前情提要:文本大量参照了以下的博客,本文创作的初衷是为了分享博主自己的学习和理解。对于刚开始接触NLP的同学来说,可以结合唐宇迪老师的B站视频【【NLP精华版教程】强推!不愧是的最完整的NLP教程和学习路线图从原理构成开始学,学完可实战!-哔哩哔哩】 https://b23.tv/WwVQnKr和【【唐博士带你学AI】NLP最著名的语言模型-BERT 10小时精讲,原理+源码+论文,计算机博士带你打通NLP-哔哩哔哩】 https://b23.tv/0ZtLcoj这两个视频使用Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT-CSDN博客
本文的大纲是:
目录
第一部分 单词向量化
1.1 word embedding
1.1.1 理解什么是one-hot representation
1.1.2 理解什么是distribution representation
1.1.2.1我们现在提出一个比one-hot更高级的文本向量化要求:
我们来比较一下词袋模型(bag of wordsmodel)和词嵌⼊模型(word embedding model)的区别:
1.1.2.2 如何用distribution representation把单词变成一个跟单词上下文有关,有语义的向量呢?
第二部分 从Seq2Seq序列引入Encoder-Decoder模型:RNN/LSTM与GRU
2.1 什么是Seq2Seq序列问题:输入一个序列 输出一个序列
2.2 介绍Encoder-Decoder模型:RNN/LSTM与GRU
2.3 开始介绍注意力机制(Attention)
第三部分 transformer
3.1自注意力部分:
3.1.1 先来认识一下三个向量
3.1.2 attention整体流程
第三、四步:分数除以8然后softmax
3.2 多头注意力机制“multi-headed” attention
3.2.1 定义
3.2.2过程介绍
第一部分 单词向量化
1.1 word embedding
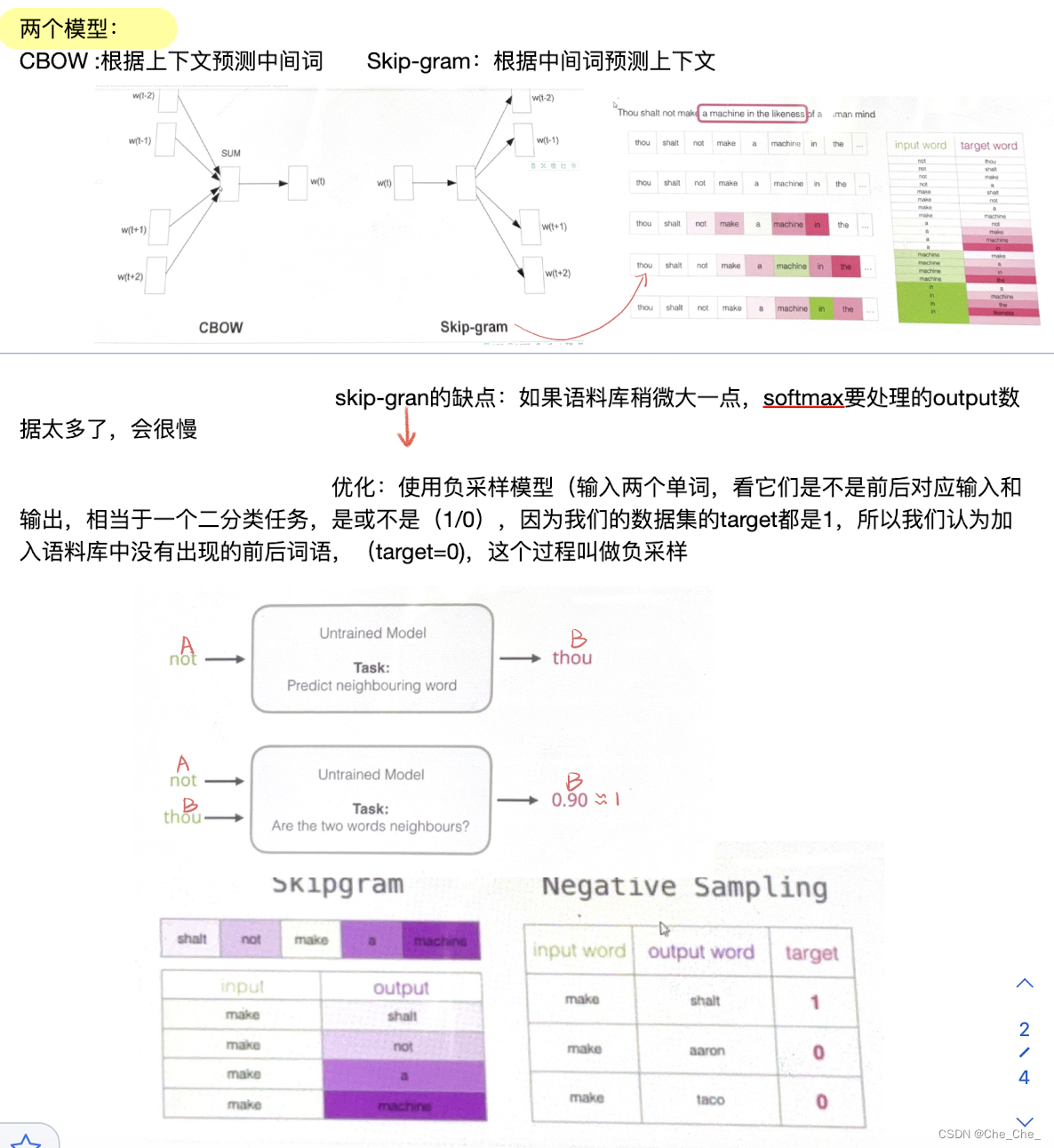
单词向量化是本节任务的一个基础,因为我们不可能直接把人类的单词文本直接输入到模型中去吧,我们要转换成计算机能够看懂的语言形式。所以,单词向量化,顾名思义,就是把单词转化成向量的形式表示,在论文中我们经常看到一个单词(embedding),用词典翻译它就是“嵌入“,我们会感到一头雾水。我们其实可以理解为:embedding就是一个映射,将单词从原先所属空间映射(嵌入)到新的多维空间(变成向量)。
在自然语言处理任务中,有两种单词向量化的方法:
·onehot representation(独热形式)
·distribution representation(分配形式)
1.1.1 理解什么是one-hot representation
我们直接用下面的例子简单最粗暴的理解:从形式上看,每个向量之间的内积为0,也就是每个向量是互相正交的,除了当前单词位置的值为1之外,其余位置的值都为0,。
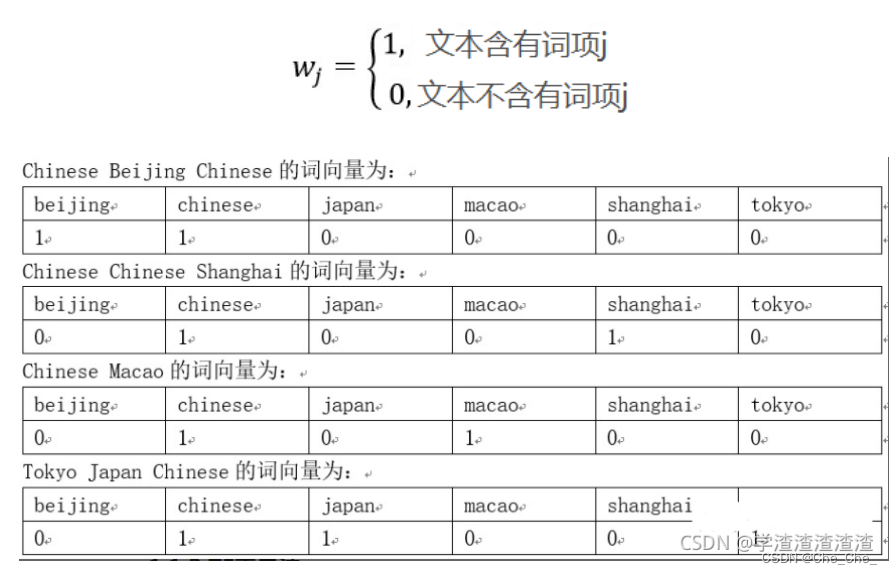
假设⽤ one-hot对句⼦进⾏表示,对句⼦分词之后,我们可以得到['我‘ , ’爱‘ , ’北京‘ , ’天安⻔‘],可以⽤one hot(独热编码)对单词进⾏编码。具体为:
“我”可以表示为[1,0,0,0]
"爱"可以表示为[0,1,0,0]
'北京'可以表示为[0,0,1,0]
'天安⻔'可以表示为[0,0,0,1]
缺点:这样单词编码之间互相正交的形式,使得的向量之间(单词)之间没有语义上的联系。
1.1.2 理解什么是distribution representation
这一节可以看唐宇迪的视频来理解:【【word2vec词向量模型】原理详解+代码实现,迪哥竟然把NLP最热门的词向量模型讲解的如此通俗易懂!-哔哩哔哩】 https://b23.tv/YJ6OMVX
不同于 one-hot粗暴的用1和0来编码,distribution representation克服了 one-hot的缺点:单词)之间没有语义上的联系。
分布式表示(distribution representation)将词转化为⼀个定⻓向量(可指定)、稠密并且互相存在语义关系(语义蕴藏在了向量的这些数字里面)的向量。
对比一下理解什么叫“蕴藏在了向量的这些数字”:
one-hot:[1,0,0,0]
distribution:[0.3,0.2,0.1,0.5] #是不是很长的像一个加权占比
1.1.2.1我们现在提出一个比one-hot更高级的文本向量化要求:
(本质上是因为distribution representation在向量化的过程中,要利用当前单词的上下文来训练模型,所以上下文语义自然蕴含在训练好的单词向量的每一维度的数值中 eg:[0.3,0.2,0.1,0.5]。
1.这个单词向量化模型要考虑单词出现的顺序:假设文本顺序为my name is chenfangyi ,出来的单词向量化中name 单词的编码(假设是[0.3,0.2,0.1,0.5])必须得体现出文本的顺序,比如只能先有name,再有is 和chenfangyi 吧,这样才符合我们人类的思维。
2.这个单词向量化模型词与词之间的等价关系要考虑到
eg:"nlp”单词要和“自然语言处理”映射到同一个向量空间,且语义相近的词在空间中离得要近。

这里插入一个跟本文主线不相关的概念:
我们来比较一下词袋模型(bag of wordsmodel)和词嵌⼊模型(word embedding model)的区别:
词袋模型是对整个文档的向量化,反映的是整个文档的单词,而本文提到的词嵌⼊模型是针对单个单词向量化,只不过在某些方法中单词的向量化与它的上下文也有关联。
1 词袋模型和编码⽅法
1.1 ⽂本向量化
⽂本向量化就是指⽤数值向量来表示⽂本的语义,即,把⼈类可读的⽂本转化成机器可读形式。
如何转化成机器可读的形式?这⾥⽤到了信息检索领域的词袋模型,词袋模型在部分保留⽂本语义的前提下对⽂本进⾏向量化表示。在后面的信息抽取博客打下基础
1.2 词袋及编码⽅法
我们先来看2个例句:
Jane wants to go to Shenzhen.
Bob wants to go to Shanghai.
将所有词语装进⼀个袋⼦⾥,不考虑其词法和语序的问题,即每个词语都
是独⽴的。例如上⾯2个例句,就可以构成⼀个词袋,袋⼦⾥包括Jane、
wants、to、go、Shenzhen、Bob、Shanghai。假设建⽴⼀个数组(或词
典)⽤于映射匹配:
[Jane, wants, to, go, Shenzhen, Bob, Shanghai]
那么上⾯两个例句就可以⽤以下两个向量表示,对应的下标与映射数组的
下标相匹配,其值为该词语出现的次数:
# 词典的key值:[Jane, wants, to, go, Shenzhen, Bob, Shanghai]
1 [1,1,2,1,1,0,0]
2 [0,1,2,1,0,1,1]
词频向量就是词袋模型,可以很明显的看到语序关系已经完全丢
失。
1.3 类型介绍
1.3.1 它也可以one-hot编码
对于每⼀个单词,我们观察该词语是否出现,出现就为1,没有出现就
是0,得到⽂本向量,规则如下:
1.3.2 TF 编码1.2例句介绍用的就是这个,TF表示法的数值计算规则为:词语序列中出现的词语其数值为词语在所在⽂本中的频次,词语序列中未出现的词语其数值为0。
1.3.3 TF- IDF表示法
TF-IDF表示法的数值计算规则为:词语序列中出现的词语其数值为词语在
所在⽂本中的频次乘以词语的逆⽂档频率,词语序列中未出现的词语其数
值为0。⽤数学式⼦表达为:

1.1.2.2 如何用distribution representation把单词变成一个跟单词上下文有关,有语义的向量呢?
假设我们的句子是A_B_C,对于单词C来说,A B就是它的上下文。我们的模型本质是一个单词预测模型已知AB,预测单词C(分类模型:最终输出的结果是整个单词语料库每个单词预测的概率),那就有疑问了,不是说是一个目的是把单词转化成蕴藏上下文语义的向量化模型吗?怎么叫单词的预测模型了?
因为我们在输入的时候,不可能直接把单词直接输入网路,我们把单词A,B表示成了一个初始化的向量(诶,那我们的任务不就结束了吗,已经单词向量化了呀?)并不是,这个初始化是我们自己定的,我们要利用这个单词预测模型来达到:不断更新单词A和B初始化向量里面的数值。
简而言之,这个单词预测模型只是一个帮手,我们其实不是要最终的输出结果,我们要知道模型每次训练除了更新权重参数,还会更新每次的输入值,我们要的就是,最终,模型训练好之后,输入的词向量里面的向量每一个维度的数值):“A”和“B”会由初始值不断更新(前向训练,反向传播)直到得到的最终的向量 。注:向量 【0.3,0.2,0.1,0.5】里面这4个数据(不一定维度一定是4,只是假设)

模型的输入是:A(假设是shalt并且已经随机向量初始化)和Bthou(假设是shalt并且已经随机向量初始化)蕴藏上下文语义的向量:
eg :
模型的输出就是:在整个语料库中每个词预测正确的概率值

总结起来就是,在这个预测模型中,随着预测单词的结果匹配语料库的概率值越来越接近真实值C,每次训练模型的输入值都会发生变化,最终我们想要的结果是蕴藏上下文语义的输入向量就得到了。
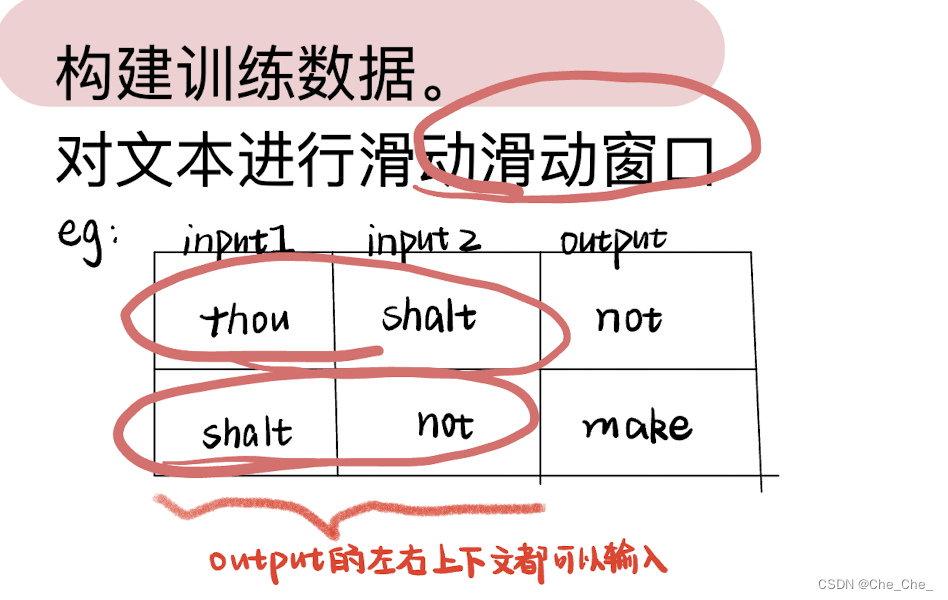
构建训练数据:

第二部分 从Seq2Seq序列引入Encoder-Decoder模型:RNN/LSTM与GRU
2.1 什么是Seq2Seq序列问题:输入一个序列 输出一个序列
比如翻译模型: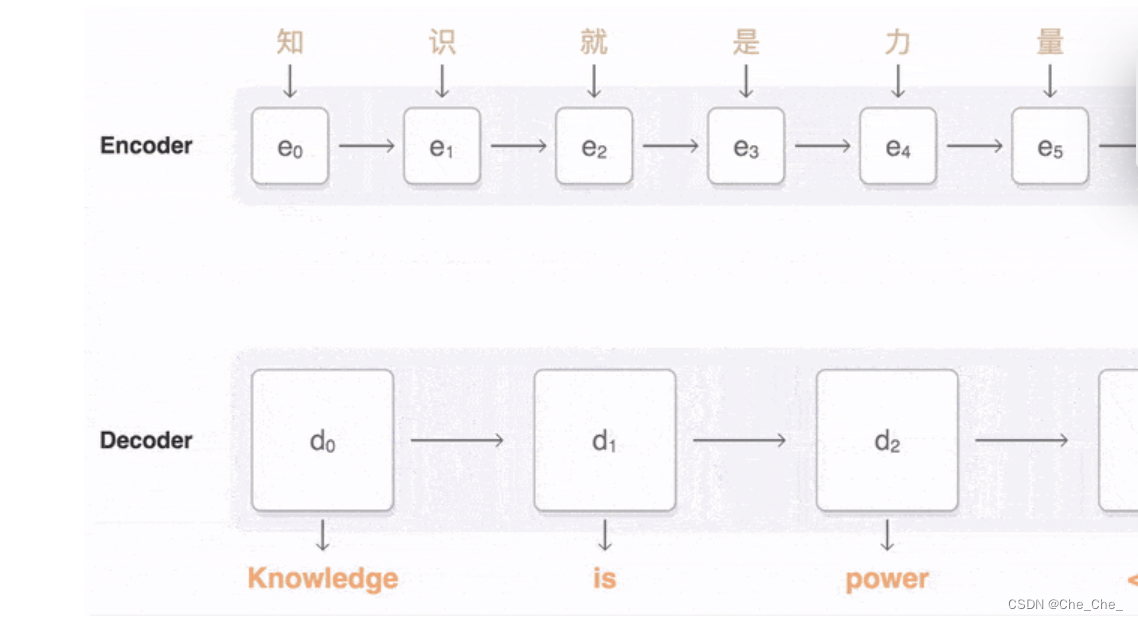
2.2 介绍Encoder-Decoder模型:RNN/LSTM与GRU
这里推荐直接去看这个大佬的博客:如何从RNN起步,一步一步通俗理解LSTM_rnn lstm-CSDN博客
大佬写的超级好,这里就不再赘述了。
2.3 开始介绍注意力机制(Attention)
·对于Seq2Seq without Attention来说:Encoder(编码器)和 Decoder(解码器)之间只有一个「向量C」来传递信息,且C的长度固定。当输入句子比较长时,所有语义完全转换为一个中间语义向量C来表示,单词原始的信息已经消失,可想而知会丢失很多细节信息

而为了解决「信息过长,信息丢失」的问题,Attention 机制就应运而生了。
·对于Seq2Seq with Attention来说:Eecoder 不再将整个输入序列编码为固定长度的「中间向量C」,而是编码成一个向量的序列(包含多个向量)。

Attention 机制:


对于中间语义编码和attention值之间的关系:看这个博主的https://blog.csdn.net/qq_45556665/article/details/127459191这一部分博客
「
「
」
我现在的理解是:经过Encoder,被编码成语义编码C,语义编码是一块高度抽象的内容。Ci 就是第i个单词的attention值,它是一个中间语义编码,解码(Y1 = f1 ( C1 ) ; Y2 = f1 ( C2 ,Y1 ) ; Y3 = f1 (C3 ,Y1,Y2 ))完成后输出序列 {Y1=“汤姆”,Y2=“追逐”,Y3=“杰瑞”}。
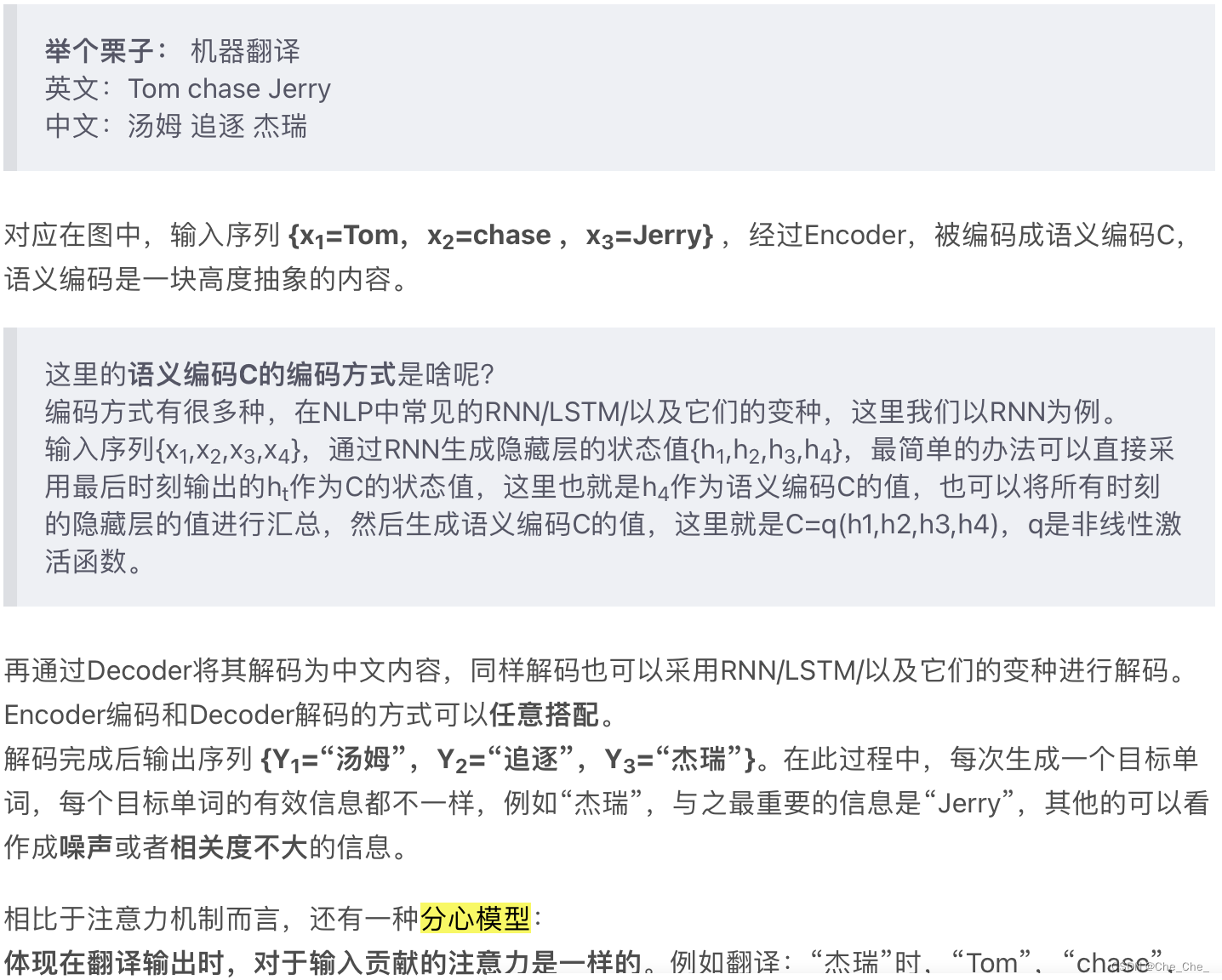

在下面的transformer中,会用到另一种机制 self-attention.
1.注意力机制Attention发生在Target的元素Query和Source中的所有元素之间。
2.而Self Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。其具体计算过程是一样的,只是计算对象发生了变化而已。
3.可以粗暴的理解为:self-attention是attention的一种特殊情况
第三部分 transformer
这一部分建议看这个视频:【【唐博士带你学AI】NLP最著名的语言模型-BERT 10小时精讲,原理+源码+论文,计算机博士带你打通NLP-哔哩哔哩】 https://b23.tv/NwnylCo
还是考虑上文中已经出现过的机器翻译的模型(Transformer一开始的提出即是为了更好的解决机器翻译问题)。

3.1自注意力部分:
3.1.1 先来认识一下三个向量
每个单词各自创建一个查询向量、一个键向量和一个值向量

3.1.2 attention整体流程

第一步:生成查询向量、键向量和值向量
第二步:计算得分:要去查询的单词(Query)去点积例子中所有词的键向量key
·q1和k1的点积(根据点积结果可以判断q1和k1这个向量的相似性)
·q1和k2的点积(根据点积结果可以判断q1和k2这个向量的相似性)
第三、四步:分数除以8然后softmax
第五、六步:值向量乘以softmax分数后对加权值向量求和
整体思路会发现,self-attention和attention 几乎一样,区别在于Target?=Source
3.2 多头注意力机制“multi-headed” attention
3.2.1 定义
简单的说就是,多来几对“
”的矩阵集合
3.2.2过程介绍
如果我们做与上述相同的自注意力计算,只需8次不同的权重矩阵运算,我们就会得到8个不同的Z矩阵


前馈层没法一下子接收多个矩阵,它需要一个单一的矩阵(矩阵中每个的行向量对应一个单词,比如矩阵的第一行对应单词Thinking、矩阵的第二行对应单词Machines)
所以我们需要一种方法把这多个矩阵合并成一个矩阵。直接把这些矩阵拼接在一起,然后乘以一个附加的权重矩阵

3.2.3 为什么要用“多头 ”,“1个头”不行吗?
我们在学习计算机视觉的时候,对于线性分类的的权值模版,在不考虑代价的情况的自然是多多益善。这样机器能学到更多的图像特征,图像分类任务会更加精准。
在本文这个任务重,通过不同的head得到不同的特征表达。总有一个头会关注到咱们想关注的点,避免在编码时遗漏了我们想要关注的点。