读AI3.0笔记04_视觉识别
news2026/2/12 17:03:52
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1404058.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

zero w配置C++ opencv csi 摄像头
经过一天半的摸索,踩过了很多坑,这里记录一下
1、系统网站:https://www.raspberrypi.org/downloads/raspberry-pi-os/
由于zero w 性能不太行,我下载的是: 2、系统烧录:
这里的坑有两个,一个…
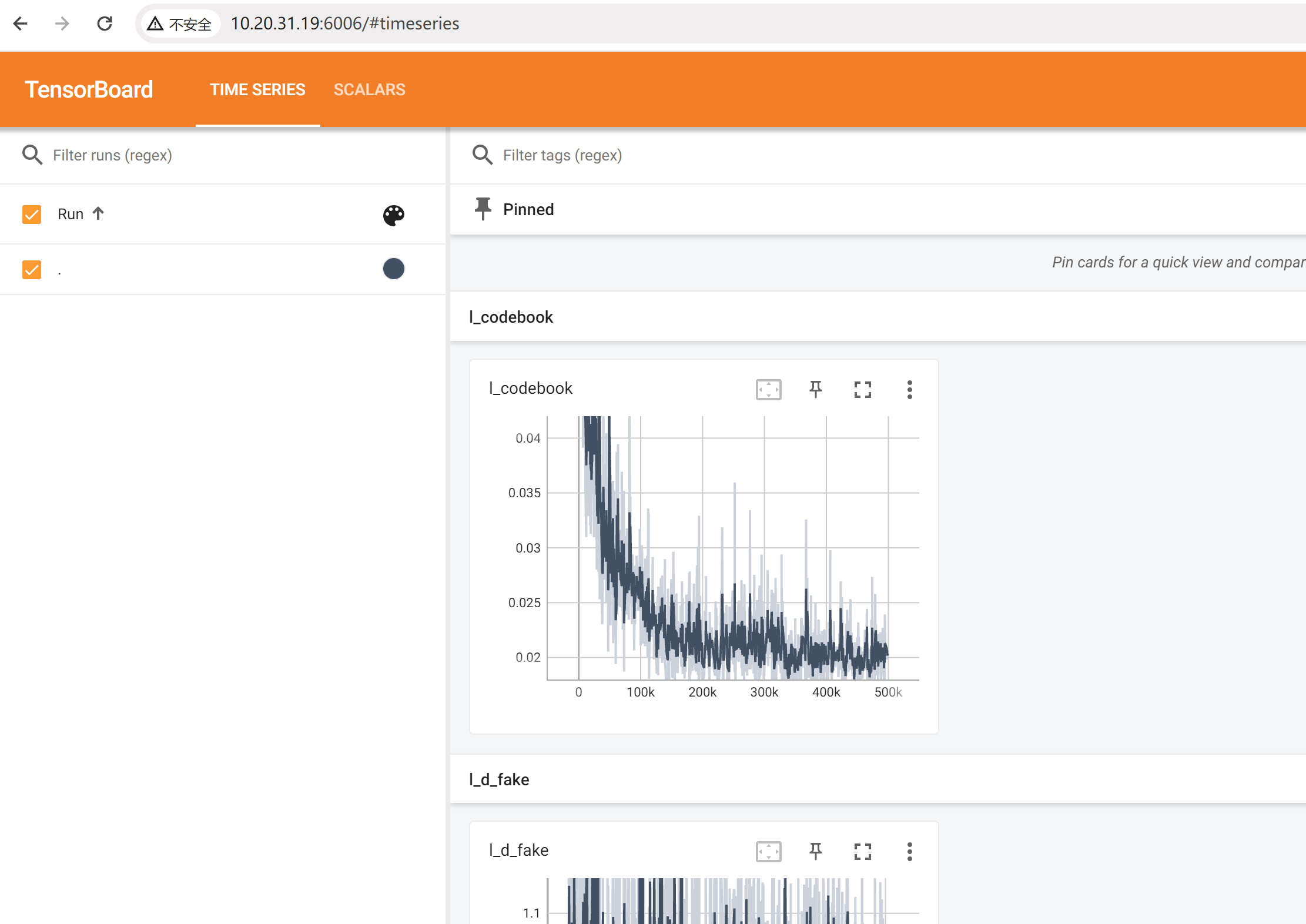
【深度学习】BasicSR训练过程记录,如何使用BasicSR训练GAN
文章目录 两种灵活的使用场景项目结构概览简化的使用方式 项目结构解读1. 代码的入口和训练的准备工作2. data和model的创建2.1 dataloader创建2.2 model的创建 3. 训练过程 动态实例化的历史演进1. If-else判断2. 动态实例化3. REGISTER注册机制 REGISTER注册机制的实现1. DAT…
React Router v6 改变页面Title
先说正事再闲聊
1、在路由表加个title字段 2、在index包裹路由 3、在App设置title 闲聊:
看到小黄波浪线了没 就是说默认不支持title字段了 出来的提示, 所以我本来是像下面这样搞的,就是感觉有点难维护,就还是用上面的方法了 …

Labview for循环精讲
本文详细介绍Labview中For循环的使用方法,从所有细节让你透彻的看明白For循环是如何使用的,如果有帮助的话记得点赞加关注~ 1. For循环结构
从最简单的地方讲起,一个常用的for循环结构是由for循环结构框图、循环次数、循环计数(i)三部分组成…

人大金仓数据库授权文件过期解决
一台用于测试的人大金仓数据库访问失败。
登录后发现服务停了。
使用命令行启动,提示服务过期。 查网上资料,说替换原有文件可以解决。
于是去官网下载一个新的,替换掉原来的授权文件。
再次启动数据库,还是提示授权文件过期。…

设计模式—行为型模式之备忘录模式
设计模式—行为型模式之备忘录模式
备忘录(Memento)模式:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便以后当需要时能将该对象恢复到原先保存的状态。该模式又叫快照模…

C++ //练习 2.35 判断下列定义推断出的类型是什么,然后编写程序进行验证。
C Primer(第5版) 练习 2.35
练习 2.35 判断下列定义推断出的类型是什么,然后编写程序进行验证。
const int i 42;
auto j i;
const auto &k i;
auto *p &i;
const auto j2 i, &k2 i;环境:Linux Ubuntu&#x…

ThreeJS快速入门指南
Three.js 介绍
Three.js 是一个开源的应用级 3D JavaScript 库,可以让开发者在网页上创建 3D 体验。Three.js 屏蔽了 WebGL的底层调用细节,让开发者能更快速的进行3D场景效果的开发。
Three.js的开发环境搭建
创建目录并使用 npm init -y 初始化 pack…

Laravel 10.x 里如何使用ffmpeg
原理上很简单,就是使用命令行去调用ffmpeg,然后分析一下输出是不是有错误。
安装
首先安装 symfony/process,主要用于包装一下,用来代替 exec, passthru, shell_exec and system 。
composer require symfony/process
composer…

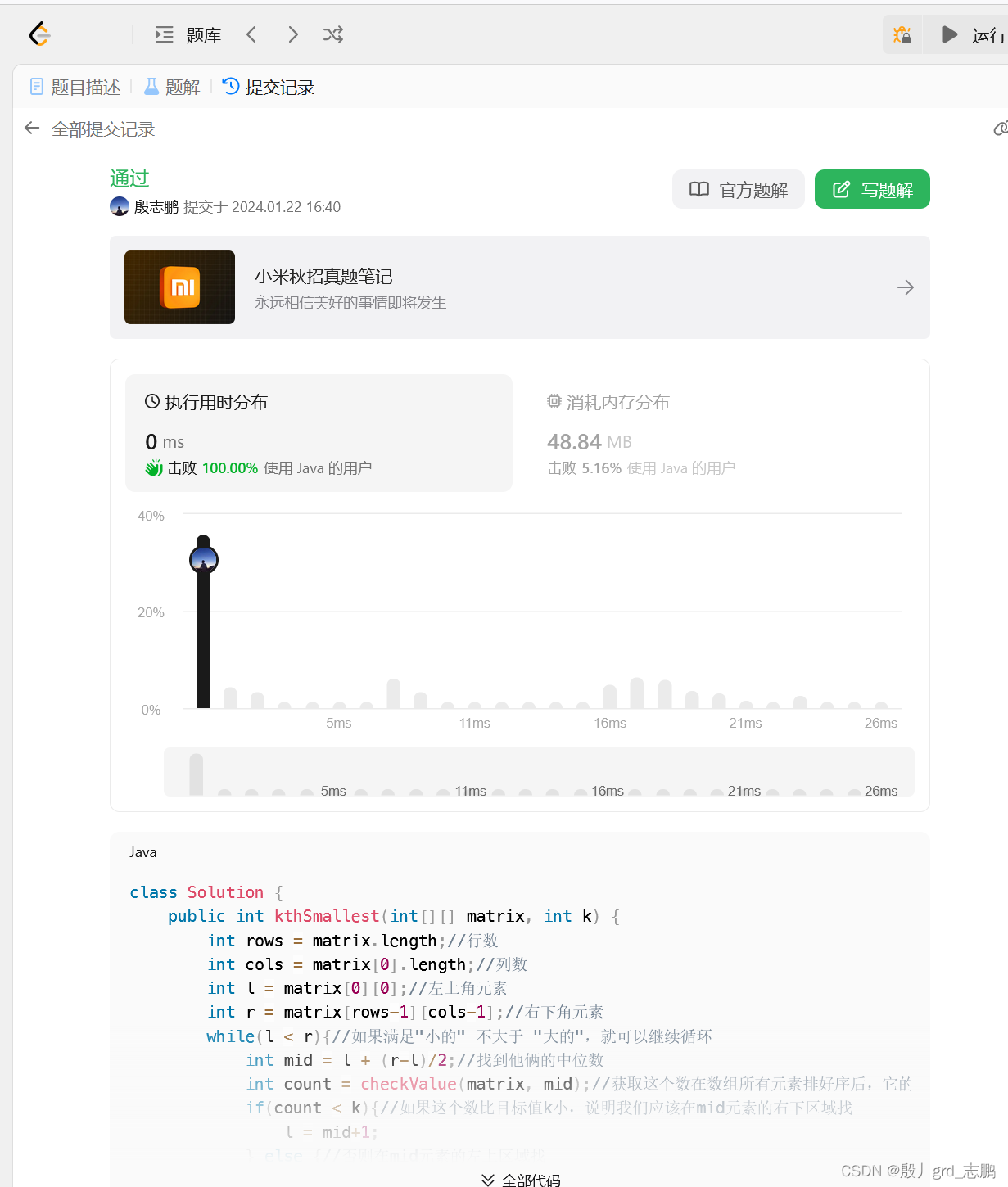
java数据结构与算法刷题-----LeetCode378. 有序矩阵中第 K 小的元素
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 解题思路 已知矩阵相对有序,可以用二分搜索,不过和…
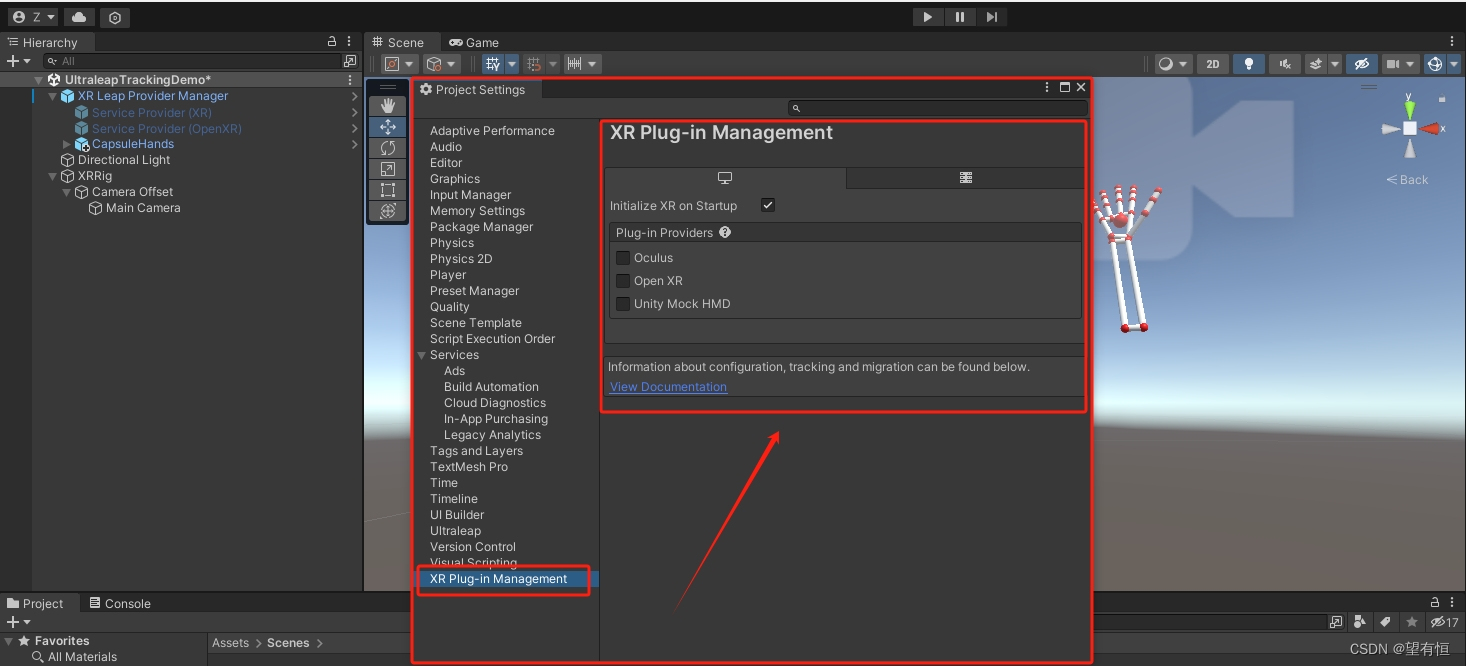
Ultraleap 3Di配置以及在 Unity 中使用 Ultraleap 3Di手部跟踪
0 开发需求
1、硬件:Ultraleap 手部追踪相机(Ultraleap 3Di) 2、软件:在计算机上安装Ultraleap Gemini (V5.2) 手部跟踪软件。 3、版本:Unity 2021 LTS 或更高版本 4、Unity XR插件管理:可从软件包管理器窗…

Pyside6在Pycharm下安装和使用
目录 一:安装
二:使用 一:安装
打开Pycharm编辑器,file-setting里Python解释器,点击小号,添加模块,搜索Pyside6,安装
安装报错,可能是默认的库安装超时,用其他的源
p…
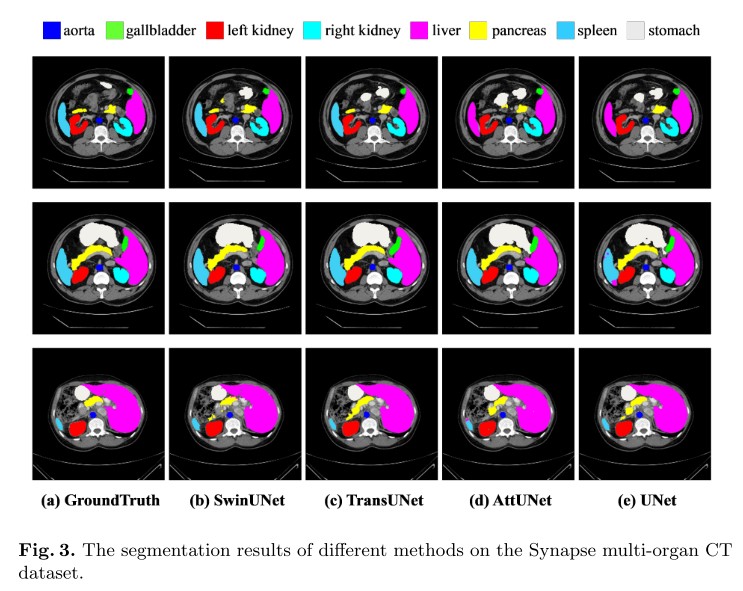
【论文阅读笔记】Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
1.介绍
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation Swin-Unet:用于医学图像分割的类Unet纯Transformer
2022年发表在 Computer Vision – ECCV 2022 Workshops Paper Code
2.摘要
在过去的几年里,卷积神经网络ÿ…
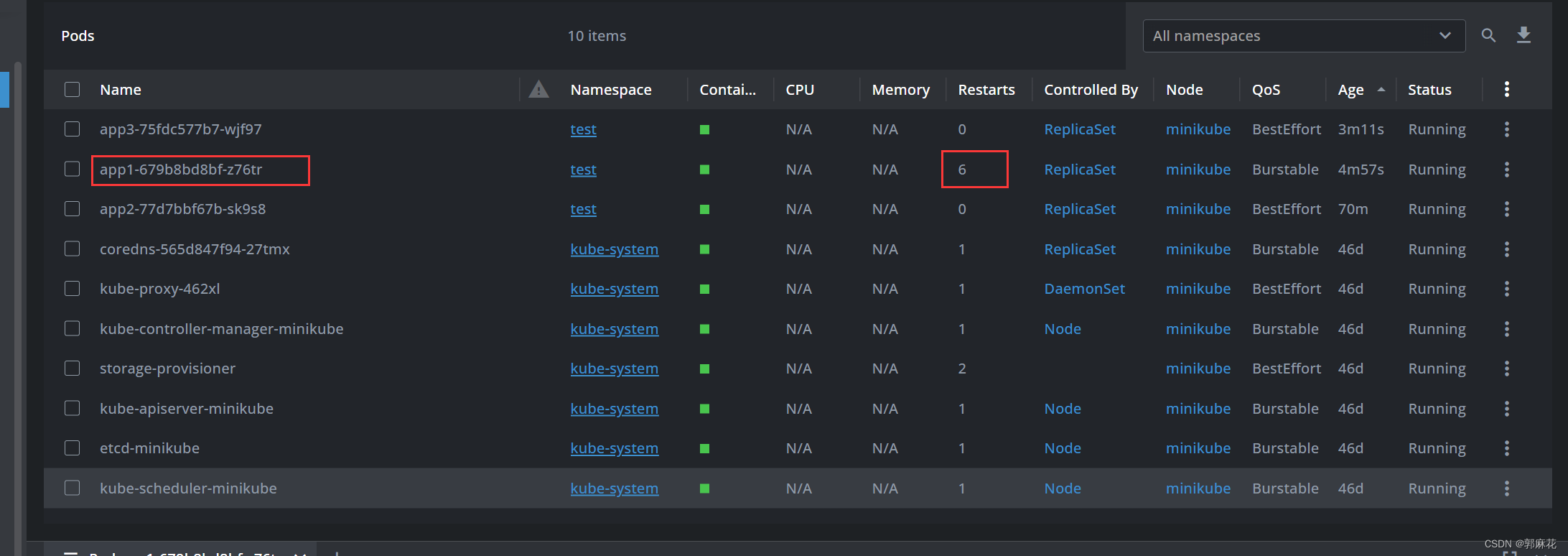
深入理解Kubernetes探针和.NET服务健康检查机制
前言
随着越来越多的软件采用云原生和微服务架构,我们面临着更多的技术挑战,比如: Kubernetes如何在容器服务异常终止、死锁等情况下,发现并自动重启服务;当服务依赖的关键服务(例如数据库,Red…
![[足式机器人]Part2 Dr. CAN学习笔记- 最优控制Optimal Control Ch07-3 线性二次型调节器(LQR)](https://img-blog.csdnimg.cn/direct/752e69a984fb4469bc62cf813284fff9.png#pic_center)
[足式机器人]Part2 Dr. CAN学习笔记- 最优控制Optimal Control Ch07-3 线性二次型调节器(LQR)
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记 - 最优控制Optimal Control Ch07-3 线性二次型调节器(LQR) 1. 数学推导2. 案例反洗与代码详解 1. 数学推导 2. 案例反洗与代码详解
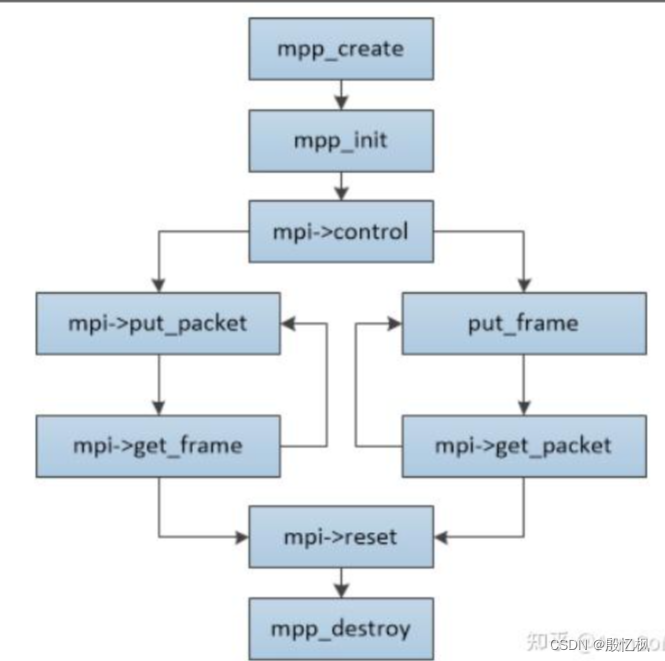
RK3568笔记十一:mpp编解码
若该文为原创文章,转载请注明原文出处。 主要是想测试MPP的解码,为后续做测试。 一、环境
1、平台:rk3568
2、开发板:ATK-RK3568正点原子板子
3、环境:buildroot
二、编译
使用的是正点原子提供的虚拟机,搭建好环…

TensorRT部署--Linux(Ubuntu)环境配置
系列文章目录
TensorRT环境配置–Linux(Ubuntu) 文章目录 系列文章目录前言一、环境配置二、CUDA下载安装三、cuDNN下载安装四、TensorRT下载安装五、模型创建总结 前言
TensorRT部署-Windows环境配置: https://blog.csdn.net/m0_70420861/article/details/135658922?csdn_s…
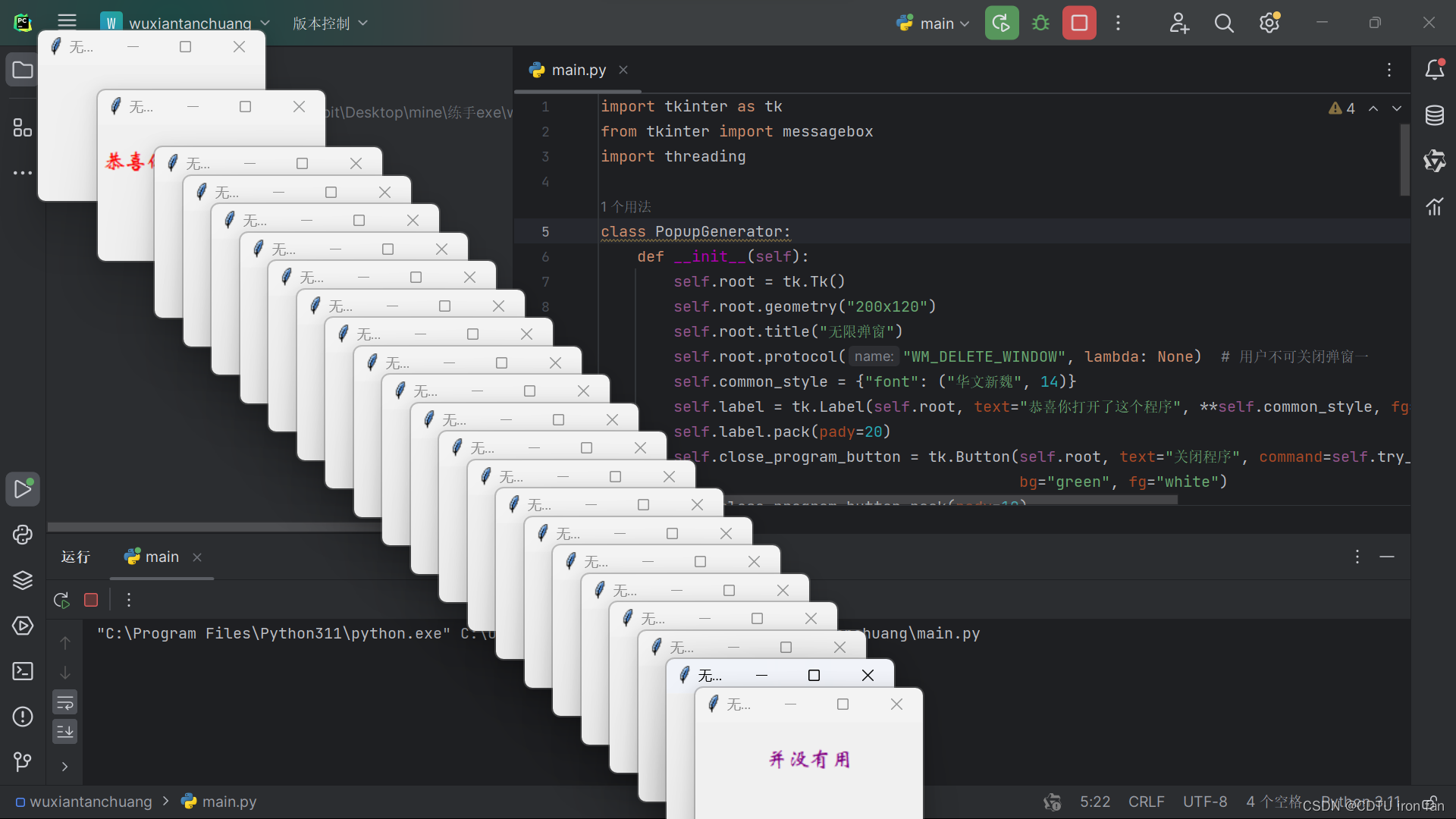
写着玩的程序:pycharm实现无限弹窗程序(非病毒程序,仅整蛊使用)
运行环境
PyCharm 2023.2.1
python3.11
具体内容
源代码
import tkinter as tk
from tkinter import messagebox
import threadingclass PopupGenerator:def __init__(self):self.root tk.Tk()self.root.geometry("200x120")self.root.title("无限弹窗&qu…