目的:使用字母数字的二值图像,进行识别:
整体思路:
1)对图像进行预处理;
对收集的单个字符进行二值化,进行数据均衡,并且将所有的字符图片直接resize为20*20(有过进行等比例缩放后padding为20*20,最终算法效果较差)
2)提取hog特征
3)进行svm(lightGBM)分类
查阅的资料:
使用python代码,提取相关的hog特征:
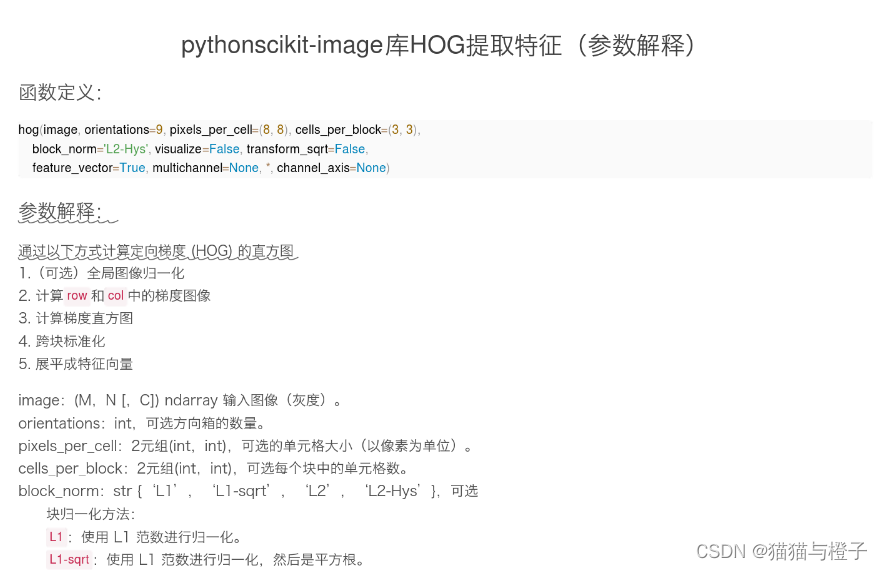

参数设置:pythonscikit-image库HOG提取特征(参数解释) - 百度文库
本人使用的hog特征提取代码:
def get_hog():
""" Get hog descriptor """
# cv2.HOGDescriptor(winSize, blockSize, blockStride, cellSize, nbins, derivAperture, winSigma, histogramNormType,
# L2HysThreshold, gammaCorrection, nlevels, signedGradient)
hog = cv2.HOGDescriptor((SZ, SZ), (8, 8), (4, 4), (8, 8), 9, 1, -1, 0, 0.2, 1, 64, True)
print("get descriptor size: {}".format(hog.getDescriptorSize()))
return hog
def get_data(train_data_path, train_dir, result_num):
'''
加载训练样本
:param train_data_path:
:param result_num:
:return:
'''
hog = get_hog()
# 识别中文
# ------加载训练样本
chars_train = []
chars_train_label = []
files = get_file_list(train_data_path) # 获取所有图片的绝对路径
files2 = get_file_list(train_dir) # 获取所有图片的绝对路径
files += files2
for filepath in files:
digit_img = cv2.imread(filepath)
digit_img = cv2.cvtColor(digit_img, cv2.COLOR_BGR2GRAY)
chars_train.append(hog.compute(deskew(digit_img)))
# chars_train.append(preprocess_hog(deskew(digit_img)))
classTag = result_num[filepath.split("/")[-2]] # 得到 类标签(数字)
chars_train_label.append(classTag)
# chars_train = np.squeeze(chars_train)
chars_train = np.squeeze(np.float32(chars_train))
chars_label = np.array(chars_train_label)
return chars_train, chars_label使用SVM进行分类的代码:
class SVM(StatModel):
def __init__(self, C = 1, gamma = 0.5):
self.model = cv2.ml.SVM_create()
self.model.setGamma(gamma)
self.model.setC(C)
self.model.setKernel(cv2.ml.SVM_RBF)
# self.model.setKernel(cv2.ml.SVM_LINEAR)
self.model.setType(cv2.ml.SVM_C_SVC)
# 定义算法终止条件
# self.model.setTermCriteria((cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 500, 1e-6)) #迭代次数超过阈值max_iter时停止,#cv2.TERM_CRITERIA_COUNT |
# train svm
def train(self, samples, responses):
self.model.train(samples, cv2.ml.ROW_SAMPLE, responses)
def predict(self, chars_test):
r = self.model.predict(chars_test)
# result = r[1].ravel()
return r
# inference
def predict_svm(self, test_imgList, tcName, model_path, c, g):
self.model = SVM(C=c, gamma=g)
if os.path.exists(model_path):
self.model.load(model_path)
# cv2.ml.SVM_load("svmtest.mat")
# self.model = joblib.load(model_path)
else:
print('model_path is missing!')
allErrCount = 0
class_num = 37
ErrCount = np.zeros(class_num, int)
TrueCount = np.zeros(class_num, int)
for chars_test, chars_test_label, index in test_imgList:
# print(chars_test.shape, index)
first = time.time()
r = self.predict(chars_test)
end = time.time()
print("Testing one pic spent {:.6f}s.".format((end - first)/len(chars_test)))
result = r[1].ravel()
# for x in result:
# if x != index:
# print('pred error:', result_index[index], result_index[x])
errCount = len([x for x in result if x != index])
ErrCount[index] = errCount
TrueCount[index] = len(chars_test_label) - errCount
print("errorCount: {}.".format(errCount), "trueCount: {}.".format(len(chars_test_label) - errCount))
allErrCount += errCount
# tet = time.time()
# print("Testing All class total spent {:.6f}s.".format(tet - tst))
print("All error Count is: {}.".format(allErrCount))
print("number", " TrueCount", " ErrCount")
mean_acc = 0
num_div = 0
for tcn in tcName:
# tcn = int(tcn)
# if all_num > 0:
num_div += 1
index = result_num[tcn]
all_num = (TrueCount[index] + ErrCount[index])
acc = TrueCount[index] /all_num
mean_acc += acc
print(tcn, " ", TrueCount[index], " ", ErrCount[index], 'acc:', acc)
mean_acc /= class_num
return mean_acc
# plt.figure(figsize=(12, 6))
# x = list(range(37))
# plt.plot(x, TrueCount, color='blue', label="TrueCount") # 将正确的数量设置为蓝色
# plt.plot(x, ErrCount, color='red', label="ErrCount") # 将错误的数量为红色
# plt.legend(loc='best') # 显示图例的位置,这里为右下方
# plt.title('Projects')
# plt.xlabel('number') # x轴标签
# plt.ylabel('count') # y轴标签
# plt.xticks(np.arange(37), list(tcName))
# plt.show()
# inference
def train_svm(self, chars_train, chars_label, c, g):
#识别英文字母和数字
self.model = SVM(C=c, gamma=g)
self.model.train(chars_train, chars_label)
# joblib.dump(self.model.model, path)
return self.model
def save_trainmodel(self, path):
if not os.path.exists(path):
self.model.save(path)
# joblib.dump(self.model, path)
# if not os.path.exists("./train_dat/svmchinese.dat"):
# self.modelchinese.save("./train_dat/svmchinese.dat")调用svm分类,并且进行最优参数查找:
best_score = 0
best_parameters = {'gamma': 0.001, 'C': 0.001}
for g in [0.001, 0.01, 0.1, 1, 10, 100]:
for c in [0.001, 0.01, 0.1, 1, 10, 100]:
# if g in [100]:
# continue
if g == 0.01 and c == 0.001:
continue
model_path = os.path.join(model_path_save, 'svm_hog20221123_'+'_g_' +str(g)+'_c_' +str(c)+'.dat')
svm_model = SVM(C=c, gamma=g) #12.5
svm_model.train_svm(chars_train, chars_label, c, g)
svm_model.save_trainmodel(model_path)
acc = svm_model.predict_svm(test_imgList, tcName, model_path, c, g)
print('c:', c, 'gamma:', g, 'MEANacc:', acc)
print('============================================')
if acc > best_score: # 找到表现最好的参数
best_score = acc
best_parameters = {'gamma': g, 'C': c}
print('best_score:', best_score, 'best_parameters:', best_parameters)使用lightGBM分类
import lightgbm as lgb
import datetime
import sklearn
# import warnings
# warnings.filterwarnings('ignore')
# folds = KFold(n_splits=5, shuffle=True, random_state=1996)
# 模型参数设定
model = lgb.LGBMClassifier(boosting_type='gbdt' #'dart' #'goss' #学习器类型,通常选取gbdt
, class_weight=None
, colsample_bytree=1.0
, importance_type='split'
, learning_rate=0.1
, max_depth=5 # * 指定了每棵树的最大深度或者它能够生长的层数上限,数据量小,4-10都无所谓。
, min_child_samples=20
, min_child_weight=0.001
, min_split_gain=0.0
, n_estimators=200#迭代次数
, n_jobs=2
, num_leaves=31 # * 用来设置组成每棵树的叶子的数量,由于lightGBM是leaves_wise生长,官方说法是要小于2^max_depth
, objective='multi:softmax'
, random_state=None
, reg_alpha=0.0
, reg_lambda=0.0
, silent=True
, subsample=1.0
, subsample_for_bin=255)
'''
n_estimators:拟合的树的棵树,相当于训练轮数
n_jobs:并行运行多线程核心数
'''
# model.fit(pca_feats, chars_label, eval_set=[(pca_feats, chars_label), (test_imgs, test_labels)],
# eval_metric=['logloss'], verbose=True) #
model.fit(chars_train, chars_label, eval_set=[(chars_train, chars_label), (test_imgs, test_labels)],
eval_metric=['logloss'], early_stopping_rounds=20, verbose=True) # early_stopping_rounds=20,
# lgb.LGBMClassifier(n_estimators=200, n_jobs=1, objective='multi:softmax')
model_path = "/home/fuxueping/4tdisk/data/certificate_reader/传统算法处理mrz/GBM_model/model.txt"
# model.booster_.savemodel(model_path)
joblib.dump(model, model_path)
start = time.time()
# model = joblib.load(model_path)
pred_y_test = model.predict(test_imgs)数据样例:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
最终未解决的问题:O和0无法分类正确,错误率很高;












![[C语言]和我一起来认识“整型在内存中的存储”](https://img-blog.csdnimg.cn/dad17bcec011401f859f7433b9a728c8.png)