Transformer 可解释性论文整理
前段时间想进一步的了解transformer的工作原理,于是找到了几篇可解释性的文章进行阅读,发现了许多比较有趣的现象和结论,对每篇文章都有自己的深度思考和理解,在此记录,欢迎交流。
1. Visualizing and Understanding Patch Interactions in Vision Transformer
TNNLS 2023
论文链接:https://arxiv.dosf.top/pdf/2203.05922.pdf
解决了什么问题?
一种新的可解释的可视化方法来分析和解释Transformer patch之间的关键注意相互作用。
动机:
动机就是想分析transformer的各个patch之间到底是如何交互的,通过统计分析得到了一些结论,同时进行了结构和方法的设计,提出了一种精确地patch筛选的方法。具体来说,是通过忽略交互区域边界外的patch来限制每个patch的交互范围。相当于限制了每个patch的建模范围,是很大的一点创新。

方法:
1.首先对patch-wise attention进行可视化、数值分析等方法量化patch之间的交互;
2.基于patch之间的交互关系计算出多层注意力矩阵方差 u(k x n x n)与对应的head方差U,U为某patch对应的注意力区域;
3.根据注意力区域,对重要程度进行从高往低的排序,计算当前patch的responsive field。
4.将当前patch的responsive field作为patch交互区域,通过分析得到的Window区域作为监督信号设计了一个Window-free Transformer(WinfT)模型。
数据集:
Imagenet 和细粒度的 CUB dataset
结论/启发:
得到的一些比较有意思的结论:
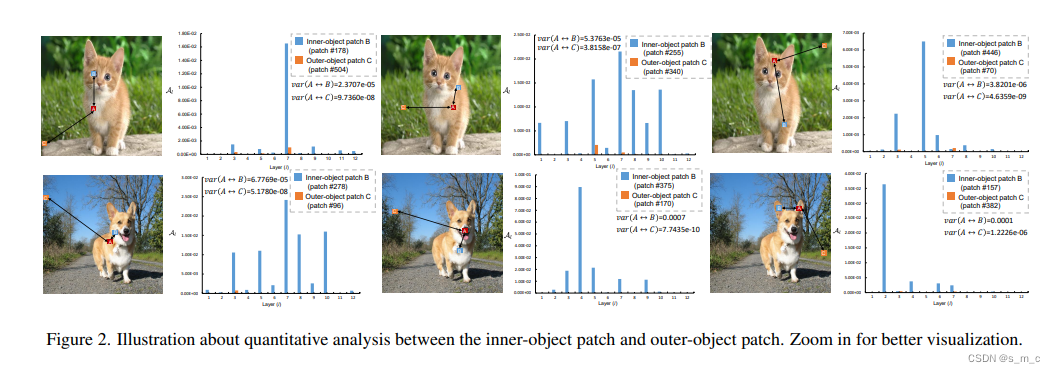
结论1:各个block的patch之间的注意力是如何变化的:即使是语义上不相关的patch之间(outer-object)也存在持续的比较低的相关性。语义上相关的patch(inner-object)之间一直保持比较高的相关性,但是不同的block之间变化的比较明显,方差比较大。
结论2:flexible and dynamic receptive field of ViT:对于一个patch而言,每一层的注意力矩阵都是不一样的,也就是说与当前的patch最相关的patch是在不断地变化的,因此是灵活的而且动态的感受野。
结论3:当前patch的交互区域大部分在其周边区域。所以说位置还是很重要的,但是transformer仍然具有cnn所不具有的全局交互的能力。
结论4:实验结果证明了每个patch的感受野都是相互独立的而且是数据依赖的(不同的数据感受野不一样,得到的自适应的感受野是根据数据集的特点得到的)。同时发现原始的ViT的全局注意力并不能带来性能的提升,我的理解是原始的 ViT 中包含了很多冗余的计算,导致性能的下降。实验结果证明了之前的方法 swim transformer 和 DynamicViT 都是将原始的 ViT的attention交互区域变小,从而提升了 ViT 的模型性能。
结论5:作者认为背景的patch越少越好。
结论6:有趣的是,在拟合合适的注意窗口后,32 × 32 patch大小的 ViT模型与16 × 16 patch大小的设置可以达到相似的性能(84.33% vs. 84.62%)。更大的补丁尺寸和更少的补丁数量可以大大降低自关注操作的计算复杂度。也就是说,使用大的patch依然可以达到很好的的分类结果。并不是patch划分的越小准确率越能高出来很多。(我认为这种发现局限于分类任务)
更多细节:
Adaptive Window Design 和Responsive Field 和 Indiscriminative Patch都是建立在原始的 ViT 的基础上的,只有对原始的ViT的量化的分析才能将本文的方法得以应用。
而且本文的方法是数据依赖的,也就是说如果是新的数据,需要重新对各个patch之间的交互进行统计分析,才能应用本文的方法。所以训练过程事比较繁琐的。
但是本文存在的最大优势就是推理阶段不需要这些统计的操作,可以直接进行复杂度和计算量较低的Window free Transformer的推理。
2. Self-Attention Attribution: Interpreting Information Interactions Inside Transformer
AAAI2021
论文链接:https://so3.cljtscd.com/scholar?hl=en&as_sdt=0%2C5&q=Self-Attention+Attribution%3A+Interpreting+Information+Interactions+Inside+Transformer&btnG=
解决了什么问题?
提出自注意力归因来解释Transformer中的信息交互。
动机:
动机就是想找到更加准确的方式解释Transformer信息交互。

方法:
相比于过去的研究,本文提出了一种自注意力机制的归因算法,可对transformer内部的信息交互进行可解释性的说明。通过该方法,模型可识别较重要的注意力head,将其他不重要的head进行有效裁剪。还可通过构建归因树(attribution tree)将不同层之间的信息交互进行直观的可视化表示。最后,文章还以bert作为扩展的实例应用,通过对归因结果分析构建的Adversarial trigger对Bert发动攻击,使得bert的预测能力显著下降。
数据集:
自然语言处理的
结论/启发:

结论:**较大的注意力分数并不意味着对最终预测的贡献更大。**不过大体的趋势是这样的,看原文图2.
启发:很重要的一点启发:归因是对head的剪枝,具体来说取某个head的attention score矩阵中分数最大的值,然后在比较。E表示期望,x表示样本(验证集样本),就是说,从验证集中随机取一些数据,跑一遍,我们就可以得到在每条数据中每个head的归因最大分数,将每个head的这个分数求期望,然后排序。这样不就是对head的一个筛选吗?能不能用到小样本跨域上,作为通道维度的筛选?
3. Transformer Interpretability Beyond Attention Visualization。
CVPR2021
论文链接:https://openaccess.thecvf.com/content/CVPR2021/papers/Chefer_Transformer_Interpretability_Beyond_Attention_Visualization_CVPR_2021_paper.pdf
解决了什么问题?
挑战:
●vit依赖跳跃连接和自注意力计算,这两者会涉及多个激活图的相加或相乘
●transformer使用了relu以外的非线性计算, 会导致负特征值而造成数值不稳定的问题。如LRU方法通过这些层传播时相关性总量会发生变化。
动机:
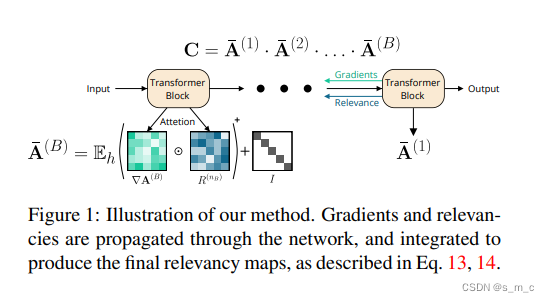
目前学界对vit的可解释性研究较少,且大多是类别无关的(利用注意力图或启发式传播注意力)。本文中作者就使用一种基于深度泰勒分解方法来计算attention中的相关性图,再把相关性分数经过各个attention层回传,以获得最终的像素热图。该方法保持了跨层的相关性不变,且是类别相关的(即可以可视化出模型对不同类别的”关注点")
方法:
贡献:
●引入- -种相关性传播机制,可以对positive和negative因素进行归因传播
●提出非参数层的归一化方法,以保证做矩阵加法和乘法时的相关性不变
●整合注意力和相关性分数,并结合多个注意力块(均值)来作为最终结果,传播到输入层
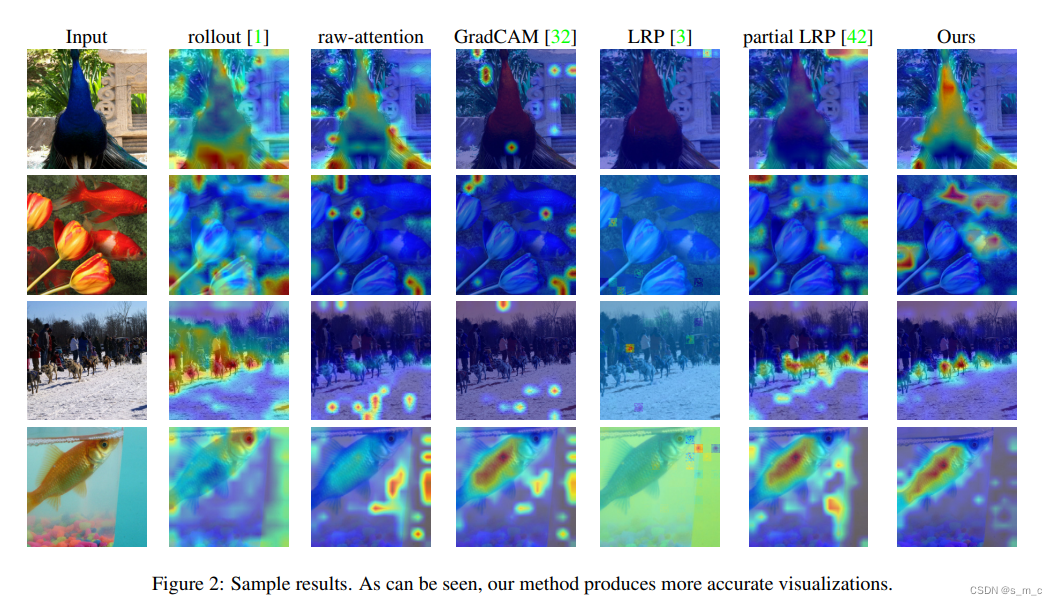
可视化效果:本文的方法得到更好的可视化结果。
4. LEVERAGING REDUNDANCY IN ATTENTION WITH REUSE TRANSFORMERS
2021年10月arXiv 一直没能发表出来
论文链接:https://arxiv.dosf.top/pdf/2110.06821.pdf
动机:
本文分析了在Transformer的不同层计算的注意力分数的相似性,并发现它们实质上是冗余的。基于此观察,提出了一种新方法,通过跨层重用注意力分数来减少 Transformer在训练和推理期间的计算和内存使用量。
方法:
基于成对product-based的注意力允许 Transformer 以依赖于输入的方式在tokens之间交换信息,并且是它们在语言和视觉方面的各种应用程序中取得成功的关键。 然而,典型的 Transformer 模型会在多个层的多个头中针对同一序列重复计算此类成对注意力分数。
我们系统地分析了这些分数在头部和层之间的经验相似性,并发现它们相当冗余,尤其是显示出高度相似性的相邻层。受这些发现的启发,我们提出了一种新颖的架构,可以在多个后续层中重用在一层中计算的注意力分数。

结论/启发:
启发:后面的层使用前面的层的attention score