跳转到根目录:知行合一:投资篇
已完成:
1、投资&技术
1.1.1 投资-编程基础-numpy
1.1.2 投资-编程基础-pandas
1.2 金融数据处理
1.3 金融数据可视化
2、投资方法论
2.1.1 预期年化收益率
2.1.2 一个关于y=ax+b的故事
2.1.3-数据标准化
2.1.4-相关性分析
3、投资实证
[3.1 2023这一年] 被鸽
文章目录
- 1. 致敬E大、有知有行
- 2. seaborn热力图
- 2.1. 一月效应
- 2.2. 各资产相关性
- 2.3. 相关性结论
- 2.4. 结果验证
- 2.4.1. 黄金和新能源
- 2.4.2. 黄金和房地产
- 2.4.3. 沪深300和中证500
- 3. 结论
很多人因为缺乏耐心、急于求成,总想跳过行动环节,寻求捷径,最后发现:这才是走了弯路,真正的捷径正是那条看起来漫长且低效的行动之路。
----《认知觉醒》
我们都知道,在投资的时候,要做到分散。
那什么才叫分散?我们投资的那些品种算是分散了吗?
举个例子,沪深300和中证500,算是相关性很高的品种吗?投了沪深300,还有没有必要再投中证500?
又比如,我就看好了A和B,能不能通过计算,得出这2个品种的相关性如何?
以上,就是分析相关性的目的,给我们的投资,提供数学理论基础。
1. 致敬E大、有知有行
关于相关性分析,是从有知有行整理的关于E大的系列文章中看到的。
这篇文章是:从相关性的角度谈资产配置
文章中,有一个图,印象是很深刻的:
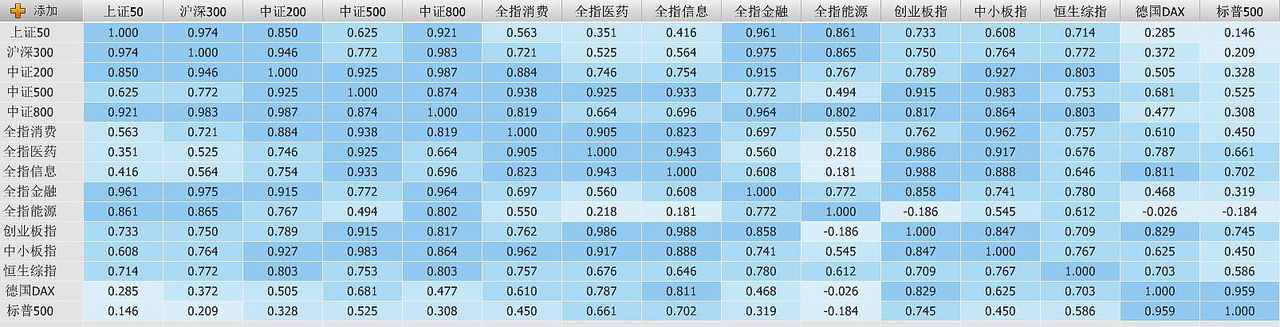
图看起来还是很容易理解的,正所谓,大道至简,越简单的东西,越容易包含很深刻的道理。
正如我们行文开头所要寻找的答案,沪深300和中证500,相关度高吗?上图结果是0.772,还是要对比着看,这个数值,基本上算是比较高了,如果要找负相关的标的,应该要寻找那种是负值的,比如“全指能源”和“创业板指”。
那有时候,我们想要自己“检测”我们看好的标的相关性如何,要怎么做呢?
2. seaborn热力图
第一个案例,是使用seaborn的heatmap热力图来绘制。
2.1. 一月效应
什么是“一月效应”?
一月效应是从统计学角度分析股市走势的一种惯常现象,指一月份的回报率往往是“正数”。最初出现一月效应的国家是美国,然后其他国家的学者也陆续发现一月效应存在其他股市之中。
我们的大A股,是否也有一月效应呢?我们做一下沪深300逐月统计其收益率情况,看看是否有所谓的1月效应?
#导入数据分析和量化常用库
import pandas as pd
import numpy as np
import qstock as qs
#导入pyecharts
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
# 只需要用收盘价进行计算和绘图用,其他字段暂不需要
index_price = qs.get_data("510300")[['close']]
# shift(1)是向下移动1个单位,然后相除正好就是当日的涨跌幅;to_period('M')是将行索引保留到月维度,便于后面分组统计月收益率
heat_data=(index_price/index_price.shift(1)-1).to_period('M')
# 分组统计月收益率
heat_data=heat_data.groupby(heat_data.index).apply(lambda x: ((((1+x).cumprod()-1).iloc[-1])*100).round(2))
heat_data=heat_data['2012':'2024']
print(heat_data)
# 开始年份
min_year = min(heat_data.index.year.tolist())
# 终止年份
max_year = max(heat_data.index.year.tolist())
# 年份数组
years = np.arange(min_year, max_year + 1, 1)
print("years=", years)
for y in range(max_year-min_year+1):
print(y)
# 从 heat_data 取出对应年月的close值
value = [[i,j,heat_data['close'].get(str(min_year+i)+'-'+str(1+j))] for i in range(max_year-min_year+1) for j in range(12)]
month=[str(i)+'月' for i in range(1,13)] # 1月、2月、3月....12月
print("value结果是:\n", value)
# 绘图
g = (HeatMap()
.add_xaxis([str(i) for i in years])
.add_yaxis("", month, value,
label_opts=opts.LabelOpts(is_show=True, position="inside"),)
.set_global_opts(
title_opts=opts.TitleOpts(title="沪深300月收益率(%)"),
visualmap_opts=opts.VisualMapOpts(is_show=False,min_=-30,max_=30,)))
g.render_notebook()
close
date
2012-05 1.34
2012-06 -7.39
2012-07 -6.28
2012-08 -7.52
2012-09 6.04
... ...
2023-09 -1.99
2023-10 -3.25
2023-11 -2.29
2023-12 -1.80
2024-01 -4.52
[141 rows x 1 columns]
years= [2012 2013 2014 2015 2016 2017 2018 2019 2020 2021 2022 2023 2024]
0
1
2
3
4
5
6
7
8
9
10
11
12
value结果是:
[[0, 0, None], [0, 1, None], [0, 2, None], [0, 3, None], [0, 4, 1.34], [0, 5, -7.39], [0, 6, -6.28], [0, 7, -7.52], [0, 8, 6.04], [0, 9, -3.12], [0, 10, -7.48], [0, 11, 26.2], [1, 0, 8.69], [1, 1, -0.93], [1, 2, -8.95], [1, 3, -2.27], [1, 4, 8.84], [1, 5, -19.15], [1, 6, 0.69], [1, 7, 7.99], [1, 8, 5.78], [1, 9, -1.97], [1, 10, 3.45], [1, 11, -6.3], [2, 0, -7.87], [2, 1, -1.25], [2, 2, -1.9], [2, 3, 0.52], [2, 4, 0.32], [2, 5, 1.6], [2, 6, 13.76], [2, 7, -0.83], [2, 8, 6.02], [2, 9, 3.31], [2, 10, 15.06], [2, 11, 32.01], [3, 0, -3.95], [3, 1, 4.81], [3, 2, 15.7], [3, 3, 20.36], [3, 4, 1.89], [3, 5, -7.83], [3, 6, -16.1], [3, 7, -13.83], [3, 8, -6.12], [3, 9, 13.64], [3, 10, 0.79], [3, 11, 5.53], [4, 0, -24.71], [4, 1, -2.72], [4, 2, 14.61], [4, 3, -2.11], [4, 4, 0.64], [4, 5, -0.3], [4, 6, 3.5], [4, 7, 4.91], [4, 8, -2.32], [4, 9, 2.62], [4, 10, 6.95], [4, 11, -7.72], [5, 0, 2.94], [5, 1, 1.97], [5, 2, 0.3], [5, 3, -0.76], [5, 4, 1.94], [5, 5, 6.41], [5, 6, 3.27], [5, 7, 2.81], [5, 8, 0.52], [5, 9, 4.63], [5, 10, -0.22], [5, 11, 0.61], [6, 0, 6.64], [6, 1, -6.49], [6, 2, -3.43], [6, 3, -4.06], [6, 4, 1.46], [6, 5, -7.82], [6, 6, 1.21], [6, 7, -5.83], [6, 8, 3.95], [6, 9, -9.75], [6, 10, 1.07], [6, 11, -6.21], [7, 0, 7.6], [7, 1, 16.12], [7, 2, 6.2], [7, 3, 0.77], [7, 4, -7.43], [7, 5, 6.9], [7, 6, 1.05], [7, 7, -0.98], [7, 8, 0.23], [7, 9, 2.15], [7, 10, -1.61], [7, 11, 7.64], [8, 0, -2.62], [8, 1, -1.7], [8, 2, -7.23], [8, 3, 7.05], [8, 4, -1.16], [8, 5, 8.7], [8, 6, 14.67], [8, 7, 2.77], [8, 8, -4.96], [8, 9, 2.54], [8, 10, 6.12], [8, 11, 5.39], [9, 0, 2.66], [9, 1, -0.37], [9, 2, -5.45], [9, 3, 1.61], [9, 4, 4.27], [9, 5, -1.6], [9, 6, -7.61], [9, 7, 0.15], [9, 8, 1.2], [9, 9, 0.97], [9, 10, -1.47], [9, 11, 2.06], [10, 0, -7.9], [10, 1, 0.38], [10, 2, -7.95], [10, 3, -4.97], [10, 4, 1.91], [10, 5, 10.59], [10, 6, -6.58], [10, 7, -1.93], [10, 8, -6.81], [10, 9, -8.11], [10, 10, 10.08], [10, 11, 0.71], [11, 0, 7.49], [11, 1, -2.15], [11, 2, -0.52], [11, 3, -0.63], [11, 4, -5.64], [11, 5, 2.14], [11, 6, 5.3], [11, 7, -6.1], [11, 8, -1.99], [11, 9, -3.25], [11, 10, -2.29], [11, 11, -1.8], [12, 0, -4.52], [12, 1, None], [12, 2, None], [12, 3, None], [12, 4, None], [12, 5, None], [12, 6, None], [12, 7, None], [12, 8, None], [12, 9, None], [12, 10, None], [12, 11, None]]

上面就是用热力图绘制的每个月的收益率情况,从13到23年的1月份,5年是下跌的6年是上涨的,并没有非常特别。
倒是7月和12月上涨的概率稍大些。
所以:不要光听所谓的名词,自己算一算自己的标的的历史回测,是否有这样的效果。
上面的案例,直接换一下qs.get_data("510300") 的证券代码,就可以回测其他标的了。
2.2. 各资产相关性
整体来说,就是构造一个dataframe,包含各标的的收盘价,然后通过seaborn的heatmap直接进行绘图即可。
import qstock as qs
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
#正常显示画图时出现的中文
from pylab import mpl
#这里使用微软雅黑字体
mpl.rcParams["font.sans-serif"] = ["Arial Unicode MS"] #mac
stocks_info = [
{'code': '510300', 'name': '沪深300'},
{'code': '510500', 'name': '中证500'},
{'code': '512010', 'name': '医药ETF'},
{'code': '512000', 'name': '券商ETF'},
{'code': '516160', 'name': '新能源ETF'},
{'code': '510800', 'name': '红利ETF'},
{'code': '518880', 'name': '黄金ETF'},
{'code': '512200', 'name': '房地产ETF'}
]
for stock in stocks_info:
df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据
stock['history_df'] = df # 将其存在 history_df 这个key里面。
# 只保留收盘价,合并数据
df_all = pd.DataFrame()
for stock in stocks_info:
df = stock['history_df']
df = df[['close']] # 只需要 date 和 close 2列就行了。
df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列
if df_all.size == 0:
df_all = df
else:
df_all = df_all.join(df) # join是按照index来连接的。
print(df_all)
# Plot
plt.figure(figsize=(12,10), dpi= 80)
sns.heatmap(df_all.corr(), xticklabels=df_all.corr().columns, yticklabels=df_all.corr().columns, cmap='RdYlGn', center=0, annot=True)
# Decorations
plt.title('指数相关性图', fontsize=22)
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
沪深300 中证500 医药ETF 券商ETF 新能源ETF 红利ETF 黄金ETF 房地产ETF
date
2012-05-28 1.935 NaN NaN NaN NaN NaN NaN NaN
2012-05-29 1.975 NaN NaN NaN NaN NaN NaN NaN
2012-05-30 1.967 NaN NaN NaN NaN NaN NaN NaN
2012-05-31 1.961 NaN NaN NaN NaN NaN NaN NaN
2012-06-01 1.961 NaN NaN NaN NaN NaN NaN NaN
... ... ... ... ... ... ... ... ...
2024-01-15 3.276 5.279 0.385 0.817 0.626 1.001 4.673 0.507
2024-01-16 3.298 5.274 0.385 0.826 0.636 1.004 4.677 0.502
2024-01-17 3.223 5.141 0.376 0.811 0.614 0.988 4.631 0.487
2024-01-18 3.268 5.146 0.381 0.818 0.632 0.995 4.616 0.486
2024-01-19 3.275 5.106 0.381 0.812 0.625 1.002 4.643 0.485
[2836 rows x 8 columns]
绘图结果是:

2.3. 相关性结论
-
沪深300和中证500,相关性结果达到0.81,还是比较高的。
-
医药和沪深300的相关性也很高,这倒是没想到的。如果你同时买沪深300和医药,可能并不能达到分散的效果。
-
黄金和新能源,负相关很显著,这是为什么呢?下面一节进行验证。
2.4. 结果验证
在验证结果的时候,我们是通过绘制2者的收盘价图来直观对比看一下。
然而,由于不同标的,收盘价可能绝对值相差很大,例如贵州茅台和沪深300,单位价格放一起不太好观察,所以要进行数据标准化。
数据标准化,参考之前的一篇文章: 2.1.3-数据标准化
2.4.1. 黄金和新能源
黄金和新能源,-0.77非常扎眼,主要原因是:选取的新能源标的存续时间很短,而且在较长时间里是下跌趋势。而黄金,由于在这段时间里,由于一些地缘事件和其他时间,基本趋势是向上的,所以它们俩的相关性结果,就是很强的负相关。
之前也在 2.1.3-数据标准化 这篇文章里做了绘图,黄金和新能源的收盘价走势图如下:
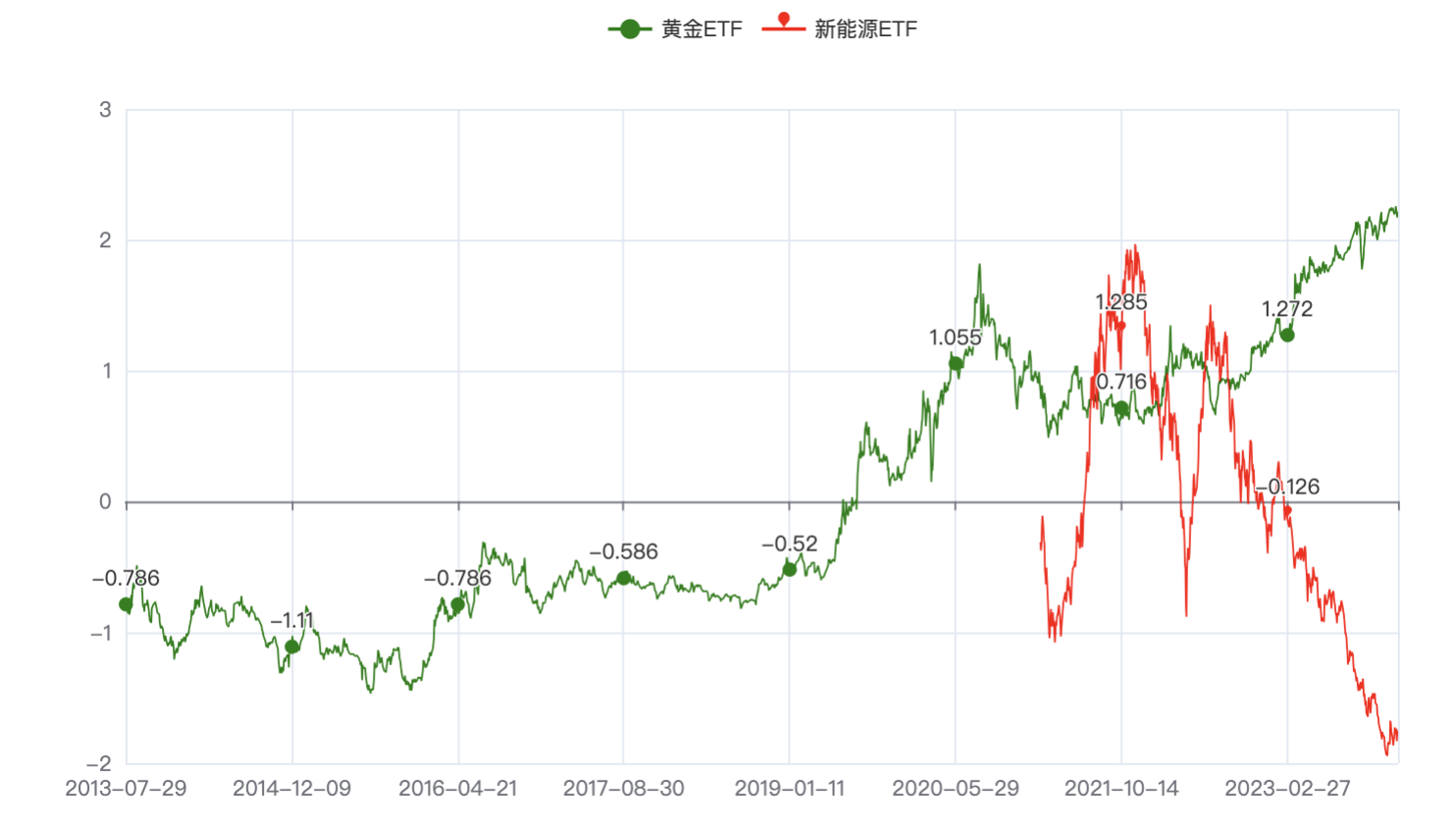
上图绘制的完整代码如下,主要就是将2者数据先进行标准化,再用pyecharts绘图即可:
import qstock as qs
import pandas as pd
#导入pyecharts
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
stocks_info = [
{'code': '518880', 'name': '黄金ETF'},
{'code': '516160', 'name': '新能源ETF'}
]
for stock in stocks_info:
df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据
stock['history_df'] = df # 将其存在 history_df 这个key里面。
# 只保留收盘价,合并数据
df_all = pd.DataFrame()
for stock in stocks_info:
df = stock['history_df']
df = df[['close']] # 只需要 date 和 close 2列就行了。
df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列
if df_all.size == 0:
df_all = df
else:
df_all = df_all.join(df) # join是按照index来连接的。
print('数据标准化前:\n', df_all) # 取第1列和第2列的方法: df_all.iloc[:, 0:2]
# 对dataframe的数据进行标准化处理
import sklearn
from sklearn import preprocessing
z_scaler = preprocessing.StandardScaler() # 建立 StandardScaler 对象
z_data = z_scaler.fit_transform(df_all) #数据标准化
z_data = pd.DataFrame(z_data) #将数据转为Dataframe
z_data.columns = df_all.columns
z_data.index = df_all.index
z_data = z_data.round(3)
print('数据标准化后:\n', z_data)
# 将标准化的数据绘图
g=(Line()
.add_xaxis(z_data.index.strftime('%Y-%m-%d').tolist())
.add_yaxis(series_name=stocks_info[0]['name'],y_axis=z_data[stocks_info[0]['name']],symbol="circle",is_symbol_show=True,itemstyle_opts={"color": "green"},symbol_size=8)
.add_yaxis(series_name=stocks_info[1]['name'],y_axis=z_data[stocks_info[1]['name']],symbol="pin",is_symbol_show=True,itemstyle_opts={"color": "red"},symbol_size=8)
)
g.render_notebook()
2.4.2. 黄金和房地产
其实,黄金和房地产的负相关性,很大一部分,还是因为房地产也是一个下降趋势。

2.4.3. 沪深300和中证500
按照我们在相关性热力图来看,沪深300和中证500,相关性值是0.81,还是很高的,我们也绘图看一下:
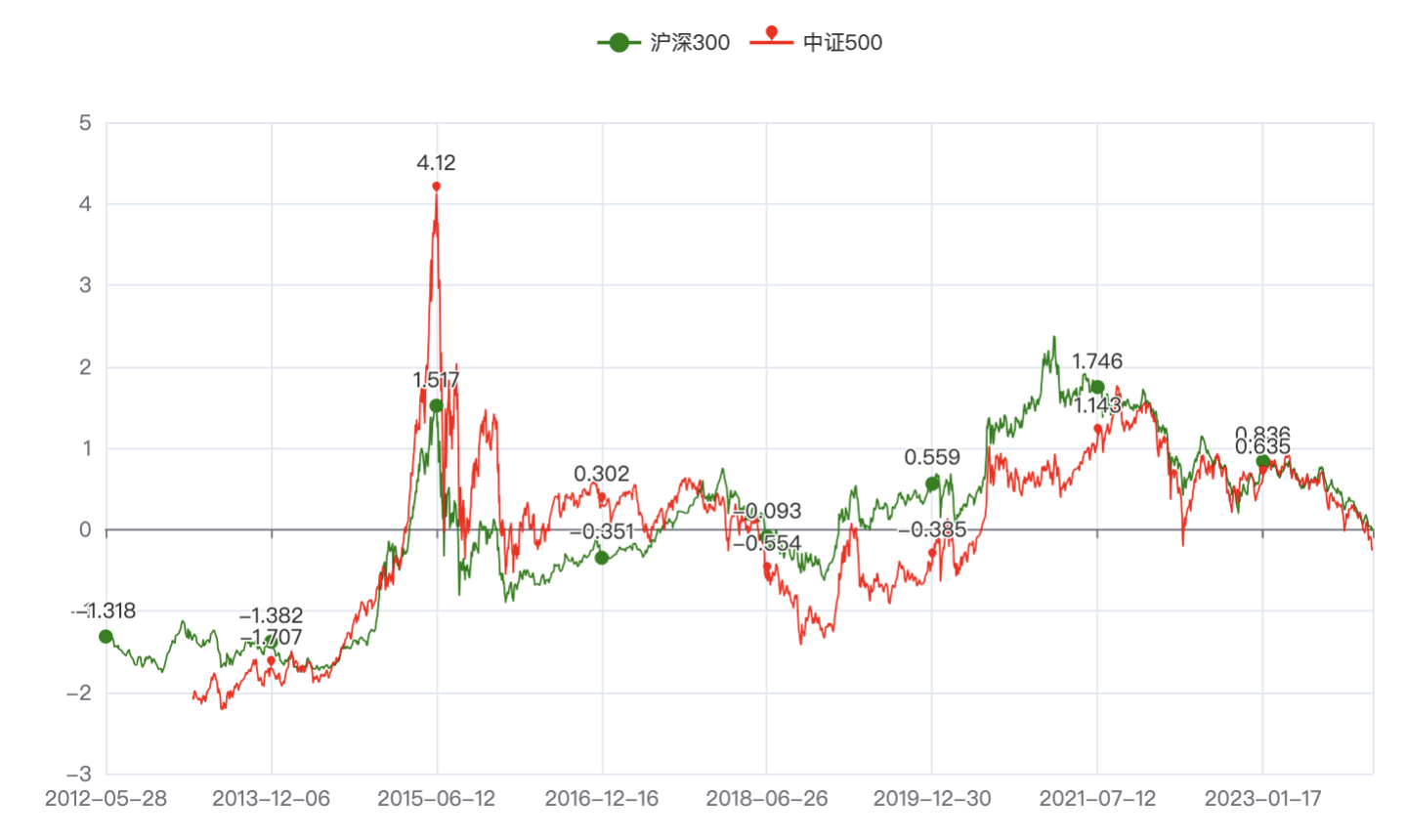
3. 结论
如果有想测算的标的,直接使用此文章里”各资产相关性“小节,进行绘图观察即可。