文章目录
- 核心功能
- 量化
- 推理引擎
- 推理服务
- 量化原理补充

部署:
在设备上运行起来,能够接受输入,返回输出。
最重要的就是性能和效率方面的考虑。大模型也是模型的一种,内存开销大,7b 要14G左右的显存。
因为是自回归的方式,需要把中间结果缓存下来,生成的结果越多,占的显存就越大。
生成过程就是采样的过程。

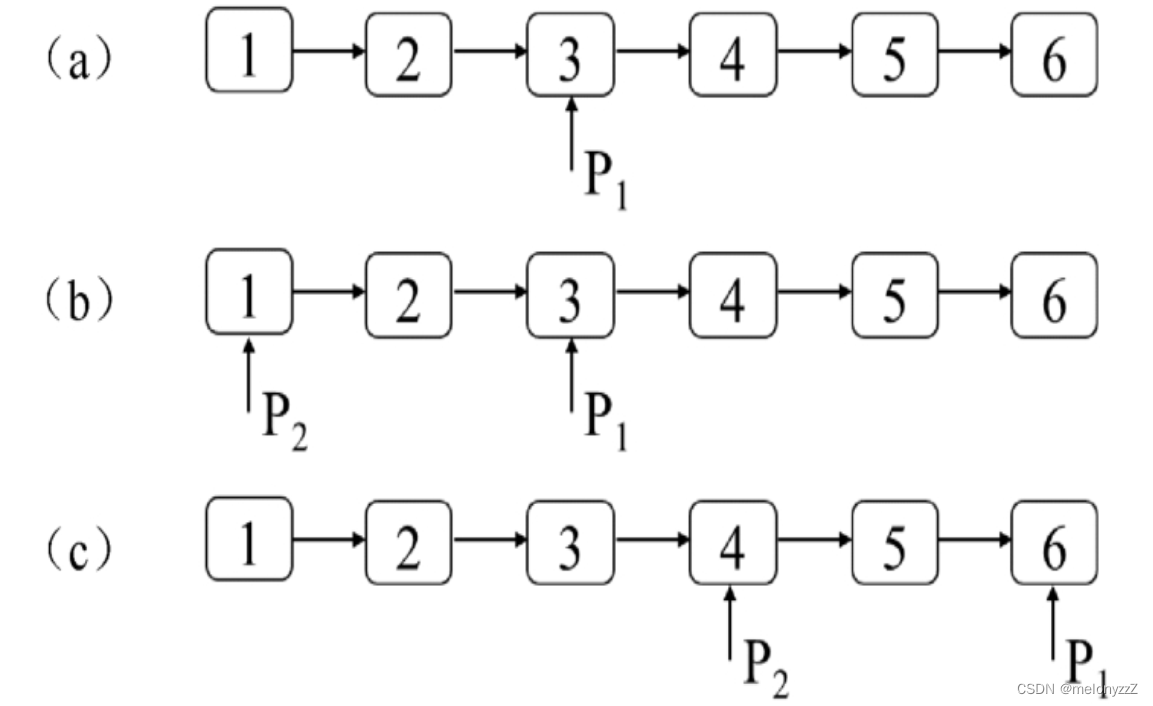
推理的时候是如何解决这种要生成万字的情况?依赖前一个生成的时候是怎么处理的?

服务也是一个框架支持起来的。
推理引擎是 C++ 写的,上层是 Python. 可以把 Python 当成一个客户端。
量化是非常有必要的。
请求的吞吐量。


提升推理的速度
核心功能
量化
降低存储空间,
大模型是访存密集型任务。
如何做量化?
- GPTQ 算法
- AWQ 算法的推理速度更快,量化的时间更短
观察到在一个矩阵,模型在推理过程中,矩阵计算、张量计算中,只有非常少部分的参数是非常重要的。


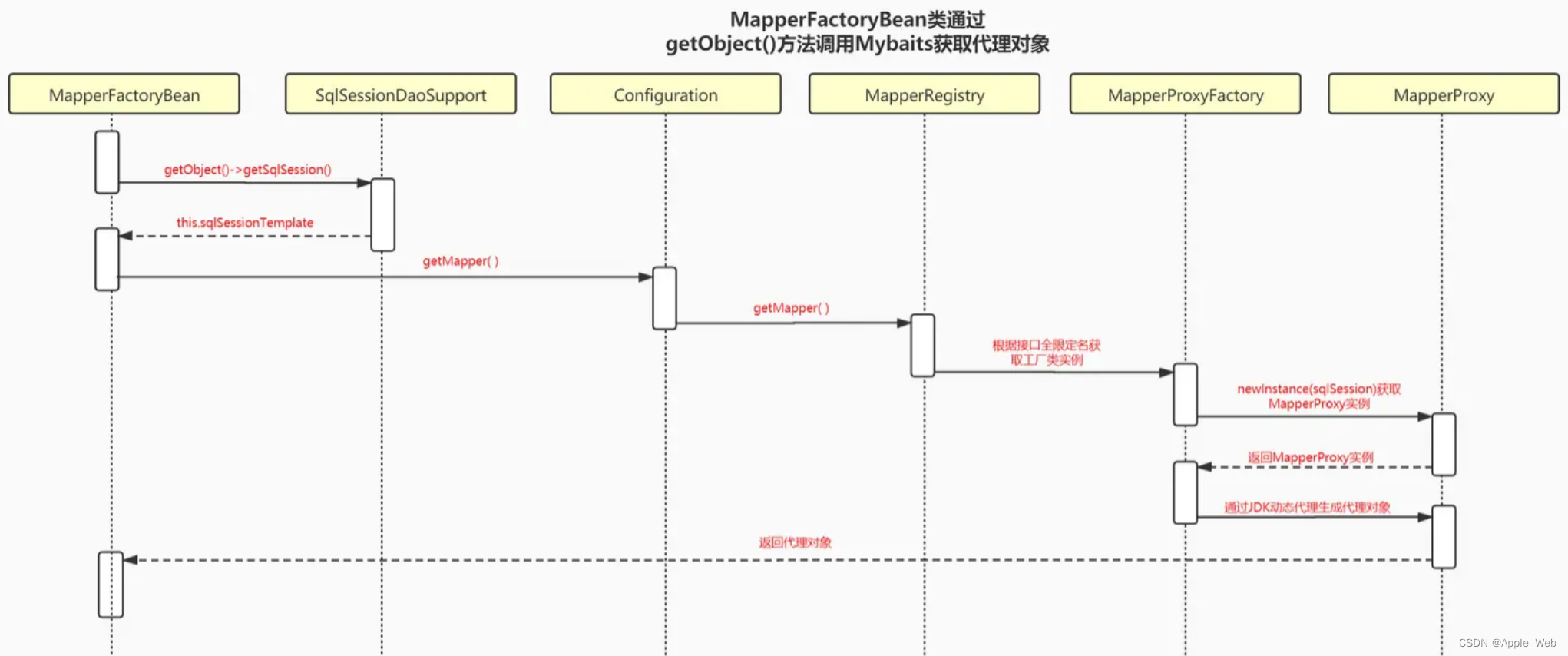
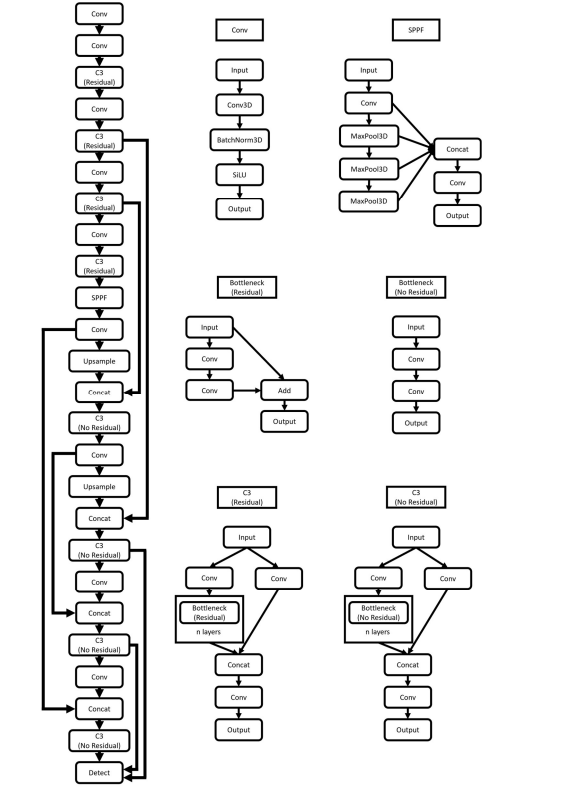
推理引擎
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。在线转换可以直接加载 Huggingface 模型,离线转换需需要先保存模型再加载。
TurboMind 是一款关于 LLM 推理的高效推理引擎,基于英伟达的 FasterTransformer 研发而成。它的主要功能包括:LLaMa 结构模型的支持,persistent batch 推理模式和可扩展的 KV 缓存管理器。




推理服务


2.3 TurboMind推理+API服务
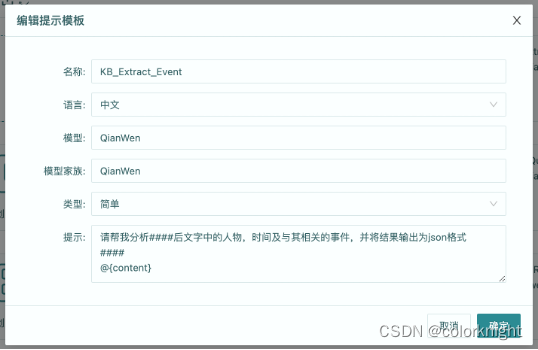
量化原理补充
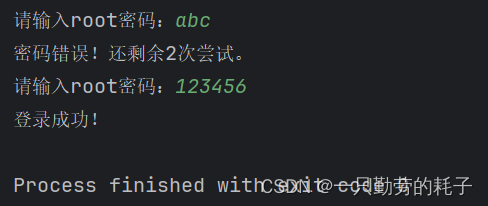
使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)