在Python 3.5版本后引入的typing模块为Python的静态类型注解提供了支持。这个模块在增强代码可读性和维护性方面提供了帮助。
目录
- 简介
- 为什么需要 Type hints
- typing常用类型
- typing初级语法
- typing基础语法
- 默认参数及 Optional
- 联合类型 (Union Type)
- 类型别名 (Type Alias)
- 子类型 (NewType)
- 强制类型转换 (Type Casting)
- Any 类型
- 底类型 Never 和 NoReturn
- 泛化容器/集合类型 (Collections)
- 元组 (Tuple)
- 标注可变长参数与关键字参数的类型
- 可调用对象 (Callable)
- 字面量(Literal)
- 字符串字面量(LiteralString)——**该特性仅在 Python 3.11+ 可用**
- 前向引用 (Forward Reference)
- @override 装饰器
- typing中级语法
- 抽象基类(Abstract Base Class)
- 泛型:类型变量 (TypeVar)
- 自引用类型 (Self)——该特性仅在 Python 3.11+ 可用
- typing高级语法
- 类型字典 (TypedDict)
- TypedDict 中的可选值
- 标注 **kwargs 的类型 (Unpack)
- 结尾
简介
typing模块为Python带来了类型提示和类型检查的能力。它允许开发者在代码中添加类型注解,提高代码的可读性和可维护性。尽管Python是一种动态类型语言,但类型注解能让开发者更清晰地了解函数和变量的预期类型。
备注:Python 运行时不强制要求函数与变量类型标注。 它们可被 类型检查器、IDE、语法检查器等第三方工具使用。
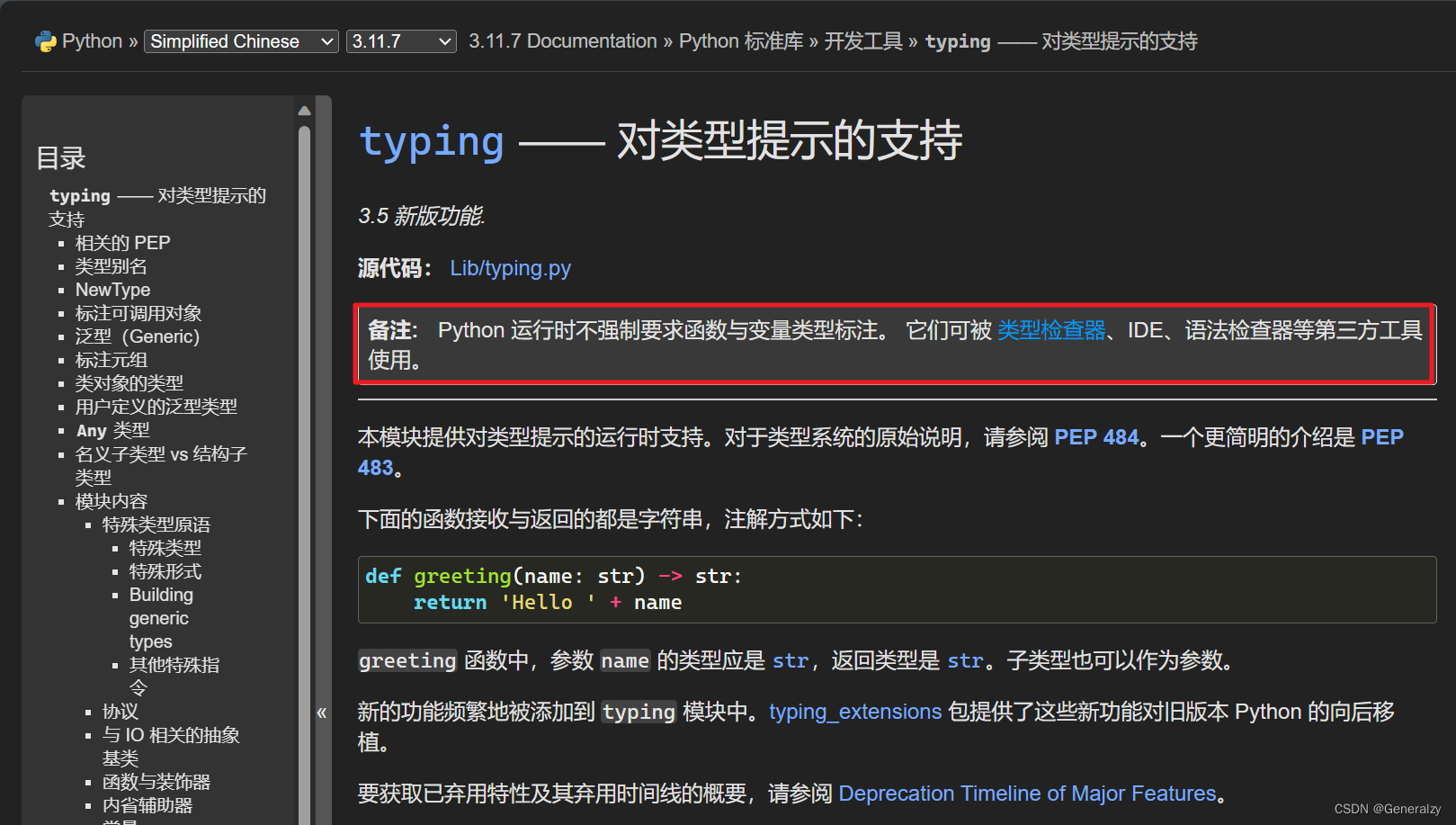
Type hints 即类型提示,是 Python 在 3.5 版本中加入的语法,并在 Python 3.6 基本可用。在此后的版本中,Type hints 的功能不断扩充,至今已经能够实现一个比较完善的静态类型系统。
正如其名称暗示的那样,Type hints 是“类型提示”而不是“类型检查”,Python 并不会在程序运行时检查你所标注的类型与变量的真实类型是否一致——如果不一致,也并不会产生错误。Type hints 最大的作用是在编辑器中对代码进行静态类型检查,以方便你发现因类型不一致而导致的潜在运行时错误,并增强你代码的重构能力,以提升代码的可维护性。对于大型项目而言,这格外有价值——但即便在小型项目中,Type hints 也具有足够的意义。
为什么需要 Type hints
如果你通常使用 Python 编写小脚本、进行数据科学工作或是构建人工智能模型,那么使用 Type hints 或许没有想象中的有效,也不一定需要了解它。
但如果你正在使用 Python 开发软件或是构建其他大型项目,那么使用 Type hints 能够使你享受静态类型带来的一部分优势,使重构变得更加便利,也能更好地减少代码中因类型不一致产生的潜在运行时错误。
不过,Python 的本质仍是动态类型语言,因此没有必要追求 100% 的类型提示,这反而失去了动态类型的优势,陷入了思维定势中——并且实际上目前的 Type hints 并不足以百分百兼容 Python 的灵活性,仍有不少场景是 Type hints 无法很好表示的。
typing常用类型
以下是typing包中常用的类型和泛型。(注意,int, float,bool,str, bytes不需要import typing,Any,Union,Tuple等需要import typing。)
基本类型:
- int: 整数类型
- float: 浮点数类型
- bool: 布尔类型
- str: 字符串类型
- bytes: 字节类型
- Any: 任意类型
- Union: 多个类型的联合类型,表示可以是其中任意一个类型
- Tuple: 固定长度的元组类型
- List: 列表类型
- Dict: 字典类型,用于键值对的映射
泛型:
- Generic: 泛型基类,用于创建泛型类或泛型函数
- TypeVar: 类型变量,用于创建表示不确定类型的占位符
- Callable: 可调用对象类型,用于表示函数类型
- Optional: 可选类型,表示一个值可以为指定类型或None
- Iterable: 可迭代对象类型
- Mapping: 映射类型,用于表示键值对的映射
- Sequence: 序列类型,用于表示有序集合类型
- Type:泛型类,用于表示类型本身
typing初级语法
typing基础语法
def show_count(count: int, word: str) -> str:
if count == 1:
return f'1 {word}'
count_str = str(count) if count else 'no'
return f'{count_str} {word}s'
Python 的 Type Hints 不仅支持基本类型,如int, float, str……也支持自定义的类型。例如:
class Bird:
def fly(self):
...
def bird_fly(bird: Bird) -> None:
bird.fly()
默认参数及 Optional
根据 PEP 8 的相关建议,在不使用 Type Hints 时,默认参数的等号两边应该没有空格,而使用 Type Hints 时,则建议在等号两边加上空格。
def show_count(count: int, singular: str, plural: str = '') -> str:
if count == 1:
return f'1 {word}'
if not plural:
plural = singular + 's'
return f'{count_str} {plural}'
有时我们需要使用 None 作为默认参数,特别是在默认参数可变的情况下,将 None 作为默认参数几乎是唯一的选择。
在 Python 3.10+ 中,建议使用 | None(读作或None) 用于表示其类型也可以是 None。
def show_count(count: int, singular: str, plural: str | None = None) -> str:
...
>>> show_count(2, 'child', 'children')
'2 children'
>>> show_count(1, 'mouse', 'mice')
'1 mouse'
在更早的 Python 版本中,可以使用 Optional[…] 作为替代:
from typing import Optional
def show_count(count: int, singular: str, plural: Optional[str] = None) -> str:
...
Optional”这个名称具有一定的迷惑性——在 Python 中经常说某一个函数参数是“可选 (Optional)”的,以表示某一个函数参数可以被传递或者不传递。然而这里的 Optional[...]却仅仅表示某个变量的类型可以是 None,而其本身却并不具有“可选”的含义。
注:永远不要使用可变值作为默认参数,因为python的可变类型的传值是引用传递,会将变量的地址传递进去:
>>> def func(arg=[]):
... return arg
...
>>> func()
[]
>>> lst = func()
>>> lst.append(0)
>>> func()
[0]
# 更好的方法是使用 `None` 作为默认值
def func(arg=None):
if arg is None:
arg = []
return arg
联合类型 (Union Type)
有时候函数可能有不同类型的返回值,甚至参数也是不同类型的。这时可以使用联合类型语法,即使用竖线|分隔类型:
def parse_token(token: str) -> str | float:
try:
return float(token)
except ValueError:
return token
| 操作符同样支持 isinstance 和 issubclass 函数:
isinstance(x, int | str | tuple)
需要注意的是,仅 Python 3.10+ 支持该语法,如果需要在更早的版本中使用联合类型,则需要从 typing 中导入 Union:
from typing import Union
def parse_token(token: str) -> Union[str, float]: ...
Union 支持多个类型与嵌套。例如以下的两种用法是等价的:
Union[A, B, Union[C, D, E]]
Union[A, B, C, D, E]
from typing import Union
def add(a: int | str, b: int | str) -> Union[int, str]:
return a + b
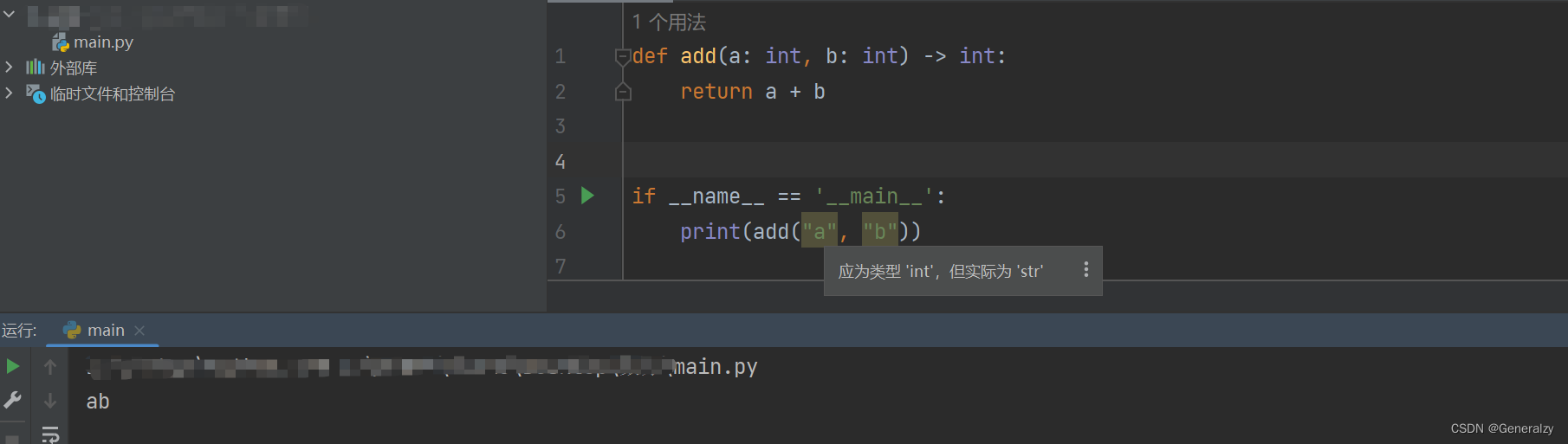
if __name__ == '__main__':
print(add(1, 2))
# 3
print(add("1", "2"))
# 12
类型别名 (Type Alias)
除联合类型外,也可以为类型命名,这被称为“类型别名(Type Alias)”。在 Python 3.12+,可以使用 type 关键字轻松创建一个类型别名:
type Hexadecimal = str | int
def hex_to_ascii_string(hex: Haxdecimal) -> str:
...
# 上面的代码与以下代码是等价的
def hex_to_ascii_string(hex: str | int) -> str:
...
事实上,使用 type 创建类型别名并不是完全必要的。也可以省略 type,直接创建类型别名:
Hexadecimal = str | int
如果使用早于 Python 3.12 的版本,type 关键字还不被支持,便只能这样写。然而尽管 type 似乎不是必要的,仍建议在 Python 3.12+ 中明确写出 type,这更清晰地表明了你只是在定义一个类型别名,而不是某个运行时使用的变量。
除了定义简单的类型别名,type 关键字还用于更方便地处理泛型定义:
type ListOrSet[T] = list[T] | set[T]
如果在使用 Python 3.10~3.11时,也希望能够像 Python 3.12+ 一样明确表示你在定义一个类型别名,则可以使用 TypeAlias 类型,这更加清晰。不过不像 type 关键字,使用 TypeAlias 最大的作用只是使类型别名更清晰并且更容易被静态类型检查器发现:
Hexadecimal: TypeAlias = str | int
TypeAlias 的另一个作用:避免前向引用类型的别名与值为特定字符串的变量混淆——但无论怎么说,TypeAlias 的功能都已经被新引入的 type 关键字完全覆盖了,并且在 Python 3.12 中被标记为了废弃 (Deprecated),所以在 Python 3.12+ 中建议尽可能使用 type 关键字。
更多关于 Python 3.12 引入的 type 关键字的信息,可以参考 PEP 695 – Type Parameter Syntax 的相关部分。
关于 Python 3.10 引入的 TypeAlias 的更多信息,可以参考 PEP 613 – Explicit Type Aliases.
from typing import Union, TypeAlias
Hexadecimal: TypeAlias = str | int
def add(a: Hexadecimal, b: Hexadecimal) -> Union[Hexadecimal]:
return a + b
if __name__ == '__main__':
print(add(1, 2))
# 3
print(add("1", "2"))
# 12
子类型 (NewType)
有时候,会在代码中创建类型别名以增强代码可读性:
type Second = float
type Millisecond = float
type Microsecond = float
def sleep(duration: Second) -> None:
...
在这里,通过为 float 起类型别名 Second 表明了 sleep 函数应当接收一个以秒为单位的时间长度。因此,通常你希望用户这样调用它:
sleep(1.5) # 休眠 1.5 秒
只是这并不能阻止粗心的用户将这里的时间单位当作毫秒。如果用户这么调用它,显然也不会产生错误:
sleep(1500) # 试图休眠 1.5 秒,实际休眠了 1500 秒
类型别名只是别名,它与原本的类型没有区别。它能起到一定的文档作用,让代码更加易读,却不能使静态类型检查器施加更严格的约束。
这时,可能更希望创建“子类型 (Subtype)”,使用户更明确地认识到函数的作用:
from typing import NewType
Second = NewType("Second", float)
Millisecond = NewType("Millisecond", float)
Microsecond = NewType("Microsecond", float)
def sleep(duration: Second) -> None:
...
sleep(1.5) # 错误: `float` 不是 `Second` 类型
sleep(Millisecond(1.5)) # 错误: `Millisecond` 不是 `Second` 类型
sleep(Second(1.5)) # 正确
还是需要注意:类型标注不会导致执行报错!!!
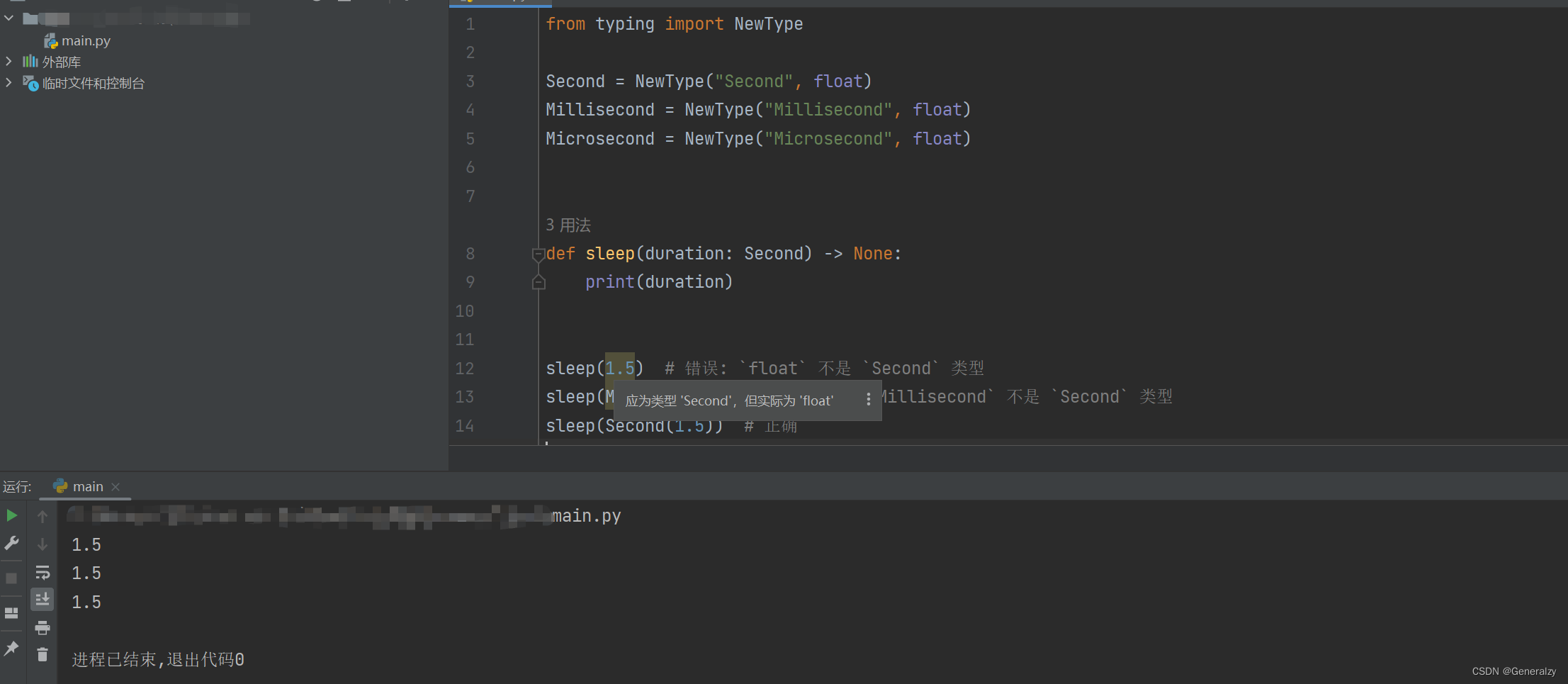
上文代码通过 NewType 创建了 float 的三个子类型 Second、Millisecond 以及 Microsecond. 现在 sleep 函数只接收 Second 类型,而不能接收 float、Millisecond 或 Microsecond. 这和继承关系有些相似,若指定使用子类型,则不能使用父类型。
在用户 ID 这样的场景下使用 NewType 定义子类型可能是个不错的主意:
from typing import NewType
UserId = NewType("UserId", int)
some_id = UserId(524313)
def get_user_name(user_id: UserId) -> str:
...
# 正确
user_a = get_user_name(UserId(42351))
# 错误: `int` 不是 `UserId`
user_b = get_user_name(-1)
也可以继续通过上面定义的 UserId 派生新的子类型:
from typing import NewType
UserId = NewType("UserId", int)
ProUserId = NewType("ProUserId", UserId)
然而,通过 NewType 定义的子类型不是一个真正的“子类”,它无法通过 class 关键字进行继承:
from typing import NewType
UserId = NewType("UserId", int)
# 错误: `UserId` 被标记为 final,无法被继承
# 这也会导致运行时错误
class AdminUserId(UserId):
...
然而,值得注意的是通过 NewType 定义的子类型可执行的操作仍与父类型完全相同。例如即使上面定义了 UserId 类型,将两个 UserId 相加后得到的结果仍是 int 类型:
# output是 `int` 类型,而非 `UserId` 类型
output = UserId(23413) + UserId(54341)
强制类型转换 (Type Casting)
from typing import cast
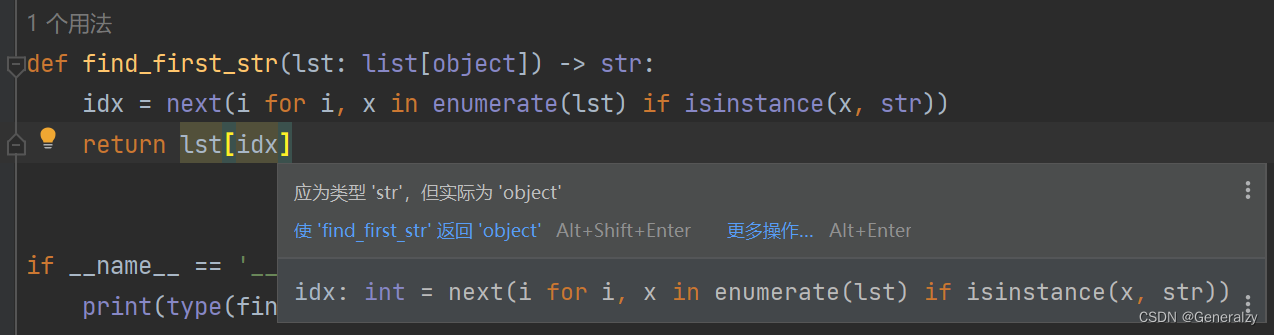
def find_first_str(lst: list[object]) -> str:
idx = next(i for i, x in enumerate(lst) if isinstance(x, str))
return lst[idx]
静态类型检查器并不能在如此复杂的情况下理解发生了什么。它会报告一个错误:
为此,可以使用 typing.cast 强制转换某个值的类型,例如这里将 lst[idx] 强制转换为 str 以消除错误:
from typing import cast
def find_first_str(lst: list[object]) -> str:
idx = next(i for i, x in enumerate(lst) if isinstance(x, str))
return cast(str, lst[idx])
cast 是否会对运行时造成性能影响?实际上几乎不会。这是它的代码实现:
def cast(typ, val):
"""将一个值转换为某个类型.
该函数会原样返回值。对于类型检查器来说,这是一个标志,
表示返回值已经被转换成了指定的类型。但在运行时,我们
希望该函数不会进行任何类型检查(因为我们希望这个函数
能够尽可能快)
"""
return val
可以看到,cast 只是作为一个标记,它并不在运行时产生任何作用,只是将传入的值原样返回。因此显然它也不会在运行时真正转换值的类型,只是为静态类型检查器提供了提示。
Any 类型
有时你会发现自己并不能明确表示某个值的类型,此时可以使用 Any,表示任意类型:
from typing import Any
# 这里先不考虑为该函数标注返回值
def double(x: Any):
return 2 * x
显然,这里的 x 可以是很多类型,例如 int、float 甚至 np.uint32 这样的数字类型,又或者是 tuple、list 或是 pd.Series 这样的序列类型。所以这里使用了 Any 类型,因为输入值有很多可能。
除非需求所需,实属无奈,一般不建议使用Any,因为使用Any是一种极其不负责任的表现,相当与把问题又踢皮球一样踢走了。如同go里面make了一个interface的map去承载string类型的key-val一样,人见人打:make(map[interface{}]interface{})
Any 实际上“逃避”了静态类型检查器的类型检查——这是一种独特的类型,假如一个变量的类型是 Any,那么任何值都能被赋值给它,同时它也能被赋值给任何类型的变量。
底类型 Never 和 NoReturn
类型通常包含一些值,例如 str 包含所有字符串,int 包含所有整数,某个自定义的 Dog 类也包含所有它以及其子类的实例。但一个特殊的类型除外,即“底类型 (Bottom type)”,它不包含任何值。
在 Python 3.12+ 中,它被命名为 Never,可以从 typing 中导入它——你可能有些奇怪,在什么情况下需要这个类型。这可能的确不是一个常用的类型,但在类型系统中却有着很大的意义。思考一下,我们通常可以将类型的层次理解为一种不精确的“包含”关系——object 作为一切的基类包含着所有值,自然也包含了 Number,Number 则作为所有数字的基类包含着一切 int、float 和 complex,自然就包含了 int,而 int 又包含着一切具体的整数。而 Never 则仅仅作为一个类型,却不具有任何值(一个空集),那么它就被任何其他类型所包含,即任何类型的子类型,存在于层级的“底部”,这就是为什么称它为“底类型”。
什么样的函数会返回 Never,这样一个不具有任何值的类型?当然是永远不会返回值的函数。例如 sys.exit() 函数必定引发一个错误导致程序退出,那么它就永远不会返回值,因此我们可以这样表示它:
from typing import Never
def exit(__status: object = ...) -> Never:
...
在 Python 3.11 及之前的版本中,存在一个 NoReturn 类型——在 Python 3.12+ 中你当然也可以使用它。它的含义与 Never 一致(类型检查器将 Never 和 NoReturn 视为同一个类型的不同别名),它的名称也很清晰地表明它表示一个永远不会返回的函数的“返回值类型”,因此我们也可以将 exit 的定义写成这样:
from typing import NoReturn
def exit(__status: object = ...) -> NoReturn:
...
对于 exit 函数的这种情况,用 NoReturn 可能是更清晰的写法。只是在 Python 3.12+ 中,Python 官方更建议优先使用 Never,因为它更明确表明了该类型的本质,而不是只能作为某个永远不会返回的函数的“返回值类型”使用。
例如,有些时候你也可以用 Never 作为某个函数的参数表示它永远不该被调用的函数,在这种情况下它比 NoReturn 这个名称看起来要更合适——尽管可能很难想象到这样一个函数的存在价值:
from typing import Never
def never_call_me(arg: Never) -> None:
...
泛化容器/集合类型 (Collections)
在 Python 中,你可以这样表示一个容器中只包含特定的值:
def tokenize(text: str) -> list[str]:
return text.upper().split()
在 Python 3.8 及更早的版本中,你不能像这样直接用 list、set 等内置关键字直接表示 Python 内置的容器类型(该语法仅适用于 Python 3.9+),而是需要从 typing 中导入它们:
from typing import List
def tokenize(text: str) -> List[str]:
return text.upper().split()
事实上,Python 正考虑在未来(初步计划是 Python 3.14 中)删除对冗余类型 typing.Tuple 等类型的支持,因此应该优先使用新语法(list、tuple、dict)而非旧语法(typing.List、typing.Tuple、typing.Dict)。
这里容器类型之后方括号 [] 中包裹的是容器中值的类型。因此,list[str] 就表示一个字符串列表,list[int | str] 就表示一个值为整数或字符串的列表,以此类推。
对于映射 (Mapping) 类型(如 dict、defaultdict),可以通过 dict[KeyType, ValueType] 这样的语法分别表示键和值的类型:
def count_chars(string: str) -> dict[str, int]:
result: dict[str, int] = {}
for char in string:
result[char] = result.get(char, 0) + 1
元组 (Tuple)
元组 (Tuple) 有三种用法:
- 用作记录 (Record)
- 用作具名记录 (Records with Named Fields)
- 用作不可变序列 (Immutable Sequences)
将 Tuple 用作记录 (Record) 时,可以直接将几个类型分别包含在 [] 中。例如 (‘Shanghai’, ‘China’, 24.28) 的类型就可以表示为 tuple[str, float, str]
city_area = {
'China': {'Shanghai': 6340.5, 'Beijing': ...},
'Russia': {...},
...
}
def population_density(city_info: tuple[str, float, str]) -> float:
name, population, country = city_info
area = city_area[country][name]
return population / area
将 Tuple 用作具名记录 (Records with named fields) 时,可以使用 NamedTuple:
from typing import NamedTuple
class Coordinate(NamedTuple):
latitude: float
longitude: float
def city_name(lat_lon: Coordinate) -> str:
...
这里用到了具名元组,它使得代码看起来更加清晰。由于 NamedTuple 是 tuple 的子类,因此 NamedTuple 与 tuple 也是相一致(consistent-with)的,这意味着可以放心地使用 NamedTuple代替 tuple,例如这里的 Coordinate 也能表示 tuple[float, float],反之则不行,比如 tuple[float, float] 就不能表示 Coordinate。
将 Tuple 用作不可变序列 (Immutable Sequences) 时,需要使用 ... 表示可变长度:
tuple[int, ...] # 表示 `int` 类型构成的元组
tuple[int] # 表示只有一个 `int` 值的元组
值得注意的是,如果省略方括号,tuple 等价于 tuple[Any, ...] 而非 tuple[Any]。tuple的 用法与list 不同,这是需要注意的。
标注可变长参数与关键字参数的类型
from typing import Optional
def tag(
name: str,
/,
*content: str,
class_: Optional[str] = None,
**attrs: str,
) -> str:
代码中的 / 表示 / 前面的参数只能通过位置指定,不能通过关键字指定。这是 Python 3.8 中新加入的特性。同样的,也可以使用 * 表示 * 后面的参数只能通过关键字指定,不能通过位置指定。
这里对可变参数的类型提示很好理解。例如,content 的类型是 tuple[str, ...],而 attrs 的类型则是 dict[str, str]. 如果把这里的 **attrs: str 改成 **attrs: float 的话,attrs 的实际类型就是 dict[str, float].
可调用对象 (Callable)
在 Python 中,对高阶函数的操作是很常见的,因此经常需要使用函数作为参数。Type hints 也提供了 Callable[[ParamType1, ParamType2, ...], ReturnType]这样的语法表示一个可调用对象(例如函数和类)。Callable 常用于标注高阶函数的类型。例如:
from collections.abc import Callable
from typing import Sequence
def reduce_int_sequence(
seq: Sequence[int],
func: Callable[[int, int], int],
initial: int | None = None
) -> int:
if initial is None:
initial = seq[0]
seq = seq[1:]
result = initial
for item in seq:
result = func(result, item)
return result
又如:
class Order:
def __init__(
self, # `self` 通常不需要显式的类型提示
customer: Customer,
cart: Sequence[LineItem],
promotion: Optional[Callable[["Order"], float]] = None,
) -> None: # `__init__` 总是返回 `None`,因此也不需要类型提示,但标上一个 `None` 通常是推荐的
这里的 Callable 使用了 “Order” 字符串作为第一个参数的类型而非 Order,这涉及到 Python 类定义的实现问题:在 Python 中,类是在读取完整个类之后才被定义的,因此在类体中无法通过直接引用类本身来表示它的类型。
遗憾的是,目前 Callable 本身还不支持可选参数,但可以结合 Protocol 用更复杂的形式表示带可选参数的 Callable。
字面量(Literal)
在 Python 3.8 中,Literal 被引入以用于表示字面量的类型。例如:
from typing import Literal
# 下面的代码定义了 `Fruit` 类型,它只能是 `"apple"`, `"pear", `"banana"` 三个字面量之一
type Fruit = Literal["apple", "pear", "banana"]
根据 PEP 586 – Literal Types 的说明,Literal 支持整数字面量、byte、Unicode 字符串、布尔值、枚举 (Enum) 以及 None. 例如以下的类型都是合法的:
Literal[26]
Literal[0x1A] # Exactly equivalent to Literal[26]
Literal[-4]
Literal["hello world"]
Literal[b"hello world"]
Literal[u"hello world"]
Literal[True]
Literal[Color.RED] # Assuming Color is some enum
Literal[None]
None 和 Literal[None] 是完全等价的,静态类型检查器会将 Literal[None] 简化为 None.
和 Union 一样,此种语法也支持嵌套:
type ReadOnlyMode = Literal["r", "r+"]
type WriteAndTruncateMode = Literal["w", "w+", "wt", "w+t"]
type WriteNoTruncateMode = Literal["r+", "r+t"]
type AppendMode = Literal["a", "a+", "at", "a+t"]
type AllModes = Literal[ReadOnlyMode, WriteAndTruncateMode,
WriteNoTruncateMode, AppendMode]
所以说 Literal[Literal[Literal[1, 2, 3], "foo"], 5, None] 和 Literal[1, 2, 3, "foo", 5, None] 其实也是等价的。
可以看到,一定程度上,Literal 可以替代枚举 (Enum) 类型——当然,与枚举 (Enum) 相比,Literal 并不实际提供运行时约束,这也是 Type hints 的一贯风格。但很大程度上,由于 Literal 的引入,需要使用枚举的地方已经少了很多了。
字符串字面量(LiteralString)——该特性仅在 Python 3.11+ 可用
LiteralString 的推出是为了满足一些不太常用的安全性需求。例如在下面的例子中,使用了某个第三方库执行 SQL 语句,并将一些操作封装到了一个特定的函数中:
def query_user(conn: Connection, user_id: str) -> User:
query = f'SELECT * FROM data WHERE user_id = {user_id}'
conn.execute(query)
这段代码看起来很好,但实际上却有着 SQL 注入的风险。例如用户可以通过下面的方式执行恶意代码:
query_user(conn, 'user123; DROP TABLE data;')
目前一些 SQL API 提供了参数化查询方法,以提高安全性,例如 sqlite3 这个库:
def query_user(conn: Connection, user_id: str) -> User:
query = 'SELECT * FROM data WHERE user_id = ?'
conn.execute(query, (user_id,))
然而目前 API 作者无法强制用户按照上面的用法使用,sqlite3 的文档也只能告诫读者不要从外部输入动态构建的 SQL 参数。于是在 Python 3.11 加入了 LiteralString,允许 API 作者直接通过类型系统表明他们的意图:
from typing import LiteralString
def execute(self, sql: LiteralString, parameters: Iterable[str] = ...) -> Cursor: ...
现在,这里的 sql 参数就不能是通过外部输入构建的了。现在再定义上面的 query_user 函数,编辑器就会在静态分析后提示错误:
def query_user(conn: Connection, user_id: str) -> User:
query = f`SELECT * FROM data WHERE user_id = {user_id}`
conn.execute(query)
# Error: Expected LiteralString, got str.
而其他字符串可以正常工作:
def query_data(conn: Connection, user_id: str, limit: bool) -> None:
# `query` 是一个 `LiteralString`
query = '''
SELECT
user.name,
user.age
FROM data
WHERE user_id = ?
'''
if limit:
# `query` 仍是 `LiteralString`,因为这里只是加上了另一个 `LiteralString`
query += ' LIMIT 1'
conn.execute(query, (user_id,)) # 不报错
如果当前使用的 Python 版本低于 Python 3.11,可以安装 Python 官方提供的 typing_extensions 扩展库来使用这一特性。
from typing_extensions import LiteralString
def execute(self, sql: LiteralString, parameters: Iterable[str] = ...) -> Cursor: ...
前向引用 (Forward Reference)
前向引用 (Forward Reference)”的一个应用——用来在类定义内部表示类自身的类型。例如:
class Rectangle:
# ... 前面的代码省略 ...
def stretch(self, factor: float) -> "Rectangle":
return Rectangle(width=self.width * factor)
事实上,此种用引号包裹尚未在运行时代码中定义类型的前向引用语法,不止适用于在类定义内部表示类自身。假设你首先定义了如下的类:
class Animal:
pass
class Dog:
def bark(self) -> None:
print("汪")
现在,假设你需要在 Animal 上定义一个 as_dog() 方法,通过判断自身是否是 Dog 的实例返回 Dog 或 None. 一个错误的定义如下:
class Animal:
def as_dog(self) -> Dog | None:
return self if isinstance(self, Dog) else None
class Dog:
def bark(self) -> None:
print("汪")
这是因为在定义 Animal 时还未定义 Dog,因此这段代码实际上会产生运行时错误。
你需要用引号包裹 Dog | None 来避免运行时的未定义问题:
class Animal:
def as_dog(self) -> "Dog | None":
return self if isinstance(self, Dog) else None
class Dog:
def bark(self) -> None:
print("汪")
注意,不要仅将 Dog 包裹起来写成 “Dog” | None,这是不合法的。
更多关于前向引用的信息,可以参考 PEP 563 – Postponed Evaluation of Annotations.
@override 装饰器
在过去,通常使用 abc 中的 ABC 和 @abstractmethod 装饰器来实现一个抽象类:
from abc import ABC, abstractmethod
class Base(ABC):
@abstractmethod
def get_color(self) -> str:
return 'blue'
class GoodChild(Base):
def get_color(self) -> str:
return 'yellow'
不过比较遗憾的是,这其实只在运行时奏效。如果定义了这样一个类:
class BadChild(Base):
def get_colour(self) -> str:
return 'red'
这里把 color 拼成了 colour. 但是类型检查器并不会提示这个错误。
在 Python 3.12+ 中,可以使用 @override 装饰器。当你用该装饰器装饰一个方法时,类型检查器会检查该方法是否真的重载了父类中的某个已有方法:
from typing import override
class Base:
def get_color(self) -> str:
return 'blue'
class GoodChild(Base):
@override # OK: overrides Base.get_color
def get_color(self) -> str:
return 'yellow'
class BadChild(Base):
@override # Type checker error: does not override Base.get_color
def get_colour(self) -> str:
return 'red'
typing中级语法
抽象基类(Abstract Base Class)
考虑这样一个函数:
def name2hex(name: str, color_map: dict[str, int]) -> str:
...
这里的 name2hex 函数接收一个字符串 name 以及一个键和值分别为 str 和 int 类型的字典,然后将字符串根据字典翻译成对应的十六进制字符串返回。
这看起来没问题,但其实有个小缺陷。defaultdict 和 OrderedDict 是 dict 的子类,所以这里的 color_map 也可以是 defaultdict 或 OrderedDict,但 UserDict 却不是 dict 的子类,所以 color_map 不能是 UserDict,但使用 UserDict 创建自定义映射却是被推荐的。因此,最好使用 collections.abc 中的 Mapping 抽象类型(映射)或 MutableMapping 抽象类型(可变映射),而不是 dict.
相比 Mapping,MutableMapping 实现了更多方法,例如 setdefault、pop 和 update. 但这里的color_map 没必要实现这些方法,因此使用 Mapping 就可以了:
from collections.abc import Mapping
def name2hex(name: str, color_map: Mapping[str, int]) -> str: ...
然而对于返回值,应该保证类型尽可能明确,因为返回值总是一个具体的类型。比如上面定义的 tokenize 函数:
def tokenize(text: str) -> list[str]:
return text.upper().split()
这里 tokenize 的返回值就应该是具体的,例如这里应该使用 list[str] 而不是 Sequence[str]。
除了 dict 可以用 Mapping 更好地表示外,list/tuple 等序列也应该尽量使用 Sequence 来表示(如果不关心序列的具体类型的话),或者用 Iterable 表示一个可迭代对象。
值得注意的是,Sequence 和 Iterable 有一些微妙的区别。例如要使用 len() 获取输入值的长度,就只能使用 Sequence 而不是 Iterable,因为 Python 中的可迭代对象在迭代完成之前是无法得到长度的,更何况还存在一些可以循环迭代的对象长度是无限的。
泛型:类型变量 (TypeVar)
# python3.12
from collections.abc import Sequence
from random import shuffle
def sample[T](population: Sequence[T], size: int) -> list[T]:
...
在这里,通过在函数名 sample 之后添加了 [T] 定义了一个适用于该函数的“类型变量 (Type variable)”并命名为 T(在其他编程语言中,可能更常将其称为“类型参数 (Type parameter)”,它们描述的是同一个事物)。类型变量只有在具体使用时才会被实际绑定到某个类型上,如对于 sample([1, 2, 3, 4], 2) 这里的 T 就被推导为 int,对于 sample([“foo”, “bar”, “baz”], 2) 则被推导为 str,以此类推。
在 Python 3.11 及更早的版本中,需要使用 typing.TypeVar 像定义普通变量一样在外部定义类型变量:
from collections.abc import Sequence
from random import shuffle
from typing import TypeVar
T = TypeVar('T')
def sample(population: Sequence[T], size: int) -> list[T]:
if size < 1:
raise ValueError('size must be >= 1')
result = list(population)
shuffle(result)
return result[:size]
和许多其他编程语言一样,在 Python 3.12+ 中也可以在函数名后边的类型变量列表里定义多个类型变量:
from typing import Callable
def map_list[T, U](func: Callable[[T], U], lst: list[T]) -> list[U]:
return [func(x) for x in lst]
有时,可能希望精确限制类型变量的取值,这时可以使用“受限类型变量 (Constrained type variable)”语法。例如我们想定义一个 sum_nums 函数,它只能接受 int、float 或 complex 构成的序列:
from typing import Sequence, cast
def sum_nums[T: (int, float, complex)](nums: Sequence[T]) -> T:
res = 0
for n in nums:
res += n
return cast(T, res)
要定义受限类型变量,需要在其名称后使用一个包含了若干类型的元组,它们表示该类型变量的可能取值。
在 Python 3.11 及更早的版本中,需要使用这样的语法定义受限类型变量:
from typing import Sequence, TypeVar, cast
T = TypeVar("T", int, float, complex)
def sum_nums(nums: Sequence[T]) -> T:
...
实际上,受限类型变量的引入最初是为了简化一些函数重载的场景。例如对于以下情况:
@overload
def concat(x: str, y: str) -> str: ...
@overload
def concat(x: bytes, y: bytes) -> bytes: ..
使用受限类型变量可以将其很好地简化:
def concat[AnyStr: (str, bytes)](x: AnyStr, y: AnyStr) -> AnyStr:
...
该 AnyStr 类型已经被 typing 库内置,可以从中导入它。
下面用受限类型变量展示了对 collections.mode 的一个实现,用来返回序列中出现次数最多的数据:
from collections.abc import Iterable
from decimal import Decimal
from fractions import Fraction
def mode[N: (float, Decimal, Fraction)](data: Iterable[N]) -> N:
pairs = Counter(data).most_common(1)
if len(pairs) == 0:
raise ValueError('no mode for empty data')
return pairs[0][0]
Python 的泛型语法支持设置某个类型变量的“上限”。例如对于这里的 collections.mode,我们也许不仅希望能支持 float、Decimal、Fraction 这几个类型,也希望支持所有支持哈希的类型(因为代码中使用了 Counter(),它的实现依赖于 dict,而 dict 中的键必须是可哈希的)。
为此,可以使用如下语法表示类型变量的“上限 (Upper bound)”:
from collections.abc import Hashable
from decimal import Decimal
from fractions import Fraction
def mode[T: Hashable](data: Iterable[T]) -> T:
pairs = Counter(data).most_common(1)
if len(pairs) == 0:
raise ValueError("no mode for empty data")
return pairs[0][0]
Hashable 表示任何实现了 __hash__ 方法的类型,在这里用起来正合适。
对于 Python 3.11 及更早的版本,需要使用 TypeVar 的 bound 参数来表示其上限:
from collections.abc import Hashable
from decimal import Decimal
from fractions import Fraction
from typing import TypeVar
HashableT = TypeVar('NumberT', bound=Hashable)
def mode(data: Iterable[HashableT]) -> HashableT:
...
需要注意的是,这里的 bound 表示 boundary(边界),和 bind 无关。此类具有边界的类型变量也被称为有界泛型,它表示某个类型的“上限”。
回到之前 sum_nums 的例子,解决一个常见问题——你可能会心想,这里似乎也可以使用类型上限——考虑到 int、float、complex 的一致性关系,你可能会写出这样的代码:
def sum_nums[T: complex](nums: Sequence[T]) -> T:
...
这样写没错,但是这会导致类型推导不够精确,有时你会看到一些意料之外的联合类型被推导出来.
这是因为 complex 不仅包含了 int、float 和 complex 自身,也包括了它们组成的联合类型——因此若不明确限定这里的 T 只能有三种单独的取值,联合类型也可能被推导出来。例如在这里的情况下,[1, 2.5, 3] 的类型实际上是 list[int | float],因此 T 便被推导为了 int | float 而不是更精确的 float.
在 Python 3.12+ 中,type 关键字所支持的语法与函数的类型参数列表相同:
type Point[T] = tuple[T, T]
type IntFunc[**P] = Callable[P, int] # ParamSpec, 后面会说
type LabeledTuple[*Ts] = tuple[str, *Ts] # TypeVarTuple, 后面也会说
type HashableSequence[T: Hashable] = Sequence[T] # TypeVar with bound
type IntOrStrSequence[T: (int, str)] = Sequence[T] # TypeVar with constraints
自引用类型 (Self)——该特性仅在 Python 3.11+ 可用
考虑到表示自身的类型是一个非常常见的应用,Python 3.11 中加入了 Self 用于表示自身。例如:
from typing import Self
class Shape:
def set_scale(self, scale: float) -> Self:
self.scale = scale
return self
假如在上面 Shape 的例子中将 set_scale() 的返回值标记为 -> “Shape”,对于下面的例子会出现问题:
class Circle(Shape):
def set_radius(self, r: float) -> Circle:
self.radius = r
return self
Circle().set_scale(0.5) # 返回值类型被推导为 `Shape`,而不是 `Circle`
Circle().set_scale(0.5).set_radius(2.7) # 类型检查出错: `Shape` 不存在属性 `set_radius`
在过去,可以使用类似下面的手段来解决这个问题:
class Shape:
def set_scale[S: "Shape"](self: S, scale: float) -> S:
self.scale = scale
return self
class Circle(Shape):
def set_radius(self, radius: float) -> "Circle":
self.radius = radius
return self
Circle().set_scale(0.5).set_radius(2.7) # 返回值的类型被推导为 `Circle`
在 Python 3.11 及更早的版本中不支持新泛型语法,因此这个 [S: “Shape”] 得用 TypeVar 表示,那这代码看着就更冗长。
现在,使用 Self 就可以优雅地解决问题:
from typing import Self
class Shape:
def set_scale(self, scale: float) -> Self:
self.scale = scale
return self
class Circle(Shape):
def set_radius(self, radius: float) -> Self:
self.radius = radius
return self
事实上,Self 不仅可以用在实例方法的返回值里,在类方法、方法参数类型、属性类型、泛型类以及即将介绍的 Protocol 中都很有用。
…
typing高级语法
类型字典 (TypedDict)
类型字典 (TypedDict) 是 Python 3.8 中新加入的语法,用来为字典进行详细的类型提示。
在上文中已经提到可以使用 dict[keyType, valueType] 标注字典的类型,但这里标注的是字典全部元素的类型。如果字典的不同键或值的类型有所区别,那么就无法使用这种方式标注其类型。
考虑这样一个字典,记录了一本书的信息:
{
'isbn': '0134757599',
'title': 'Refactoring, 2e',
'authors': ['Martin Fowler', 'Kent Beck'],
'pagecount': 478,
}
在 Python 3.8 之前,只能使用 Dict[str, Any] 或是 Dict[str, Union[str, int, List[str]]] 表示其类型,但这两种表示方式都不能完全表示这个字典的类型。下面演示使用 TypedDict 表示这个字典:
from typing import TypedDict
class BookDict(TypedDict):
isbn: str
title: str
authors: list[str]
pagecount: int
这看起来和上文提到过的 NamedTuple 很像,而 NamedTuple 实际上是一个 dataclass,但这里的 TypedDict 不是一个 dataclass。TypedDict 不会实际创建一个类,它只是借鉴了 dataclass 的语法,作为 Type hints 的一部分用来表示一个字典的类型。
在运行时,一个 TypedDict 构造器和创建一个包含相同参数的 dict 构造器是等价的。这意味着这里的“键”不会创建实例属性,也不能被赋予默认值,同时一个 TypedDict 也不能包含任何方法。如下所示:
>>> from typing import TypedDict
>>> class BookDict(TypedDict):
... isbn: str
... title: str
... authors: list[str]
... pagecount: int
...
...
>>> bd = BookDict(title='Programming Pearls',
... authors='Jon Bentley',
... isbn='0201657880',
... pagecount=256)
...
>>> bd
{'title': 'Programming Pearls', 'authors': 'Jon Bentley', 'isbn': '0201657880',
'pagecount': 256}
>>> type(bd)
<class 'dict'>
可以看到,在使用 BookDict 创建字典 bd 时,虽然 authors 并没有被赋以由 TypedDict 标注的字符串列表,而是被赋以一个字符串,但 Python 在运行时仍不会报错,这是因为 Python 不会对 TypedDict 做运行时类型检查。在不使用静态类型检查器时,TypedDict 和注释没有任何区别,也不会起到任何作用,它唯一的作用就是提高代码的可读性,而 dataclass 则会在运行时创建一个真实的类,这与 TypedDict 有明显的不同。
TypedDict 中的可选值
在 Python 3.11 中,typing 库中引入了 NotRequired 类型,可表示某个键值对是“可选的”:
from typing import TypedDict, NotRequired
class BookDict(TypedDict):
isbn: str
title: str
authors: list[str]
pagecount: NotRequired[int]
当然,Python 也提供了相应的 Required 用来表示 TypedDict 中某个键是“必要的”。
from typing import TypedDict, Required, NotRequired
class BookDict(TypedDict):
isbn: Required[str]
title: Required[str]
authors: Required[list[str]]
pagecount: NotRequired[int]
同样的,如果希望在低版本应用这一特性,可以考虑安装 typing_extensions 库。
标注 **kwargs 的类型 (Unpack)
Python 3.12 以来,Python 官方添加了新类型 Unpack,用于解决**kwargs少传入了一个必选参数这个问题:
from typing import NotRequired, TypedDict, Unpack
class BaseChartArgs(TypedDict):
color: str
height: NotRequired[int]
width: NotRequired[int]
def draw_base_chart(**kwargs: Unpack[BaseChartArgs]) -> None:
...
def draw_bar_chart(data: list[int], *args, **kwargs: Unpack[BaseChartArgs]) -> None:
...
draw_base_chart(*args, **kwargs)
...
现在静态类型检查器就能成功检查出来**kwargs中某个字段未赋值的问题了。
…
结尾
python的类型标注到后期往往会有一些晦涩难懂的内容,作为一个普通开发者其实只需要掌握初级语法,了解中级语法就可以了,剩下的语法可以在开发中阅读一些优秀的三方库源码或大佬的文档来逐渐熟悉。
不要有太大的心理负担,毕竟类型标注只是写给编辑器看的而不是解释器或编译器,他不会提高代码的执行效率。





![SSE[Server-Sent Events]实现页面流式数据输出(模拟ChatGPT流式输出)](https://img-blog.csdnimg.cn/direct/f1c68ee09107401b97ec38edd3f8c015.png)