目录
一、Model Hierarchy
二、CPU
三、Data Cache Object
四、Tags & Data Block
五、MSHR and Write Buffer Queues
六、Memory Access Ordering
七、Coherent Bus Object
八、Simple Memory Object
九、Message Flow
1、Memory Access Ordering
2、Memory Access Ordering
官网教程:gem5: gem5_memory_syste
这个教程描述了gem5的内存子系统,重点关注CPU在进行简单内存事务(读取或写入)期间的程序流程。
一、Model Hierarchy
该文档中使用的模型由两个乱序(O3)ARM v7 CPU、相应的 L1 数据缓存和简单内存组成。它是通过以下参数运行 gem5 创建的。
configs/example/fs.py –-caches –-cpu-type=arm_detailed –-num-cpus=2gem5 使用派生对象的仿真对象作为构建内存系统的基本块。它们通过端口连接,建立了主/从层次结构。数据流在主端口上启动,而响应消息和嗅探查询则出现在从端口上。
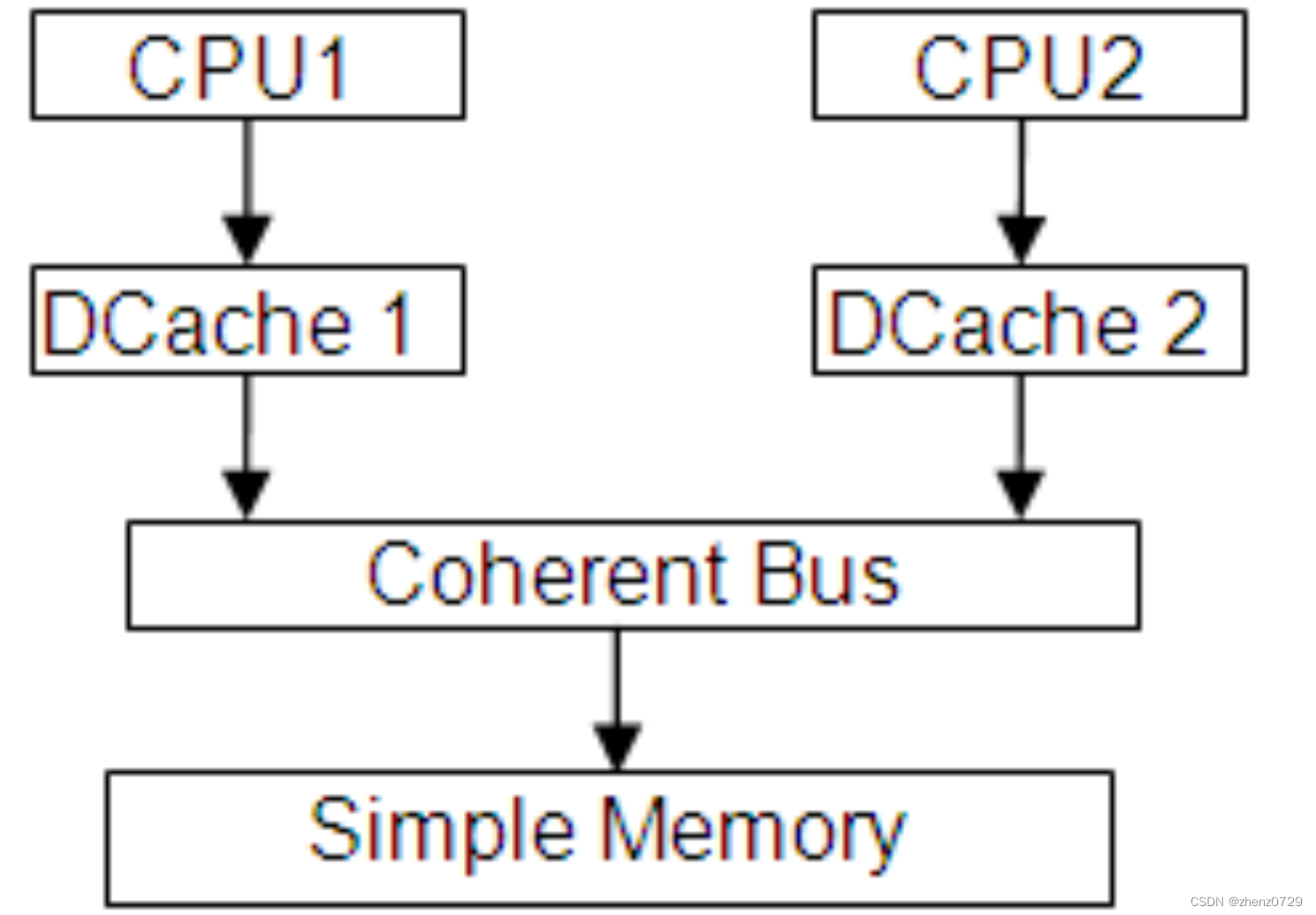
二、CPU
数据缓存对象可以实现一个标准的缓存结构。
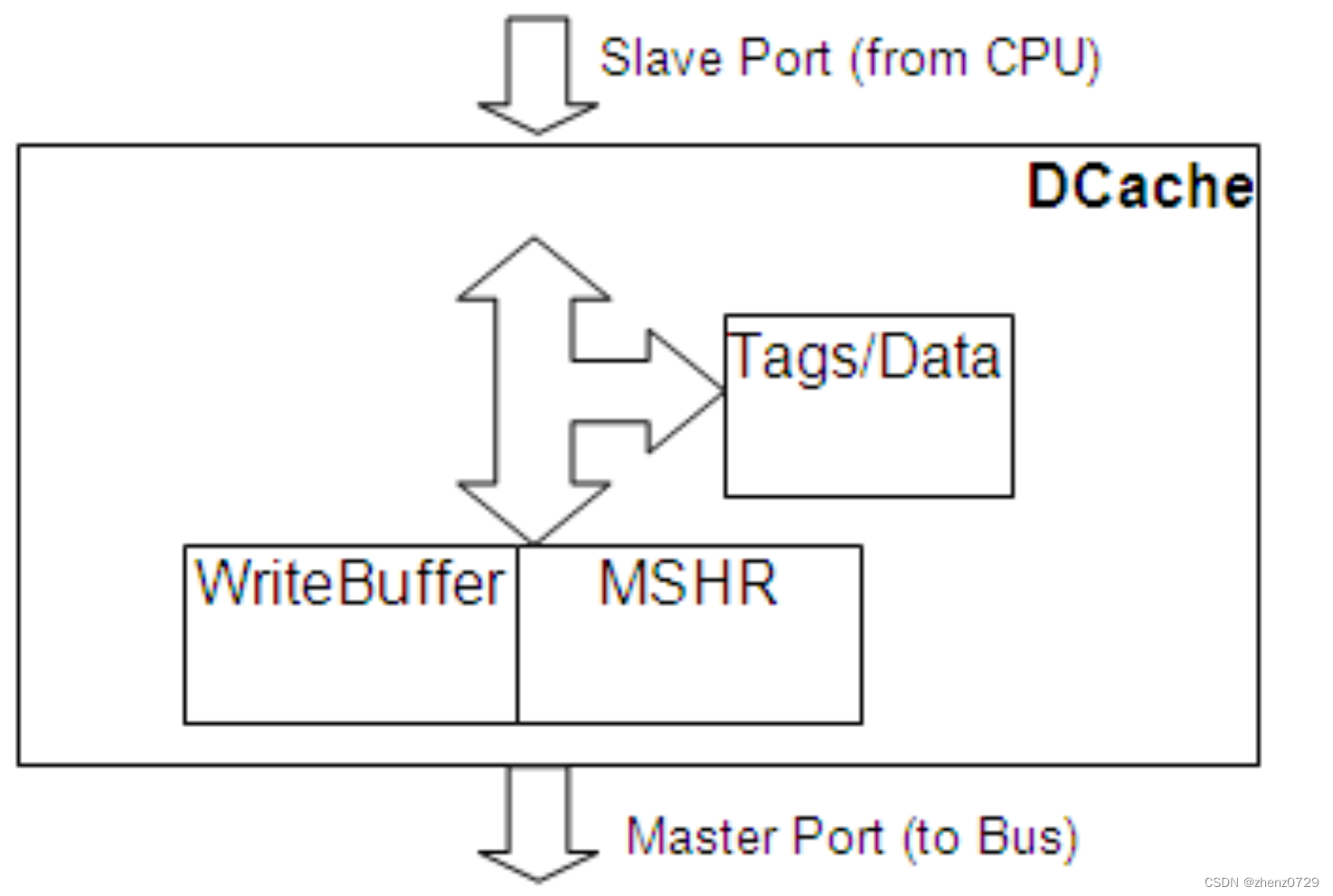
本教程中不包括详细描述 O3 CPU 模型,因此以下仅提供有关该模型的一些相关说明:
读取访问(Read access)是通过向指向 DCache 对象的端口发送消息来启动的。如果 DCache 拒绝消息(因为阻塞或繁忙),CPU 将清空流水线,并在稍后重新尝试访问。当接收到来自 DCache 的回复消息(ReadRep)后,访问完成。
写入访问(Write access)是通过将请求存储到存储缓冲区中,其上下文在每个时钟周期被清空并发送到 DCache 中来启动的。DCache 也可能拒绝请求。当接收到来自 DCache 的写入回复(WriteRep)消息时,写入访问完成。
读取和写入访问(Load & store)的加载和存储缓冲区不对活动内存访问的数量施加任何限制。因此,CPU 仿真对象对 CPU 的内存访问请求的最大数量的限制不是由 CPU 仿真对象本身确定,而是由底层内存系统模型确定。
分割内存访问(Split memory access)被实现。
CPU 发送的消息包含所访问区域的内存类型(Normal、Device、Strongly Ordered 和可缓存性)。然而,模型的其余部分在处理内存类型时采用了更简化的方法,因此不使用此信息。
-
Normal(普通):这是最常见的内存类型,用于描述对标准内存区域的访问。普通内存区域通常是可缓存的,并且按照一般的内存访问规则进行处理。
-
Device(设备):设备内存类型用于描述对设备寄存器或设备映射内存的访问。设备内存通常不可缓存,且对于访问设备寄存器或进行设备通信而言具有特殊的处理要求。
-
Strongly Ordered(强序):强序内存类型用于描述对强序内存区域的访问。强序内存区域包含具有强制顺序执行要求的指令或数据,通常用于确保指令的顺序执行或实现硬件同步。
-
可缓存性:可缓存性描述了内存访问是否可以进行缓存。当内存访问具有可缓存性时,系统可以使用缓存机制提高访问速度和效率。相反,如果内存访问不可缓存,则不会使用缓存,每次访问都会直接读取或写入主存。
三、Data Cache Object
数据缓存对象可以实现一个标准的缓存结构。
1、与特定缓存标记(具有有效和读取标志)匹配的缓存内存读取(Cached memory reads)将在可配置的时间后完成(通过向 CPU 发送 ReadResp)。否则,该请求将转发到缺失状态和处理寄存器(MSHR)块。
MSHR:gem5: gem5::MSHR Class Reference
2、与特定缓存标记(具有有效、读取和写入标志)匹配的缓存内存写入(Cached memory writes)将在相同的可配置时间后完成(通过向 CPU 发送 WriteResp)。否则,该请求将转发到缺失状态和处理寄存器(MSHR)块。
3、未缓存的内存读取Uncached memory reads()将转发到缺失状态和处理寄存器(MSHR)块。
4、未缓存的内存写入(Uncached memory writes)将转发到写缓冲区块。
5、被淘汰(且脏)的缓存行(Evicted (& dirty) cache lines )将转发到写缓冲区块。
如果满足以下任何条件,CPU 对数据缓存的访问将被阻塞:
- MSHR 块已满(MSHR 缓冲区的大小是可配置的)。
- 写回块已满(该块的缓冲区大小是可配置的)。
- 相同内存缓存行的未完成内存访问数量已达到可配置的阈值 - 详见 MSHR 和写缓冲区的详细信息。
- 处于块状态的数据缓存将拒绝来自从端口(CPU)的任何请求,无论其是否导致缓存命中或缺失。请注意,主端口上的传入消息(响应消息和嗅探请求)永远不会被拒绝。
对已经被标记为不可缓存的内存区域进行缓存读取时,如果发生缓存命中(即缓存中已经有该内存区域的数据),根据ARM架构的规范,缓存行将会被标记为无效,并且需要从内存中获取最新的数据。
四、Tags & Data Block
缓存行(在源代码中称为块)按照可配置的关联度和大小组织为集合,并具有以下状态标志:
-
Valid(有效):表示缓存行中保存的数据和地址标签是有效的。
-
Read(读取):用于控制缓存行对读取请求的响应。在设置了该标志之前,缓存行不会接受读取请求,即被标记为不可读取。
【当缓存行处于某种状态(例如等待写入标志完成写入访问)时,它可能已经有效(Valid),但由于某些原因,不允许进行读取操作。这可能是因为该缓存行正在执行某个写入操作,而该操作尚未完成或正在等待其他相关的处理。在这种情况下,即使缓存行的数据是有效的,仍然不会接受读取请求。只有当读取标志被设置后,缓存行才会响应读取请求,并提供有效的数据。这种机制可以用于确保数据的一致性和正确性。当缓存行正在进行写入操作时,阻止对该缓存行的读取请求可以避免读取到不一致或不完整的数据。只有在写入操作完成后,读取标志被设置,才允许对缓存行进行读取操作】。 -
Write(写入):标记缓存行可以接受写入操作。当缓存行具有写入标志时,它允许接收写入请求,并且被认为是唯一状态,即没有其他缓存存储器持有该副本。
【当某个处理器或核心对某个内存地址进行写入操作时,如果该地址对应的数据已经存在于缓存中,并且相应的缓存行具有有效(Valid)和读取(Read)标志,那么写入操作将命中该缓存行。但是,只有在写入标志也被设置为有效时,该缓存行才能接受写入请求。通过将写入标志设置为有效,缓存系统可以确保该缓存行处于唯一状态。这意味着该处理器或核心是该缓存行的唯一拥有者,并且没有其他缓存存储器持有该缓存行的副本。这对于保持数据的一致性非常重要,因为在写入操作期间,其他处理器或核心不能同时读取或修改该缓存行的内容,以避免数据冲突和不一致性。】 -
Dirty(脏):表示当缓存行被淘汰时,其中的数据已被修改,并且需要进行写回(Writeback)操作。
【当一个缓存行被加载到缓存中时,它的数据与对应的内存地址中的数据是一致的。如果在缓存行中的数据被修改(写入)后,该缓存行被淘汰(从缓存中移除),则该缓存行中的数据与内存地址中的数据就不再一致了。为了保持数据的一致性,当一个被标记为脏的缓存行被淘汰时,需要执行写回操作。这意味着将缓存行中的修改数据写回到相应的内存地址,以确保内存中的数据与缓存中的数据保持一致。】
当进行缓存访问时,命中(hit)缓存行表示所请求的数据或指令在缓存中已经存在,而不需要从主存或者其他较慢的缓存层级中获取。
以下是读取和写入访问,命中缓存行需要满足的条件。
(1)对于读取访问,命中缓存行的条件如下:
-
地址标签匹配:缓存使用地址标签来标识每个缓存行所对应的内存地址范围。当读取请求的地址与缓存行的地址标签匹配时,表示地址命中。
-
有效(Valid)标志被设置:有效标志用于表示缓存行中保存的数据是有效的。只有当缓存行的有效标志被设置时,才表示该缓存行中的数据是可用的。
-
读取(Read)标志被设置:读取标志用于控制缓存行对读取请求的响应。只有当缓存行的读取标志被设置后,它才会接受读取请求。
只有当以上三个条件同时满足时,读取访问才会命中缓存行。这意味着所请求的数据已经存在于缓存行中,可以直接从缓存中获取,而不需要从主存或其他较慢的存储层级中获取。
(2)对于写入访问,命中缓存行的条件如下:
-
地址标签匹配:与读取访问一样,写入访问需要地址标签与缓存行的地址匹配。
-
有效(Valid)标志被设置:缓存行的有效标志指示该缓存行中的数据是有效的。
-
读取(Read)标志被设置:读取标志用于控制缓存行对读取请求的响应。
-
写入(Write)标志被设置:写入标志用于表示缓存行可以接受写入操作。
只有当以上四个条件同时满足时,写入访问才会命中缓存行。这意味着所请求的数据已经存在于缓存行中,并且该缓存行可以接受写入操作。在这种情况下,可以直接在缓存行中进行写入操作,而不需要访问主存或其他较慢的存储层级。
【注意】:如果读取或写入访问未命中缓存行,即以上条件之一不满足,系统将执行相应的缓存访问替代策略,通常是从较低层级的存储中获取所需的数据,并将其加载到缓存以供后续的访问使用。
五、MSHR and Write Buffer Queues
Miss Status and Handling Register(MSHR)队列保存了CPU的未完成内存请求列表,这些请求需要对较低层级的内存进行读取访问。包括以下类型的请求:
-
缓存的读取未命中(Cached Read misses):当CPU发起对某个地址的读取请求时,发现对应的缓存行不存在或无效,需要从较低层级的内存层级获取数据。
-
缓存的写入未命中(Cached Write misses):当CPU发起对某个地址的写入请求时,发现对应的缓存行不存在或无效,需要从较低层级的内存层级获取数据,并将修改后的数据写回到内存。
-
非缓存的读取(Uncached reads):当CPU发起对某个地址的读取请求时,明确指定不使用缓存,并需要直接从较低层级的内存层级获取数据。
写缓冲(WriteBuffer)队列保存了以下类型的内存请求:
-
非缓存的写入(Uncached writes):当CPU发起对某个地址的写入请求时,明确指定不使用缓存,并需要直接将数据写入到较低层级的内存层级。
-
从被淘汰的(且已修改)缓存行写回(Writeback from evicted & dirty cache lines):当缓存行被淘汰时,如果该缓存行被标记为脏(Dirty),则其中的修改数据需要写回到较低层级的内存层级。
写缓冲队列用于暂存这些内存请求,以便后续进行处理。它允许CPU继续执行后续的指令,而不需要等待内存访问的完成。写缓冲队列的存在可以提高系统的性能和效率。
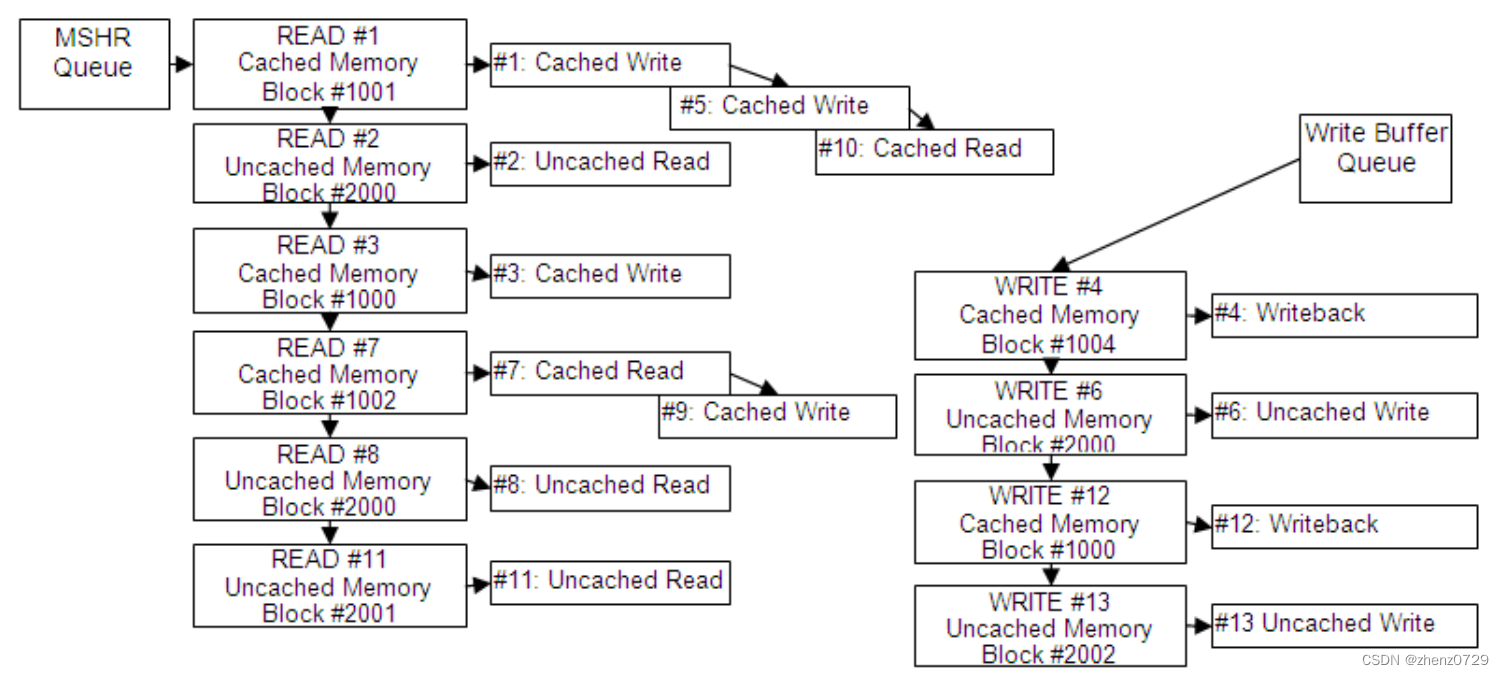
每个内存请求都被分配给相应的MSHR对象(在上面的图表中表示为READ或WRITE),它表示需要读取或写入的特定内存块(缓存行),以完成相应的命令。如上图所示,对同一缓存行的缓存读取/写入具有共享的MSHR对象,并且将通过单个内存访问完成。
块的大小指在内存层级之间进行读取或写入访问时,每次访问的数据块的大小。具体的大小取决于不同的访问方式和指令:
- 对于缓存访问和写回,块的大小通常与缓存行的大小相同。缓存行是计算机体系结构中的一个固定大小的数据块,用于在高速缓存和较低层次内存之间进行数据传输。当CPU进行缓存读取或写入操作时,一次访问将读取或写入一个完整的缓存行。
- 对于非缓存访问,块的大小取决于CPU指令中的规定。根据指令的要求,CPU会指定一次读取或写入的粒度,即每次访问的数据块的大小。
一般来说,数据缓存模型区分了两种内存类型:
1、正常的缓存内存(Normal Cached memory):
- 写回(write-back)策略:当数据需要被写入到内存时,它首先被缓存在高速缓存中,并且在需要释放缓存行或被替换出时,才将修改的数据写回到内存中。这样可以减少对内存的写入操作次数,提高效率。
- 读取和写入分配(read and write allocate):当CPU进行读取或写入操作时,如果数据在缓存中不存在(缓存未命中),则会从较低层级的内存中获取数据,并将其加载到缓存中。这样可以提高后续对同一数据的访问效率。
2、正常的非缓存内存、设备内存和强序内存类型(Normal uncached, Device, and Strongly Ordered types):
- 这些类型的内存被视为相同的非缓存内存类型(uncached memory)。读取和写入操作直接访问较低层级的存储,而不会经过缓存。这意味着每次操作都需要访问较低层级的内存,而不会从缓存中获取数据。这种方式适用于设备内存、I/O操作和需要强制遵循访问顺序的内存。
六、Memory Access Ordering
每个CPU读/写请求(按照它们出现在从属端口上的顺序)都被分配一个唯一的顺序号,这个顺序号用来确定在执行时的顺序。MSHR对象的顺序号是从第一个分配的读/写请求复制过来的。
两个队列中的每个内存读/写操作(Memory read/writes)按照分配的顺序号执行。当这两个队列都不为空时,模型会按照分配的顺序号执行MSHR块中的内存读取操作,除非写缓冲区已满。对同一内存缓存行的读取和写入操作将按照它们分配的顺序号依次进行,以维护它们的顺序。
总结如下:
-
缓存内存的访问顺序:对于缓存内存的读取和写入操作,其执行顺序不会被保留,除非它们针对同一缓存行(Cache line)。例如,对于访问#1、#5和#10,它们将在同一个时钟周期内同时完成,但仍然按照它们的顺序进行执行。而访问#5会在访问#3之前完成。
-
非缓存内存写入的顺序:所有非缓存内存写入操作的顺序都会被保留。这意味着Write#6始终在Write#13之前完成,无论它们之间是否存在其他操作。
-
非缓存内存读取的顺序:所有非缓存内存读取操作的顺序都会被保留。这意味着Read#2始终在Read#8之前完成,无论它们之间是否存在其他操作。
-
读取和写入非缓存内存访问的顺序:对于读取和写入非缓存内存的操作,它们的顺序不一定会被保留,除非它们的访问区域重叠。因此,Write#6始终在Read#8之前完成,因为它们针对同一内存块。然而,Write#13可能在Read#8之前完成,因为它们的访问区域可能不重叠。
总结来说,缓存内存的访问顺序不保留,非缓存内存的写入和读取操作的顺序会被保留,但读取和写入非缓存内存的操作的顺序不一定会被保留,除非它们的访问区域重叠。这些规则和行为有助于优化内存访问的效率和性能。
七、Coherent Bus Object
Coherent Bus对象提供基本的Snoop协议支持:
-
所有从从属端口发出的请求都会转发到相应的主控端口。对于缓存内存区域的请求也会作为Snoop请求转发到其他从属端口。
-
主控端口的回复会被转发到相应的从属端口。
-
主控端口的Snoop请求会被转发到所有从属端口。
-
从属端口的Snoop回复会被转发到发出请求的端口。(需要注意的是,Snoop请求的源可以是从属端口或主控端口。)
【Snoop请求】:Snoop请求用于向其他处理器发送缓存操作的通知。它可以是一个无效请求(Invalidate),用于通知其他处理器将其缓存中的数据无效化,或者是一个更新请求(Update),用于通知其他处理器将其缓存中的数据更新为最新的值。当一个处理器在总线上发起一个Snoop请求时,其他处理器的缓存控制器会监听总线并检查请求的目标地址是否与其缓存中的数据相匹配。如果匹配,那么相应的缓存控制器会执行相应的无效化或更新操作,以确保数据的一致性。
在以下任何事件发生后,总线会声明自身处于阻塞状态,并阻塞一段可配置的时间:
- 将数据包发送(或发送失败)到从属端口。
- 向主控端口发送回复消息。
- 将一个从属端口的Snoop响应发送到另一个从属端口。
当总线处于阻塞状态时,会拒绝以下传入消息:
- 从属端口的请求。
- 主控端口的回复。
- 主控端口的Snoop请求。
简单来说,Coherent Bus对象通过实现Snoop协议来支持多个主控端口和多个从属端口之间的通信。它负责将请求、回复和Snoop消息在各个端口之间进行转发,并通过阻塞状态来管理消息的流动,以确保协议的正确执行。
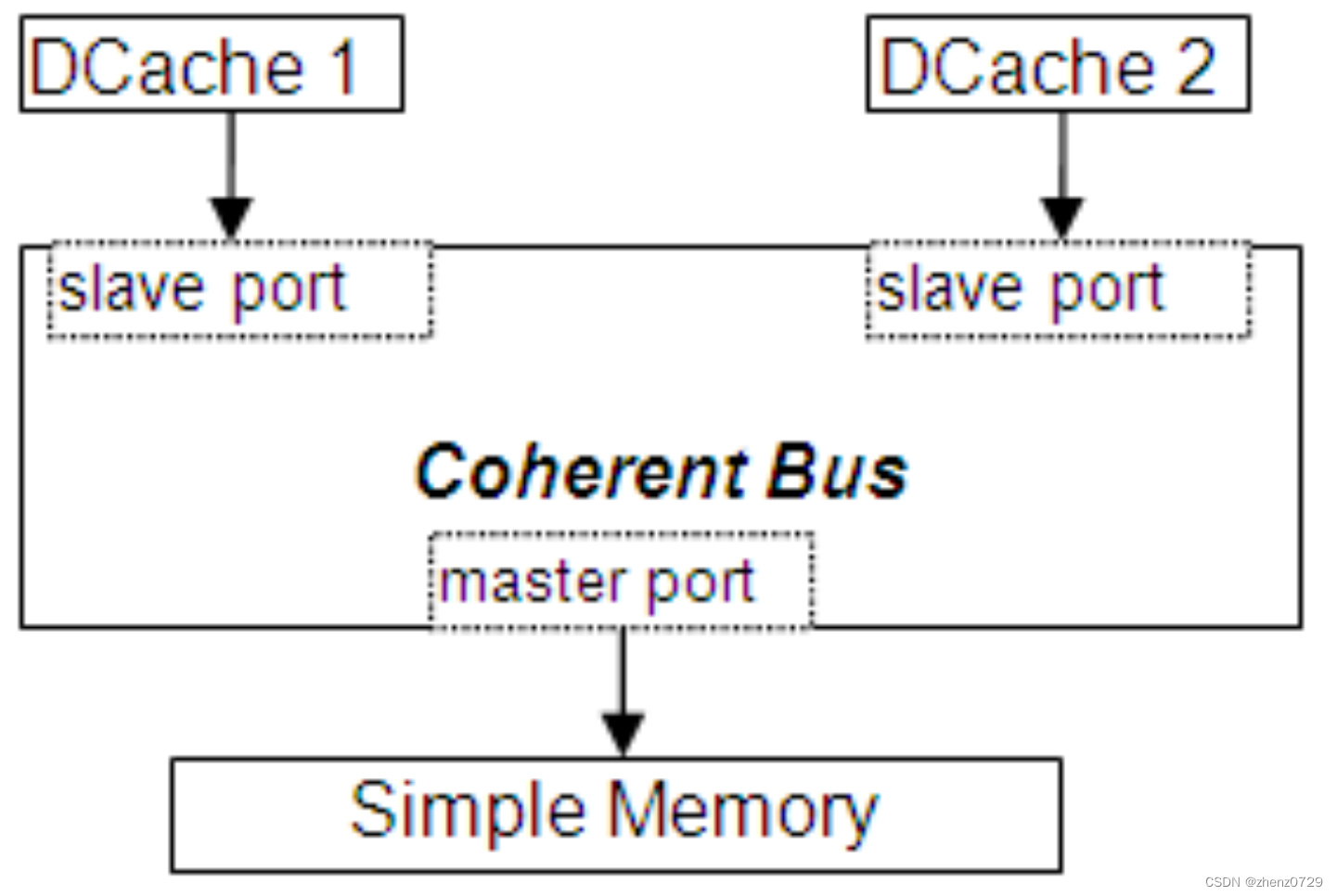
八、Simple Memory Object
-
它不会阻塞从属端口的访问:Coherent Bus对象不会对从属端口的访问进行阻塞。这意味着当从属端口发出读取或写入请求时,总线会立即将请求传递给相应的主控端口或其他需要处理该请求的组件。
-
内存读/写操作会立即生效:当总线接收到来自从属端口的内存读取或写入请求时,它会立即执行该请求。这意味着读取操作将返回请求的数据,写入操作将立即将数据写入到指定的内存位置。总线不会延迟读取或写入操作的执行。
-
回复消息在可配置的时间段之后发送:当主控端口接收到来自其他组件的请求或Snoop请求时,它会在可配置的时间段之后发送回复消息。这个时间段可以根据系统需求进行配置,以实现特定的时序要求或优化总线的性能。因此,回复消息的发送可能会有一定的延迟,而不是立即发送。
九、Message Flow
1、Memory Access Ordering
下图展示了对具有有效和读取标志的数据缓存行的读取访问。

缓存未命中的读取访问将生成以下消息序列。
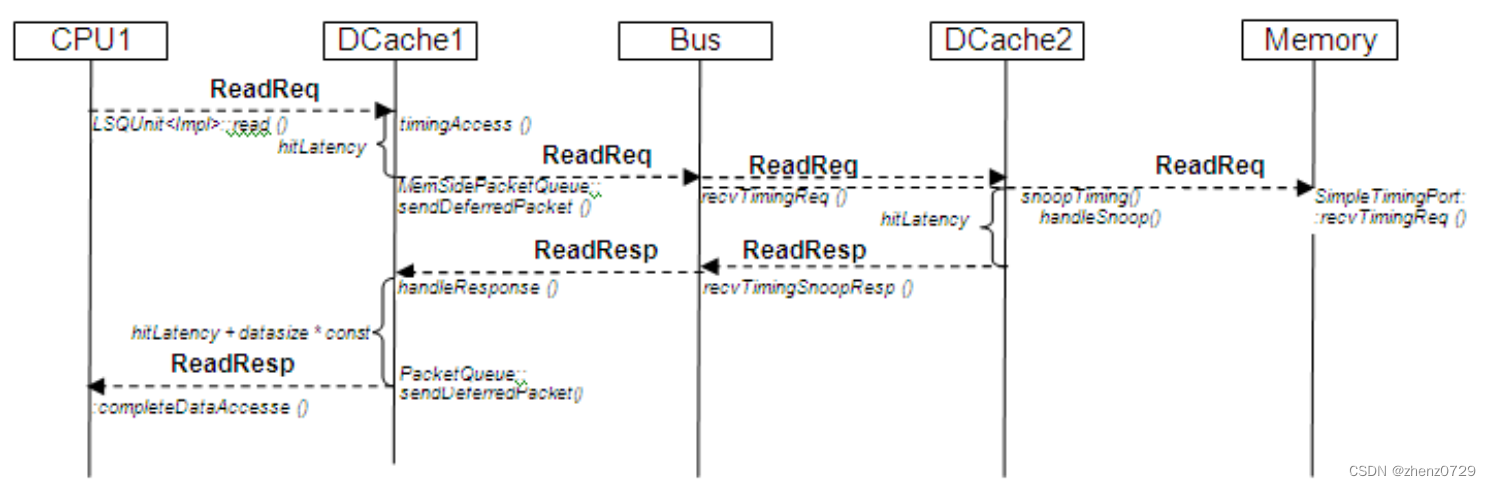
请注意,总线对象从未同时从DCache2和Memory对象接收响应。它将完全相同的ReadReq数据包(消息)对象发送到内存和数据缓存。当数据缓存希望对Snoop请求进行回复时,它会标记该消息的MEM_INHIBIT标志,告知内存对象不要处理该消息。
2、Memory Access Ordering
下图展示了对具有有效和写入标志的DCache1缓存行的写入访问:

下图展示了对具有有效但没有写入标志的DCache1缓存行的写入访问,这被称为写入未命中。DCache1发出UpgradeReq以获取写入权限。DCache2::snoopTiming将使已被命中的缓存行无效化。请注意,UpgradeResp消息不携带数据。
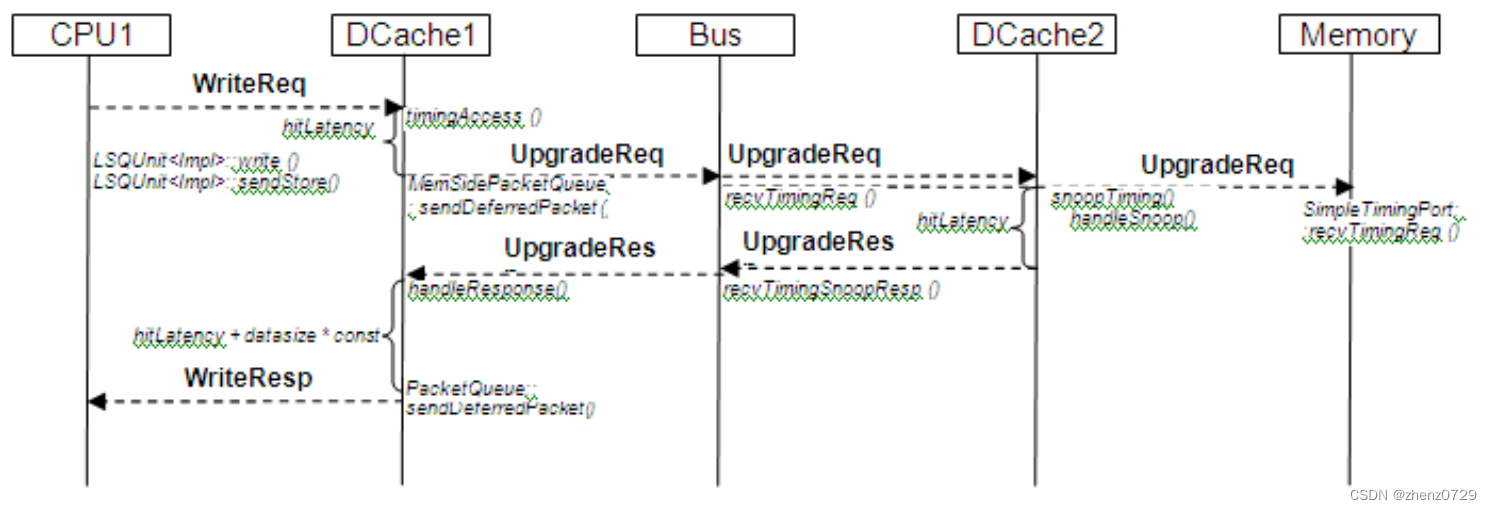
下图展示了DCache中的写入未命中情况。ReadExReq将使DCache2中的缓存行无效。ReadExResp携带内存缓存行的内容。

今天周末,浅更一篇~