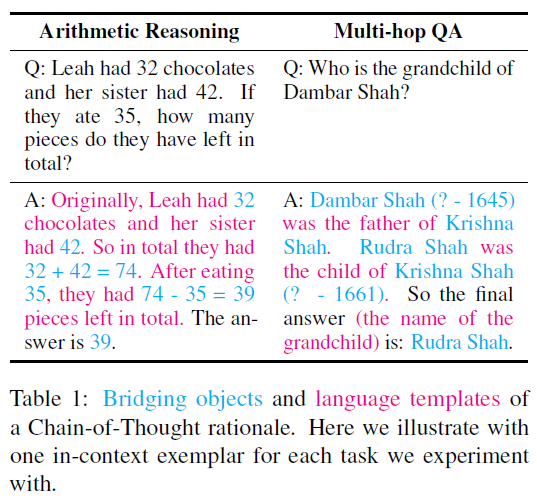
论文首先定义了思维链中的两种核心元素
-
Bridge Object: 模型解决问题所需的核心和必须元素。例如数学问题中的数字和公式,QA问题中的实体,有点类似把论文1中pattern和symbol和在了一起,感觉定义更清晰了
-
Language Template:除去Bridge Object剩余的部分基本都是Language Template
其次定义了思维链的两种核心关系
-
一致性(Coherence): 推理步骤之间的逻辑顺序, 先说什么后说什么
-
相关性(Relevance): Question中核心元素是否在推理中出现
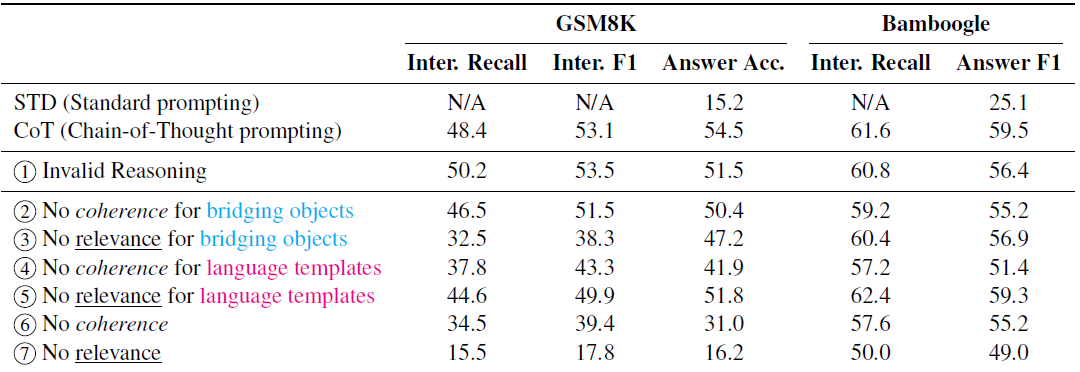
实验
论文的消融实验通过人工修改few-shot COT中的few-shot样本,来验证思维链中不同元素的贡献,这里我们以一个数学问题问题为例,看下实验的两个阶段
观点1. 完全正确的COT并非必要
第一步作者证明了完全正确的In-Context样本并不是必须的,用的什么方法嘞?
如下图所示,作者手工把正确的In-Context COT样本改写成错误的,改写方式是在保留部分推理顺序,和部分bridge object的前提下,随机的把推理改成错误的推理逻辑。作者发现魔改后错误的few-shot的样本,对比正确的few-shot-cot保留了80%+的水平,只有小幅的下降。

观点2.推理顺序和核心元素的出现更重要
既然完全正确的COT样本并非必须,那究竟思维链的哪些元素对效果的影响最大呢?针对以上两种元素和两种关系,作者用了数据增强的方式来对few-shot样本进行修改,得到破坏某一种元素/关系后的few-shot样本
-
破坏相关性: 这里使用了Random Substitution; 针对Bridge Obejct,就是固定文字模板,把数学问题中出现的数字在COT里面(32/42/35)随机替换成其他数字,这里为了保持上下文一致性相同的数字会用相同的随机数字来替换; 针对template,就固定Bridge Object,从样本中随机采样其他的COT推理模板来进行替换。
-
破坏一致性: 这里使用了Random Shuffle;针对Bridge Object,就是把COT中不同位置的Bridge Obejct随机打乱顺序;针对Template,就固定Bridge Object,把文字模板的句子随机改变位置。
整体效果如下图

论文正文用的是text-davinci-002,附录里也补充了text-davinci-003的效果,看起来003的结果单调性更好,二者结论是基本一致的,因此这里我们只看下003的消融实验效果,可以得到以下几个核心结论
-
对比COT推理的正确性,相关性和一致性更加重要,尤其是相关性。也就是在推理过程中复述question中的关键信息可以有效提高模型推理准确率。个人猜测是核心元素的复述可以帮助模型更好理解指令识别指令中的关键信息,并提高该信息对应的知识召回【这一点我们在下游难度较高的多项选择SFT中也做过验证,我们在多项选择的推理模板的最后加入了题干的复述,效果会有一定提升,进一步把选项的结果完形填空放到题干中,效果会有更进一步的提升】
-
Language Template的一致性贡献度较高。也就是正确的逻辑推理顺序有助于模型推理效果的提升。这一点更好理解主要和decoder需要依赖上文的解码方式相关。【还是多项选择的指令微调,我们对比了把选项答案放在推理的最前面和放在复述题干之前的效果,都显著差于先推理分析,复述题干并填入选项答案,最后给出选项答案这个推理顺序】