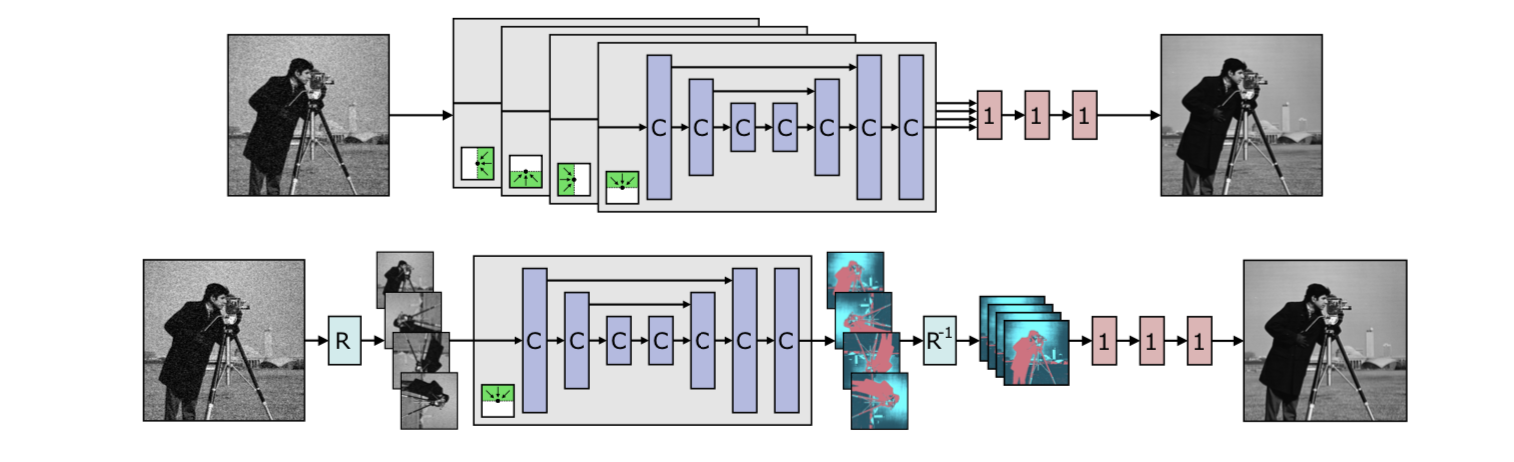
gdip-yolo是2022年提出了一个端到端的图像自适应目标检测框架,其论文中的效果展示了良好的图像增强效果。其提出了gdip模块 |mdgip模块 |GDIP regularizer模块等模块,并表明这是效果提升的关键。为此对gdip-yolo的项目进行深入分析。
gdip-yolo的论文可以查阅:https://hpg123.blog.csdn.net/article/details/135658906

1、整体分析
gdip-yolo项目基于yolov3项目改进所实现,与原始代码相比,仅是删除了训练代码。这里的代码与核心部分gdip功能关联不是很强,其配置文件为常规yolov3训练配置文件。
1.1 配置文件
这里所展露的是gdip-yolo项目中基于py的方式编写配置文件,与新一代的配置文件格式yaml|yml相比存在一定不足。
# coding=utf-8
# project
DATA_PATH = "/scratch/data"
PROJECT_PATH = "/scratch/"
WEIGHT_PATH="/scratch/data/weights/darknet53_448.weights"
DATA = {"CLASSES":['person','bicycle','car','bus','motorbike'],
"NUM":5}
#DATA = {"CLASSES":['bicycle','boat','bottle','bus','car','cat','chair','dog','motorbike','person'],
# "NUM":10}
# model
MODEL = {"ANCHORS":[[(1.25, 1.625), (2.0, 3.75), (4.125, 2.875)], # Anchors for small obj
[(1.875, 3.8125), (3.875, 2.8125), (3.6875, 7.4375)], # Anchors for medium obj
[(3.625, 2.8125), (4.875, 6.1875), (11.65625, 10.1875)]] ,# Anchors for big obj
"STRIDES":[8, 16, 32],
"ANCHORS_PER_SCLAE":3
}
# train
TRAIN = {
"TRAIN_IMG_SIZE":448,
"AUGMENT":True,
"BATCH_SIZE":8,
"MULTI_SCALE_TRAIN":False,
"IOU_THRESHOLD_LOSS":0.5,
"EPOCHS":80,
"NUMBER_WORKERS":5,
"MOMENTUM":0.9,
"WEIGHT_DECAY":0.0005,
"LR_INIT":1e-4,
"LR_END":1e-6,
"WARMUP_EPOCHS":2 # or None
}
# test
TEST = {
"TEST_IMG_SIZE":448,
"BATCH_SIZE":1,
"NUMBER_WORKERS":0,
"CONF_THRESH":0.01,
"NMS_THRESH":0.5,
"MULTI_SCALE_TEST":False,
"FLIP_TEST":False,
"DATASET_PATH":"/scratch/data/RTTS",
"DATASET_DIRECTORY":"JPEGImages"
}
1.2 推理与测试代码
推理代码核心为eval目录下的各类evaluator文件,在项目外面的推理代码仅为for循环调用。通过对eval相关代码进行对比分析,发现针对于各类数据的测试代码处数据预处理部分有差异外其余结构都完全一致。
from torch.utils.data import DataLoader
import utils.gpu as gpu
from model.yolov3_multilevel_gdip import Yolov3
from tqdm import tqdm
from utils.tools import *
from eval.evaluator_RTTS_GDIP import Evaluator
import argparse
import os
import config.yolov3_config_RTTS as cfg
from utils.visualize import *
from tqdm import tqdm
# import os
# os.environ["CUDA_VISIBLE_DEVICES"]='0'
class Tester(object):
def __init__(self,
weight_path=None,
gpu_id=0,
img_size=544,
visiual=None,
eval=False
):
self.img_size = img_size
self.__num_class = cfg.DATA["NUM"]
self.__conf_threshold = cfg.TEST["CONF_THRESH"]
self.__nms_threshold = cfg.TEST["NMS_THRESH"]
self.__device = gpu.select_device(gpu_id)
self.__multi_scale_test = cfg.TEST["MULTI_SCALE_TEST"]
self.__flip_test = cfg.TEST["FLIP_TEST"]
self.__visiual = visiual
self.__eval = eval
self.__classes = cfg.DATA["CLASSES"]
self.__model = Yolov3(cfg).to(self.__device)
self.__load_model_weights(weight_path)
self.__evalter = Evaluator(self.__model, visiual=False)
def __load_model_weights(self, weight_path):
print("loading weight file from : {}".format(weight_path))
weight = os.path.join(weight_path)
chkpt = torch.load(weight, map_location=self.__device)
self.__model.load_state_dict(chkpt)
# self.__model.load_state_dict(chkpt['model'])
print("loading weight file is done")
del chkpt
def test(self):
if self.__visiual:
imgs = os.listdir(self.__visiual)
for v in tqdm(imgs):
path = os.path.join(self.__visiual, v)
# print("test images : {}".format(path))
img = cv2.imread(path)
assert img is not None
bboxes_prd = self.__evalter.get_bbox(img)
if bboxes_prd.shape[0] != 0:
boxes = bboxes_prd[..., :4]
class_inds = bboxes_prd[..., 5].astype(np.int32)
scores = bboxes_prd[..., 4]
visualize_boxes(image=img, boxes=boxes, labels=class_inds, probs=scores, class_labels=self.__classes)
path = os.path.join(cfg.PROJECT_PATH, "results/rtts/{}".format(v))
cv2.imwrite(path, img)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--weight_path', type=str, default='best.pt', help='weight file path')
parser.add_argument('--visiual', type=str, default='path/to/images', help='test data path or None')
parser.add_argument('--eval', action='store_true', default=True, help='eval the mAP or not')
parser.add_argument('--gpu_id', type=int, default=0, help='gpu id')
opt = parser.parse_args()
Tester( weight_path=opt.weight_path,
gpu_id=opt.gpu_id,
eval=opt.eval,
visiual=opt.visiual).test()
2、数据加载器分析
在gdip-yolo论文中提到训练时无需专属loss,理论上参照原始的dataloader即可,但是在分析代码时发现针对带雾数据、低亮度数据都有单独的加载器。为此进行源码分析。
2.1 IA_datasets_foggy.py
代码在utils\IA_datasets_foggy.py中,其关键代码如下所示,非foggy相关代码部分被博主删除了。可以看到IA_datasets_foggy中返回了img 与adv_img 图像,adv_img 为img的带雾副本图像(使用getFog函数实现)。这里奇怪的是adv_img 在论文中没有利用,却被返回了。带雾图像的概率为0.5。这里可以看出gdip-yolo使用的是在线数据增强的策略。ia-yolo:使用ASM来生成10个不同级别的雾,以包括在我们的综合训练集中的方差。我们以类似的方式从PascalVOC 2007测试集准备4952张图像(称为V_F_Ts)合成测试集。我们采用了一种混合策略,即混合使用雾和清晰的图像(以2:1的比例),即带雾概率为0.66
class VocDataset(Dataset):
def __getitem__(self, item):
img_org,adv_img_org, bboxes_org = self.__parse_annotation(self.__annotations[item])
img_org = img_org.transpose(2, 0, 1) # HWC->CHW
adv_img_org = adv_img_org.transpose(2, 0, 1) # HWC->CHW
img,adv_img, bboxes = dataAug.Mixup()(img_org,adv_img_org, bboxes_org)
del img_org, bboxes_org,adv_img_org
label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes = self.__creat_label(bboxes)
img = torch.from_numpy(img).float()
adv_img = torch.from_numpy(adv_img).float()
label_sbbox = torch.from_numpy(label_sbbox).float()
label_mbbox = torch.from_numpy(label_mbbox).float()
label_lbbox = torch.from_numpy(label_lbbox).float()
sbboxes = torch.from_numpy(sbboxes).float()
mbboxes = torch.from_numpy(mbboxes).float()
lbboxes = torch.from_numpy(lbboxes).float()
return img,adv_img, label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes
def __parse_annotation(self, annotation):
"""
Data augument.
:param annotation: Image' path and bboxes' coordinates, categories.
ex. [image_path xmin,ymin,xmax,ymax,class_ind xmin,ymin,xmax,ymax,class_ind ...]
:return: Return the enhanced image and bboxes. bbox'shape is [xmin, ymin, xmax, ymax, class_ind]
"""
anno = annotation.strip().split(' ')
img_path = anno[0]
img = cv2.imread(img_path) # H*W*C and C=BGR
assert img is not None, 'File Not Found ' + img_path
bboxes = np.array([list(map(float, box.split(','))) for box in anno[1:]])
img, bboxes = dataAug.RandomHorizontalFilp()(np.copy(img), np.copy(bboxes))
img, bboxes = dataAug.RandomCrop()(np.copy(img), np.copy(bboxes))
img, bboxes = dataAug.RandomAffine()(np.copy(img), np.copy(bboxes))
adv_img = img.copy() # H*W*C and C=BGR
if random.randint(0,2) > 0:
adv_img = normalize(adv_img)
fog_img = getFog(adv_img.copy())
fog_img = fog_img.astype(np.uint8)
adv_img = fog_img.copy()
# assert adv_img is not None, 'File Not Found ' + adv_img_path
img, bboxes = dataAug.Resize((self.img_size, self.img_size), True)(np.copy(img), np.copy(bboxes))
adv_img,_ = dataAug.Resize((self.img_size, self.img_size), True)(np.copy(adv_img), np.copy(bboxes))
return img,adv_img, bboxes
2.2 IA_datasets_lightning.py
IA_datasets_lightning的代码在utils\IA_datasets_lightning.py中,同样按照惯例删除非关键代码进行分析。IA_datasets_lightning的实现风格与上一份一样,多了一个adv_img,为原始图像的低亮度副本,基于getLightning函数实现(伽玛从1.5到5的范围内均匀采样)。图像低亮度的概率为0.5。这里可以看出gdip-yolo使用的是在线数据增强的策略。ia-yolo: 我们从ExDark中选择具有对象的PascalVOC中的图像,并应用伽玛变化来模拟低光照条件,伽玛从1.5到5的范围内均匀采样。在训练过程中,我们采用混合策略(类似于雾设置),使用黑暗和清晰图像的混合。即0.66的低亮度概率
class VocDataset(Dataset):
def __getitem__(self, item):
img_org,adv_img_org, bboxes_org = self.__parse_annotation(self.__annotations[item])
img_org = img_org.transpose(2, 0, 1) # HWC->CHW
adv_img_org = adv_img_org.transpose(2, 0, 1) # HWC->CHW
img,adv_img, bboxes = dataAug.Mixup()(img_org,adv_img_org, bboxes_org)
del img_org, bboxes_org,adv_img_org
label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes = self.__creat_label(bboxes)
img = torch.from_numpy(img).float()
adv_img = torch.from_numpy(adv_img).float()
label_sbbox = torch.from_numpy(label_sbbox).float()
label_mbbox = torch.from_numpy(label_mbbox).float()
label_lbbox = torch.from_numpy(label_lbbox).float()
sbboxes = torch.from_numpy(sbboxes).float()
mbboxes = torch.from_numpy(mbboxes).float()
lbboxes = torch.from_numpy(lbboxes).float()
return img,adv_img, label_sbbox, label_mbbox, label_lbbox, sbboxes, mbboxes, lbboxes
def __parse_annotation(self, annotation):
"""
Data augument.
:param annotation: Image' path and bboxes' coordinates, categories.
ex. [image_path xmin,ymin,xmax,ymax,class_ind xmin,ymin,xmax,ymax,class_ind ...]
:return: Return the enhanced image and bboxes. bbox'shape is [xmin, ymin, xmax, ymax, class_ind]
"""
anno = annotation.strip().split(' ')
img_path = anno[0]
img = cv2.imread(img_path) # H*W*C and C=BGR
assert img is not None, 'File Not Found ' + img_path
bboxes = np.array([list(map(float, box.split(','))) for box in anno[1:]])
img, bboxes = dataAug.RandomHorizontalFilp()(np.copy(img), np.copy(bboxes))
img, bboxes = dataAug.RandomCrop()(np.copy(img), np.copy(bboxes))
img, bboxes = dataAug.RandomAffine()(np.copy(img), np.copy(bboxes))
adv_img = img.copy() # H*W*C and C=BGR
if random.randint(0,2) > 0:
adv_img = normalize(adv_img)
l_img = getLightning(adv_img.copy())
l_img = l_img.astype(np.uint8)
adv_img = l_img.copy()
# assert adv_img is not None, 'File Not Found ' + adv_img_path
img, bboxes = dataAug.Resize((self.img_size, self.img_size), True)(np.copy(img), np.copy(bboxes))
adv_img,_ = dataAug.Resize((self.img_size, self.img_size), True)(np.copy(adv_img), np.copy(bboxes))
return img,adv_img, bboxes
2.3 getFog与getLightning函数
getFog函数实现如下所示,相比于ia-yolo的实现代码行数更多
def getFog(img):
h,w,c = img.shape
x = np.linspace(0,w-1,w)
y = np.linspace(0,h-1,h)
xx,yy = np.meshgrid(x,y)
x_c , y_c = w//2 , h//2
transmission_map = np.zeros((h,w,1))
c = np.random.uniform(0,9)
beta = 0.01*c+0.05
A = 0.5
d = -0.04 * np.sqrt((yy-y_c)**2+(xx-x_c)**2)+np.sqrt(np.maximum(h,w))
transmission_map[:,:,0] = np.exp(-beta*d)
fog_img = img*transmission_map + (1-transmission_map)* A
# fog_img = normalize(fog_img)
fog_img = fog_img*255.
fog_img = np.clip(fog_img,0,255)
return fog_img
getLightning的实现如下,基于gamma变化实现
def getLightning(img):
gamma = np.random.uniform(1.5,5)
img = img**gamma
img = img*255.
img = np.clip(img,0,255)
return img
3、GDIP-yolo关键模块
在GDIP-yolo论文中描述到,没有额外使用loss,故此所开源的loss代码与原始yolov3 loss一模一样。但是在GDIP regularizer模块中需要额外loss(与原始图像计算l1 loss与 mae loss作为正则项),但是没有找到相应实现。
3.1 GatedDIP
在gidp-yolo项目中有多个GatedDIP模块,这里以符合论文中描述的代码为参考。通过代码注释可以看到GatedDIP可以使用vgg16做编码器。这里的GatedDIP内带VisionEncoder。
import math
import torch
import torchvision
from model.vision_encoder import VisionEncoder
class GatedDIP(torch.nn.Module):
"""_summary_
Args:
torch (_type_): _description_
"""
def __init__(self,
encoder_output_dim : int = 256,
num_of_gates : int = 7):
"""_summary_
Args:
encoder_output_dim (int, optional): _description_. Defaults to 256.
num_of_gates (int, optional): _description_. Defaults to 7.
"""
super(GatedDIP,self).__init__()
print("GatedDIP with custom Encoder!!")
# Encoder Model
# self.encoder = torchvision.models.vgg16(pretrained=False)
self.encoder = VisionEncoder(encoder_output_dim=encoder_output_dim)
# Gating Module
self.gate_module = torch.nn.Sequential(torch.nn.Linear(encoder_output_dim,num_of_gates,bias=True))
# White-Balance Module
self.wb_module = torch.nn.Sequential(torch.nn.Linear(encoder_output_dim,3,bias=True))
# Gamma Module
self.gamma_module = torch.nn.Sequential(torch.nn.Linear(encoder_output_dim,1,bias=True))
# Sharpning Module
self.gaussian_blur = torchvision.transforms.GaussianBlur(13, sigma=(0.1, 5.0))
self.sharpning_module = torch.nn.Sequential(torch.nn.Linear(encoder_output_dim,1,bias=True))
# De-Fogging Module
self.defogging_module = torch.nn.Sequential(torch.nn.Linear(encoder_output_dim,1,bias=True))
# Contrast Module
self.contrast_module = torch.nn.Sequential(torch.nn.Linear(encoder_output_dim,1,bias=True))
# Contrast Module
self.tone_module = torch.nn.Sequential(torch.nn.Linear(encoder_output_dim,8,bias=True))
def rgb2lum(self,img: torch.tensor):
"""_summary_
Args:
img (torch.tensor): _description_
Returns:
_type_: _description_
"""
img = 0.27 * img[:, 0, :, :] + 0.67 * img[:, 1, :,:] + 0.06 * img[:, 2, :, :]
return img
def lerp(self ,a : int , b : int , l : torch.tensor):
return (1 - l.unsqueeze(2).unsqueeze(3)) * a + l.unsqueeze(2).unsqueeze(3) * b
def dark_channel(self,x : torch.tensor):
"""_summary_
Args:
x (torch.tensor): _description_
Returns:
_type_: _description_
"""
z = x.min(dim=1)[0].unsqueeze(1)
return z
def atmospheric_light(self,x : torch.tensor,dark : torch.tensor ,top_k : int=1000):
"""_summary_
Args:
x (torch.tensor): _description_
top_k (int, optional): _description_. Defaults to 1000.
Returns:
_type_: _description_
"""
h,w = x.shape[2],x.shape[3]
imsz = h * w
numpx = int(max(math.floor(imsz/top_k),1))
darkvec = dark.reshape(x.shape[0],imsz,1)
imvec = x.reshape(x.shape[0],3,imsz).transpose(1,2)
indices = darkvec.argsort(1)
indices = indices[:,imsz-numpx:imsz]
atmsum = torch.zeros([x.shape[0],1,3]).cuda()
# print(imvec[:,indices[0,0]].shape)
for b in range(x.shape[0]):
for ind in range(1,numpx):
atmsum[b,:,:] = atmsum[b,:,:] + imvec[b,indices[b,ind],:]
a = atmsum/numpx
a = a.squeeze(1).unsqueeze(2).unsqueeze(3)
return a
def blur(self,x : torch.tensor):
"""_summary_
Args:
x (torch.tensor): _description_
Returns:
_type_: _description_
"""
return self.gaussian_blur(x)
def defog(self,x:torch.tensor ,latent_out : torch.tensor ,fog_gate : torch.tensor):
"""Defogging module is used for removing the fog from the image using ASM
(Atmospheric Scattering Model).
I(X) = (1-T(X)) * J(X) + T(X) * A(X)
I(X) => image containing the fog.
T(X) => Transmission map of the image.
J(X) => True image Radiance.
A(X) => Atmospheric scattering factor.
Args:
x (torch.tensor): Input image I(X)
latent_out (torch.tensor): Feature representation from DIP Module.
fog_gate (torch.tensor): Gate value raning from (0. - 1.) which enables defog module.
Returns:
torch.tensor : Returns defogged image with true image radiance.
"""
omega = self.defogging_module(latent_out).unsqueeze(2).unsqueeze(3)
omega = self.tanh_range(omega,torch.tensor(0.1),torch.tensor(1.))
dark_i = self.dark_channel(x)
a = self.atmospheric_light(x,dark_i)
i = x/a
i = self.dark_channel(i)
t = 1. - (omega*i)
j = ((x-a)/(torch.maximum(t,torch.tensor(0.01))))+a
j = (j - j.min())/(j.max()-j.min())
# j = j* fog_gate.unsqueeze(1).unsqueeze(2).unsqueeze(3)
return j
def white_balance(self,x : torch.tensor,latent_out : torch.tensor ,wb_gate: torch.tensor):
""" White balance of the image is predicted using latent output of an encoder.
Args:
x (torch.tensor): Input RGB image.
latent_out (torch.tensor): Output from the last layer of an encoder.
wb_gate (torch.tensor): White-balance gate used to change the influence of color scaled image.
Returns:
torch.tensor: returns White-Balanced image.
"""
log_wb_range = 0.5
wb = self.wb_module(latent_out)
wb = torch.exp(self.tanh_range(wb,-log_wb_range,log_wb_range))
color_scaling = 1./(1e-5 + 0.27 * wb[:, 0] + 0.67 * wb[:, 1] +
0.06 * wb[:, 2])
wb = color_scaling.unsqueeze(1)*wb
wb_out = wb.unsqueeze(2).unsqueeze(3)*x
wb_out = (wb_out-wb_out.min())/(wb_out.max()-wb_out.min())
# wb_out = wb_gate.unsqueeze(1).unsqueeze(2).unsqueeze(3)*wb_out
return wb_out
def tanh01(self,x : torch.tensor):
"""_summary_
Args:
x (torch.tensor): _description_
Returns:
_type_: _description_
"""
return torch.tanh(x)*0.5+0.5
def tanh_range(self,x : torch.tensor,left : float,right : float):
"""_summary_
Args:
x (torch.tensor): _description_
left (float): _description_
right (float): _description_
Returns:
_type_: _description_
"""
return self.tanh01(x)*(right-left)+ left
def gamma_balance(self,x : torch.tensor,latent_out : torch.tensor,gamma_gate : torch.tensor):
"""_summary_
Args:
x (torch.tensor): _description_
latent_out (torch.tensor): _description_
gamma_gate (torch.tensor): _description_
Returns:
_type_: _description_
"""
log_gamma = torch.log(torch.tensor(2.5))
gamma = self.gamma_module(latent_out).unsqueeze(2).unsqueeze(3)
gamma = torch.exp(self.tanh_range(gamma,-log_gamma,log_gamma))
g = torch.pow(torch.maximum(x,torch.tensor(1e-4)),gamma)
g = (g-g.min())/(g.max()-g.min())
# g = g*gamma_gate.unsqueeze(1).unsqueeze(2).unsqueeze(3)
return g
def sharpning(self,x : torch.tensor,latent_out: torch.tensor,sharpning_gate : torch.tensor):
"""_summary_
Args:
x (torch.tensor): _description_
latent_out (torch.tensor): _description_
sharpning_gate (torch.tensor): _description_
Returns:
_type_: _description_
"""
out_x = self.blur(x)
y = self.sharpning_module(latent_out).unsqueeze(2).unsqueeze(3)
y = self.tanh_range(y,torch.tensor(0.1),torch.tensor(1.))
s = x + (y*(x-out_x))
s = (s-s.min())/(s.max()-s.min())
# s = s * (sharpning_gate.unsqueeze(1).unsqueeze(2).unsqueeze(3))
return s
def identity(self,x : torch.tensor,identity_gate : torch.tensor):
"""_summary_
Args:
x (torch.tensor): _description_
identity_gate (torch.tensor): _description_
Returns:
_type_: _description_
"""
# x = x*identity_gate.unsqueeze(1).unsqueeze(2).unsqueeze(3)
return x
def contrast(self,x : torch.tensor,latent_out : torch.tensor,contrast_gate : torch.tensor):
"""_summary_
Args:
x (torch.tensor): _description_
latent_out (torch.tensor): _description_
contrast_gate (torch.tensor): _description_
Returns:
_type_: _description_
"""
alpha = torch.tanh(self.contrast_module(latent_out))
luminance = torch.minimum(torch.maximum(self.rgb2lum(x), torch.tensor(0.0)), torch.tensor(1.0)).unsqueeze(1)
contrast_lum = -torch.cos(math.pi * luminance) * 0.5 + 0.5
contrast_image = x / (luminance + 1e-6) * contrast_lum
contrast_image = self.lerp(x, contrast_image, alpha)
contrast_image = (contrast_image-contrast_image.min())/(contrast_image.max()-contrast_image.min())
# contrast_image = contrast_image * contrast_gate.unsqueeze(1).unsqueeze(2).unsqueeze(3)
return contrast_image
def tone(self,x : torch.tensor,latent_out : torch.tensor,tone_gate : torch.tensor):
"""_summary_
Args:
x (torch.tensor): _description_
latent_out (torch.tensor): _description_
tone_gate (torch.tensor): _description_
Returns:
_type_: _description_
"""
curve_steps = 8
tone_curve = self.tone_module(latent_out).reshape(-1,1,curve_steps)
tone_curve = self.tanh_range(tone_curve,0.5, 2)
tone_curve_sum = torch.sum(tone_curve, dim=2) + 1e-30
total_image = x * 0
for i in range(curve_steps):
total_image += torch.clamp(x - 1.0 * i /curve_steps, 0, 1.0 /curve_steps) \
* tone_curve[:,:,i].unsqueeze(2).unsqueeze(3)
total_image *= curve_steps / tone_curve_sum.unsqueeze(2).unsqueeze(3)
total_image = (total_image-total_image.min())/(total_image.max()-total_image.min())
# total_image = total_image * tone_gate.unsqueeze(1).unsqueeze(2).unsqueeze(3)
return total_image
def forward(self, x : torch.Tensor):
"""_summary_
Args:
x (torch.Tensor): _description_
Returns:
_type_: _description_
"""
# latent_out = torch.nn.functional.relu_(self.encoder(x))
latent_out = self.encoder(x)
gate = self.tanh_range(self.gate_module(latent_out),0.01,1.0)
out_idx = gate.argmax(dim=1)
if out_idx == 0:
wb_out = self.white_balance(x,latent_out,gate[:,0])
return wb_out,gate
elif out_idx == 1:
gamma_out = self.gamma_balance(x,latent_out,gate[:,1])
return gamma_out,gate
elif out_idx == 2:
identity_out = self.identity(x,gate[:,2])
return identity_out,gate
elif out_idx == 3:
sharpning_out = self.sharpning(x,latent_out,gate[:,3])
return sharpning_out, gate
elif out_idx == 4:
fog_out = self.defog(x,latent_out,gate[:,4])
return fog_out,gate
elif out_idx == 5:
contrast_out = self.contrast(x,latent_out,gate[:,5])
return contrast_out, gate
else:
tone_out = self.tone(x,latent_out,gate[:,6])
return tone_out,gate
if __name__ == '__main__':
batch_size = 2
encoder_out_dim = 256
x = torch.randn(batch_size,3,448,448)
x = (x-x.min())/(x.max()-x.min())
model = GatedDIP(encoder_output_dim = encoder_out_dim)
print(model)
out,gate= model(x)
print('out shape:',out.shape)
print('gate shape:',gate.shape)
作者论文中所提出的视觉编码器实现如下所示:
import torch
class VisionEncoder(torch.nn.Module):
def __init__(self,encoder_output_dim=256):
super(VisionEncoder,self).__init__()
# conv_1
self.conv_1 = torch.nn.Sequential(torch.nn.Conv2d(3,64,kernel_size = 3 , stride = 1),
torch.nn.ReLU(True))
self.max_pool_1 = torch.nn.AvgPool2d((3,3),(2,2))
# conv_2
self.conv_2 = torch.nn.Sequential(torch.nn.Conv2d(64,128,kernel_size = 3 , stride = 1),
torch.nn.ReLU(True))
self.max_pool_2 = torch.nn.AvgPool2d((3,3),(2,2))
# conv_3
self.conv_3 = torch.nn.Sequential(torch.nn.Conv2d(128,256,kernel_size = 3 , stride = 1),
torch.nn.ReLU(True))
self.max_pool_3 = torch.nn.AvgPool2d((3,3),(2,2))
# conv_4
self.conv_4 = torch.nn.Sequential(torch.nn.Conv2d(256,512,kernel_size = 3 , stride = 1),
torch.nn.ReLU(True))
self.max_pool_4 = torch.nn.AvgPool2d((3,3),(2,2))
# conv_5
self.conv_5 = torch.nn.Sequential(torch.nn.Conv2d(512,1024,kernel_size = 3 , stride = 1),
torch.nn.ReLU(True))
self.adp_pool_5 = torch.nn.AdaptiveAvgPool2d((1,1))
self.linear_proj_5 = torch.nn.Sequential(torch.nn.Linear(1024,encoder_output_dim),
torch.nn.ReLU(True))
def forward(self,x):
out_x = self.conv_1(x)
max_pool_1 = self.max_pool_1(out_x)
out_x = self.conv_2(max_pool_1)
max_pool_2 = self.max_pool_2(out_x)
out_x = self.conv_3(max_pool_2)
max_pool_3 = self.max_pool_3(out_x)
out_x = self.conv_4(max_pool_3)
max_pool_4 = self.max_pool_4(out_x)
out_x = self.conv_5(max_pool_4)
adp_pool_5 = self.adp_pool_5(out_x)
linear_proj_5 = self.linear_proj_5(adp_pool_5.view(adp_pool_5.shape[0],-1))
return linear_proj_5
if __name__ == '__main__':
img = torch.randn(4,3,448,448).cuda()
encoder = VisionEncoder(encoder_output_dim=256).cuda()
print('output shape:',encoder(img).shape) # output should be [4,256]
gdip模块的用法如下所示,可以看到兼容原始yolo框架代码,但多返回了一个增强后的图像与各个DIP操作的权重。
import torch
from model.gdip_model import GatedDIP
from model.yolov3 import Yolov3
class Yolov3GatedDIP(torch.nn.Module):
def __init__(self):
super(Yolov3GatedDIP,self).__init__()
self.gated_dip = GatedDIP(256)
self.yolov3 = Yolov3()
#self.yolov3.load_darknet_weights(weights_path)
def forward(self,x):
out_x,gates = self.gated_dip(x)
p,p_d = self.yolov3(out_x)
return out_x,gates,p,p_d
3.2 MultiLevelGDIP
代码在model\mgdip.py中。在MultiLevelGDIP中又单独实现了gdip,这里可以看到gdip-yolo项目代码比较混乱。在这里的GatedDIP中,没有内置视觉编码器,而是在MultiLevelGDIP中内置视觉编码器,将GatedDIP作为MultiLevelGDIP中的一个部件。同时,mgdip相关的VisionEncoder与gdip中的返回值不一样,为了实现多尺度VisionEncoder返回的是一个dict,其中包含了各个尺度的特征图。
class GatedDIP(torch.nn.Module):
'''这里删除了与上一份代码类似的部分'''
def forward(self,x,linear_proj):
gate = self.tanh_range(self.gate_module(linear_proj),0.01,1.0)
wb_out = self.white_balance(x,linear_proj,gate[:,0])
gamma_out = self.gamma_balance(x,linear_proj,gate[:,1])
identity_out = self.identity(x,gate[:,2])
sharpning_out = self.sharpning(x,linear_proj,gate[:,3])
fog_out = self.defog(x,linear_proj,gate[:,4])
contrast_out = self.contrast(x,linear_proj,gate[:,5])
tone_out = self.tone(x,linear_proj,gate[:,6])
x = wb_out + gamma_out + fog_out + sharpning_out + contrast_out + tone_out + identity_out
x = (x-x.min())/(x.max()-x.min())
return x,gate
class MultiLevelGDIP(torch.nn.Module):
def __init__(self,
encoder_output_dim : int = 256,
num_of_gates : int = 7):
super(MultiLevelGDIP,self).__init__()
self.vision_encoder = VisionEncoder(encoder_output_dim,base_channel=32)
self.gdip1 = GatedDIP(encoder_output_dim,num_of_gates)
self.gdip2 = GatedDIP(encoder_output_dim,num_of_gates)
self.gdip3 = GatedDIP(encoder_output_dim,num_of_gates)
self.gdip4 = GatedDIP(encoder_output_dim,num_of_gates)
self.gdip5 = GatedDIP(encoder_output_dim,num_of_gates)
self.gdip6 = GatedDIP(encoder_output_dim,num_of_gates)
def forward(self, x : torch.Tensor):
"""_summary_
Args:
x (torch.Tensor): _description_
Returns:
_type_: _description_
"""
out_image = list()
gates_list = list()
output_dict = self.vision_encoder(x)
x,gate_6 = self.gdip6(x,output_dict['linear_proj_6'])
out_image.append(x)
gates_list.append(gate_6)
x,gate_5 = self.gdip5(x,output_dict['linear_proj_5'])
out_image.append(x)
gates_list.append(gate_5)
x,gate_4 = self.gdip4(x,output_dict['linear_proj_4'])
out_image.append(x)
gates_list.append(gate_4)
x,gate_3 = self.gdip3(x,output_dict['linear_proj_3'])
out_image.append(x)
gates_list.append(gate_3)
x,gate_2 = self.gdip2(x,output_dict['linear_proj_2'])
out_image.append(x)
gates_list.append(gate_2)
x,gate_1 = self.gdip1(x,output_dict['linear_proj_1'])
out_image.append(x)
gates_list.append(gate_1)
return x,out_image,gates_list
其使用代码如下所示:
import torch
from model.mgdip import MultiLevelGDIP
from model.yolov3 import Yolov3
class Yolov3MGatedDIP(torch.nn.Module):
def __init__(self):
super(Yolov3MGatedDIP,self).__init__()
self.mgdip = MultiLevelGDIP(256,7)
self.yolov3 = Yolov3()
def forward(self,x):
out_x,_,gates_list = self.mgdip(x)
p,p_d = self.yolov3(out_x)
return out_x,gates_list,p,p_d
3.3 GDIP regularizer
代码在model\yolov3_multilevel_gdip.py,这里是mgdip regularizer模块。同样与上一份代码中的MultiLevelGDIP有所差别,这里的MultiLevelGDIP没有内置视觉编码器,而是获取Yolov3 backbone的3个尺度的输出+ 原始输入作为特征图输入MultiLevelGDIP(即使用Yolov3 backbone作为特征提取器)。其关键代码如下所示,同时发现MultiLevelGDIP没有使用预训练模型,而论文中提到MultiLevelGDIP可以作为正则化器。正则化器的loss通过训练后使Yolov3 backbone提取的特征与MultiLevelGDIP提取的一样。在这里MultiLevelGDIP参与训练,但其输出的值又不参与前向传播。
class Yolov3(nn.Module):
"""
Note : int the __init__(), to define the modules should be in order, because of the weight file is order
"""
def __init__(self, cfg, init_weights=True):
super(Yolov3, self).__init__()
self.__anchors = torch.FloatTensor(cfg.MODEL["ANCHORS"])
self.__strides = torch.FloatTensor(cfg.MODEL["STRIDES"])
self.__nC = cfg.DATA["NUM"]
self.__out_channel = cfg.MODEL["ANCHORS_PER_SCLAE"] * (self.__nC + 5)
self.__backnone = Darknet53()
self.__fpn = FPN_YOLOV3(fileters_in=[1024, 512, 256],
fileters_out=[self.__out_channel, self.__out_channel, self.__out_channel])
# small
self.__head_s = Yolo_head(nC=self.__nC, anchors=self.__anchors[0], stride=self.__strides[0])
# medium
self.__head_m = Yolo_head(nC=self.__nC, anchors=self.__anchors[1], stride=self.__strides[1])
# large
self.__head_l = Yolo_head(nC=self.__nC, anchors=self.__anchors[2], stride=self.__strides[2])
# multilevel gdip
self.__multilevel_gdip = MultiLevelGDIP()
if init_weights:
self.__init_weights()
def forward(self, x):
out = []
x_s, x_m, x_l = self.__backnone(x)
out_x,img_list,gates_list = self.__multilevel_gdip(x,x_s,x_m,x_l)
x_s, x_m, x_l = self.__fpn(x_l, x_m, x_s)
out.append(self.__head_s(x_s))
out.append(self.__head_m(x_m))
out.append(self.__head_l(x_l))
if self.training:
p, p_d = list(zip(*out))
return out_x,gates_list[-1],p, p_d # smalll, medium, large
else:
p, p_d = list(zip(*out))
return out_x,gates_list[-1],p, torch.cat(p_d, 0)