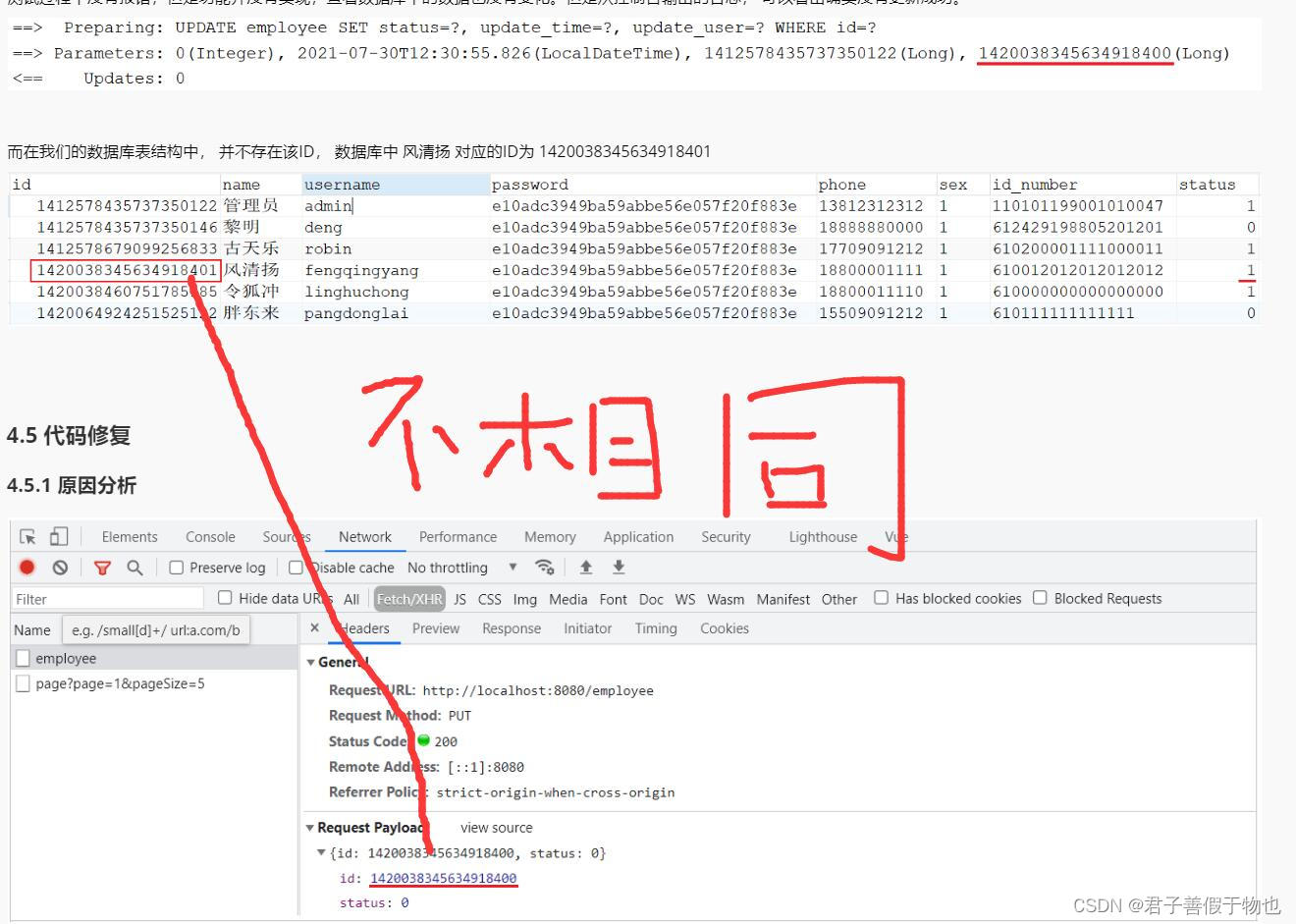
文章目录
- Pandas
- 1. Pandas介绍
- 2. Series
- 2.1 Series 的创建
- 2.1.1 列表创建
- 2.1.2 NumPy 数组创建
- 2.1.3 字典创建
- 2.1.4 Series 参数
- 2.2 Series 的索引
- 2.2.1 显式索引
- 2.2.2 隐式索引
- 2.2.3 修改索引
- 2.2.4 通过索引获取值
- 2.2.5 通过索引修改值
- 2.3 Series 的切片
- 2.3.1 显式切片
- 2.3.2 隐式切片
- 2.4 Series 的基本属性和方法
- 2.4.1 基本属性
- 2.4.2 方法
- 2.4.3 检测缺失数据
- 2.4.4 使用 bool 值索引过滤数据
- 2.5 Series 的运算
- 2.5.1 Series 之间的运算
- 3. DataFrame
- 3.1 DataFrame 的创建
- 3.1.1 字典创建
- 3.1.4 二维数组创建
- 3.1.3 其他创建方式
- 3.2 DataFrame 的基本属性和方法
- 3.2.1 基本属性
- 3.2.2 方法
- 3.3 DataFrame 的索引
- 3.3.1 对列进行索引
- 3.3.2 对行取索引
- 3.3.3 对元素进行索引
- 3.4 DataFrame 的切片
- 3.4.1 行切片
- 3.4.2 列切片
- 3.4.3 练习
- 3.4.4 总结
- 3.5 DataFrame 的运算
- 3.5.2 DataFrame 和标量之间的运算
- 3.5.3 DataFrame 之间的运算
- 3.5.4 DataFrame 和 Series 之间的运算
- 4. Pandas 层次化索引
- 4.1 创建多层行/列索引
- 4.1.1 隐式构造
- 4.1.2 显示构造
- 4.2 多层索引对象的索引与切片操作
- 4.2.1 Series 的操作
- 4.2.1.1 索引
- 4.2.1.2 元素
- 4.2.1.3 切片
- 4.2.2 DataFrame 的操作
- 4.2.2.1 元素
- 4.2.2.2 索引
- 4.2.2.3 切片
- 5. 索引的堆叠
- 5.1 stack() 方法
- 5.2 unstack() 方法
- 5.3 fill_value 填充
- 6. 聚合操作
- 6.1 DataFrame 的聚合操作
- 6.2 多层索引聚合操作
- 7. Pandas 数据合并
- 7.1 使用 pd.concat() 级联
- 7.1.1 简单级联
- 7.1.2 忽略行索引
- 7.1.3 使用多层索引
- 7.1.4 不匹配级联
- 7.1.4.1 外连接
- 7.1.4.2 内连接
- 7.2 使用 _append() 函数添加
- 7.3 使用 pd.merge() 合并
- 7.3.1 一对一合并
- 7.3.2 多对一合并
- 7.3.3 多对多合并
- 7.3.4 Key 的规范化
- 7.3.5 内合并与外合并
- 7.3.6 列冲突问题
- 8. Pandas 缺失值处理
- 8.1 Pandas 中的None与NaN
- 8.2 Pandas 中的None与np.nan的操作
- 8.2.1 判断函数
- 8.2.2 过滤数据
- 8.2.2.1 使用bool值索引过滤数据
- 8.2.2.2 过滤函数 dropna()
- 8.2.3 填充空值
- 9. Pandas 重复值处理
- 10. Pandas 数据映射
- 10.1 replace() 函数
- 10.2 map() 函数
- 10.3 rename() 函数
- 10.3.1 修改索引
- 10.3.2 重置索引
- 10.4 apply() 函数
- 10.5 transform() 函数
- 11. Pandas 异常值处理
- 11.1 describe() 函数
- 11.2 std() 函数
- 11.3 drop() 函数
- 11.4 unique() 函数
- 11.5 query() 函数
- 11.6 sort_values() 函数
- 11.7 sort_index() 函数
- 11.8 info() 函数
- 11.9 练习
- 12. 抽样
- 12.1 无放回抽样
- 12.2 有放回抽样
- 13. Pandas 数学函数
- 13.1 聚合函数
- 13.2 其他函数
- 14. Pandas 分组
- 14.1 练习
- 15. Pandas 加载数据
- 15.1 CSV 数据加载
- 15.2 Excel 数据加载
- 15.3 MySQL 数据加载
- 16. Pandas 分箱操作
- 16.1 等宽分箱
- 16.2 等频分箱
Pandas
1. Pandas介绍
Pandas是基于NumPy的一种工具,该工具是为解决数据分析任务而创建的,Pandas提供了大量能快速便捷地处理数据的功能。
Pandas与出色的Jupyter工具包和其他库相结合,Python中用于进行数据分析的环境在性能、生产率和协作能力方面都是卓越的。
Pandas的主要数据结构是Series(一维数据)与DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数案例。
处理数据一般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化,Pandas是处理数据的理想工具。
2. Series
Series是一种类似于一维数组的数据结构。
Series可以看作是一个有序的字典结构。
有两个部分组成:
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
创建 Pandas 的 Series 对象时,可以使用多种参数来指定数据、索引等。下面是一些常用的参数:
data:指定数据,可以是以下类型之一:- 标量值(如数字或字符串)
- 列表、元组或其他可迭代对象
- NumPy 数组
index:指定索引,可以是以下类型之一:- 单个标签或标签列表
- 整数索引
- Pandas 的索引对象(例如 RangeIndex)
name:指定 Series 的名称(一个字符串)。
2.1 Series 的创建
Series的创建方法:
- 列表创建。
- 字典创建。
- NumPy数组创建。
默认索引为0到N-1的整数型索引。
2.1.1 列表创建
import numpy as np
import pandas as pd
# 列表创建
list1 = [11,22,33,44]
s = pd.Series(list1)
print(s)
输出结果如下:
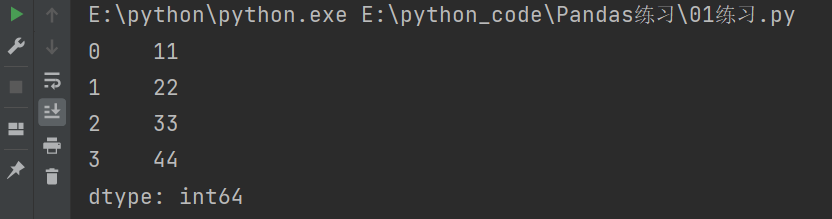
可以将Series当作一个携带索引的一维数组。
import numpy as np
import pandas as pd
# 列表创建
list1 = [11,22,33,44]
s = pd.Series(list1)
# values是值
print(s.values)
# index是索引的意思
print(s.index)
# 或者强制转换为列表查看
print(list(s.index))
输出结果如下:
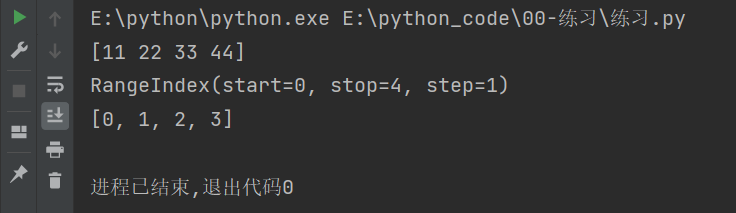
说明:
- start 表示从0开始。
- stop 表示到4结束,不包含4。
- step 表示步长为1。
2.1.2 NumPy 数组创建
import pandas as pd
import numpy as np
list1 = [11,22,33,44]
# NumPy数组创建
n = np.array(list1)
s1 = pd.Series(n)
print(s1)
2.1.3 字典创建
import pandas as pd
d = {
'a':66,
'b':77,
'c':88,
'd':99
}
s = pd.Series(d)
print(s)
2.1.4 Series 参数
在 Pandas 中,创建 Series 对象时可以传入多种参数,常用的包括:
- data:Series 的数据部分,可以是列表、数组、字典或标量值。
- index:用于指定索引标签的参数,可以是与数据长度相同的索引列表,也可以是单个值,如果不指定索引,则默认为整数索引。
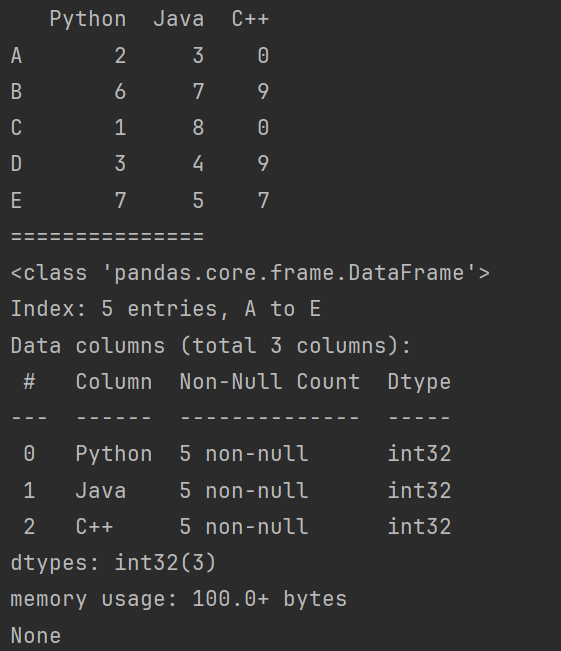
s = pd.Series([98,84,94], index = ['小王','小李','小张'])
s2 = pd.Series({'Python':100,'Java':110,'C++':120})
print(s)
print("===================================")
print(s2)
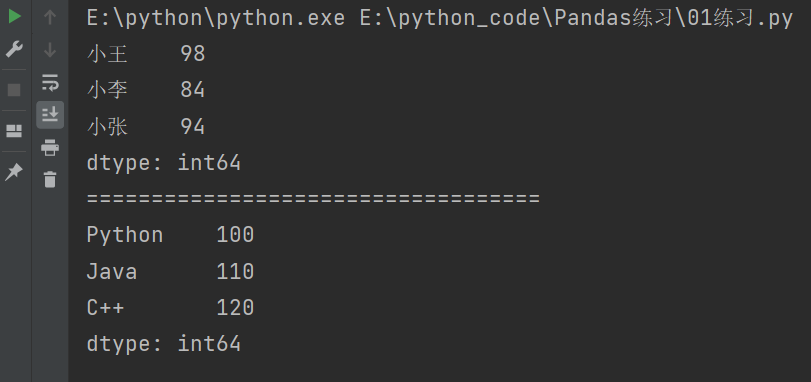
说明:
[98,84,94]:这是Series对象的数据部分,它是一个列表,包含了四个整数元素。index = ['小王','小李','小张']:这是Series对象的索引部分,它是一个列表,包含了与数据对应的四个标签。dtype: int64:表示数据的类型为64位整数。
2.2 Series 的索引
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的仍然是一个Series类型)。分为显示索引和隐式索引:
2.2.1 显式索引
- 使用index中的元素作为索引值。
- 索引**.loc[]** (推荐)
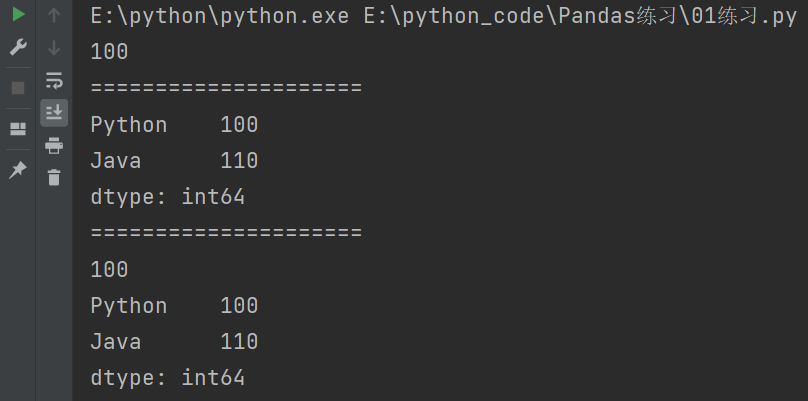
# 显示索引
s = pd.Series({'Python':100,'Java':110,'C++':120})
# 获取单个值
print(s['Python'])
print("=====================")
# 获取多个值
print(s[['Python','Java']])
print("=====================")
# 使用.loc[]
print(s.loc['Python'])
print(s.loc[['Python','Java']])
说明:
-
使用两个中括号所得到的类型为Series类型,如果使用一个中括号得到的类型是一个值(示例中的整数型)。
-
.loc是 Pandas 中用于按标签访问数据的属性。它可以用于 Series 和 DataFrame 对象。
2.2.2 隐式索引
- 使用整数作为索引值。
- 使用**.iloc[]**(推荐)
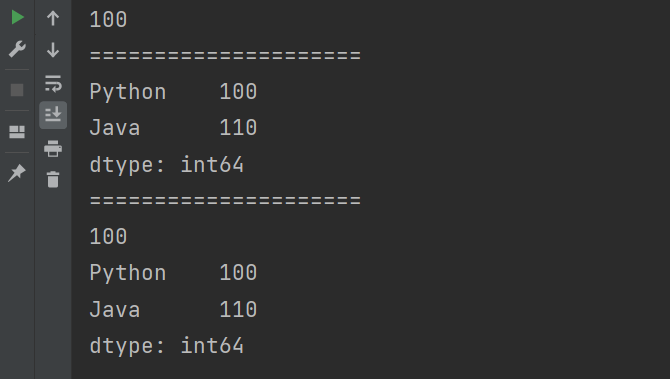
# 隐式索引
s = pd.Series({'Python':100,'Java':110,'C++':120})
# 获取单个值
print(s[0])
print("=====================")
# 获取多个值
print(s[[0,1]])
print("=====================")
# 使用loc[]
print(s.iloc[0])
print(s.iloc[[0,1]])
错误写法
s.iloc['Python']
s.loc[0]
2.2.3 修改索引
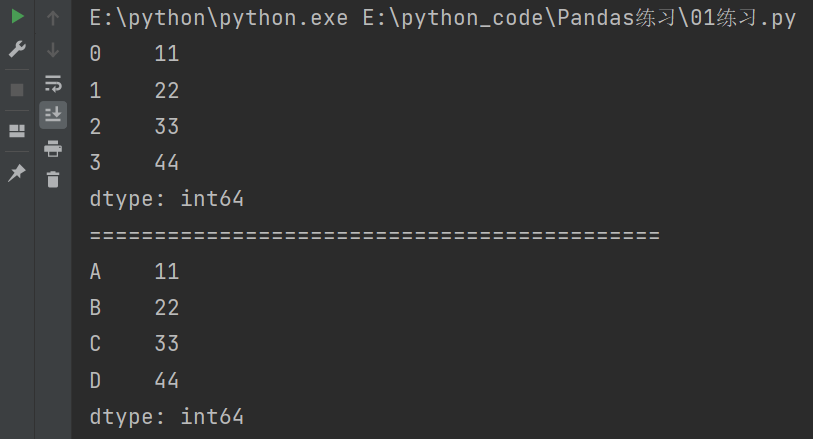
import pandas as pd
# 列表创建
list1 = [11,22,33,44]
s = pd.Series(list1)
print(s)
print("============================================")
# 修改索引
s.index = ["A","B","C","D"]
print(s)
2.2.4 通过索引获取值
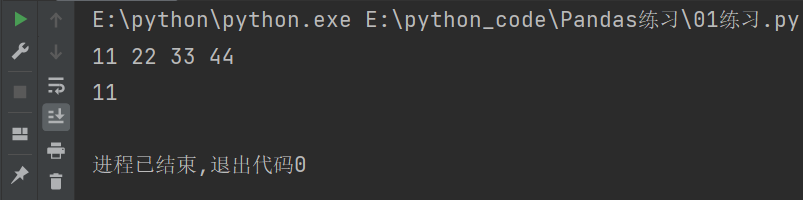
import pandas as pd
# 列表创建
list1 = [11,22,33,44]
s = pd.Series(list1)
# 修改索引
s.index = ["A","B","C","D"]
print(s.A,s.B,s.C,s.D)
# 如果索引是数值的话就不要用.的方式来获取
# 显示索引
print(s['A'])
注意:如果索引是数字的话就不要用.的方式来获取值了。
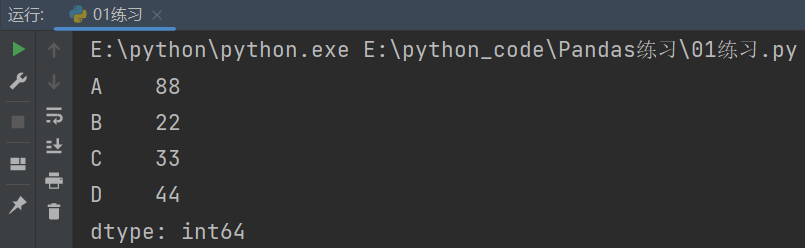
2.2.5 通过索引修改值
import pandas as pd
# 列表创建
list1 = [11,22,33,44]
s = pd.Series(list1)
# 修改索引
s.index = ["A","B","C","D"]
s.A = 88
# s['A'] = 88
print(s)
2.3 Series 的切片
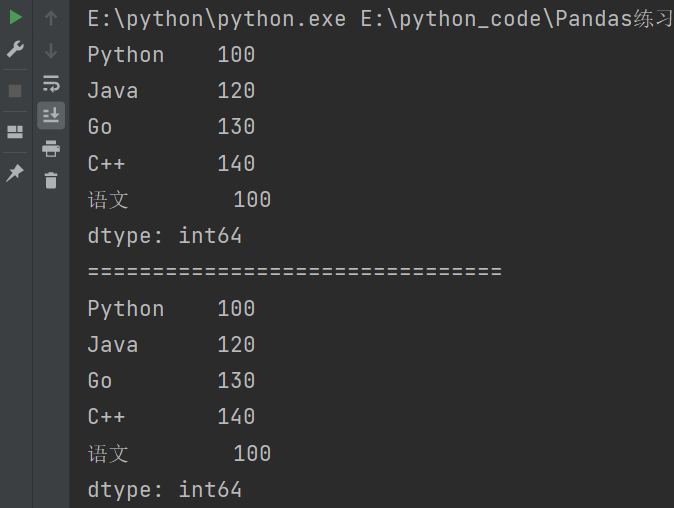
2.3.1 显式切片
显式切片使用的是索引名称来进行切片的,左闭右闭。
import pandas as pd
s = pd.Series({
'Python':100,
'Java':120,
'Go':130,
'C++':140,
'语文':100,
'数学':98,
'英语':99
})
# 切片
# 显示切片:使用索引名称(左闭右闭)
print(s['Python':'语文'])
print("================================")
print(s.loc['Python':'语文'])
输出结果:
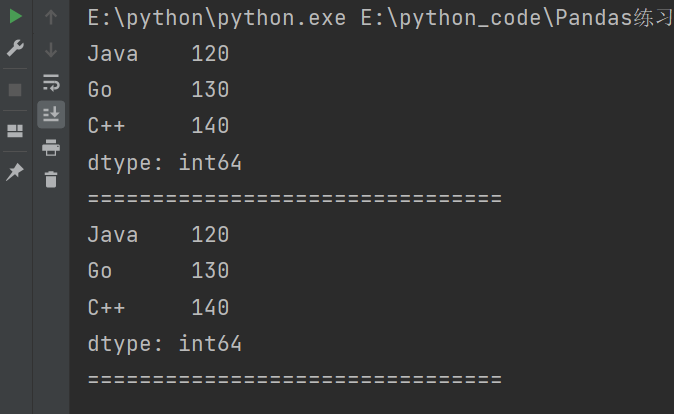
2.3.2 隐式切片
隐式切片是通过数字下标进行切片的,左闭右开。
import pandas as pd
s = pd.Series({
'Python':100,
'Java':120,
'Go':130,
'C++':140,
'语文':100,
'数学':98,
'英语':99
})
# 切片
# 隐式切片:使用数字下标(左闭右开)
print(s[1:4]) # 输出结果从下标1开始到下标4-1结束。
print("================================")
print(s.iloc[1:4])
print("================================")
输出结果:
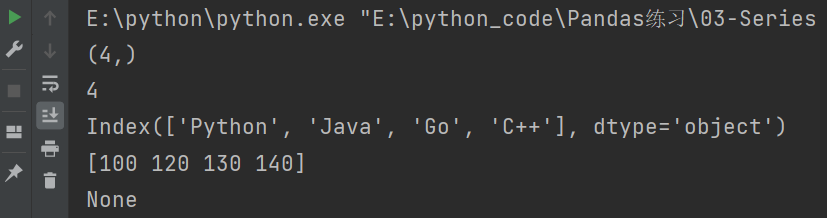
2.4 Series 的基本属性和方法
2.4.1 基本属性
- shape 形状
- size 元素个数
- index 索引
- values 值
- name 名字
import pandas as pd
s = pd.Series({
'Python':100,
'Java':120,
'Go':130,
'C++':140
})
print(s.shape) # 形状
print(s.size) # 元素个数
print(s.index) # 索引
print(s.values) # 值
print(s.name) # 名字
输出结果:
2.4.2 方法
查看元素的方法
- head():查看前几条数据,默认5条。
- tail():查看后几条数据,默认5条。
import pandas as pd
s = pd.Series({
'Python':100,
'Java':120,
'Go':130,
'C++':140,
'C':100,
'C#':110
})
# Series方法
print(s.head()) # 查看前5条数据。
print(s.tail()) # 查看后5条数据。
输出结果:

2.4.3 检测缺失数据
- pd.isnull():判断是否为空。
- pd.notnull():判断是否不为空。
- isnull():判断是否为空。
- notnull():判断是否不为空。
import pandas as pd
import numpy as np
# 检测缺失数据
s2 = pd.Series(['小王','小李','小张',np.nan]) # np.nan的结果表示空值
print(pd.isnull(s2)) # 判断是否为空
print(s2.isnull()) # 方式二
print("==================")
print(pd.notnull(s2)) # 判断是否不为空
print(s2.notnull()) # 方式二
说明:np.nan是NumPy库中用于表示缺失值(NaN)的特殊值。NaN代表不是一个数字(Not a Number),在数据分析和处理中经常会遇到缺失值,因此NumPy提供了np.nan作为一种方便的表示方式。
输出结果:
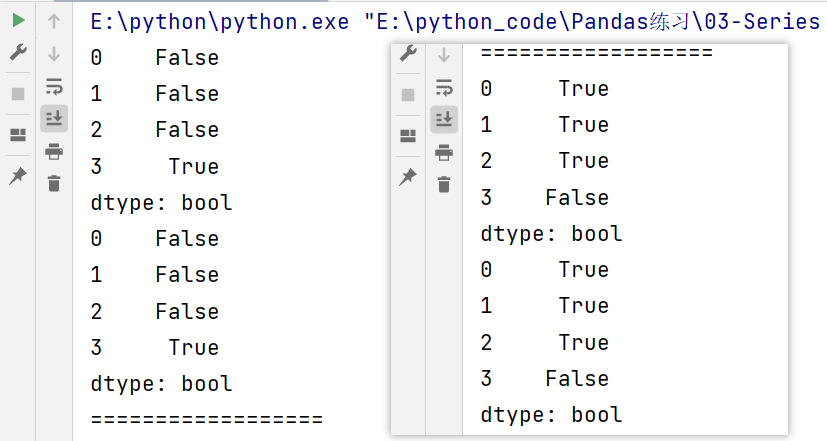
如果有空值的情况下,数值就没有意义了。
2.4.4 使用 bool 值索引过滤数据
方式一:
import pandas as pd
import numpy as np
s2 = pd.Series(['小王','小李','小张',np.nan])
# 过滤空值
cond1 = s2.isnull()
print(s2[cond1])
print(s2[~cond1])
print("================")
# s2[cond1]输出结果为NaN,s2[~cond1]输出结果为'小王','小李','小张'
说明:
~:表示取反的意思。- s2[cond1]输出结果为NaN,s2[~cond1]输出结果为’小王’,‘小李’,‘小张’。
输出结果:

方式二:
import pandas as pd
import numpy as np
s2 = pd.Series(['小王','小李','小张',np.nan])
# 过滤空值
cond2 = s2.notnull()
# 输出不为空的值
print(s2[cond2])
输出结果:

2.5 Series 的运算
适用于NumPy的数组运算也适用于Series
import pandas as pd
import numpy as np
s1 = pd.Series(np.random.randint(10,100,size=10))
print(s1)
print("=========")
# Series运算
s1[0] += 10
s1[1] -= 10
s1[2] *= 1
s1[3] /= 1 # 除
s1[4] //= 2 # 整除
s1[5] %= 2 # 取余
print(s1)
说明:
- np.random.randint()函数接受三个参数:low、high和size。其中,low表示随机整数的最小值,high表示随机整数的最大值(不包括该值),size表示生成数组的形状。在这个例子中,low=10,high=100,size=10,因此生成一个长度为10,元素取值在[10, 100)之间的一维数组。

2.5.1 Series 之间的运算
- Series 在运算中自动对齐索引(通过索引进行运算)。
- 如果索引不对应,则补齐NaN。
- Series 没有广播机制。
广播机制(broadcasting)是指在进行操作时,自动对不同形状的数组进行适当的扩展和匹配。通俗地讲,广播机制会让形状不同的数组在执行某些操作时,自动变换为相同的形状,使得操作能够进行。
示例,演示了如何在NumPy中使用广播机制:
import numpy as np # 创建一个形状为(3, 2)的二维数组 a = np.array([[1, 2], [3, 4], [5, 6]]) # 创建一个形状为(2,)的一维数组 b = np.array([10, 20]) # 使用广播机制将二维数组和一维数组相加 c = a + b # 打印结果 print(c)输出:
array([[11, 22], [13, 24], [15, 26]])
import pandas as pd
import numpy as np
s2 = pd.Series(np.random.randint(10,100,size=3))
s3 = pd.Series(np.random.randint(10,100,size=3))
print(s2,s3)
print("=========")
print(s2 + s3)
print("=========")
print(s2 - s3)
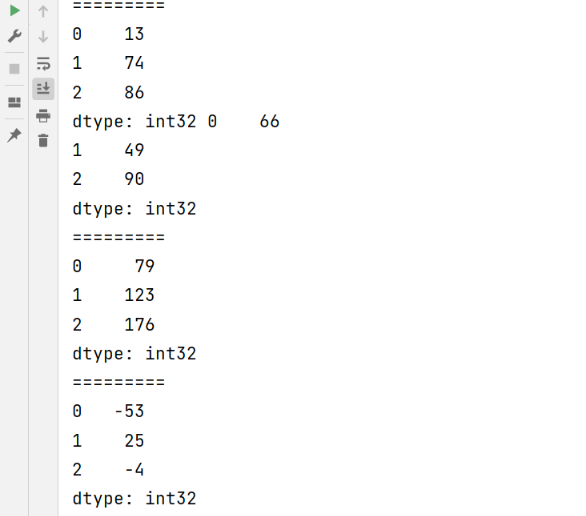
两个Series中的值个数不一致
import pandas as pd
import numpy as np
s2 = pd.Series(np.random.randint(10,100,size=3))
s3 = pd.Series(np.random.randint(10,100,size=4))
print(s2)
print("=========")
print(s3)
print("=========")
print(s2 + s3)
运行结果:
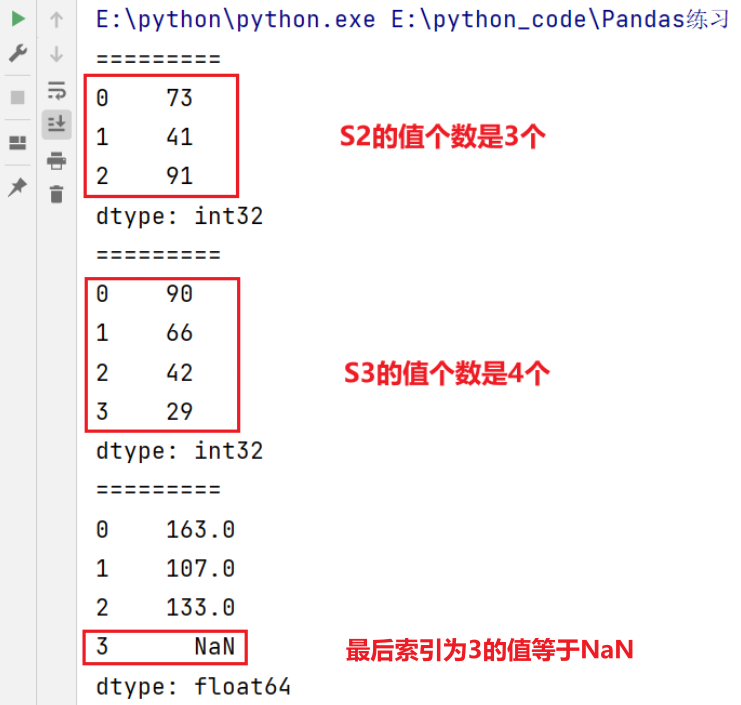
说明:索引下标3的值等于NaN,其原因是因为两个Series之间的运算是通过索引来运算的。
修改索引进行验证
import pandas as pd
import numpy as np
s2 = pd.Series(np.random.randint(10,100,size=3))
s3 = pd.Series(np.random.randint(10,100,size=4))
print(s2)
print("=========")
s3.index= [3,2,1,0]
print(s3)
print("=========")
print(s2 + s3)
输出结果:
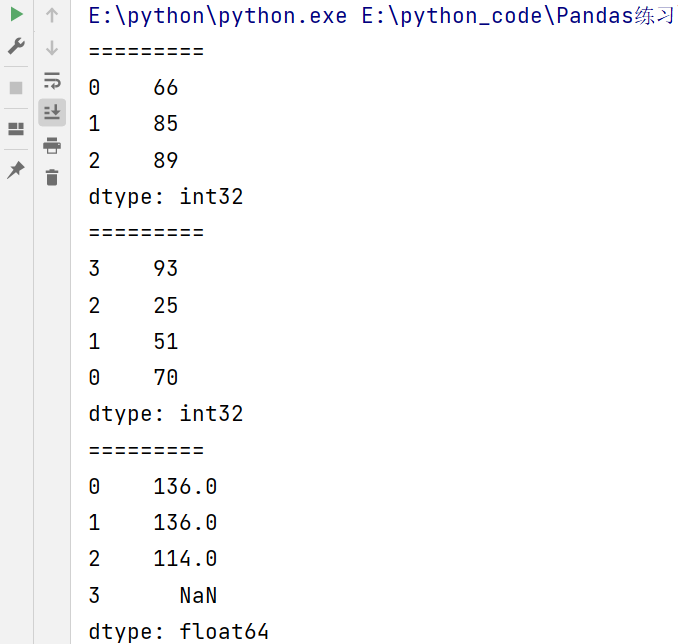
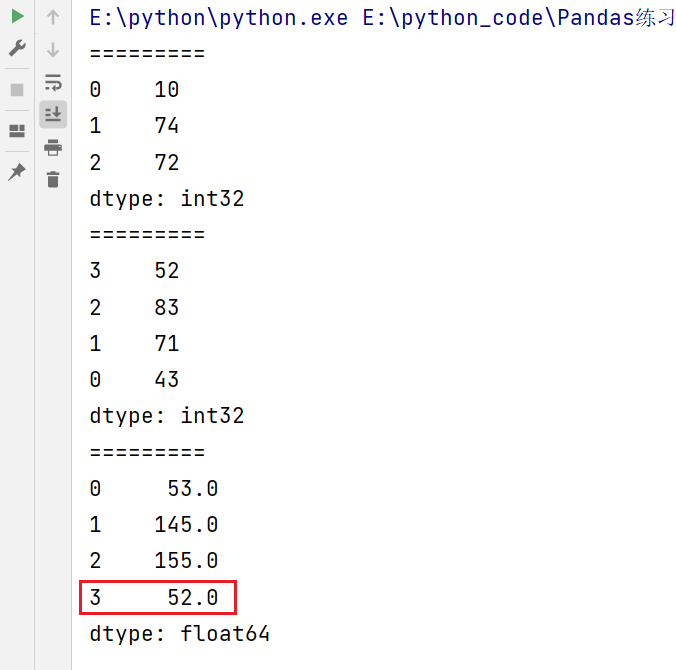
注意要想保留所有的index,则需要使用.add()函数。通俗的讲就是如果不想让上面示例中索引为3的值为NaN的话,可以使用.add()函数,添加参数fill_value。
print(s2.add(s3,fill_value=0))
3. DataFrame
DataFrame是一种有行有列的表格型数据结构。
DataFrame是一个【表格型】的数据结构,可以看做是【由Series组成的字典】(共用同一个索引)。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values(NumPy的二维数组)
DataFrame参数
创建 DataFrame 对象时,可以使用多种参数来指定数据、行索引、列索引等。下面是一些常用的参数:
data:指定数据,可以是以下类型之一:- 二维数组(如 NumPy 数组)
- 字典(字典的值可以是列表、元组或其他可迭代对象)
- Pandas 的 Series 对象
- Pandas 的 DataFrame 对象
index:指定行索引,可以是以下类型之一:- 单个标签或标签列表
- 整数索引
- Pandas 的索引对象(例如 RangeIndex)
columns:指定列索引,可以是以下类型之一:- 单个标签或标签列表
- Pandas 的索引对象
3.1 DataFrame 的创建
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。此外,DataFrame会自动加上每一行的索引(和Series一样)。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
3.1.1 字典创建
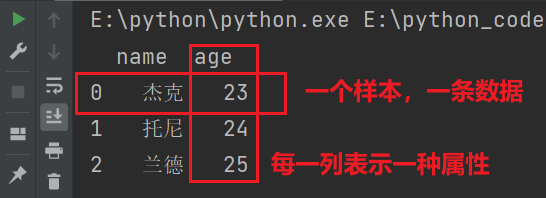
import pandas as pd
# DataFrame 的创建
# 方式一:字典创建
d = {
'name':['杰克','托尼','兰德'],
'age':[23,24,25]
}
df = pd.DataFrame(d)
print(df)
输出结果:
3.1.4 二维数组创建
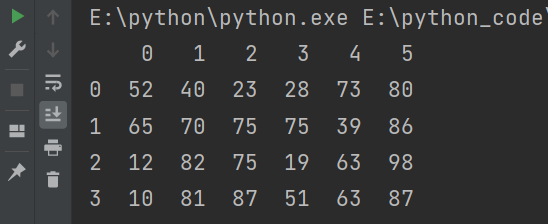
import numpy as np
import pandas as pd
df2 = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6))
)
print(df2)
输出结果:
在创建的时候指定列索引和行索引。
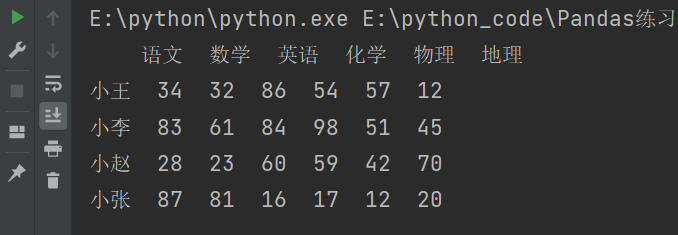
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
print(df)
说明:调用 randint(10, 100, size=(4, 6)), 表示生成一个形状为 (4, 6) 的随机整数数组。其中,第一个数字 4 表示数组的行数,第二个数字 6 表示数组的列数。,其中每个元素的取值范围是从 10(包含)到 100(不包含)之间的整数。
3.1.3 其他创建方式
import pandas as pd
# DataFrame 的创建
d = {
'name':['杰克','托尼','兰德'],
'age':[23,24,25]
}
# 在创建的时候,设置行索引
df = pd.DataFrame(d,index = ['A','B','C'])
df2 = pd.DataFrame(d,index = list('abc'))
print(df)
print(df2)
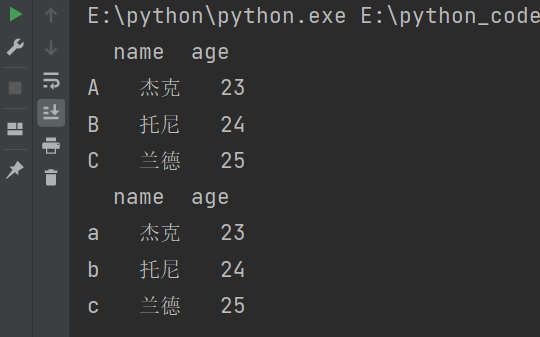
说明:list(‘abc’):表示将字符串”abc“转换为列表。
输出结果:
import pandas as pd
# DataFrame 的创建
d = {
'name':['杰克','托尼','兰德'],
'age':[23,24,25]
}
df = pd.DataFrame(d)
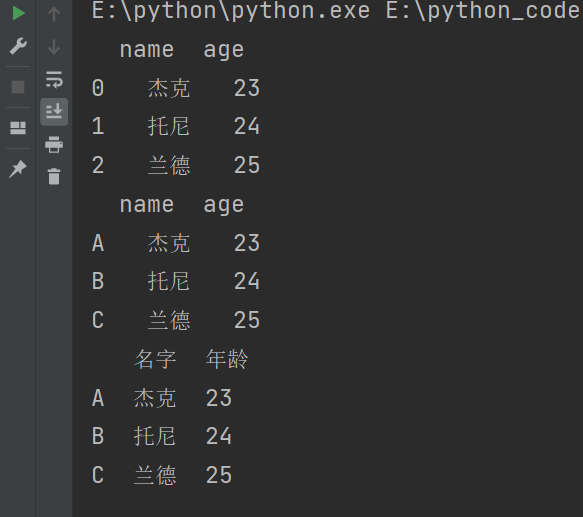
# 在创建后设置行索引
df.index = list('ABC')
print(df)
# 在创建后设置列索引
df.columns = ['名字','年龄']
print(df)
输出结果:
3.2 DataFrame 的基本属性和方法
- vaules:表示值。
- columns:列索引。
- index:行索引。
- shape():形状(如果拿到的数据非常的多的话,需要查看形状)。
- head():查看前几条数据,默认5条。
- tail():查看后几条数据,默认5条。
3.2.1 基本属性
import pandas as pd
df = pd.DataFrame({
'name':['杰克','托尼','兰德'],
'age':[23,24,25]
})
print(df.values) # 二维数组的数据
print("===========")
print(df.columns) # 输出列索引
print("===========")
print(df.index) # 输出行索引
print("===========")
print(df.shape) # 形状
输出结果:
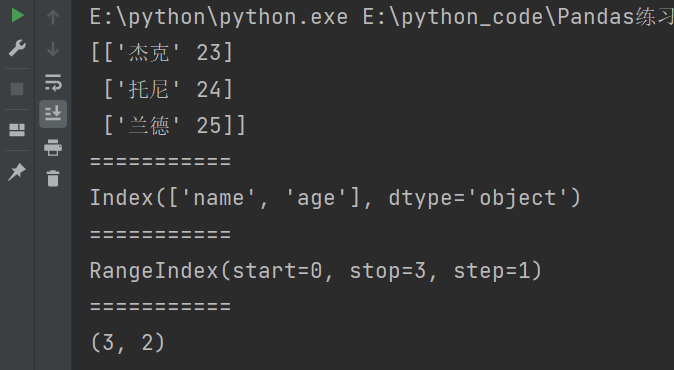
输出的形状是三行二列。
3.2.2 方法
查看元素的方法:
- head():查看前几条数据,默认5条。
- tail():查看后几条数据,默认5条。
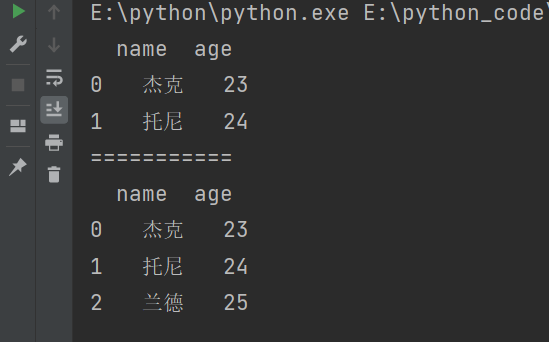
import pandas as pd
df = pd.DataFrame({
'name':['杰克','托尼','兰德'],
'age':[23,24,25]
})
print(df.head(2)) # 输出前2条数据
print("===========")
print(df.tail()) # 输出后5条数据
3.3 DataFrame 的索引
3.3.1 对列进行索引
- 通过类似字典的方式。
- 通过属性的方式。
可以将DataFrame的列获取为一个Series。返回的Series拥有原来DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
# 对列进行索引
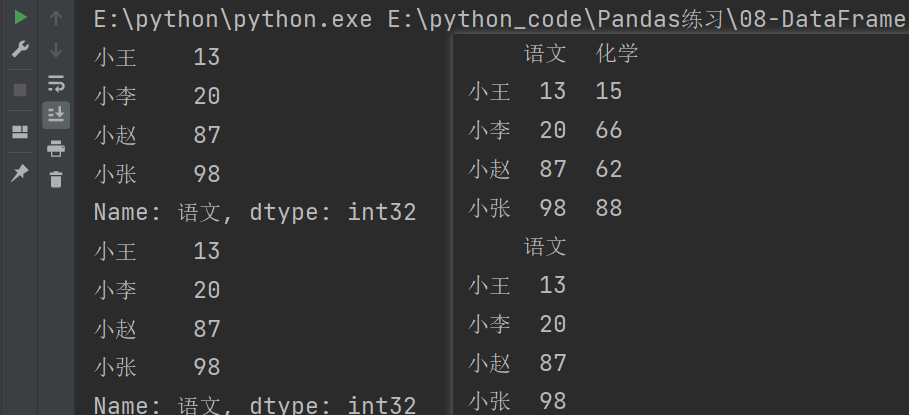
print(df.语文) # 获取到的是Series类型
print(df['语文']) # 获取到的是Series类型
print(df[['语文','化学']]) # 获取到的是DataFrame类型
print(df[['语文']]) # 获取到的是DataFrame类型
输出结果:
3.3.2 对行取索引
- 使用.loc[]加index来进行行索引。
- 使用.iloc[]加整数来进行行索引。
同样返回一个Series,index为原来的columns
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
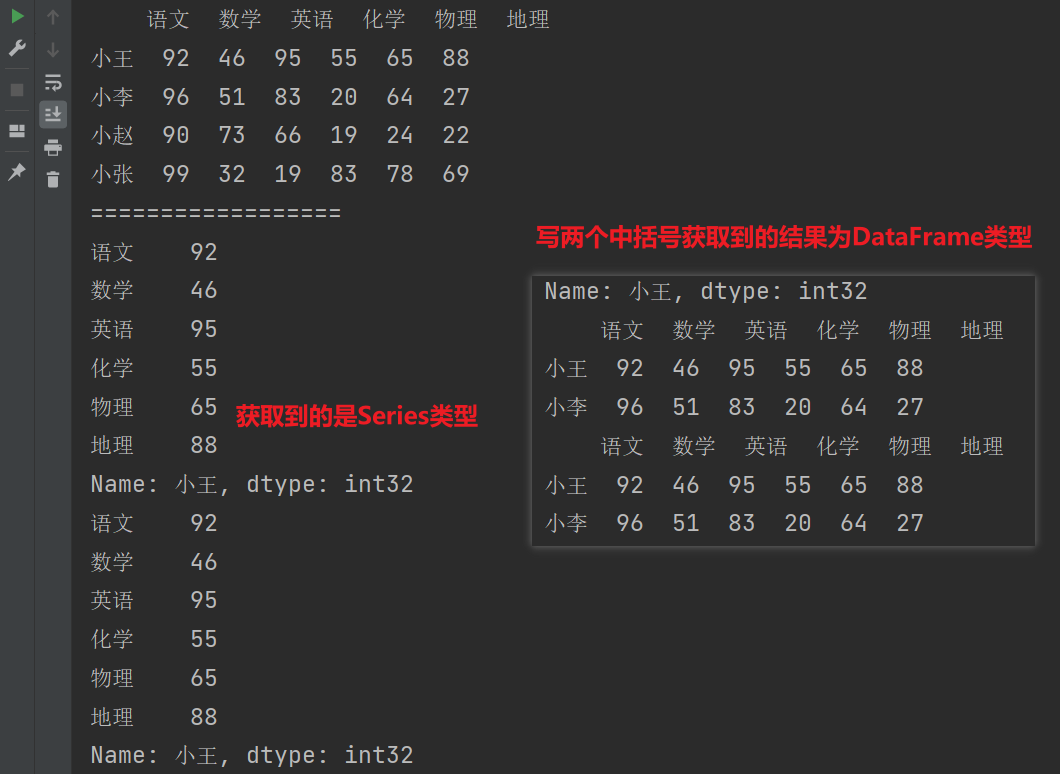
# 对行取索引
# DataFrame默认情况下是先取列索引,然后再取行索引
print(df.loc['小王']) # 获取到的是Series类型
print(df.iloc[0]) # 获取到的是Series类型
print(df.loc[['小王','小李']]) # 获取到的是DataFrame类型
print(df.iloc[[0,1]]) # 获取到的是DataFrame类型
输出结果:
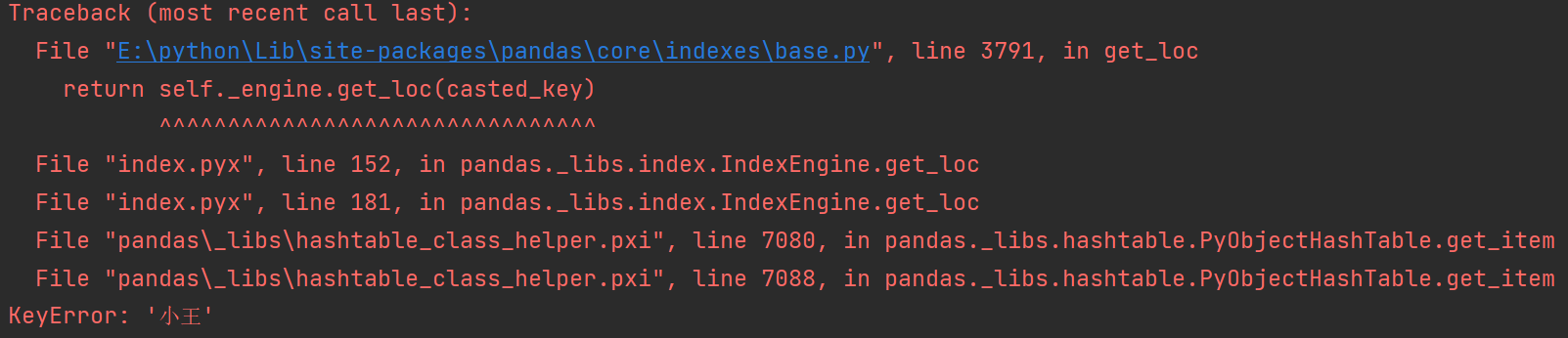
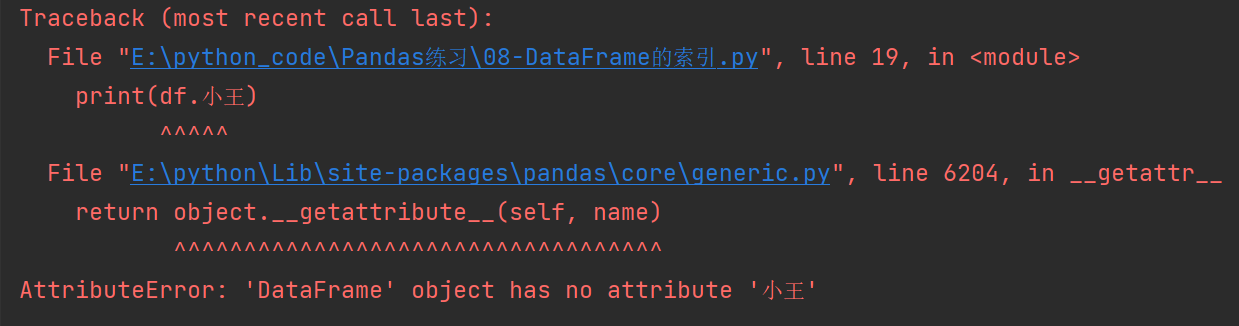
注意:如果使用 . 或者 [] 的方式来对行取索引就会报错。
# 不可以直接取行索引
print(df['小王'])
print(df.小王)
3.3.3 对元素进行索引
- 使用列索引。
- 使用行索引
(iloc[3,1])相对于两个参数;(iloc[3,3])里面的[3,3]看作是一个参数。 - 使用values属性(二维NumPy数组)
print(df.values)。
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
print(df)
print("==================")
# 对元素进行索引
# 先取列,再取行
print(df['语文']['小王'])
print(df['语文'][0])
print(df.语文[0])
print(df.语文.小王)
print("========================")
# 先取行,再去列
print(df.loc['小王']['语文'])
print(df.loc['小王','语文'])
print(df.loc['小王'][0])
print(df.iloc[0][1])
print(df.iloc[0,1])
print(df.iloc[0]['语文'])
注意:如果索引是数字的话就不要用.的方式来获取值了。
输出结果:
3.4 DataFrame 的切片
DataFrame的切片是选取DataFrame中部分数据的操作,类似于Python中的列表或字符串切片。
注意:直接用中括号时:
- 索引优先对列进行操作。
- 切片优先对行进行操作。
3.4.1 行切片
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
print(df)
# DataFrame切片是优先对行先切片
# 行切片
print(df[1:3]) # 左闭右开
print(df.iloc[1:3]) # 写法二
print(df['小李':'小赵']) # 左闭右闭
print(df.loc['小李':'小赵']) # 写法二
输出结果:
3.4.2 列切片
由于DataFrame是优先对行进行切片的。所以要对列做切片,首先对行做切片。
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
print(df)
# 列切片
# 对列做切片必须先对行切片
print(df.iloc[1:3,1:4])
print(df.loc[:,'数学':'化学'])
# 在方括号中逗号前面是对行做切片,逗号后是对列做切片
# 因为逗号前只有一个冒号,所以是对所有行
说明:
-
df.iloc[1:3,1:4]-
1:3表示要选择第 2 行到第 3 行之间的所有行。注意,这里不包括第 3 行,即只选择第 2 行和第 3 行。 -
1:4表示要选择第 2 列到第 4 列之间的所有列。同样地,这里不包括第 4 列,即只选择第 2 列、第 3 列和第 4 列。
-
输出结果:
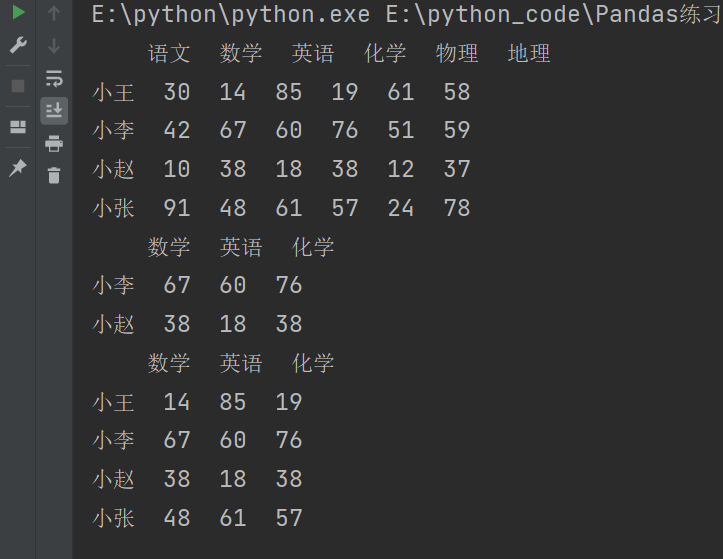
3.4.3 练习
需求:获取小李和小赵这两个人的数学和化学成绩
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
print(df)
# 写法一
print(df.loc['小李':'小赵','数学':'化学'])
# 写法二
print(df.iloc[1:3,1:4])
输出结果:
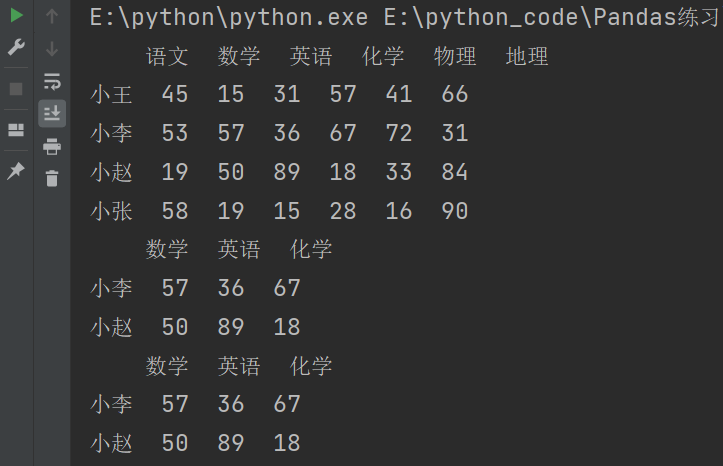
需求:获取小赵一个人的数学,英语,化学成绩。
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
print(df)
# 写法一
print(df.loc['小赵','数学':'化学'])
# 写法二
print(df.iloc[2,1:4])
输出结果:
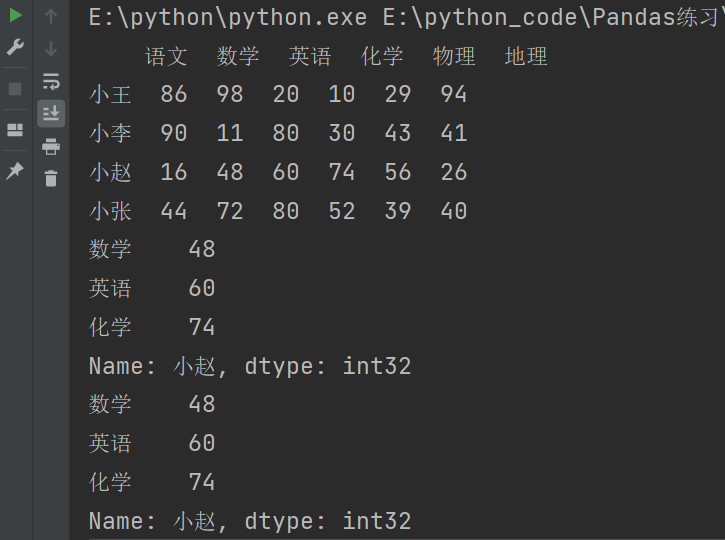
需求:获取取任意两个人的成绩
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
print(df)
# 写法一
print(df.loc[['小李','小张'],'数学':'化学'])
# 写法二
print(df.iloc[[1,3],1:4])
# 写法三
print(df.iloc[[1,-1],1:4])
说明:['小李', '小张'] 是一个包含两个元素的列表,用于指定要选择的行标签。
输出结果:
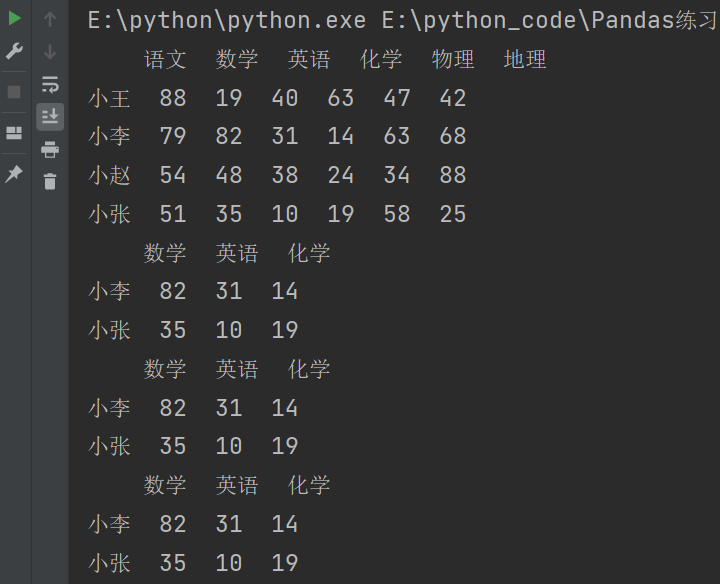
3.4.4 总结
- 要么取一行或者一列:行索引,列索引。
- 要么取连续的多行或多列:切片。
- 要么取不连续的多行或多列:中括号。
3.5 DataFrame 的运算
DataFrame之间的运算:
- 在运算中自动对齐不同索引的数据。
- 如果索引不对应,则补NaN。
- DataFrame没有广播机制。
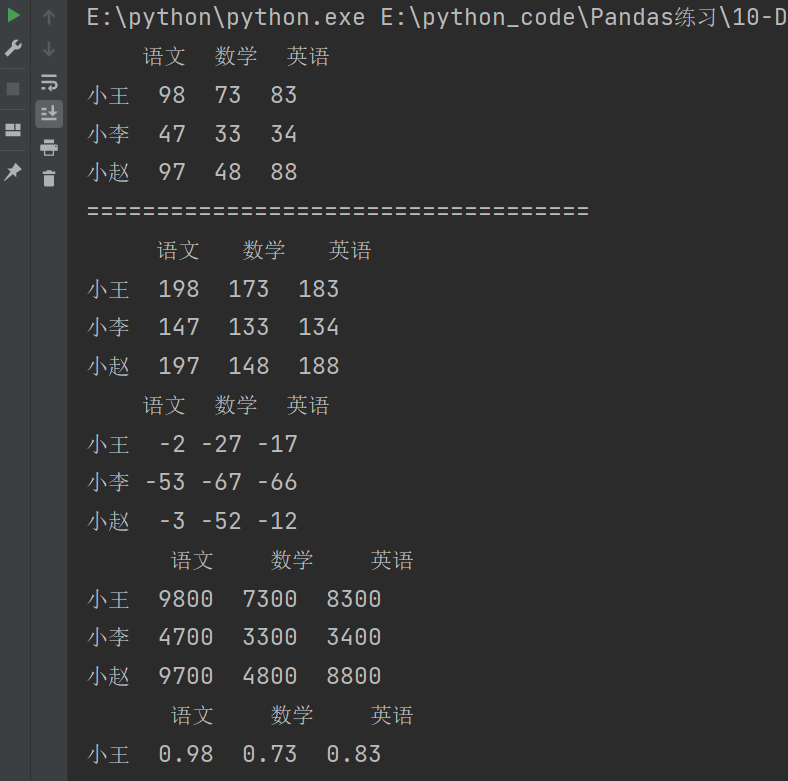
3.5.2 DataFrame 和标量之间的运算
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
data = np.random.randint(10,100,size=(4,6)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语','化学','物理','地理']
)
print(df1)
print("====================================")
print(df1 + 100)
print(df1 - 100)
print(df1 * 100)
print(df1 / 100)
输出结果:
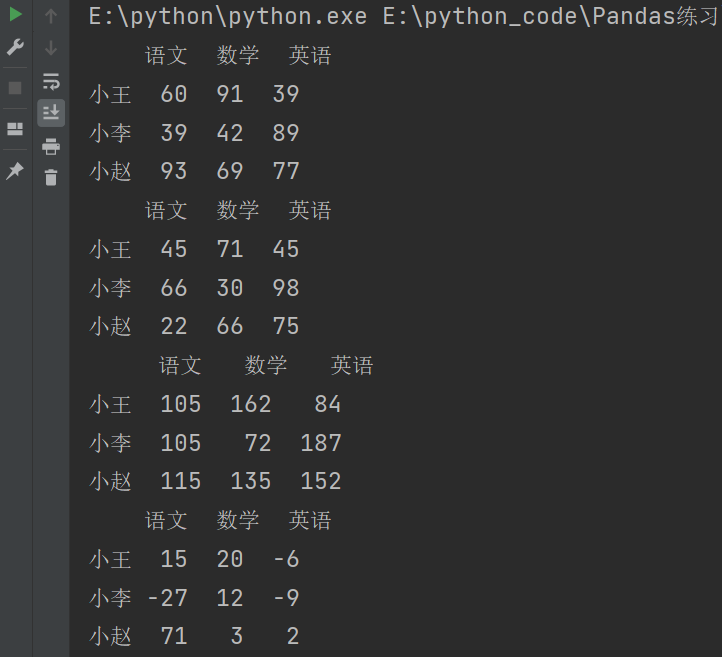
3.5.3 DataFrame 之间的运算
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
data = np.random.randint(10,100,size=(3,3)),
index = ['小王','小李','小赵'],
columns = ['语文','数学','英语']
)
df2 = pd.DataFrame(
data = np.random.randint(10,100,size=(3,3)),
index = ['小王','小李','小赵'],
columns = ['语文','数学','英语']
)
print(df1)
print(df2)
print(df1 + df2)
print(df1 - df2)
输出结果:
两个DataFrame中的值个数不一致的时候。
import numpy as np
import pandas as pd
df1 = pd.DataFrame(
data = np.random.randint(10,100,size=(3,3)),
index = ['小王','小李','小赵'],
columns = ['语文','数学','英语']
)
df2 = pd.DataFrame(
data = np.random.randint(10,100,size=(4,3)),
index = ['小王','小李','小赵','小张'],
columns = ['语文','数学','英语']
)
print(df1)
print(df2)
print(df1 + df2)
说明:如果索引不对应,则补NaN。
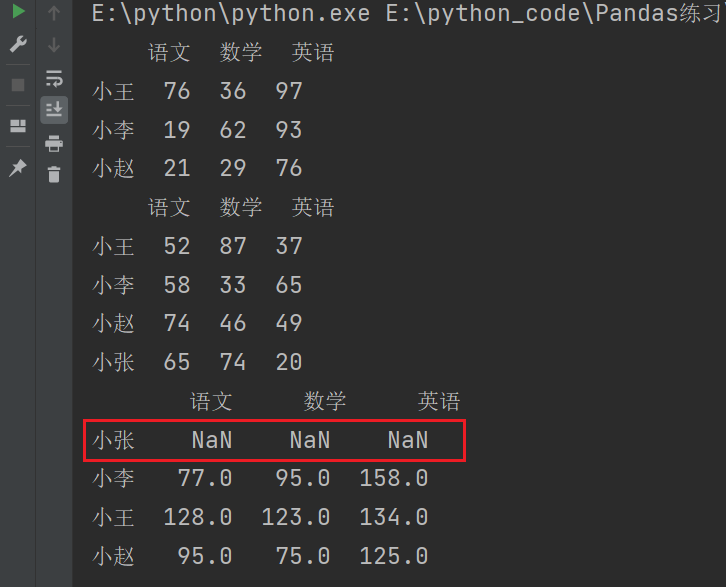
可以使用.add()方法,添加参数fill_value。
print(df1.add(df2,fill_value=0))
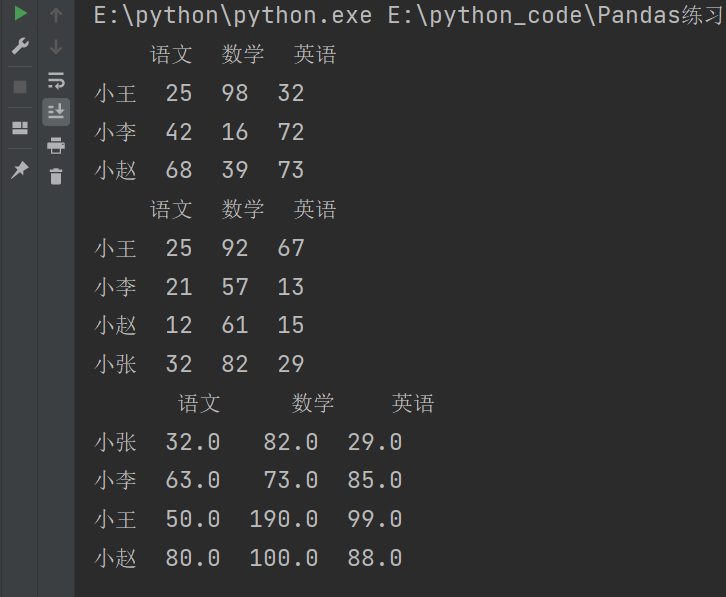
补充
数据操作和运算:
add():执行元素间的加法操作。subtract():执行元素间的减法操作。multiply():执行元素间的乘法操作。divide():执行元素间的除法操作。
3.5.4 DataFrame 和 Series 之间的运算
DataFrame 和 Series 之间的运算其中Series的值将会被广播(broadcasted)到DataFrame 的每一行或列(具体看配置情况),然后进行运算。
具体来说,如果DataFrame是一个m行n列,Series含有n个元素,那么运算结果将会是一个m行n列的新DataFrame,其中每一行或列都与Series进行运算。
import numpy as np
import pandas as pd
# Series和DadaFrame之间的运算
df1 = pd.DataFrame(
data = np.random.randint(10,100,size=(3,3)),
index = ['小王','小李','小赵'],
columns = ['语文','数学','英语']
)
s = pd.Series([100,10,1],index = df1.columns)
print(df1)
print(s)
# 方式一
print(df1 + s)
# 方式二
print(df1.add(s,axis='columns')) # axis默认值是columns
# 方式三
print(df1.add(s,axis=1)) # 按照列进行匹配
说明:index = df1.columns表示Series 对象的索引需要与 DataFrame 的列索引对应
输出结果:
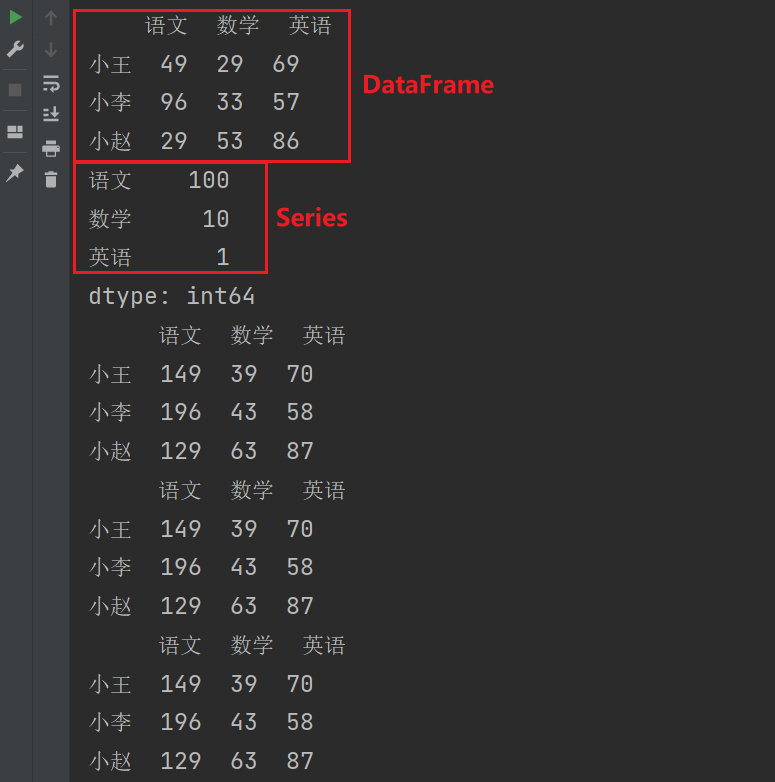
将axis的值修改为0,表示按照行进行匹配,输出结果为NaN
print(df1.add(s,axis=0))
会把Series中的语文,数学,英语当作行进行匹配。发现于DataFrame之间的行不匹配所以会多出三行。
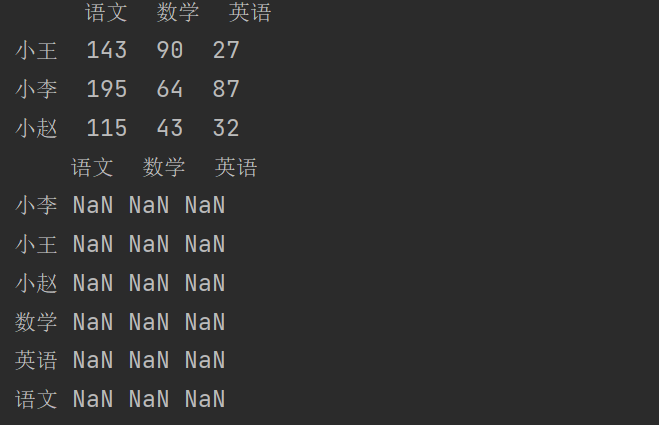
Series 对象的索引需要与 DataFrame 的行索引对应,那么就将index的值修改为df1.index。
df1 = pd.DataFrame(
data = np.random.randint(10,100,size=(3,3)),
index = ['小王','小李','小赵'],
columns = ['语文','数学','英语']
)
print(df1)
print("===========================")
s2 = pd.Series([100,10,1],index = df1.index)
print(s2)
print(df1 + s2) # 全为NaN
print(df1.add(s2,axis=0)) # 按照行进行匹配(自动匹配行索引)
说明:当执行 df1 + s2 进行相加操作时,虽然df1和s2的索引相同,但是由于默认情况下,Pandas会按照列进行对齐,因此在这个操作中,Pandas会尝试将s2的值与df1的每一列进行相加。这会导致运算过程中出现不匹配的情况,从而产生 NaN 值。
4. Pandas 层次化索引
Pandas 的层次化索引(Hierarchical Indexing),也被称为多级索引(MultiIndex),是 Pandas 库的一个重要特性。它允许在数据框或系列中创建具有多个层次的行或列索引,从而更灵活地组织和访问数据。
层次化索引可以看作是在一个或多个维度上将索引进行扩展,使得数据可以按照多个维度进行标识和查询。通过层次化索引,我们可以轻松处理具有复杂结构的数据,例如多维时间序列、多个特征的数据集等。
在 Pandas 中,层次化索引主要通过以下两种方式实现:
- 多级行索引:可以在数据框的行索引中设置多个层次。每个层次可以使用不同的标签或整数值来标识不同的行。多级行索引可以通过
pd.MultiIndex类来创建,或者通过在创建数据框时直接指定层次化索引。 - 多级列索引:可以在数据框的列索引中设置多个层次。每个层次可以使用不同的标签或整数值来标识不同的列。多级列索引可以通过在创建数据框时使用元组列表来指定层次化索引。
4.1 创建多层行/列索引
4.1.1 隐式构造
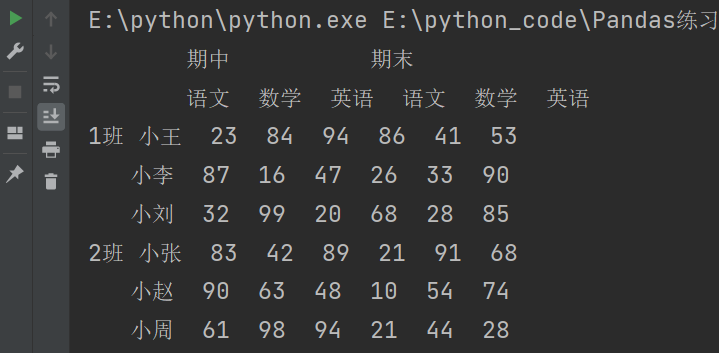
最常见的方法是给DataFrame构造函数的index参数传递两个或更多的数组(列表)。
import pandas as pd
import numpy as np
# 创建多层索引
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = [
['1班','1班','1班','2班','2班','2班'],
['小王','小李','小刘','小张','小赵','小周']
],
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
# 如果连续的三个是相同的,那么就会显示一个
print(df)
Series也可以创建多层索引
import pandas as pd
import numpy as np
# Series创建多层索引
s = pd.Series(
data = np.random.randint(10,100,size=6),
index=[
['1班', '1班', '1班', '2班', '2班', '2班'],
['小王', '小李', '小刘', '小张', '小赵', '小周']
],
)
print(s)
4.1.2 显示构造
pd.MultiIndex.from_arrays() 是 Pandas 库中用于创建多级索引的函数之一。它可以根据给定的数组来创建一个多级索引对象。(from_arrays可以默认不写)
使用数组
pd.MultiIndex.from_arrays
df2 = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = pd.MultiIndex.from_arrays([
['1班','1班','1班','2班','2班','2班'],
['小王','小李','小刘','小张','小赵','小周']
]),
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
print(df2)
使用元组(tuple)
pd.MultiIndex.from_tuples
df3 = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = pd.MultiIndex.from_tuples(
(
('1班','小王'),('1班','小李'),('1班','小刘'),
('2班','小张'),('2班','小赵'),('2班','小周'),
)
),
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
# 写法二
df3 = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = pd.MultiIndex.from_tuples(
(
('1班','小王'),('1班','小李'),('1班','小刘'),
('2班','小张'),('2班','小赵'),('2班','小周'),
)
),
columns = pd.MultiIndex.from_tuples(
(
('期中','语文'),('期中','数学'),('期中','英语'),
('期末','语文'),('期末','数学'),('期末','英语'),
)
)
)
print(df3)
pd.MultiIndex.from_tuples() 是 Pandas 库中的一个函数,用于从元组列表创建多级索引对象。
使用product(笛卡尔积)
笛卡尔积:{a,b}{c,d} => {a,c},{a,d},{b,c},{b,d}
pd.MultiIndex.from_product
# 使用product(笛卡尔积)
# 笛卡尔积:{a,b}{c,d} => {a,c},{a,d},{b,c},{b,d}
df4 = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = pd.MultiIndex.from_product([
['1班','2班'],
['小王','小李','小刘']
]),
columns = pd.MultiIndex.from_product([
['期中','期末'],
['语文','数学','英语']
])
)
print(df4)
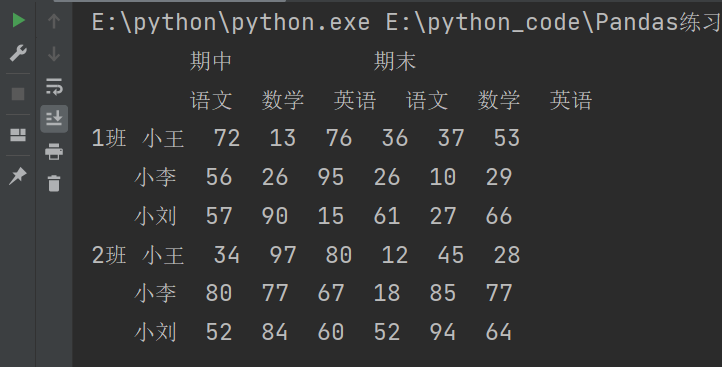
4.2 多层索引对象的索引与切片操作
4.2.1 Series 的操作
对于Series来说,直接中括号 [] 与使用 .loc() 完全一样。
4.2.1.1 索引
显示索引
import pandas as pd
import numpy as np
s = pd.Series(
data = np.random.randint(10,100,size = 6),
index=[
['1班', '1班', '1班', '2班', '2班', '2班'],
['小王', '小李', '小刘', '小张', '小赵', '小周']
]
)
print(s)
print("====================")
# 显示索引
print(s['1班'])
print(s[['1班']]) # 多层索引
print(s[['1班','2班']]) # 多层索引
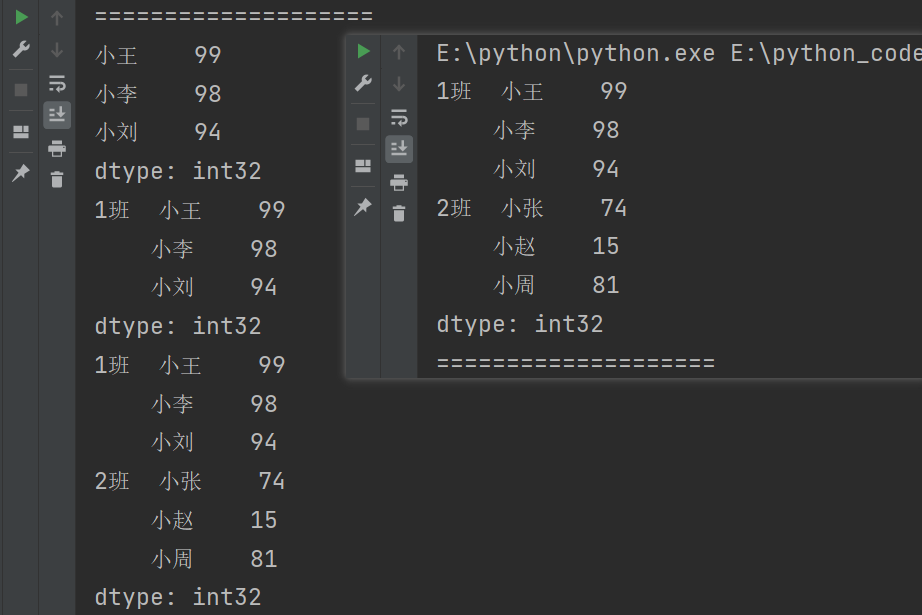
隐式索引
print(f"s[0]的值为: {s[0]}")
print(f"s[1]的值为: {s[1]}")
print(f"s[4]的值为: {s[4]}")
print(f"s[0]的值为: {s.iloc[0]}")
print(s.iloc[[0,1]])
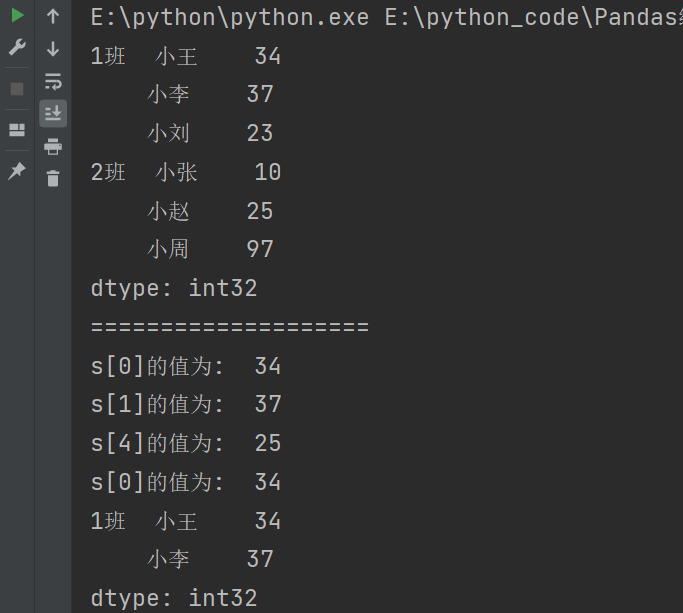
4.2.1.2 元素
import pandas as pd
import numpy as np
s = pd.Series(
data = np.random.randint(10,100,size = 6),
index=[
['1班', '1班', '1班', '2班', '2班', '2班'],
['小王', '小李', '小刘', '小张', '小赵', '小周']
]
)
print(s)
print("====================")
# 先取第一层,再取第二层
print(s['1班','小刘'])
print(s['1班']['小刘'])
print(s.loc['1班','小刘'])
print(s.loc['1班']['小刘'])
print(s.loc['1班'][['小李','小刘']])
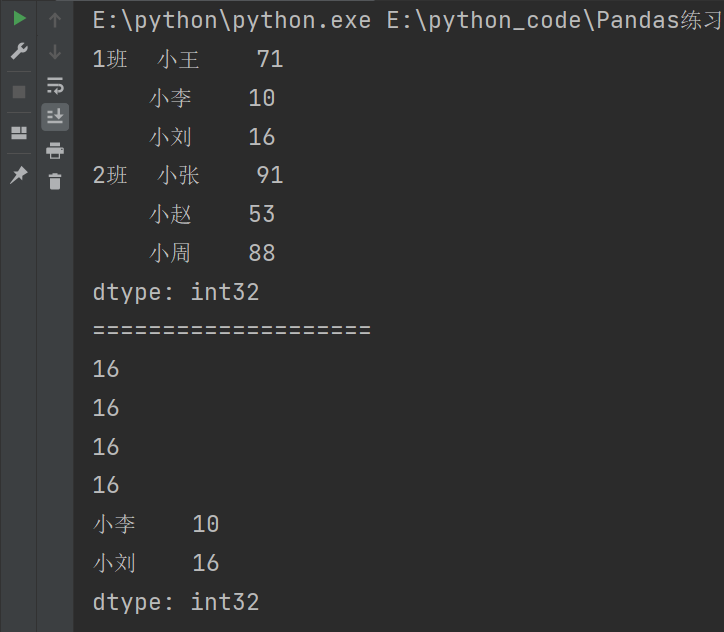
4.2.1.3 切片
显示切片
import pandas as pd
import numpy as np
s = pd.Series(
data = np.random.randint(10,100,size = 6),
index=[
['1班', '1班', '1班', '2班', '2班', '2班'],
['小王', '小李', '小刘', '小张', '小赵', '小周']
]
)
print(s)
print("====================")
print(s['1班':'2班'])
print(s.loc['1班':'2班'])
print(s.loc['1班'][:])
print(s.loc['1班'][1:3])
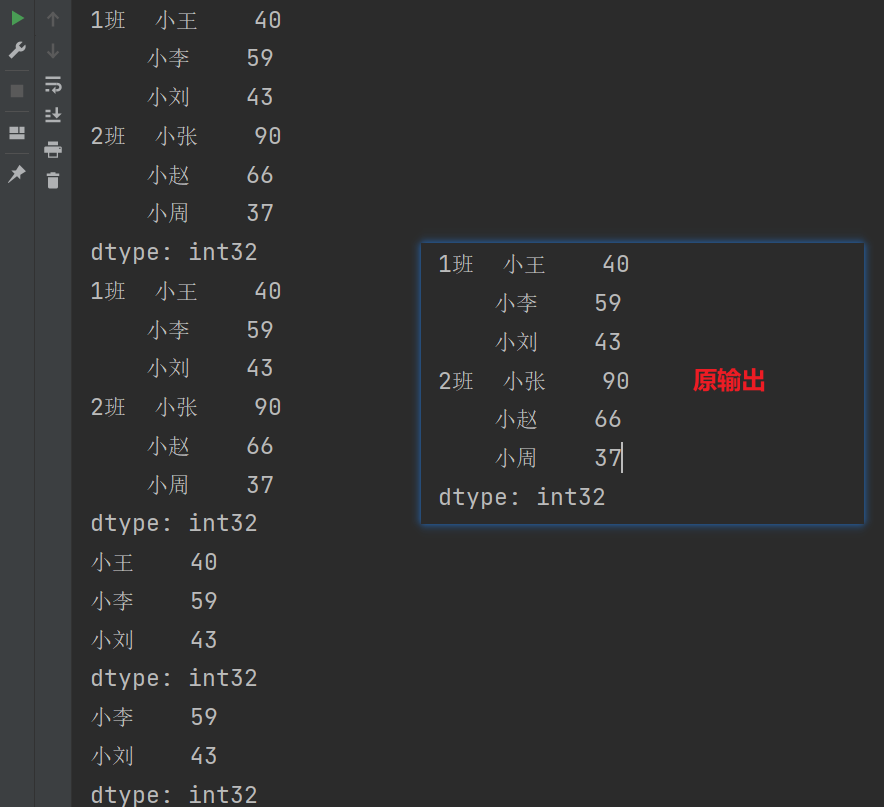
隐式切片
print(s[1:5])
print(s.iloc[1:5])
4.2.2 DataFrame 的操作
4.2.2.1 元素
import pandas as pd
import numpy as np
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = [
['1班','1班','1班','2班','2班','2班'],
['小王','小李','小刘','小张','小赵','小周']
],
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
print(df)
print("================================")
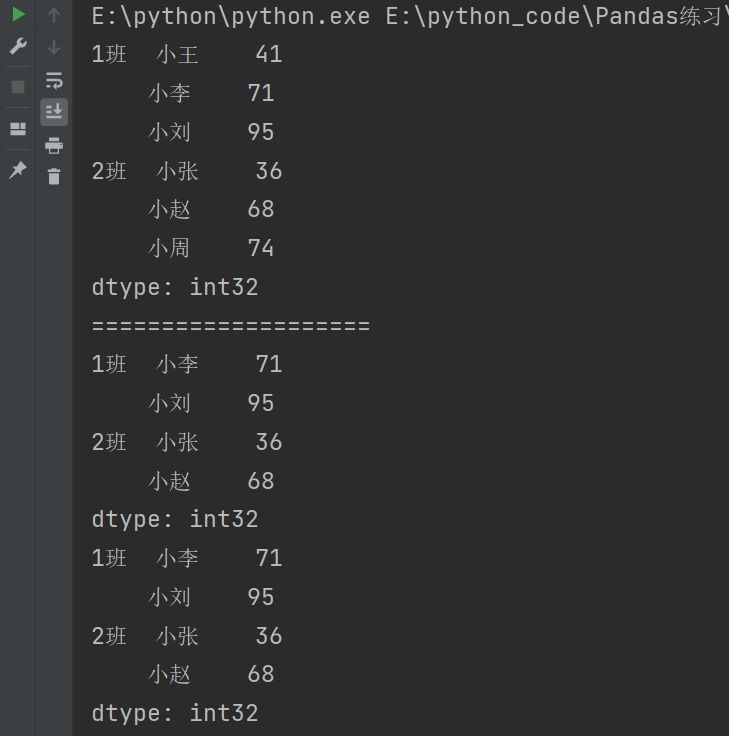
# 获取元素
print(df['期中']['数学']['1班']['小刘'])
print(df['期中']['数学']['1班'][2])
print(df.loc[('1班','小刘'),('期中','数学')])
print(df.loc['1班','小李']['期中','数学'])
print(df.iloc[2,1])
print(df.iloc[2][1])
补充:使用print(df['1班']['小刘']['期中']['数学'])进行数据操作的时候,就会报错。因为在使用 [] 运算符时,Pandas 会默认将其解释为对列进行选择的操作。
4.2.2.2 索引
列索引
import pandas as pd
import numpy as np
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = [
['1班','1班','1班','2班','2班','2班'],
['小王','小李','小刘','小张','小赵','小周']
],
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
print(df)
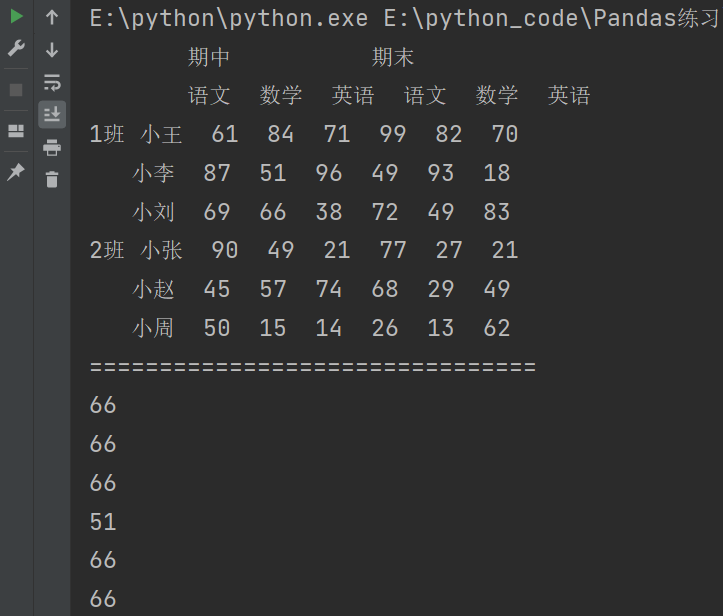
print("================================")
print(df['期中'])
print(df['期中'][['数学']])
print(df['期中']['数学'])
print(df['期中','数学'])
print(df.期中.数学)
print(df.iloc[:,2]) # 逗号之前只有一个冒号,表示对所有行。逗号后表示对列
print(df.iloc[:,[0,2,1]])
print(df.loc[:,('期中','英语')])
行索引
import pandas as pd
import numpy as np
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = [
['1班','1班','1班','2班','2班','2班'],
['小王','小李','小刘','小张','小赵','小周']
],
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
print(df)
print("================================")
print(df.loc['2班'])
print(df.loc['2班','小赵'])
print(df.loc[('2班','小赵')])
print(df.loc['2班'].loc['小赵'])
print(df.iloc[4][1]) # 隐式索引只需要关注第几行即可
print(df.iloc[4,1])
print(df.iloc[[1,2,3,4]])
4.2.2.3 切片
行切片
建议切片使用隐式索引
import pandas as pd
import numpy as np
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = [
['1班','1班','1班','2班','2班','2班'],
['小王','小李','小刘','小张','小赵','小周']
],
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
print(df)
print("================================")
# 行切片(优先)
print(df[1:5]) # 左闭右开(从第二行到第5行)
print(df.iloc[1:5])
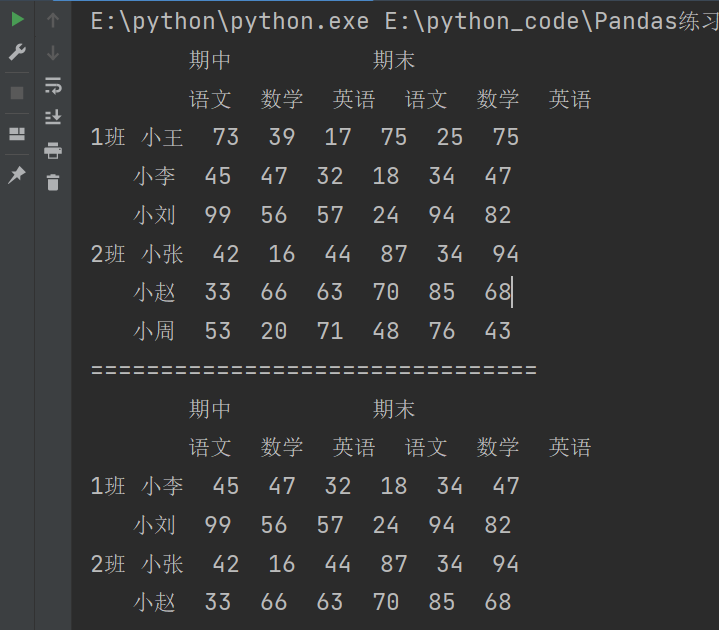
列切片
import pandas as pd
import numpy as np
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = [
['1班','1班','1班','2班','2班','2班'],
['小王','小李','小刘','小张','小赵','小周']
],
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
print(df)
print("================================")
# 列切片
# 逗号之前只有一个冒号,表示对所有行。逗号后表示对列
print(df.iloc[:,1:5])
print(df.loc[:,'期中':'期末'])
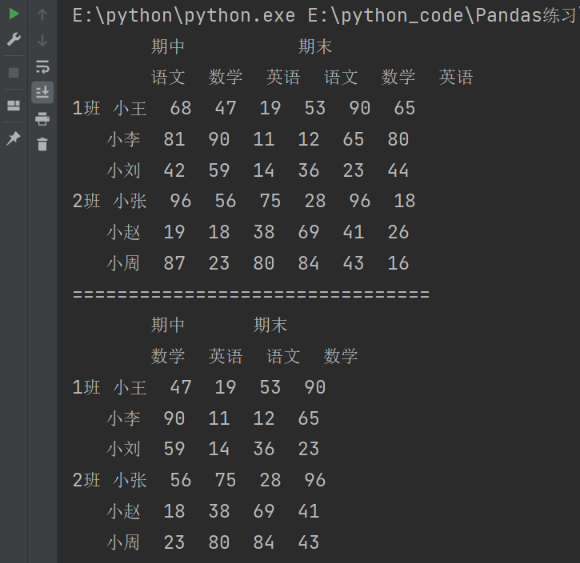
5. 索引的堆叠
stack()方法将列索引转换为行索引,从而创建一个具有多级行索引的 Series 或 DataFrame。它是将数据从"宽格式"转换为"长格式"的操作。unstack()方法将行索引转换为列索引,从而创建一个具有多级列索引的 DataFrame。它是将数据从"长格式"转换为"宽格式"的操作。
5.1 stack() 方法
小技巧:使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = pd.MultiIndex.from_product([
['1班','2班'],
['小王','小李','小刘']
]),
columns = pd.MultiIndex.from_product([
['期中','期末'],
['语文','数学','英语']
])
)
print(df)
print("===============================")
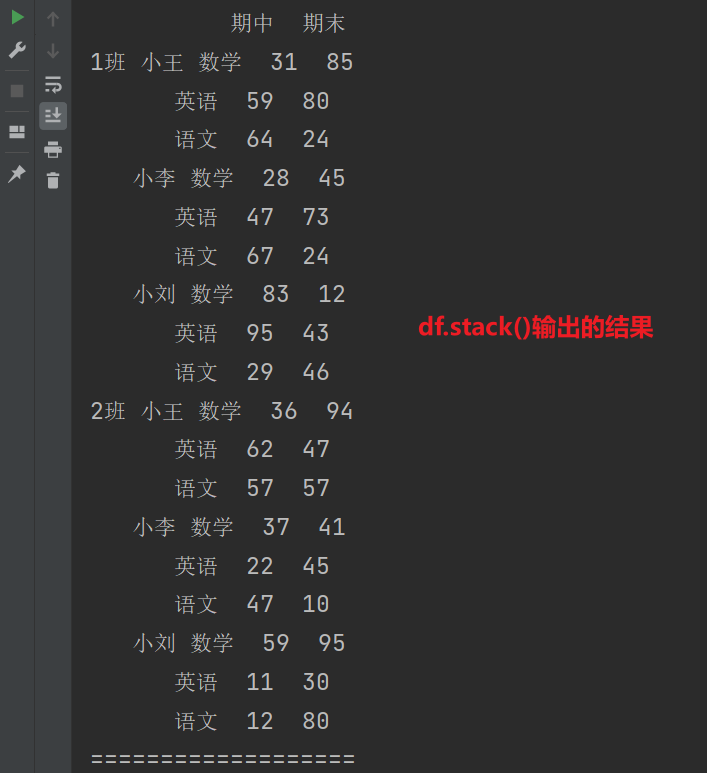
# stack()方法将列索引转换为行索引
# 默认是将最里层的列索引变成行索引
print(df.stack())
print("===================")
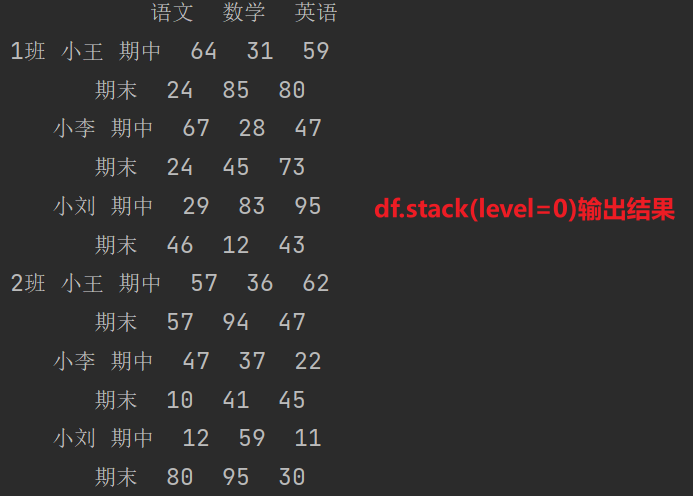
# level默认-1
print(df.stack(level = -1)) # 表示最后一层
print(df.stack(level = 1)) # 表示第一层
print(df.stack(level = 0)) # 表示第二层
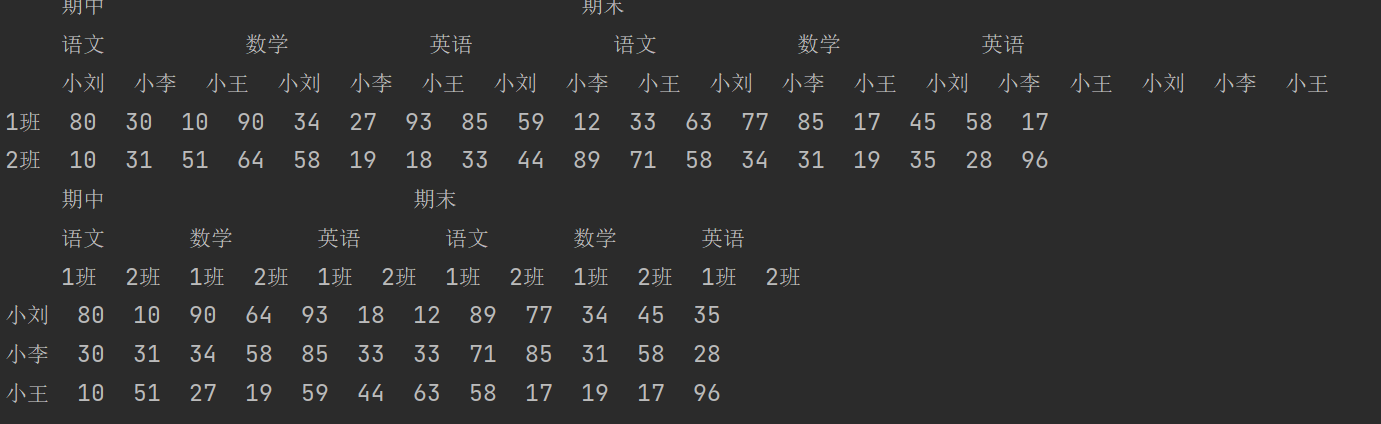
5.2 unstack() 方法
小技巧:使用unstack()的时候,level等于哪一个,哪一个就消失,出现在列里。
print(df.unstack())
print("===================")
print(df.unstack(level=-1))
print(df.unstack(level=1))
print(df.unstack(level=0))
5.3 fill_value 填充
fill_value 参数是可选的,用于指定在转换过程中遇到缺失值时所填充的默认值。
import pandas as pd
import numpy as np
df2 = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index = pd.MultiIndex.from_tuples(
(
('1班','小王'),('1班','小李'),('1班','小刘'),
('2班','小张'),('2班','小赵'),('2班','小周'),
)
),
columns = [
['期中','期中','期中','期末','期末','期末'],
['语文','数学','英语','语文','数学','英语']
]
)
print(df2)
print("=====================")
print(df2.unstack())
print(df2.unstack(fill_value=0))
说明:索引对齐错误才会出现缺失值的情况,在上例中当使用 df2.unstack() 将行索引转换为列索引时,由于不同班级的学生不同,就会导致转换后的数据框中出现缺失值。
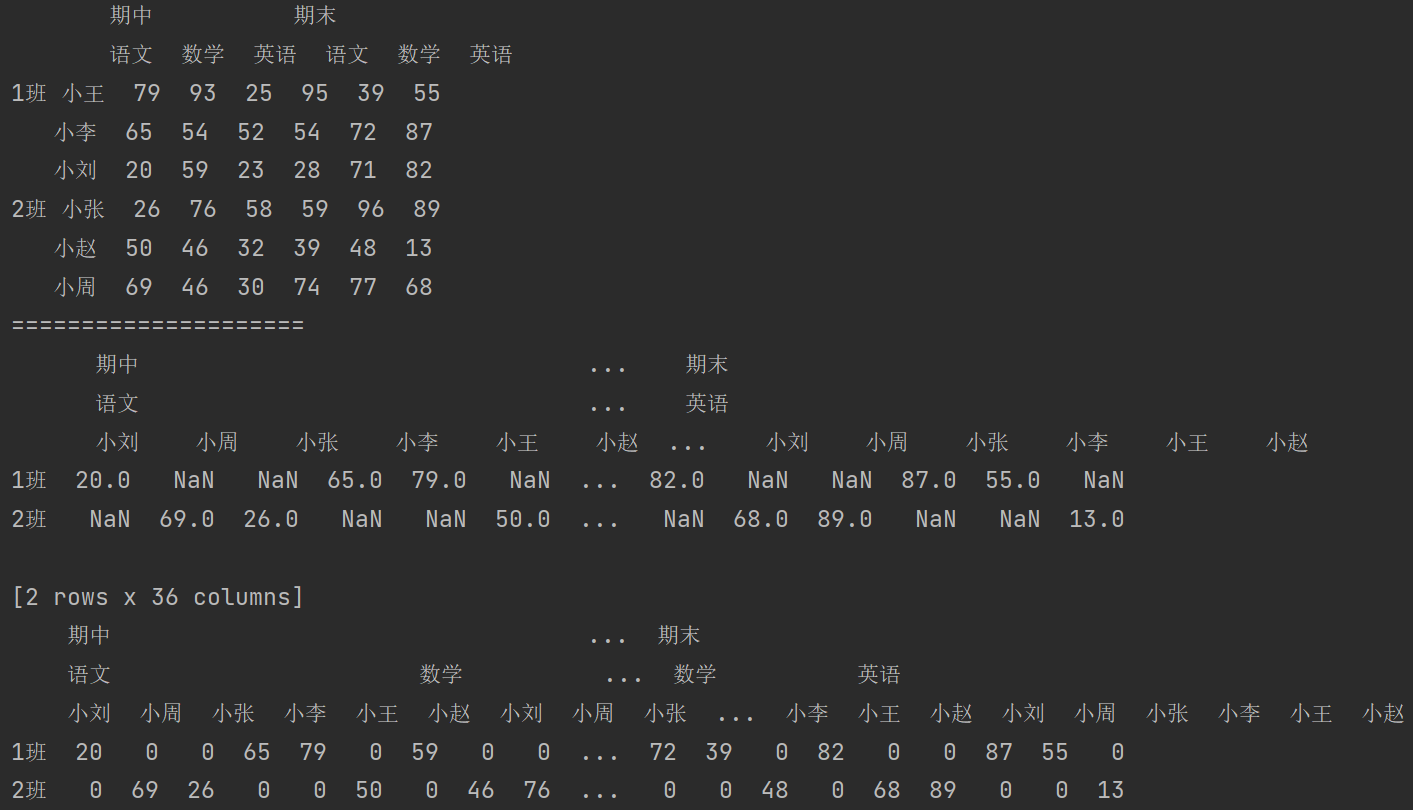
6. 聚合操作
6.1 DataFrame 的聚合操作
DataFrame 的聚合操作是指对数据进行统计汇总。
DataFrame的聚合操作:
- 求和
- 平均值
- 最大值
- 最小值等
import pandas as pd
import numpy as np
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index=[
['1班', '1班', '1班', '2班', '2班', '2班'],
['小王', '小李', '小刘', '小张', '小赵', '小周']
],
columns=[
['期中', '期中', '期中', '期末', '期末', '期末'],
['语文', '数学', '英语', '语文', '数学', '英语']
]
)
print(df)
print("======================")
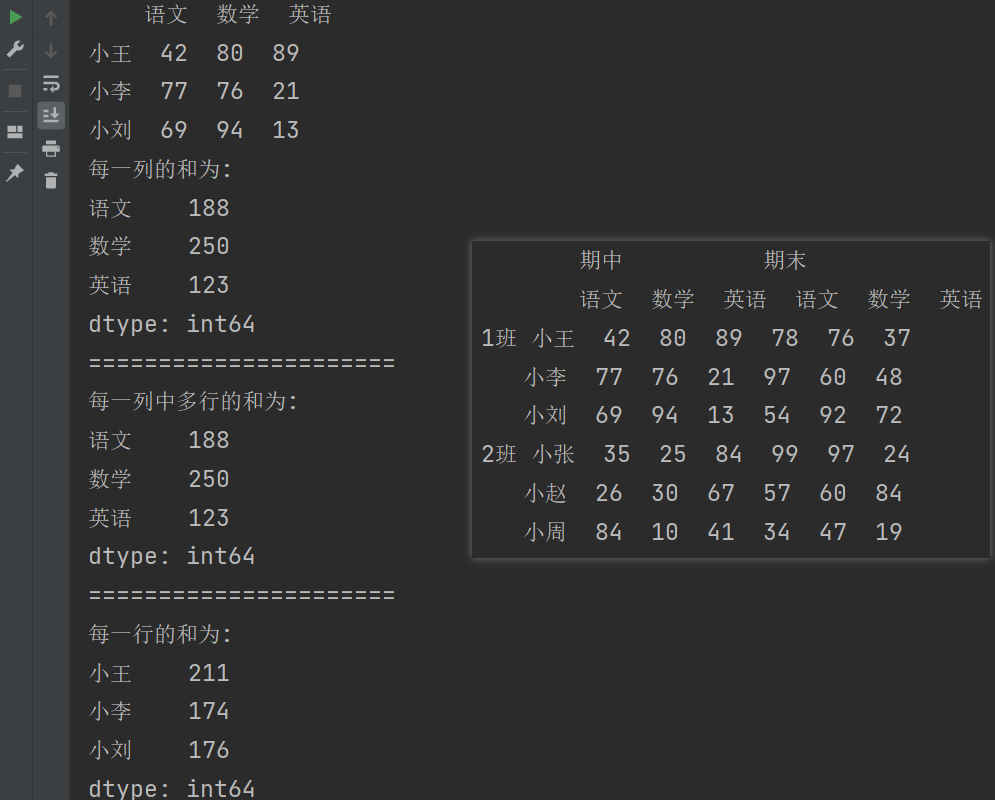
df2 = df.loc['1班','期中']
print(df2)
# 求和
print(f"每一列的和为: {df2.sum()}") # 求出每一列的和
print("======================")
print(f"每一列中多行的和为: {df2.sum(axis= 0)}") # 求出每一列中多行的和
print("======================")
print(f"每一行的和为: {df2.sum(axis= 1)}") # 求出每一行的和
print("======================")
说明:
axis参数用于指定沿着哪个轴进行求和操作。- axis值为0表示对列进行操作。
- axis值为1表示对行进行操作。
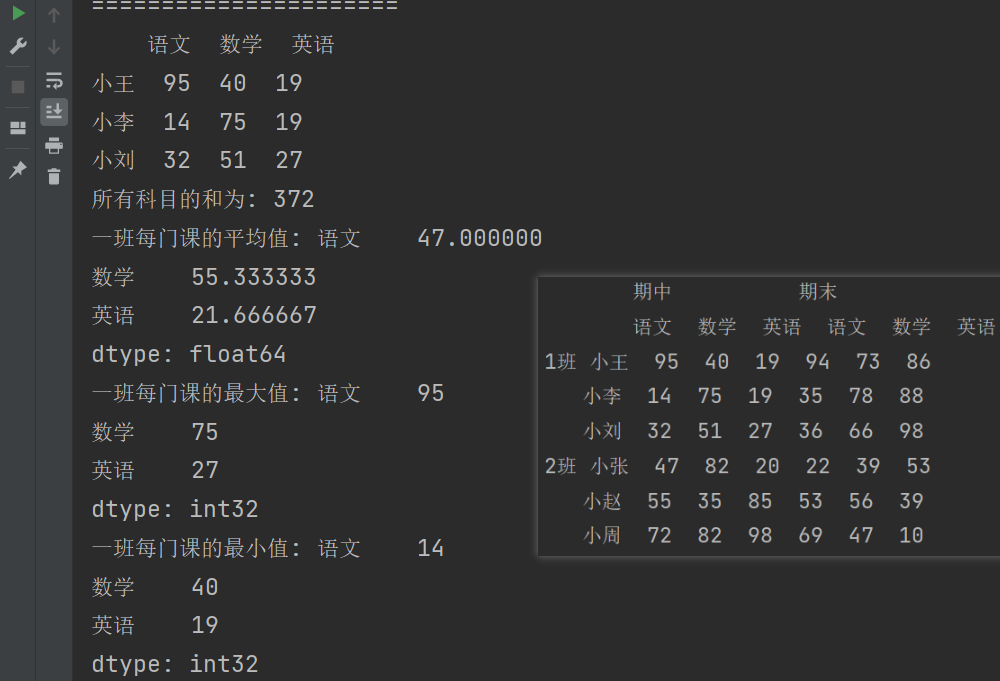
# 求所有数的和
print(f"所有科目的和为: {df2.values.sum()}")
# 平均值
print(f"一班每门课的平均值: {df2.mean()}")
# 最大值
print(f"一班每门课的最大值: {df2.max()}")
# 最小值
print(f"一班每门课的最小值: {df2.min()}")
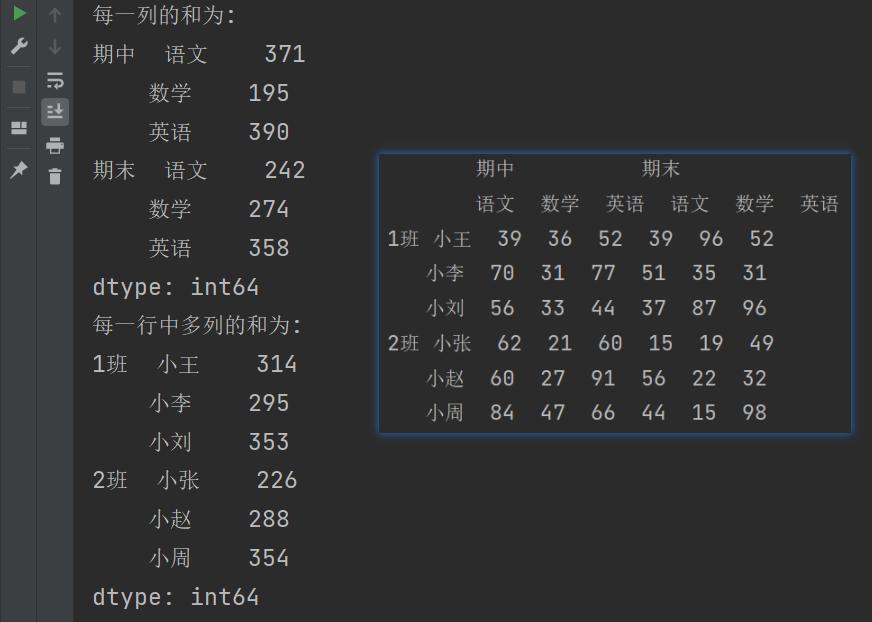
6.2 多层索引聚合操作
import pandas as pd
import numpy as np
# 多层索引聚合操作
df = pd.DataFrame(
data = np.random.randint(10,100,size=(6,6)),
index=[
['1班', '1班', '1班', '2班', '2班', '2班'],
['小王', '小李', '小刘', '小张', '小赵', '小周']
],
columns=[
['期中', '期中', '期中', '期末', '期末', '期末'],
['语文', '数学', '英语', '语文', '数学', '英语']
]
)
print(df)
print("======================")
print(f"每一列的和为:\n{df.sum()}") # 求每一列中多行的和
print(f"每一列的和为:\n{df.sum(axis=0)}") # 写法二
print(f"每一行中多列的和为:\n{df.sum(axis=1)}") # 求每一行中多列的和
# level参数不可用
# print(df.sum(axis=0,level=0)) # 表示计算行中的第一层(level=0)
# print(df.sum(axis=0,level=1)) # 表示计算行中的第二层(level=1)
# print(df.sum(axis=1,level=0)) # 表示计算列中的第一层(level=0)
# print(df.sum(axis=1,level=1)) # 表示计算列中的第二层(level=1)
7. Pandas 数据合并
pd.concat()
pd.append()
pd.merge()
- 一对一关系
- 一对多关系
- 多对多关系
7.1 使用 pd.concat() 级联
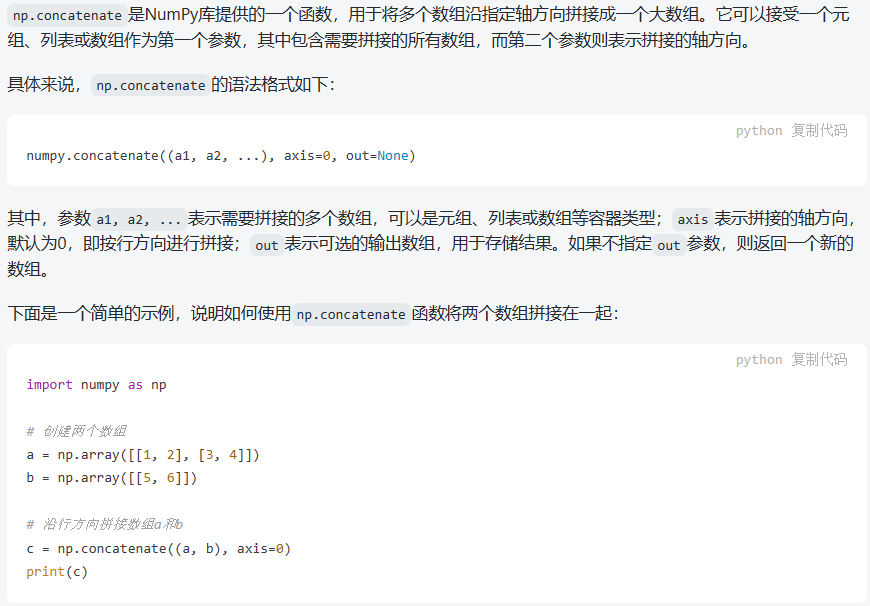
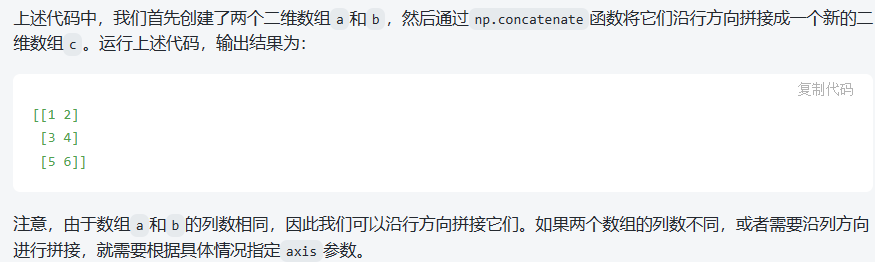
pandas使用pd.concat函数,与np.concatenate函数类似。
np.concatenate函数:
7.1.1 简单级联
import pandas as pd
def make_df(indexs,columns):
data = [
[str(j)+str(i) for j in columns] for i in indexs
]
df = pd.DataFrame(data = data,index = indexs,columns = columns)
return df
# 简单级联
df1 = make_df([1,2],['A','B'])
df2 = make_df([3,4],['A','B'])
print(df1)
print(df2)
print("==================")
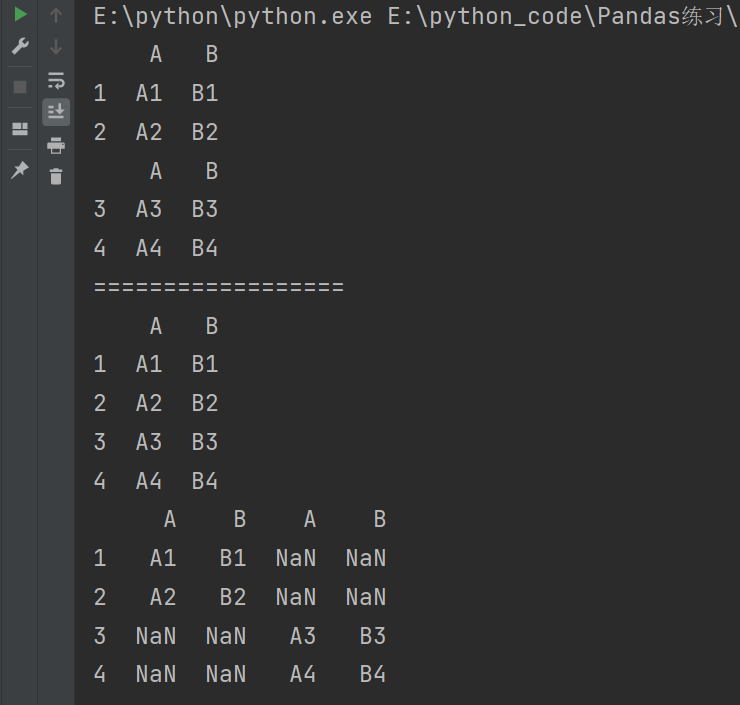
print(pd.concat([df1,df2],axis=0)) # 上下合并(垂直合并)
print(pd.concat([df1,df2],axis=1)) # 左右合并(水平合并)。会出现索引不匹配的情况
说明:默认是进行上下合并(垂直合并)
7.1.2 忽略行索引
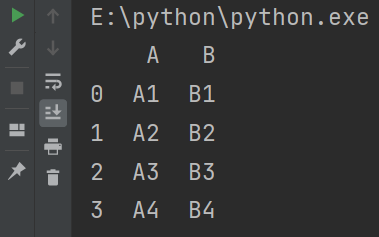
print(pd.concat([df1,df2],ignore_index=True))
7.1.3 使用多层索引
print(pd.concat([df1,df2],keys=['x','y']))
print(pd.concat([df1,df2],keys=['x','y'],axis=1))
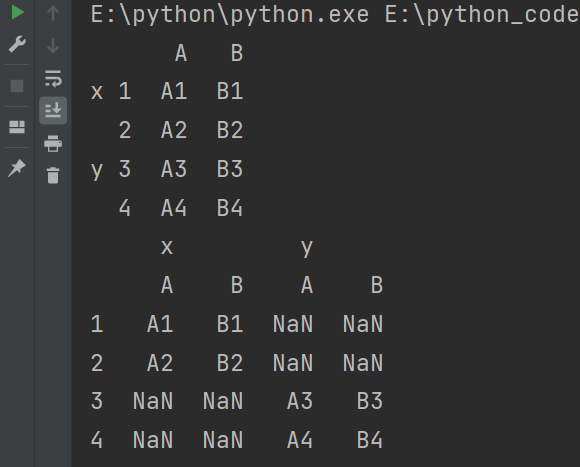
7.1.4 不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致。
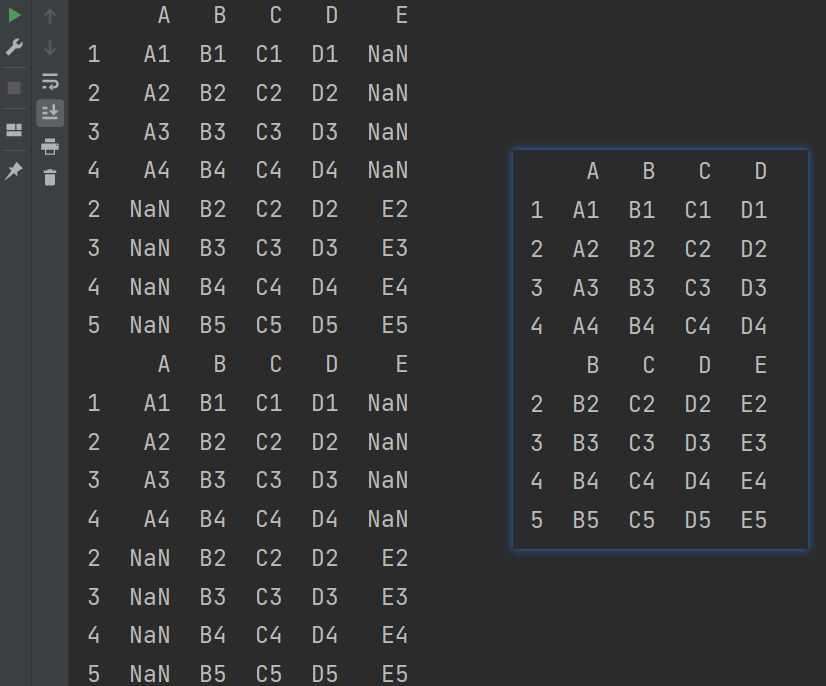
7.1.4.1 外连接
外连接类似并集,显示所有数据,会补齐NaN。
import pandas as pd
def make_df(indexs,columns):
data = [
[str(j)+str(i) for j in columns] for i in indexs
]
df = pd.DataFrame(data = data,index = indexs,columns = columns)
return df
df3 = make_df([1,2,3,4],list('ABCD'))
df4 = make_df([2,3,4,5],list('BCDE'))
print(df3)
print(df4)
print("===============")
# 外连接:补NaN(默认模式)类似并集,显示所有数据
print(pd.concat([df3,df4])) # 对于索引没有值,会自动用NaN填充
print(pd.concat([df3,df4],join='outer'))
说明:
-
join参数用于指定连接操作中的索引对齐方式。 -
join参数可以取以下几种值:inner:执行内连接,只保留两个 DataFrame 共有的索引标签。outer:执行外连接,保留所有索引标签,缺失的值用 NaN 填充。
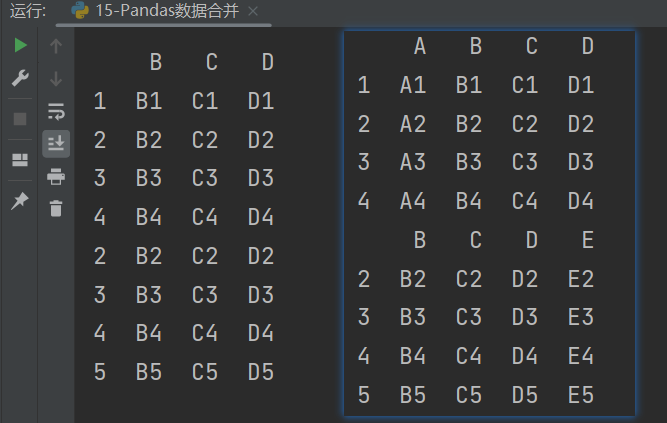
7.1.4.2 内连接
内连接:只连接匹配的项,类似交集,只显示共同的部分。
import pandas as pd
def make_df(indexs,columns):
data = [
[str(j)+str(i) for j in columns] for i in indexs
]
df = pd.DataFrame(data = data,index = indexs,columns = columns)
return df
df3 = make_df([1,2,3,4],list('ABCD'))
df4 = make_df([2,3,4,5],list('BCDE'))
print(df3)
print(df4)
print("===============")
# 内连接:只连接匹配的项,类似交集,只显示共同的部分
print(pd.concat([df3,df4],join='inner'))
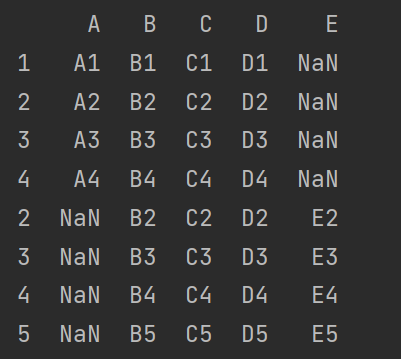
7.2 使用 _append() 函数添加
由于后面的级联的使用非常普遍,因此有一个函数 _append() 专门用在后面添加。
需要注意的是,_append() 方法并不会修改原有的 DataFrame 对象,而是返回一个新的对象,因此需要将其赋值给一个新的变量。
print(df3._append(df4))
注意:由于两个 DataFrame 对象具有相同的列名,因此在合并过程中,列名没有发生改变。如果两个 DataFrame 对象列名不同,将会自动合并它们,并将缺失的位置填充为 NaN 值。如果需要手动指定如何合并列名,可以使用 ignore_index 和 suffixes 参数进行设置。
7.3 使用 pd.merge() 合并
- 类似MySQL中表和表直接的合并。
- merge与concat的区别在于,merge需要依据某一共同的行或列来进行合并。
- 使用pd.merge()合并时,会自动根据两者相同column名称那一列,作为key来进行合并。
- 每一列元素的顺序不要求一致。
7.3.1 一对一合并
import pandas as pd
# pd.merge() 合并
df5 = pd.DataFrame(
{
'name':['小王','小李','小张'],
'id':[1,2,3],
'age':[22,23,24]
}
)
df6 = pd.DataFrame(
{
'id':[2,3,4],
'sex':['男','女','男'],
'job':['Teacher','Attorney','Manager']
}
)
print(df5)
print(df6)
print("================")
# 合并
print(pd.merge(df5,df6))
print(df5.merge(df6)) # 写法二
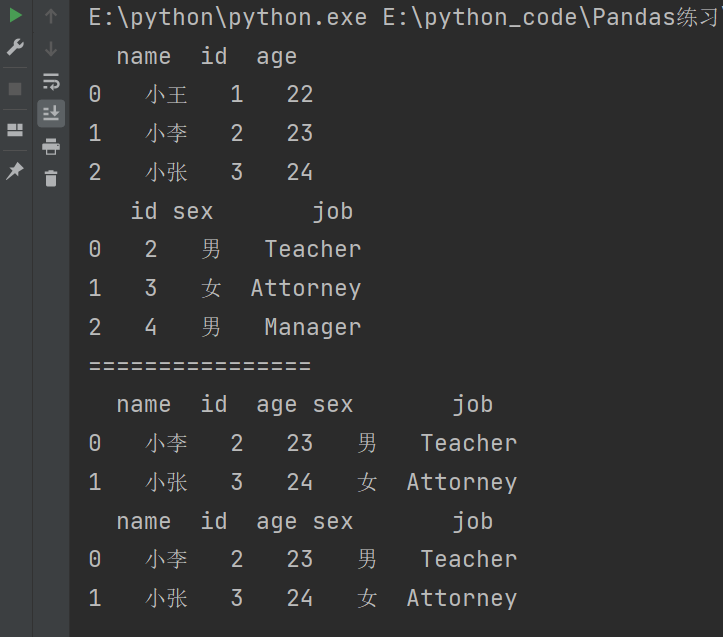
7.3.2 多对一合并
import pandas as pd
# 多对一合并
df3 = pd.DataFrame({
'name':['小王','小李','小张'],
'id':[1,2,2],
'age':[22,23,24]
})
df4 = pd.DataFrame({
'id':[2,3,4],
'sex':['男','女','男'],
'job':['Teacher','Attorney','Manager']
})
print(df3)
print(df4)
print("================")
print(df3.merge(df4))
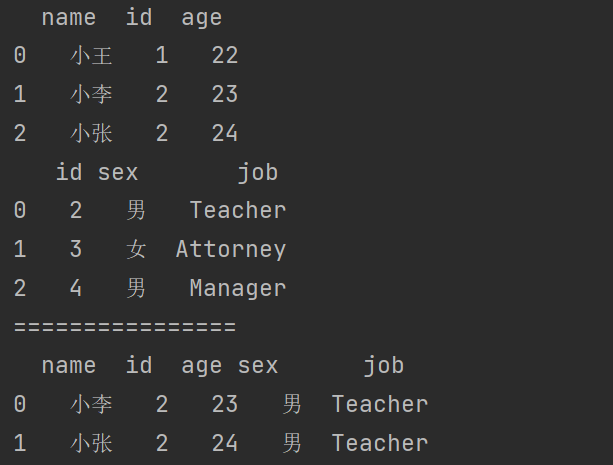
7.3.3 多对多合并
import pandas as pd
# 多对多合并
df5 = pd.DataFrame({
'name':['小王','小李','小张'],
'id':[1,2,2],
'age':[22,23,24]
})
df6 = pd.DataFrame({
'id':[2,2,4],
'sex':['男','女','男'],
'job':['Teacher','Attorney','Manager']
})
print(df5)
print(df6)
print("================")
print(df5.merge(df6))
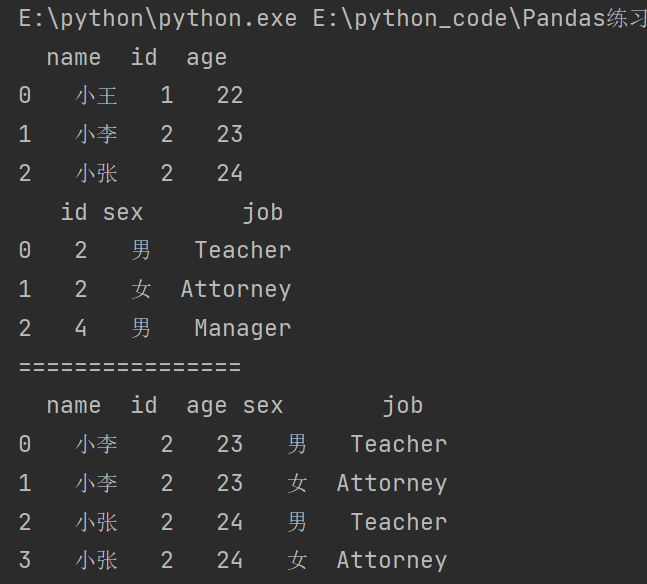
7.3.4 Key 的规范化
说明:使用on=显示指定那一列为key,当2个DataFrame有多列相同时使用。
import pandas as pd
# Key的规范化
df7 = pd.DataFrame({
'id':[1,2,3],
'name':['小王','小李','小张'],
'age':[22,23,24]
})
df8 = pd.DataFrame({
'id':[2,3,4],
'name':['小张','小赵','小周'],
'job':['Teacher','Attorney','Manager']
})
print(df7)
print(df8)
print("================")
print(df7.merge(df8)) # 如果有多列相同,那么需要有多列完全相同才可以匹配。
# 多列名称相同,需要指定一列作为连接的字段。
print(df7.merge(df8,on = 'id'))
print("================")
print(df7.merge(df8,on = 'name'))
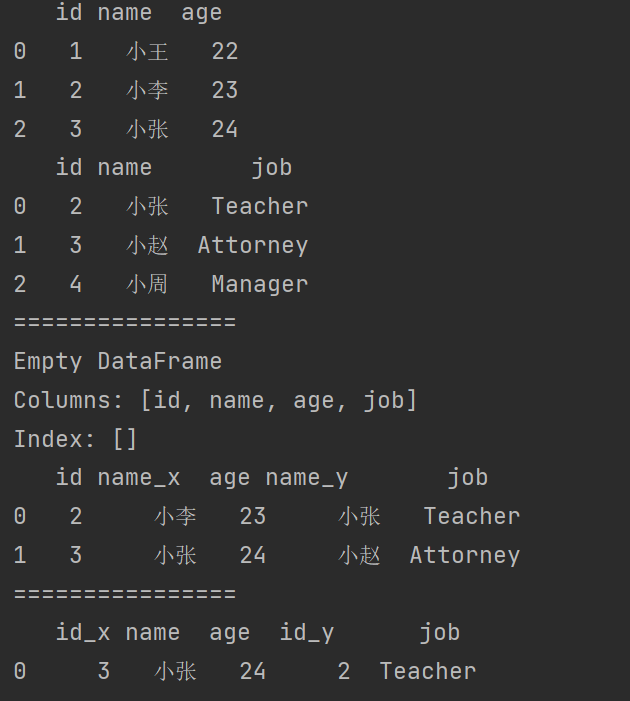
使用**left_on和right_on**指定左右两边的列作为key,当左右两边的key都不相等的时候使用。
import pandas as pd
# 当左右两边的key都不相等。
df9 = pd.DataFrame({
'id':[1,2,3],
'name':['小王','小李','小张'],
'age':[22,23,24]
})
df10 = pd.DataFrame({
'id2':[2,3,4],
'sex':['男','女','男'],
'job':['Teacher','Attorney','Manager']
})
print(df9)
print(df10)
print("================")
print(df9.merge(df10,left_on='id',right_on='id2'))
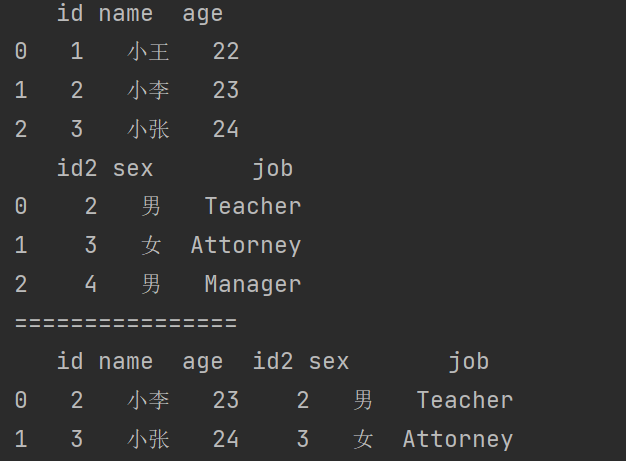
当左边的列和右边的index相同的时候,使用right_index=True。
import pandas as pd
# 可用使用行索引
df11 = pd.DataFrame({
'id':[1,2,3],
'name':['小王','小李','小张'],
'age':[22,23,24]
})
df12 = pd.DataFrame({
'id2':[2,3,4],
'sex':['男','女','男'],
'job':['Teacher','Attorney','Manager']
})
print(df11)
print(df12)
print("================")
print(df11.merge(df12,left_index=True,right_index=True)) # 行索引和行索引进行合并
print(df11.merge(df12,left_index=True,right_on='id2')) # 行索引和列名进行合并
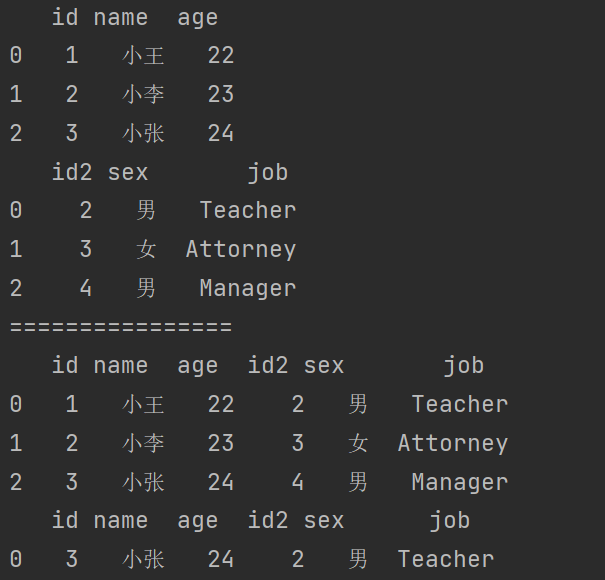
7.3.5 内合并与外合并
内合并:只保留两着都有的key(默认模式)
import pandas as pd
# 内合并与外合并
df13 = pd.DataFrame({
'id':[1,2,3],
'name':['小王','小李','小张'],
'age':[22,23,24]
})
df14 = pd.DataFrame({
'id':[2,3,4],
'sex':['男','女','男'],
'job':['Teacher','Attorney','Manager']
})
print(df13)
print(df14)
print("================")
# 内合并
print(df13.merge(df14)) # 默认是内合并 inner join
print(df13.merge(df14,how='inner'))
print("================")
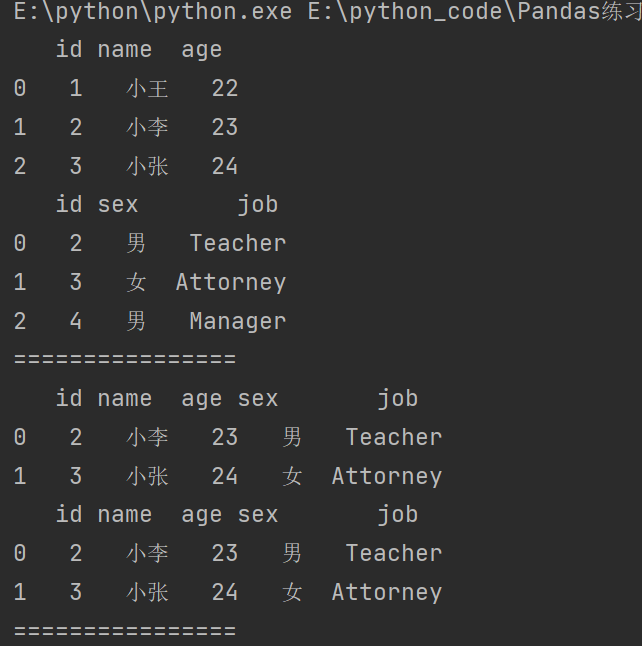
外合并:how=‘outer’:显示两个表单所有数据,没有的补NaN
# 外合并(显示两个表单所有数据,没有的补NaN)
print(df13.merge(df14,how='outer'))
print("================")
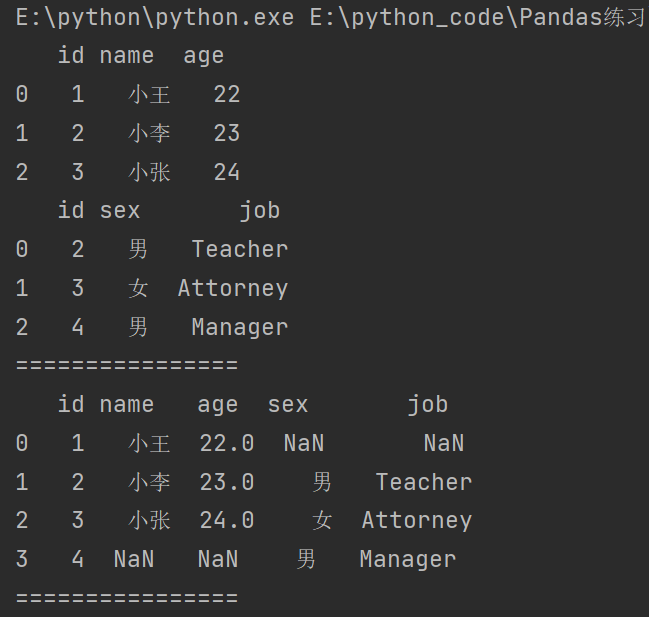
左合并,右合并:how=‘outer’,how=‘right’
# 左合并,右合并:how='left',how='right'
# 左合并:显示左边表的所有数据和右边表的公共数据
print(df13.merge(df14,how='left'))
print("================")
# 右合并:显示右边表的所有数据和左边表的公共数据
print(df13.merge(df14,how='right'))
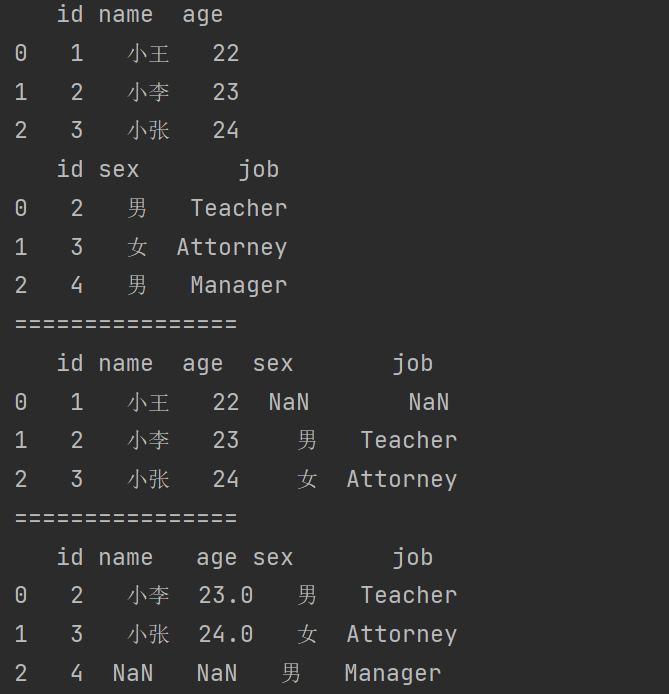
7.3.6 列冲突问题
当列冲突时,即有多个列名称相同时,需要使用 on= 来指定哪一个列作为key,配合suffixes指定冲突列名可以使用suffixes=自己指定后缀。
import pandas as pd
df1 = pd.DataFrame({
'id':[1,2,3],
'name':['小王','小李','小张'],
'age':[22,23,24]
})
df2 = pd.DataFrame({
'id':[2,3,4],
'name':['小刘','小赵','小周'],
'job':['Teacher','Attorney','Manager']
})
print(f"{df1}\n{df2}")
print("=============")
print(df1.merge(df2,on='id'))
print(df1.merge(df2,on='id',suffixes=['_df1','_df2']))
对于冲突的列名默认的是_x和 _y来进行的命名。
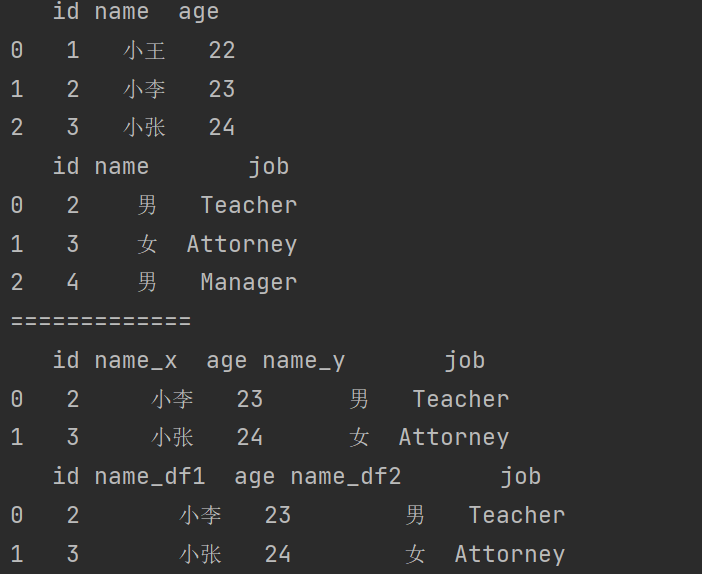
8. Pandas 缺失值处理
_None和NaN的区别
有两种丢失数据(空值):
- None
- np.nan
None:
- None是Python的一个特殊类型,是Python自带的,表示一个空值或者不存在的值。
- 在Python中,None不是数字,也不是字符串、列表或其他数据结构,它是一个单独的类型NoneType。
- 当你希望表示一个变量尚未被赋值,或者一个函数没有返回任何值时,你会使用None。
- 在Pandas中,如果一列数据全是数值类型,而某个单元格的值为None,Pandas通常会自动将None转换为NaN。
NaN:
- NaN,全称为"Not a Number",不是一个具体的值,而是一种标记,用于表示数值数据中无法表示或不存在的值。
- 在Python中,NaN通常来自numpy库,是一个特殊的浮点数(
np.nan)。 - NaN主要用于数据分析和科学计算中,当遇到无效或缺失的数值数据时,会用NaN来表示。
- 在Pandas中,如果一个Series包含NaN,那么这个Series的dtype通常是浮点数(
float64),即使其他值都是整数。
import numpy as np
n = np.array([1,2,3,np.nan,5,6])
print(n)
print(np.sum(n)) # nan和任何值运行都是nan
print(np.nansum(n)) # nansum()自动过滤nan,不计算nan
总结来说,主要区别如下:
- 类型不同:None是Python的NoneType,而NaN是浮点数类型。
- 使用场景不同:None通常用于表示一般的空值或未定义的值,而NaN专门用于表示数值数据中的缺失或无效值。
8.1 Pandas 中的None与NaN
Pandas中的None与NaN都视作np.nan
import numpy as np
import pandas as pd
# Pandas 中的None与NaN
df = pd.DataFrame(
data = np.random.randint(0,100,size=(5,5)),
columns= list('ABCDE')
)
print(df)
print("================")
df.loc[2,'B'] = np.nan
df.loc[3,'C'] = None
print(df)
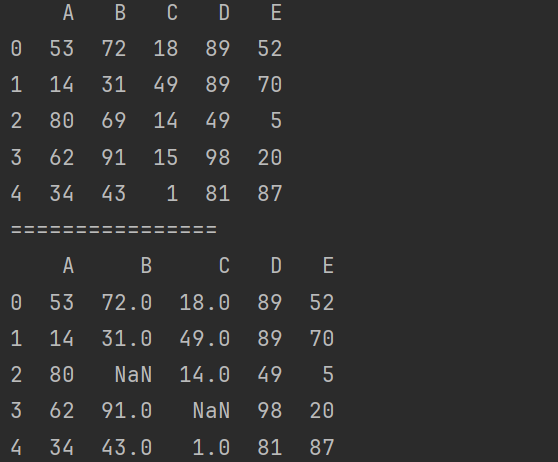
8.2 Pandas 中的None与np.nan的操作
- isnull()
- notnull()
- all()和any()
- dropna():过滤丢失数据
- fillna():填充丢失数据
8.2.1 判断函数
- isnull()
- notnull()
# Pandas 中的None与np.nan的操作
print(df.isnull())
print(df.notnull())
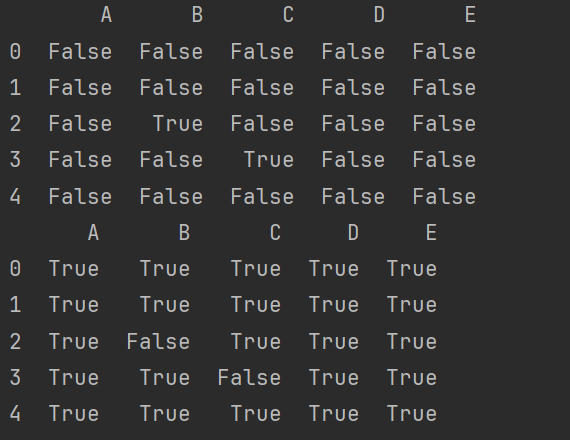
- all():必须全部为True才会是True,类似and。
- any():只要一个为True就为True,类似or。
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(0,100,size=(5,5)),
columns= list('ABCDE')
)
df.loc[2,'B'] = np.nan
df.loc[3,'C'] = None
print(df.isnull())
print(df.notnull())
print("================")
# 找有空值的列
# print(df.isnull().all()) # 必须全部都为空的列才会为True
print(df.isnull().any()) # 常用,尽可能找到有空的列
print("================")
# 找没有空值的列
print(df.notnull().all()) # 常用,尽可能找到没有空的列
# print(df.notnull().any())
print("================")
# 找有空值的行
print(df.isnull().any(axis=1))
# 找没有空值的行
print(df.notnull().all(axis=1))
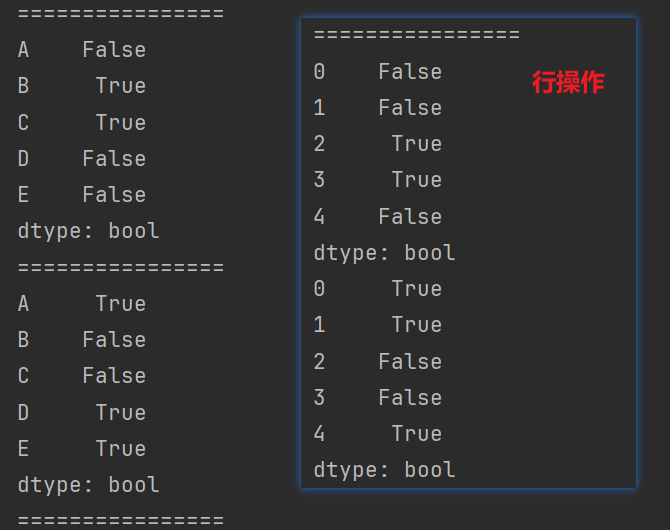
8.2.2 过滤数据
8.2.2.1 使用bool值索引过滤数据
对行进行过滤操作
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(0,100,size=(5,5)),
columns= list('ABCDE')
)
df.loc[2,'B'] = np.nan
df.loc[3,'C'] = None
print(df.isnull())
print(df.notnull())
print("================")
# 使用bool值索引过滤行数据
print(df)
# 过滤行,删除空行
cond = df.isnull().any(axis=1)
# print(~cond) # 取反
print(df[~cond])
# 方式二
cond2 = df.notnull().all(axis=1)
print(cond2)
print(df[cond2])
print("==================")
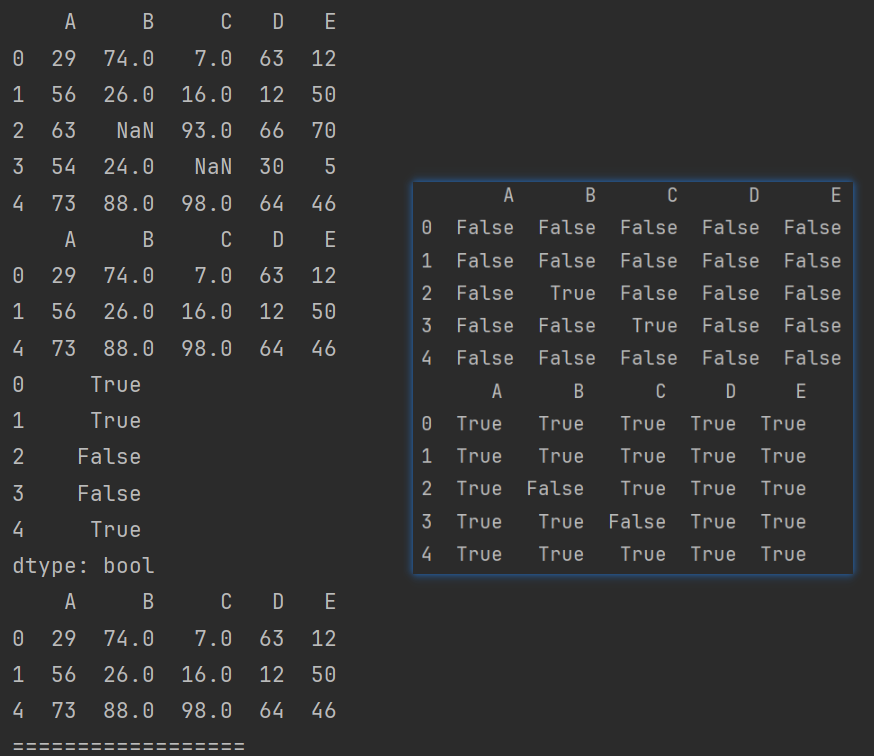
对列进行过滤操作
# 使用bool值索引过滤列数据
# 过滤列,删除空列
cond3 = df.isnull().any()
# print(~cond3) # 取反
print(df.loc[:,~cond3])
print("==================")
# 方式二
cond4 = df.notnull().all()
print(cond4) # 取反
print(df.loc[:,cond4])
8.2.2.2 过滤函数 dropna()
可以选择过滤的是行还是列(默认为行)
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(0,100,size=(5,5)),
columns= list('ABCDE')
)
df.loc[2,'B'] = np.nan
df.loc[3,'C'] = None
"""
过滤函数dropna()
"""
print(df)
# 默认删除有空的行
print(df.dropna())
# 删除有空的列
print(df.dropna(axis=1))

选择过滤方式 how = ‘all’,函数参数的解析:
how: 这个参数指定了在决定是否删除行或列时,应考虑的缺失值的数量或比例。可能的值包括 'any' 和 'all'。
'any':如果一行(或一列,取决于axis参数)中的任何值是缺失的,那么这一行(或一列)就会被删除。'all':只有当一行(或一列)中的所有值都是缺失的,这一行(或一列)才会被删除。
# 选择过滤方式 how = 'all'
print(df.dropna(how='any')) # 默认过滤方式
print(df.dropna(how='all')) # 对于行必须所有数据都为空,才会删除
print(df.dropna(how='all',axis=1)) # 对于列必须所有数据都为空,才会删除
inplace =True 修改原数据。
# inplace =True 修改原数据
df2 = df.copy()
print(df2)
print(df2.dropna(inplace=True))
print(df2)
说明:inplace =True该操作将会直接在原数据上进行修改,而不是创建一个新的 DataFrame。
8.2.3 填充空值
如果在一个表中数据为空,除了可以将其删除之外,还可以进行填充。
填充函数:Series/DataFrame
- fillna()
import numpy as np
import pandas as pd
df = pd.DataFrame(
data = np.random.randint(0,100,size=(5,5)),
columns= list('ABCDE')
)
df.loc[2,'B'] = np.nan
df.loc[3,'C'] = None
print(df)
print("==================")
print(df.fillna(value=666))
limit参数可以限制填充的次数
# limit限制填充的次数
df2 = df.copy()
df2.loc[1,'B'] = np.nan
df2.loc[2,'C'] = np.nan
print(df2)
print(df2.fillna(value=666,limit=1))
print(df2.fillna(value=666,limit=2))
print("===================")
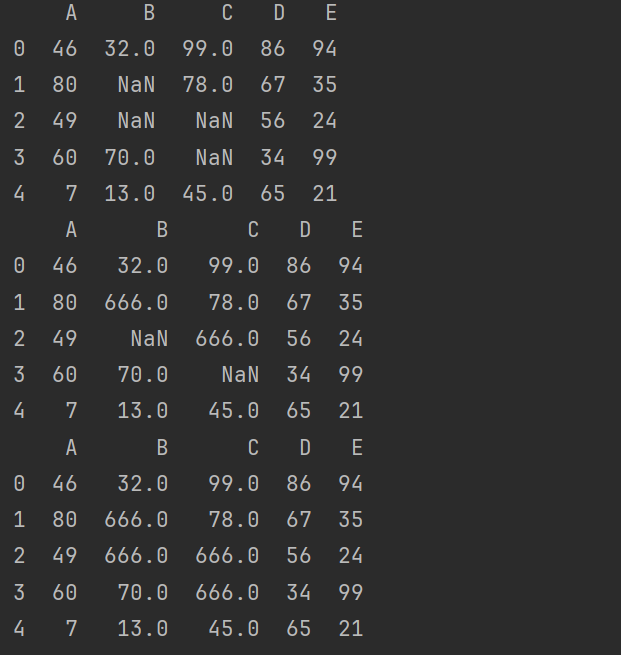
可以选择前向填充还是后向填充。
# 可以选择前向填充还是后向填充。
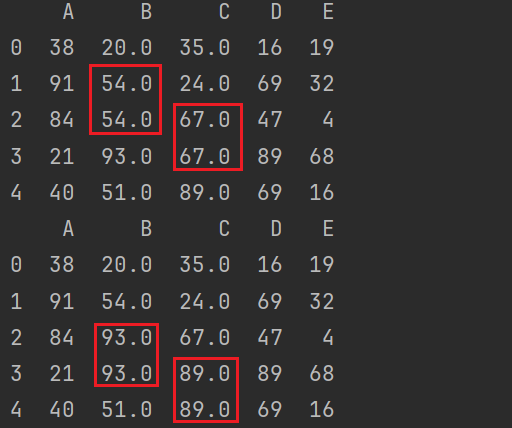
print(df.fillna(method='ffill')) # 前向填充
print(df.fillna(method='backfill')) # 后向填充
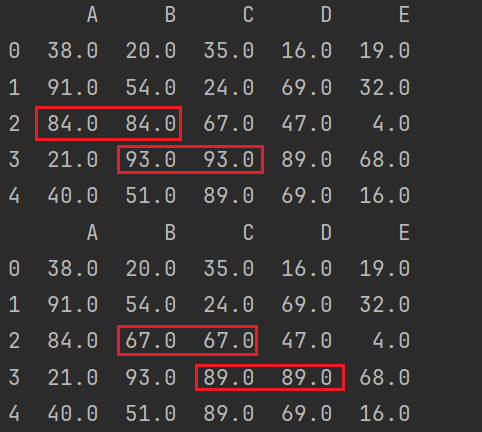
print(df.fillna(method='ffill',axis=1)) # 左向填充
print(df.fillna(method='backfill',axis=1)) # 右向填充
前向填充及后向填充:
左向填充及右向填充:
9. Pandas 重复值处理
duplicated()函数检测重复的行。
import pandas as pd
def make_df(indexs,columns):
data = [
[str(j)+str(i) for j in columns] for i in indexs
]
df = pd.DataFrame(data = data,index = indexs,columns = columns)
return df
df = make_df([1,2,3,4],list('ABCD'))
print(df)
print("===============")
df.loc[1] = df.loc[2]
print(df)
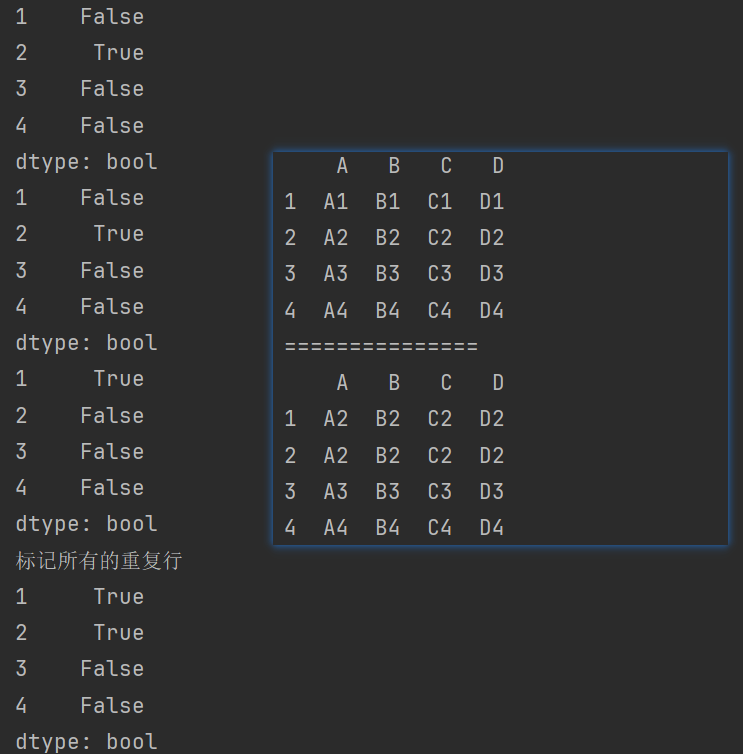
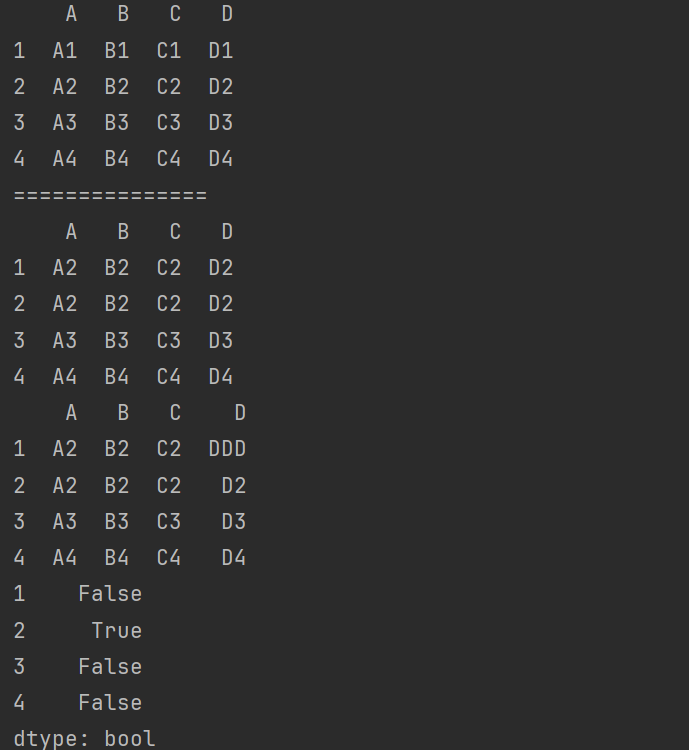
print(df.duplicated()) # 后面的行与前面的行重复
print(df.duplicated(keep='first')) # 默认值first,表示保留第一行
print(df.duplicated(keep='last')) # 保留最后一行
print(f"标记所有的重复行\n{df.duplicated(keep=False)}") # 标记所有的重复行,不保留任何一行
keep 参数值:
'first'(默认值):保留每个重复数据组的第一行,删除其他重复的行。'last':保留每个重复数据组的最后一行,删除其他重复的行。False:删除所有重复的行。
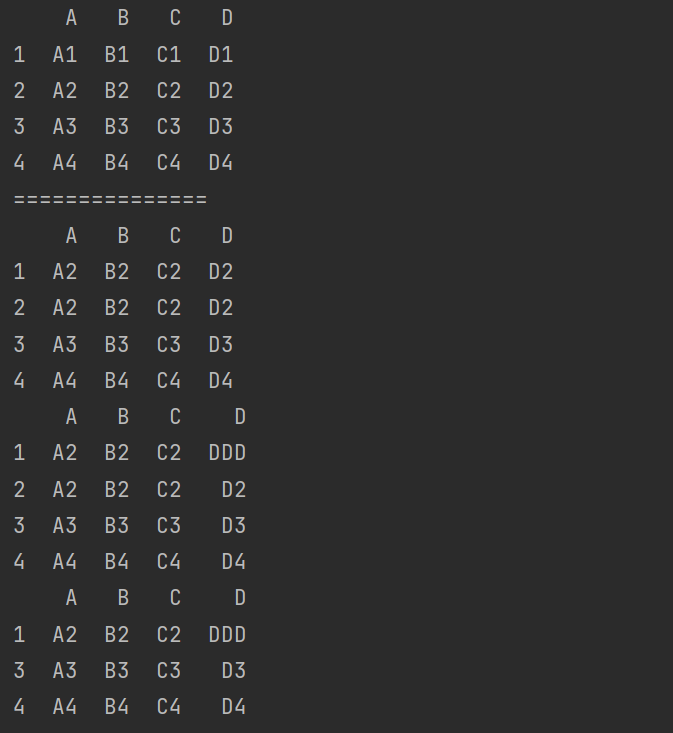
df.loc[1,'D'] = 'DDD'
print(df)
print(df.duplicated(subset=['A','B'])) # subset:子集
说明:
- 用于指定考虑哪些列来判断重复行。它可以是一个包含列名的列表或数组。
- 在这个例子中,
subset=['A','B']表示只考虑列 ‘A’、‘B’ 的值来判断重复行。如果有两行在这些指定列的值上完全相同,则认为它们是重复的。
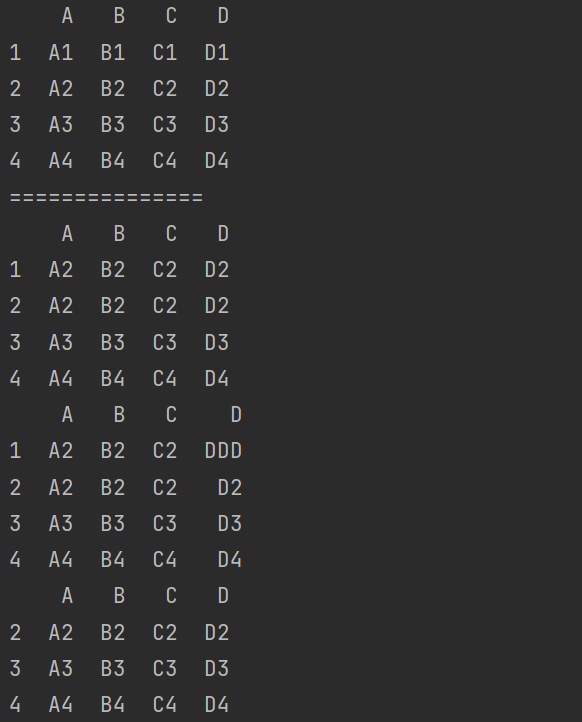
drop_duplicates()函数删除重复的行。
print(df.drop_duplicates(subset=['A','B','C']))
print(df.drop_duplicates(subset=['A','B','C'],keep='last'))
说明:last保留每个重复数据组的最后一行,删除其他重复的行。
10. Pandas 数据映射
在Pandas中,数据映射是一种将DataFrame中的一个或多个列的值转换为其他值的过程。这种转换通常是基于某种规则或者映射关系进行的。
以下是一些常见的Pandas数据映射方法:
- replace()函数:替换元素。
replace()函数用于直接替换Series或DataFrame中的特定值。 - map()函数:处理某一单独的列,最重要。
map()函数用于将Series或DataFrame的某一列应用一个函数或者映射字典进行元素级别的转换。 - rename()函数:替换索引。
- apply()函数:既支持Series,也支持DataFrame。
- transform()函数:将给定的函数应用于DataFrame或Series,并返回一个与原数据形状相同的新对象。
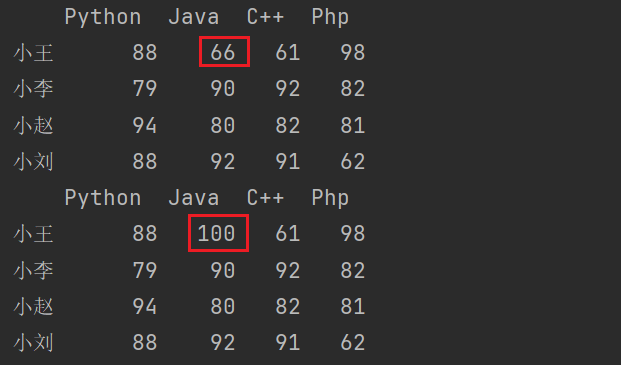
10.1 replace() 函数
replace()函数:替换元素,对value进行替换操作。
import pandas as pd
import numpy as np
data = np.random.randint(60,100,size=(4,4))
index = ['小王','小李','小赵','小刘']
columns = ['Python','Java','C++','Php']
df = pd.DataFrame(data,index,columns)
print(df)
# replace()函数用于直接替换Series或DataFrame中的特定值。
print(df.replace({66:100}))
# 还可以替换多个值
# print(df.replace({66:100},{77,100}))
10.2 map() 函数
处理某一单独的列,最重要。map()函数用于将Series或DataFrame的某一列应用一个函数或者映射字典进行元素级别的转换。
import pandas as pd
import numpy as np
data = np.random.randint(60,100,size=(4,4))
index = ['小王','小李','小赵','小刘']
columns = ['Python','Java','C++','Php']
df = pd.DataFrame(data,index,columns)
print(df)
# map一般用在Series数据结构,不能用于DataFrame
df2 = df.copy()
print(df2['Python'].map({66:99}))
这种方式如果要修改的话,需要将其全部的值修改掉。不然就会出现NaN值。
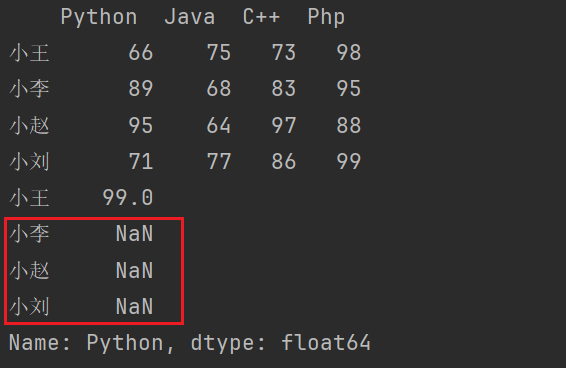
print(df2['Python'].map({66:99, 89:88, 95:77, 71:66}))
批量处理
# 批量处理
print(df2['Python']*10) # 将Python课每门课的成绩乘10。
print(df2['Python'].map(lambda x:x*10))
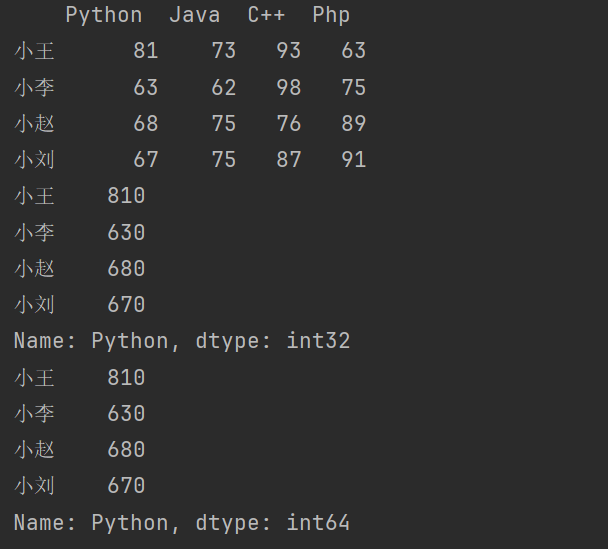
新增一列
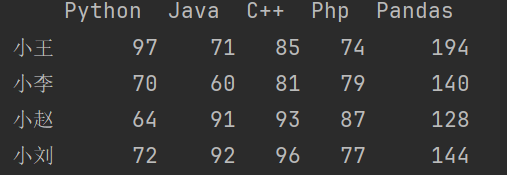
df2['Pandas'] = df2['Python'].map(lambda x:x*2)
print(df2)
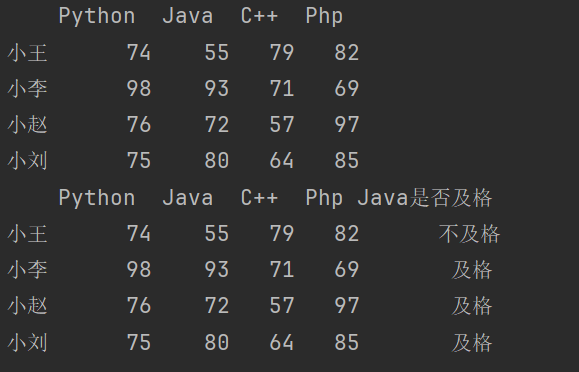
新增一列,判断Java的成绩是否及格。
df2['Java是否及格'] = df2['Java'].map(lambda x:'及格' if x>=60 else '不及格')
print(df2)
普通函数
# 新增:判断C++成绩
def test(x):
if x < 60:
return '不及格'
elif x < 80:
return '良好'
return '优秀'
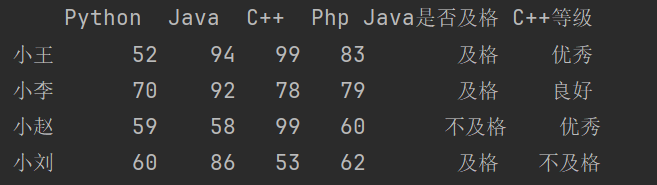
df2['C++等级'] = df2['C++'].map(test)
print(df2)
10.3 rename() 函数
10.3.1 修改索引
import pandas as pd
import numpy as np
data = np.random.randint(50,100,size=(4,4))
index = ['小王','小李','小赵','小刘']
columns = ['Python','Java','C++','Php']
df = pd.DataFrame(data,index,columns)
df3 = df.copy()
print(df3)
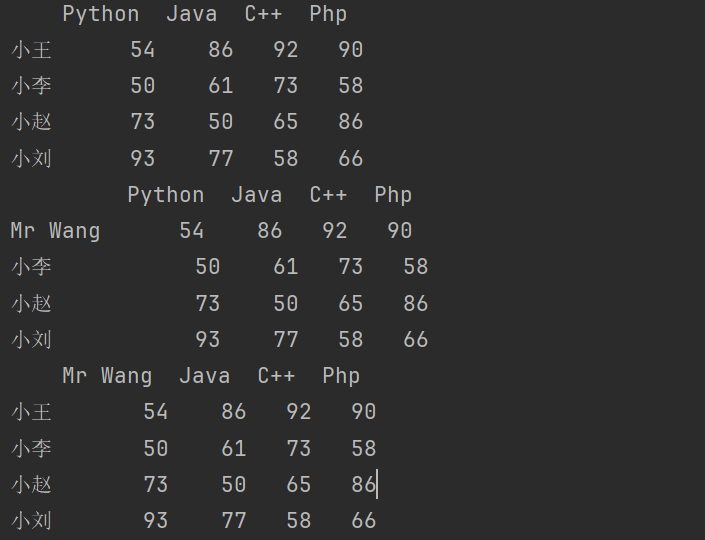
print(df3.rename({'小王':'Mr Wang'})) # 默认修改行索引名
print(df3.rename({'Python':'Mr Wang'},axis=1)) # 修改列索引名
修改索引方式二:
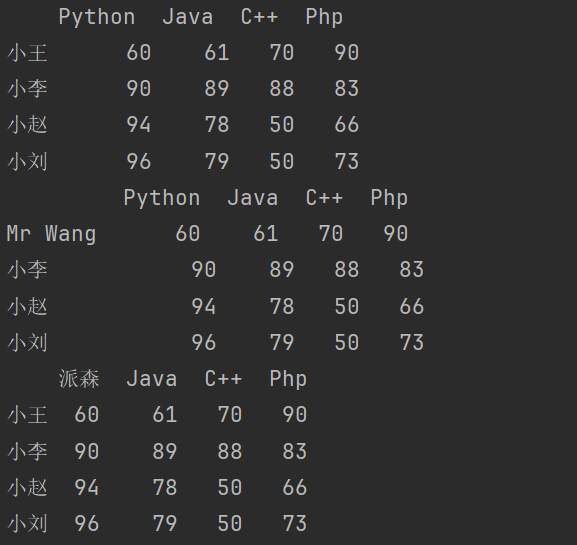
print(df3.rename(index = {'小王':'Mr Wang'})) # 修改行索引名
print(df3.rename(columns = {'Python':'派森'})) # 修改列索引名
10.3.2 重置索引
reset_index() 函数:用于将 DataFrame 的当前索引重置为默认的整数索引,并将原索引作为新列添加到 DataFrame 中。这在将层次索引或非整数索引转换回普通索引时非常有用。
set_index() 函数:用于将 DataFrame 中的一个或多个列设置为新的索引。
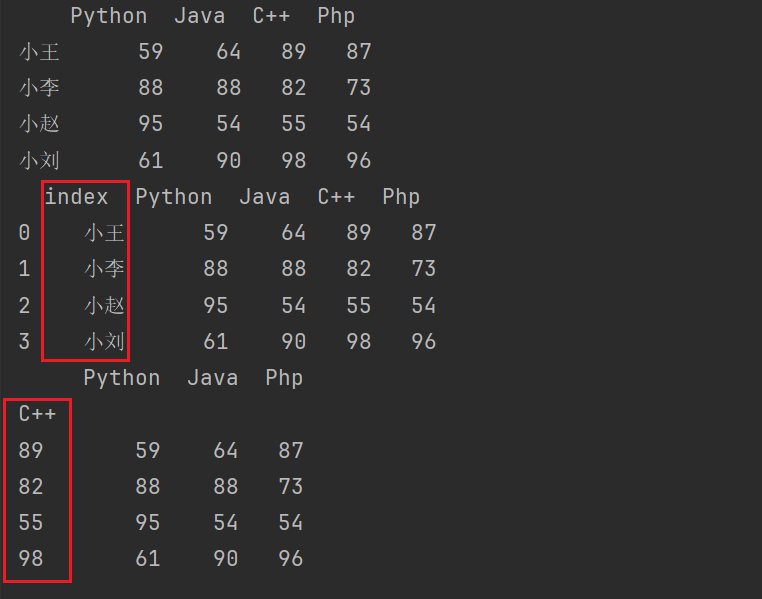
# 重置索引
print(df3.reset_index())
# 设置其他的列作为行索引
print(df3.set_index(keys= ['C++']))
10.4 apply() 函数
当apply()函数作用于DataFrame时,它会根据axis参数沿着行或列的方向应用给定的函数。如果函数返回的是一个标量值,apply()函数会尝试将这个标量值扩展到整个结果中。
import pandas as pd
import numpy as np
df4 = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df4)
# x表示Series中的元素
print(df4['Python'].apply(lambda x: True if x>=5 else False))
# 用于DataFrame,其中x是DataFrame中行或列的Series数据
# 求每一列数据的平均值
print(df4.apply(lambda x: x.mean())) # mean()计算平均值 # 默认计算列
# 求每一行数据的平均值
print(df4.apply(lambda x: x.mean(),axis=1))
# 使用自定义方法
def test2(x):
return x.mean()
print(df4.apply(test2))
print(df4.apply(test2,axis=1))
ap
applymap()函数会将给定的函数应用于DataFrame或Series的每一个元素。这意味着函数会被逐一应用到DataFrame的每一个单元格或者Series的每一个值上。
# applymap():DataFrame专有的方法,其中的x是每个元素
print(df4.applymap(lambda x:x+100))
注意:
applymap()函数主要用于元素级别的操作,当需要对整个行或列应用函数时,应使用apply()函数。- 对于大型数据集,
applymap()函数可能会比较慢,因为它逐个处理每个元素。
10.5 transform() 函数
transform()函数会将给定的函数应用于DataFrame或Series,并返回一个与原数据形状相同的新对象。
与apply()函数不同的是,transform()函数要求返回的结果必须与输入的数据具有相同的形状。这意味着无论你应用的函数对数据做了什么操作,返回的新对象应该有相同的行数和列数(对于DataFrame)或者元素数量(对于Series)。如果在transform()中使用了一个返回标量的函数,为了保持形状一致,这个标量会被复制并填充到整个结果中。
import pandas as pd
import numpy as np
df4 = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df4)
# transform() 函数可以执行多项计算
# Series中使用transform
# np.sqrt用于计算输入数组元素的平方根
# np.exp用于计算输入数组元素的自然指数(e的幂)
print(df4['Python'].transform([np.sqrt,np.exp]))
# DataFrame中使用transform
def convert(x):
if x.mean()>5:
return x*10
return x*(-10)
print(df4.transform(convert)) # 处理每一列
print(df4.transform(convert,axis=1)) # 处理每一行
apply()函数: 想象一下你有一个表格(DataFrame),你可以使用apply()函数对这个表格的每一行或每一列应用一个自定义的规则或者计算。比如,你决定对每一行的所有数字求和,然后返回一个新的表格或者一个单一的值。这个新的结果可能是不同形状的,比如它可能只包含一行或一列,取决于你的操作。
transform()函数: 而transform()函数也是用来对表格(DataFrame)进行操作的,但是它有一个特殊的要求:无论你对数据做了什么操作,返回的结果必须和原始表格有相同的形状。也就是说,如果你对每一行的数据进行了某种计算,返回的新表格还应该有同样的行数和列数。比如,你决定对每一行的所有数字求和,但是你不希望改变表格的形状,而是想让每个元素变成它所在行的总和,那么你就需要使用transform()函数。
否则就会报错:
def convert(x):
return x.mean()
print(df4.transform(convert)) # 处理每一列

11. Pandas 异常值处理
-
describe():查看每一列的描述性统计量。
-
df.info():查看数据信息。
-
df.std():可以求得DataFrame对象每一列的标准差。
-
df.drop():删除特定索引。
-
unique():唯一,去重。
-
query():按条件查询。
-
df.sort_values():根据值排序。
-
df.sort_index():根据索引排序。
11.1 describe() 函数
describe()函数会返回一个包含数据集主要统计信息的新DataFrame或Series。这些统计信息包括:
- count(非缺失值的数量,行数)
- mean(平均值)
- std(标准差)
- min(最小值)
- 25%(第一四分位数,也称为下四分位数或Q1)
- 50%(中位数)
- 75%(第三四分位数,也称为上四分位数或Q3)
- max(最大值)
import pandas as pd
import numpy as np
# Pandas 异常值处理
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df)
# - describe():查看每一列的描述性统计量。
print(df.describe())
# 可以自定义中位数
print(df.describe([0.1,0.9,0.99]))
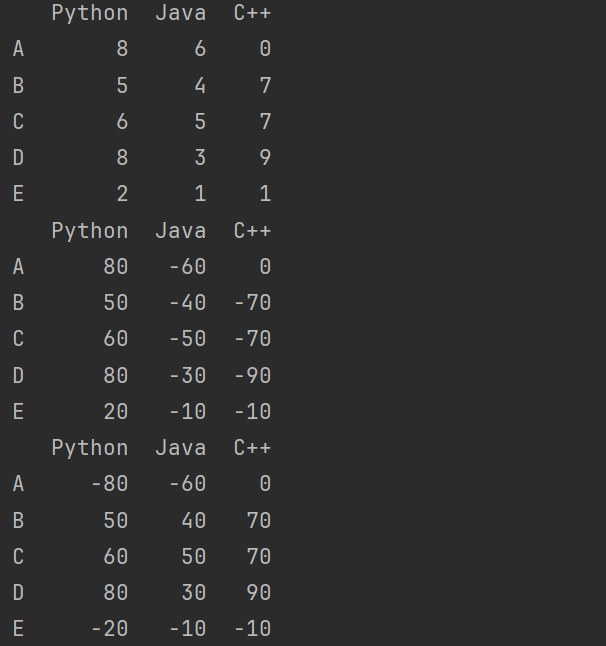
print(df.describe([0.1,0.9,0.99]).T)
说明:在Pandas中,.T是一个属性或方法,表示数据的转置。当用于DataFrame时,它会将DataFrame的行和列互换,也就是说,原DataFrame的列将成为新DataFrame的行,而原DataFrame的行将成为新DataFrame的列。
11.2 std() 函数
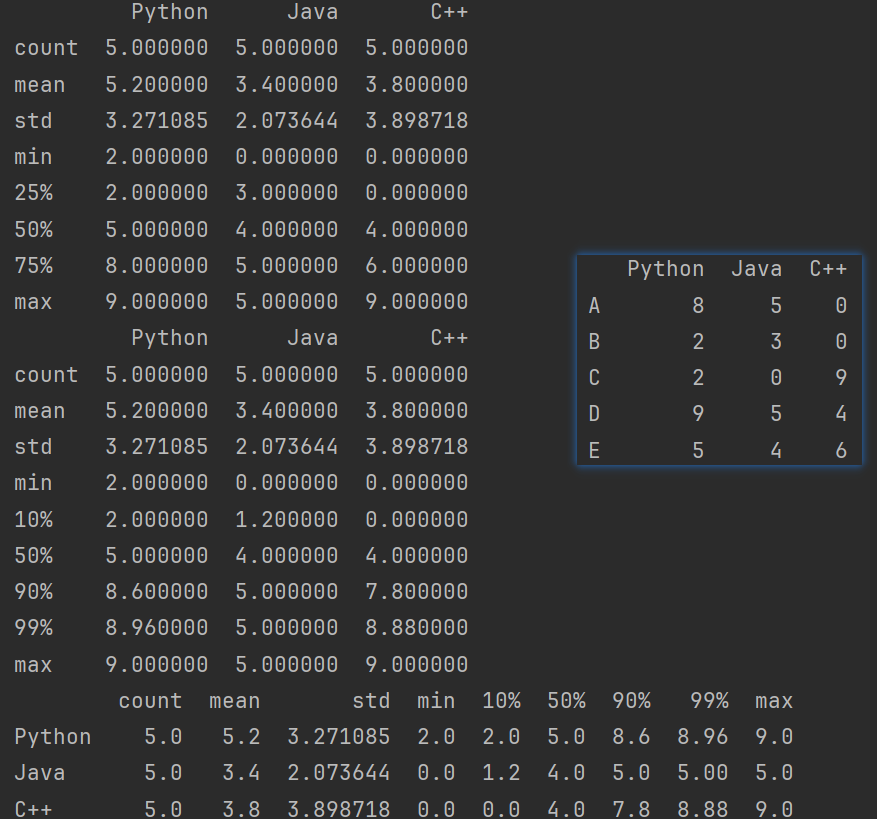
df.std():可以求得DataFrame对象每一列的标准差。
import pandas as pd
import numpy as np
# Pandas 异常值处理
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df)
print('===============')
# - df.std():可以求得DataFrame对象每一列的标准差。
print(df.std)
11.3 drop() 函数
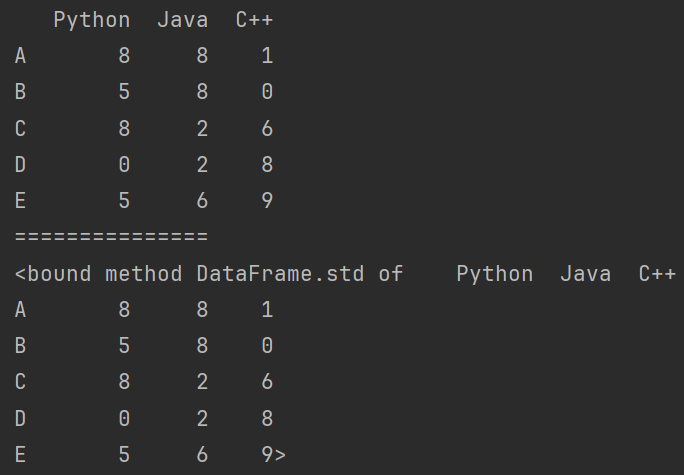
df.drop():删除特定索引。
删除单行单列
import pandas as pd
import numpy as np
# Pandas 异常值处理
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df)
# - df.drop():删除特定索引。
df2 = df.copy()
# print(df2.drop('Python')) # 会报错
print(df2.drop('A')) # 删除行
print(df2.drop('Python',axis=1)) # 删除列
print(df2.drop(index='A')) # 删除行
print(df2.drop(columns='Python')) # 删除行
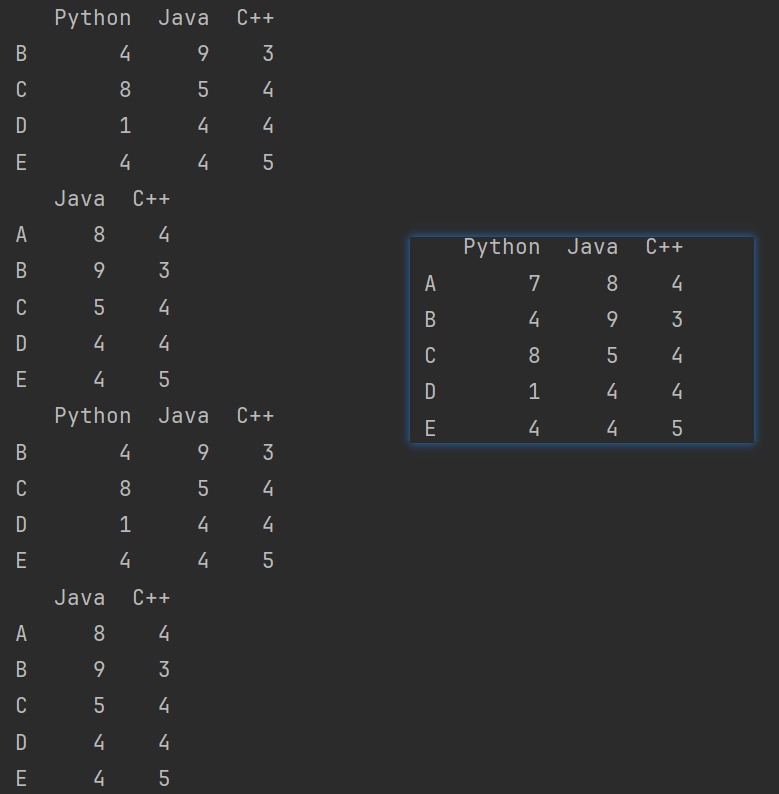
删除多行多列
# 删除多列多行
print(df2.drop(columns=['Python','C++']))
print(df2.drop(index=['A','B']))
print(df2.drop(index=['A','B'],inplace=True)) # 直接修改元数据
11.4 unique() 函数
unique():唯一,去重。
import pandas as pd
import numpy as np
# Pandas 异常值处理
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df)
# - unique():唯一,去重。
# DataFrame没有unique,Series调用unique
# print(df.unique()) # 会报错
print(df['Python'].unique()) # 对列做操作
11.5 query() 函数
query()函数是Pandas库中的一个函数,它提供了一种使用类似SQL语法的方式对DataFrame进行查询和过滤操作。
query():按条件查询。
import pandas as pd
import numpy as np
# Pandas 异常值处理
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df)
df2 = df.copy()
# - query():按条件查询。
# and, in, &, |, ==, >, <, or
print(df2.query('Python == 9')) # 找到Python列中等于9的所有行
print(df2.query('Python > 5')) # 找到Python列中大于9的所有行
print(df2.query('Python > 5 and Java > 1'))
print(df2.query('Python > 5 & Java > 1'))
print(df2.query('Python in [1,2,3,4]'))
使用变量
# 使用变量
n = 7
print(df2.query('Python == @n')) # 在变量前面加一个@符号,系统才认该值是变量
m = [1,2,3,4,5]
print(df2.query('Python == @m'))
11.6 sort_values() 函数
df.sort_values():根据值排序。
import pandas as pd
import numpy as np
# Pandas 异常值处理
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df)
"""
- df.sort_values():根据值排序。
"""
print(df.sort_values('Python')) # 默认按照列名进行升序,所对应的一整行都进行移动
print(df.sort_values('Python',ascending=False)) # 降序排序
按照行索引名排序
# 按照行索引名排序,把列进行排序(不常用)
print(df.sort_values('A',axis=1)) # 按照行进行升序
print(df.sort_values('B',axis=1)) # 按照行进行升序
11.7 sort_index() 函数
df.sort_index():根据索引排序。
import pandas as pd
import numpy as np
# Pandas 异常值处理
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df)
"""
- df.sort_index():根据索引排序。
"""
print(df.sort_index(ascending=False))
print(df.sort_index(axis=1)) # 按照列名排序
11.8 info() 函数
info()函数是Pandas库中的一个函数,主要用于提供DataFrame或Series的基本信息摘要。
info()函数输出的信息主要包括以下内容:
- 数据集类型:显示数据集是DataFrame还是Series。
- 索引信息:
- 索引的类型,如RangeIndex、Int64Index等。
- 索引的范围和数量。
- 列信息:
- 列名及其对应的数据类型(dtype)。
- 每一列的非空值数量(non-null count)。
- 内存使用情况:
- 数据集的总内存使用量(total memory usage)。
- 如果数据集进行了内存优化,会显示"memory usage optimized"。
- 每一列的内存使用量(memory usage for each column)。
- 其他信息:
- 如果数据集中存在重复的索引值,会显示"dupe"标记。
- 如果数据集中存在NA或NULL值,会在相应的列下显示非空值数量。
import pandas as pd
import numpy as np
# Pandas 异常值处理
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
print(df)
"""
- info:
"""
print(df.info())
11.9 练习
新建一个形状为10000*3的标准正态分布的DataFrame(np.random.randn),去除掉所有满足以下情况的行:其中任一元素绝对值大于3倍标准差。
"""
新建一个形状为10000*3的标准正态分布的DataFrame(np.random.randn),
去除掉所有满足以下情况的行:其中任一元素绝对值大于3倍标准差。
"""
import pandas as pd
import numpy as np
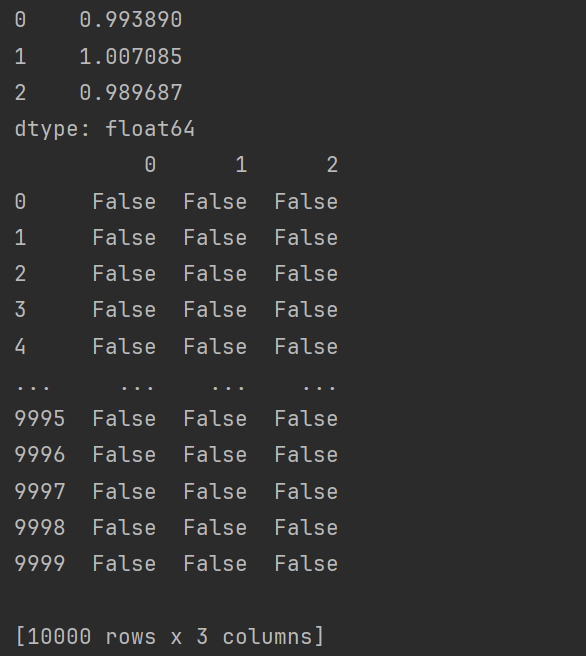
df = pd.DataFrame(data = np.random.randn(10000,3))
# 过滤掉大于三倍标准差的行
print(df.std()) # 每一列的标准差
# 绝对值 df.abs()
# cond:找到每一个元素是否大于三倍标准差
cond = df.abs() > df.std()*3
print(cond)
print('==============')
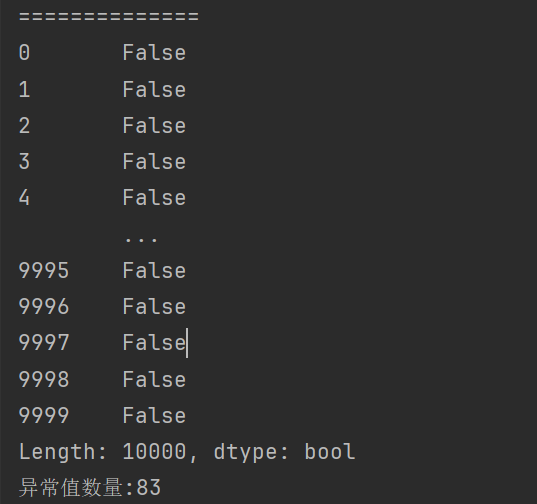
# 找到存在大于三倍标准差的行
cond2 = cond.any(axis=1) # any():只要一个为True就为True。
print(cond2)
print(f"异常值数量:{cond2.sum()}") # 返回Series中为True的数量
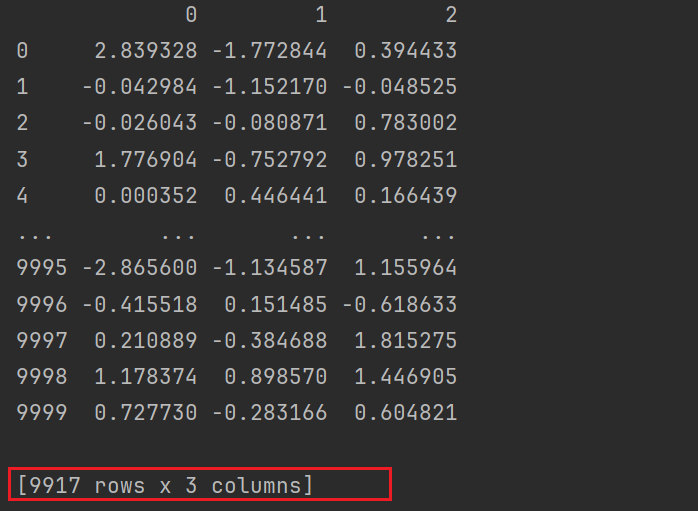
# bool值索引,过滤异常值
print(df[~cond2])
12. 抽样
在Pandas中,抽样(sampling)是指从DataFrame或Series中随机选择一部分数据行或者数据点的过程。抽样可以帮助数据科学家和分析师快速获取数据集的子集,以便进行探索性数据分析、模型验证、交叉验证或其他目的。
- 使用.take()函数排序。
take()函数是一个用于从DataFrame或Series中按照指定的索引位置提取元素的函数。
import pandas as pd
import numpy as np
# Pandas 抽样
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
df2 = df.copy()
print(df2)
print(df2.take([0,1,2])) # 行 排列
print(df2.take([0,1],axis=1)) # 列 排列
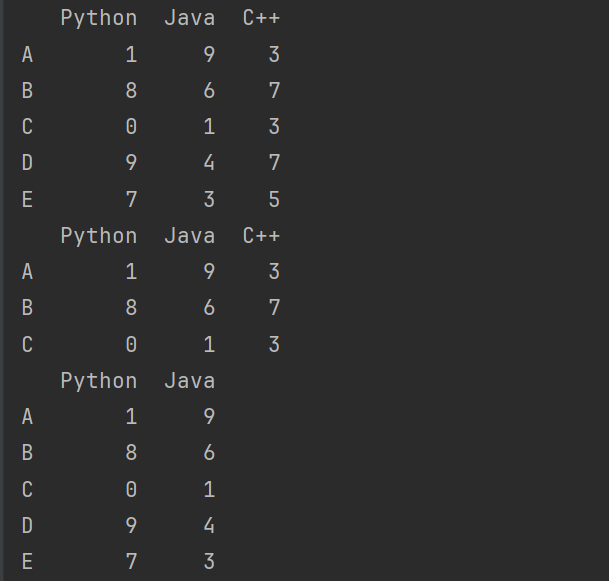
- 可以借助np.random.permutation()函数随机排序。
# 随机排列
print(np.random.permutation(df2))

12.1 无放回抽样
在无放回抽样中,每次从数据集中抽取一个样本后,不会将其放回原数据集。这意味着每个样本只能被抽取一次,且后续的抽取不会影响之前已经抽取过的样本。
无放回抽样的优点是可以保证每个样本在最终的抽样结果中只出现一次,这对于保持数据的独立性和避免重复非常有用。然而,当数据集较小或者需要抽取的样本数量较大时,无放回抽样可能导致某些样本无法被抽取到,从而影响抽样的代表性。
import pandas as pd
import numpy as np
# Pandas 抽样
df = pd.DataFrame(
data= np.random.randint(0,10,size=(5,3)),
index= list('ABCDE'),
columns= ['Python','Java','C++']
)
df2 = df.copy()
print(df2)
# 行之间的随机提取,无放回抽样
# 无放回抽样,依次取出,没有重复值
print(df2.take(np.random.permutation([0,1,2])))
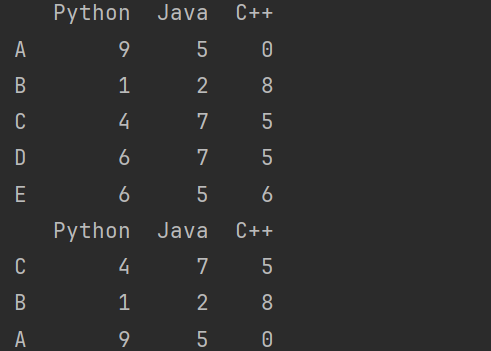
12.2 有放回抽样
在有放回抽样中,每次从数据集中抽取一个样本后,会将其放回原数据集。这意味着同一个样本可以被多次抽取到。
有放回抽样的优点是可以无限次地进行抽样,即使数据集较小或者需要抽取的样本数量较大。这种抽样方法通常用于模拟随机事件或生成具有某种统计特性的随机数据。然而,由于样本可以被重复抽取,因此有放回抽样的结果可能包含重复的样本。
# 有放回抽样,可能会出现重复值
print(df2.take(np.random.randint(0,5,size=5)))
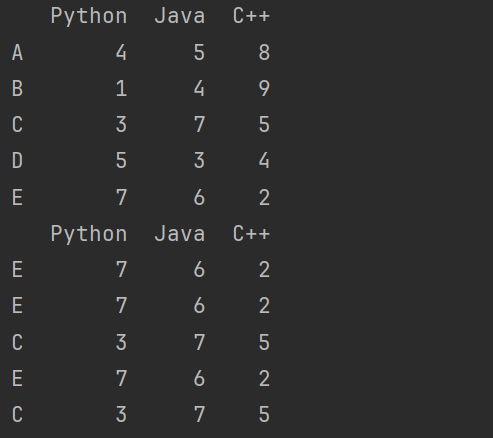
13. Pandas 数学函数
13.1 聚合函数
- count():非空值函数
- max():最大值
- min():最小值
- median():中位数
- sum():求和
- mean():每一行的平均值
import pandas as pd
import numpy as np
"""
聚合函数
"""
df = pd.DataFrame(
data = np.random.randint(0,100,size=(5,3))
)
print(df)
# - count():非空值函数
print(df.count()) # 每一列非空的数量
print(df.count(axis=1)) # 每一行非空的数量
# - max():最大值
print(df.max()) # 每一列最大值
print(df.max(axis=1)) # 每一行最大值
# - min():最小值
print(df.min()) # 每一列最小值
print(df.min(axis=1)) # 每一行最小值
# - median():中位数
print(df.median()) # 每一列中位数
print(df.median(axis=1)) # 每一行中位数
# - sum():求和
print(df.sum()) # 每一列和
print(df.sum(axis=1)) # 每一行和
# - mean():每一列或行的平均值
print(df.mean()) # 每一列平均值
print(df.mean(axis=1)) # 每一行平均值
13.2 其他函数
- value_counts():统计元素出现次数。
- cumsum():累加。
- cumprod():累乘。
- std():标准差。
- var():方差。
- cov():协方差。
- df.cor():所有属性相关性系数。
import pandas as pd
import numpy as np
"""
其他函数
"""
df = pd.DataFrame(
data = np.random.randint(0,100,size=(5,3))
)
print(df)
# - value_counts():统计元素出现次数
df2 = df.copy()
df2.iloc[0] = df2.iloc[1]
print(df2)
print('================')
print(df2[0].value_counts())
# - cumsum():累加
print(df.cumsum()) # 列累加
print(df.cumsum(axis=1)) # 行累加
# - cumprod():累乘。
print(df.cumprod()) # 列累乘
print(df.cumprod(axis=1)) # 行累乘
14. Pandas 分组
Pandas中的分组(Grouping)是一个强大的数据分析工具,它允许用户根据一个或多个列的值将数据分割成不同的组,并对每个组进行独立的分析和操作。
基本原理
分组的核心是groupby()函数。调用groupby()函数时,Pandas会根据指定的列或函数将DataFrame分割成多个子集,每个子集包含具有相同值的行。
语法
- groupby()函数。
- .groups属性查看各行的分组情况。
数据分类处理
- 分组:先把数据分为几组。
- 用函数处理:为不同组的数据应用不同的函数以转换数据。
- 合并:把不同组得到的结果合并起来。
数据分类处理的核心:groupby()函数,使用.groups属性查看各行的分组情况
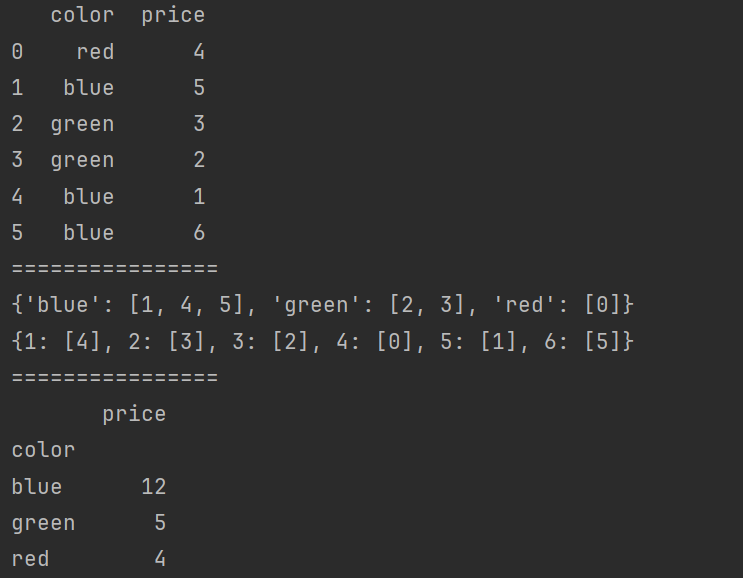
import pandas as pd
df = pd.DataFrame(
{
'color': ['red', 'blue', 'green', 'green', 'blue', 'blue'],
'price': [4, 5, 3, 2, 1, 6]
}
)
print(df)
print('================')
df2 = df.groupby(by='color')
print(df2.groups)
df3 = df.groupby(by='price')
print(df3.groups)
print('================')
# 分组 + 聚合
print(df.groupby('color').sum())
14.1 练习
假设菜市场张大妈在卖菜,有以下属性:
- 菜品(item):萝卜,白菜,辣椒,冬瓜
- 颜色(color):白,青,红
- 重量(weight)
- 价格(price)
- 要求以属性作为列索引,新建一个df
- 对ddd进行聚合操作,求出颜色为白色的价格总和
- 对ddd进行聚合操作,分别求出萝卜的所有重量以及平均价格
- 使用merge合并总重量及平均价格
需求:
- 要求以属性作为列索引,新建一个df
- 对df进行聚合操作,求出颜色为白色的价格总和
- 对df进行聚合操作,分别求出萝卜的所有重量以及平均价格
- 使用merge合并总重量及平均价格
import pandas as pd
df = pd.DataFrame(
data={
'item': ['萝卜', '白菜', '辣椒', '冬瓜', '萝卜', '白菜', '辣椒', '冬瓜'],
'color': ['白', '青', '红', '白', '青', '红', '白', '青'],
'weight': [10, 20, 10, 10, 30, 40, 50, 60],
'price': [0.99, 1.99, 2.99, 3.99, 4, 5, 6, 7],
}
)
print(df)
# 1. 对df进行聚合操作,求出颜色为白色的价格总和
color = df.groupby('color')['price'].sum() # Series
color2 = df.groupby('color')[['price']].sum() # DataFrame
print(color.loc['白'])
print(color2.loc['白'])
print(color2.loc[['白']].values)

# 2. 对df进行聚合操作,分别求出萝卜的所有重量以及平均价格
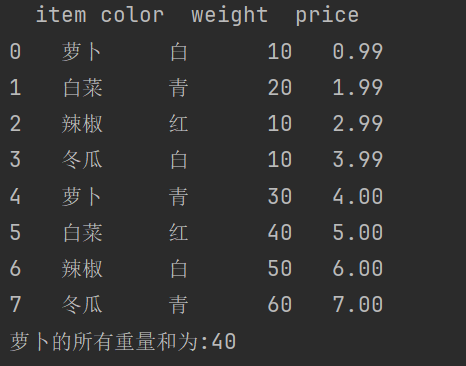
weight = df.groupby('item')['weight'].sum().loc['萝卜']
# weight = df.groupby('item')[['weight']].sum().ilo[2]
print(f"萝卜的所有重量和为:{weight}")
# 3. 使用merge合并总重量及平均价格
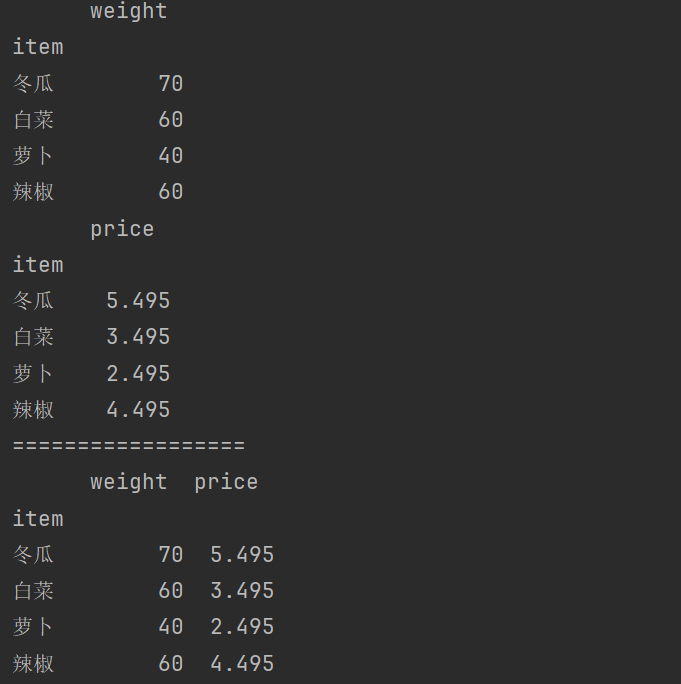
weight2 = df.groupby('item')[['weight']].sum()
print(weight2)
price2 = df.groupby('item')[['price']].mean()
print(price2)
print('==================')
print(weight2.merge(price2,on = 'item'))
15. Pandas 加载数据
15.1 CSV 数据加载
CSV(Comma-Separated Values)是一种常见的文件格式,用于存储表格数据。CSV文件是以文本形式存在的,其中的数据由逗号(或其他分隔符)分隔,每行代表一个数据记录,而每列则代表一种数据类型或属性。
Name,Age,Gender,Occupation
John,30,Male,Engineer
Emily,25,Female,Doctor
Michael,40,Male,Lawyer
Sarah,35,Female,Teacher
David,28,Male,Data Scientist
在这个例子中:
- 文件包含6行数据,其中第一行是列名或字段名。
- 每一列代表一种数据类型或属性:
Name、Age、Gender和Occupation。 - 后面的5行是数据记录或观测值,每行包含了对应列的值。
- 数据项之间用逗号(
,)分隔。
参数说明:
-
path_or_buf: 指定要保存CSV文件的路径或缓冲区。如果未指定,则返回CSV格式的字符串。 -
sep: 列分隔符,默认为逗号(', ')。 -
na_rep: 缺失值的表示方式,默认为空字符串(‘’)。 -
float_format: 浮点数的格式化方式,默认为None,即使用Python的默认格式。 -
columns: 要保存的列名列表,默认为所有列。 -
header: 是否包含列名,默认为True。 -
index: 是否包含索引,默认为True。 -
index_label: 索引列的标签,默认为索引名称。 -
mode: 写入文件的模式,默认为’w’(写入)。 -
…
保存CSV数据
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=np.random.randint(0, 50, size=(10, 5)),
columns=['Python', 'Java', 'H5', 'C++', 'Php']
)
print(df)
# 保存到CSV中
# sep:分隔符默认为逗号
# path_or_buf:保存路径
# header:表示是否保留列索引
# index:表示保留行索引
df.to_csv('data.csv', sep=',', header=True, index=True)
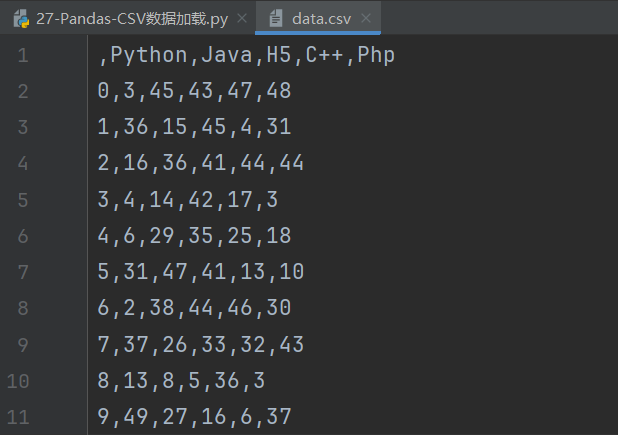
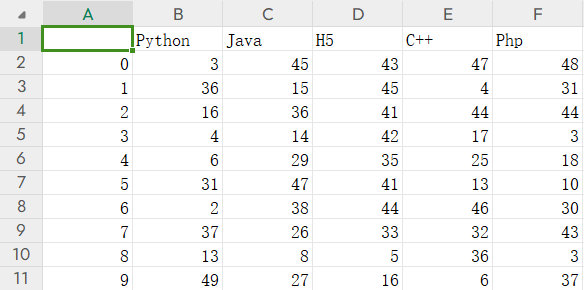
header和index为True的话,在程序执行后就会保留,行列索引。
不获取列header=None
# 加载CSV数据,默认以逗号隔开
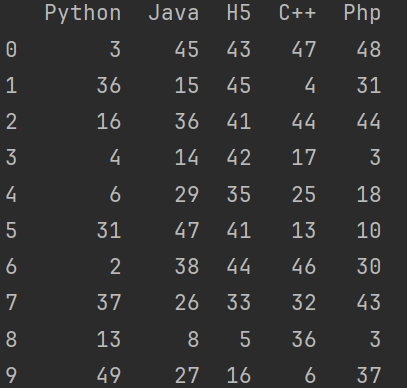
print(pd.read_csv('data.csv', sep=',', header=[0], index_col=0))
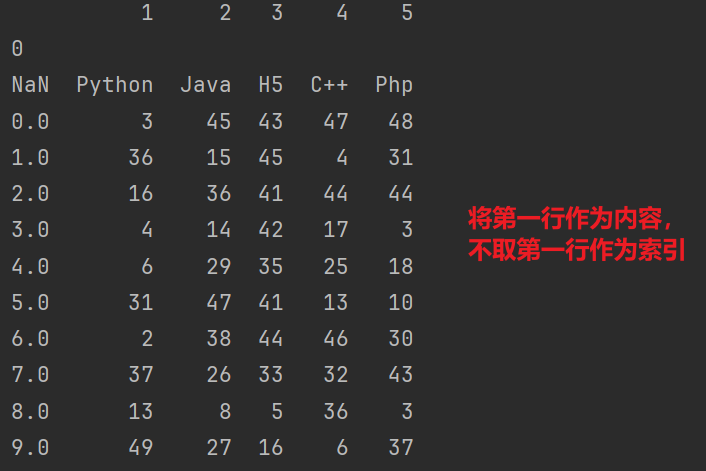
# 会将第一行作为内容,不取第一行作为索引
print(pd.read_csv('data.csv', sep=',', header=None, index_col=0))
pd.read_table
# pd.read_table
# sep默认不等于逗号
print(pd.read_table('data.csv', sep=',', index_col=0))
print(pd.read_table('data.csv', sep='\t', index_col=0))
说明:
read_csv函数默认使用逗号(,)作为分隔符来解析CSV文件。read_table函数默认使用制表符(\t)作为分隔符来解析制表符分隔的文件(TSV)。
15.2 Excel 数据加载
保存到Excel文件
to_excel()参数说明:
excel_writer: 可以是一个文件路径(字符串)或一个已经打开的ExcelWriter对象。sheet_name: 要写入的Excel工作表的名称,默认为’Sheet1’。na_rep: 缺失值的表示方式,默认为空字符串。float_format: 浮点数的格式化方式,默认为None,即使用Python的默认格式。columns: 要保存的列名列表,默认为所有列。header: 是否包含列名,默认为True。index: 是否包含索引,默认为True。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=np.random.randint(0, 50, size=(10, 5)),
columns=['Python', 'Java', 'H5', 'C++', 'Php']
)
print(df)
# 保存到Excel文件
"""
sheet_name:工作表名称(默认Sheet1)
header:是否保存列索引
index:是否保存行索引
"""
df.to_excel('data2.xlsx',sheet_name='Sheet1',header=True,index=False)
读取Excel文件
pd.read_excel()参数说明:
io: 文件路径或已经打开的文件对象。可以是Excel文件的路径(字符串)或一个包含Excel数据的对象。sheet_name: 要读取的工作表名称或索引,默认为0(即第一个工作表)。header: 表头行的行号,默认为0(即第一行是表头)。names: 列名列表,默认为None,即从文件中读取列名。替换掉原来的列名。
# 读取Excel文件
print(pd.read_excel('data2.xlsx',sheet_name='Sheet1'))
# sheet_name='0'读取第一个工作表
print(pd.read_excel('data2.xlsx',sheet_name=0))
# names=list('ABCDE')替换掉原来的列名
print(pd.read_excel('data2.xlsx',sheet_name=0,names=list('ABCDE')))
15.3 MySQL 数据加载
保存到MySQL数据库
df.to_sql()参数说明:
name: 要写入的表的名称。con: 一个 SQLAlchemy connectable 对象(如 Engine 或 Connection)或一个 DBAPI2 连接对象。schema: 数据库架构(如果适用)。if_exists: 指定当表已经存在时的行为,可选值为 ‘fail’(默认)、‘replace’、‘append’ 或 ‘ignore’。index: 是否保存DataFrame的索引,默认为True。index_label: 索引列的名称,默认为None。chunksize: 分块写入的大小(以行数为单位),默认为None,即一次性写入整个DataFrame。dtype: 字典,用于指定每个列的数据类型。method: 可选值为 ‘multi’ 或 ‘single’,指定批量插入的方法。
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
df = pd.DataFrame(
data=np.random.randint(0, 100, size=(100, 3)),
columns=['Python', 'Java', 'PHP']
)
# 连接数据库
"""
mysql+pymysql:数据库类型+驱动
root:820129:数据库用户名+密码
localhost:3306:数据库地址+端口
wuhu:数据库名称
"""
conn = create_engine('mysql+pymysql://root:820129@localhost:3306/wuhu')
"""
name='test':数据库中表名称
con=conn:数据库连接对象
index=False:是否保存行索引
if_exists='append':如果表存在,则追加数据
"""
# 保存到MySQL数据库
df.to_sql(name='test', con=conn, index=False, if_exists='append')
从MySQL数据库中读取数据
pd.read_sql()参数说明:
sql: SQL查询语句。con: 一个 SQLAlchemy connectable 对象(如 Engine 或 Connection)或一个 DBAPI2 连接对象。index_col: 用作DataFrame的索引的列名或列编号,默认为None。
# 从MySQL数据库中读取数据
print(
pd.read_sql(
'select * from test', con=conn
)
)
16. Pandas 分箱操作
Pandas中的分箱操作(Binning)是一种数据预处理技术,它将连续的数据分割成离散的区间或“箱子”(bins),每个区间包含一定范围内的值。分箱操作通常用于减少数据的复杂性、处理异常值、可视化数据分布以及进行非参数统计分析。
16.1 等宽分箱
等宽分箱: 等宽分箱是指将数值区间分割成宽度相等的箱子。例如,如果一个年龄变量,并希望将其分成5个箱子,你可以设置每个箱子的宽度为5年。在这种情况下,所有年龄在0-4岁的人会被分到第一个箱子,5-9岁的人被分到第二个箱子,以此类推。
pd.cut()参数说明:
x: 要进行分箱操作的一维数组或Series。bins: 定义箱子边界的列表或数组。可以是等宽的间隔列表、等频的分位数列表,或者是自定义的边界列表。right: 默认为True,表示箱子的右端点是包含的。如果设置为False,则左端点是包含的。labels: 自定义箱子的标签,而不是默认的区间表示。如果为None(默认值),则使用区间的表示。
value_counts()是Pandas库中的一个函数,用于计算Series或DataFrame某一列中各个值的出现次数
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=np.random.randint(0, 100, size=(5, 3)),
columns=['Python', 'Java', 'PHP']
)
print(df)
print('==============')
# 等宽分箱
# print(df.Python)
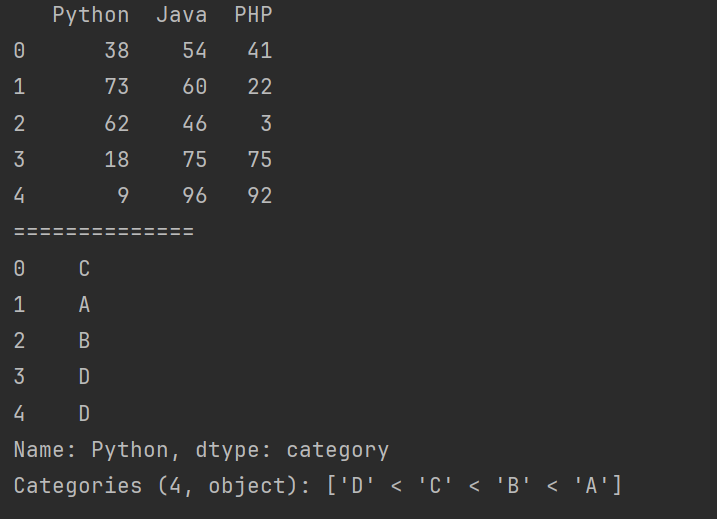
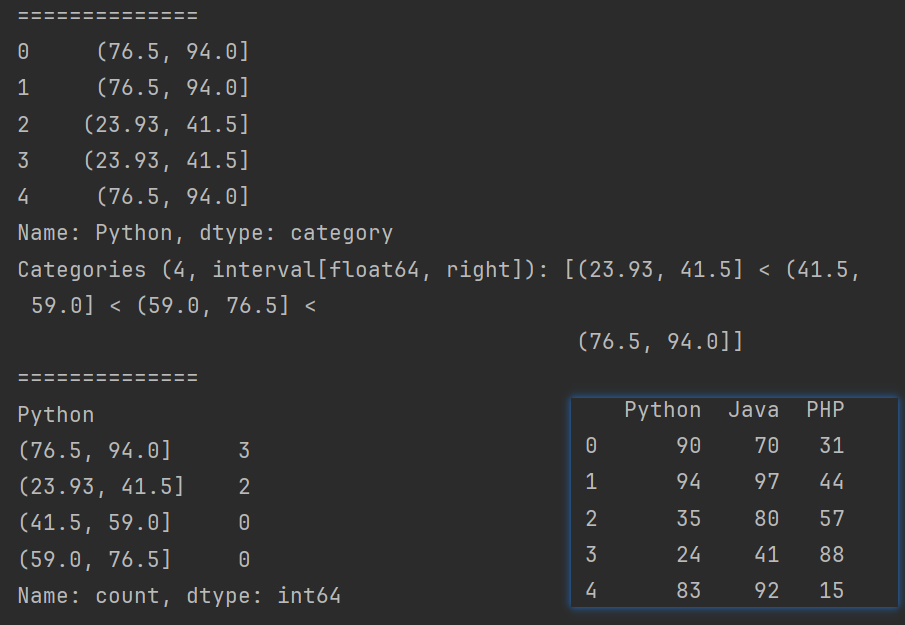
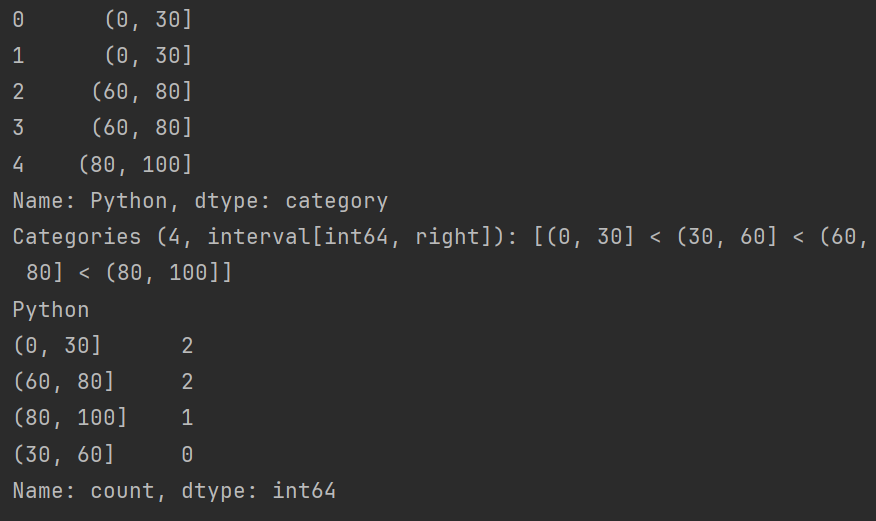
# s = pd.cut(df.Python, bins=4) # 将Python分成4个箱子
# s = pd.cut(df.Python, bins=[0,30,60,80,100]) # bins=[0,30,60,80,100]分箱中的断点
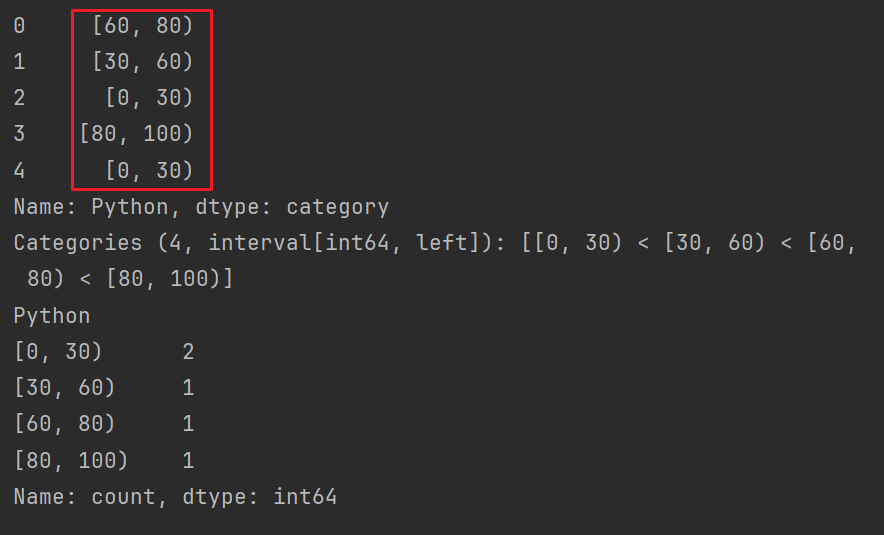
# s = pd.cut(df.Python, bins=[0, 30, 60, 80, 100], right=False) # 左闭右开,默认左开右闭
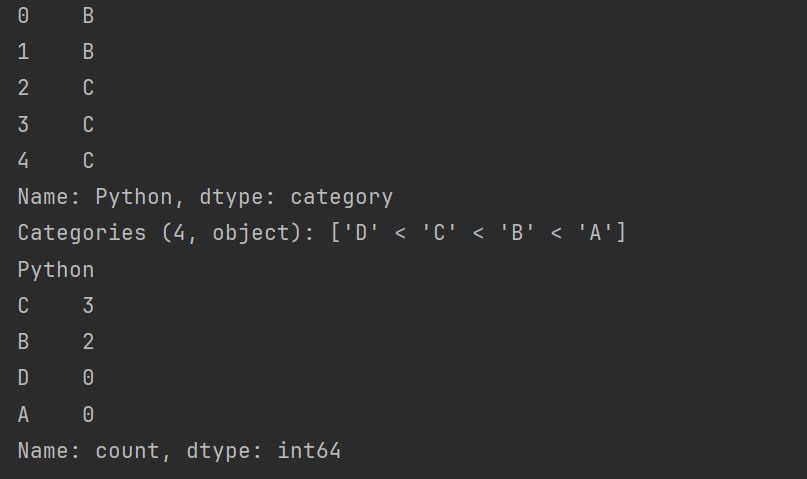
# s = pd.cut(df.Python, bins=[0, 30, 60, 80, 100], right=False,labels=['D','C','B','A']) # 自定义箱子的标签,而不是默认的区间表示。
print(s)
print('==============')
print(s.value_counts())
16.2 等频分箱
等频分箱: 等频分箱是指将数值区间分割成包含相同数量观察值的箱子。这种方法确保每个箱子包含相同数量的数据点,因此箱子的宽度可能会有所不同。
pd.qcut()参数说明:
x: 要进行分箱操作的一维数组或Series。q: 定义箱子数量的列表或数组。可以是一个整数(表示等分的箱子数量),或者是自定义的分位数列表。labels: 自定义箱子的标签,而不是默认的区间表示。如果为None(默认值),则使用区间的表示。
import pandas as pd
import numpy as np
df = pd.DataFrame(
data=np.random.randint(0, 100, size=(5, 3)),
columns=['Python', 'Java', 'PHP']
)
print(df)
print('==============')
# 等频分箱
s = pd.qcut(df.Python, q=4, labels=['D', 'C', 'B', 'A'])
print(s)