文章目录
- 前言
- 一、解决问题
- 二、基本原理
- 三、添加方法
- 四、总结
前言
作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!关注免费领取深度学习算法学习资料!
一、解决问题
常见的特征融合方式主要有 FPN、PANET和BIFPN。FPN 特征融合能够解决目标检测对小物体检测困难的问题,因为小物体的像素点数量要比大物体少很多,随着网络深度的加深,大物体的特征信息得以保留,而小物体的特征信息会越来越少。对于小目标信息丢失的问题,可通过多尺度图像金字塔解决, 图像金字塔其实就是对原图像进行不同尺度的采样得到的特征图组成的特征图 层,最底层的特征图分辨率最高,越往上分辨
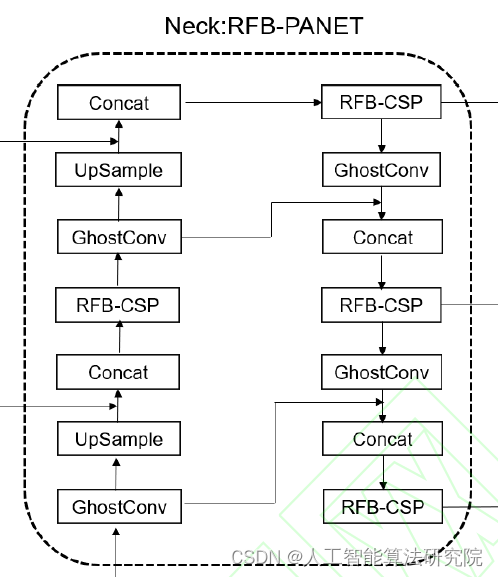
率越低。而使用图像金字塔进行推理预测,计算量很大,不利于实际使用。为了解决该问题,FPN 通过上采样增大 图像的尺寸,然后与上一个浅层的特征图进行融合,并通过卷积提取特征信息。 PANET 对 FPN 浅层特征图的特征信息提取做了优化,因为随着网络深度加深,深层特征图的语义信息被不断提取,而 FPN 自顶向下的特征融合路径中的 下采样过程,也是不断提取深层语义信息的过程,相应的,浅层语义信息会丢失的越来越多。而 PANET 增加了自下而上的特征融合路径,再次将浅层的特征信息融入到深层的特征图当中。 YOLOv5s的颈部特征提取网络采用的是PANET结构,主要由CSP结构组成,CSP结构将输入分为两部分,一部分先经过 Bottleneck模块进行n次操作,然后再进行卷积操作,而另一部分直接进行卷积操作。随后,使用Concat操作将两部分进行拼接作为输出。Bottleneck结构使得颈部特征提取网络PANET的特征提取不够充分,从而影响了YOLOv5s的检测精度。受RFB模块启发,本文提出了多分支空洞卷积结构RFB-Bottleneck替换PANET的Bottleneck结构,改进后的特征融合方式RFB-PANET更加适用于轻量化目标检测网络,RFB-PANET采用的是多分支的空洞卷积结构,相比改进前,可以通过不增加网络深度的方
二、基本原理
原文链接
源代码链接
受RFB模块启发,对PANET网络中的Bottleneck结构做了改进,RFB-Bottleneck采用了多分支的结构,每个分支会经过不同感受野的空洞卷积来提取特征(空洞卷积的膨胀率分别是1,3,5),再进行拼接操作后通过1*1卷积调整通道数得到最终的输出结构。改进后的RFB-Bottleneck结构相比Bottleneck结构,可以融合不同感受野的空洞卷积特征,通过更少的参数量获得更大的感受野,从而提取更精确的目标特征。

三、添加方法
RFB模块部分代码如下,详情关注后私信获取。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from layers import *
import torchvision.transforms as transforms
import torchvision.models as models
import torch.backends.cudnn as cudnn
import os
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU(inplace=True) if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class BasicRFB(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, scale = 0.1, visual = 1):
super(BasicRFB, self).__init__()
self.scale = scale
self.out_channels = out_planes
inter_planes = in_planes // 8
self.branch0 = nn.Sequential(
BasicConv(in_planes, 2*inter_planes, kernel_size=1, stride=stride),
BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=visual, dilation=visual, relu=False)
)
self.branch1 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),
BasicConv(inter_planes, 2*inter_planes, kernel_size=(3,3), stride=stride, padding=(1,1)),
BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=visual+1, dilation=visual+1, relu=False)
)
self.branch2 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),
BasicConv(inter_planes, (inter_planes//2)*3, kernel_size=3, stride=1, padding=1),
BasicConv((inter_planes//2)*3, 2*inter_planes, kernel_size=3, stride=stride, padding=1),
BasicConv(2*inter_planes, 2*inter_planes, kernel_size=3, stride=1, padding=2*visual+1, dilation=2*visual+1, relu=False)
)
self.ConvLinear = BasicConv(6*inter_planes, out_planes, kernel_size=1, stride=1, relu=False)
self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False)
self.relu = nn.ReLU(inplace=False)
def forward(self,x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
out = torch.cat((x0,x1,x2),1)
out = self.ConvLinear(out)
short = self.shortcut(x)
out = out*self.scale + short
out = self.relu(out)
return out
class BasicRFB_a(nn.Module):
def __init__(self, in_planes, out_planes, stride=1, scale = 0.1):
super(BasicRFB_a, self).__init__()
self.scale = scale
self.out_channels = out_planes
inter_planes = in_planes //4
self.branch0 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),
BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=1,relu=False)
)
self.branch1 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),
BasicConv(inter_planes, inter_planes, kernel_size=(3,1), stride=1, padding=(1,0)),
BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=3, dilation=3, relu=False)
)
self.branch2 = nn.Sequential(
BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),
BasicConv(inter_planes, inter_planes, kernel_size=(1,3), stride=stride, padding=(0,1)),
BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=3, dilation=3, relu=False)
)
self.branch3 = nn.Sequential(
BasicConv(in_planes, inter_planes//2, kernel_size=1, stride=1),
BasicConv(inter_planes//2, (inter_planes//4)*3, kernel_size=(1,3), stride=1, padding=(0,1)),
BasicConv((inter_planes//4)*3, inter_planes, kernel_size=(3,1), stride=stride, padding=(1,0)),
BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=5, dilation=5, relu=False)
)
self.ConvLinear = BasicConv(4*inter_planes, out_planes, kernel_size=1, stride=1, relu=False)
self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False)
self.relu = nn.ReLU(inplace=False)
def forward(self,x):
x0 = self.branch0(x)
x1 = self.branch1(x)
x2 = self.branch2(x)
x3 = self.branch3(x)
out = torch.cat((x0,x1,x2,x3),1)
out = self.ConvLinear(out)
short = self.shortcut(x)
out = out*self.scale + short
out = self.relu(out)
return out
class RFBNet(nn.Module):
"""RFB Net for object detection
The network is based on the SSD architecture.
Each multibox layer branches into
1) conv2d for class conf scores
2) conv2d for localization predictions
3) associated priorbox layer to produce default bounding
boxes specific to the layer's feature map size.
See: https://arxiv.org/pdf/1711.07767.pdf for more details on RFB Net.
Args:
phase: (string) Can be "test" or "train"
base: VGG16 layers for input, size of either 300 or 512
extras: extra layers that feed to multibox loc and conf layers
head: "multibox head" consists of loc and conf conv layers
"""
def __init__(self, phase, size, base, extras, head, num_classes):
super(RFBNet, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.size = size
if size == 300:
self.indicator = 3
elif size == 512:
self.indicator = 5
else:
print("Error: Sorry only SSD300 and SSD512 are supported!")
return
# vgg network
self.base = nn.ModuleList(base)
# conv_4
self.Norm = BasicRFB_a(512,512,stride = 1,scale=1.0)
self.extras = nn.ModuleList(extras)
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if self.phase == 'test':
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""Applies network layers and ops on input image(s) x.
Args:
x: input image or batch of images. Shape: [batch,3*batch,300,300].
Return:
Depending on phase:
test:
list of concat outputs from:
1: softmax layers, Shape: [batch*num_priors,num_classes]
2: localization layers, Shape: [batch,num_priors*4]
3: priorbox layers, Shape: [2,num_priors*4]
train:
list of concat outputs from:
1: confidence layers, Shape: [batch*num_priors,num_classes]
2: localization layers, Shape: [batch,num_priors*4]
3: priorbox layers, Shape: [2,num_priors*4]
"""
sources = list()
loc = list()
conf = list()
# apply vgg up to conv4_3 relu
for k in range(23):
x = self.base[k](x)
s = self.Norm(x)
sources.append(s)
# apply vgg up to fc7
for k in range(23, len(self.base)):
x = self.base[k](x)
# apply extra layers and cache source layer outputs
for k, v in enumerate(self.extras):
x = v(x)
if k < self.indicator or k%2 ==0:
sources.append(x)
# apply multibox head to source layers
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
#print([o.size() for o in loc])
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
if self.phase == "test":
output = (
loc.view(loc.size(0), -1, 4), # loc preds
self.softmax(conf.view(-1, self.num_classes)), # conf preds
)
else:
output = (
loc.view(loc.size(0), -1, 4),
conf.view(conf.size(0), -1, self.num_classes),
)
return output
def load_weights(self, base_file):
other, ext = os.path.splitext(base_file)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
self.load_state_dict(torch.load(base_file))
print('Finished!')
else:
print('Sorry only .pth and .pkl files supported.')
# This function is derived from torchvision VGG make_layers()
# https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py
def vgg(cfg, i, batch_norm=False):
layers = []
in_channels = i
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C':
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
}
def add_extras(size, cfg, i, batch_norm=False):
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
if in_channels == 256 and size == 512:
layers += [BasicRFB(in_channels, cfg[k+1], stride=2, scale = 1.0, visual=1)]
else:
layers += [BasicRFB(in_channels, cfg[k+1], stride=2, scale = 1.0, visual=2)]
else:
layers += [BasicRFB(in_channels, v, scale = 1.0, visual=2)]
in_channels = v
if size == 512:
layers += [BasicConv(256,128,kernel_size=1,stride=1)]
layers += [BasicConv(128,256,kernel_size=4,stride=1,padding=1)]
elif size ==300:
layers += [BasicConv(256,128,kernel_size=1,stride=1)]
layers += [BasicConv(128,256,kernel_size=3,stride=1)]
layers += [BasicConv(256,128,kernel_size=1,stride=1)]
layers += [BasicConv(128,256,kernel_size=3,stride=1)]
else:
print("Error: Sorry only RFBNet300 and RFBNet512 are supported!")
return
return layers
extras = {
'300': [1024, 'S', 512, 'S', 256],
'512': [1024, 'S', 512, 'S', 256, 'S', 256,'S',256],
}
def multibox(size, vgg, extra_layers, cfg, num_classes):
loc_layers = []
conf_layers = []
vgg_source = [-2]
for k, v in enumerate(vgg_source):
if k == 0:
loc_layers += [nn.Conv2d(512,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers +=[nn.Conv2d(512,
cfg[k] * num_classes, kernel_size=3, padding=1)]
else:
loc_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * num_classes, kernel_size=3, padding=1)]
i = 1
indicator = 0
if size == 300:
indicator = 3
elif size == 512:
indicator = 5
else:
print("Error: Sorry only RFBNet300 and RFBNet512 are supported!")
return
for k, v in enumerate(extra_layers):
if k < indicator or k%2== 0:
loc_layers += [nn.Conv2d(v.out_channels, cfg[i]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, cfg[i]
* num_classes, kernel_size=3, padding=1)]
i +=1
return vgg, extra_layers, (loc_layers, conf_layers)
mbox = {
'300': [6, 6, 6, 6, 4, 4], # number of boxes per feature map location
'512': [6, 6, 6, 6, 6, 4, 4],
}
def build_net(phase, size=300, num_classes=21):
if phase != "test" and phase != "train":
print("Error: Phase not recognized")
return
if size != 300 and size != 512:
print("Error: Sorry only RFBNet300 and RFBNet512 are supported!")
return
return RFBNet(phase, size, *multibox(size, vgg(base[str(size)], 3),
add_extras(size, extras[str(size)], 1024),
mbox[str(size)], num_classes), num_classes)
四、总结
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
参考论文原文出自《基于改进YOLOv5s的轻量化目标检测算法》本文仅用于学术分享,如有侵权,请联系后台作删文处理。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
YOLO系列算法改进方法 | 目录一览表
💡🎈☁️1. 添加SE注意力机制
💡🎈☁️2.添加CBAM注意力机制
💡🎈☁️3. 添加CoordAtt注意力机制
💡🎈☁️4. 添加ECA通道注意力机制
💡🎈☁️5. 改进特征融合网络PANET为BIFPN
💡🎈☁️6. 增加小目标检测层
💡🎈☁️7. 损失函数改进
💡🎈☁️8. 非极大值抑制NMS算法改进Soft-nms
💡🎈☁️9. 锚框K-Means算法改进K-Means++
💡🎈☁️10. 损失函数改进为SIOU
💡🎈☁️11. 主干网络C3替换为轻量化网络MobileNetV3
💡🎈☁️12. 主干网络C3替换为轻量化网络ShuffleNetV2
💡🎈☁️13. 主干网络C3替换为轻量化网络EfficientNetv2
💡🎈☁️14. 主干网络C3替换为轻量化网络Ghostnet
💡🎈☁️15. 网络轻量化方法深度可分离卷积
💡🎈☁️16. 主干网络C3替换为轻量化网络PP-LCNet
💡🎈☁️17. CNN+Transformer——融合Bottleneck Transformers
💡🎈☁️18. 损失函数改进为Alpha-IoU损失函数
💡🎈☁️19. 非极大值抑制NMS算法改进DIoU NMS
💡🎈☁️20. Involution新神经网络算子引入网络
💡🎈☁️21. CNN+Transformer——主干网络替换为又快又强的轻量化主干EfficientFormer
💡🎈☁️22. 涨点神器——引入递归门控卷积(gnConv)
💡🎈☁️23. 引入SimAM无参数注意力
💡🎈☁️24. 引入量子启发的新型视觉主干模型WaveMLP(可尝试发SCI)
💡🎈☁️25. 引入Swin Transformer
💡🎈☁️26. 改进特征融合网络PANet为ASFF自适应特征融合网络
💡🎈☁️27. 解决小目标问题——校正卷积取代特征提取网络中的常规卷积
💡🎈☁️28. ICLR 2022涨点神器——即插即用的动态卷积ODConv
💡🎈☁️29. 引入Swin Transformer v2.0版本
💡🎈☁️30. 引入10月4号发表最新的Transformer视觉模型MOAT结构
💡🎈☁️31. CrissCrossAttention注意力机制
💡🎈☁️32. 引入SKAttention注意力机制
💡🎈☁️33. 引入GAMAttention注意力机制
💡🎈☁️34. 更换激活函数为FReLU
💡🎈☁️35. 引入S2-MLPv2注意力机制
💡🎈☁️36. 融入NAM注意力机制
💡🎈☁️37. 结合CVPR2022新作ConvNeXt网络
💡🎈☁️38. 引入RepVGG模型结构
💡🎈☁️39. 引入改进遮挡检测的Tri-Layer插件 | BMVC 2022
💡🎈☁️40. 轻量化mobileone主干网络引入
💡🎈☁️41. 引入SPD-Conv处理低分辨率图像和小对象问题
💡🎈☁️42. 引入V7中的ELAN网络
💡🎈☁️43. 结合最新Non-local Networks and Attention结构
💡🎈☁️44. 融入适配GPU的轻量级 G-GhostNet
💡🎈☁️45. 首发最新特征融合技术RepGFPN(DAMO-YOLO)
💡🎈☁️46. 改进激活函数为ACON
💡🎈☁️47. 改进激活函数为GELU
💡🎈☁️48. 构建新的轻量网络—Slim-neck by GSConv(2022CVPR)
💡🎈☁️49. 模型剪枝、蒸馏、压缩









![Bandit算法学习[网站优化]02——epsilon-Greedy 算法](https://img-blog.csdnimg.cn/07689f6aa1504895a38e270927c306db.png)