一、什么是网络爬虫
网络爬虫,也可以叫做网络数据采集更容易理解。它是指通过编程向网络服务器(web)请求数据(HTML表单),然后解析HTML,提取出自己想要的数据。 它包括了根据url获取HTML数据、解析HTML,获取目标信息、存储数据几个步骤;过程中可能会涉及到数据库、网络服务器、HTTP协议、HTML、数据科学、网络安全、图像处理等非常多的内容。是不是觉得太复杂了,不用担心,对于初学者来说,并不需要全部掌握。
二、为什么需要爬虫
经常会遇到这一类网页,登录进去后,可以查看到很多有用的数据,但是网页无导出功能,想要下载这部分数据,通常只能手动一点一点去复制,这种方式不仅复制的时候,再粘贴到表格中格式会混乱,要花时间去慢慢调整;其次如果有很多页的数据,还得一页一页翻页复制,其麻烦程度 可想而知。。。
此时,了解一下python的爬虫,动手write一下,释放生产力。关于爬虫有很多使用的场景,也有很多可以去使用的模块,可以根据具体系统架构和爬取内容情况来适配使用。
三、测试用例
这里以自己的一个测试系统为例,目标链接有个主机信息的表,但是前提需要登录后才能访问,并且也存在分页的情况,要求是后台获取的内容直接以excel形式保存展示。
四、测试过程
这个简单实例里,主要使用到3个基础模块:
requests:构建请求的相关动作,例如传递登录信息,调测目标网址,保存登录cookie等内容
BeautifulSoup:对获取到html文本内容进行解析,查找里面的表格内容
pandas:对解析后内容,用来存储到目标excel
通常在爬取具体内容数据时,先可以通过F12,查看下网页的源代码,了解下网页的结构,从而设计自己的脚本,上述例子的网页,只是个简单html内容页,有基础的表格属性内容,例如table、tr元素,所以只需要针对这些属性内容,直接匹配获取相应的值即可。
直接上脚本,有相关注释内容,如果有类似场景的可直接用
import requests
from bs4 import BeautifulSoup
import pandas as pd
#构建缓存登录的session
url = 'http://XXX.XXX.XXX.XXX:5000/auth/login'
username = 'XXXX'
password = 'XXXX'
# 创建一个session,作用会自动保存cookie
session = requests.session()
data = {
'username': username,
'password': password
}
# 使用session发起post请求来获取登录后的cookie,cookie已经存在session中
response = session.post(url = url,data=data)
#提前创建个空列表来存储数据,方便后面写入excel
data = []
###构建目标网页的请求,存在分页的情况,写个循环
url = 'http://192.168.163.134:5000/query/inventory?page={}'
for i in range(1, 5):
url2 = url.format(i)
html_content = session.get(url=url2).text
#print(html_content)
#对获取到html使用BeautifulSoup库解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
# 查找解析后表格元素
table = soup.find('table')
# 获取所有行
rows = table.find_all('tr')
# 遍历所有行,并将每行的所有单元格的文本添加到data列表中
for row in rows:
cells = row.find_all('td')
if len(cells) > 1:
row_data = [cell.text.strip() for cell in cells]
data.append({
"主机IP": row_data[0],
"系统名称": row_data[1],
"系统类型": row_data[2],
"主机分组": row_data[3],
"纳管情况": row_data[4],
"纳管时间": row_data[5],
})
# 输出列表
#print(data)
# 使用 pandas 将列表转换成 DataFrame
df = pd.DataFrame(data, columns=['主机IP', '系统名称', '系统类型', '主机分组', '纳管情况', '纳管时间'])
# 使用 to_excel 函数将 DataFrame 保存为 excel 文件
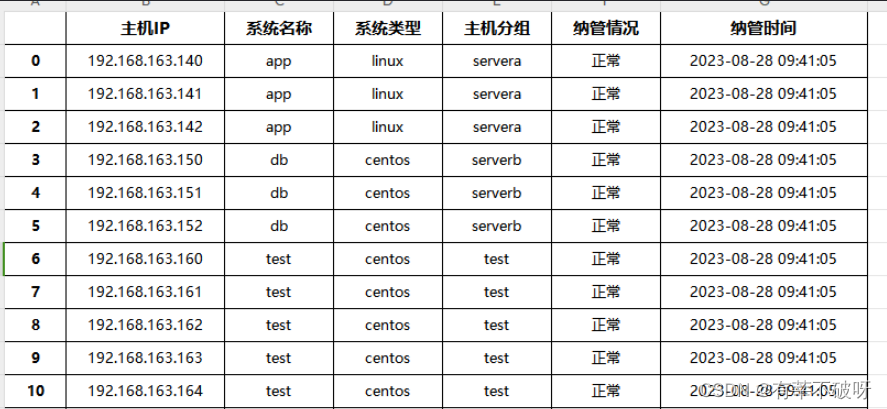
df.to_excel("data.xlsx")五、测试效果
写好的代码,以后随时需要导出数据,执行下py脚本即可,大工告成~
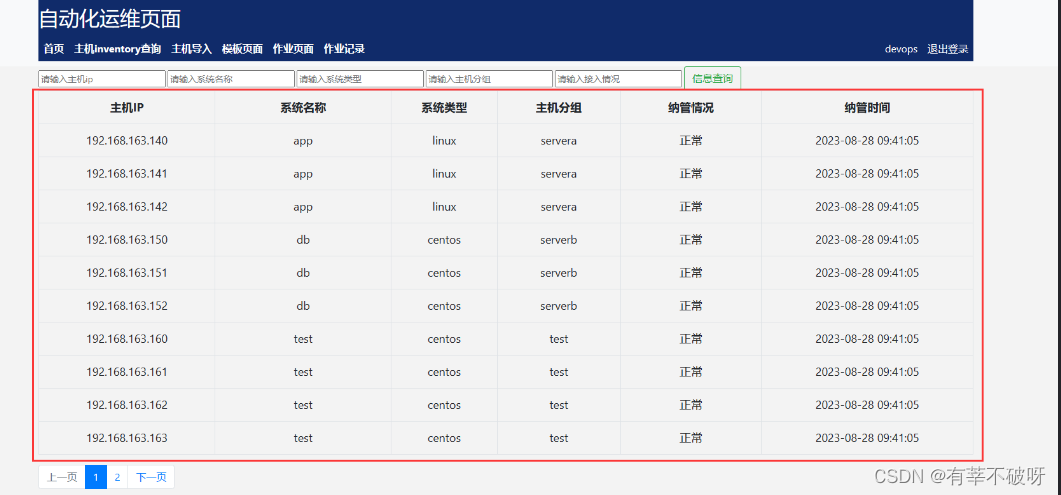
输出的表格效果如下,对比网页展示的内容,完全get:
六、应对反爬几点建议
在写爬虫时,经常会被目标网址禁止爬取内容,那么在写爬虫防止被封有以下几点建议:
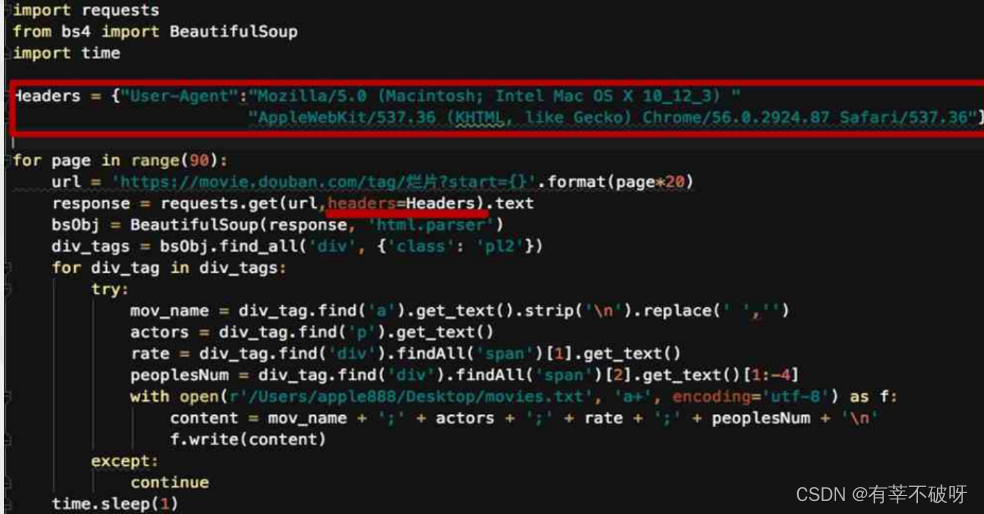
1、伪装请求报头
例如伪装成浏览器访问
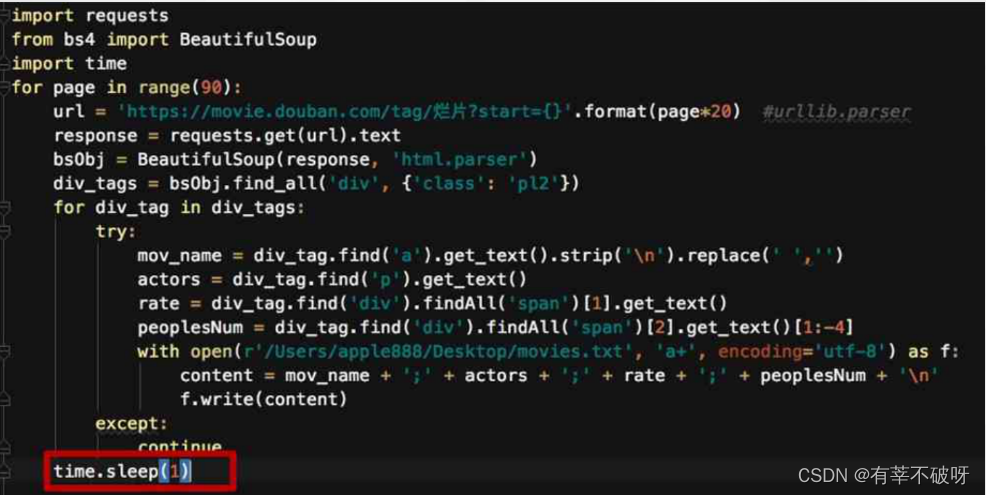
2、减轻访问频率,速度
例如控制访问频率,加入time.sleep参数
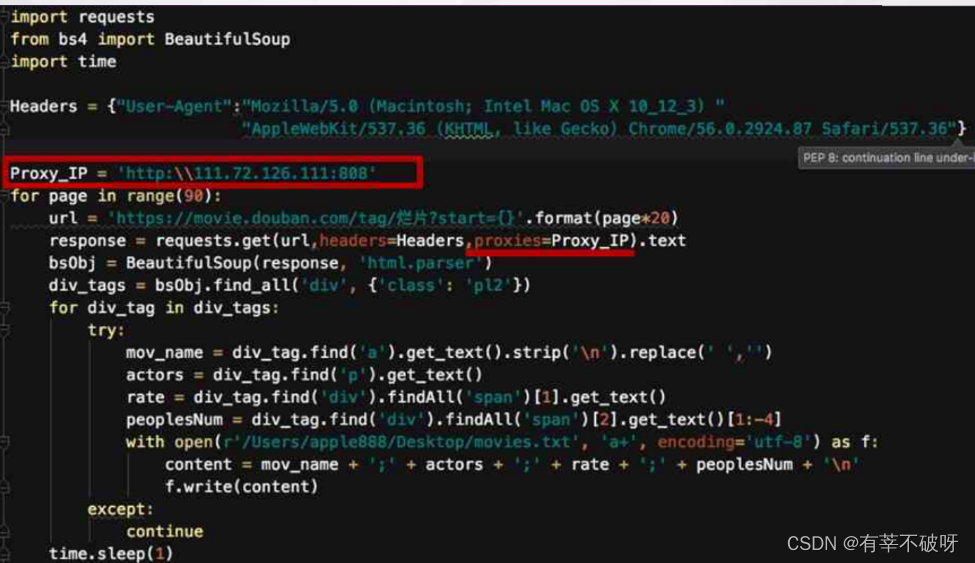
3、使用代理IP
例如加入proxy代理地址,掩藏真实访问地址