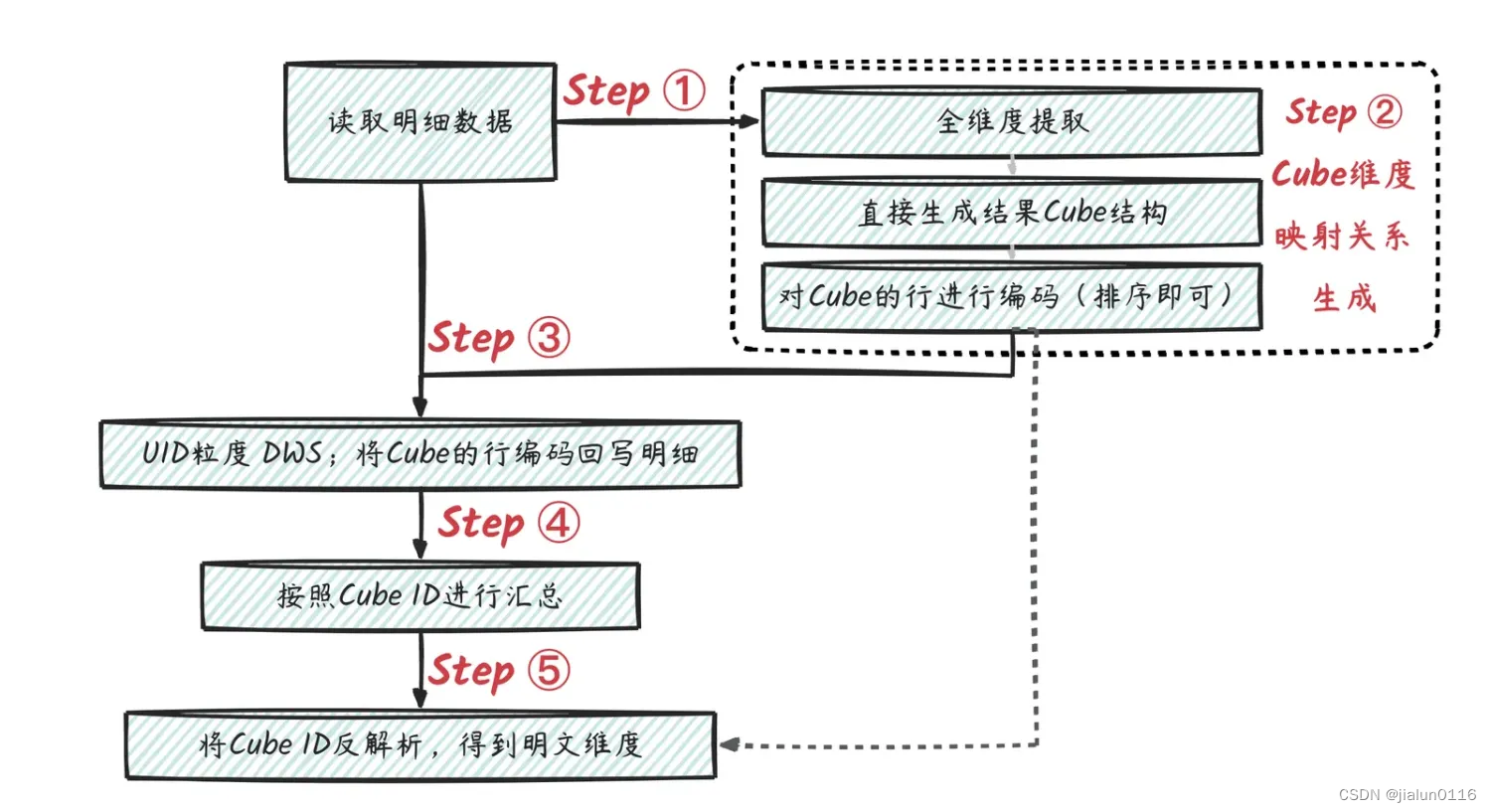
一、概述
将相似的样本自动归到一个类别中,不同的相似度计算方法,会得到不同的聚类结果,常用欧式距离法;聚类算法的目的是在没有先验知识的情况下,自动发现数据集中的内在结构和模式。是无监督学习算法
二、分类
根据聚类颗粒度:细聚类、粗聚类
根据实现方法
K-means:按照 质心 分类,主要介绍K-means,通用、普遍;
层次聚类:对数据进行逐层划分,直到达到聚类的类别个数;
DBSCAN聚类:一种基于 密度 的聚类算法;
谱聚类:是一种基于 图论 的聚类算法
三、KMeans方法
实现流程
1 、事先确定常数K ,常数K意味着最终的聚类类别数
2、随机选择 K 个样本点作为初始聚类中心
3、计算每个样本到 K 个中心的距离,选择最近的聚类中心点作为标记类别
4、根据每个类别中的样本点,重新计算出新的聚类中心点(平均值),如果计算得出的新中心点与原中心点一样则停止聚类,否则重新进行第 2 步过程,直到聚类中心不再变化
# 导包
from sklearn.cluster import KMeans
sklearn.cluster.KMeans ( n_clusters = 8 )
# 方法
estimator.fit_predict(x)导包:from sklearn.cluster import KMeans
sklearn.cluster.KMeans ( n_clusters = 8 )
参数:n_clusters:开始的聚类中心数量(整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数
方法:estimator.fit_predict(x)
评估:silhouette_score(x, y_pred) # 评估 聚类效果,数值越大越好
案例
1 导包
# 1.导入工具包
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score # 计算SC系数2 创建数据集
# 2.创建数据集 1000个样本,每个样本2个特征 4个质心蔟数据标准差[0.4, 0.2, 0.2, 0.2]
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1,-1], [0,0], [1,1], [2,2]],cluster_std = [0.4, 0.2, 0.2, 0.2], random_state=22)
plt.figure()
plt.scatter(x[:, 0], x[:, 1], marker='o')
plt.show() n_samples:样本数
n_features:特征数
cluster_std:质心蔟数据标准差
3 实例化Kmeans模型并预测,并展示聚类效果
# 3 使用k-means进行聚类, 并使用CH方法评估
y_pred = KMeans(n_clusters=3, random_state=22).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=y_pred)
plt.show()4 评估聚类效果好坏
# 4 模型评估
print(silhouette_score(x, y_pred))
# 评估方法2
from sklearn.metrics import calinski_harabasz_score
calinski_harabasz_score(x, y_pred)四、模型评估方法
1、误差平方和(SSE)
The sum of squares due to error
SSE 越小,表示数据点越接近它们的中心,聚类效果越好,主要考量:簇内聚程度
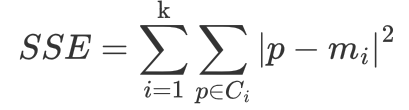
参数:Ci 表示簇
k 表示聚类中心的个数
p 表示某个簇内的样本
m 表示质心点
代码展示
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics import calinski_harabasz_score
def dm01_SSE误差平方和求模型参数():
sse_list = []
# 产生数据random_state=22固定好
x, y = make_blobs(n_samples=1000, n_features=2, centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=22)
for clu_num in range(1, 100):
my_kmeans = KMeans(n_clusters=clu_num,max_iter=100, random_state=0)
my_kmeans.fit(x)
sse_list.append(my_kmeans.inertia_ ) # 获取sse的值
plt.figure(figsize=(18, 8), dpi=100)
plt.xticks(range(0, 100, 3), labels=range(0, 100, 3))
plt.grid()
plt.title('sse')
plt.plot(range(1, 100), sse_list, 'or-')
plt.show()
通过图像可观察到 n_clusters = 4时,sse开始下降趋缓,最佳值为4
2、“肘”方法 - K值确定
Elbow method
通过 SSE 确定 n_clusters 的值
1 对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算 SSE
2 SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。
3 SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
4 在决定什么时候停止训练时,肘方法同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。

3、轮廓系数法(SC)
Silhouette Coefficient
考虑簇内的内聚程度(Cohesion),簇外的分离程度(Separation)
计算过程
1 计算每一个样本 i 到同簇内其他样本的平均距离 ai,该值越小,说明簇内的相似程度越大
2 计算每一个样本 i 到最近簇 j 内的所有样本的平均距离 bij,该值越大,说明该样本越不属于其他簇 j
根据下面公式计算该样本的轮廓系数:
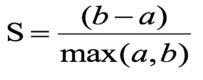
a:样本 i 到 簇内其他样本的平均距离
b:样本 i 到其他簇间的距离平均值的 最小值
3 计算所有样本的平均轮廓系数
4 轮廓系数的范围为:[-1, 1],SC值越大聚类效果越好
代码展示
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score
def dm02_轮廓系数SC():
tmp_list = []
# 产生数据random_state=22固定好
x, y = make_blobs(n_samples=1000, n_features=2,centers=[[-1, -1], [0, 0], [1, 1], [2, 2]],cluster_std=[0.4, 0.2, 0.2, 0.2], random_state=22)
for clu_num in range(2, 100):
my_kmeans = KMeans(n_clusters=clu_num,max_iter=100, random_state=0)
my_kmeans.fit(x)
ret = my_kmeans.predict(x)
tmp_list.append(silhouette_score(x, ret)) # sc
plt.figure(figsize=(18, 8), dpi=100)
plt.xticks(range(0, 100, 3), labels=range(0, 100, 3))
plt.grid()
plt.title(‘sse’)
plt.plot(range(2, 100), tmp_list, ‘ob-’)
plt.show()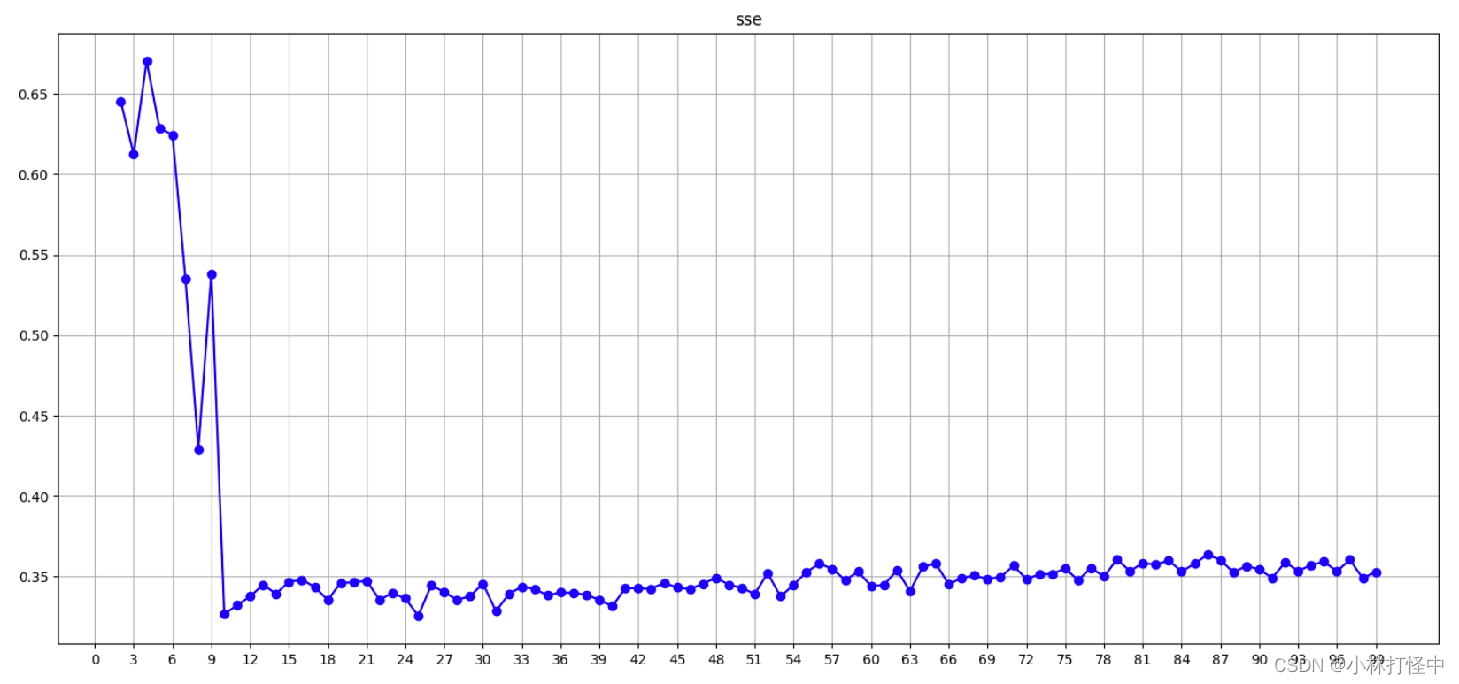
通过图像可观察到 n_clusters=4 取到最大值; 最佳值为 4
五、案例:顾客数据聚类分析
已知:客户性别、年龄、年收入、消费指数
需求:对客户进行分析,找到业务突破口,寻找黄金客户
肘方法、sh系数代码实现:
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score
# 聚类分析用户分群
def dm01_聚类分析用户群():
dataset = pd.read_csv('data/customers.csv')
dataset.info()
print('dataset-->\n', dataset)
X = dataset.iloc[:, [3, 4]]
print('X-->\n', X)
mysse = []
mysscore = []
# 评估聚类个数
for i in range(2, 11):
mykeans = KMeans(n_clusters=i)
mykeans.fit(X)
mysse.append(mykeans.inertia_) # inertia 簇内误差平方和
ret = mykeans.predict(X)
mysscore.append(silhouette_score(X, ret)) # sc系数 聚类需要1个以上的类别
plt.plot(range(2, 11), mysse)
plt.title('the elbow method')
plt.xlabel('number of clusters')
plt.ylabel('mysse')
plt.grid()
plt.show()
plt.title('sh')
plt.plot(range(2, 11), mysscore)
plt.grid(True)
plt.show()效果分析:
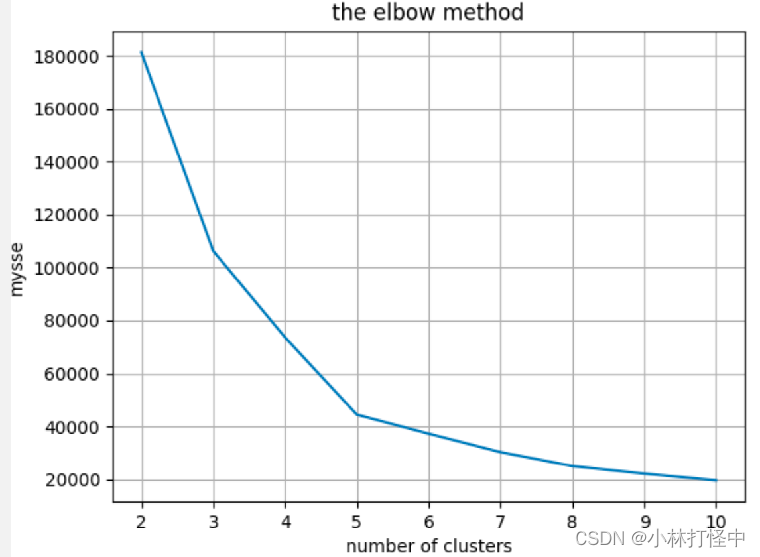

通过肘方法、sh系数都可以看出,聚成5类效果最好
客户分群代码实现:
def dm02_聚类分析用户群():
dataset = pd.read_csv('data/customers.csv')
X = dataset.iloc[:, [3, 4]]
mykeans = KMeans(n_clusters=5)
mykeans.fit(X)
y_kmeans = mykeans.predict(X)
# 把类别是0的, 第0列数据,第1列数据, 作为x/y, 传给plt.scatter函数
plt.scatter(X.values[y_kmeans == 0, 0],X.values[y_kmeans == 0, 1], s=100, c='red', label='Standard')
# 把类别是1的, 第0列数据,第1列数据, 作为x/y, 传给plt.scatter函数
plt.scatter(X.values[y_kmeans == 1, 0],X.values[y_kmeans == 1, 1], s=100, c='blue', label='Traditional')
# 把类别是2的, 第0列数据,第1列数据, 作为x/y, 传给plt.scatter函数
plt.scatter(X.values[y_kmeans == 2, 0],X.values[y_kmeans == 2, 1], s=100, c='green', label='Normal')
plt.scatter(X.values[y_kmeans == 3, 0],X.values[y_kmeans == 3, 1], s=100, c='cyan', label='Youth')
plt.scatter(X.values[y_kmeans == 4, 0],X.values[y_kmeans == 4, 1], s=100, c='magenta', label='TA')
plt.scatter(mykeans.cluster_centers_[:, 0],mykeans.cluster_centers_[:, 1], s=300, c='black', label='Centroids’)
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()
客户分群效果展示:
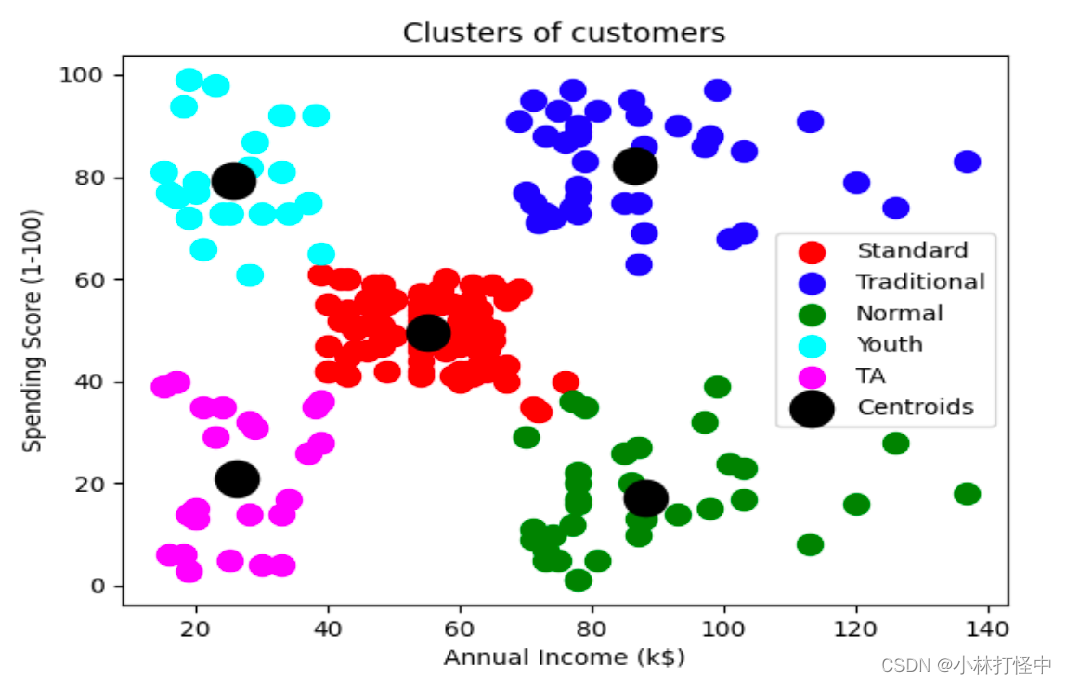
从图中可以看出,聚成5类,右上角属于挣的多,消费也多的黄金客户群