CLIP探索笔记
记录CLIP的流水账,训练和推理是如何完成的?
每一次阅读都有不同的领悟和发现,一些简单的想法。
官方信息
- Code
- Paper
- Blog
- 只有预测代码+模型,没有训练代码
训练阶段
- Text Encoder不需要训练,直接拿现成的文本模型来用就可以了,比如GPT,提取文本特征
- 代码中用的是transformer
- Image Encoder需要训练,提取图片特征
- 代码中用的是CNN,resnet结构
- 计算余弦相似度
- 论文中给出了伪代码,文本特征和图像特征,分别和真实标签特征做相似度计算,然后再求平均
- 对角线是正样本
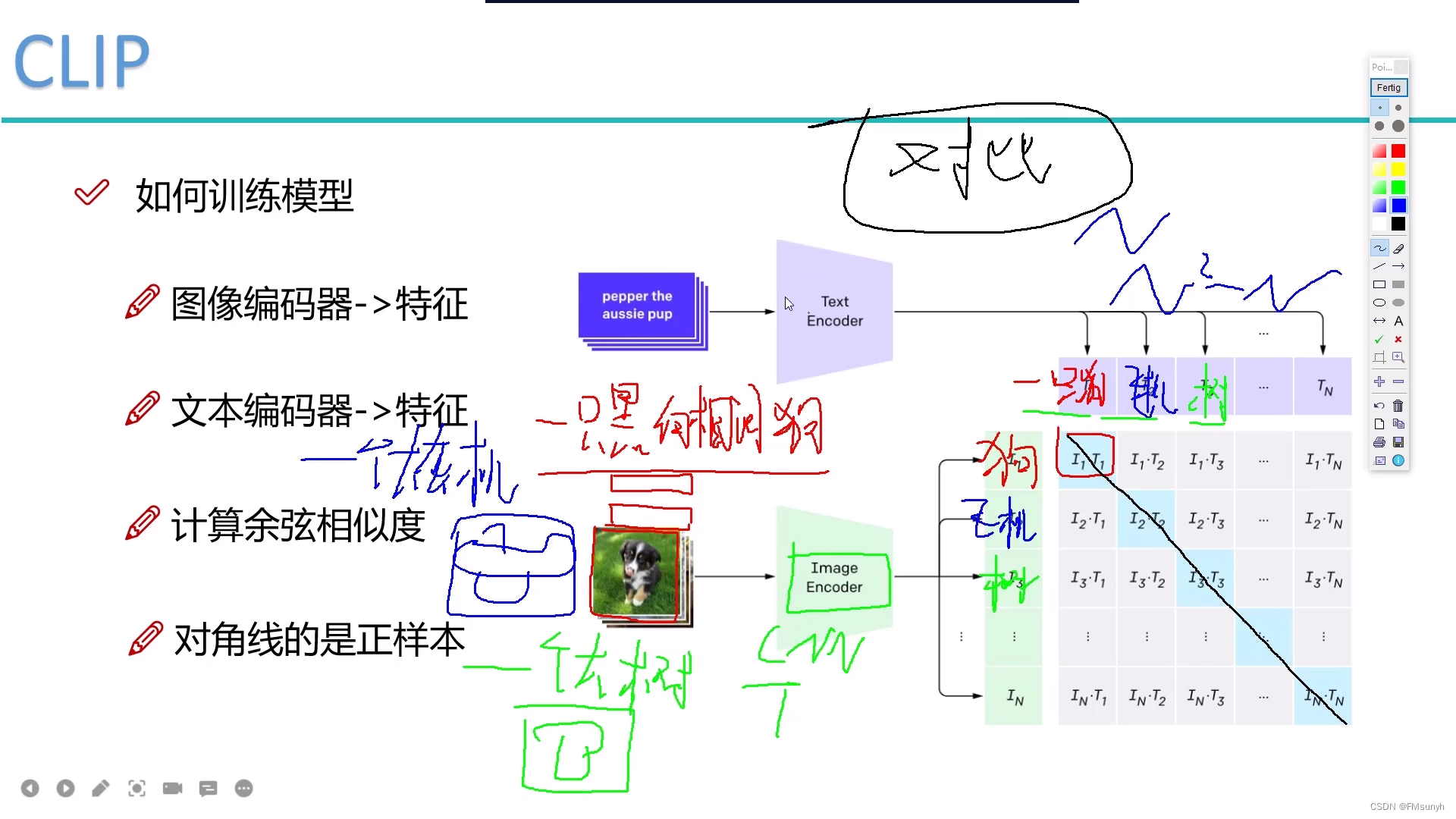
计算LOSS的伪代码

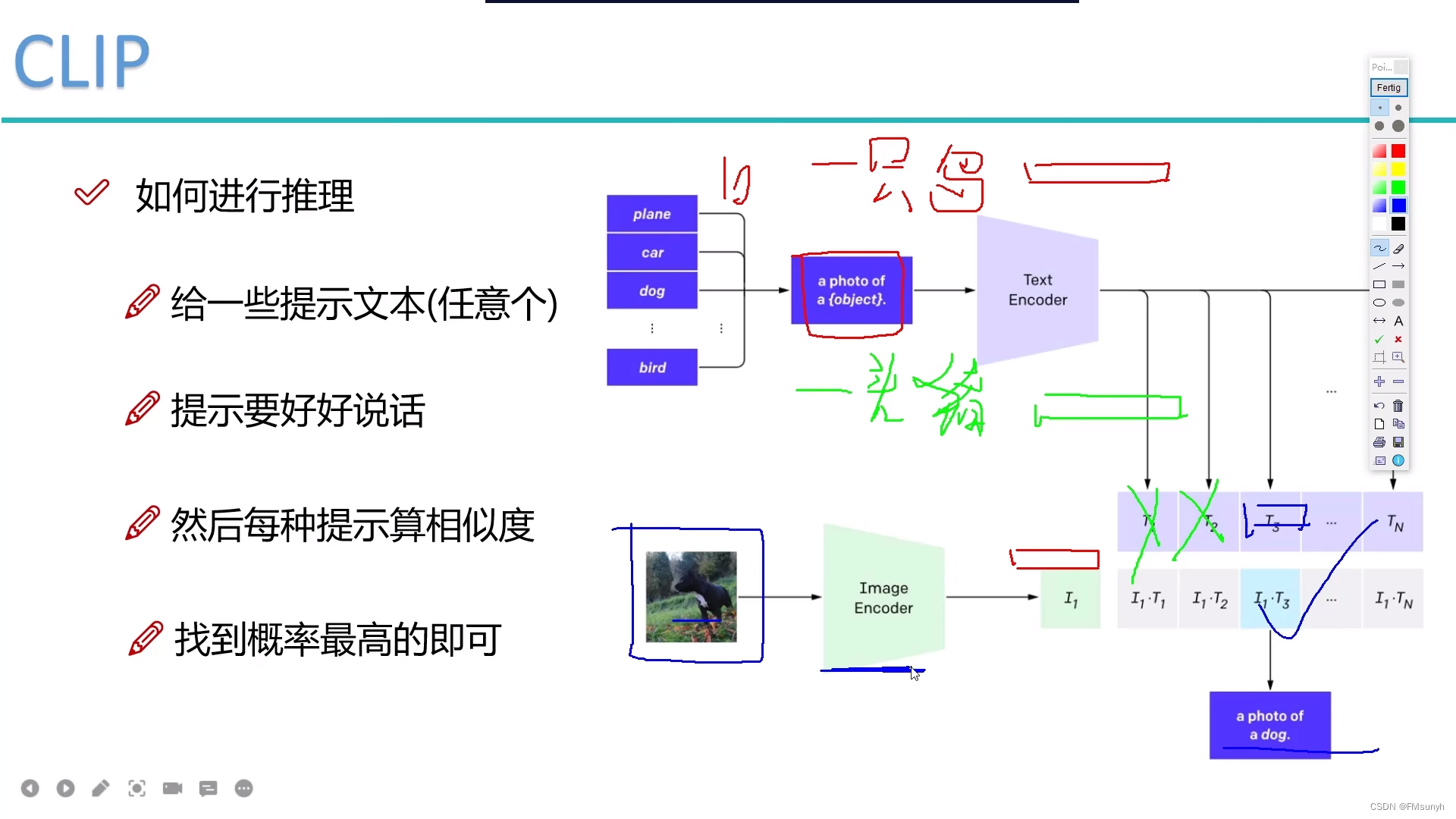
推理阶段
- 对一张图,给出假设文本提示(任意n个),预设答案n个
- 预设的文本提示,很重要,影响特征值对比的值
- 文本的预测是模糊预测的,比如:一只猪 或 有一头猪,
- 以前咱们是直接预测是猫或是狗,CLIP说 我们不这样干,不做精准的文本预测,我们考虑做相关性预测
- 计算图像数据的特征
- 计算图像特征和文本特征的相似度,相似度最高的就是答案
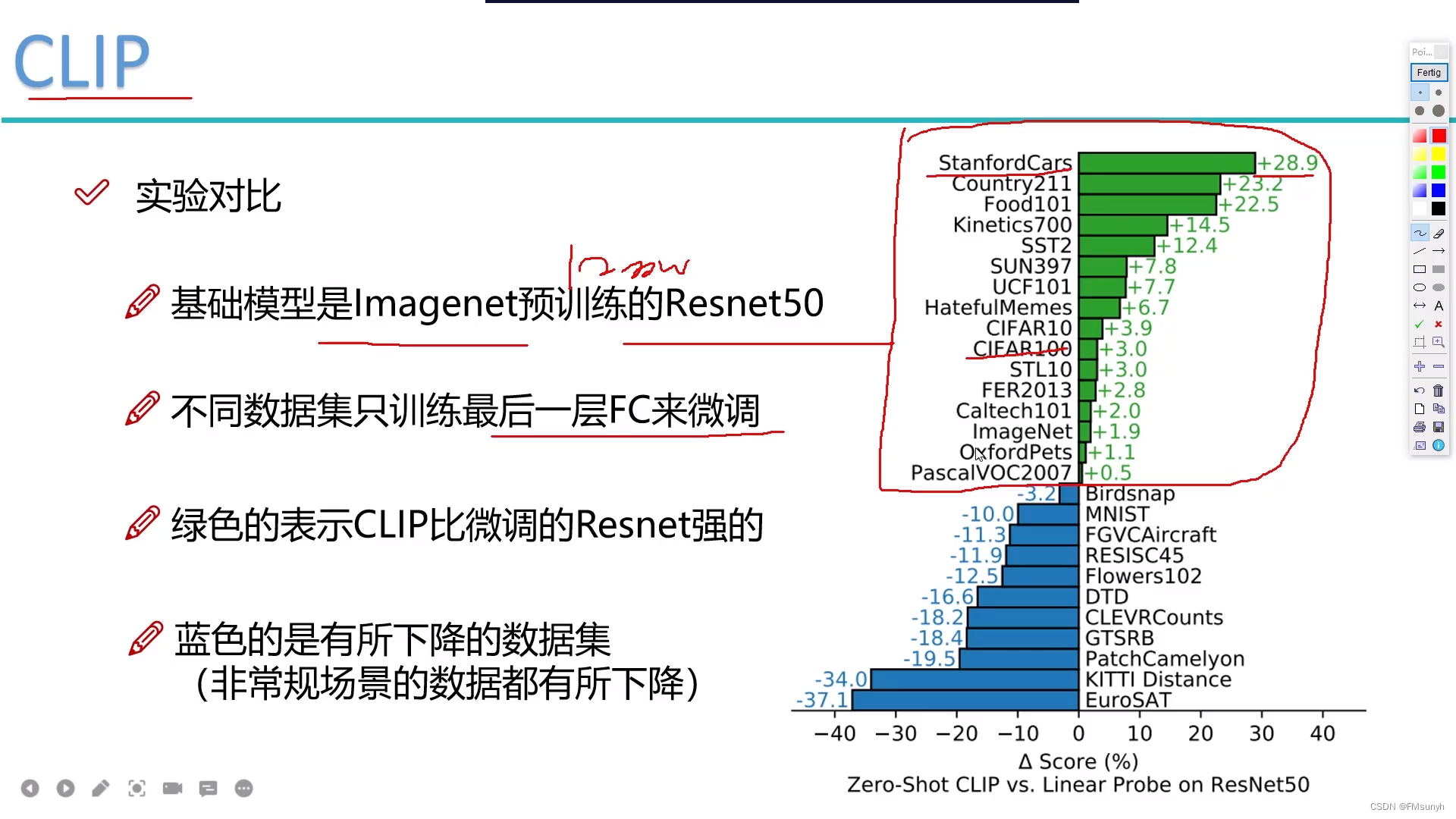
实验对比
代码测试
Hugging Face