Linux进程间通信
- 一、进程间通信介绍
- 1、概念
- 2、进程间通信目的
- 3、进程间通信的本质
- 4、进程间通信分类
- 二、管道
- 1、什么是管道
- 2、匿名管道
- (1)匿名管道原理
- (2)pipe函数
- (3)匿名管道的使用步骤
- i、父进程调用pipe函数创建管道
- ii、父进程创建子进程(此时子进程和父进程一样与管道进行读写)
- iii、父进程关闭写端,子进程关闭读端
- iv、注意点
- (4)站在文件描述符的角度再来看看这三个步骤
- i、父进程调用pipe函数创建管道
- ii、父进程创建子进程
- iii、父进程关闭写端,子进程关闭读端
- (4)代码解释匿名管道
- 3、管道读写规则
- 4、管道的特点
- (1)管道内部自带同步与互斥机制
- (2)管道的生命周期随进程
- (3)管道提供的是流式服务
- (4)管道是半双工通信的
- 5、管道的四种特殊情况
- 6、管道的大小
- (1)方法1:使用man手册
- (2)方法2:使用ulimit -a命令
- (3)方法3:子进程一直写,父进程不读
- 三、命名管道
- 1、命名管道的原理
- 2、利用mkfifo创建一个命名管道
- 3、在程序中创建命名管道
- (1)第一个参数filename
- (2)第二个参数mode
- (3)返回值
- 4、命名管道的打开规则
- 5、用命名管道实现serve&client通信
- (1)服务端和客户端之间的退出关系
- (2)通信是在内存当中进行的
- (3)用命名管道实现派发计算任务
- (4)用命名管道实现进程遥控
- (5)用命名管道实现文件拷贝
- i、使用管道实现文件的拷贝有什么意义
- 5、匿名管道和命名管道的区别
- 6、命令行当中的管道
- 四、system V进程间通信
- 1、system V共享内存
- (1)共享内存的基本原理
- (2)共享内存数据结构
- (3)共享内存的建立与释放
- i、共享内存的建立
- (i)传入shmget函数的第一个参数key,需要我们使用ftok函数进行获取
- (ii)传入shmget函数的第三个参数shmflg,常用的组合方式有以下两种
- (iv)利用ftok和shaget写一块共享内存
- ii、共享内存的释放
- (i)使用命令释放共享内存
- (ii)在进程通信完毕后调用释放共享内存的函数进行释放
- (4)共享内存的关联
- (5)共享内存的去关联
- (6)用共享内存实现serve和client通信
- i、测试是否挂起成功
- ii、客户端不断从共享内存中写入数据,服务端不断从共享内存读取数据
- (7)共享内存与管道进行对比
- i、通信管道
- ii、共享内存通信
- iii、总结
- 2、System V消息队列
- (1)消息队列的基本原理
- 总结
- (2)消息队列数据结构
- (3)消息队列的创建
- (4)消息队列的释放
- (5)向消息队列发送数据
- (6)从消息队列获取数据
- 3、System V信号量
- (1)信号量相关概念
- (2)信号量数据结构
- (3)信号量相关函数
- i、信号量集的创建
- ii、信号量集的删除
- iii、信号量集的操作
- 五、进程互斥
- 六、system V IPC联系
一、进程间通信介绍
1、概念
进程间通信简称IPC(Interprocess communication),进程间通信就是在不同进程之间传播或交换信息。
2、进程间通信目的
- 数据传输:一个进程需要将它的数据发送给另一个进程。
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
3、进程间通信的本质
本质是:让不同的进程看到同一份资源。
由于因为进程间之间具有独立性,这个独立性主要体现在数据层面,而代码逻辑层面可以私有也可以公有(例如父子进程),因此各个进程之间要实现通信是非常困难的。
各个进程之间若想实现通信,一定要借助第三方资源,这些进程就可以通过向这个第三方资源写入或是读取数据,进而实现进程之间的通信,这个第三方资源实际上就是操作系统提供的一段内存区域。

因此,进程间通信的本质就是,让不同的进程看到同一份资源(内存,文件内核缓冲等)。 由于这份资源可以由操作系统中的不同模块提供,因此出现了不同的进程间通信方式。
4、进程间通信分类
管道
- 匿名管道pipe
- 命名管道
System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
二、管道
1、什么是管道
管道是Unix中最古老的进程间通信的形式。我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”
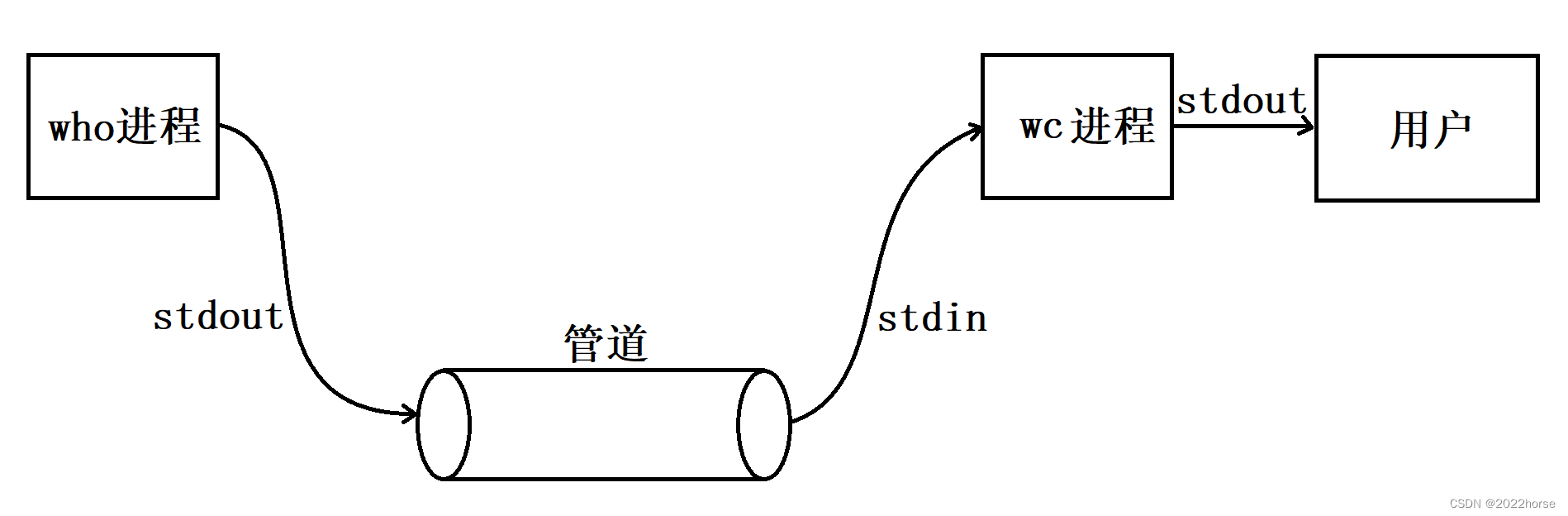
我们可以用who | wc -l的命令看当前使用云服务器上的登录用户个数。
who命令用于查看当前云服务器的登录用户(一行显示一个用户),wc -l用于统计当前的行数。
who和wc这两个命令都是程序,当它们运行起来的时候,就是两个进程,who这个进程通过标准输出流进入到管道中,wc进程再通过标准输入流对管道内数据进行读入,最后再通过标准输出流给用户。
2、匿名管道
(1)匿名管道原理
匿名管道的本质就是进行本地父子进程之间的通信,也就是让不同的进程看到同一份资源,使用匿名管道实现父子进程间通信的原理就是,让两个父子进程先看到同一份被打开的文件资源,然后父子进程就可以对该文件进行写入或是读取操作,进而实现父子进程间通信。
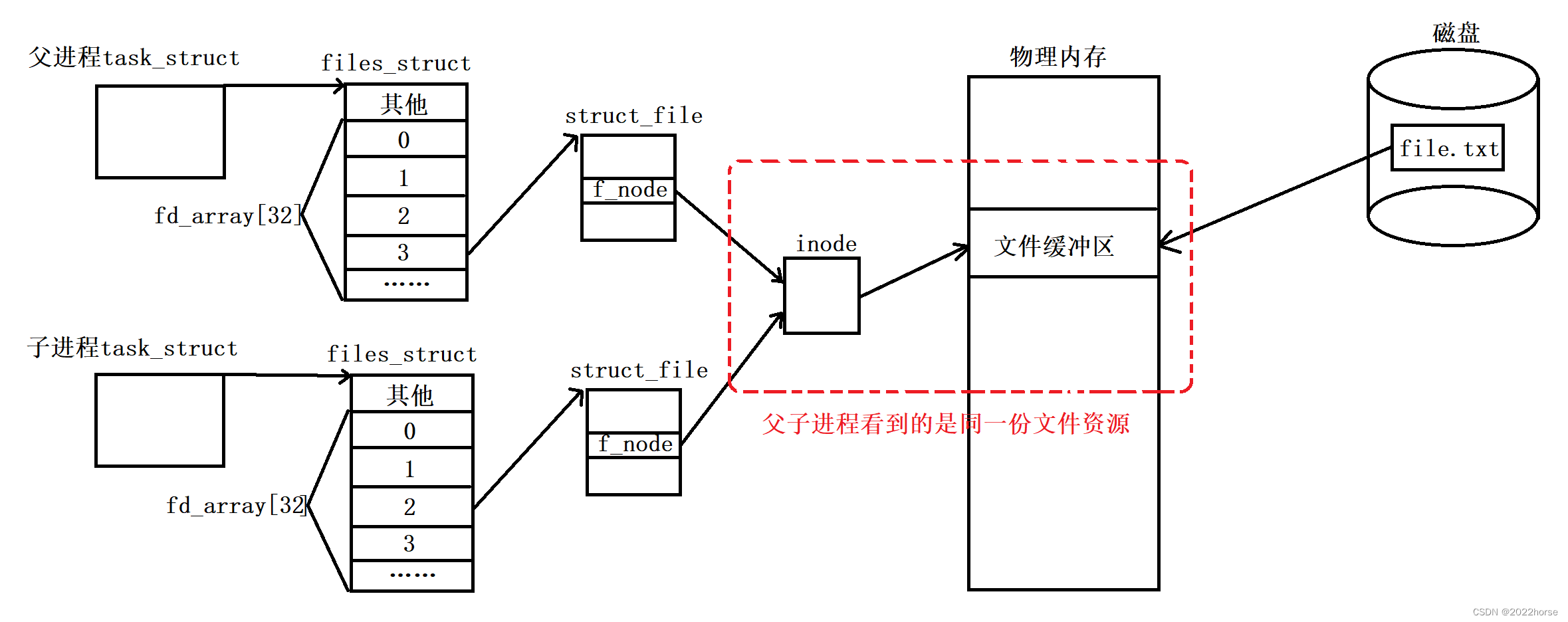
我们需要注意的点在于:
- 这里父子进程看到的同一份文件资源是由操作系统来维护的,所以当父子进程对该文件进行写入操作时,该文件缓冲区当中的数据并不会进行写时拷贝。
- 管道虽然用的是文件的方案,但操作系统一定不会把进程进行通信的数据刷新到磁盘当中,因为这样做有IO参与会降低效率,而且也没有必要。也就是说,这种文件是一批不会把数据写到磁盘当中的文件,换句话说,磁盘文件和内存文件不一定是一一对应的,有些文件只会在内存当中存在,而不会在磁盘当中存在。
(2)pipe函数
- 功能:创建一个匿名管道。
- 函数原型:int pipe(int fd[2]);
- fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端
- 返回值:成功返回0,失败返回错误代码
(3)匿名管道的使用步骤
匿名管道的使用需要使用pipe和fork两个函数的配合。
i、父进程调用pipe函数创建管道
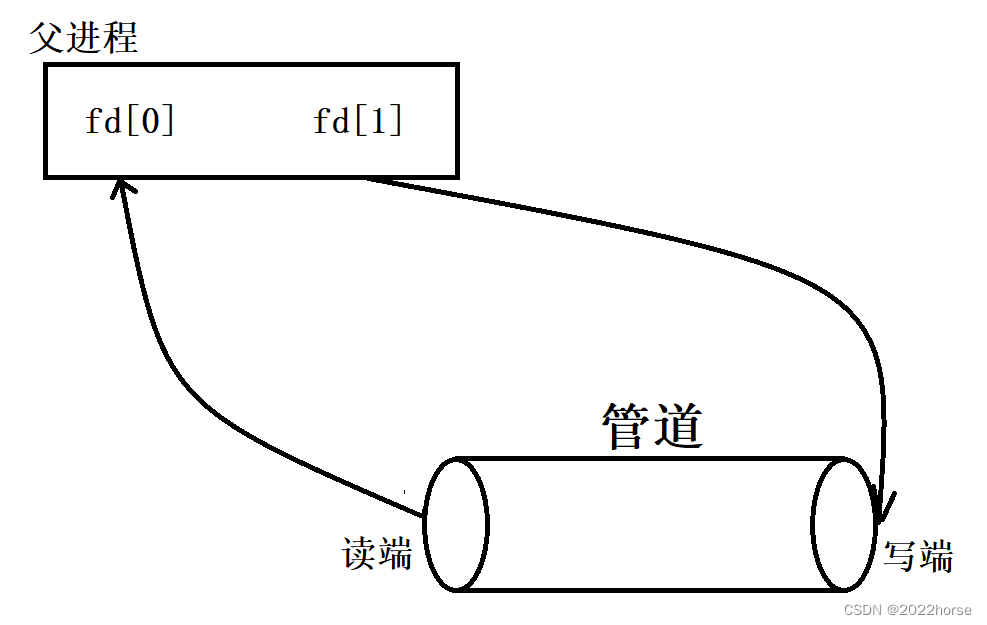
ii、父进程创建子进程(此时子进程和父进程一样与管道进行读写)
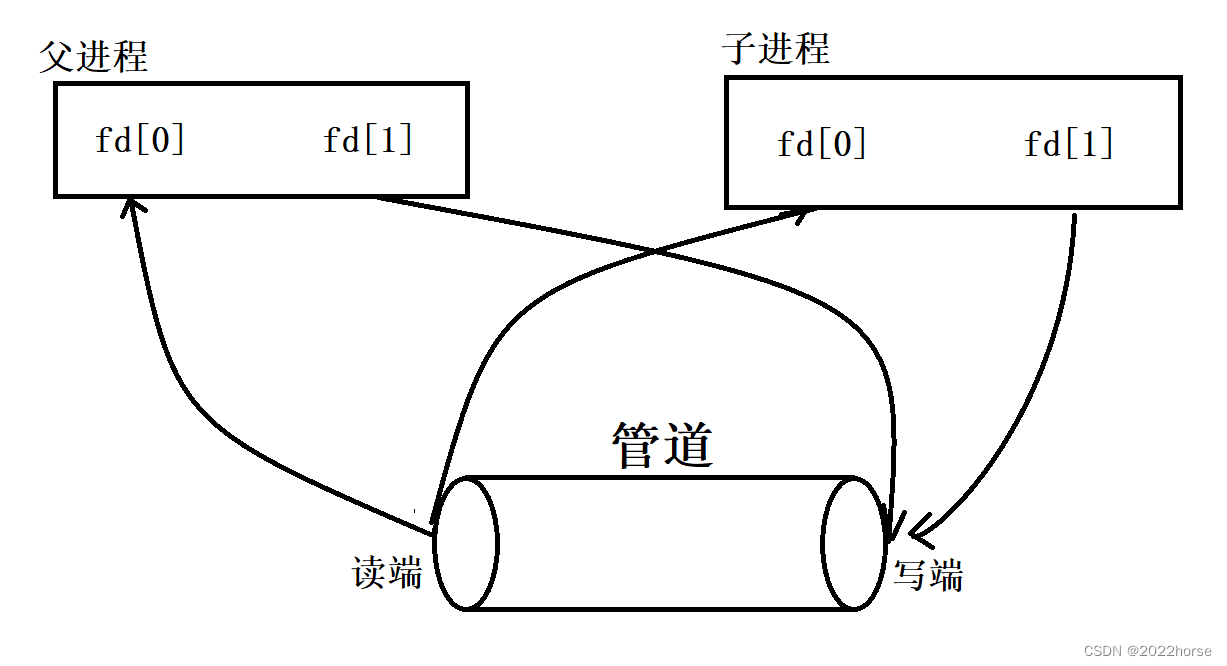
iii、父进程关闭写端,子进程关闭读端
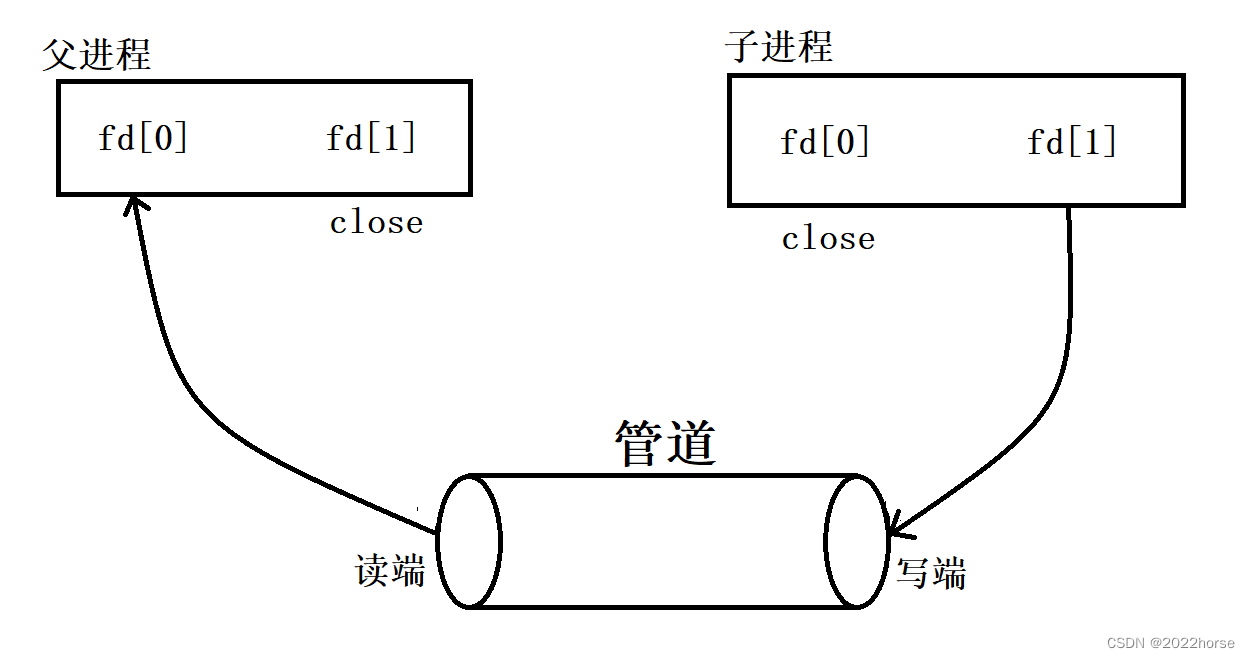
iv、注意点
- 管道只能够进行单向通信,因此当父进程创建完子进程后,需要确认父子进程谁读谁写,然后关闭相应的读写端。
- 从管道写端写入的数据会被内核缓冲,直到从管道的读端被读取。
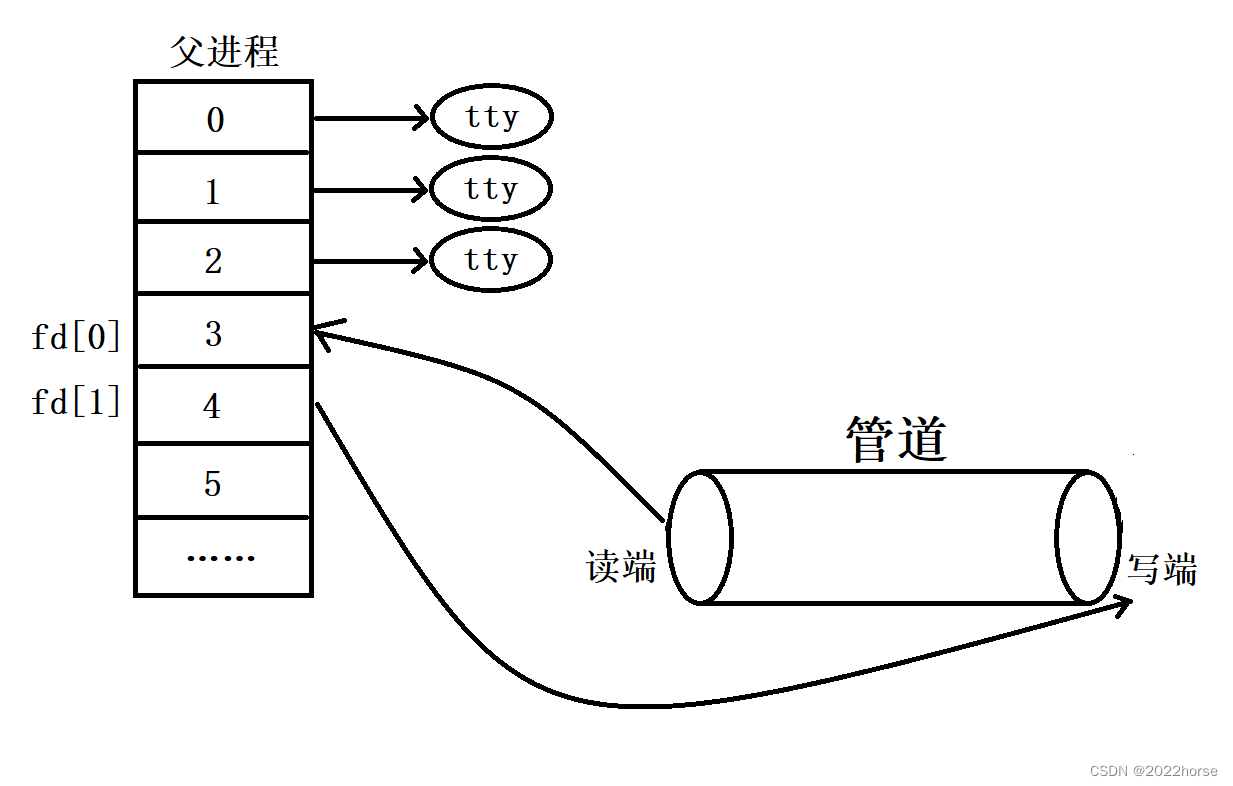
(4)站在文件描述符的角度再来看看这三个步骤
i、父进程调用pipe函数创建管道
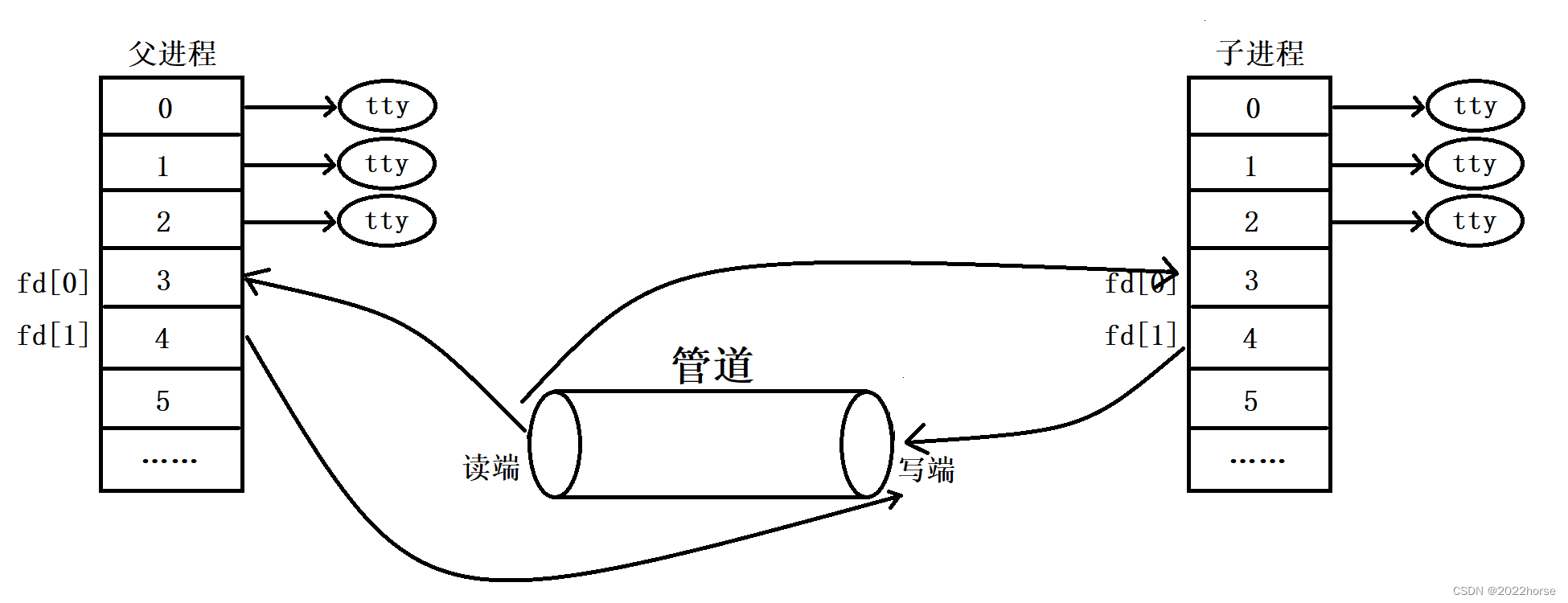
ii、父进程创建子进程
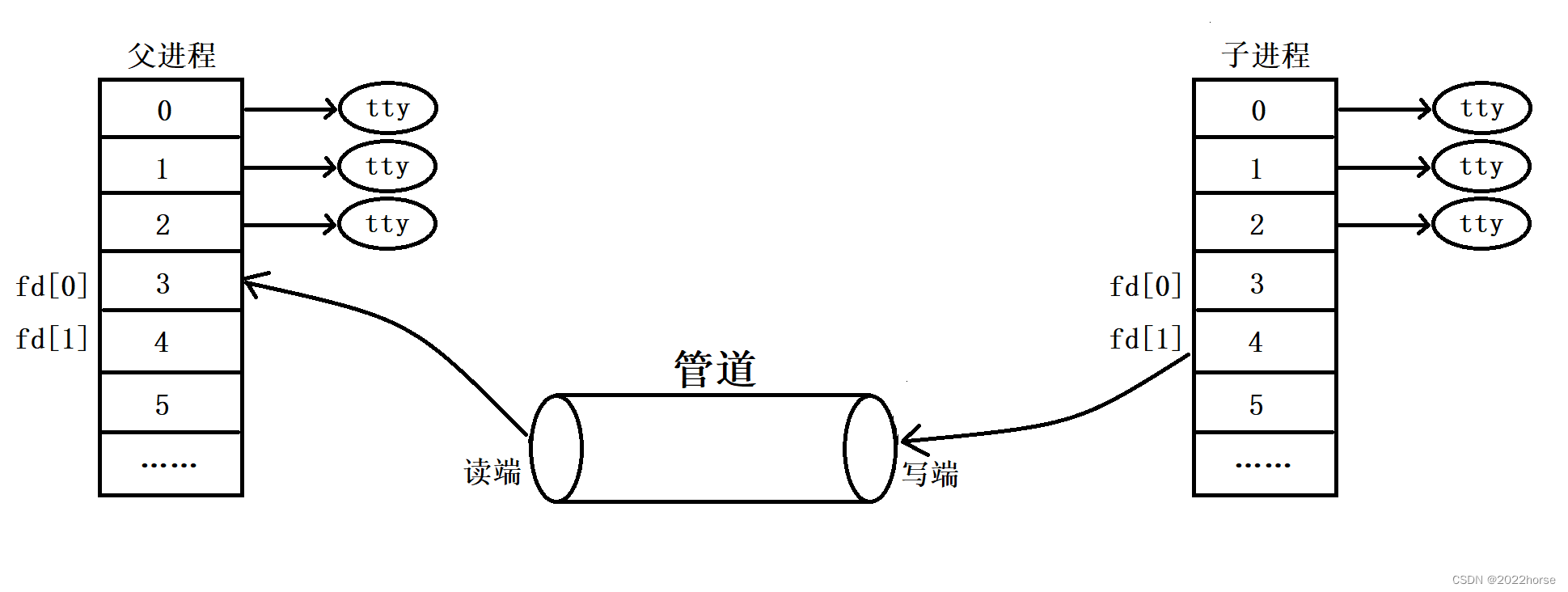
iii、父进程关闭写端,子进程关闭读端
(4)代码解释匿名管道
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#define Ssize 64
// child->write father->read
int main()
{
int fd[2] = { 0 }; // 定一下fd文件描述符
if(pipe(fd) < 0)
{
// 调用失败
perror("pepe failed\n");
return 1;
}
// 创建子进程
pid_t id = fork();
if(id < 0)
{
// 创建失败
perror("fork failed\n");
return 1;
}
else if(id == 0)
{
// child
close(fd[0]); // 关闭读端
// 向管道写入数据
const char* msg = "hello my father, I am your child...";
for(int i = 0; i < 10; i++)
{
write(fd[1], msg, strlen(msg));
sleep(1);
}
close(fd[1]); // 关闭文件
exit(0);
}
// father
close(fd[1]); // 关闭写端
char buff[Ssize]; // 文件缓冲区
while(1)
{
ssize_t s = read(fd[0], buff, sizeof(buff)); // 读数据
if(s == 0)
{
// 读结束
printf("father read end\n");
break;
}
else if(s > 0)
{
// 开始输出给显示器
buff[s] = '\0';
printf("child send msg to father, is:%s\n", buff);
}
else
{
// 读错误
perror("read failed\n");
break;
}
}
close(fd[0]); //父进程读取完毕,关闭文件
waitpid(id, NULL, 0);
return 0;
}
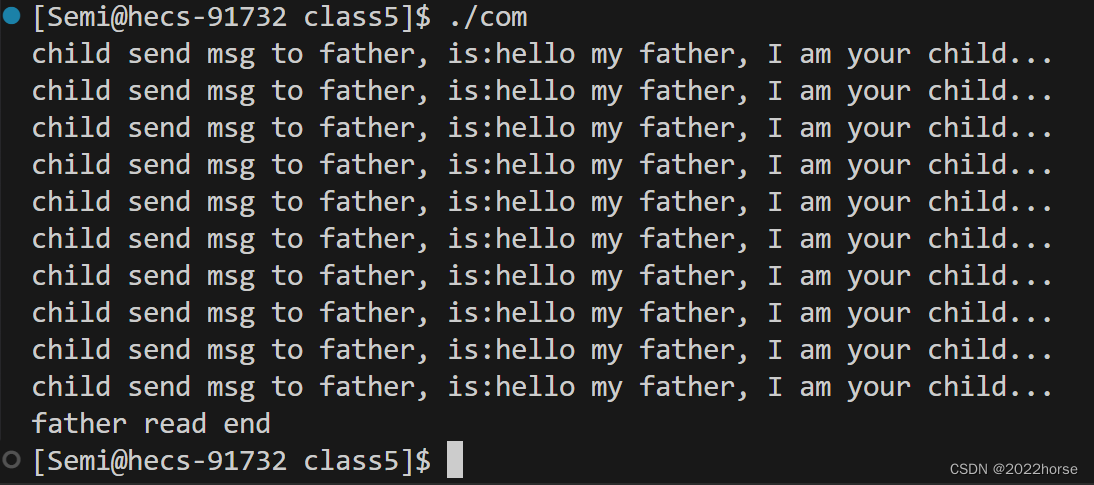
3、管道读写规则
pipe2函数与pipe函数类似,也是用于创建匿名管道,其函数原型如下:
int pipe2(int pipefd[2], int flags);
pipe2函数的第二个参数用于设置选项。
当没有数据可读时
- O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止。
- O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
当管道满的时候
- O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
- O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
如果所有管道写端对应的文件描述符被关闭,则read返回0
如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
4、管道的特点
(1)管道内部自带同步与互斥机制
我们先来介绍一下临界资源:
我们将一次只允许一个进程使用的资源,称为临界资源。管道在同一时刻只允许一个进程对其进行写入或是读取操作,因此管道也就是一种临界资源。
临界资源是需要被保护的,若是我们不对管道这种临界资源进行任何保护机制,那么就可能出现同一时刻有多个进程对同一管道进行操作的情况,进而导致同时读写、交叉读写以及读取到的数据不一致等问题。
- 同步的概念:两个或两个以上的进程在运行过程中协同步调,按预定的先后次序运行。比如,A任务的运行依赖于B任务产生的数据。
- 互斥的概念: 一个公共资源同一时刻只能被一个进程使用,多个进程不能同时使用公共资源。
实际上,同步是一种更为复杂的互斥,而互斥是一种特殊的同步。对于管道的场景来说,互斥就是两个进程不可以同时对管道进行操作,它们会相互排斥,必须等一个进程操作完毕,另一个才能操作,而同步也是指这两个不能同时对管道进行操作,但这两个进程必须要按照某种次序来对管道进行操作。
也就是说,互斥具有唯一性和排它性,但互斥并不限制任务的运行顺序,而同步的任务之间则有明确的顺序关系。
(2)管道的生命周期随进程
管道的本质是通过文件进行通信的,也就是说管道依赖于文件系统,那么当所有打开该文件的进程都退出后,该文件也就会被释放掉,所以说管道的生命周期随进程。
(3)管道提供的是流式服务
当进程1将数据写到管道中后,进程2将数据拿出的时候是随机拿取的,拿多少取多少是不固定的,这种被称为流式服务。
(4)管道是半双工通信的
在数据通信中,数据在线路上的传送方式可以分为以下三种:
- 单工通信(Simplex Communication):单工模式的数据传输是单向的。通信双方中,一方固定为发送端,另一方固定为接收端。
- 半双工通信(Half Duplex):半双工数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。
- 全双工通信(Full Duplex):全双工通信允许数据在两个方向上同时传输,它的能力相当于两个单工通信方式的结合。全双工可以同时(瞬时)进行信号的双向传输。
管道是半双工的,数据只能向一个方向流动,需要双方通信时,需要建立起两个管道。
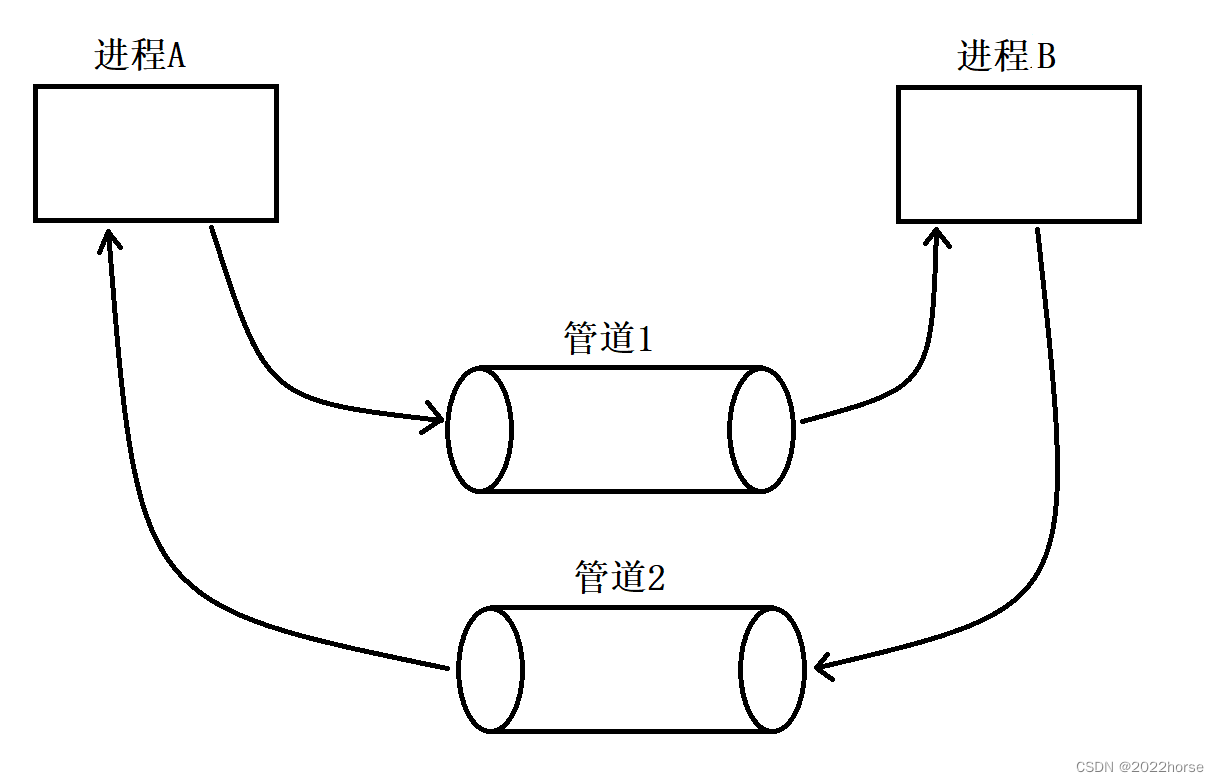
5、管道的四种特殊情况
- 写端进程不写,读端进程一直读,那么此时会因为管道里面没有数据可读,对应的读端进程会被挂起,直到管道里面有数据后,读端进程才会被唤醒。
- 读端进程不读,写端进程一直写,那么当管道被写满后,对应的写端进程会被挂起,直到管道当中的数据被读端进程读取后,写端进程才会被唤醒。
- 写端进程将数据写完后将写端关闭,那么读端进程将管道当中的数据读完后,就会继续执行该进程之后的代码逻辑,而不会被挂起。
- 读端进程将读端关闭,而写端进程还在一直向管道写入数据,那么操作系统会将写端进程杀掉。
前面两种情况就能够很好的说明,管道是自带同步与互斥机制的,读端进程和写端进程是有一个步调协调的过程的,不会说当管道没有数据了读端还在读取,而当管道已经满了写端还在写入。读端进程读取数据的条件是管道里面有数据,写端进程写入数据的条件是管道当中还有空间,若是条件不满足,则相应的进程就会被挂起,直到条件满足后才会被再次唤醒。
第三种情况也很好理解,读端进程已经将管道当中的所有数据都读取出来了,而且此后也不会有写端再进行写入了,那么此时读端进程也就可以执行该进程的其他逻辑了,而不会被挂起。
第四种情况也不难理解,既然管道当中的数据已经没有进程会读取了,那么写端进程的写入将没有意义,因此操作系统直接将写端进程杀掉。而此时子进程代码都还没跑完就被终止了,属于异常退出,那么子进程必然收到了某种信号。
下面的代码反应了第四种情况,我们想看一下子进程收到了什么信号。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#define Ssize 64
// child->write father->read
int main()
{
int fd[2] = { 0 }; // 定一下fd文件描述符
if(pipe(fd) < 0)
{
// 调用失败
perror("pepe failed\n");
return 1;
}
// 创建子进程
pid_t id = fork();
if(id < 0)
{
// 创建失败
perror("fork failed\n");
return 1;
}
else if(id == 0)
{
// child
close(fd[0]); // 关闭读端
// 向管道写入数据
const char* msg = "hello my father, I am your child...";
for(int i = 0; i < 10; i++)
{
write(fd[1], msg, strlen(msg));
sleep(1);
}
close(fd[1]); // 关闭文件
exit(0);
}
// father
close(fd[1]); // 关闭写端
close(fd[0]); // 父进程关闭读端,导致子进程直接被系统杀死
int status = 0;
waitpid(id, &status, 0);
printf("child get signal:%d\n", status & 0x7F); //打印子进程收到的信号
return 0;
}

13信号是什么呢?我们kill -l看一下吧:
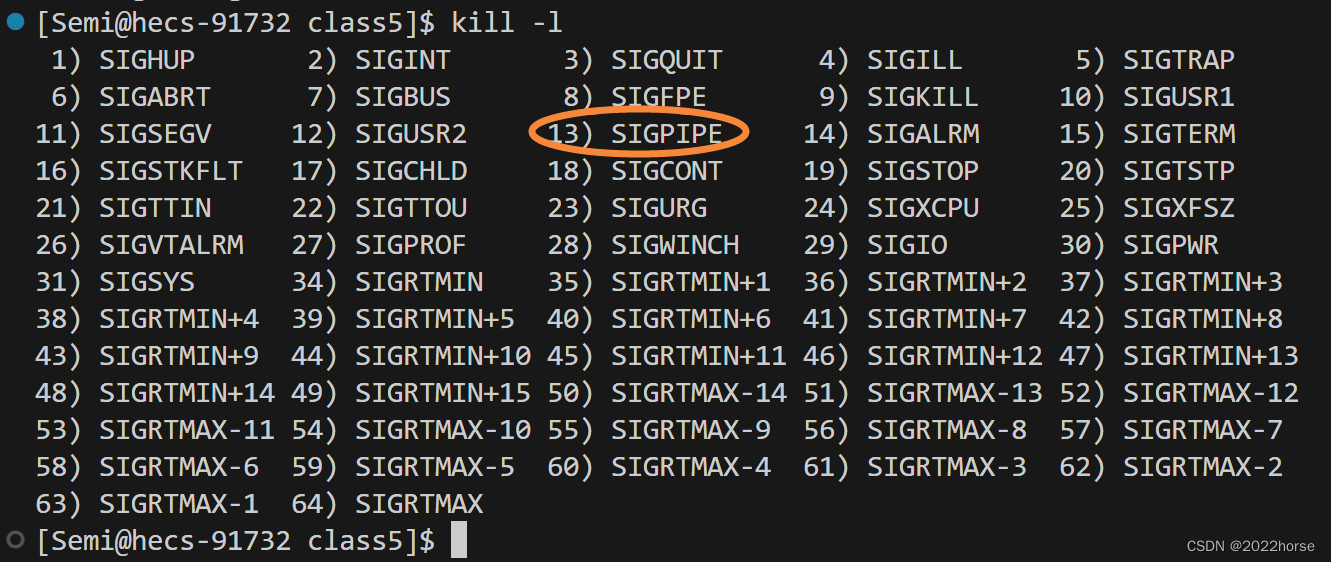
操作系统向子进程发送SIGPIPE信号将子进程停止。
6、管道的大小
我们从上面的管道特点肯定能够看出管道是有大小的,如果管道已满,那么写端将阻塞或失败,那么管道的最大容量是多少呢?
(1)方法1:使用man手册


2.6.11版本往后的linux中,其管道最大容量都是65536bytes。
(2)方法2:使用ulimit -a命令
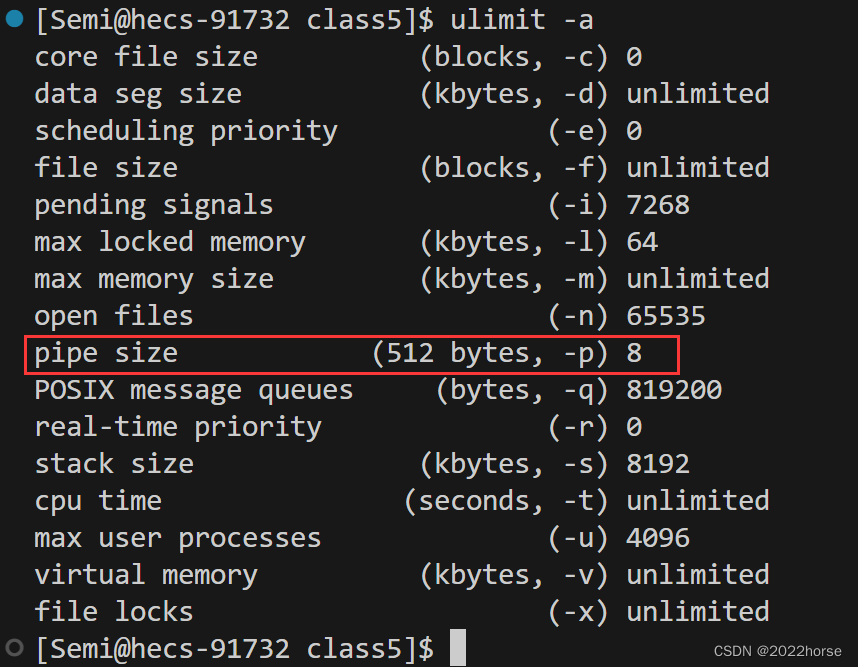
管道最大的容量为512*8bytes = 4096bytes。
(3)方法3:子进程一直写,父进程不读
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
int fd[2] = { 0 };
if(pipe(fd) < 0)
{
perror("pipe failed\n");
return 1;
}
pid_t id = fork();
if(id < 0)
{
perror("fork failed\n");
exit(0);
}
else if(id == 0)
{
// child
close(fd[0]); // 关闭读端
char a = 'c';
int count = 0;
while(1) // child一直写
{
write(fd[1], &a, 1);
count++;
printf("count = %d\n", count);
}
close(fd[1]);
exit(0);
}
// father
close(fd[1]); // 关闭写端
// 不读
waitpid(id, NULL, 0);
close(fd[0]);
return 0;
}

我们发现到65536的时候就被挂起了,说明就是管道最大容量就是65536了。
三、命名管道
1、命名管道的原理
匿名管道只能用于具有共同祖先的进程(具有亲缘关系的进程)之间的通信,通常,一个管道由一个进程创建,然后该进程调用fork,此后父子进程之间就可应用该管道。
如果要实现两个毫不相关进程之间的通信,可以使用命名管道来做到。命名管道就是一种特殊类型的文件,两个进程通过命名管道的文件名打开同一个管道文件,此时这两个进程也就看到了同一份资源,进而就可以进行通信了。
- 普通文件是很难做到通信的,即便做到通信也无法解决一些安全问题。
- 命名管道和匿名管道一样,都是内存文件,只不过命名管道在磁盘有一个简单的映像,但这个映像的大小永远为0,因为命名管道和匿名管道都不会将通信数据刷新到磁盘当中。
2、利用mkfifo创建一个命名管道
[Semi@hecs-91732 fifo]$ mkfifo fifo
使用mkfifo命令创建一个命名管道。
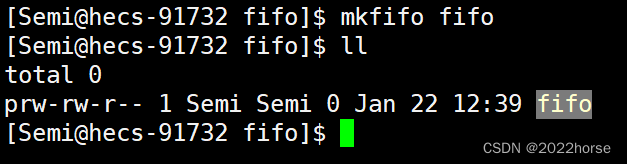
创建出来的文件的类型是p,代表该文件是命名管道文件。
使用这个命名管道文件,就能实现两个进程之间的通信了。我们在一个进程(进程1)中用shell脚本每秒向命名管道写入一个字符串,在另一个进程(进程2)当中用cat命令从命名管道当中进行读取。
现象就是当进程1启动后,进程2会每秒从命名管道中读取一个字符串打印到显示器上。这就证明了这两个毫不相关的进程可以通过命名管道进行数据传输,即通信。
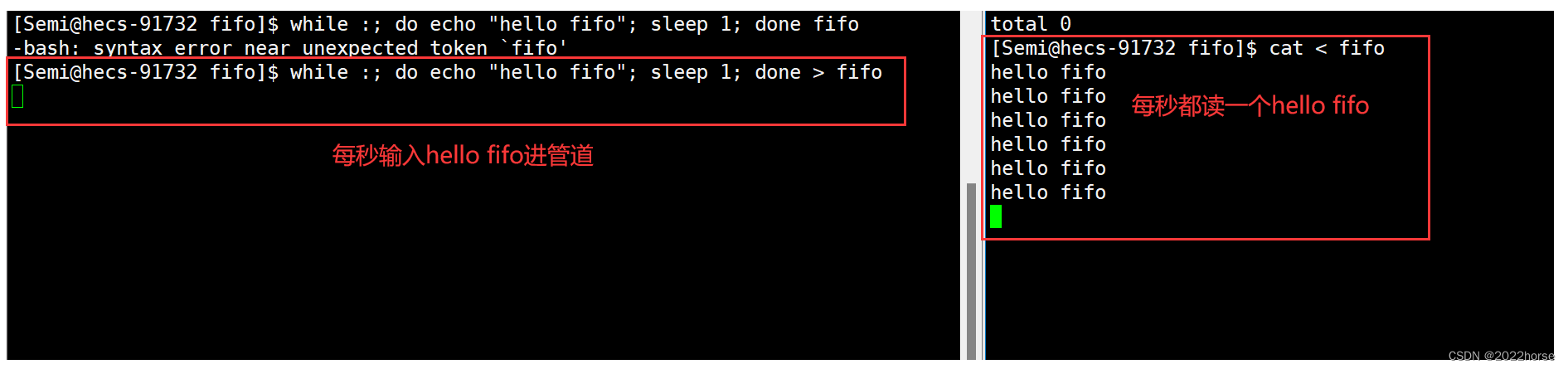
当管道的读端进程退出后,写端进程再向管道写入数据就没有意义了,此时写端进程会被操作系统杀掉,在这里就可以很好的得到验证:当我们终止掉读端进程后,因为写端执行的循环脚本是由命令行解释器bash执行的,所以此时bash就会被操作系统杀掉,我们的云服务器也就退出了。
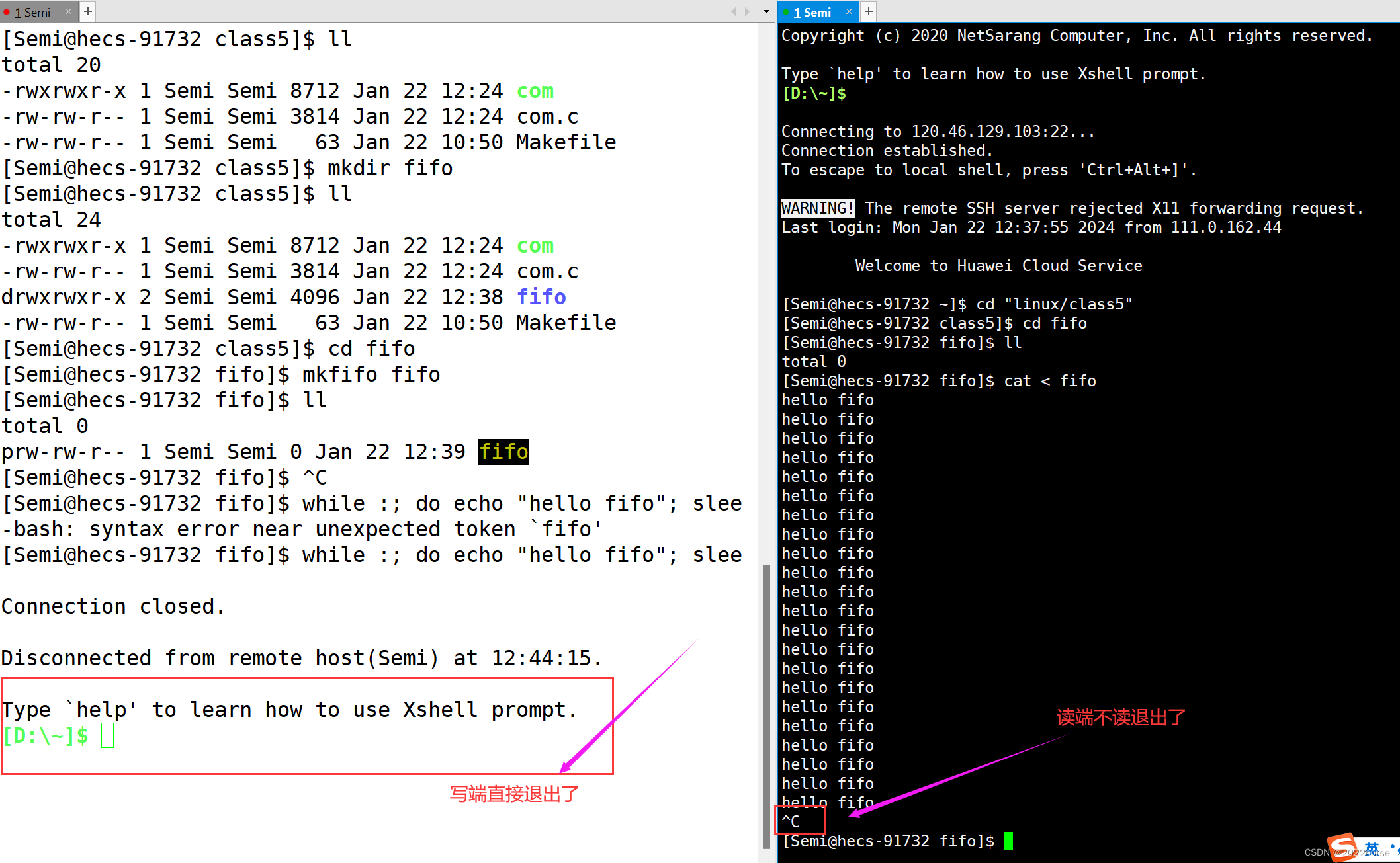
3、在程序中创建命名管道
在程序中创建命名管道使用mkfifo函数,mkfifo函数的函数原型如下:
int mkfifo(const char *filename,mode_t mode);
(1)第一个参数filename
第一个参数是filename,示要创建的命名管道文件。
注意点:
- 若filename用的是路径,那么则将命名管道文件创建在pathname路径下。
- 若filename用的是文件名,那么将命名管道文件创建在当前路径下。
(2)第二个参数mode
mode就是权限的意思,我们一般是0666,而当然内部是有掩码也就是我们常用的umask,我们提前将umask设置成0,再进行mode权限设置成0666即可。
(3)返回值
- 命名管道创建成功,返回0。
- 命名管道创建失败,返回-1。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
umask(0); // 掩码设置成0
// 使用mkfifo创建命名管道文件
if (mkfifo(FILE_NAME, 0666) < 0)
{
perror("mkfifo");
return 1;
}
// 创建成功
// ...
return 0;
}
4、命名管道的打开规则
如果当前打开操作是为读而打开FIFO时。
- O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO。
- O_NONBLOCK enable:立刻返回成功。
如果当前打开操作是为写而打开FIFO时。
- O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO。
- O_NONBLOCK enable:立刻返回失败,错误码为ENXIO。
5、用命名管道实现serve&client通信
我们创建两个源文件,一个是serve.c,另一个是client.c,即服务端和客户端,服务端是用来创建管道的,并且其进行读取功能,而客户端是用来写入管道数据的。所以我们先将服务端跑起来,因为它执行的是创建管道和只读功能,进而再让客户端跑起来进行键盘输入。
serve.c
// 读取
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_SIZE 128
#define FILE_NAME "myfifo"
int main()
{
umask(0);
if(mkfifo(FILE_NAME, 0666) < 0) // 创建管道
{
perror("mkfifo failed\n");
return 1;
}
int fd = open(FILE_NAME, O_RDONLY); // 以只读方式打开,因为这个源文件只读取
if(fd < 0)
{
perror("open failed\n");
return 2;
}
char msg[FILE_SIZE]; // 来个数组用来存取
while(1)
{
// 每次读之前将msg内清空
msg[0] = '\0';
// 从命名管道中读取信息
ssize_t s = read(fd, msg, sizeof(msg) - 1);
if(s < 0)
{
perror("read failed\n");
break;
}
else if(s == 0)
{
printf("read quit\n");
break;
}
else
{
// 成功
msg[s] = '\0'; // 分割
printf("client# %s\n", msg);
}
}
close(fd); // 管道文件关闭
return 0;
}
由于管道已经被创建了,所以在客户端只需要进行打开相对应的管道进行只写的操作即可。
client.c
// 写入
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_SIZE 128
#define FILE_NAME "myfifo"
int main()
{
int fd = open(FILE_NAME, O_WRONLY); // 以只写方式打开
if(fd < 0)
{
perror("open failed\n");
return 1;
}
char msg[FILE_SIZE]; // 创建一个数组用来存储
while(1)
{
msg[0] = '\0'; // 每次读之前将内部清零
printf("Please Enter# "); // 提示客户端输入
fflush(stdout); // 刷新缓冲区
// 从0这个标准输入流中读取
ssize_t s = read(0, msg, sizeof(msg) - 1);
if(s < 0)
{
perror("read failed\n");
break;
}
else if(s == 0)
{
printf("read quit\n");
break;
}
else
{
// 写入操作
msg[s - 1] = '\0'; // 将最后用\0隔开提取字符
write(fd, msg, strlen(msg)); // 写入操作
}
}
close(fd);
return 0;
}
代码编写完毕后,先将服务端进程运行起来,之后我们就能在客户端看到这个已经被创建的命名管道文件。

接着再将客户端也运行起来,此时我们从客户端写入的信息被客户端写入到命名管道当中,服务端再从命名管道当中将信息读取出来打印在服务端的显示器上,该现象说明服务端是能够通过命名管道获取到客户端发来的信息的。
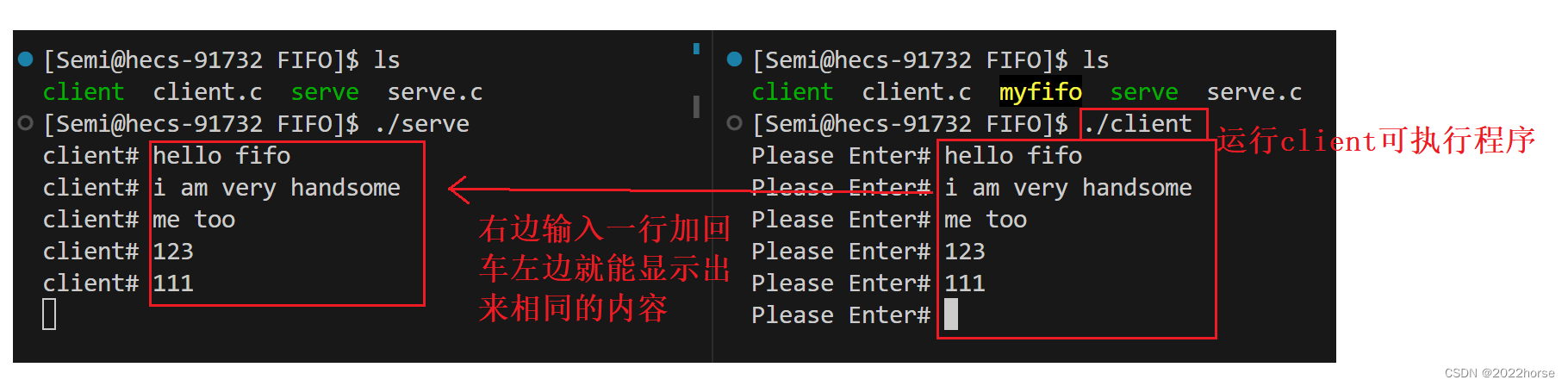
(1)服务端和客户端之间的退出关系
当客户端退出后,服务端将管道当中的数据读完后就再也读不到数据了,那么此时服务端也就会去执行它的其他代码了。
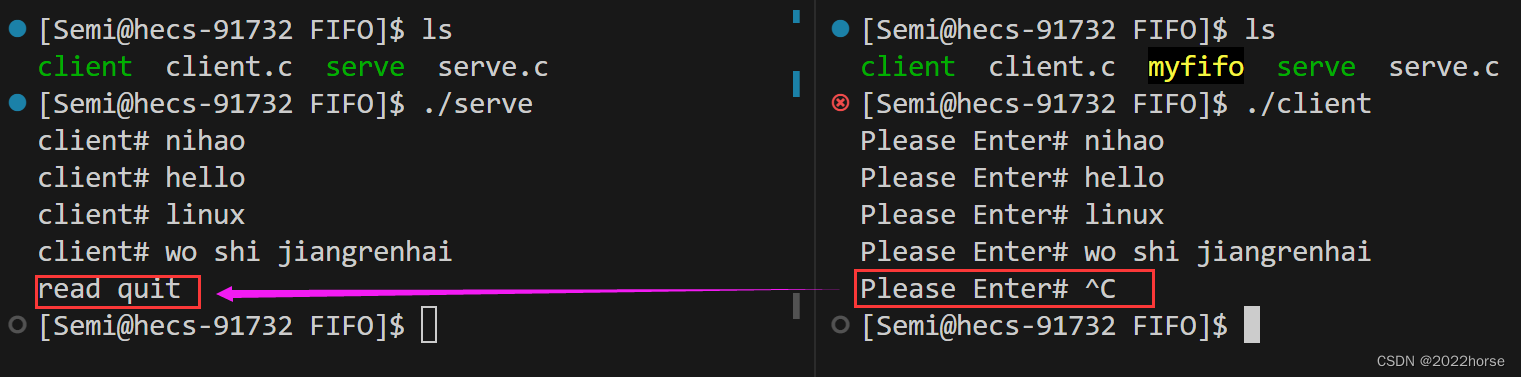
当服务端退出后,客户端写入管道的数据就不会被读取了,也就没有意义了,那么当客户端下一次再向管道写入数据时,就会收到操作系统发来的13号信号(SIGPIPE),此时客户端就被操作系统强制杀掉了。
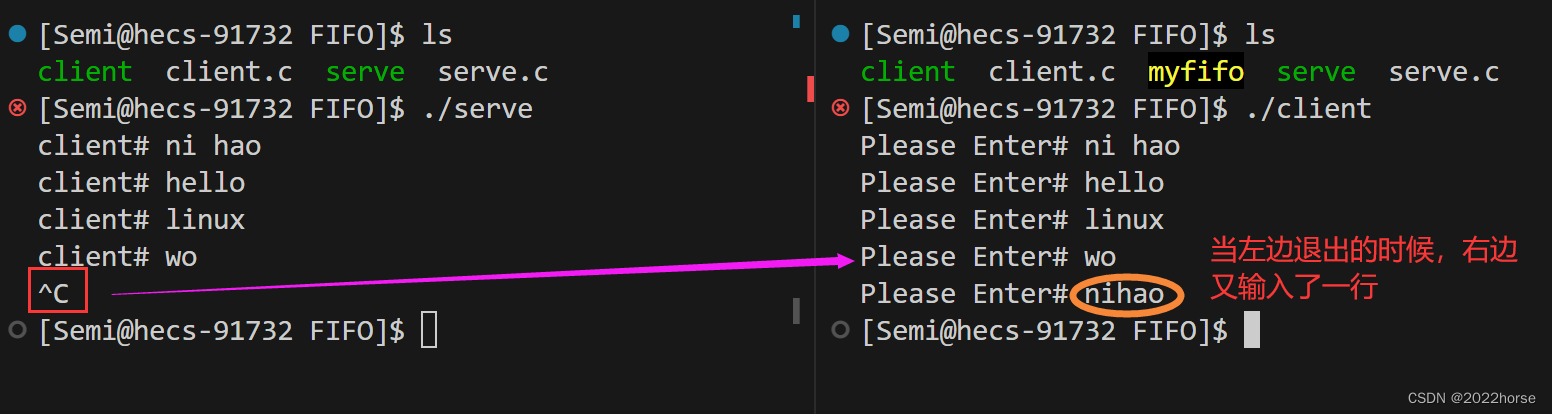
(2)通信是在内存当中进行的
我们只让客户端一直写,而服务端不进行读取,我们看一下myfifo管道文件是否改变:
serve.c
// 读取
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_SIZE 128
#define FILE_NAME "myfifo"
int main()
{
umask(0);
if(mkfifo(FILE_NAME, 0666) < 0) // 创建管道
{
perror("mkfifo failed\n");
return 1;
}
int fd = open(FILE_NAME, O_RDONLY); // 以只读方式打开,因为这个源文件只读取
if(fd < 0)
{
perror("open failed\n");
return 2;
}
char msg[FILE_SIZE]; // 来个数组用来存取
while(1)
{
// 啥事不干
}
close(fd); // 管道文件关闭
return 0;
}
client.c
// 写入
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_SIZE 128
#define FILE_NAME "myfifo"
int main()
{
int fd = open(FILE_NAME, O_WRONLY); // 以只写方式打开
if(fd < 0)
{
perror("open failed\n");
return 1;
}
char msg[FILE_SIZE]; // 创建一个数组用来存储
while(1)
{
msg[0] = '\0'; // 每次读之前将内部清零
printf("Please Enter# "); // 提示客户端输入
fflush(stdout); // 刷新缓冲区
// 从0这个标准输入流中读取
ssize_t s = read(0, msg, sizeof(msg) - 1);
if(s < 0)
{
perror("read failed\n");
break;
}
else if(s == 0)
{
printf("read quit\n");
break;
}
else
{
// 写入操作
msg[s - 1] = '\0'; // 将最后用\0隔开提取字符
write(fd, msg, strlen(msg)); // 写入操作
}
}
close(fd);
return 0;
}
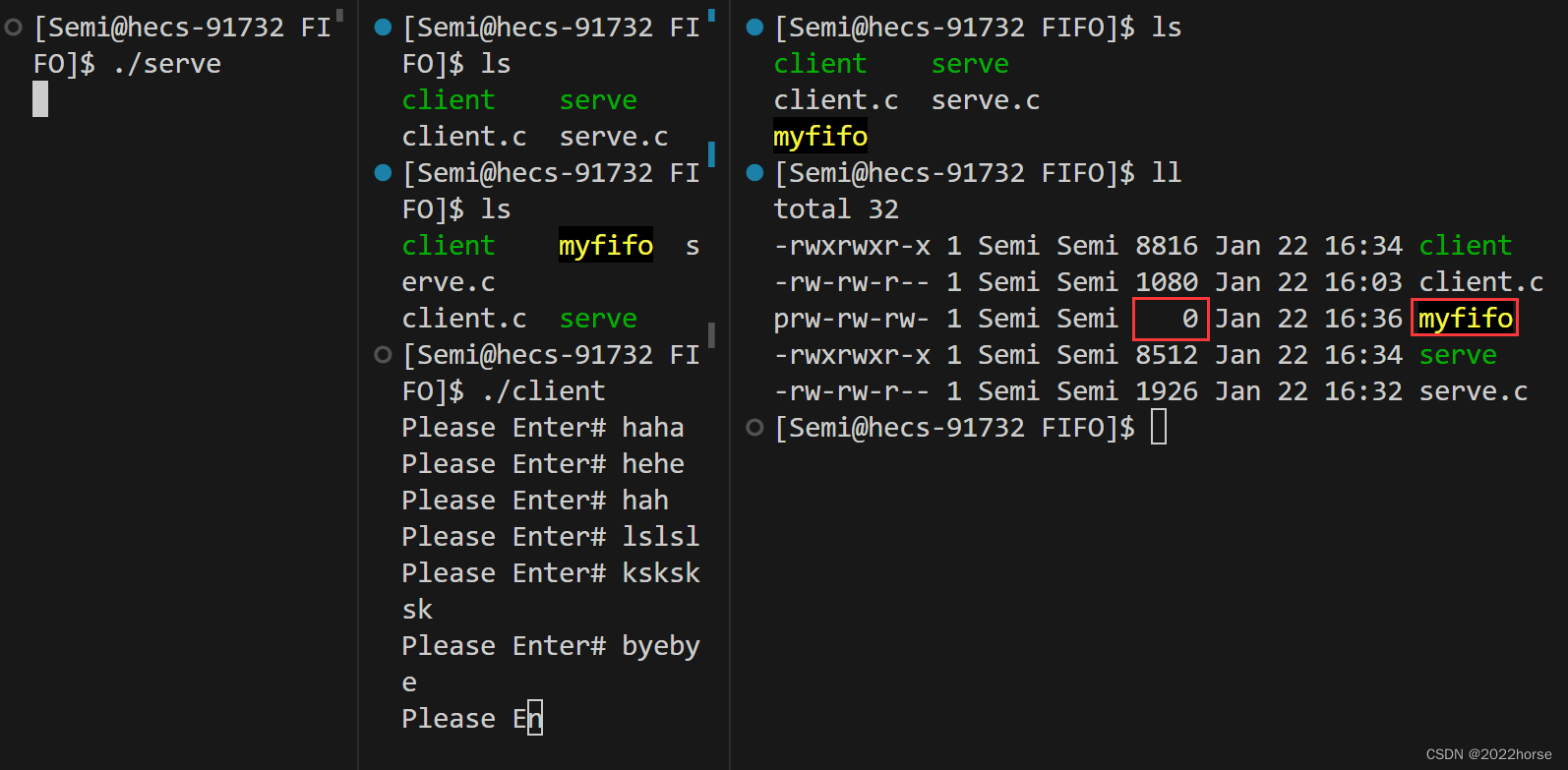
(3)用命名管道实现派发计算任务
两个进程之间的通信,并不是简单的发送字符串而已,服务端是会对客户端发送过来的信息进行某些处理的。
client.c
// 写入
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_SIZE 128
#define FILE_NAME "myfifo"
int main()
{
int fd = open(FILE_NAME, O_WRONLY); // 以只写方式打开
if(fd < 0)
{
perror("open failed\n");
return 1;
}
char msg[FILE_SIZE]; // 创建一个数组用来存储
while(1)
{
msg[0] = '\0'; // 每次读之前将内部清零
printf("Please Enter# "); // 提示客户端输入
fflush(stdout); // 刷新缓冲区
// 从0这个标准输入流中读取
ssize_t s = read(0, msg, sizeof(msg) - 1);
if(s < 0)
{
perror("read failed\n");
break;
}
else if(s == 0)
{
printf("read quit\n");
break;
}
else
{
// 写入操作
msg[s - 1] = '\0'; // 将最后用\0隔开提取字符
write(fd, msg, strlen(msg)); // 写入操作
}
}
close(fd);
return 0;
}
serve.c:
// 读取
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_SIZE 128
#define FILE_NAME "myfifo"
int main()
{
umask(0);
if(mkfifo(FILE_NAME, 0666) < 0) // 创建管道
{
perror("mkfifo failed\n");
return 1;
}
int fd = open(FILE_NAME, O_RDONLY); // 以只读方式打开,因为这个源文件只读取
if(fd < 0)
{
perror("open failed\n");
return 2;
}
char msg[FILE_SIZE]; // 来个数组用来存取
while(1)
{
msg[0] = '\0'; //每次读之前将msg清空
//从命名管道当中读取信息
ssize_t s = read(fd, msg, sizeof(msg) - 1);
if(s > 0)
{
msg[s] = '\0';
printf("client# %s\n", msg);
// 传到服务端进行计算
char* lable = "+-*/%";
char* p = msg;
int flag = 0;
while(*p)
{
switch(*p)
{
case '+':
flag = 0;
break;
case '-':
flag = 1;
break;
case '*':
flag = 2;
break;
case '/':
flag = 3;
break;
case '%':
flag = 4;
break;
}
p++;
}
char* data1 = strtok(msg, "+-*/%"); // 分割第一个
char* data2 = strtok(NULL, "+-*/%"); // 传入的参数为NULL,使得该函数默认使用上一次未分割完的字符串继续分割
int num1 = atoi(data1); // 分解转化成数num1
int num2 = atoi(data2); // 分解转化成数num2
int ret = 0;
switch(flag)
{
case 0:
ret = num1 + num2;
break;
case 1:
ret = num1 - num2;
break;
case 2:
ret = num1 * num2;
break;
case 3:
ret = num1 / num2;
break;
case 4:
ret = num1 % num2;
break;
}
printf("%d %c %d = %d\n", num1, lable[flag], num2, ret); //打印计算结果
}
else if(s == 0)
{
printf("quit\n");
break;
}
else
{
perror("read failed\n");
break;
}
}
close(fd); // 管道文件关闭
return 0;
}
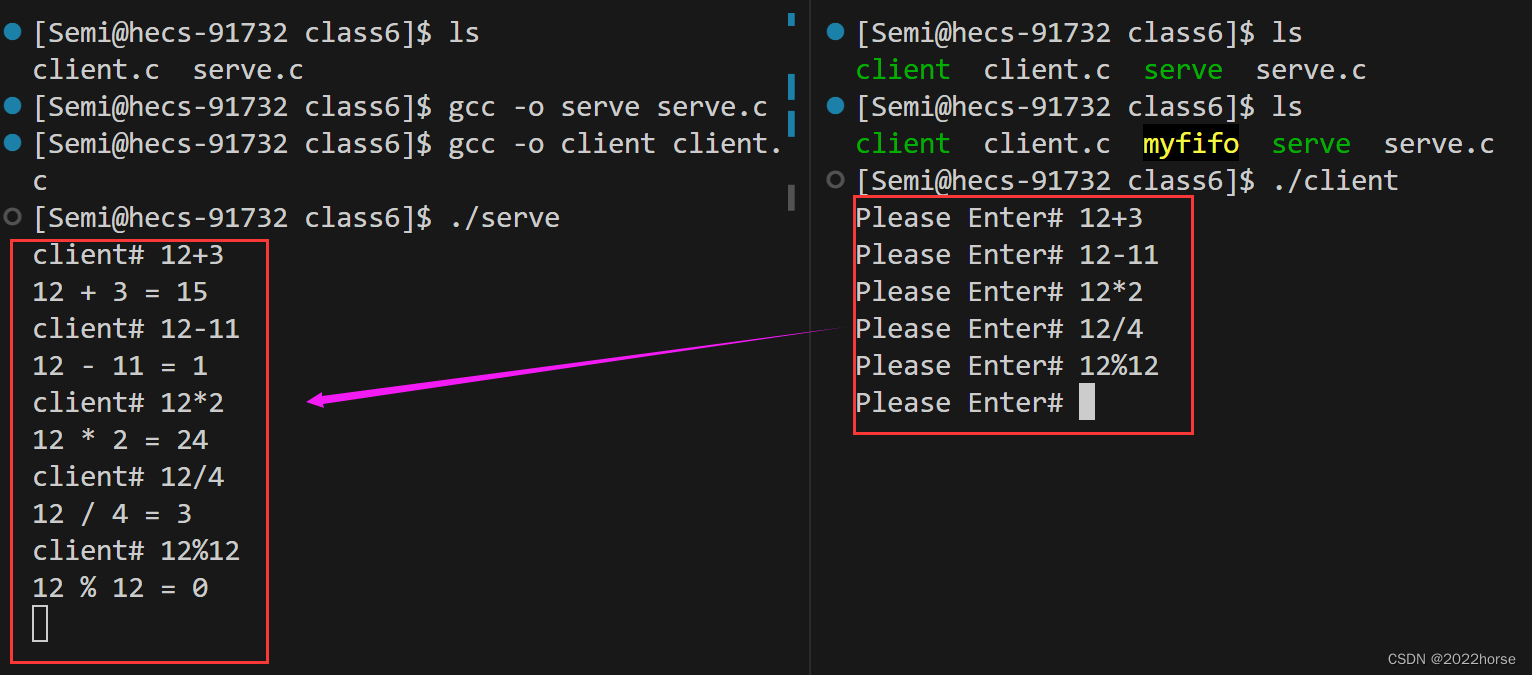
(4)用命名管道实现进程遥控
我们可以通过一个进程1控制进程2的行为,比如我们从客户端输入命令到管道当中,再让服务端将管道当中的命令读取出来并执行。也就是说可以控制进程2的命令行的命令执行,我们只实现不带-的命令行,因为制作-和上面进行程序替换的逻辑差不多,我们只需要更改serve.c中的代码即可,client.c中的代码不需要进行改变。
serve.c:
// 读取
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_SIZE 128
#define FILE_NAME "myfifo"
int main()
{
umask(0);
if(mkfifo(FILE_NAME, 0666) < 0) // 创建管道
{
perror("mkfifo failed\n");
return 1;
}
int fd = open(FILE_NAME, O_RDONLY); // 以只读方式打开,因为这个源文件只读取
if(fd < 0)
{
perror("open failed\n");
return 2;
}
char msg[FILE_SIZE]; // 来个数组用来存取
while(1)
{
msg[0] = '\0'; //每次读之前将msg清空
//从命名管道当中读取信息
ssize_t s = read(fd, msg, sizeof(msg) - 1);
if(s > 0)
{
msg[s] = '\0'; // 手动设置'\0',便于输出
printf("client #%s\n", msg);
pid_t id = fork();
if(id == 0)
{
// child
execlp(msg, msg, NULL);
exit(1);
}
waitpid(-1, NULL, 0); //等待子进程
}
else if(s == 0)
{
printf("quit\n");
break;
}
else
{
perror("read failed\n");
break;
}
}
close(fd); // 管道文件关闭
return 0;
}
服务端接收到客户端的信息后,便进行进程程序替换,进而执行客户端发送过来的命令。
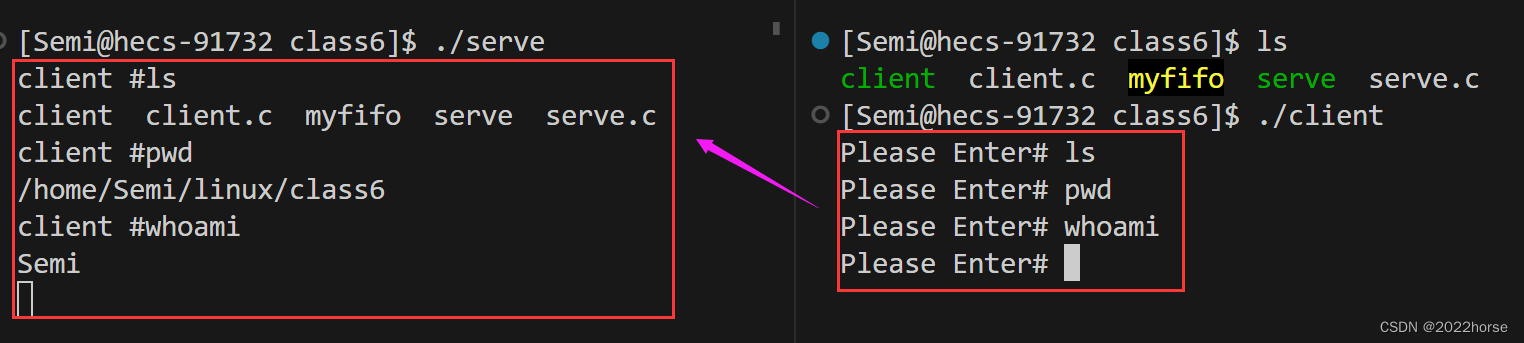
(5)用命名管道实现文件拷贝
让客户端将file.txt文件通过管道发送给服务端,在服务端创建一个file_bat.txt文件,并将从管道获取到的数据写入file-bat.txt文件当中,至此便实现了file.txt文件的拷贝。
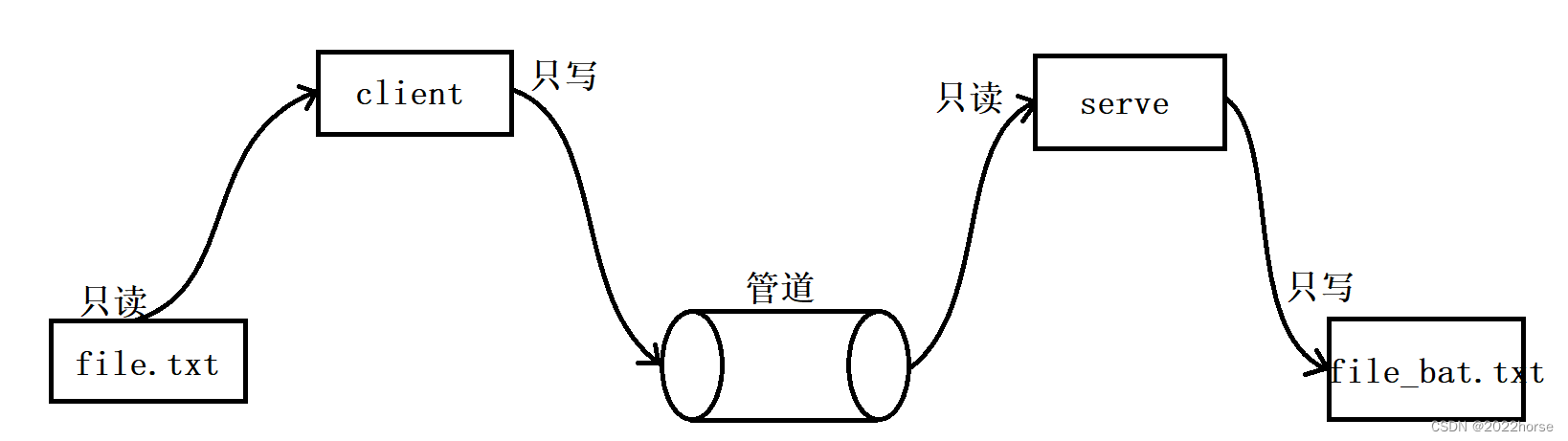
serve.c:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_NAME "myfifo"
int main()
{
umask(0);
if(mkfifo(FILE_NAME, 0666) < 0)
{
perror("mkfifo failed\n");
return 1;
}
// 1、以读方式打开管道文件
int fd = open(FILE_NAME, O_RDONLY);
if(fd < 0)
{
perror("fd open failed\n");
return 2;
}
// 2、写的方式写入目标文件
int fdout = open("log-bat.txt", O_CREAT | O_WRONLY, 0666);
if(fdout < 0)
{
perror("fdout open failed\n");
return 3;
}
char msg[128];
while(1)
{
msg[0] = '\0'; // 先都清空
// 3.0、从管道中读取信息
ssize_t s = read(fd, msg, sizeof(msg) - 1);
if(s > 0)
{
// 3.1、以写的方式写入目标文件
write(fdout, msg, s);
}
else if(s == 0)
{
printf("quit\n");
break;
}
else
{
perror("read failed\n");
break;
}
}
close(fd);
close(fdout);
return 0;
}
client.c:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_NAME "myfifo"
int main()
{
// 以只写方式打开管道文件
int fd = open(FILE_NAME, O_WRONLY);
if(fd < 0)
{
perror("fd open failed\n");
return 1;
}
// 以只读的方式打开目标文件
int fdin = open("log.txt", O_RDONLY);
if(fdin < 0)
{
perror("fdin open failed\n");
return 2;
}
// 从log.txt读取数据写到管道里面
char msg[128];
while(1)
{
ssize_t s = read(fdin, msg, sizeof(msg));
if(s > 0)
{
write(fd, msg, s); // 写到管道里
}
else if(s == 0)
{
printf("quit\n");
break;
}
else
{
perror("fdin read failed\n");
break;
}
}
close(fd);
close(fdin);
return 0;
}
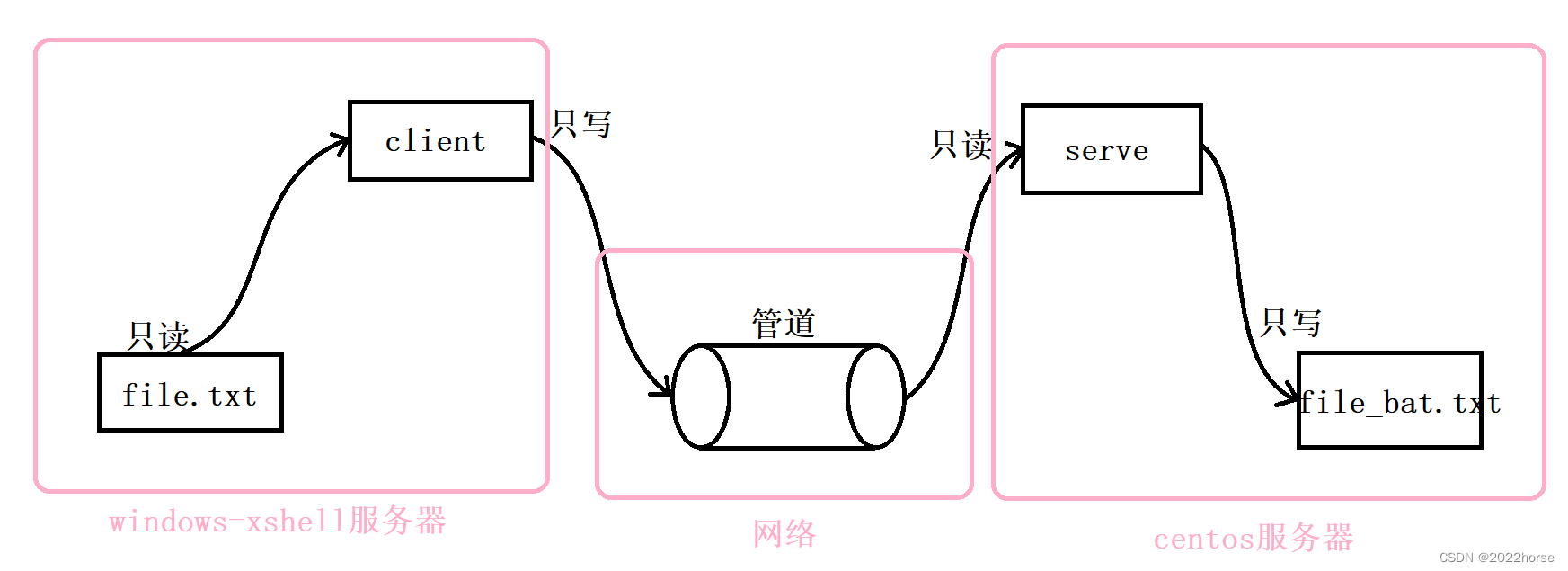
i、使用管道实现文件的拷贝有什么意义
我们若是将这里的管道想象成“网络”,将客户端想象成“Windows Xshell”,再将服务端想象成“centos服务器”。那我们此时实现的就是文件上传的功能,若是将方向反过来,那么实现的就是文件下载的功能。
5、匿名管道和命名管道的区别
- 匿名管道由pipe函数创建并打开。
- 命名管道由mkfifo函数创建,由open函数打开。
- FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在于它们创建与打开的方式不同,一旦这些工作完成之后,它们具有相同的语义。
6、命令行当中的管道
[Semi@hecs-91732 Bat]$ cat test.txt | grep fifo
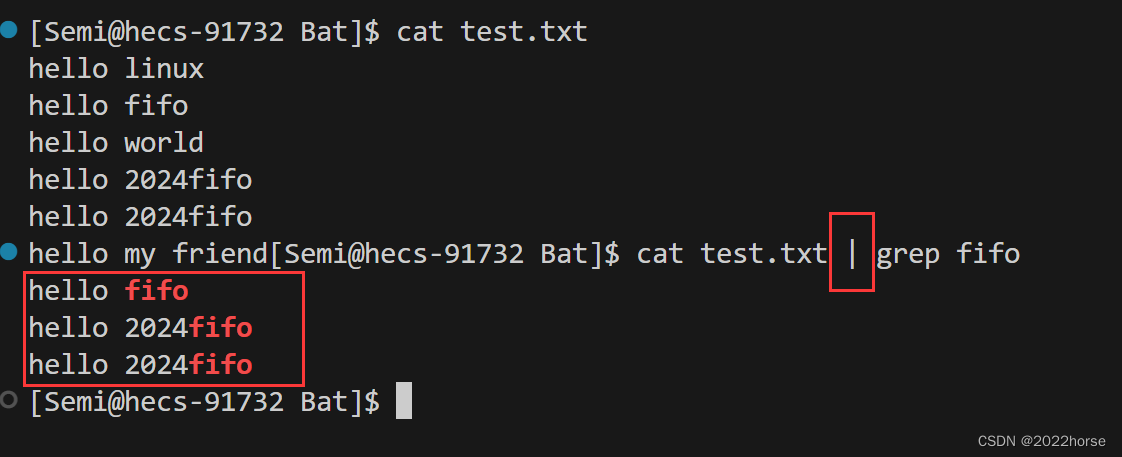
有一个问题:那么在命令行当中的管道(“|”)到底是匿名管道还是命名管道呢?
由于匿名管道只能用于有亲缘关系的进程之间的通信,而命名管道可以用于两个毫不相关的进程之间的通信,因此我们可以先看看命令行当中用管道(“|”)连接起来的各个进程之间是否具有亲缘关系。
我们试试用三个毫不相干的进程来看一下他们的PID和PPID:
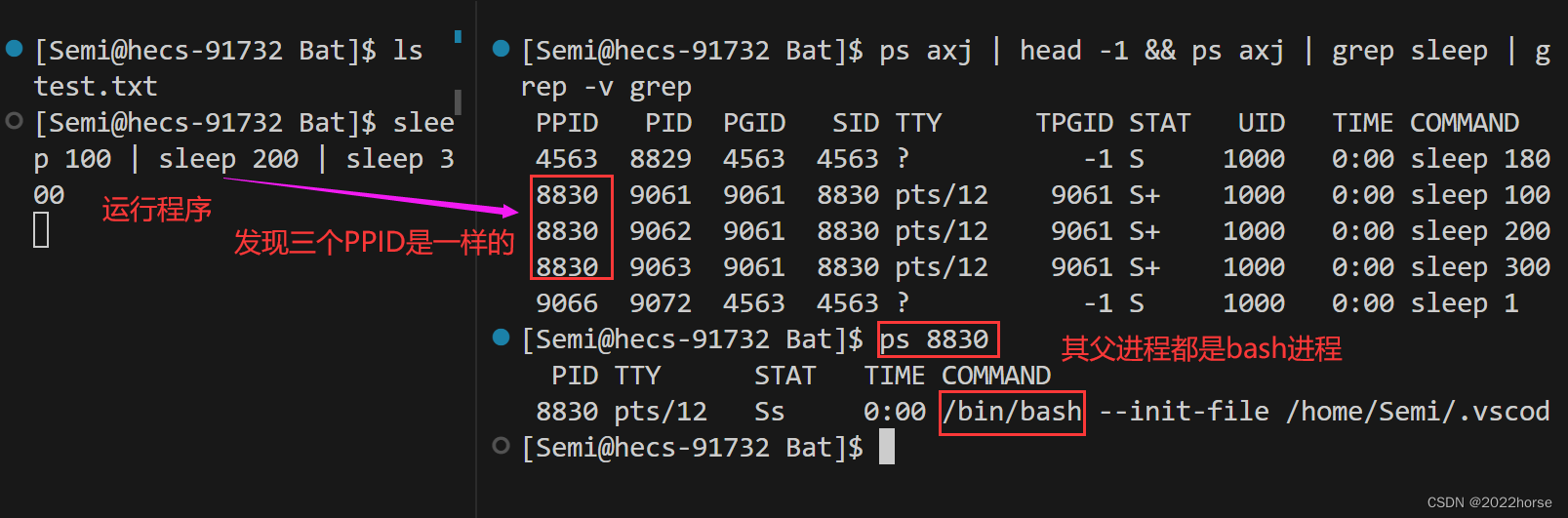
也就是说,由管道(“|”)连接起来的各个进程是有亲缘关系的,它们之间互为兄弟进程。
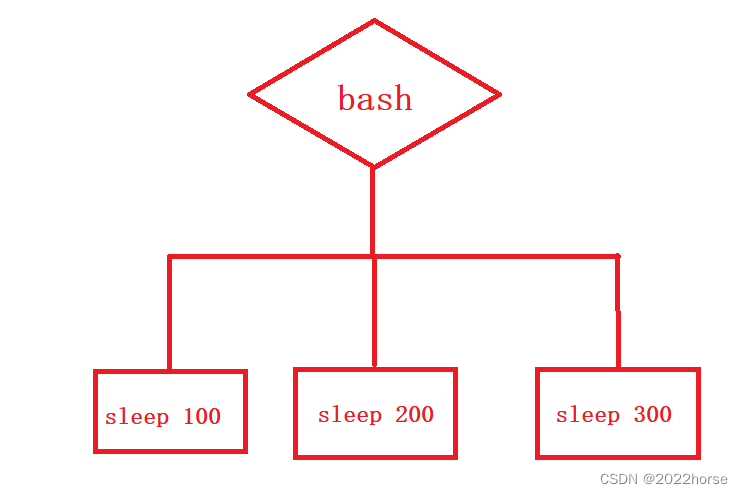
四、system V进程间通信
管道通信本质是基于文件的,也就是说操作系统并没有为此做过多的设计工作,而system V IPC是操作系统特地设计的一种通信方式。但是不管怎么样,它们的本质都是一样的,都是在想尽办法让不同的进程看到同一份由操作系统提供的资源。
system V IPC提供的通信方式有以下三种:
- system V共享内存
- system V消息队列
- system V信号量
其中,system V共享内存和system V消息队列是以传送数据为目的的,而system V信号量是为了保证进程间的同步与互斥而设计的,虽然system V信号量和通信好像没有直接关系,但属于通信范畴。system V共享内存和system V消息队列就类似于手机,用于沟通信息;system V信号量就类似于下棋比赛时用的棋钟,用于保证两个棋手之间的同步与互斥。
1、system V共享内存
(1)共享内存的基本原理
共享内存让不同进程看到同一份资源的方式就是,在物理内存当中申请一块内存空间,然后将这块内存空间分别与各个进程各自的页表之间建立映射,再在虚拟地址空间当中开辟空间并将虚拟地址填充到各自页表的对应位置,使得虚拟地址和物理地址之间建立起对应关系,至此这些进程便看到了同一份物理内存,这块物理内存就叫做共享内存。
这里所说的开辟物理空间、建立映射等操作都是调用系统接口完成的,也就是说这些动作都由操作系统来完成。
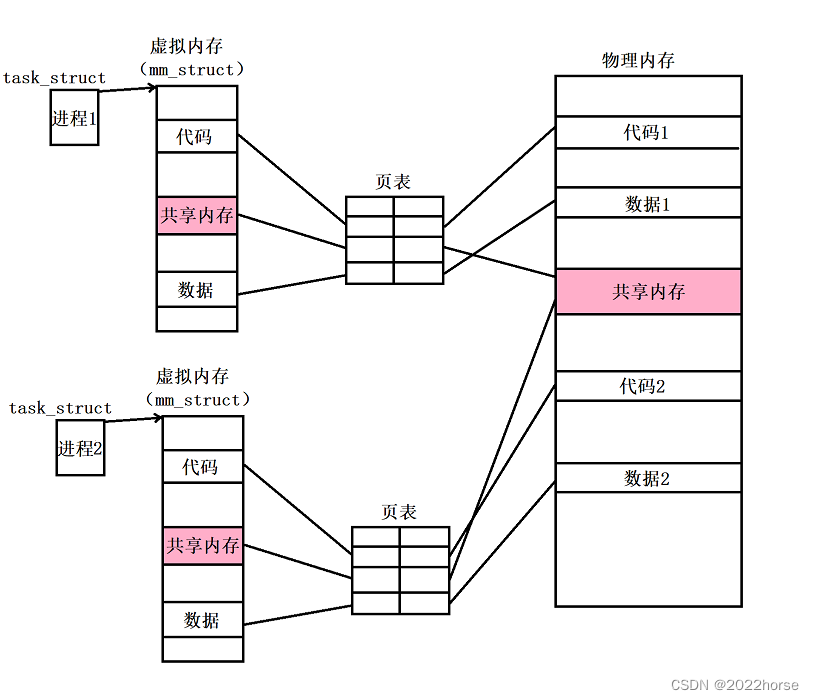
(2)共享内存数据结构
在系统当中可能会有大量的进程在进行通信,因此系统当中就可能存在大量的共享内存,那么操作系统必然要对其进行管理,所以共享内存除了在内存当中真正开辟空间之外,系统一定还要为共享内存维护相关的内核数据结构。
我们看一下共享内存的维护相关的内核数据结构:
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
当我们申请了一块共享内存后,为了让要实现通信的进程能够看到同一个共享内存,因此每一个共享内存被申请时都有一个key值,这个key值用于标识系统中共享内存的唯一性。可以看到上面共享内存数据结构的第一个成员是shm_perm,shm_perm是一个ipc_perm类型的结构体变量,每个共享内存的key值存储在shm_perm这个结构体变量当中,其中ipc_perm结构体的定义如下:
struct ipc_perm{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
共享内存的数据结构shmid_ds和ipc_perm结构体分别在/usr/include/linux/shm.h和/usr/include/linux/ipc.h中定义。
(3)共享内存的建立与释放
共享内存的建立大致包括以下两个过程:
- 在物理内存当中申请共享内存空间。
- 将申请到的共享内存挂接到地址空间,即建立映射关系。
共享内存的释放大致包括以下两个过程:
- 将共享内存与地址空间去关联,即取消映射关系。
- 释放共享内存空间,即将物理内存归还给系统。
i、共享内存的建立
创建共享内存我们需要用shmget函数,shmget函数的函数原型如下:
int shmget(key_t key, size_t size, int shmflg);
shmget函数的参数说明:
- 第一个参数key,表示待创建共享内存在系统当中的唯一标识。
- 第二个参数size,表示待创建共享内存的大小。
- 第三个参数shmflg,表示创建共享内存的方式。
shmget函数的返回值说明:
- shmget调用成功,返回一个有效的共享内存标识符(用户层标识符)。
- shmget调用失败,返回-1。
我们把具有标定某种资源能力的东西叫做句柄,而这里shmget函数的返回值实际上就是共享内存的句柄,这个句柄可以在用户层标识共享内存,当共享内存被创建后,我们在后续使用共享内存的相关接口时,都是需要通过这个句柄对指定共享内存进行各种操作。
(i)传入shmget函数的第一个参数key,需要我们使用ftok函数进行获取
函数原型:
key_t ftok(const char *pathname, int proj_id);
ftok函数的作用就是,将一个已存在的路径名pathname和一个整数标识符proj_id转换成一个key值,称为IPC键值,在使用shmget函数获取共享内存时,这个key值会被填充进维护共享内存的数据结构当中。需要注意的是,pathname所指定的文件必须存在且可存取。
注意点:
1、使用ftok函数生成key值可能会产生冲突,此时可以对传入ftok函数的参数进行修改。
2、需要进行通信的各个进程,在使用ftok函数获取key值时,都需要采用同样的路径名和和整数标识符,进而生成同一种key值,然后才能找到同一个共享资源。
(ii)传入shmget函数的第三个参数shmflg,常用的组合方式有以下两种

即第一个IPC_CREAT一定会获得一个共享内存的句柄,但无法确认该共享内存是否是新建的共享内存。
第二个IPC_CREAT | IPC_EXCL,只有shmget函数调用成功时才会获得共享内存的句柄,并且该共享内存一定是新建的共享内存。
(iv)利用ftok和shaget写一块共享内存
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/Semi/linux/class6/shm/shm.c"
#define PROJ_ID 0X6666
#define SIZE 4096
int main()
{
// 获取key值
key_t key = ftok(PATHNAME, PROJ_ID);
if(key < 0)
{
perror("ftok failed\n");
return 1;
}
// 写shmget
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL);
if(shm < 0)
{
perror("shmget failed\n");
return 2;
}
printf("key:%d\n", key);
printf("shm:%d\n", shm);
return 0;
}
运行一下看一下key和shm的值:
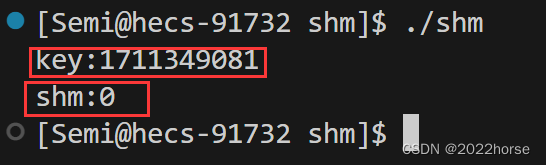
使用ipcs命令看一下有关进程间通信设施的信息。
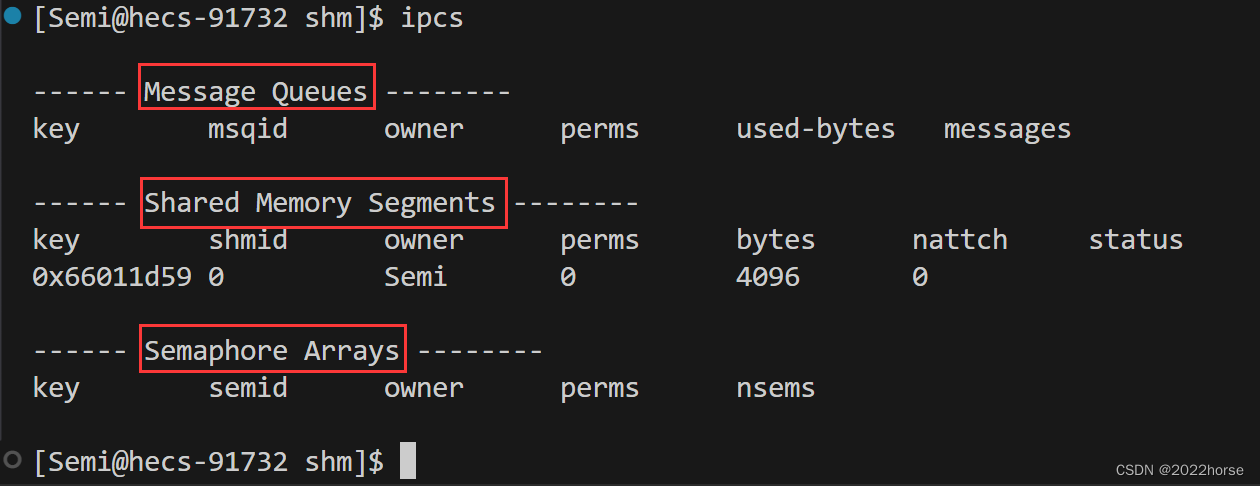
单独使用ipcs命令时,会默认列出消息队列、共享内存以及信号量相关的信息,若只想查看它们之间某一个的相关信息,可以选择携带以下选项:
-q:列出消息队列相关信息。
-m:列出共享内存相关信息。
-s:列出信号量相关信息。
我们这里只看共享内存相关信息,所以用的是-m选项:
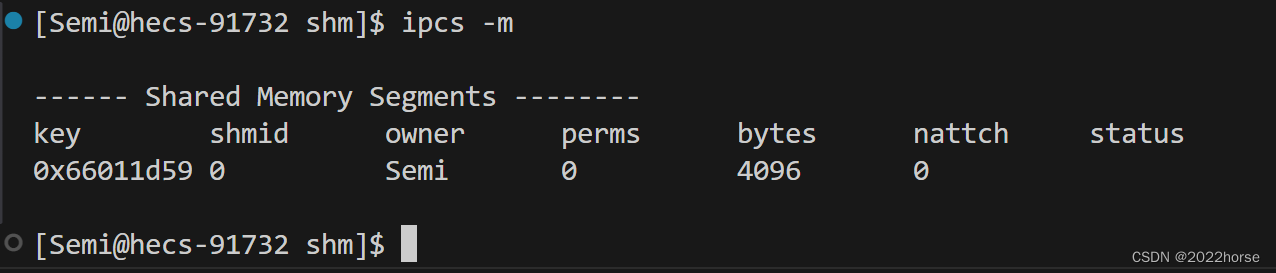
那肯定是创建成功了,我们看上面的信息。
ipcs各参数的含义:
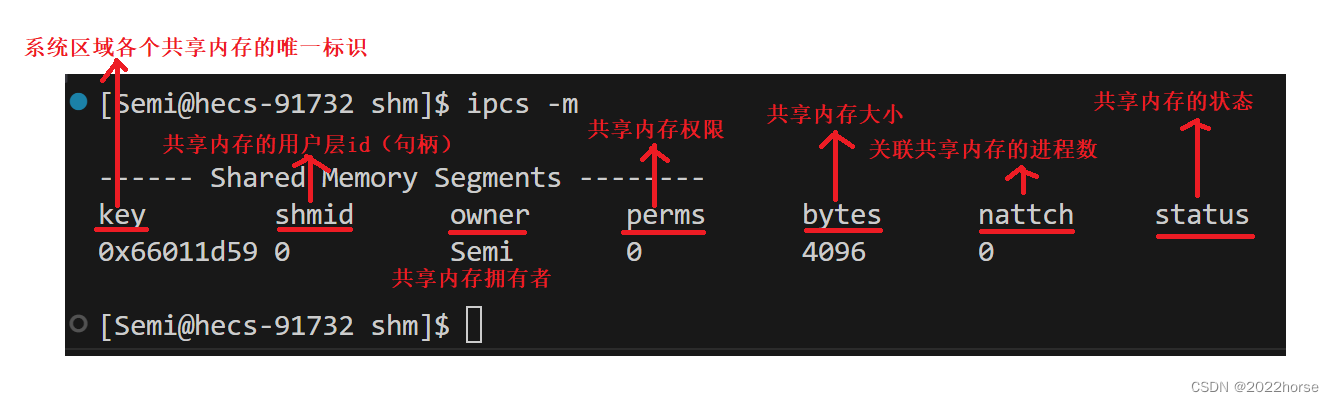
注意点:key是在内核层面上保证共享内存唯一性的方式,而shmid是在用户层面上保证共享内存的唯一性,key和shmid之间的关系类似于fd和FILE*之间的的关系。
ii、共享内存的释放
我们从上面可以发现,当我们的进程退出的时候,而共享内存却没有退出,这就说明共享内存的生命周期肯定不是跟随进程的,实际上,管道的生命周期是跟随进程的,而共享内存的生命周期是跟随内核走的,也就是说进程虽然已经退出,但是曾经创建的共享内存不会随着进程的退出而释放。如果我们退出进程后不对共享内存进行释放,那么这个共享内存会一直都存在着,直到关机重启(system V IPC都是如此),同时也说明了IPC资源是由内核提供并维护的。
我们若是要将创建的共享内存释放,有两个方法,一就是使用命令释放共享内存,二就是在进程通信完毕后调用释放共享内存的函数进行释放。
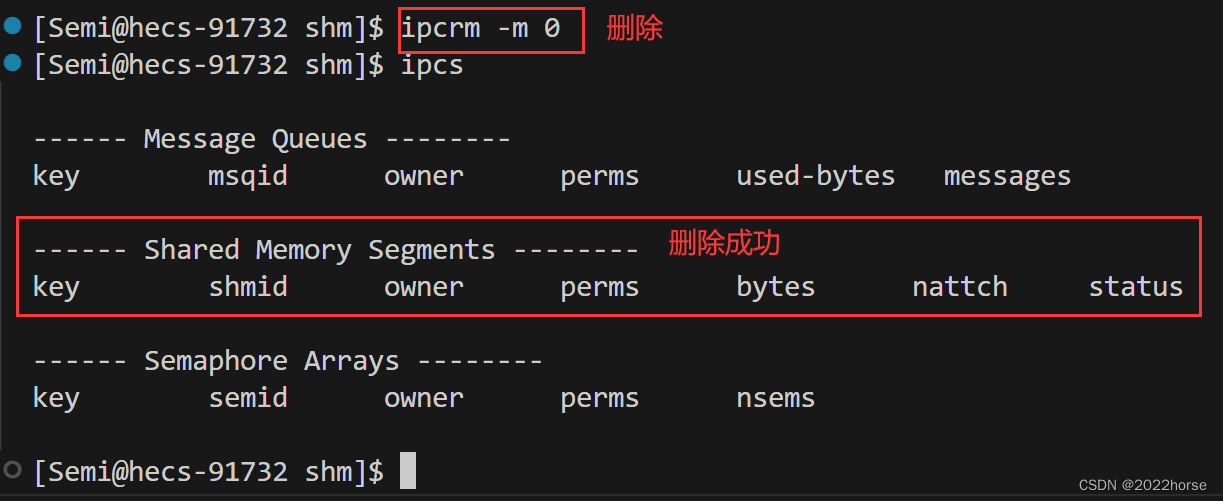
(i)使用命令释放共享内存
ipcrm -m shmid
使用上面的命令就可以将我们的共享内存进行释放掉,我们可以清晰的看到我自己的数据shmid是0,所以我只需要用这个命令后面变成0即可。
(ii)在进程通信完毕后调用释放共享内存的函数进行释放
控制共享内存我们需要用shmctl函数,shmctl函数的函数原型如下:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
shmctl函数的参数说明:
- 第一个参数shmid,表示所控制共享内存的用户级标识符。
- 第二个参数cmd,表示具体的控制动作。
- 第三个参数buf,用于获取或设置所控制共享内存的数据结构。
shmctl函数的返回值说明:
- shmctl调用成功,返回0。
- shmctl调用失败,返回-1。
作为shmctl函数的第二个参数传入的常用的选项有以下三个:

#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/Semi/linux/class6/shm/shm.c"
#define PROJ_ID 0X6666
#define SIZE 4096
int main()
{
// 获取key值
key_t key = ftok(PATHNAME, PROJ_ID);
if(key < 0)
{
perror("ftok failed\n");
return 1;
}
// 写shmget
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL);
if(shm < 0)
{
perror("shmget failed\n");
return 2;
}
printf("key:%d\n", key);
printf("shm:%d\n", shm);
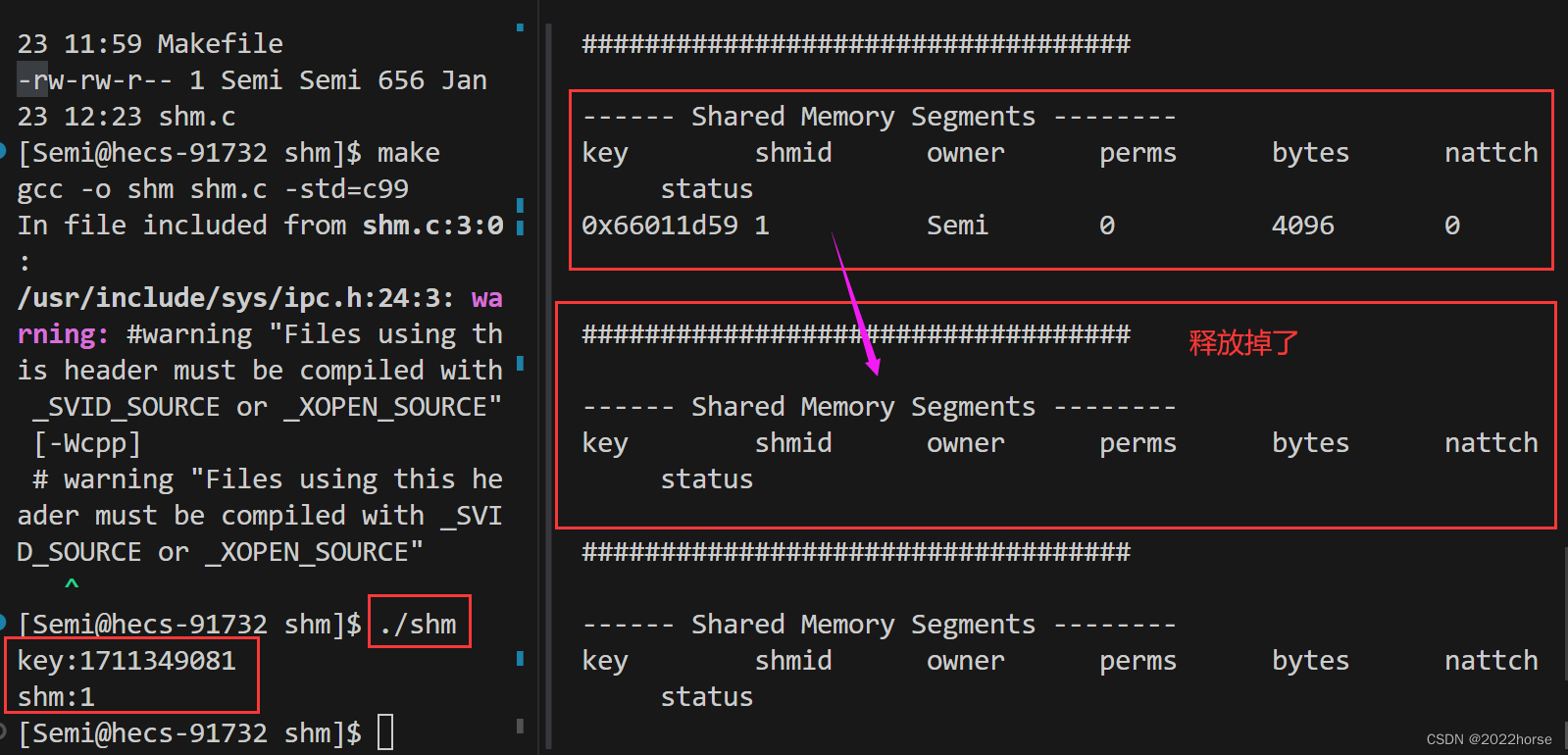
sleep(4);
shmctl(shm, IPC_RMID, NULL); //释放共享内存
sleep(4);
return 0;
}
while脚本。
while :; do ipcs -m;echo "###################################";sleep 1;done
(4)共享内存的关联
将共享内存连接到进程地址空间我们需要用shmat函数,shmat函数的函数原型如下:
void *shmat(int shmid, const void *shmaddr, int shmflg);
shmat函数的参数说明:
- 第一个参数shmid,表示待关联共享内存的用户级标识符。
- 第二个参数shmaddr,指定共享内存映射到进程地址空间的某一地址,通常设置为NULL,表示让内核自己决定一个合适的地址位置。
- 第三个参数shmflg,表示关联共享内存时设置的某些属性。
shmat函数的返回值说明:
- shmat调用成功,返回共享内存映射到进程地址空间中的起始地址。
- shmat调用失败,返回(void*)-1。
作为shmat函数的第三个参数传入的常用的选项有以下三个:

#define _GNU_SOURCE
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/Semi/linux/class6/shm/shm.c"
#define PROJ_ID 0X6666
#define SIZE 4096
int main()
{
// 获取key值
key_t key = ftok(PATHNAME, PROJ_ID);
if(key < 0)
{
perror("ftok failed\n");
return 1;
}
// 写shmget
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL);
if(shm < 0)
{
perror("shmget failed\n");
return 2;
}
printf("key:%x\n", key);
printf("shm:%d\n", shm);
printf("attach begin!\n");
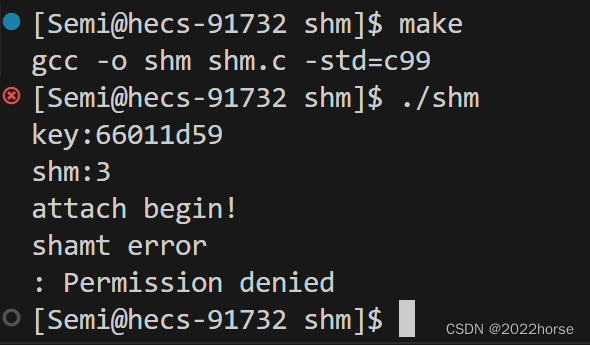
char* mem = shmat(shm, NULL, 0);
if(mem == (void*)-1)
{
perror("shamt error\n");
return 5;
}
printf("attach end\n");
sleep(4);
shmctl(shm, IPC_RMID, NULL); //释放共享内存
return 0;
}
代码运行后发现关联失败,主要原因是我们使用shmget函数创建共享内存时,并没有对创建的共享内存设置权限,所以创建出来的共享内存的默认权限为0,即什么权限都没有,因此shm进程没有权限关联该共享内存。
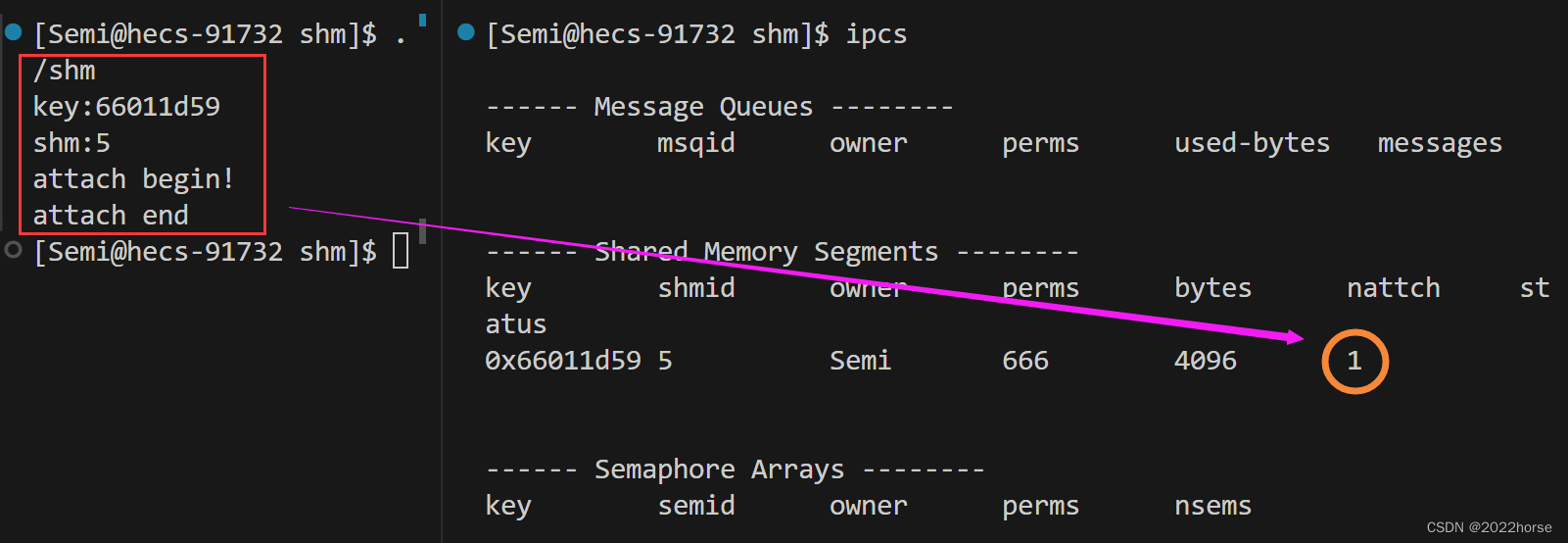
我们将进程改成0666即可。

完美链接数为1。
(5)共享内存的去关联
取消共享内存与进程地址空间之间的关联我们需要用shmdt函数,shmdt函数的函数原型如下:
int shmdt(const void *shmaddr);
shmdt函数的参数说明:
- 待去关联共享内存的起始地址,即调用shmat函数时得到的起始地址。
shmdt函数的返回值说明:
- shmdt调用成功,返回0。
- shmdt调用失败,返回-1。
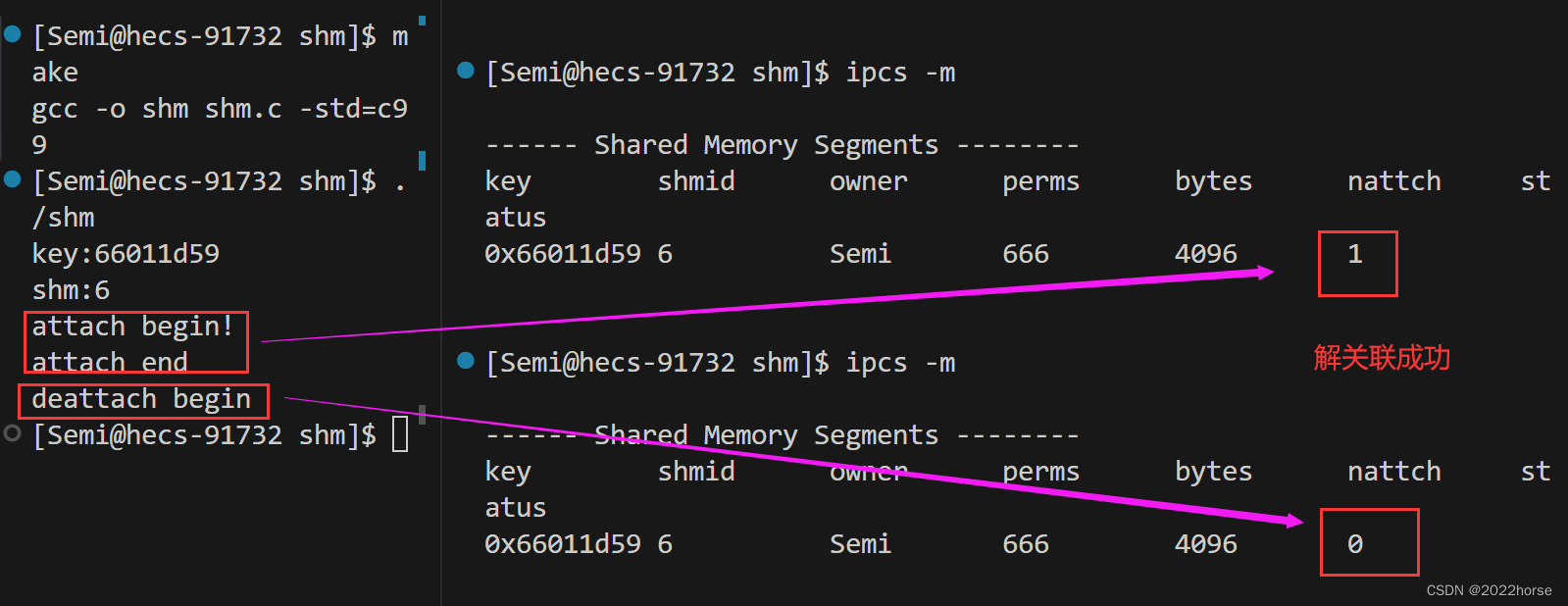
将共享内存段与当前进程脱离不等于删除共享内存,只是取消了当前进程与该共享内存之间的联系。
(6)用共享内存实现serve和client通信
i、测试是否挂起成功
服务端负责创建共享内存,创建好后将共享内存和服务端进行关联,之后进入死循环,便于观察服务端是否挂接成功。
serve.c:
#define _GNU_SOURCE
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/Semi/linux/class6/serve.c"
#define PROJ_ID 0X6666
#define SIZE 4096
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); // key值
if(key < 0)
{
perror("ftok error\n");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666); // 新的共享内存
if(shm < 0)
{
perror("shmget error\n");
return 2;
}
printf("key#%x\n", key);
printf("shm#%d\n", shm);
char* mem = shmat(shm, NULL, 0); // 关联共享内存
while(1)
{
// 什么也不做...
}
shmdt(mem); //共享内存去关联
shmctl(shm, IPC_RMID, NULL); //释放共享内存
return 0;
}
client.c:
#define _GNU_SOURCE
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/Semi/linux/class6/serve.c"
#define PROJ_ID 0X6666
#define SIZE 4096
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); // 获取和serve.c一样的key值
if(key < 0)
{
perror("ftok error\n");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT); // 获取与用户层一样的shm,id还有一样的共享内存
if(shm < 0)
{
perror("shmget error\n");
return 2;
}
printf("key#%x\n", key);
printf("shm#%d\n", shm);
// 关联共享内存
char* mem = shmat(shm, NULL, 0);
if(mem == (void*)-1)
{
perror("shmat error\n");
return 3;
}
while(1)
{
// 啥也不做...
}
shmdt(mem); // 解关联
return 0;
}
先后运行服务端和客户端后,通过监控脚本可以看到服务端和客户端所关联的是同一个共享内存,共享内存关联的进程数也是2,表示服务端和客户端挂接共享内存成功。
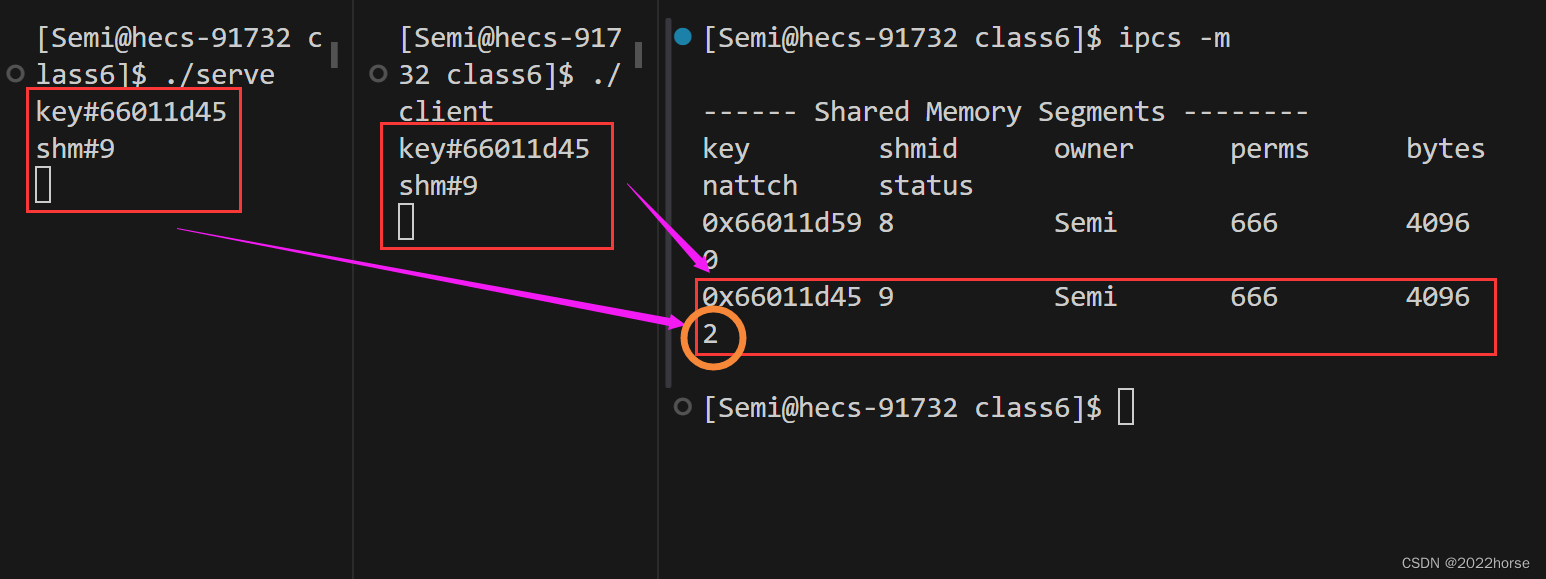
ii、客户端不断从共享内存中写入数据,服务端不断从共享内存读取数据
serve.c补充内容:
while(1)
{
// 不断从共享内存中读取数据并打印出来
printf("client#%s\n", mem);
sleep(1);
}
client.c补充内容:
int i = 0;
while(1)
{
// 不断对共享内存写入数据
mem[i] = 'a' + i;
i++;
mem[i] = '\0';
sleep(1);
}
此时先运行服务端创建共享内存,当我们运行客户端时服务端就开始不断输出数据,说明服务端和客户端是能够正常通信的。
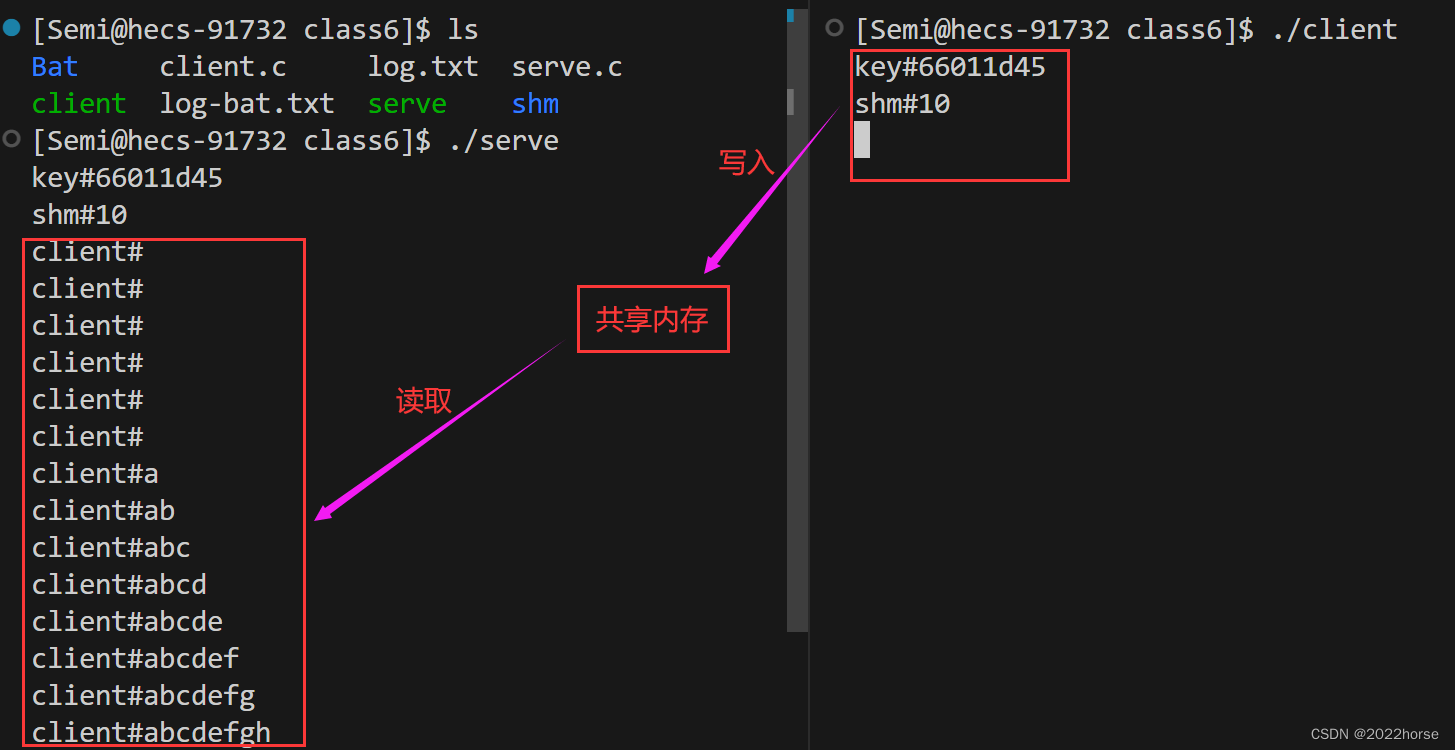
(7)共享内存与管道进行对比
当共享内存创建好后就不再需要调用系统接口进行通信了,而管道创建好后仍需要read、write等系统接口进行通信。实际上,共享内存是所有进程间通信方式中最快的一种通信方式。
我们通信的速度取决于拷贝的次数,也就是从一个文件到另一个文件的次数。
i、通信管道
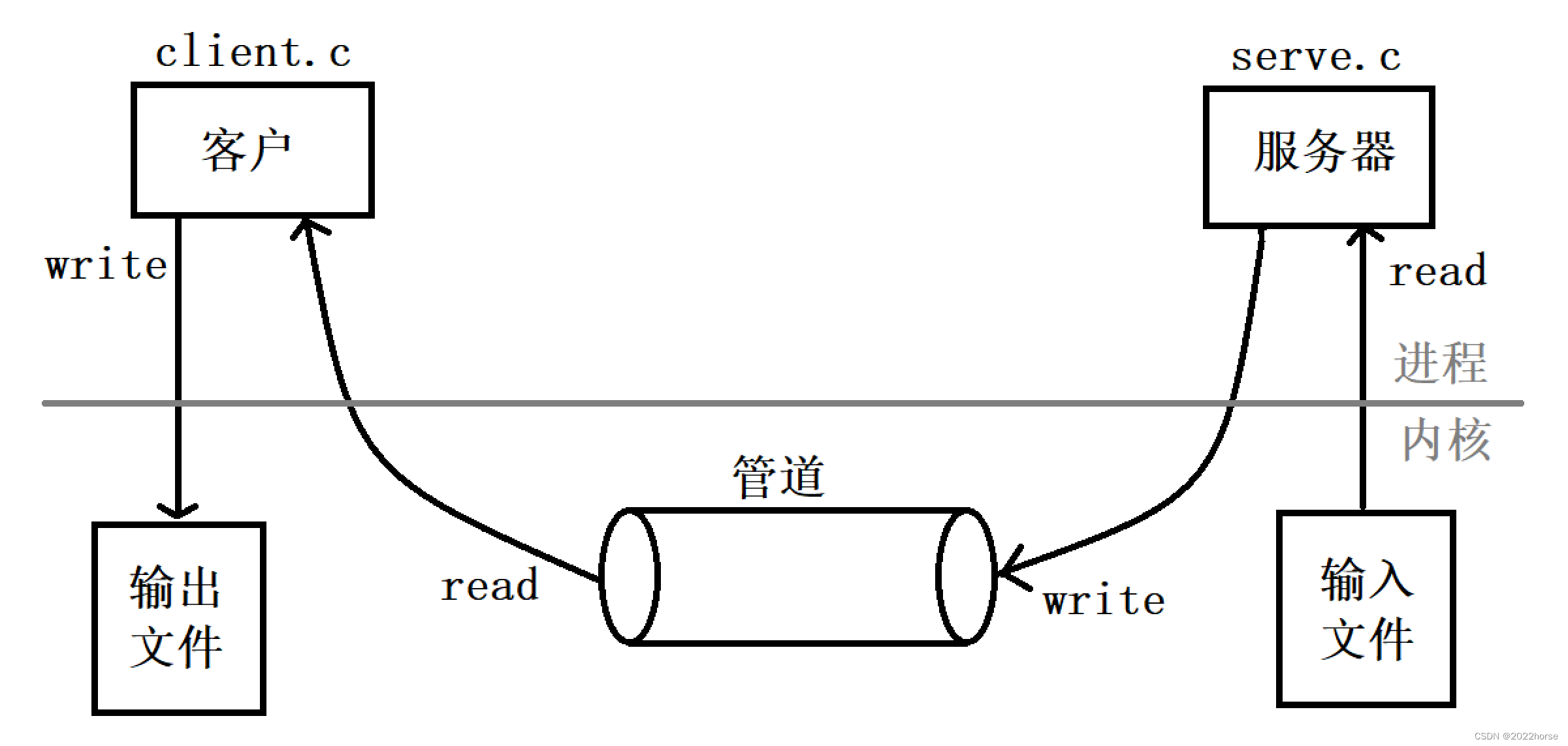
从这张图可以看出,使用管道通信的方式,将一个文件从一个进程传输到另一个进程需要进行四次拷贝操作:
- 输入文件到服务器的临时缓冲区中
- 服务器的临时缓冲区到管道中
- 管道到客户端的临时缓冲区中
- 客户的缓冲区到输出文件中
ii、共享内存通信
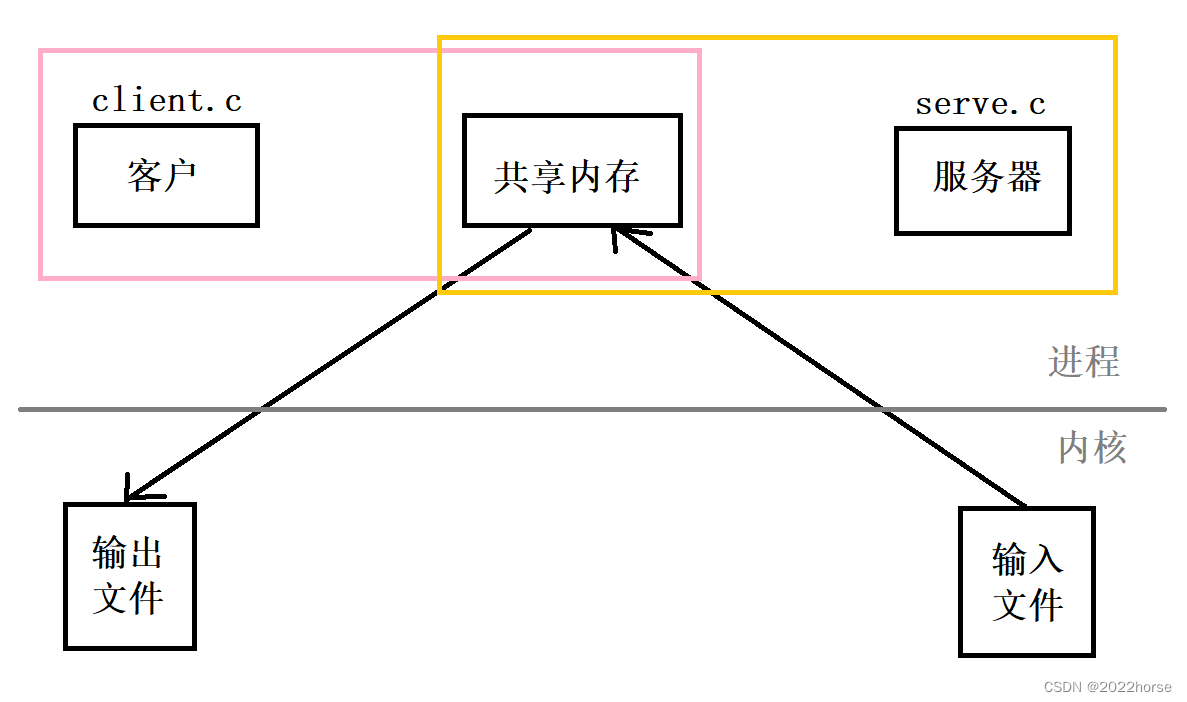
从这张图可以看出,使用共享内存进行通信,将一个文件从一个进程传输到另一个进程只需要进行两次拷贝操作:
- 输入文件到共享内存中
- 共享内存到输出文件中
iii、总结
但是共享内存也是有缺点的,我们知道管道是自带同步与互斥机制的,但是共享内存并没有提供任何的保护机制,包括同步与互斥。
共享内存是所有进程间通信方式中最快的一种通信方式,因为该通信方式需要进行的拷贝次数最少。
2、System V消息队列
(1)消息队列的基本原理
消息队列实际上就是在系统当中创建了一个队列,队列当中的每个成员都是一个数据块,这些数据块都由类型和信息两部分构成,两个互相通信的进程通过某种方式看到同一个消息队列,这两个进程向对方发数据时,都在消息队列的队尾添加数据块,这两个进程获取数据块时,都在消息队列的队头取数据块。
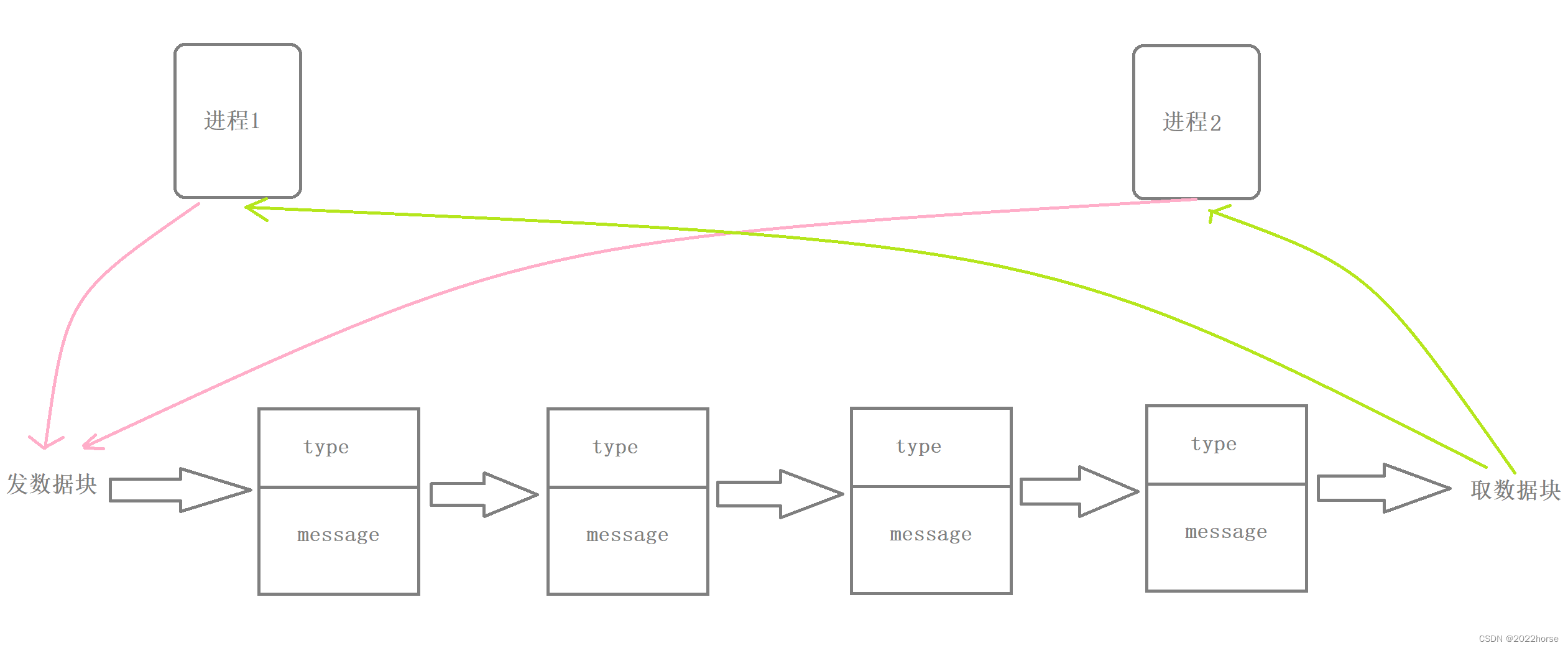
总结
- 消息队列提供了一个从一个进程向另一个进程发送数据块的方法。
- 每个数据块都被认为是有一个类型的,接收者进程接收的数据块可以有不同的类型值。
- 和共享内存一样,消息队列的资源也必须自行删除,否则不会自动清除,因为system V IPC资源的生命周期是随内核的。
(2)消息队列数据结构
共享内存的数据结构msqid_ds和ipc_perm结构体分别在/usr/include/linux/msg.h和/usr/include/linux/ipc.h中定义。
struct msqid_ds
{
struct ipc_perm msg_perm;
struct msg *msg_first; /* first message on queue,unused */
struct msg *msg_last; /* last message in queue,unused */
__kernel_time_t msg_stime; /* last msgsnd time */
__kernel_time_t msg_rtime; /* last msgrcv time */
__kernel_time_t msg_ctime; /* last change time */
unsigned long msg_lcbytes; /* Reuse junk fields for 32 bit */
unsigned long msg_lqbytes; /* ditto */
unsigned short msg_cbytes; /* current number of bytes on queue */
unsigned short msg_qnum; /* number of messages in queue */
unsigned short msg_qbytes; /* max number of bytes on queue */
__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */
__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
可以看到消息队列数据结构的第一个成员是msg_perm,它和shm_perm是同一个类型的结构体变量,ipc_perm结构体的定义如下:
struct ipc_perm
{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
(3)消息队列的创建
创建消息队列我们需要用msgget函数,msgget函数的函数原型如下:
int msgget(key_t key, int msgflg);
- 创建消息队列也需要使用ftok函数生成一个key值,这个key值作为msgget函数的第一个参数。
- msgget函数的第二个参数,与创建共享内存时使用的shmget函数的第三个参数相同。
- 消息队列创建成功时,msgget函数返回的一个有效的消息队列标识符(用户层标识符)。
(4)消息队列的释放
释放消息队列我们需要用msgctl函数,msgctl函数的函数原型如下:
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
msgctl函数的参数与释放共享内存时使用的shmctl函数的三个参数相同,只不过msgctl函数的第三个参数传入的是消息队列的相关数据结构。
(5)向消息队列发送数据
msgsnd函数的参数说明:
- 第一个参数msqid,表示消息队列的用户级标识符。
- 第二个参数msgp,表示待发送的数据块。
- 第三个参数msgsz,表示所发送数据块的大小。
- 第四个参数msgflg,表示发送数据块的方式,一般默认为0即可。
msgsnd函数的返回值说明:
- msgsnd调用成功,返回0。
- msgsnd调用失败,返回-1。
其中msgsnd函数的第二个参数必须为以下结构:
struct msgbuf
{
long mtype; /* message type, must be > 0 */
char mtext[1]; /* message data */
};
(6)从消息队列获取数据
从消息队列获取数据我们需要用msgrcv函数,msgrcv函数的函数原型如下:
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
msgrcv函数的参数说明:
- 第一个参数msqid,表示消息队列的用户级标识符。
- 第二个参数msgp,表示获取到的数据块,是一个输出型参数。
- 第三个参数msgsz,表示要获取数据块的大小。
- 第四个参数msgtyp,表示要接收数据块的类型。
msgrcv函数的返回值说明:
- msgsnd调用成功,返回实际获取到mtext数组中的字节数。
- msgsnd调用失败,返回-1。
3、System V信号量
(1)信号量相关概念
- 由于进程要求共享资源,而且有些资源需要互斥使用,因此各进程间竞争使用这些资源,进程的这种关系叫做进程互斥。
- 系统中某些资源一次只允许一个进程使用,称这样的资源为临界资源或互斥资源。
- 在进程中涉及到临界资源的程序段叫临界区。
- IPC资源必须删除,否则不会自动删除,因为system V IPC的生命周期随内核。
(2)信号量数据结构
共享内存的数据结构msqid_ds和ipc_perm结构体分别在/usr/include/linux/sem.h和/usr/include/linux/ipc.h中定义。
struct semid_ds
{
struct ipc_perm sem_perm; /* permissions .. see ipc.h */
__kernel_time_t sem_otime; /* last semop time */
__kernel_time_t sem_ctime; /* last change time */
struct sem *sem_base; /* ptr to first semaphore in array */
struct sem_queue *sem_pending; /* pending operations to be processed */
struct sem_queue **sem_pending_last; /* last pending operation */
struct sem_undo *undo; /* undo requests on this array */
unsigned short sem_nsems; /* no. of semaphores in array */
};
信号量数据结构的第一个成员也是ipc_perm类型的结构体变量,ipc_perm结构体的定义如下:
struct ipc_perm
{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
(3)信号量相关函数
i、信号量集的创建
创建信号量集我们需要用semget函数,semget函数的函数原型如下:
int semget(key_t key, int nsems, int semflg);
- 创建信号量集也需要使用ftok函数生成一个key值,这个key值作为semget函数的第一个参数。
- semget函数的第二个参数nsems,表示创建信号量的个数。
- semget函数的第三个参数,与创建共享内存时使用的shmget函数的第三个参数相同。
- 信号量集创建成功时,semget函数返回的一个有效的信号量集标识符(用户层标识符)。
ii、信号量集的删除
删除信号量集我们需要用semctl函数,semctl函数的函数原型如下:
int semctl(int semid, int semnum, int cmd, ...);
iii、信号量集的操作
对信号量集进行操作我们需要用semop函数,semop函数的函数原型如下:
int semop(int semid, struct sembuf *sops, unsigned nsops);
五、进程互斥
进程间通信通过共享资源来实现,这虽然解决了通信的问题,但是也引入了新的问题,那就是通信进程间共用的临界资源,若是不对临界资源进行保护,就可能产生各个进程从临界资源获取的数据不一致等问题。
保护临界资源的本质是保护临界区,我们把进程代码中访问临界资源的代码称之为临界区,信号量就是用来保护临界区的,信号量分为二元信号量和多元信号量。
比如当前有一块大小为100字节的资源,我们若是一25字节为一份,那么该资源可以被分为4份,那么此时这块资源可以由4个信号量进行标识。
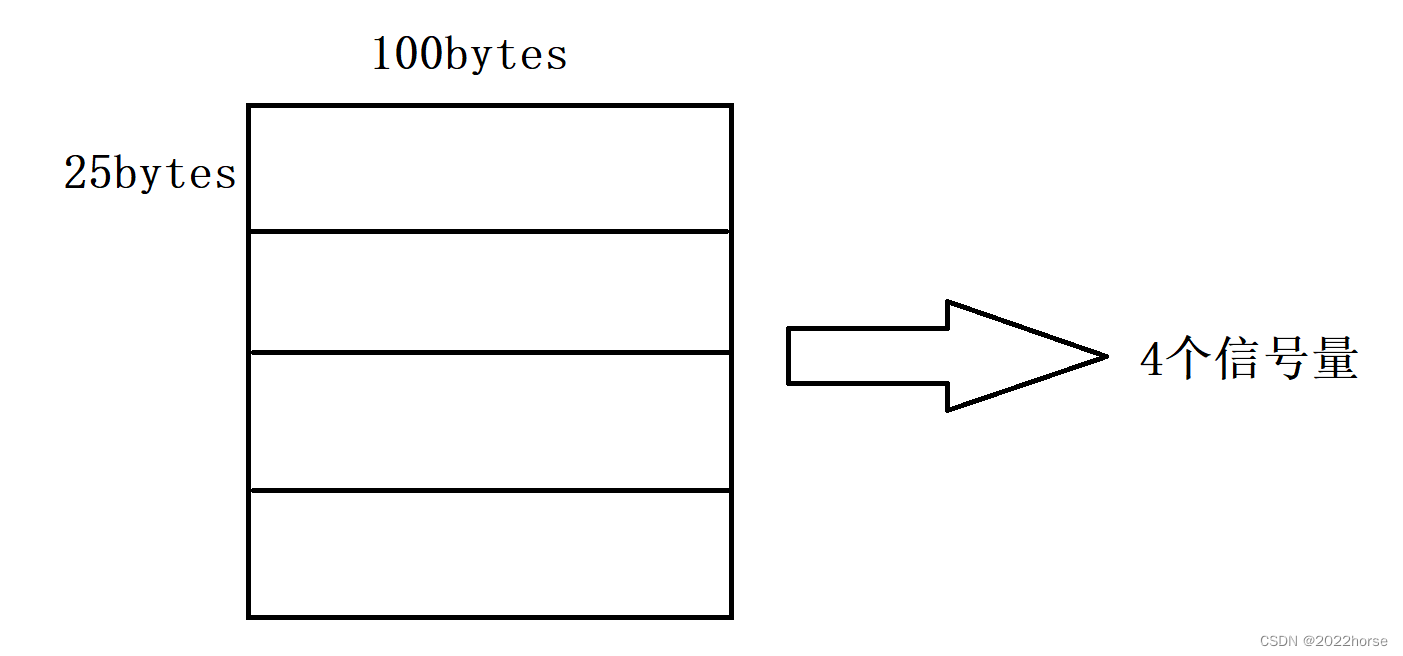
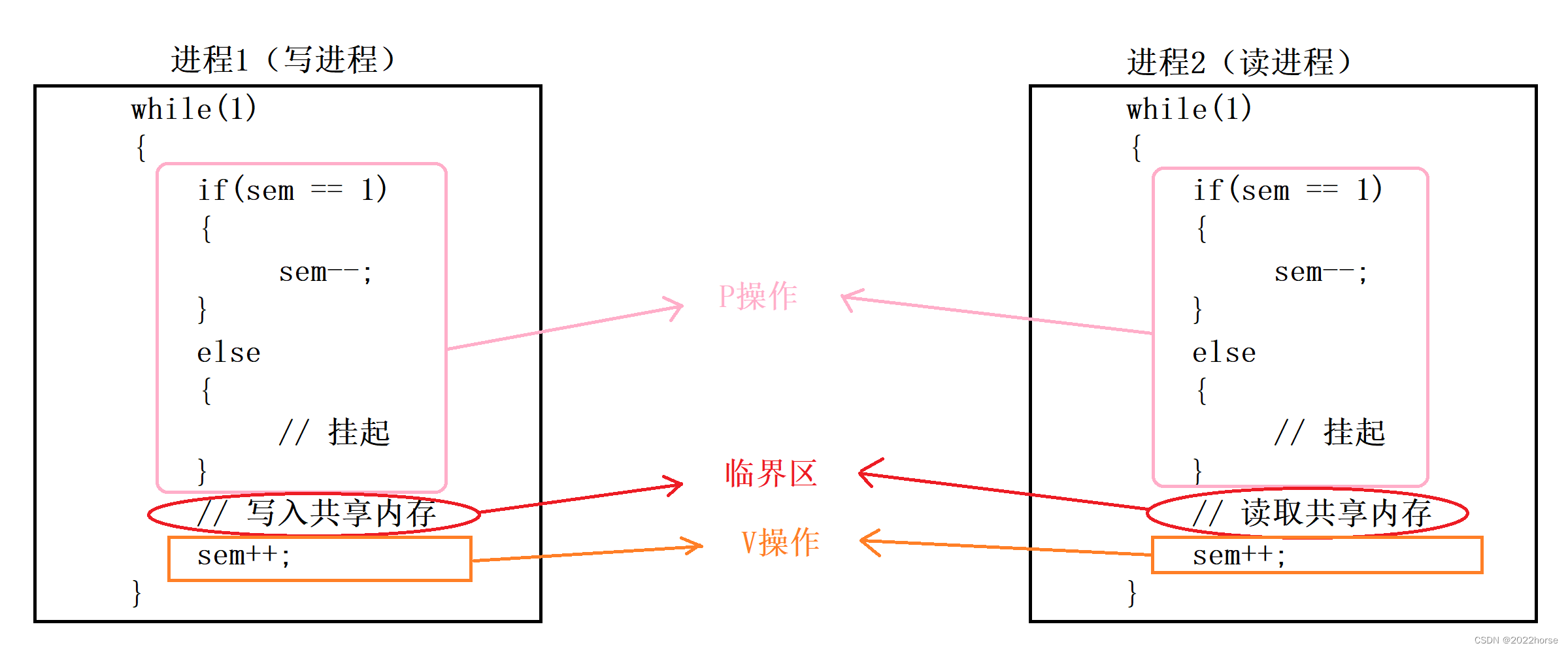
信号量本质是一个计数器,在二元信号量中,信号量的个数为1(相当于将临界资源看成一整块),二元信号量本质解决了临界资源的互斥问题,以下面的伪代码进行解释:
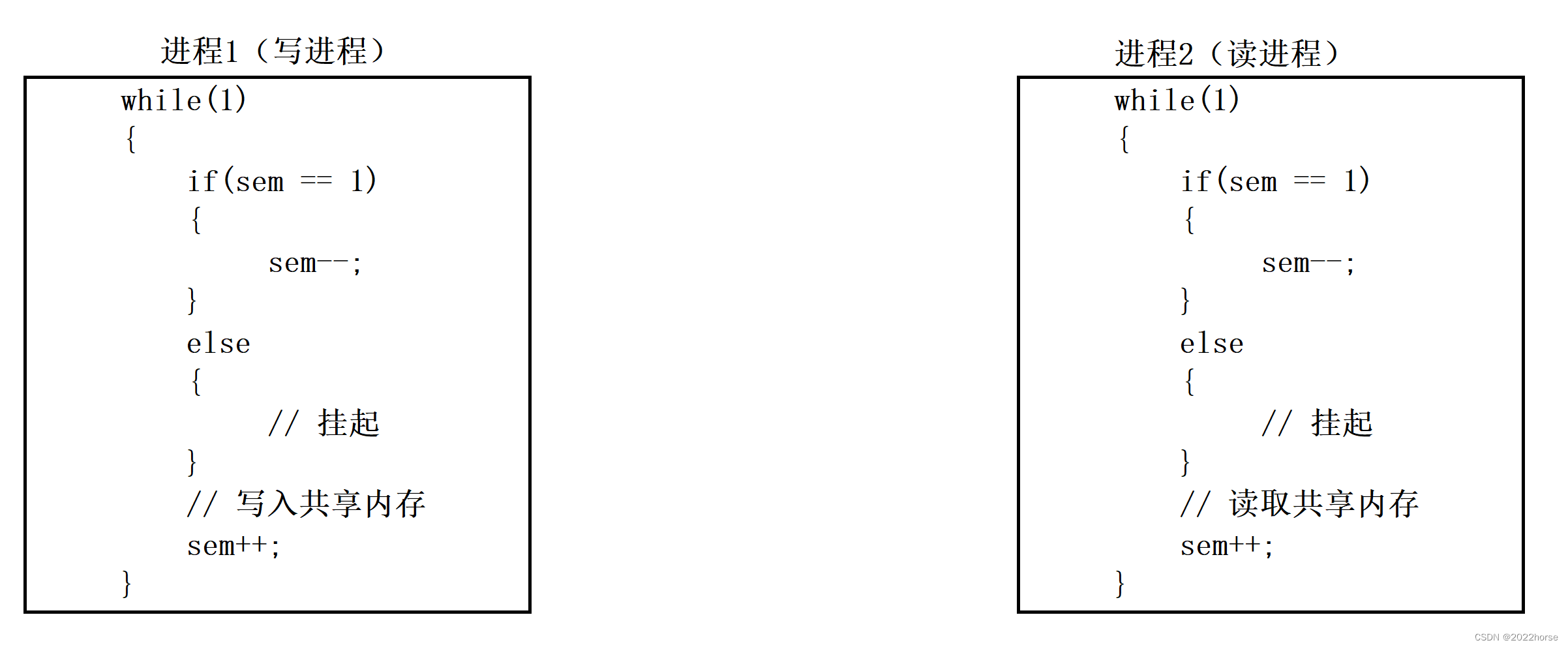
根据以上代码,当进程A申请访问共享内存资源时,如果此时sem为1(sem代表当前信号量个数),则进程A申请资源成功,此时需要将sem减减,然后进程A就可以对共享内存进行一系列操作,但是在进程A在访问共享内存时,若是进程B申请访问该共享内存资源,此时sem就为0了,那么这时进程B会被挂起,直到进程A访问共享内存结束后将sem加加,此时才会将进程B唤起,然后进程B再对该共享内存进行访问操作。
在这种情况下,无论什么时候都只会有一个进程在对同一份共享内存进行访问操作,也就解决了临界资源的互斥问题。
实际上,代码中计数器sem减减的操作就叫做P操作,而计数器加加的操作就叫做V操作,P操作就是申请信号量,而V操作就是释放信号量。
六、system V IPC联系
通过对system V系列进程间通信的学习,可以发现共享内存、消息队列以及信号量,虽然它们内部的属性差别很大,但是维护它们的数据结构的第一个成员确实一样的,都是ipc_perm类型的成员变量。
这样设计的好处就是,在操作系统内可以定义一个struct ipc_perm类型的数组,此时每当我们申请一个IPC资源,就在该数组当中开辟一个这样的结构。
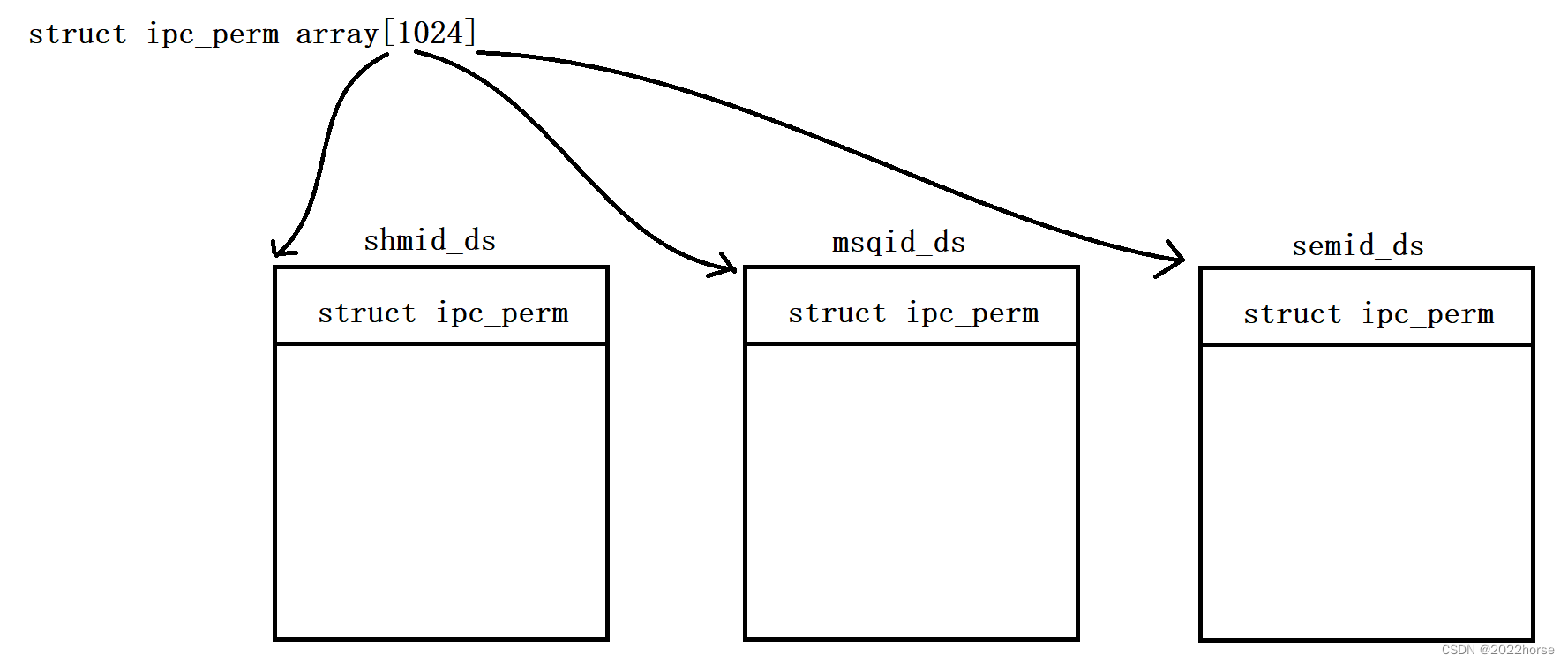
也就是说,在内核当中只需要将所有的IPC资源的ipc_perm成员组织成数组的样子,然后用切片的方式获取到该IPC资源的起始地址,然后就可以访问该IPC资源的每一个成员了。