram_Load ) begin
shift_reg <= scram_seed;
Scram_Vld <= 0;
end
else if( Scram_En && ~Signal_Flag_In ) begin
Scram_Dout <= shift_reg[6] + shift_reg[3] + Scram_Din; //s(x) = x^7 + x^4 + 1
Scram_Vld <= 1;
shift_reg <= {shift_reg[5:0],(shift_reg[6]+shift_reg[3])}; //寄存器自移位
end
else if( Scram_En && Signal_Flag_In ) begin
Scram_Dout <= Scram_Din;
Scram_Vld <= 1;
end
else begin
Scram_Vld <= 0;
end
end
always@(posedge clk or negedge rst_n ) begin
if(!rst_n) begin
Signal_Flag_Out <= 0;
end
else if( ~Signal_Flag_In ) begin
Signal_Flag_Out <= 0;
end
else if( Signal_Flag_In ) begin
Signal_Flag_Out <= 1;
end
end2.卷积编码与删余
Data域中的编码方式以约束长度为7、编码效率为R=1/2的卷积编码 ,其结构图为:

从上图可看出 ,输出数据A生成多项式为:
![]()
输出数据B生成多项式为:
![]()
因此,可以使用6个移位寄存器来实现卷积编码,每输入1比特数据,都将会同时输出2比特数据A和B,实现了1/2码率的卷积编码。
代码如下:
always@(posedge clk or negedge rst_n ) begin
if(!rst_n || Tx_Clr) begin
shift_reg <= 0;
Conv_Dout <= 0;
Conv_Vld <= 0;
end
else if( Conv_En ) begin
Conv_Dout[0] <= shift_reg[5] + shift_reg[4] + shift_reg[2] + shift_reg[1] + Conv_Din;
Conv_Dout[1] <= shift_reg[5] + shift_reg[2] + shift_reg[1] + shift_reg[0] + Conv_Din;
Conv_Vld <= 1;
shift_reg <= {shift_reg[4:0],Conv_Din}; //移位寄存器
end
else begin
Conv_Vld <= 0;
end
end卷积后,再通过对编码器输出的数据进行删余(Puncturing)操作,可以获得码率为2/3、3/4的卷积编码,如下图所示,其中图(a)和图(b)分别是1/2编码后通过删余操作变换为3/4码率的编码和2/3码率的编码。删余操作就是在发射机上删除一些比特(这样减少了发射比特数,从而提高了编码率),在接收机卷积解码器上把删除的比特位再插入空比特,在IEEE 802.11a标准中推荐使用viterbi算法解密。

(a)3/4码率

(b) 2/3码率
设计上,在输入时钟域下,通过当前Rate_Con 信号得到删余方式,通过一个6比特位宽寄存器(最大删余输入比特数),先对输入数据进行缓存,并对当前数据删余方式作标记,再通过多次打拍加边沿检测,做夸时钟域处理。
在输出时钟域下,在当前删余数据数据被断言后,截取输入时钟域数据,并获取当前数据删余方式。计算输出计数器数值范围,并驱动计数器开始计数。同时向输出端口驱动当前时钟域缓存区数据。
代码如下:
//输入时钟域下,对数据缓存
always@(posedge din_clk or negedge rst_n ) begin
if(!rst_n) begin
Puncture_in <= 0;
Cnt_Index <= 0;
Cache_Valid <= 0;
end
else if( Punt_En ) begin //间隔3clk 有效
case ( RATE_CON )
4'b1101,4'b0101,4'b1001: begin
Puncture_in[1:0] <= Punt_Din; // Rate is 1/2 .
Cache_Valid <= 1'b1;
Cnt_Index <= 0;
end
4'b1111,4'b0111,4'b1011,4'b0011: begin
Puncture_in <= {Puncture_in[3:0],Punt_Din}; // Rate is 3/4 .
if(Cnt_Index==2)
Cnt_Index <= 0;
Cache_Valid <= 1'b1;
else
Cnt_Index <= Cnt_Index + 1'b1;
Cache_Valid <= 1'b0;
end
4'b0001: begin
Puncture_in <= {Puncture_in[3:0],Punt_Din}; // Rate is 2/3 .
if(Cnt_Index==1)
Cnt_Index <= 0;
Cache_Valid <= 1'b1;
else
Cnt_Index <= Cnt_Index + 1'b1;
Cache_Valid <= 1'b0;
end
default:;
endcase
end
else begin
Cache_Valid <= 1'b0;
end
end
***
***
***
//输出时钟域下,读取数据
always@(posedge cb_clk or negedge rst_n ) begin
if(!rst_n) begin
Punt_Dout <= 0;
Punt_Vld <= 0;
end
else if(Add_Cnt_Bit ) begin
case(Cnt_Bit_Max)
1:begin
case ( Cnt_Bit )
0: begin
Punt_Dout <= Puncture_reg[0];
Punt_Vld <= 1'b1;
end
1: begin
Punt_Dout <= Puncture_reg[1];
Punt_Vld <= 1'b1;
end
default:;
endcase
end
2:begin
case ( Cnt_Bit )
0: begin
Punt_Dout <= Puncture_reg[0];
Punt_Vld <= 1'b1;
end
1: begin
Punt_Dout <= Puncture_reg[1];
Punt_Vld <= 1'b1;
end
2: begin
Punt_Dout <= Puncture_reg[2];
Punt_Vld <= 1'b1;
end
default:;
endcase
end
3:begin
case ( Cnt_Bit )
0: begin
Punt_Dout <= Puncture_reg[0];
Punt_Vld <= 1'b1;
end
1: begin
Punt_Dout <= Puncture_reg[1];
Punt_Vld <= 1'b1;
end
2: begin
Punt_Dout <= Puncture_reg[2];
Punt_Vld <= 1'b1;
end
3: begin
Punt_Dout <= Puncture_reg[5];
Punt_Vld <= 1'b1;
end
default: Punt_Vld <= 0;
endcase
end
default: Punt_Vld <= 0;
endcase
end
else begin
Punt_Vld <= 1'b0;
end
end
3.数据交织
卷积编码只能用来纠错随机错误,而通信系统中常会出现整个序列错误,即所谓的突发错误。交织的目的就是在时域或频域,或同时在时域和频域上分布传输比特,以便把突发错误变为随机错误。
所有编码后的数据都要以单个OFDM符号中的比特数Ncpbs为块的大小,使用块交织器进行交织。所有的编码数据比特的交织都在一个OFDM符号内进行,其交织长度为OFDM符号的长度。整个交织过程分为两级,第一级为标准的块交织,其作用是保证相邻的编码比特被映射到非相邻的子载波上。第二级交织保证相邻的编码比特被分别映射到星座图中的高有效和低有效比特位,避免了数据中LSB(Least Significant Bits,最低位有效)长时间低可靠性。
第一次交织交换公式为:
![]()
第二级交织公式为:
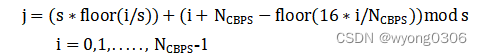
分组交织器的读写结构如下所示。
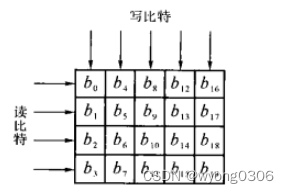
由调制方式的不同,可得BPSK、QPSK、16-QAM和64-QAM调制的交织深度分别为48、96、192和288个比特。Signal域符号采用BPSK调制,因此其交织只涉及第一级变换;Data域符号采用16-QAM调制,需要两级交织处理,第一级为标准的分组交织器,第二级交织为每24个比特为一个单元,前12个顺序保持不变,后12个每相邻两位交换位置,这样就保证了相邻的编码比特被分别映射到星座图中的重要和次要位置。
在设计上,为保证流水线设计结构,能够对数据进行连续处理,需要将RAM的存储空间设置为最大交织深度288的一倍。相邻的OFDM符元就能实现乒乓缓存。0-287地址空间为乒乓缓存A区数据空间,288-575为乒乓缓存B区数据空间,实现A区写入数据,B区读取数据。
当输入数据有效时,对输入数据按一级交织方式进行错位写入RAM,并驱动写入计数器以交织深度为长度进行计数,计满一个交织深度后,拉高当前缓存区标志信号,并驱动读取计数器以当前缓存区长度计数,通过Signal域标志信号,判断当前是否需要进行二级交织。在不需要进行二级交织时,直接驱动当前地址以顺序读取RAM数据驱动到输出端口;在需要进行二级交织时,驱动模12计数器和模1计数器,模12计数器以输出有效为计数单位,模1计数器以模12计数器为单位。当模1计数器为1时,需要对RAM地址的低1比特作变换操作(1’b0->1’b1,1’b1->1’b0),以达到二级交织效果。
代码如下:
//乒乓缓存,交叉写入buffer
always@(posedge clk or negedge rst_n ) begin
if(!rst_n) begin
wea <= 0;
addra <= 0;
dina <= 0;
i <= 0;
end
else if( Add_Cnt_Index && (i==0) ) begin
case(Intv_Con)
N_48:begin //N = 48
wea <= 1;
addra <= Cnt_Index[3:0] + (Cnt_Index[3:0]<<1) + Cnt_Index[8:4] ; //Cnt_Index *3
dina <= Intv_Din;
end
N_96:begin //N = 96
wea <= 1;
addra <= (Cnt_Index[3:0]<<1) + (Cnt_Index[3:0]<<2) + Cnt_Index[8:4] ; //Cnt_Index *6
dina <= Intv_Din;
end
N_192:begin //N = 192
wea <= 1;
addra <= (Cnt_Index[3:0]<<3) + (Cnt_Index[3:0]<<2) + Cnt_Index[8:4]; //Cnt_Index *12
dina <= Intv_Din;
end
N_288:begin //N = 288
wea <= 1;
addra <= (Cnt_Index[3:0]<<4) + (Cnt_Index[3:0]<<1) + Cnt_Index[8:4]; //Cnt_Index *18
dina <= Intv_Din;
end
default:;
endcase
if(End_Cnt_Index) i <= 1;
end
else if( Add_Cnt_Index && (i==1) ) begin
case(Intv_Con)
N_48:begin //N = 48
wea <= 1;
addra <= Cnt_Index[3:0] + (Cnt_Index[3:0]<<1) + Cnt_Index[8:4] + 288; //Cnt_Index *6
dina <= Intv_Din;
end
N_96:begin //N = 96
wea <= 1;
addra <= (Cnt_Index[3:0]<<1) + (Cnt_Index[3:0]<<2) + Cnt_Index[8:4] + 288; //Cnt_Index *6
dina <= Intv_Din;
end
N_192:begin //N = 192
wea <= 1;
addra <= (Cnt_Index[3:0]<<3) + (Cnt_Index[3:0]<<2) + Cnt_Index[8:4] + 288; //Cnt_Index *12
dina <= Intv_Din;
end
N_288:begin //N = 288
wea <= 1;
addra <= (Cnt_Index[3:0]<<4) + (Cnt_Index[3:0]<<1) + Cnt_Index[8:4] + 288; //Cnt_Index *18
dina <= Intv_Din;
end
default:;
endcase
if(End_Cnt_Index) i <= 0;
end
else begin
wea <= 0;
end
end
**
**
**
//顺序读出或二级交织错位读出
always@(posedge clk or negedge rst_n ) begin
if(!rst_n) begin
addrb <= 0;
Rd_Buf_Vld <= 0;
end
else if( Buf_A_Flag && ~Signal_Flag_Reg ) begin
Rd_Buf_Vld <= 1'b1;
if(Back_12Bits==0)
addrb <= Cnt_Bit;
else if(Back_12Bits==1) begin
case(Cnt_Bit[1:0])
1'b0: addrb <= {Cnt_Bit[8:1],1'b1};
1'b1: addrb <= {Cnt_Bit[8:1],1'b0};
default:;
endcase
end
end
else if( Buf_B_Flag && ~Signal_Flag_Reg) begin
Rd_Buf_Vld <= 1'b1;
if(Back_12Bits==0)
addrb <= 288 + Cnt_Bit;
else if(Back_12Bits==1) begin
case(Cnt_Bit[0])
1'b0: addrb <= 288 + {Cnt_Bit[8:1],1'b1};
1'b1: addrb <= 288 + {Cnt_Bit[8:1],1'b0};
default:;
endcase
end
end
else if( Signal_Flag_Reg && (Signal_Interval_Time==0) ) begin
addrb <= Cnt_Bit;
Rd_Buf_Vld <= 1;
end
else begin
Rd_Buf_Vld <= 0;
end
end 4.符号调制
根据不同的速率要求,OFDM的子载波需要用BPSK、QPSK、16-QAM和64-QAM调制方式调制。数据经过卷积编码和交织后,串行的数据流以每1、2、4或6个比特分成一组,以一定的规则映射成复数,形成BPSK、QPSK、16-QAM和64-QAM调制。 本系统中Signal域数据以BPSK调制,Data域数据以16-QAM调制。
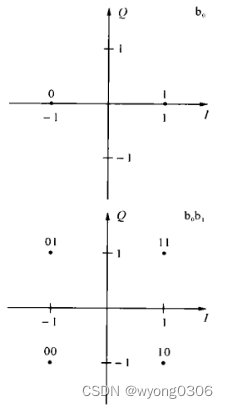
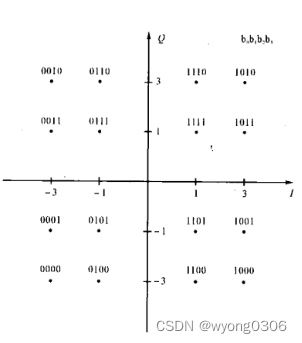
BPSK和QPSK星座映射图 16-QAM星座映射图

64-QAM星座映射图
调制方式不同,对应的归一化因子也不同

在设计上,在输入时钟域中,通过调制方式不同,将串行数据流以1、2、4或6比特分成一组,缓存在一个6比特寄存器中,等到比特数据达到一组时,将该组数据通过连续打拍方式,将数据及控制信号寄存到输出时钟域中。在输出时钟域中,再通过改组数据映射方式进行映射并归一化得到调制的I和Q两路数据。复数以8位定点数形式进行输出,格式为:1位符号位,一位整数位,6位小数位,负数以补码形式表示。
代码如下:
// 通过调制方式不同,得到Cnt_Bits不同的最大值,进行缓存
always@(posedge cb_clk or negedge rst_n ) begin
if(!rst_n) begin
Map_Bits <= 0;
end
else if( Add_Cnt_Bits ) begin
case(Map_Type)
2'b00:
case(Cnt_Bits)
0: Map_Bits[0] <= Qam16_Din;
default:;
endcase
2'b01:
case(Cnt_Bits)
0: Map_Bits[0] <= Qam16_Din;
1: Map_Bits[1] <= Qam16_Din;
default:;
endcase
2'b10:
case(Cnt_Bits)
0: Map_Bits[0] <= Qam16_Din;
1: Map_Bits[1] <= Qam16_Din;
2: Map_Bits[2] <= Qam16_Din;
3: Map_Bits[3] <= Qam16_Din;
default:;
endcase
2'b11:
case(Cnt_Bits)
0: Map_Bits[0] <= Qam16_Din;
1: Map_Bits[1] <= Qam16_Din;
2: Map_Bits[2] <= Qam16_Din;
3: Map_Bits[3] <= Qam16_Din;
4: Map_Bits[4] <= Qam16_Din;
5: Map_Bits[5] <= Qam16_Din;
default:;
endcase
default:;
endcase
end
end
**
**
**
//映射,输出的8bits数据为经过归一化处理后的数据
always@(posedge clk or negedge rst_n ) begin
if(!rst_n || Tx_Clr) begin
Qam16_Re <= 0;
Qam16_Im <= 0;
Qam16_Vld <= 0;
Index_Out <= 6'b111_111;
end
else if( Map_Bits_Vld_20M ) begin
case(Map_Type_20M)
2'b00: begin //Bpsk
case(Map_Bits_20M[0])
1'b0: Qam16_Re <= 8'b1100_0000; //
1'b1: Qam16_Re <= 8'b0100_0000;
default:Qam16_Re <= 0;
endcase
Qam16_Im <= 8'b00000000;
Qam16_Vld <= 1;
Index_Out <= Index_Out + 1;
end
2'b01: begin //Qpsk
case(Map_Bits_20M[0])
1'b0: Qam16_Re <= 8'b1101_0011; //-1 * 1/√2
1'b1: Qam16_Re <= 8'b0010_1101; //1 * 1/√2
default:Qam16_Re <= 0;
endcase
case(Map_Bits_20M[1])
1'b0: Qam16_Im <= 8'b1101_0011;
1'b1: Qam16_Im <= 8'b0010_1101;
default: Qam16_Im <= 0;
endcase
Qam16_Vld <= 1;
Index_Out <= Index_Out + 1;
end
2'b10: begin //16-qam
case(Map_Bits_20M[1:0])
2'b00: Qam16_Re <= 8'b11000011; //-3 * 1/√10
2'b10: Qam16_Re <= 8'b11101100;
2'b11: Qam16_Re <= 8'b00111101;
2'b10: Qam16_Re <= 8'b00010100;
default:Qam16_Re <= 0;
endcase
case(Map_Bits_20M[3:2])
2'b00: Qam16_Im <= 8'b11000011;
2'b10: Qam16_Im <= 8'b11101100;
2'b11: Qam16_Im <= 8'b00111101;
2'b10: Qam16_Im <= 8'b00010100;
default: Qam16_Im <= 0;
endcase
Qam16_Vld <= 1;
Index_Out <= Index_Out + 1;
end
2'b11: begin //64-qam
case(Map_Bits_20M[2:0])
3'b000: Qam16_Re <= 8'b1011_1011; //-7 * 1/√42
3'b001: Qam16_Re <= 8'b1100_1111; //-5*1/√42
3'b011: Qam16_Re <= 8'b1110_0011; //-3*1/√42
3'b010: Qam16_Re <= 8'b1111_0111; //-1*1/√42
3'b110: Qam16_Re <= 8'b0100_0101; //7*1/√42
3'b111: Qam16_Re <= 8'b0011_0001;//5*1/√42
3'b101: Qam16_Re <= 8'b0001_1101;//3*1/√42
3'b100: Qam16_Re <= 8'b0000_1001;//1*1/√42
default:Qam16_Re <= 0;
endcase
case(Map_Bits_20M[5:3])
3'b000: Qam16_Im <= 8'b1011_1011; //-7 * 1/√42
3'b001: Qam16_Im <= 8'b1100_1111; //-5*1/√42
3'b011: Qam16_Im <= 8'b1110_0011; //-3*1/√42
3'b010: Qam16_Im <= 8'b1111_0111; //-1*1/√42
3'b110: Qam16_Im <= 8'b0100_0101; //7*1/√42
3'b111: Qam16_Im <= 8'b0011_0001;//5*1/√42
3'b101: Qam16_Im <= 8'b0001_1101;//3*1/√42
3'b100: Qam16_Im <= 8'b0000_1001;//1*1/√42
default: Qam16_Im <= 0;
endcase
Qam16_Vld <= 1;
Index_Out <= Index_Out + 1;
end
default:;
endcase
end
else begin
Qam16_Vld <= 0;
Index_Out <= 6'b111_111;
end
end5.导频插入
接收符号通过训练序列校正频偏后还会存在一定的剩余频率偏差,会造成所有子载波产生一定的相位偏转,因此在符号同步之后,还需要不断地对参考相位进行跟踪。为此,需要在52个子载波中插入4个导频符号,它们的位置为{-21,-7,7,21};它们由一个二进制伪码序列进行BPSK调制。
Data域数据经过映射后以串行复数流输入,以为单位分组,每一组对应一个OFDM号。52个子载波标号依次为-26,-25,...,-1,1,2,...,25,26。4个导频初始极性依次为1,1,1,-1对应位置{-21,7,7,21}。4个导频插入的极性是随OFDM符号序号的变化而变化的(1->-1,-1->1),其关系可以为一个初始状态全为“1”的扰码器产生。
由于导频插入模块之后为IFFT变换,因此本模块在输出时需要对输出顺序作变换,使得数据输出时顺序符合IFFT输入要求。当使用64点IFFT运算时,输入的48个数据(标号0-47)的标号应按如下公式进行变换,映射为-26~26,其中,符号标号-21,-7,7,21为导频插入处,K为输出数据标号:
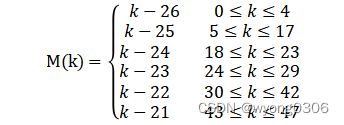
根据IEEE 802.11a协议对IFFT输入端口映射的规定,将变换后的M(k)为1~26的子载波映射到IFFT输入端口的1~26,M(k)为-26~-1的子载波映射到IFFT的端口38~63,剩下的全置为零值。映射描述图如下:

相应的,插入导频的位置-21,-7,7,21分别对应IFFT的输入端口43,57,1,7。因此,写入RAM中的数据标号可以以如下公式变换实现:
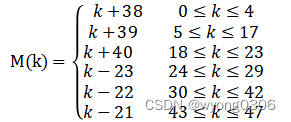
在设计上,采用乱序写,顺序读的方式。先定义2个RAM,分别对输入数据的实数和虚数按Index序号通过式4-7公式变换后,存入RAM中。再通过扰码器产生的极性控制信号,对导频是否极性变换做处理,极性处理后,将导频信号写入对应RAM地址空间中。最后,以顺序方式从RAM中读取数据。为保证流水线处理,以及写入写成不发生冲突,RAM的深度需设置为2个OFDM符号的长度。
代码如下:
//导频极性控制
always@(posedge clk or negedge rst_n ) begin
if(!rst_n || Tx_Clr) begin
shift_reg <= 7'b111_1111;
end
else if( pilot_start ) begin
shift_reg <= 7'b111_1111;
end
else if( wr_done ) begin
shift_reg <= {shift_reg[5:0],(shift_reg[6]+shift_reg[3])}; //寄存器自移位
end
end
assign scram_out = (shift_reg[6]+shift_reg[3]); //当 scram_out== 0 时,不需要极性取反, 当 scram_out==1 时,需要极性取反。
**
**
**
//错序写入
else if( Pilot_En ) begin //写入复数样值
Re_addra[6] <= cnt_symbol[0] ? 1 : 0;
case(Pilot_Index)
0,1,2,3,4 :
Re_addra[5:0] <= Pilot_Index+38 ;
5,6,7,8,9,10,11,12,13,14,15,16,17 :
Re_addra[5:0] <= Pilot_Index+39 ;
18,19,20,21,22,23 :
Re_addra[5:0] <= Pilot_Index+40 ;
24,25,26,27,28,29 :
Re_addra[5:0] <= Pilot_Index-23 ;
30,31,32,33,34,35,36,37,38,39,40,41,42 :
Re_addra[5:0] <= Pilot_Index-22 ;
43,44,45,46,47 :
Re_addra[5:0] <= Pilot_Index-21 ;
default:Re_addra[5:0] <= 0;
endcase
Re_dina <= Pilot_DinRe;
Re_wea <= 1;
end
**
**
**
//导频插入
else if( insert ) begin //先插入导频
case(Re_addra[5:0]) // 顺序 1,1,1,-1 >> 43 57 7 21
0 :begin
Re_addra[5:0] <= 7;
Re_dina <= scram_out ? 8'b11000000 : 8'b01000000;
Re_wea <= 1;
end
7 :begin
Re_addra[5:0] <= 21;
Re_dina <= scram_out ? 8'b01000000 : 8'b11000000;
Re_wea <= 1;
end
21 : begin
Re_addra[5:0] <= 43;
Re_dina <= scram_out ? 8'b11000000 : 8'b01000000;
Re_wea <= 1;
end
43 :begin
Re_addra[5:0] <= 57;
Re_dina <= scram_out ? 8'b11000000 : 8'b01000000;
Re_wea <= 1;
end
57 :begin
Re_addra[5:0] <= 0;
Re_wea <= 0;
end
default: begin
Re_addra[5:0] <= 0;
Re_wea <= 0;
end
endcase
end
**
**
**
//顺序读取
always@(posedge clk or negedge rst_n ) begin
if(!rst_n) begin
Pilot_DoutRe <= 0;
Pilot_DoutIm <= 0;
Pilot_Vld <= 0;
end
else if( rdy1 ) begin //输出一次64个数据
Pilot_DoutRe <= Re_doutb;
Pilot_DoutIm <= Im_doutb;
Pilot_Vld <= 1;
end
else
Pilot_Vld <= 0;
end6.IFFT变换
OFDM复等效基带信号可以用快速傅里叶变换(FFT/IFFT)实现。在设计上,直接利用Xilinx提供的IP核来实现FFT功能。本系统采样版本为FFT 9.1 ,该IP核核心功能强大,配置灵活,完全可以满足本系统的要求。
对FFT 9.1 IP核信息配置为:
(1)Configuration:
Number of Channels(通道数)设置为:1;
Transform Length(FFT长度)设置为:64;
Target Clock Frequency(目标时钟频率)设置为:80,每个OFDM符号64个数据,每帧间隔16个系统时钟周期,20MHz是无法满足这种要求的,所有需要提高FFT运算时钟频率;
Architecture Choice(FFT结构选择)设置为:Radix-4,基4的迭代算法,使用的资源比流水线结构多,相对于Radix-2时间相对更短;
(2)Implementation:
Data Format(数据格式)设置为:Fixed Point,定点数;
Scaling Options(缩放选项)设置为:Scaled,截断数据与输入数据位宽相同;
Rounding Modes(舍入模式)设置为:Truncation收敛截位,如果该数是奇数则向上舍入,如果该数是偶数则向下舍入;
Precision Options(精度选项)均设置为:16,为了提高FFT处理时中间步骤的运算精度,保证DAC变换的精度,需对输入I/Q两路数据进行放大处理,并将FFT IP核的输入位宽设置为16位;
Control Signal可选可不选;
Output Ordering(输出秩序)设置为:Natural Order自然顺序;
Optional Output Fields设置为: XK_INDEX, 输出数据的通道数,也即是XK 的下标;
Throttle Schemes设置为:Non Real Time;
(3)Detaild implementation:Memory option,选择数据存储的存储器类型;Optimize options优化选项等默认即可。
FFT IP核端口信号描述
| 信号 | 方向 | 说明 |
| s_axis_config_tdata | in | 配置参数 |
| s_axis_config_tvalid | in | 配置参数有效 |
| s_axis_config_tready | out | FFT IP核配置参数准备好 |
| s_axis_data_tdata | in | 输入数据。低16位为实数输入,高16位为虚数输入 |
| s_axis_data_tvalid | in | 数据有效信号 |
| s_axis_data_tready | out | 输入数据准备好 |
| s_axis_data_tlast | in | 标识每帧的最后一个数据 |
| m_axis_data_tdata | out | 数据输出(复数) |
| m_axis_data_tuser | out | 输出数据的下标 |
| m_axis_data_tvalid | out | 数据有效 |
| m_axis_data_tready | in | 接收数据准备好 |
| m_axis_data_tlast | out | 标识最后一个数据 |
| event_frame_started | out | 当开始处理一个新帧时,该事件信号被断言为单个时钟周期 |
| event_tlast_unexpected | out | 当没有接收到一帧的最后一个数据而s_axis_data_tlast拉高时,这表明输入数据的长度与IP核预设的数据不匹配 |
| event_tlast_missing | out | 当接收到一帧的最后一个数据而s_axis_data_tlast没有拉高时,这表明输入数据的长度与IP核预设的数据不匹配 |
| event_status_channel_halt | out | 每当核心需要向data Output通道写入数据,但由于通道中的缓冲区已满而无法写入时,都会断言此事件 |
| event_data_in_channel_halt | out | 当IP核需要来自数据输入通道的数据但没有可用数据时,在每个周期断言此事件。 |
| event_data_out_channel_halt | out | 每当核心需要向Status通道写入数据,但由于通道上的缓冲区已满而无法写入时,都会断言此事件。 |
为保证OFDM符号的连续性,IFFT的处理频率不能小于20M,因此,需要对输入数据进行提频处理,IFFT处理完成后,再对输出作降频处理。在这里采样异步FIFO处理。
IFFT处理结构如下图所示:
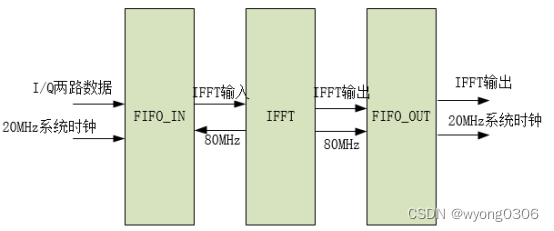
需要注意的是FIFO_IN输出的数据为8bits的I/Q两路数据,而FFT输入数据是I/Q两路数据经过放大8倍处理的结果。即对I/Q两路数据左移3位,再以高位填充符号位,低位补零形式,扩展为两路16bits数据输入到FFT中;而FFT输出的两路16bits数据直接曲低8bits作为FIFO_OUT输入数据即可。
代码如下:
//FIFO_IN数据读取控制信号,以及IFFT输入数据
always @ (negedge rst_n or posedge clk_80m ) begin
if (!rst_n) begin
rd_falg <= 0;
end
else if( cnt_num>=63 ) begin
rd_falg <= 0;
end
else if( infifo_rd_data_count>=63 ) begin
rd_falg <= 1;
end
end
always @ (negedge rst_n or posedge clk_80m ) begin
if (!rst_n) begin
infifo_rd_en <= 0;
cnt_num <= 0;
last_flag <= 0;
end
else if( cnt_num>=64 ) begin
infifo_rd_en <= 0;
last_flag <= 0;
cnt_num <= 0;
end
else if( rd_falg && fft_s_data_tready && ~infifo_empty ) begin
infifo_rd_en <= 1;
cnt_num <= cnt_num + 1;
if ( cnt_num==63 ) last_flag <= 1;
end
else begin
infifo_rd_en <= 0;
last_flag <= 0;
end
end
always @ (negedge rst_n or posedge clk_80m ) begin
if (!rst_n) begin
fft_s_data_tvalid <= 0;
fft_s_data_tlast <= 0;
end
else if( infifo_rd_en ) begin
fft_s_data_tvalid <= 1;
fft_s_data_tlast <= last_flag;
end
else begin
fft_s_data_tvalid <= 0;
fft_s_data_tlast <= last_flag;
end
end
assign fft_s_data_tdata = { {5{infifo_dout[15]}},infifo_dout[15:8],3'b0 , {5{infifo_dout[7]}},infifo_dout[7:0],3'b0 };
**
**
**
//FIFO_OUT输出数据 Dout_Index为输出样值序号
always @ (negedge rst_n or posedge sys_clk) begin
if (!rst_n) begin
out_flag <= 0;
end
else if( outfifo_rd_en && (out_Index>=63) ) begin
out_flag <= 0;
end
else if( outfifo_rd_data_count>=63 ) begin
out_flag <= 1;
end
end
//out_Index
always @ (negedge rst_n or posedge sys_clk) begin
if (!rst_n) begin
out_Index <= 0;
end
else if( outfifo_rd_en && (out_Index>=63) ) begin
out_Index <= 0;
end
else if( outfifo_rd_en ) begin
out_Index <= out_Index + 1'b1;
end
end
always @ (negedge rst_n or posedge sys_clk) begin
if (!rst_n) begin
Dout_Vld <= 0;
Dout_Index <= 0;
end
else if( outfifo_rd_en ) begin
Dout_Vld <= 1;
Dout_Index <= out_Index;
end
else begin
Dout_Vld <= 0;
Dout_Index <= 0;
end
end
assign outfifo_rd_en = out_flag && ~outfifo_empty ;
assign Dout_Re = outfifo_dout[7:0];
assign Dout_Im = outfifo_dout[15:8];7.循环前缀&加窗
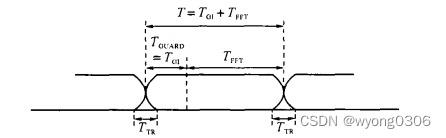
在OFDM系统中,信道间干扰(Inter Channel Interference,ICI)是其应用的主要限制。为了应付ICI和符号间干扰(Inter Symbol Interferene,ISI)。从而引入了循环前缀。循环前缀能够有效的消除多径所造成的ISI与ICI。其方法是在OFDM符号保护间隔内填入循环前缀(cyclic prefix,CP),即将每个OFDM符号的后Tg时间内的样值复制到OFDM符号前面以形成前缀。以保证在FFT周期内OFDM符号的时延副本内包含的波形周期个数也是整数。如下图所示:

添加循环前缀后,需要对数据进行加窗处理。加窗可以使OFDM符号在带宽之外的功率谱密度下降得更快,对OFDM符号加窗就是意味着符号周期边缘的幅度值逐渐过渡到零。通常采用的窗类型为升余弦函数:
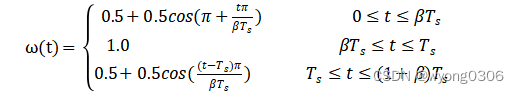
其中为滚降因子,
是加窗前的符号长度,而加窗后的符号长度为(1+
)
。从而允许在相邻符号之间存在有相互重叠的区域。经过加窗处理的OFDM符号如下图所示:
在设计上,为实现流水线模式,采样乒乓缓存模式,使用4个长度为64的RAM,分别存储乒乓缓存A区I/Q两路数据和乒乓缓存B区I/Q两路数据。添加循环前缀的方法急速将每个OFDM符号的后16个数据辅助到前16个数据中,形成一个80个数据的OFDM符号,实现上一个OFDM符号的前48个数据存入RAM,后16个数据一边输出,一边写入RAM,到64个数据输出完成后,再从RAM中按顺序输出64个数据。
加窗输出要求每个OFDM符号多输出一个数据,该数据依然满足周期性要求,为OFDM符号64个样值中的第一个,而下一个符号的第一个数据将和该数据相加再右移1位进行输出。
代码如下:
//输入写入RAM中
assign wen1 = Din_En&&(~Flag_Spam);
assign wen2 = Din_En&&Flag_Spam;
spram_64 spram_Re1(
.rst_n (rst_n ) ,
.clka (clk ) ,
.wea (wen1 ) ,
.addra (Din_Index ) ,
.dina (Din_Re ) ,
.douta ( ) ,
.clkb (clk ) ,
.web (rd_ram_en ) ,
.addrb (rd_ram_addr ) ,
.dinb ( ) ,
.doutb (dout_Re1 )
);
spram_64 spram_Im1(
.rst_n (rst_n ) ,
.clka (clk ) ,
.wea (wen1 ) ,
.addra (Din_Index ) ,
.dina (Din_Im ) ,
.douta ( ) ,
.clkb (clk ) ,
.web (rd_ram_en ) ,
.addrb (rd_ram_addr ) ,
.dinb ( ) ,
.doutb (dout_Im1 )
);
spram_64 spram_Re2(
.rst_n (rst_n ) ,
.clka (clk ) ,
.wea (wen2 ) ,
.addra (Din_Index ) ,
.dina (Din_Re ) ,
.douta ( ) ,
.clkb (clk ) ,
.web (rd_ram_en ) ,
.addrb (rd_ram_addr ) ,
.dinb ( ) ,
.doutb (dout_Re2 )
);
spram_64 spram_Im2(
.rst_n (rst_n ) ,
.clka (clk ) ,
.wea (wen2 ) ,
.addra (Din_Index ) ,
.dina (Din_Im ) ,
.douta ( ) ,
.clkb (clk ) ,
.web (rd_ram_en ) ,
.addrb (rd_ram_addr ) ,
.dinb ( ) ,
.doutb (dout_Im2 )
);
**
**
**
//缓存第一个样值
always@(posedge clk or negedge rst_n ) begin
if(!rst_n) begin
First_Re1 <= 0;
First_Im1 <= 0;
First_Re2 <= 0;
First_Im2 <= 0;
end
else if( Din_Index==0 ) begin
case(Flag_Spam)
0:begin
First_Re1 <= Din_Re;
First_Im1 <= Din_Im;
end
1:begin
First_Re2 <= Din_Re;
First_Im2 <= Din_Im;
end
endcase
end
end
**
**
**
//读取数据
always@(posedge clk or negedge rst_n ) begin
if(!rst_n) begin
Dout_Re <= 0;
Dout_Im <= 0;
Dout_Vld <= 0;
end
else if( Din_Index == 48 ) begin
Dout_Vld <= 1;
case(Flag_Spam) //
0:begin
Dout_Re <= (First_Re2 + Din_Re)>>1; //下一个OFDM第一个样值与上一个OFDM第一个样值相加再除2
Dout_Im <= (First_Im2 + Din_Im)>>1; //下一个OFDM第一个样值与上一个OFDM第一个样值相加再除2
end
1:begin
Dout_Re <= (First_Re1 + Din_Re)>>1;
Dout_Im <= (First_Im1 + Din_Im)>>1;
end
endcase
end
else if( Din_Index>48 ) begin
Dout_Re <= Din_Re;
Dout_Im <= Din_Im;
Dout_Vld <= 1;
end
else if( rd_ram_en ) begin
Dout_Vld <= 1;
case(Flag_Spam)//注意读出数据ram顺序
0:begin
Dout_Re <= dout_Re2;
Dout_Im <= dout_Im2;
end
1:begin
Dout_Re <= dout_Re1;
Dout_Im <= dout_Im1;
end
endcase
end
else begin
Dout_Vld <= 1'b0;
end
end8.训练序列生成
PLCP的前导部分由一组重复10次的短训练序列和一组加了一个长型保护间隔与重复2次的有效OFDM符号组成的长训练序列组成。短训练序列主要用于接收机的AGC控制、信道选择以及接收信号的捕获、定时和粗同步;长训练序列主要用于信道估计和精准的频偏校正。长、短训练序列的长度均为8us,短训练序列符号长度为800ns;长训练序列的有效OFDM长度为3.2us,长训练序列的长型保护间隔长度为1.6us,即为有效OFDM长度的最后1.6us。短训练序列传输的为接收机已知的12个经过QPSK调制后乘以功率因子()的固定值,其中12个数据对应的子载波间隔为正常OFDM符号的四倍;长训练序列的有效OFDM符号传输的是经过BPSK调制后再乘以归一化系数经过IFFT变换后的52个数据。
训练序列生成模块主要是提前将长、短序列的时域样值计算出并存入RAM中,需要时直接读取数据即可。由于Data域数据在IFFT处理之前会扩大8倍,相应的长训练序列在进行IFFT处理之前也需要扩大8倍。同时长、短训练序列也是需要经过加窗处理的,即多输出一个样值,该值为第一个样值,同时将第一个样值与最后一个样值缩小一倍。
短序列时域样值为:
| 地址 | Re | Im | 地址 | Re | Im |
| 0 | 8'b00001100 | 8'b00001100 | 8 | 8'b00001100 | 8'b00001100 |
| 1 | 8'b11011110 | 8'b00000001 | 9 | 8'b00000001 | 8'b11011110 |
| 2 | 8'b11111101 | 8'b11101100 | 10 | 8'b11101100 | 8'b11111101 |
| 3 | 8'b00100100 | 8'b11111101 | 11 | 8'b11111101 | 8'b00100100 |
| 4 | 8'b00011000 | 8'b00000000 | 12 | 8'b00000000 | 8'b00011000 |
| 5 | 8'b00100100 | 8'b11111101 | 13 | 8'b11111101 | 8'b00100100 |
| 6 | 8'b11111101 | 8'b11101100 | 14 | 8'b11101100 | 8'b11111101 |
| 7 | 8'b11011110 | 8'b00000001 | 15 | 8'b00000001 | 8'b11011110 |
长序列时域样值为:
| 地址 | Re | Im | 地址 | Re | Im |
| 0 | 8'b00101000 | 8'b00000000 | 32 | 8'b11011000 | 8'b00000000 |
| 1 | 8'b11111111 | 8'b11100001 | 33 | 8'b00000011 | 8'b11100111 |
| 2 | 8'b00001010 | 8'b11100100 | 34 | 8'b00010111 | 8'b11100101 |
| 3 | 8'b00011001 | 8'b00010101 | 35 | 8'b11101000 | 8'b11100011 |
| 4 | 8'b00000101 | 8'b00000111 | 36 | 8'b11111111 | 8'b11110010 |
| 5 | 8'b00001111 | 8'b11101010 | 37 | 8'b00010011 | 8'b00010011 |
| 6 | 8'b11100011 | 8'b11110010 | 38 | 8'b11011111 | 8'b00000101 |
| 7 | 8'b11110110 | 8'b11100101 | 39 | 8'b11100001 | 8'b00000100 |
| 8 | 8'b00011001 | 8'b11111001 | 40 | 8'b11110111 | 8'b00100111 |
| 9 | 8'b00001110 | 8'b00000001 | 41 | 8'b11110010 | 8'b00000110 |
| 10 | 8'b00000000 | 8'b11100011 | 42 | 8'b11110001 | 8'b11101011 |
| 11 | 8'b11011101 | 8'b11110100 | 43 | 8'b00010010 | 8'b11111100 |
| 12 | 8'b00000110 | 8'b11110001 | 44 | 8'b00010101 | 8'b11101000 |
| 13 | 8'b00001111 | 8'b11111100 | 45 | 8'b11011110 | 8'b11101111 |
| 14 | 8'b11111010 | 8'b00101001 | 46 | 8'b11110001 | 8'b11110110 |
| 15 | 8'b00011111 | 8'b11111111 | 47 | 8'b00001001 | 8'b11100111 |
| 16 | 8'b00010000 | 8'b11110000 | 48 | 8'b00010000 | 8'b00010000 |
| 17 | 8'b00001001 | 8'b00011001 | 49 | 8'b00011111 | 8'b00000001 |
| 18 | 8'b11110001 | 8'b00001010 | 50 | 8'b11111010 | 8'b11010111 |
| 19 | 8'b11011110 | 8'b00010001 | 51 | 8'b00001111 | 8'b00000100 |
| 20 | 8'b00010101 | 8'b00011000 | 52 | 8'b00000110 | 8'b00001111 |
| 21 | 8'b00010010 | 8'b00000100 | 53 | 8'b11011101 | 8'b00001100 |
| 22 | 8'b11110001 | 8'b00010101 | 54 | 8'b00000000 | 8'b00011101 |
| 23 | 8'b11110010 | 8'b11111010 | 55 | 8'b00001110 | 8'b11111111 |
| 24 | 8'b11110111 | 8'b11011001 | 56 | 8'b00011001 | 8'b00000111 |
| 25 | 8'b11100001 | 8'b11111100 | 57 | 8'b11110110 | 8'b00011011 |
| 26 | 8'b11011111 | 8'b11111011 | 58 | 8'b11100011 | 8'b00001110 |
| 27 | 8'b00010011 | 8'b11101101 | 59 | 8'b00001111 | 8'b00010110 |
| 28 | 8'b11111111 | 8'b00001110 | 60 | 8'b00000101 | 8'b11111001 |
| 29 | 8'b11101000 | 8'b00011101 | 61 | 8'b00011001 | 8'b11101011 |
| 30 | 8'b00010111 | 8'b00011011 | 62 | 8'b00001010 | 8'b00011100 |
| 31 | 8'b00000011 | 8'b00011001 | 63 | 8'b11111111 | 8'b00011111 |
代码如下:
//短序列输出逻辑
else if( STS_Req && (STS_Index<161) ) begin
STS_Index <= STS_Index + 1;
STS_Vld <= 1'b1;
if(i<10) begin
if(j==15) begin
j <= 0;
i <= i+ 1;
STS_Re <= Short_Mem[j][15:8];
STS_Im <= Short_Mem[j][7:0];
end
else begin
if(i==0 && j==0) begin
STS_Re <= Short_Mem[j][15:8]>>1; //加窗,左移一
STS_Im <= Short_Mem[j][7:0]>>1;//注意:Short_Mem【0】为正数
end
else begin
STS_Re <= Short_Mem[j][15:8];
STS_Im <= Short_Mem[j][7:0];
end
j <= j + 1;
end
end
else begin //最后一位
STS_Re <= Short_Mem[0][15:8]>>1; //加窗,左移一 第一个值
STS_Im <= Short_Mem[0][7:0]>>1;
STS_Done <= 1'b1;
end
end
**
**
**
//长序列输出逻辑
else if( LTS_Req && (LTS_Index<161) ) begin
LTS_Index <= LTS_Index + 1;
LTS_Vld <= 1'b1;
if(i==0) begin
if(j==31) begin
j <= 0;
i <= i+ 1;
LTS_Re <= Long_Mem[j+32][15:8];
LTS_Im <= Long_Mem[j+32][7:0];
end
else begin
if(i==0 && j==0) begin
LTS_Re <= 8'b11101100; //短训练序列到长训练序列的窗口函数
LTS_Im <= Long_Mem[j+32][7:0];
end
else begin
LTS_Re <= Long_Mem[j+32][15:8];
LTS_Im <= Long_Mem[j+32][7:0];
end
j <= j + 1;
end
end
else if( i==1 || i==2 ) begin
if(j==63) begin
j <= 0;
i <= i+ 1;
LTS_Re <= Long_Mem[j][15:8];
LTS_Im <= Long_Mem[j][7:0];
end
else begin
LTS_Re <= Long_Mem[j][15:8];
LTS_Im <= Long_Mem[j][7:0];
j <= j + 1;
end
end
else begin // 加窗处理
LTS_Re <= Long_Mem[0][15:8]>>1; //加窗,左移一位
LTS_Im <= Long_Mem[0][7:0]>>1;
LTS_Done <= 1'b1;
end
end 9.发射主控MCU
主控模块控制与协调处理各个子模块的工作,以保证整个发射系统时序正确,同时还与MAC层交互,向MAC层请求数据等。最终的OFDM符号存在严格的时序要求,训练序列后紧跟Signal域和Data域,Data域OFDM符号之间不能存在空闲时序。因此,主控模块要并串转换MAC端数据,并同步序列训练符号、Signal域符号和Data域符号。并串夸时域转换同样采样异步FIFO完成。
在7.5MHz时钟域下:一、同步MAC端数据发射请求,并解析数据长度、发射Rate参数以及功率等级等信息,并设置到各个模块中;二、同步来自60MHz时钟域下的MAC数据请求,并向MAC端请求数据作为异步FIFO输入缓存,一个OFDM符号为18字节数据,在这里通过一个5比特计数器完成计数。注意的是MAC端请求发射的PSDU长度、service域和Tail Bits位所有字节数应为18字节的倍数。三、全局初始化各个模块。
在60MHz时钟域下:一、控制Signal符号和数据符号生成开始时刻,完成训练符号与Signal符号和Data符号无缝衔接;二、通过两个计数器完成单个OFDM符号时钟周期计数以及OFDM符号长度计数;三、一个Data符号生成之前,向7.5MHz时钟域发送MAC数据请求,并在Data符号开始时向异步FIFO读取数据;四、完成Signal符号数据与Data符号数据不同格式的生成以及相应标志信号生成。
在20MHz时钟域下,主要为同步数据起始信号,驱动序列训练生成。
需要注意的是在调制之前Signal域数据只有24比特,而Data域数据为144比特,而且Signal符号调制方式为BPSK,而Data符号调制方式为16-QAM,因此在主控模块对Signal域比特流的输出有效应保持6个时钟周期间隔,与Data域数据频率保持一致。
发射主控模块结构图为:
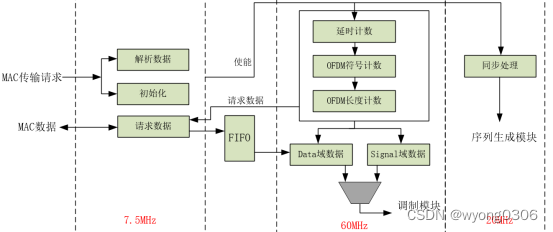
代码如下:
//7.5M时钟域下 //对ofdM基带发射机系统 清除处理并复位到初始状态 always@(posedge mac_clk or negedge rst_n ) begin if(!rst_n) begin Tx_Clr <= 0; end else if( Txstart_Req || Txstart_Req1 ) begin Tx_Clr <= 1'b1; end else begin Tx_Clr <= 0; end end //接收MAC发射请求 always@(posedge mac_clk or negedge rst_n ) begin if(!rst_n) begin Byte_Length <= 0; Rate <= 0; Rate_Con <= 0; TxPWR <= 0; Scram_Seed <= 0; end else if( Txstart_Req ||Txstart_Req1 ) begin Byte_Length <= Tx_Param[20:9]; Rate <= Tx_Param[8:3]; TxPWR <= Tx_Param[2:0]; Scram_Seed <= 7'b1011101; case(Tx_Param[8:3]) 6'd6 : Rate_Con <= 4'b1101 ; 6'd9 : Rate_Con <= 4'b1111 ; 6'd12: Rate_Con <= 4'b0101 ; 6'd18: Rate_Con <= 4'b0111 ; 6'd24: Rate_Con <= 4'b1001 ; 6'd36: Rate_Con <= 4'b1011 ; 6'd48: Rate_Con <= 4'b0010 ; 6'd54: Rate_Con <= 4'b0011 ; default: Rate_Con <= 4'b0000; endcase end end //向MAC请求18字节数据 always@(posedge mac_clk or negedge rst_n ) begin if(!rst_n) begin Din_Req <= 0; end else if ( End_Req_Byte_Cnt ) begin Din_Req <= 1'b0; // end else if ( ~MAC_Data_Req1 && OFDM_Byte_Req) begin Din_Req <= 1'b1; // end end //Req_Byte_Cnt always@(posedge mac_clk or negedge rst_n ) begin if(!rst_n) begin Req_Byte_Cnt <= 0; end else if( End_Req_Byte_Cnt ) begin Req_Byte_Cnt <= 0; end else if( Add_Req_Byte_Cnt ) begin Req_Byte_Cnt <= Req_Byte_Cnt + 1'b1; // end end assign Add_Req_Byte_Cnt = Din_Req || (~MAC_Data_Req1 && OFDM_Byte_Req) ; assign End_Req_Byte_Cnt = Add_Req_Byte_Cnt && (Req_Byte_Cnt== OFDM_SYMBOL_BYTES-1); ** ** ** //60M时钟域下 //控制序列符号与Signal符号和Data符号时序对齐 always@(posedge clk_60m or negedge rst_n ) begin if(!rst_n) begin Symbol_Delay_Time <= 0; end else if( Symbol_Delay_Time >= DATA_SYMBO_WAIT_TIME ) begin Symbol_Delay_Time <= 0; end else if( Txstart_Req_wait && ~Txstart_Req1 ) begin Symbol_Delay_Time <= 1; end else if ( Symbol_Delay_Time>0 ) begin Symbol_Delay_Time <= Symbol_Delay_Time + 1'b1; end end //一个OFDM符号的时钟周期计数 always@(posedge clk_60m or negedge rst_n ) begin if(!rst_n) begin Symbol_Period <= 0; end else if( End_Symbol_Period ) begin Symbol_Period <= 0; end else if( Add_Symbol_Period ) begin Symbol_Period <= Symbol_Period + 1'b1; // end end assign Add_Symbol_Period = OFDM_Runing; assign End_Symbol_Period = Add_Symbol_Period && (Symbol_Period==SYMBOL_PERIOD_TIME-1); //OFDM符号数计数 always@(posedge clk_60m or negedge rst_n ) begin if(!rst_n) begin OFDM_Symbol_Cnt <= 0; end else if( End_OFDM_Symbol_Cnt ) begin OFDM_Symbol_Cnt <= 0; end else if( Add_OFDM_Symbol_Cnt ) begin OFDM_Symbol_Cnt <= OFDM_Symbol_Cnt + 1'b1; end end assign Add_OFDM_Symbol_Cnt = OFDM_Runing && End_Symbol_Period; assign End_OFDM_Symbol_Cnt = Add_OFDM_Symbol_Cnt && (OFDM_Symbol_Cnt == OFDM_Symbol_Cnt_Max); ** ** ** //20M时钟域下,序列使能 //Train_Start_En always@(posedge clk_20m or negedge rst_n ) begin if(!rst_n) begin Train_Start_En <= 0; end else if( Train_Runing1 && ~Txstart_Req1 ) begin Train_Start_En <= 1'b1; end else begin Train_Start_En <= 0; end end
四.仿真
1.modelsim仿真

2.ILA在线测试结果

附录
代码链接:
https://download.csdn.net/download/wyong0306/88398162
总结
本文主要介绍了OFDM基带处理发射机的实现,接收机的部分等后续完成了再传。由于时间的关系,还要很多详细的地方没有讲到,有兴趣的同学推荐阅读《基于Xilinx FPGA的OFDM通信系统基带设计》,如果对本文有什么不懂的地方欢迎欢迎大家提问,当然文中描述不当的也欢迎大家指点。谢谢!