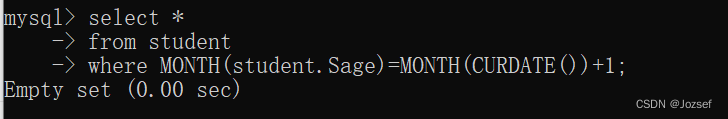原理
线性数据分割
如下图所示,其中含有两类数据,红的和蓝的。如果是使用kNN算法,对于一个测试数据我们要测量它到每一个样本的距离,从而根据最近的邻居分类。测量所有的距离需要足够的时间,并且需要大量的内存存储训练样本。但是分类下图所示的数据真的需要占用这么多资源吗?

我们在考虑另外一个想法。我们找到了一条直线f (x) = ax1 + bx2 + c,它可以将所有的数据分割到两个区域。当我们拿到一个测试数据X 时,我们只需要把它代入f (x)。如果|f (X) | > 0,它就属于蓝色组,否则就属于红色组。我们把这条线称为决定边界(Decision_Boundary)。很简单而且内存使用效率也很高。这种使用一条直线(或者是高位空间中的超平面)将平面上的数据分成两组的方法成为线性分割。
从上图中我们看到有很多条直线可以将数据分为蓝红两组,哪一条直线是最好的呢?直觉上上这两条直线应该是与两组数据的距离越远越好。为什么呢?因为测试数据可能有噪音影响(真实数据+ 噪声)。这些数据不应该影响分类的准确性。所以这条距离远的直线抗噪声能力也就最强。所以SVM 要做就是找到一条直线并使这条直线到(训练样本)各组数据的最短距离最大。下图
中加粗的直线经过中心。
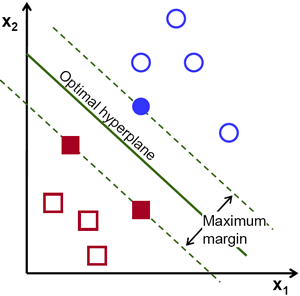
要找到决定边界,就需要使用训练数据。我们需要所有的训练数据吗?不是的,只需要那些靠近边界的数据,如上图中一个蓝色的圆盘和两个红色的方块。我们叫他们支持向量,经过他们的直线叫做支持平面。有了这些数据就可以找到决定边界了。
实际上,我们还是会担心所有的数据,因为这对于数据简化有帮助。 到底发生了什么呢?首先我们找到了分别代表两组数据的超平面。例如,蓝色数据可以用ωT x+b0 > 1 表示,而红色数据可以用ωT x+b0 < −1 表示,ω 叫做权重向量,ω = [ω1, ω2, . . . , ω3],x 为特征向量x = [x1, x2, . . . ,xn],b0 被叫做bias(截距)。权重向量决定了决定边界的走向,而bias 点决定了它(决定边界)的位置。决定边界被定义为这两个超平面的中间线(平面),表达式为ωT x+b0 = 0。

非线性数据分割
想象一下,如果一组数据不能被一条直线分为两组怎么办?例如在一维空间中X 类包含的数据点有(-3,3),O 类包含的数据点有(-1,1)。很明显不可能使用线性分割将X 和O 分开。但是有一个方法可以帮我们解决这个问题。使用函数 ![]() 对这组数据进行映射后得到的X 为9,O 为1,这时就可以使用线性分割了。
对这组数据进行映射后得到的X 为9,O 为1,这时就可以使用线性分割了。
或者我们也可以把一维数据转换成两维数据。我们可以使用函数![]() 对数据进行映射。这样X 就变成了(-3,9)和(3,9)而O 就变成了(-1,1)和(1,1)。同样可以线性分割,简单来说就是在低维空间不能线性分割的数据在高维空间很有可能可以线性分割。
对数据进行映射。这样X 就变成了(-3,9)和(3,9)而O 就变成了(-1,1)和(1,1)。同样可以线性分割,简单来说就是在低维空间不能线性分割的数据在高维空间很有可能可以线性分割。
通常我们可以将d 维数据映射到D 维数据来检测是否可以线性分割(D>d)。这种想法可以帮助我们通过对低维输入(特征)空间的计算来获得高维空间的点积。我们可以用下面的例子说明。

这说明三维空间中的内积可以通过计算二维空间中内积的平方来获得。这可以扩展到更高维的空间。所以根据低维的数据来计算算它们的高维特征。在进行完映射后,我们就得到了一个高维空间数据。
除了上面的这些概念之外,还有一个问题需要解决,那就是分类错误。仅仅找到具有最大边缘的决定边界是不够的。我们还需要考虑错误分类带来的误差。有时我们找到的决定边界的边缘可能不是最大的但是错误分类是最少的。所以我们需要对我们的模型进行修正来找到一个更好的决定边界:最大的边缘,最小的错误分类。评判标准就被修改为:
![]()
下图显示这个概念。对于训练数据的每一个样本又增加了一个参数ξi。它表示训练样本到他们所属类(实际所属类)的超平面的距离。对于那些分类正确的样本个参数为0,因为它们会落在它们的支持平面上。
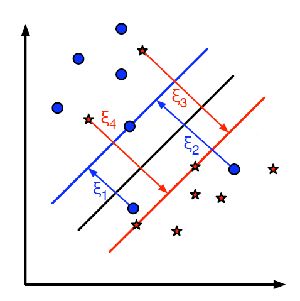
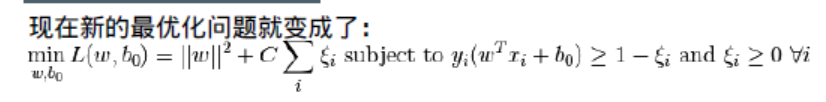
参数C 的取值应该如何选择呢?很明显应该取决于你的训练数据。虽然没有一个统一的答案,但是在选取C 的取值时我们还是应该考虑一下下面的规则:
- 如果C 的取值比较大,错误分类会减少,但是边缘也会减小。其实就是错误分类的代价比较高,惩罚比较大。通常在数据噪声很小时我们可以选取较大的C 值。
- 如果C 的取值比较小,边缘会比较大,但错误分类的数量会升高。其实就是错误分类的代价比较低,惩罚很小。整个优化过程就是为了找到一个具有最大边缘的超平面对数据进行分类。如果数据噪声比较大时,应该考虑这么做。
使用SVM 进行手写数据OCR
这里我们还是要进行手写数据的OCR,但这次我们使用的是SVM 而不是kNN。在kNN 中我们直接使用像素的灰度值作为特征向量。这次我们要使用方向梯度直方图(Histogram of Oriented Gradients) HOG作为特征向量。在计算HOG 前我们使用图片的二阶矩对其进行抗扭斜(deskew)处理。所以我们首先定义一个函数deskew(),它可以对一个图像进行抗扭斜处理。下面就是deskew() 函数:
def deskew(img):
m = cv2.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv2.warpAffine(img,M,(SZ, SZ),flags=affine_flags)
return img下图显示了对含有数字0 的图片进行抗扭斜处理后的效果。左侧是原始图像,右侧是处理后的结果。
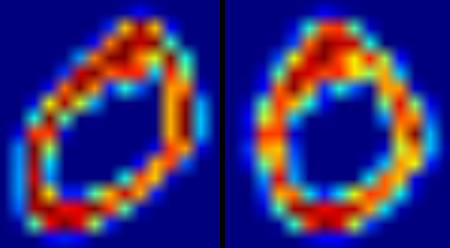
接下来我们要计算图像的HOG 描述符,创建一个函数hog()。为此我们创建算图像X 方向和Y 方向的Sobel 导数。然后计算得到每个像素的梯度的方向和大小。把这个梯度转换成16 位的整数。将图像分为4 个小的方块,对每一个小方块计算它们的朝向直方图(16 个bin),使用梯度的大小做权重。这样每一个小方块都会得到一个含有16 个成员的向量。4 个小方块的4 个向量就组成了这个图像的特征向量,包含64 个成员。这就是我们要训练练数据的特征向量。
def hog(img):
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)
mag, ang = cv2.cartToPolar(gx, gy)
bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)
bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists) # hist is a 64 bit vector
return hist最后,和前面一样,我们将大图分割成小图。使用每个数字的前250 个作为训练数据,后250 个作为测试数据。全部代码如下所示:
# -*- coding: utf-8 -*-
import cv2
import numpy as np
SZ=20
bin_n = 16 # Number of bins
svm_params = dict( kernel_type = cv2.SVM_LINEAR,svm_type = cv2.SVM_C_SVC,C=2.67, gamma=5.383 )
affine_flags = cv2.WARP_INVERSE_MAP|cv2.INTER_LINEAR
def deskew(img):
m = cv2.moments(img)
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11']/m['mu02']
M = np.float32([[1, skew, -0.5*SZ*skew], [0, 1, 0]])
img = cv2.warpAffine(img,M,(SZ, SZ),flags=affine_flags)
return img
def hog(img):
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)
mag, ang = cv2.cartToPolar(gx, gy)
bins = np.int32(bin_n*ang/(2*np.pi)) # quantizing binvalues in (0...16)
bin_cells = bins[:10,:10], bins[10:,:10], bins[:10,10:], bins[10:,10:]
mag_cells = mag[:10,:10], mag[10:,:10], mag[:10,10:], mag[10:,10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists) # hist is a 64 bit vector
return hist
img = cv2.imread('digits.png',0)
cells = [np.hsplit(row,100) for row in np.vsplit(img,50)]
# First half is trainData, remaining is testData
train_cells = [ i[:50] for i in cells ]
test_cells = [ i[50:] for i in cells]
###### Now training ########################
deskewed = [map(deskew,row) for row in train_cells]
hogdata = [map(hog,row) for row in deskewed]
trainData = np.float32(hogdata).reshape(-1,64)
responses = np.float32(np.repeat(np.arange(10),250)[:,np.newaxis])
svm = cv2.SVM()
svm.train(trainData,responses, params=svm_params)
svm.save('svm_data.dat')
###### Now testing ########################
deskewed = [map(deskew,row) for row in test_cells]
hogdata = [map(hog,row) for row in deskewed]
testData = np.float32(hogdata).reshape(-1,bin_n*4)
result = svm.predict_all(testData)
####### Check Accuracy ########################
mask = result==responses
correct = np.count_nonzero(mask)
print (correct*100.0/result.size)准确率达到了94%。你可以尝试一下不同的参数值,看看能不能得到更高的准确率。或者也可以详细读一下这个领域的文章并用代码实现它。


![[足式机器人]Part2 Dr. CAN学习笔记- Kalman Filter卡尔曼滤波器Ch05-5+6](https://img-blog.csdnimg.cn/direct/3ec3f5756ce14450b76d20641d9ce807.png#pic_center)