文章目录
- 题目
- 标题和出处
- 难度
- 题目描述
- 要求
- 示例
- 数据范围
- 前言
- 解法一
- 思路和算法
- 代码
- 复杂度分析
- 解法二
- 思路和算法
- 代码
- 复杂度分析
题目
标题和出处
标题:二叉树的序列化与反序列化
出处:297. 二叉树的序列化与反序列化
难度
8 级
题目描述
要求
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
请设计一个算法来实现二叉树的序列化与反序列化。这里不限定序列化和反序列化算法的执行逻辑,只需要保证一个二叉树可以被序列化为一个字符串并且这个字符串可以被反序列化为原始的树结构。
示例
示例 1:
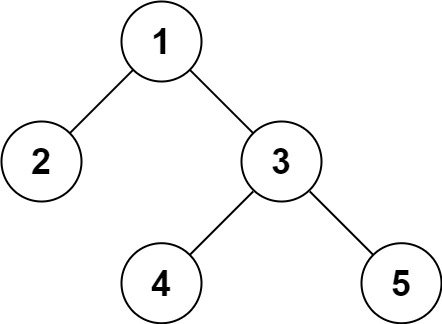
输入:
root
=
[1,2,3,null,null,4,5]
\texttt{root = [1,2,3,null,null,4,5]}
root = [1,2,3,null,null,4,5]
输出:
[1,2,3,null,null,4,5]
\texttt{[1,2,3,null,null,4,5]}
[1,2,3,null,null,4,5]
示例 2:
输入:
root
=
[]
\texttt{root = []}
root = []
输出:
[]
\texttt{[]}
[]
数据范围
- 树中结点数目在范围 [0, 10 4 ] \texttt{[0, 10}^\texttt{4}\texttt{]} [0, 104] 内
- -1000 ≤ Node.val ≤ 1000 \texttt{-1000} \le \texttt{Node.val} \le \texttt{1000} -1000≤Node.val≤1000
前言
这道题要求实现二叉树的序列化与反序列化,将二叉树序列化为一个字符串之后可以将字符串反序列化得到原始二叉树。为了能反序列化得到原始二叉树,两个不同的二叉树的序列化结果一定不同。
二叉树的序列化可以使用深度优先搜索或广度优先搜索实现,反序列化的执行逻辑由序列化的执行逻辑决定。
解法一
思路和算法
使用深度优先搜索实现二叉树的序列化时,可以存储二叉树的前序遍历的结果,包括空结点,即如果一个非空结点的某个子结点为空,则空的子结点也需要包含在序列化的结果中。序列化的结果中,非空结点使用结点值表示,空结点使用字符 ‘#’ \text{`\#'} ‘#’ 表示,每个结点之间使用逗号分隔。该序列化的方法可以确保两个不同的二叉树的序列化结果一定不同。
例如,示例 1 的二叉树的序列化结果是 “1,2,#,#,3,4,#,#,5,#,#" \text{``1,2,\#,\#,3,4,\#,\#,5,\#,\#"} “1,2,#,#,3,4,#,#,5,#,#"。
反序列化时,首先将序列化结果根据逗号分隔成字符串数组,然后遍历数组并构造二叉树。构造二叉树的过程需要模拟二叉树的前序遍历的过程,使用栈存储尚未填充左右子结点的结点。
数组的首个元素为根结点值,根据数组的首个元素创建根结点,将根结点入栈。遍历数组中的其余元素,对于每个元素,执行如下操作。
-
如果当前元素是 ‘#’ \text{`\#'} ‘#’,则创建空结点,否则根据当前元素创建非空结点。
-
栈顶结点为当前结点的父结点,判断当前结点作为父结点的左子结点还是右子结点。
-
如果父结点的左子结点为空且不为 ‘#’ \text{`\#'} ‘#’,则将当前结点作为父结点的左子结点。
-
否则,将当前结点作为父结点的右子结点,并将父结点出栈。
-
-
如果当前结点不为空,则将当前结点入栈。
遍历结束之后,即可得到原始二叉树,返回根结点。
代码
public class Codec {
public String serialize(TreeNode root) {
if (root == null) {
return "#";
}
StringBuffer sb = new StringBuffer();
sb.append(root.val);
sb.append(',');
sb.append(serialize(root.left));
sb.append(',');
sb.append(serialize(root.right));
return sb.toString();
}
public TreeNode deserialize(String data) {
if ("#".equals(data)) {
return null;
}
String[] arr = data.split(",");
TreeNode root = new TreeNode(Integer.parseInt(arr[0]));
Deque<TreeNode> stack = new ArrayDeque<TreeNode>();
stack.push(root);
boolean isLeftNull = false;
int length = arr.length;
for (int i = 1; i < length; i++) {
String str = arr[i];
TreeNode parent = stack.peek();
TreeNode node = "#".equals(str) ? null : new TreeNode(Integer.parseInt(str));
if (parent.left == null && !isLeftNull) {
parent.left = node;
if (node == null) {
isLeftNull = true;
}
} else {
parent.right = node;
stack.pop();
isLeftNull = false;
}
if (node != null) {
stack.push(node);
}
}
return root;
}
}
复杂度分析
-
时间复杂度:序列化和反序列化的时间复杂度都是 O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。序列化和反序列化的过程中,每个结点都被访问一次。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。空间复杂度包括栈空间和将字符串转化成的数组。
解法二
思路和算法
使用广度优先搜索实现二叉树的序列化时,可以存储二叉树的层序遍历的结果,包括空结点,即如果一个非空结点的某个子结点为空,则空的子结点也需要包含在序列化的结果中。序列化的结果中,非空结点使用结点值表示,空结点使用字符 ‘#’ \text{`\#'} ‘#’ 表示,每个结点之间使用逗号分隔。该序列化的方法可以确保两个不同的二叉树的序列化结果一定不同。
例如,示例 1 的二叉树的序列化结果是 “1,2,3,#,#,4,5,#,#,#,#" \text{``1,2,3,\#,\#,4,5,\#,\#,\#,\#"} “1,2,3,#,#,4,5,#,#,#,#"。
反序列化时,首先将序列化结果根据逗号分隔成字符串数组,然后遍历数组并构造二叉树。构造二叉树的过程需要模拟二叉树的层序遍历的过程,使用队列存储尚未填充左右子结点的结点。
数组的首个元素为根结点值,根据数组的首个元素创建根结点,将根结点入队列。遍历数组中的其余元素,对于每个元素,执行如下操作。
-
如果当前元素是 ‘#’ \text{`\#'} ‘#’,则创建空结点,否则根据当前元素创建非空结点。
-
队首结点为当前结点的父结点,判断当前结点作为父结点的左子结点还是右子结点。
-
如果父结点的左子结点为空且不为 ‘#’ \text{`\#'} ‘#’,则将当前结点作为父结点的左子结点。
-
否则,将当前结点作为父结点的右子结点,并将父结点出队列。
-
-
如果当前结点不为空,则将当前结点入队列。
遍历结束之后,即可得到原始二叉树,返回根结点。
代码
public class Codec {
public String serialize(TreeNode root) {
if (root == null) {
return "#";
}
StringBuffer sb = new StringBuffer();
sb.append(root.val);
sb.append(',');
Queue<TreeNode> queue = new ArrayDeque<TreeNode>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
TreeNode left = node.left, right = node.right;
if (left == null) {
sb.append('#');
} else {
sb.append(left.val);
queue.offer(left);
}
sb.append(',');
if (right == null) {
sb.append('#');
} else {
sb.append(right.val);
queue.offer(right);
}
sb.append(',');
}
sb.deleteCharAt(sb.length() - 1);
return sb.toString();
}
public TreeNode deserialize(String data) {
if ("#".equals(data)) {
return null;
}
String[] arr = data.split(",");
TreeNode root = new TreeNode(Integer.parseInt(arr[0]));
Queue<TreeNode> queue = new ArrayDeque<TreeNode>();
queue.offer(root);
boolean isLeftNull = false;
int length = arr.length;
for (int i = 1; i < length; i++) {
String str = arr[i];
TreeNode parent = queue.peek();
TreeNode node = "#".equals(str) ? null : new TreeNode(Integer.parseInt(str));
if (parent.left == null && !isLeftNull) {
parent.left = node;
if (node == null) {
isLeftNull = true;
}
} else {
parent.right = node;
queue.poll();
isLeftNull = false;
}
if (node != null) {
queue.offer(node);
}
}
return root;
}
}
复杂度分析
-
时间复杂度:序列化和反序列化的时间复杂度都是 O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。序列化和反序列化的过程中,每个结点都被访问一次。
-
空间复杂度: O ( n ) O(n) O(n),其中 n n n 是二叉树的结点数。空间复杂度包括队列空间和将字符串转化成的数组。