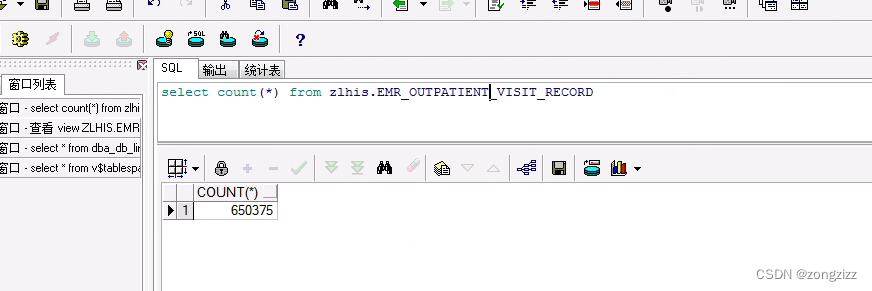
Buffer类简介
Buffer类是一个抽象类,对应于Java的主要数据类型,在NIO中有8种缓冲区类,分别如下: ByteBuffer、 CharBuffer、 DoubleBuffer、 FloatBuffer、 IntBuffer、 LongBuffer、 ShortBuffer、MappedByteBuffer。 本文以它的子类ByteBuffer类为例子讲解。ByteBuffer子类就拥有一个byte[]类型的数组成员final byte[] hb,作为自己的读写缓冲区,数组的元素类型与Buffer子类的操作类型相互对应。Buffer类及其子类在NIO中的地位非常重要,接下来将介绍Buffer类的属性及其重要的方法。
Buffer 重要属性
Buffer类额外提供了一些重要的属性,其中有以下三个重要的成员属性:
capacity(容量),缓存数组的大小,一旦初始化就不能改变了,例如ByteBuffer创建实例时capacity为10那么只能写入10个Byte类型数据,同理如果是DoubleBuffer实例capacity为10那么只能写入10个Double类型数据。position(读写位置),读写指针表示当前读取或者写入的数组下标位置,初始位置为0,当切换读写模式时其值会进行相应的调整,最大可读写位置为 limit-1。
+limit(读写的限制),表示可以写入或者读取的最大上限,其属性值的具体含义,也与缓冲区的读写模式有关, 在写入模式下, limit属性值的含义为可以写入的数据最大上限。在刚进入到写入模式时, limit的值会被设置成缓冲区的capacity容量值,表示可以一直将缓冲区的容量写满。在读取模式下, limit的值含义为最多能从缓冲区中读取到多少数据。mark(读写位置的临时备份),记住某个位置mark=position,再调用 reset()可以让 position 恢复到 mark 标记的位置,即 position=mark。通过mark和reset()可以对缓冲区中的数据循环重复读取某片段。
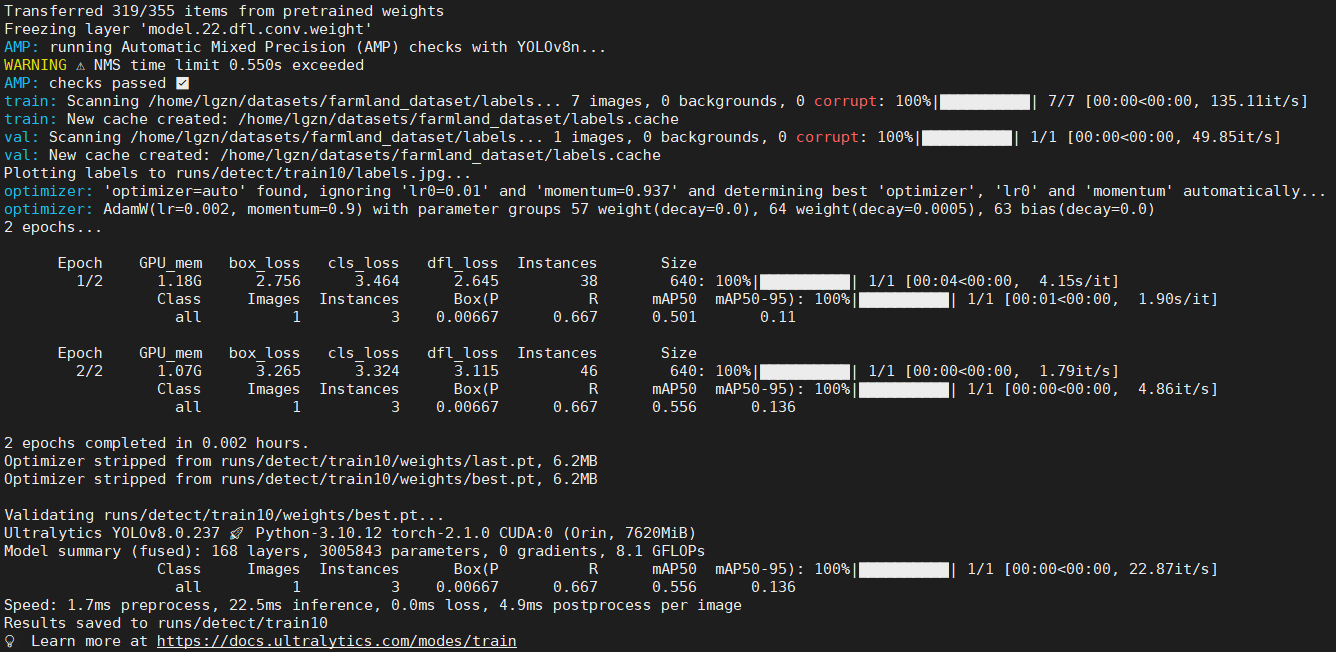
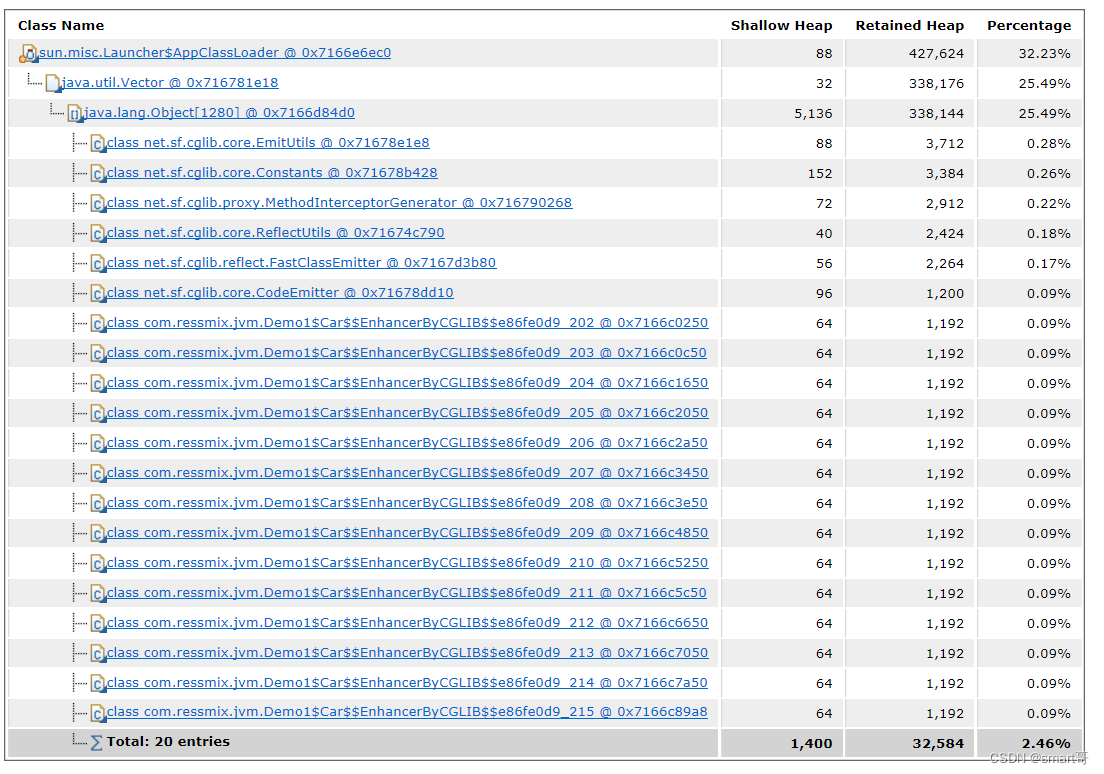
通过flip()方法可以切换读写模式,也就是主要重新设置position、 limit两个属性,如下面的例子,开始实例化一个缓冲区,初始模式为写模式,capacity为10,position默认为0,limit=capacity=10;写入5个数据后的状态如下面中间数组所示,如果此时调用flip()方法则切换到读模式,读模式下只能从缓冲区读取数据不能写,flip()方法将limit=position=5,而position重置为0,这个时候就能读取前面5个格子中的数据了。

以上的内容很重要,需要完全掌握,后面会给出对应的代码来实现上面的例子。mark这个属性后面结合代码再讲。这个图下面代码会反复提起,需要回来看下!
Buffer重要方法
allocate()创建缓冲区
上图第一个初始化的数组状态的代码如下,通过allocate申请容量为10的类型为Byte的缓冲区:
public static void main(String[] args) {
ByteBuffer byteBuffer = ByteBuffer.allocate(10);
// IntBuffer intBuffer = IntBuffer.allocate(10);
System.out.println("positon: "+byteBuffer.position()); // positon: 0
System.out.println("limit: "+byteBuffer.limit()); // limit: 10
System.out.println("capacity: "+byteBuffer.capacity());// capacity: 10
}
put()写入到缓冲区
紧接着上面allocate示例的代码,往byteBuffer中写入5个byte类型的数据,缓存区状态图对应上图的中间状态,代码如下:
// 往byteBuffer写入五个Byte类型的数据
// 也可以使用数组一次性写入,下面for循环等价于 byteBuffer.put(new byte[]{0,1,2,3,4});
for (int i = 0; i < 5; i++) {
byteBuffer.put((byte) i); // 每次调用put,position都会自增1
}
System.out.println("positon: "+byteBuffer.position()); // positon: 5
System.out.println("limit: "+byteBuffer.limit()); // limit: 10
System.out.println("capacity: "+byteBuffer.capacity());// capacity: 10
写入了5个元素之后,缓冲区的position属性值变成了5,所以指向了第6个(从0开始的)可以进行写入的元素位置。而limit最大可写上限、 capacity最大容量两个属性的值,都没有发生变化。put()方法接受一个Byte类型的参数将其写入到缓冲区中,并且position会自增1,直到position等于limit-1,如果大于等于limit则抛出异常!
flip()翻转
向缓冲区写入数据之后,是不可以直接从缓冲区中读取数据的,因为此时的 position 指向的是未写入数据的位置,如果需要读取写入的数据,例如上图的中间状态,需要将position指向第一个写入的数据,limit指向最后一个写入的数据,然后移动position一直到limit就可以读取到写入的数据。而flip()方法所做的就是将limit指向position,将position指向0,最后将mark清除的操作,也就是将写模式切换为读模式。同样紧接上面put示例的代码,代码如下:
// flip()将写模式切换为读模式
byteBuffer.flip();
System.out.println("positon: "+byteBuffer.position()); // positon: 0
System.out.println("limit: "+byteBuffer.limit()); // limit: 5
System.out.println("capacity: "+byteBuffer.capacity());// capacity: 10
在读取完成后,如何再一次将缓冲区切换成写入模式呢?答案是:可以调用下面将讲到的Buffer.clear() 清空或者Buffer.compact()压缩方法,它们可以将缓冲区转换为写模式。总体的Buffer模式转换 :

flip()的源码如下:
public final Buffer flip() {
limit = position; //设置可读的长度上限 limit,设置为写入模式下的 position 值
position = 0; //把读的起始位置 position 的值设为 0,表示从头开始读
mark = UNSET_MARK; // 清除之前的 mark 标记
return this;
}
get()从缓冲区读取
使用调用flip方法将缓冲区切换成读取模式之后,就可以开始从缓冲区中进行数据读取了。读取数据的方法很简单,可以调用get()方法每次从position的位置读取一个数据,并且position自增1。 在position值和limit的值相等时,表示所有数据读取完成, position指向了一个没有数据的元素位置,已经不能再读了。此时再读,会抛出BufferUnderflowException异常。读完后如果需要再次写入需要调用Buffer.clear()或Buffer.compact()方法,即清空或者压缩缓冲区,将缓冲区切换成写入模式,让其重新可写。 紧接上面flip示例代码,代码如下:
// byte[] bytes = new byte[4];
// buffer.get(bytes);
// 也可以全部一次性读取到一个数组中,下面for循环等于上面
for (int i = 0; i < 5; i++) {
byte b = byteBuffer.get();
System.out.print(b+" ");
} // 输出:0 1 2 3 4
System.out.println("positon: "+byteBuffer.position()); // positon: 5
System.out.println("limit: "+byteBuffer.limit()); // limit: 5
System.out.println("capacity: "+byteBuffer.capacity());// capacity: 10
rewind()倒带
已经读完的数据,如果需要再读一遍,可以调用rewind()方法。 rewind()也叫倒带,就像播放磁带一样倒回去,再重新播放。 rewind()的源码如下:
public final Buffer rewind() {
position = 0;//重置为 0,所以可以重读缓冲区中的所有数据
mark = -1; // mark 标记被清理,表示之前的临时位置不能再用了
return this;
}
可以看到,rewind将position重新指向了第一个可读数据,然后将mark清除,limit不变。紧接着get()的示例代码,测试rewind()如下:
// rewind 重新从头读取
byteBuffer.rewind();
System.out.println("positon: "+byteBuffer.position()); //positon: 0
System.out.println("limit: "+byteBuffer.limit()); // limit: 5
System.out.println("capacity: "+byteBuffer.capacity());// capacity: 10
mark()和reset()
mark( )和reset( )两个方法是成套使用的: Buffer.mark()方法将当前position的值保存起来,放在mark属性中,让mark属性记住这个临时位置;之后,可以调用Buffer.reset()方法将mark的值恢复到position中。 比如说要实现第2和第3个数据重复读三次,再读取后面的数据,上面的代码经过rewind后又可以从第1个数据从头读了(第一个数据是0,最后一个数据是4),那么要实现的效果输出结果应该是:“12121234”,实现代码如下:
// 测试mark和reset方法
byteBuffer.get(); // 第一个数据0不需要,现在position=1
byteBuffer.mark(); // 记录此时的position,mark = position = 1
for (int i = 0; i < 3; i++) {
byteBuffer.reset(); // 使得 position = mark 而mark为1
System.out.print(byteBuffer.get()+" "+byteBuffer.get()+" "); // 输出:1 2 1 2 1 2 ,而此时position为3
}
System.out.print(byteBuffer.get()+" "+byteBuffer.get()+" "); // 输出:3 4 ,而此时position为5
clear()清空缓冲区
上面基本都是介绍读模式的方法,如果此时又需要切换到写模式应该如何办呢?在读取模式下,调用clear()方法将缓冲区切换为写入模式。此方法的作用: (1)会将position清零; (2) limit设置为capacity最大容量值,可以一直写入,直到缓冲区写满。 即一旦调用clear()就可以将position=0,limit=capacity,这和缓存区刚被初始化出来的时候一样。调用clear就是写模式了,此时不可用从缓存区中读取数据了。代码如下:
// 测试 clear 方法
byteBuffer.clear();
System.out.println("positon: "+byteBuffer.position()); //positon: 0
System.out.println("limit: "+byteBuffer.limit()); // limit: 10
System.out.println("capacity: "+byteBuffer.capacity());// capacity: 10
compact()清空已读数据
compact的作用就是压缩缓冲区,将缓冲区从读模式转为写模式,比如说此时缓冲区中有5个数据,目前前面两个读完了,此时position为2,还有三个数据没有读取完,那么此时如果调用compact(),会将前面两个读完的数据删除并将三个未读的数据向左移动两个位置,此时position指向的是3,即第一个还没有写入的格子,此时缓冲区就是写模式,测试代码紧接着mark( )和reset( ) 测试后面:
byteBuffer.rewind(); //重头读
// 先读取两个
byteBuffer.get(); // 读取了0
byteBuffer.get(); // 读取了1
System.out.println("positon: "+byteBuffer.position()); //positon: 2
byteBuffer.compact(); // 缓存区压缩已读数据,转为写模式,此时缓冲区还有2 3 4 三个数据
System.out.println("positon: "+byteBuffer.position()); //positon: 3
byteBuffer.put((byte) 99); //positon: 4
byteBuffer.flip(); //切换读模式,不切换的话下面get将输出4,也就是positon为4的那个数据
System.out.println(byteBuffer.get()); //输出:2
使用Buffer类的基本步骤
总体来说,使用Java NIO Buffer类的基本步骤如下:
- 使用创建子类实例对象的allocate( )方法,创建一个Buffer类的实例对象。
- 调用put( )方法,将数据写入到缓冲区中。
- 写入完成后,在开始读取数据前,调用Buffer.flip( )方法,将缓冲区转换为读模式。
- 调用get( )方法,可以从缓冲区中读取数据。
- 读取完成后,调用Buffer.clear( )方法或Buffer.compact()方法,将缓冲区转换为写入模式,可以继续写入。
经典神书推荐:《Java高并发核心编程系列》——尼恩