我是南城余!阿里云开发者平台专家博士证书获得者!
欢迎关注我的博客!一同成长!
一名从事运维开发的worker,记录分享学习。
专注于AI,运维开发,windows Linux 系统领域的分享!
知识库链接:
Java基础入门 · 语雀

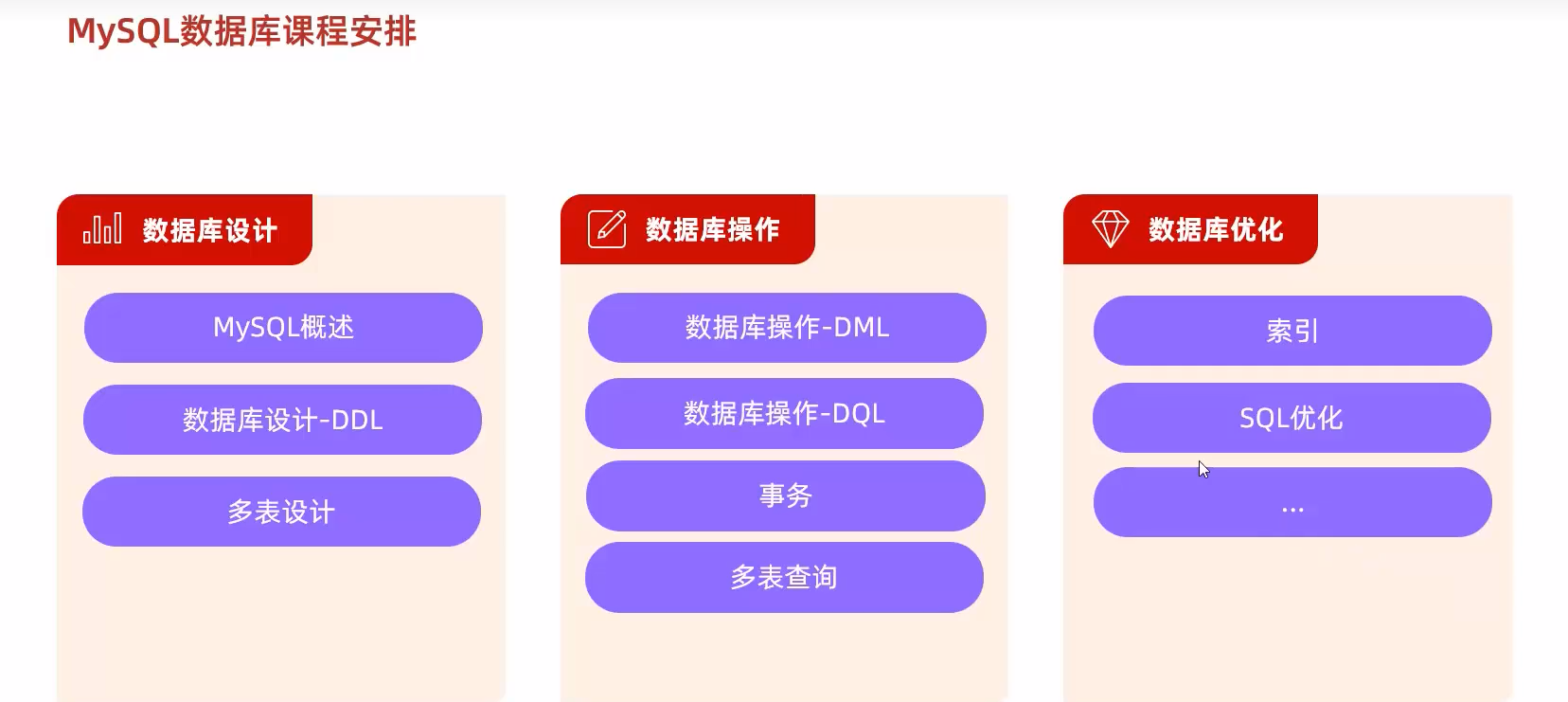
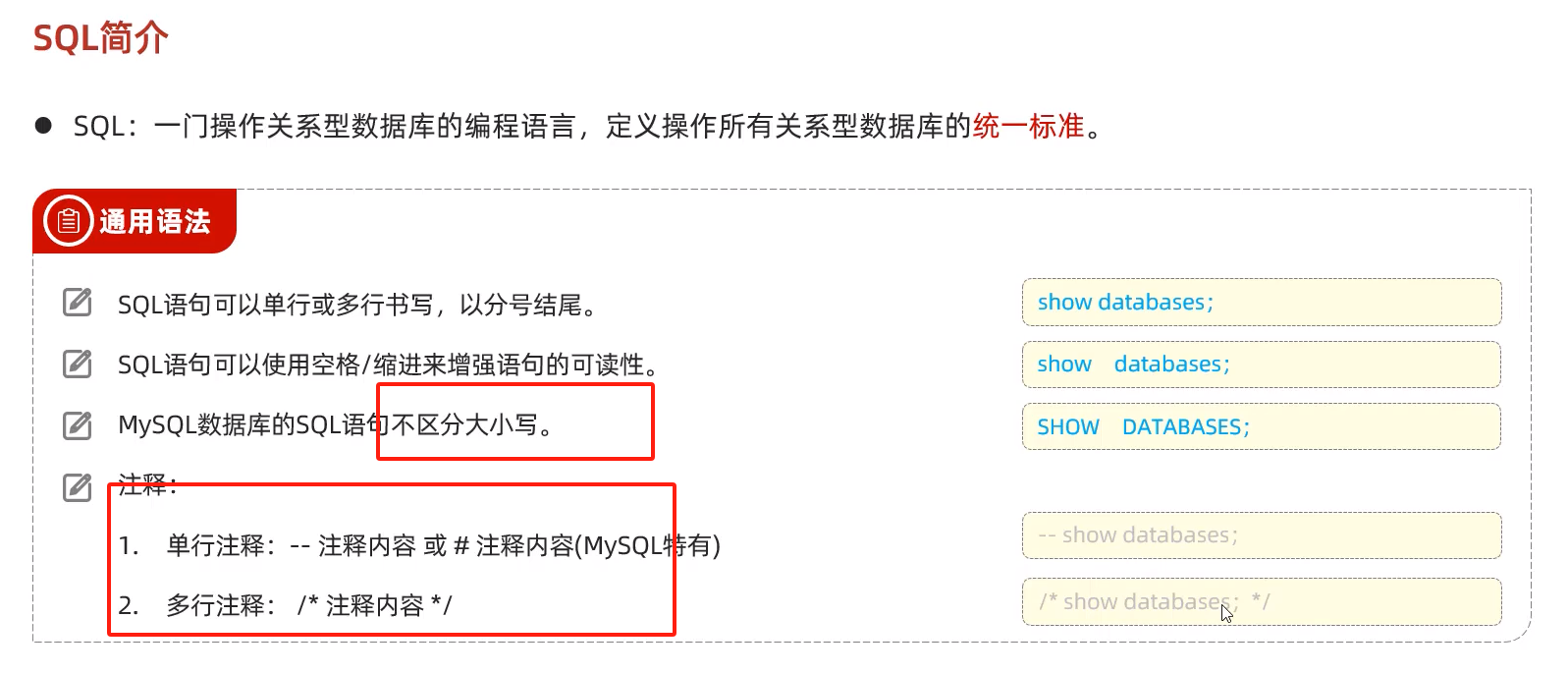


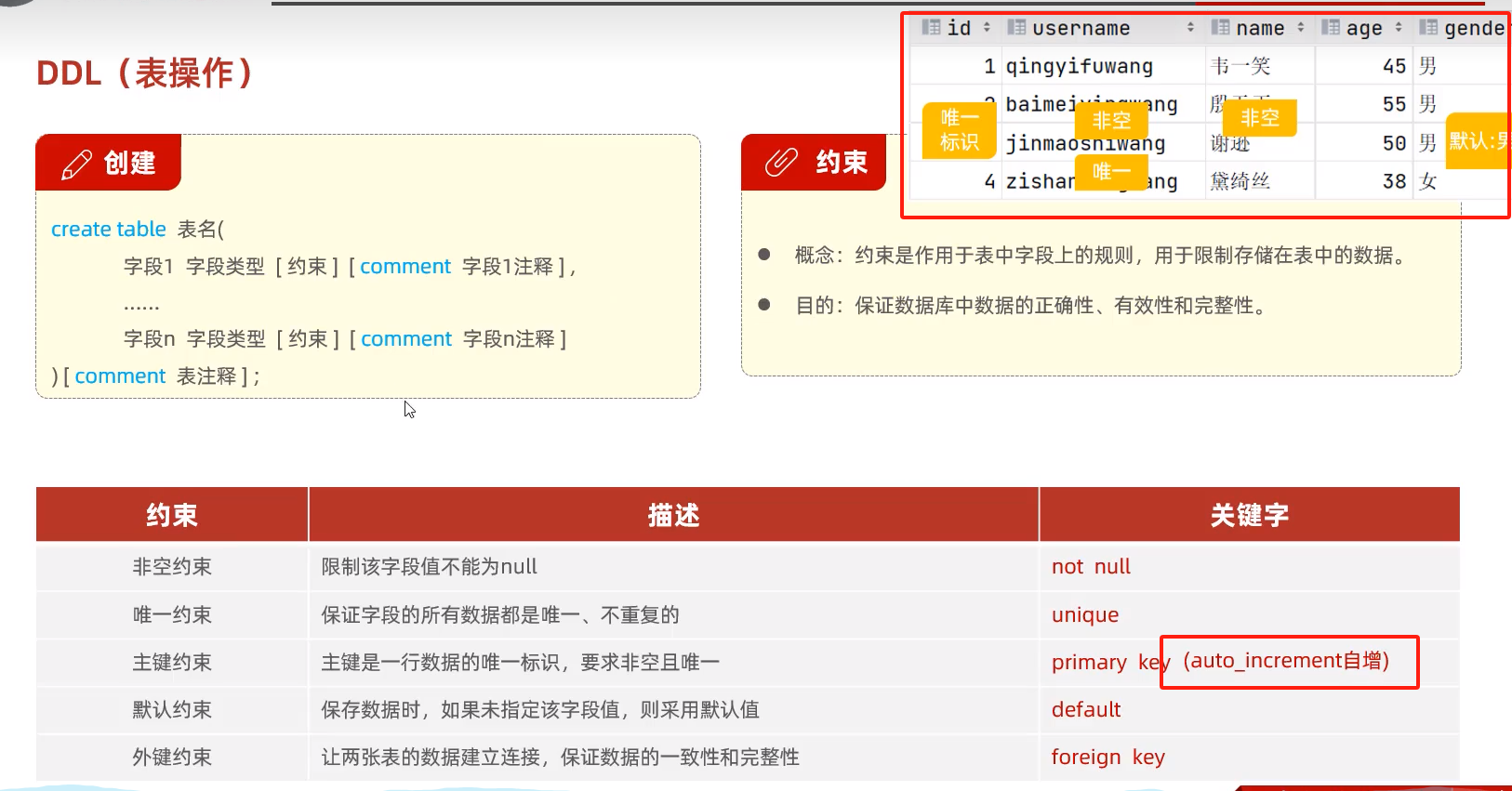
数据库约束
- 主键约束 primary key
- 外键约束 foreign key
- 非空约束 not null
- 唯一约束 unique
- 默认约束 default

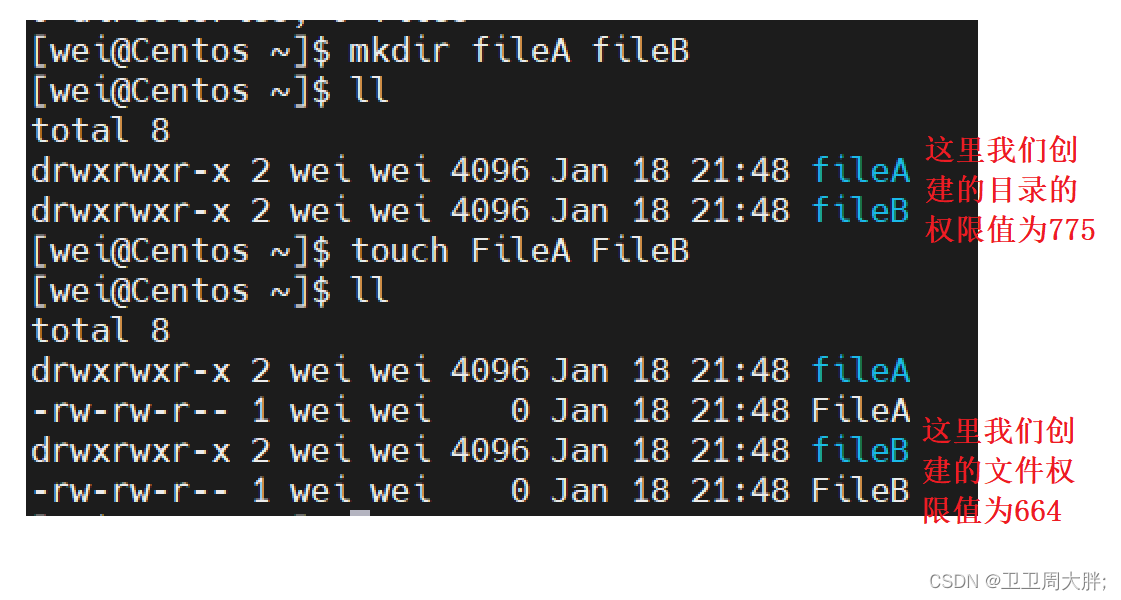
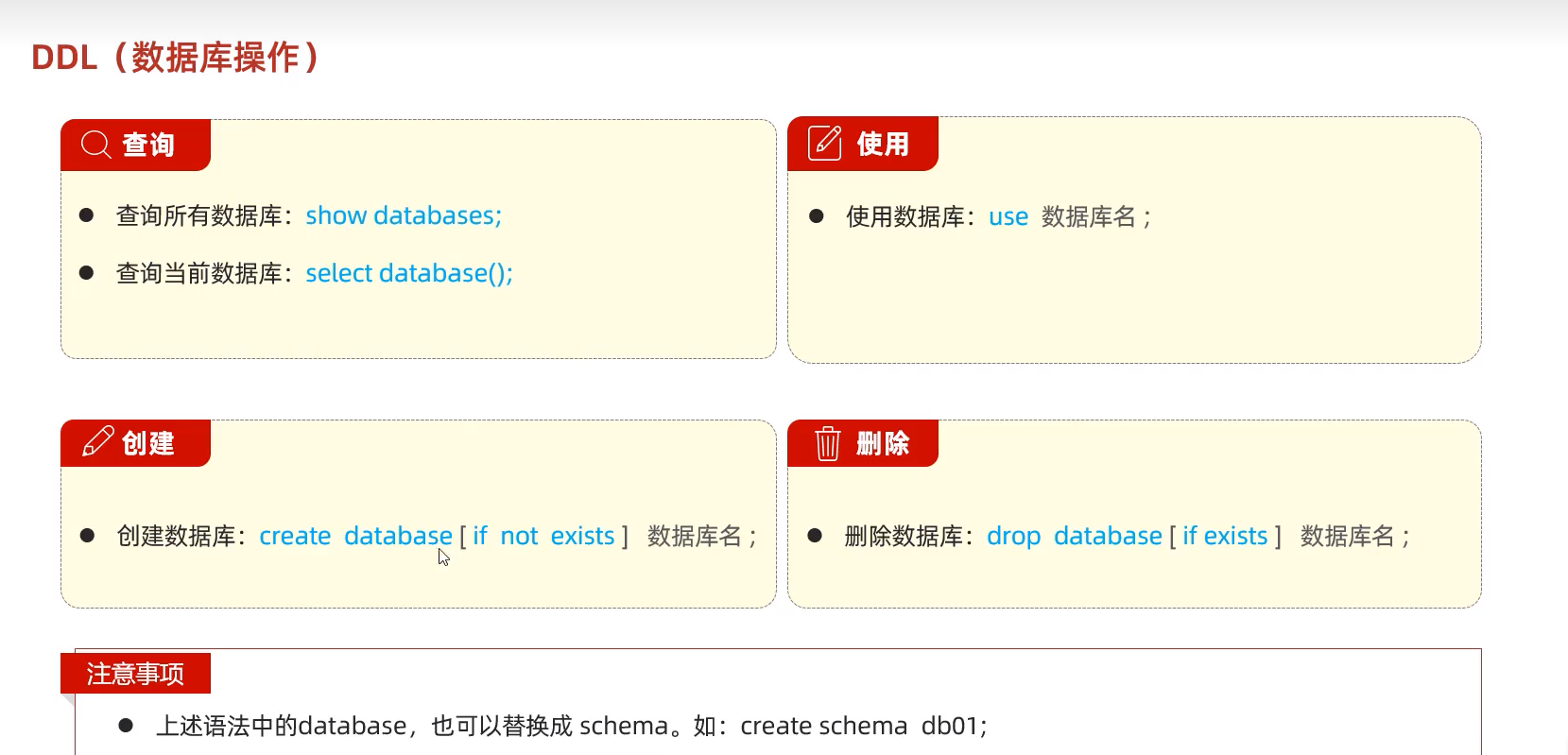
create database ts_db;
use ts_db;
-- DDL实战(表操作)
-- 普通建表语句
create table t_user(
id int comment 'ID,唯一标识符',
username varchar(20) comment '用户名',
name varchar(10) comment '名字',
age int comment '年龄',
gender char(1) comment '性别'
) comment '用户表';
drop table t_user;
-- 约束建表语句
create table t_user(
id int primary key auto_increment comment 'ID,唯一标识符',
username varchar(20) not null unique comment '用户名',
name varchar(10) not null comment '名字',
age int comment '年龄',
gender char(1) default '男' comment '性别'
) comment '用户表';
案例和数据类型

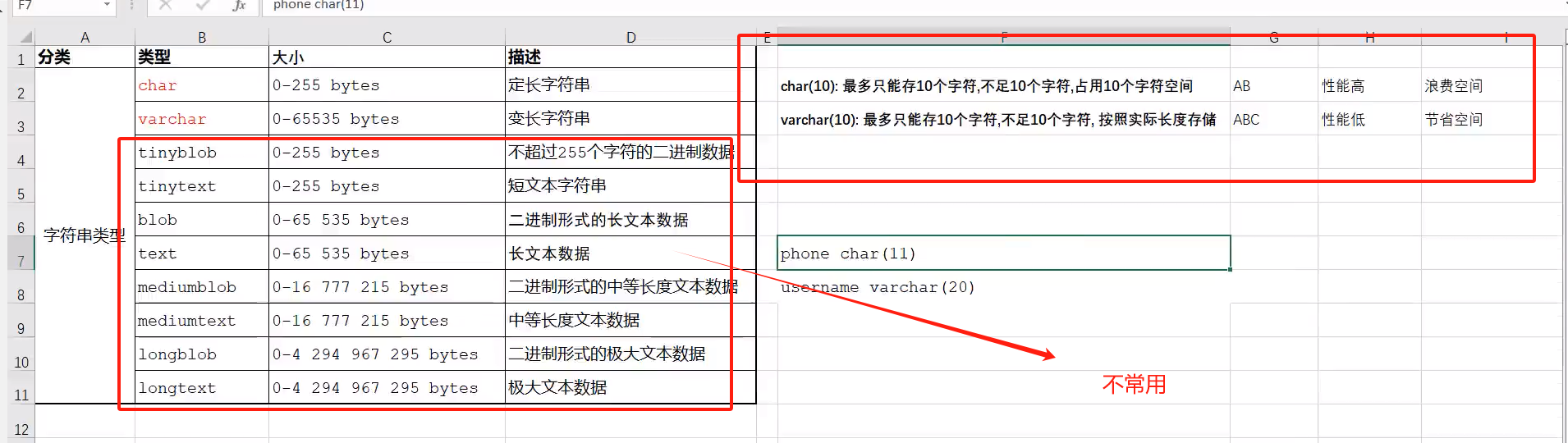
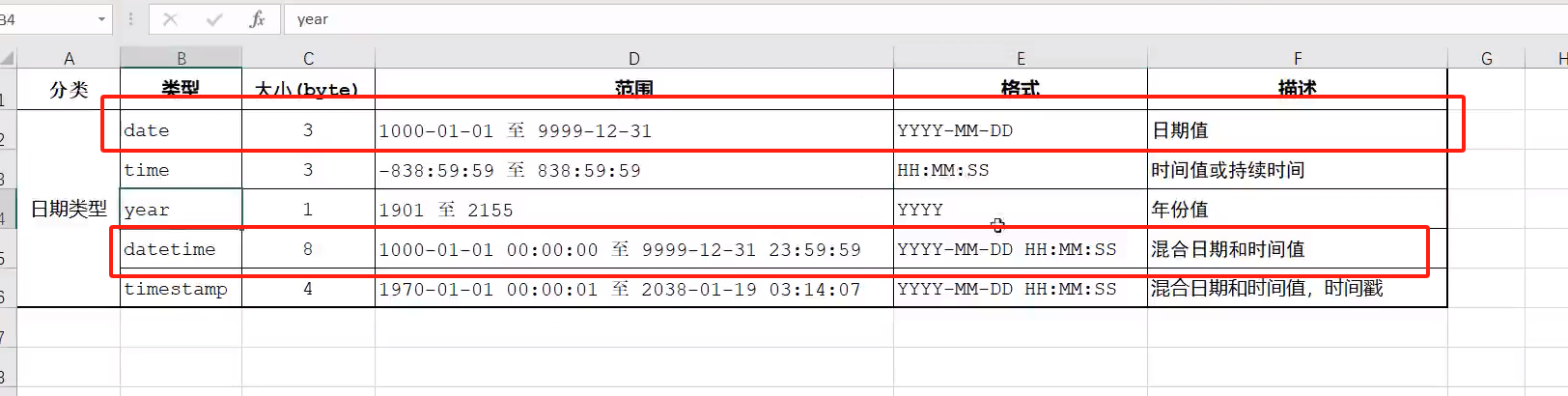
char和varchar的区别:
char(10):代表字段占10个字,全部占完,如果不足10个,则补null
varchar(10):不足10个,也不补充,默认为几个字符就存储几个字符
所以在日常开发中,varchar使用比例别char高
- float,double和decimal
这三个数组类型都是小数型数值类型,后面都可以跟()表示数字长度
float(5,2)代表 5表示整个数字长度,2代表小数位个数
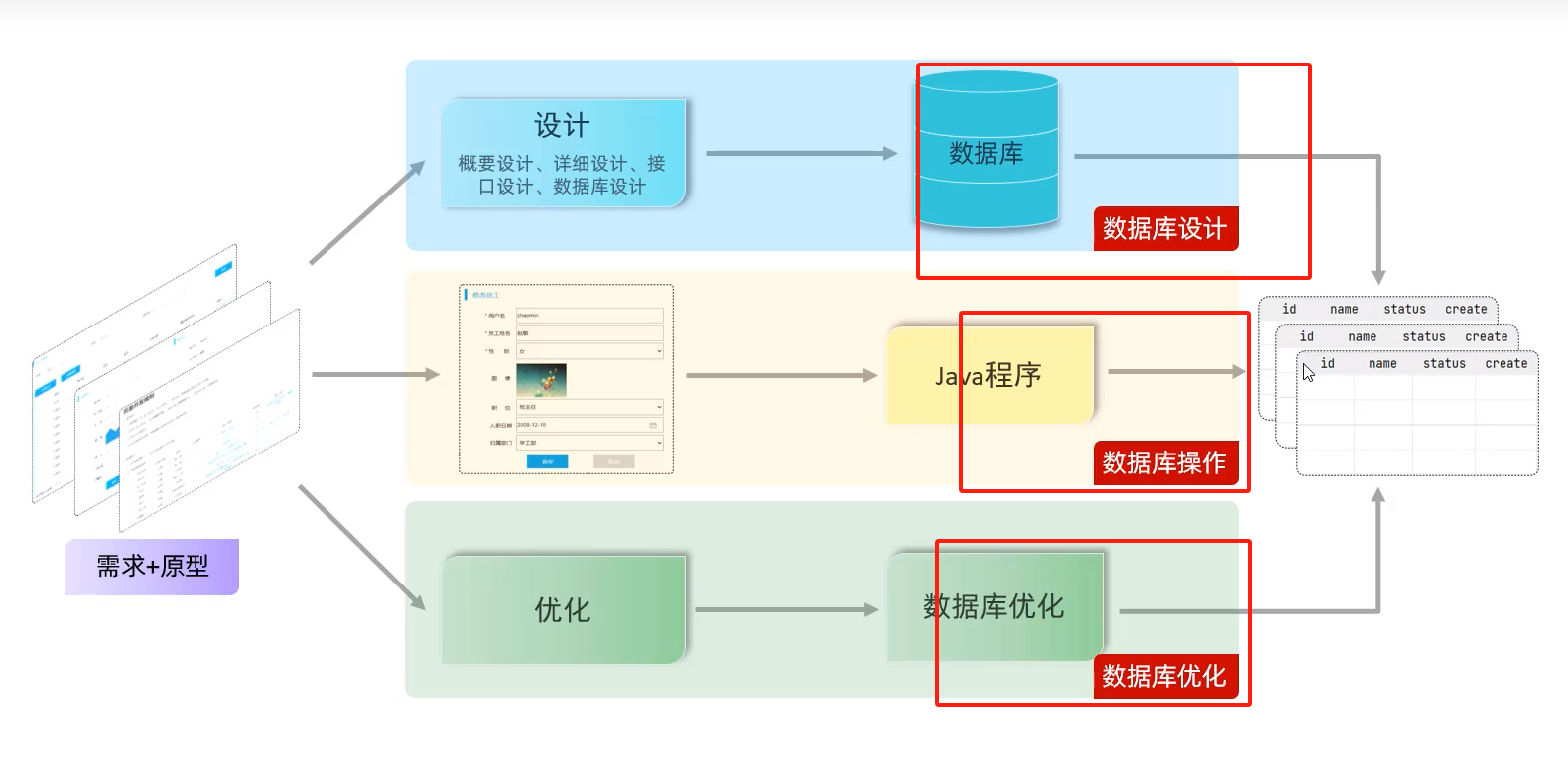
根据页面原型,需求创建表
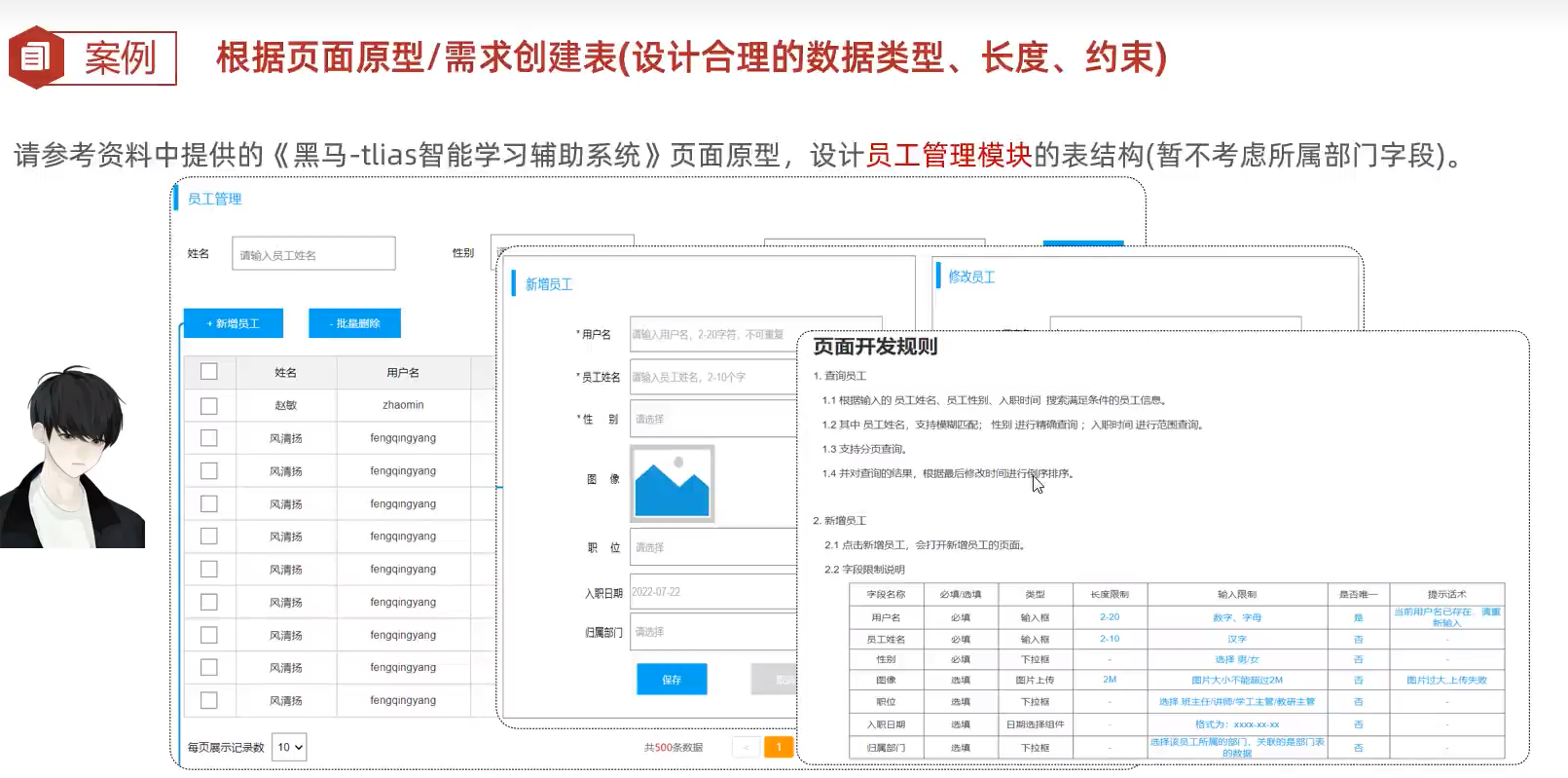
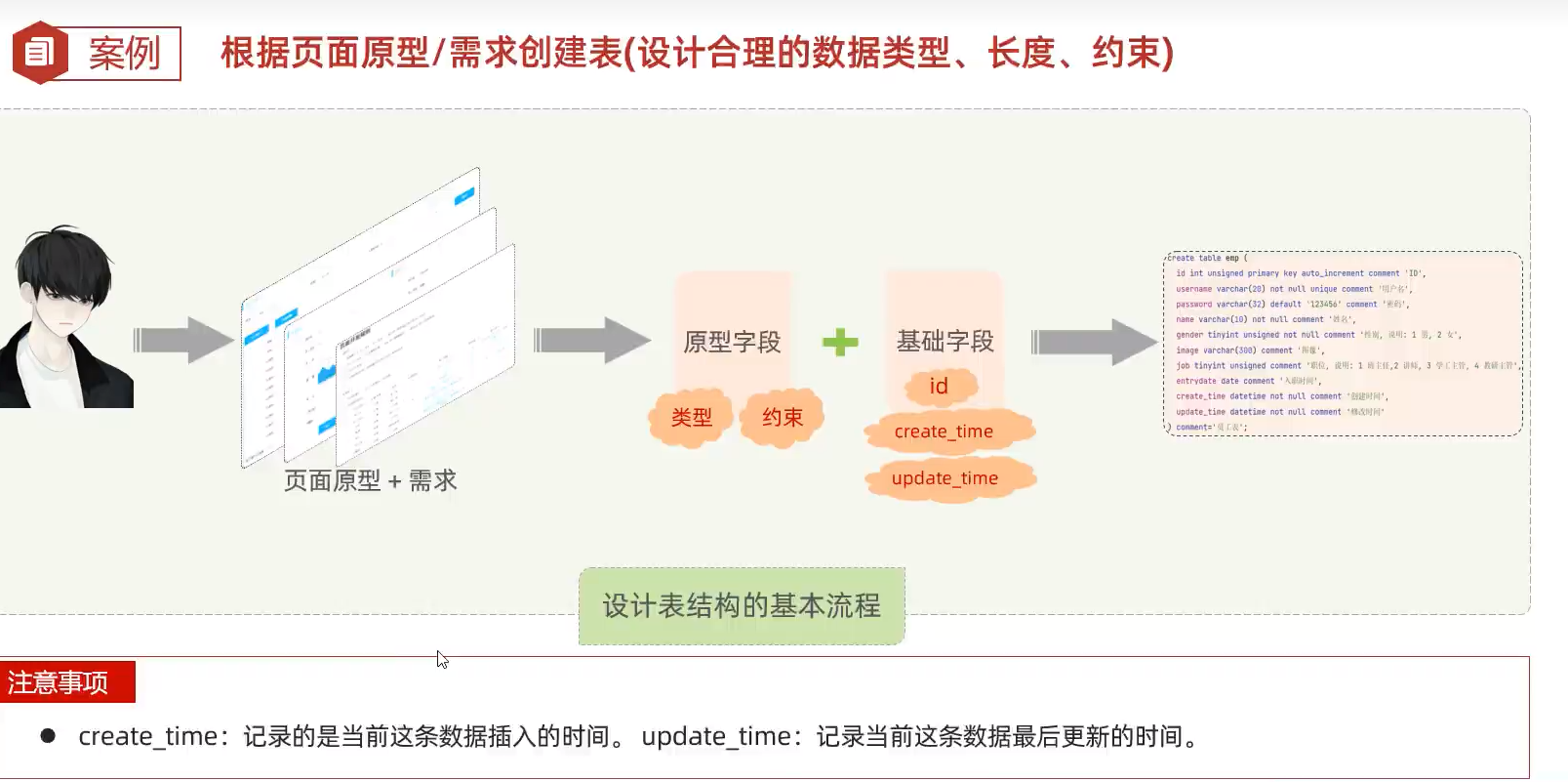
unsigned为无符号的,即为不能为负数 在企业开发种 类似gender这种复选框的选项,一般采用数字
-- 案例实战
create table t_emp(
id int primary key auto_increment,
username varchar(20) not null unique comment '用户名非空 必填 唯一',
employeeName varchar(10) not null comment '员工姓名非空 必填',
gender tinyint unsigned not null default '性别 存储1 - 男 2 - 女',
-- unsigned为无符号的,即为不能为负数 在企业开发种 类似gender这种复选框的选项,一般采用数字
-- 对应的含义 1 - 男 2 - 女
headerImage varchar(200) ,
job tinyint unsigned comment '1- 2- 3- 4-',
entryDate date,
password varchar(15) default '123456',
create_time datetime not null,
update_time datetime not null
);DDL语句



TODOD6 -10 数据库 DML
update tb_emp set name = '张三',update_time = now() where id = 1;
-- delete 不能删除字段值,所以如果想要删除某个字段 可以使用update更新某个字段为NULL
delete from tb [where 条件] --如果没条件 则删除整个表的所有数据数据库 DQL
-- 去重 distinct
select distinct id from tb;
-- 别名
select name '姓名' from tb;
-- *在实际开发中 影响效率 不直观 一般不使用
-- 查询null 要用 is null
select * from tb where job is null;
--某张表的数据总量 1.count(字段) 2.count(常量) 3.count(*)√ 推荐数据库对其做了优化
select count(*) from tb;
--聚合函数 和 条件查询使用
--先查询入职时间在‘2015-01-01'(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select job,count(*) from tb where entry_time <= '2015-01-01' group by job having count(*) >= 2;
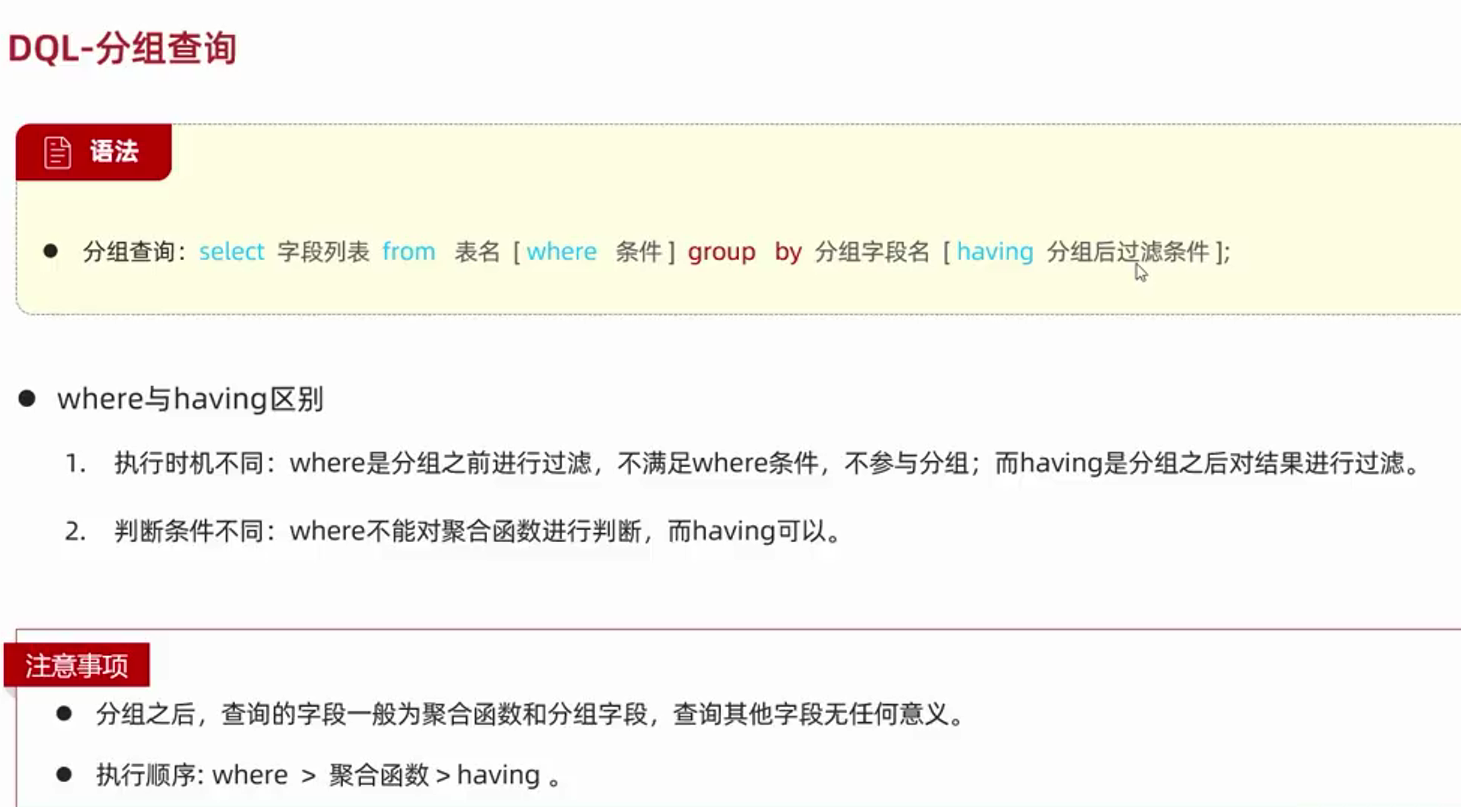
--分组查询后,查询的字段一般为分组字段和聚合函数,而查询其他字段无任何意义
--执行顺序:where > 聚合函数 > having
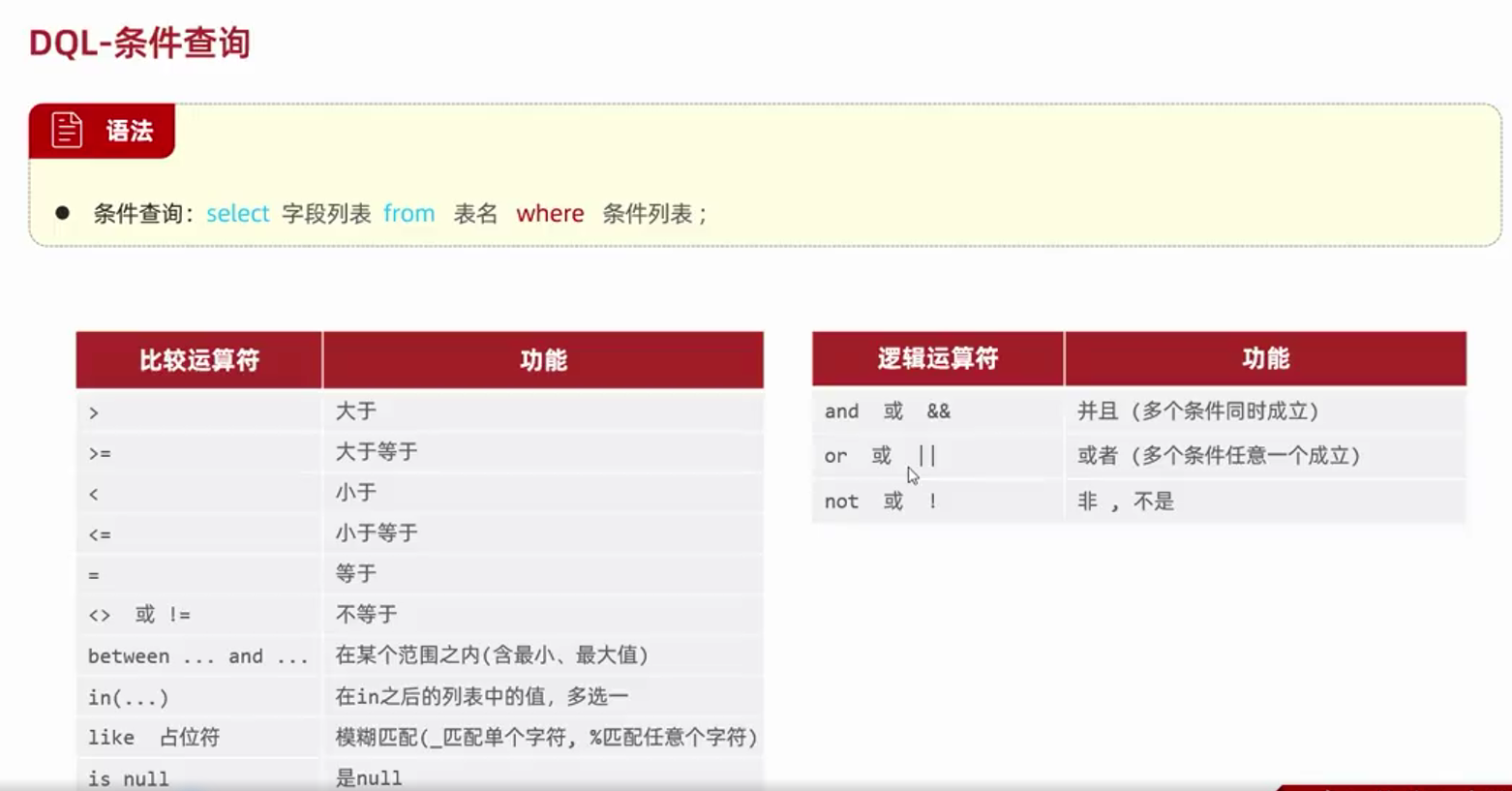
--where 和 having的区别
--1. 执行时机不同:where是分组之前进行过滤,不满足where条件和不参与分组;而having是分组之后对结果进行过滤
--2. 判断条件不同:where不能对聚合函数进行判断,而having可以
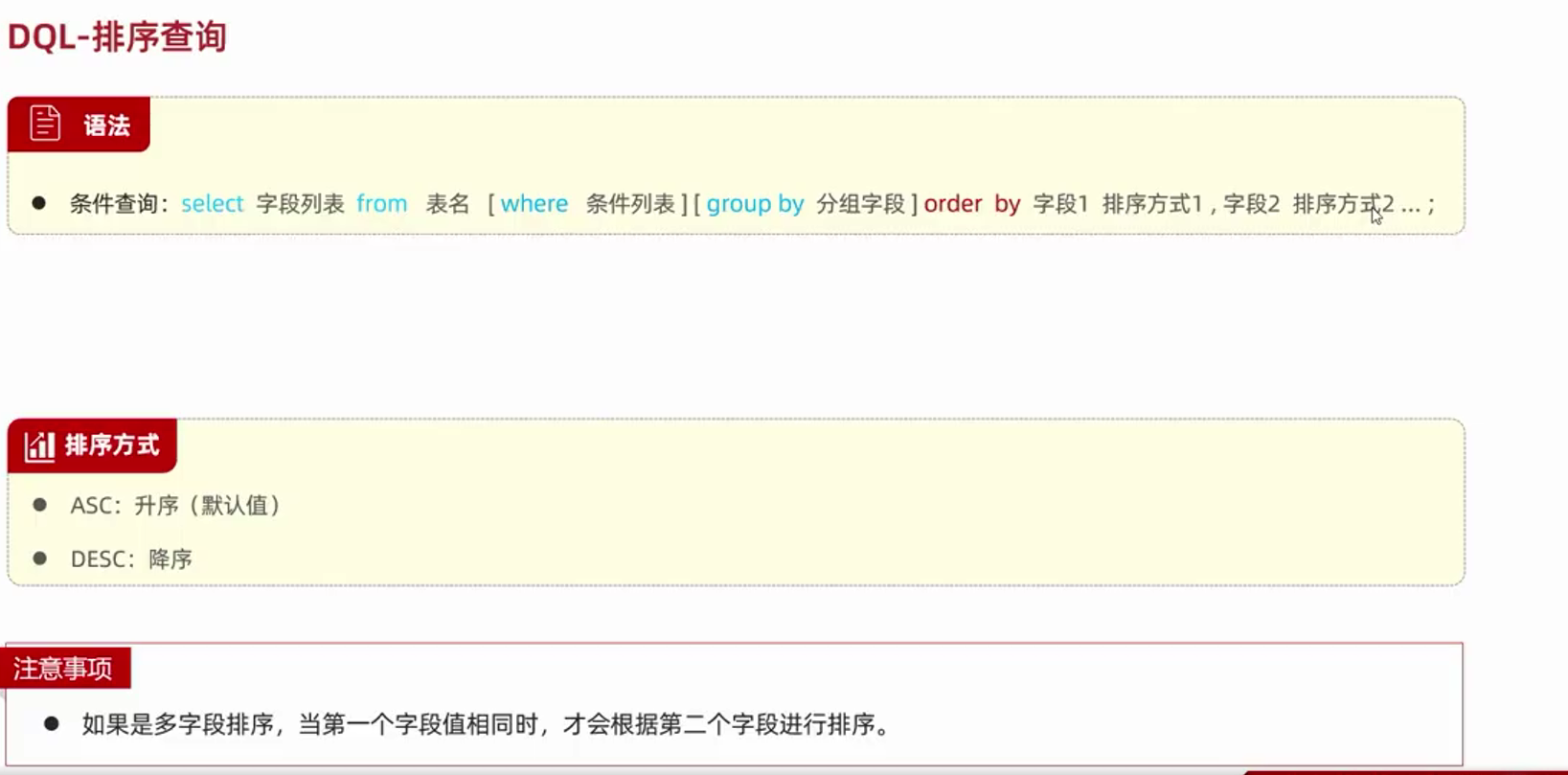
--排序查询
select * from tb order by entry_time , order by update_time;
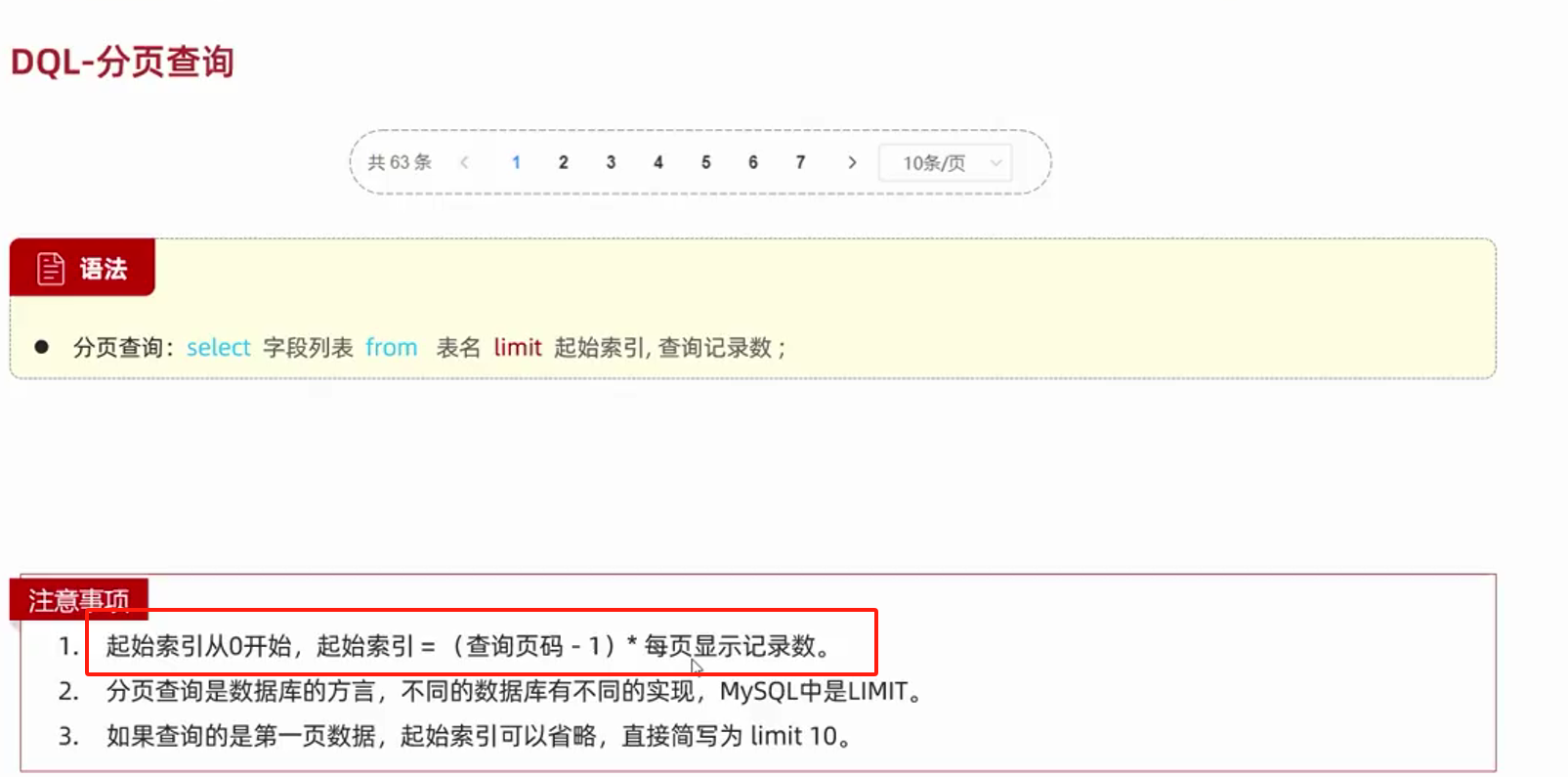
--分页查询
select * from tb limit(起始索引,查询记录数);
--起始索引=(查询页码-1)*每页显示记录数
--案例
--根据需求,完成员工性别统计
select if(gender = 1,'man','woman') 性别,count(*) from tb group by gender ;
--完成员工职位信息统计
select (case job when 1 then '班主任' when 2 then '讲师' when 3 then '学生主管' else '未分配职位' end) '职位'
,count(*) from tb group by job;


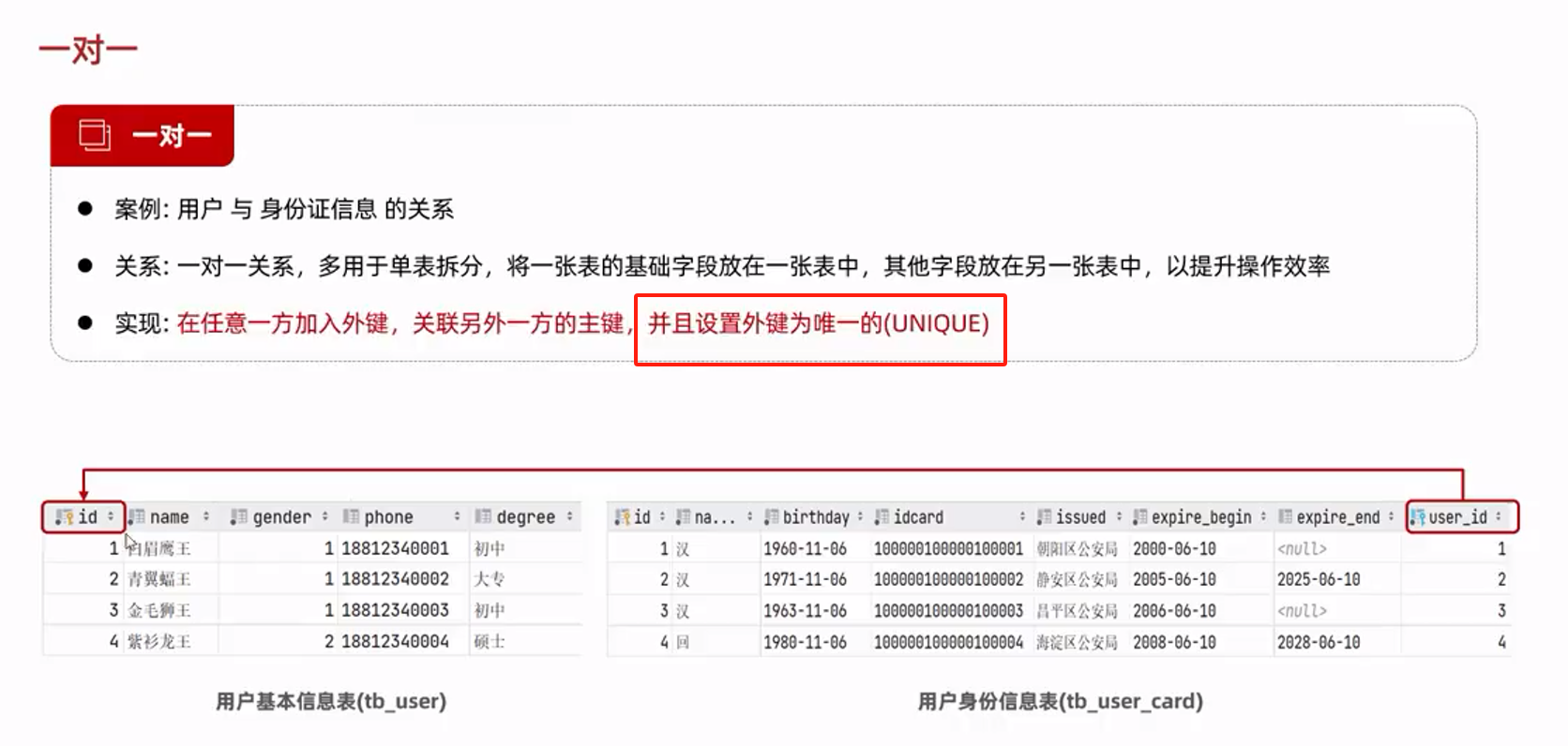
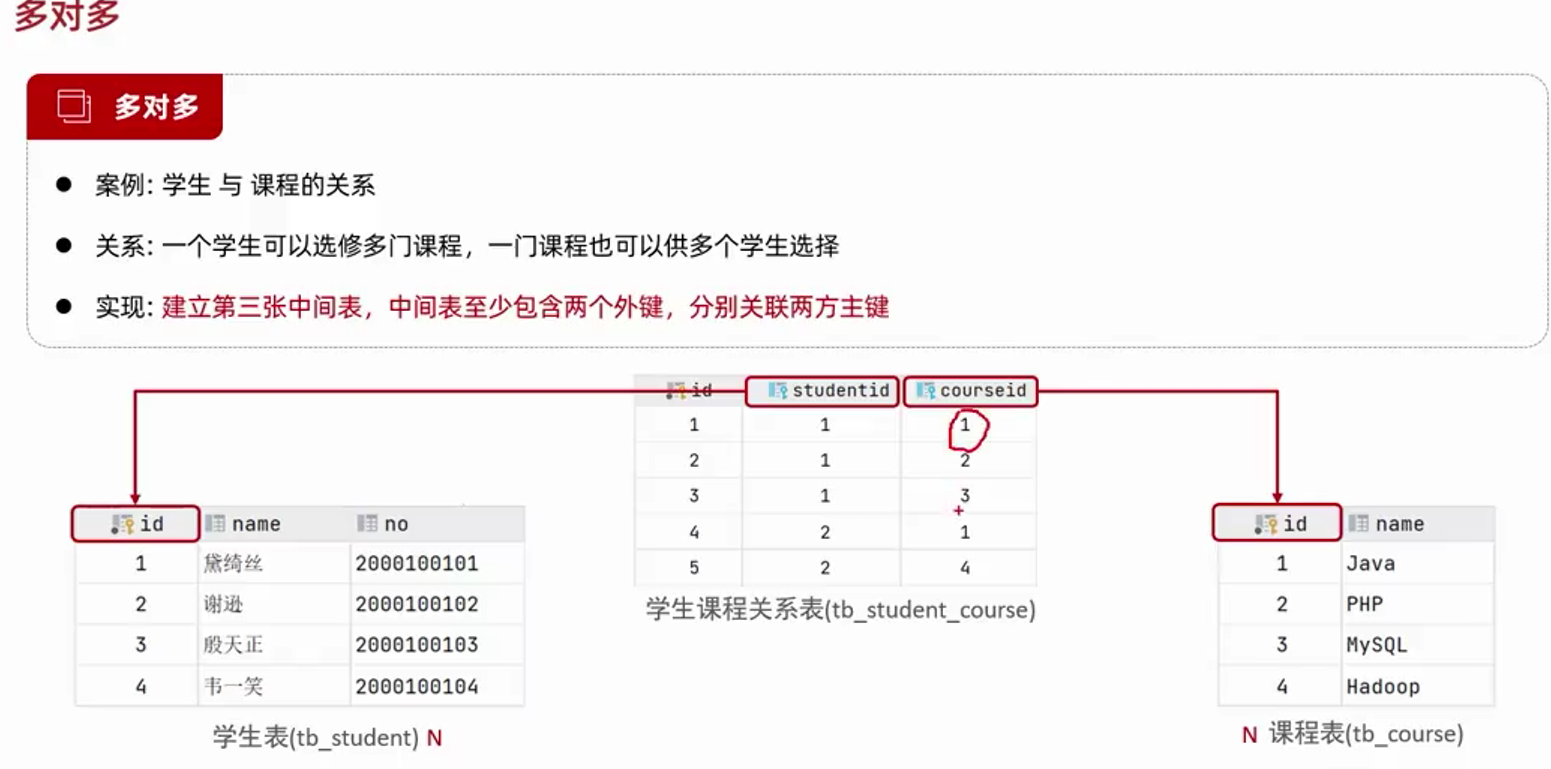
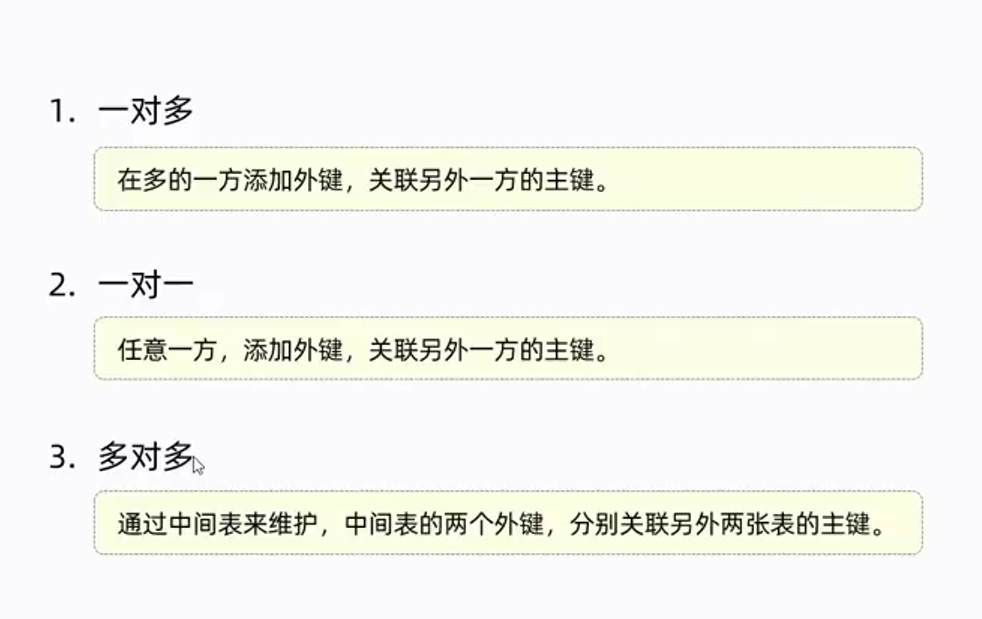
多表设计
-- 表 分为 一对多、一对一(通过外键关联主键)
--多对多(一般借助第三张表实现,也称为关系维护表,第三张表用来设置外键关联另外两张表)




多表查询
--外连接 (x连接查询出来的结果为x的全部数据和两张表交集的全部数据)
--A.查询员工表所有 员工的信息,和对应的部门名称(左外连接)
select e.name, d.name from employee e left join department d on e.dept_id = d.id;
--B.查询部门表 所有 部门的名称,和对应的员工名称(右外连接)
select e.name, d.name from employee e right join department d on e.dept_id = d.id;
select e.name, d.name from department d left join employee e on e.dept_id = d.id;
--所谓的行列子查询 指的是子查询结果的表现形式为行或者列
--列子查询 用in
--行子查询 查询与南城余入职日期和职位都相同的员工信息
select * from employee where (entry_time,job) = (select entry_time ,job from employee where name = '南城余');
--表子查询 多行多列的子查询 常作为临时表使用
-- 查询入职日期是“2006-10-01”之后的员工信息及其部门名称
select e.*,d.name from (select * from employee where entry_time > '2006-10-01') e,departmen d where e.dept_id = d.id;
--题目 查询出低于菜品平均每个的菜品信息(展示出菜品名称、菜品价格)
select name,price from dish where price < (select avg(price) from dish);




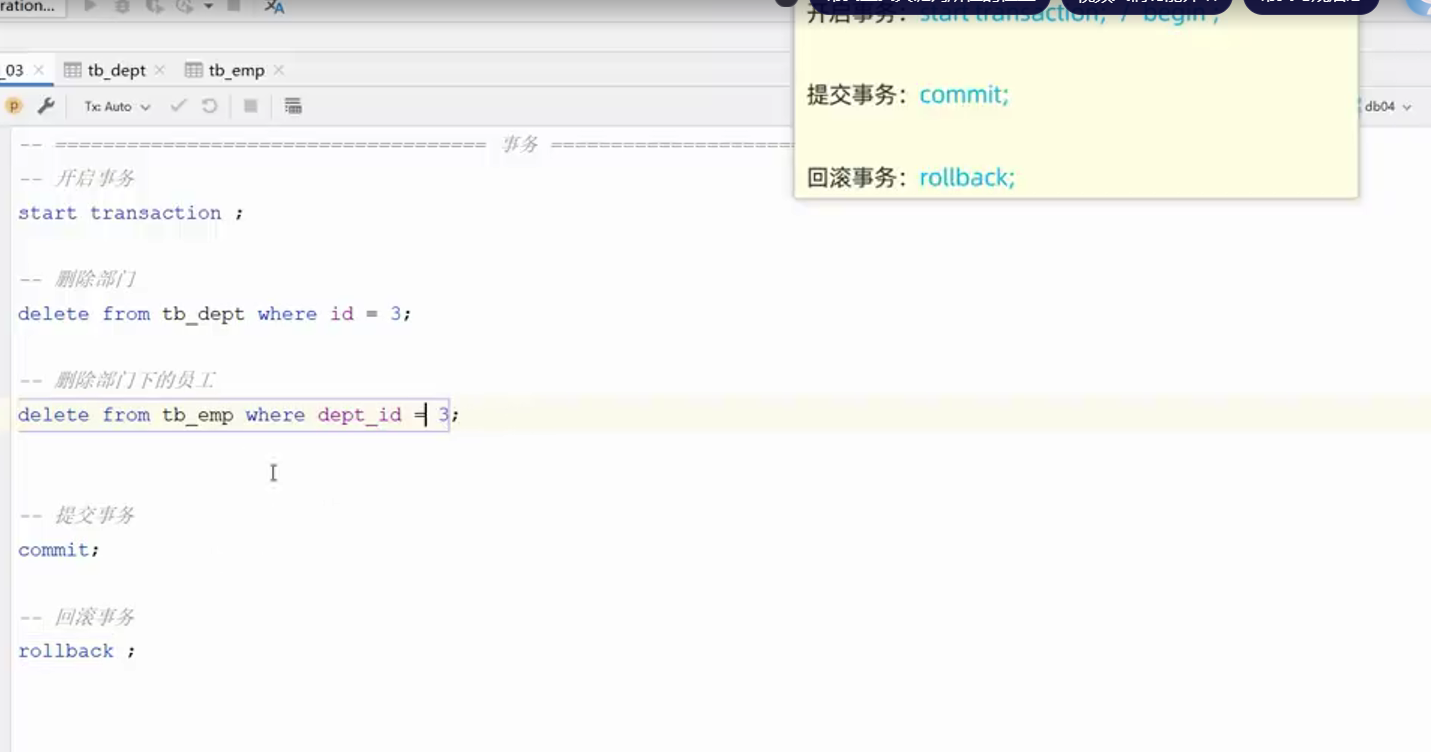
事务
--开始事务
start transaction;/begin;
--删除部门
delete from tb_dept where id = 2;
--删除部门下的员工
delete from tb_emp where dept_id = 2;
--提交事务 (上面两条sql执行成功方可执行)
commit;
--回滚事务(上面两条sql有一条失败执行此语句回滚)
rollback;


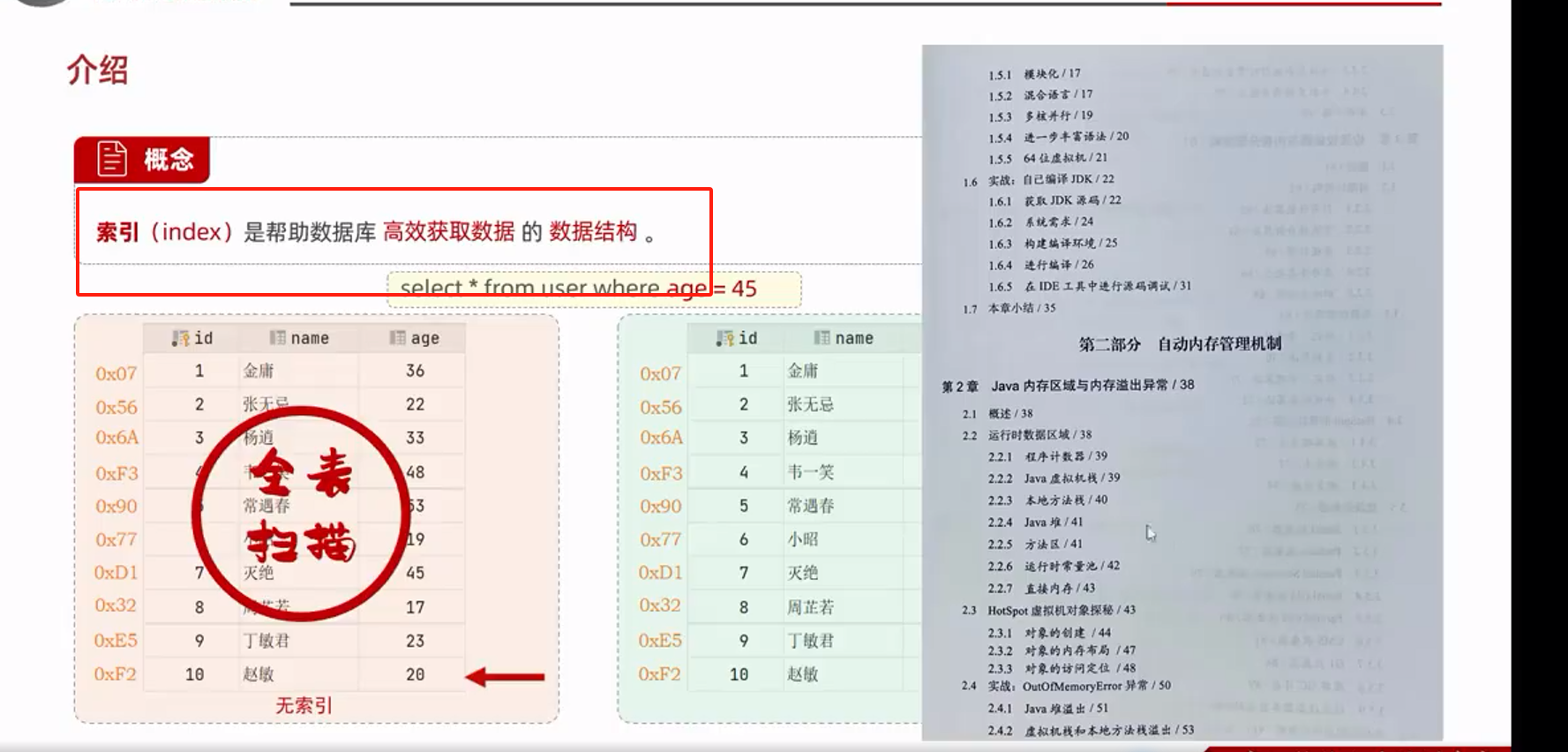
索引
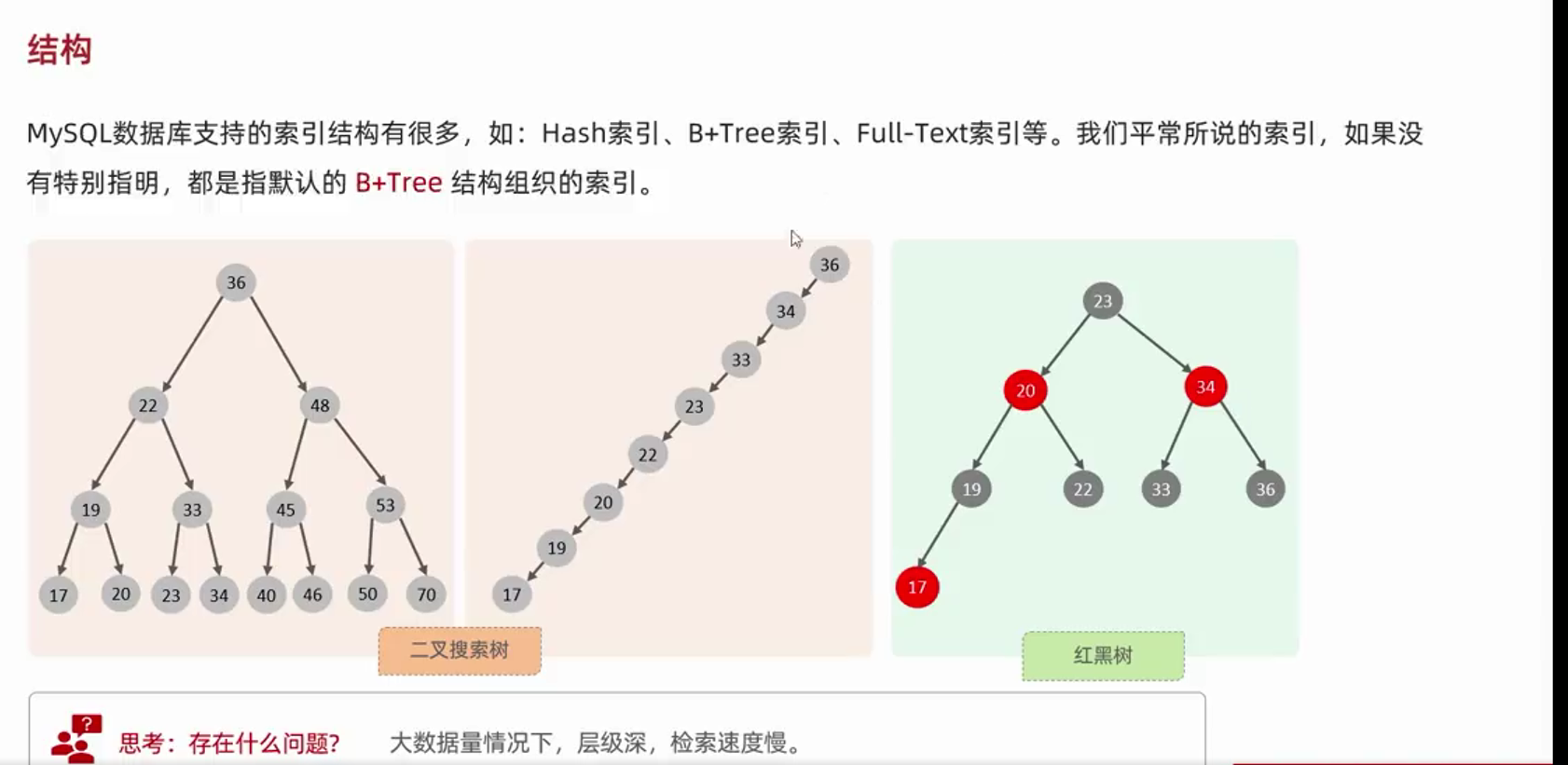
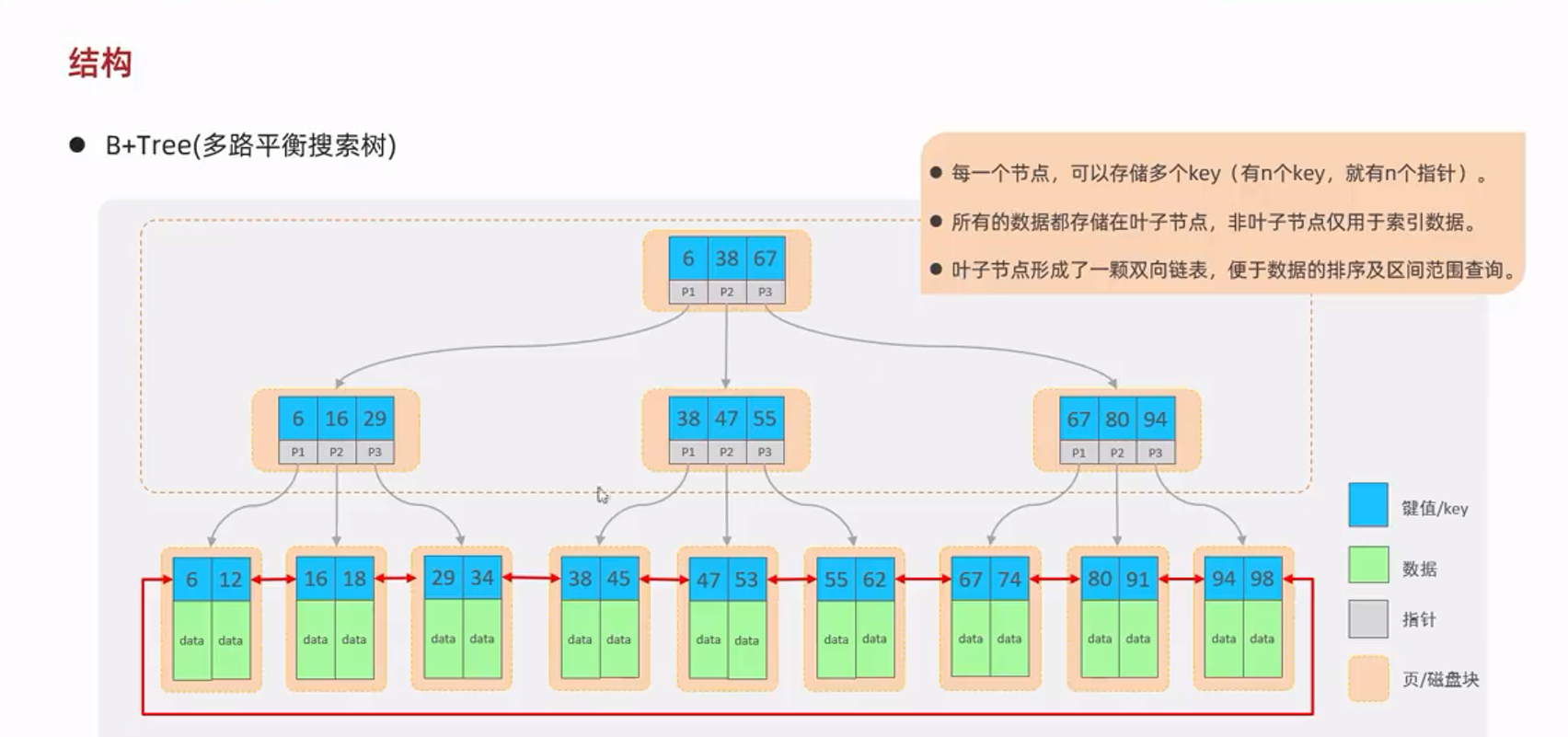
--MySQL数据库默认索引为B+tree(多路平衡搜索树)
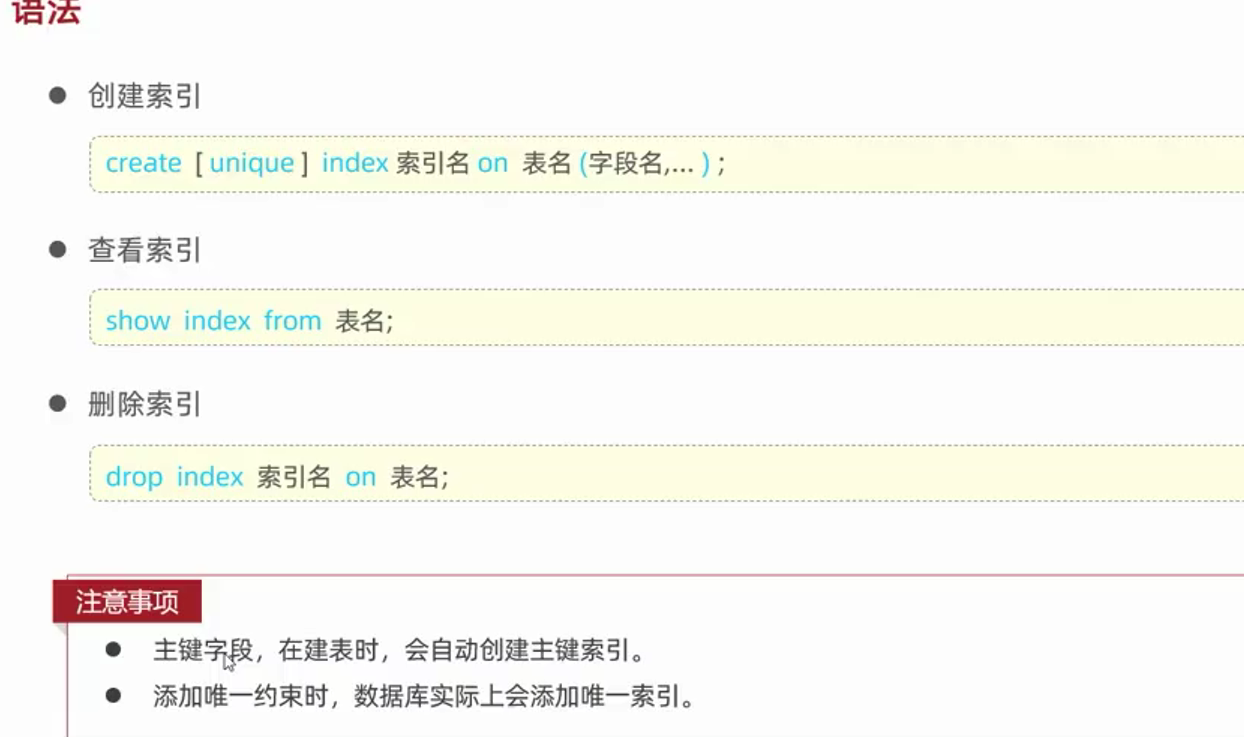
--创建索引
create index idx_emp_name on tb_emp(name);
--查询索引 查询出来的索引包括 唯一索引 主键索引(所有索引中性能最高的)
show index from tb_emp;
--删除索引
drop index idx_emp_name on tb_emp;