电影推荐
启动
./bin/pycharm.sh
django-admin startproject movie_recommendation_project
cd movie_recommendation_project/
python manage.py movie_recommendation_app
python manage.py startapp movle_recommendation_app
ls
python manage.py runserverUsing the URLconf defined in movie_recommendation_project.urls, Django tried these URL patterns, in this order:
admin/
movie/The empty path didn’t match any of these.
You’re seeing this error because you have DEBUG = True in your Django settings file. Change that to False, and Django will display a standard 404 page.


第二步
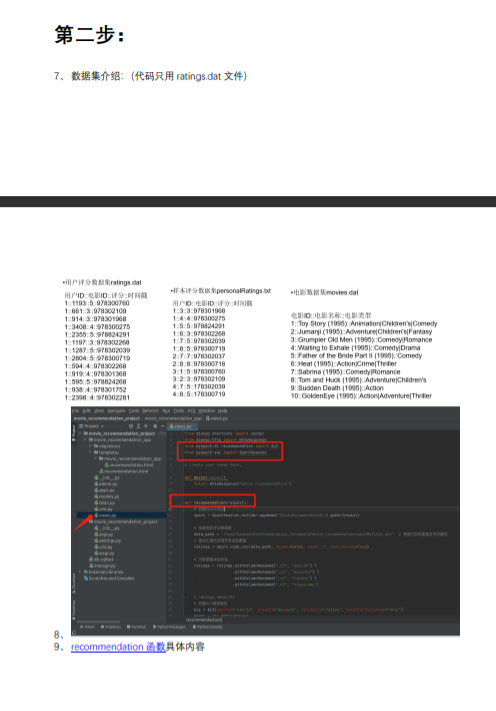
def recommendation(request):
# 创建Spark会话
spark = SparkSession.builder.appName("MovieRecommendation").getOrCreate()
# 加载电影评分数据集
data_path = "/home/hadoop/Downloads/movie_recommend/movie_recommend/personalRatings.dat" # 替换为实际数据文件的路径
# 使用正确的分隔符来读取数据
ratings = spark.read.csv(data_path, header=False, sep="::", inferSchema=True)
# 为数据集添加列名
ratings = ratings.withColumnRenamed("_c0", "userId") \
.withColumnRenamed("_c1", "movieId") \
.withColumnRenamed("_c2", "rating") \
.withColumnRenamed("_c3", "timestamp")
# ratings.show(10)
# 创建ALS推荐模型
als = ALS(userCol="userId", itemCol="movieId", ratingCol="rating", coldStartStrategy="drop")
model = als.fit(ratings)
# 为某个用户生成电影推荐
user_id = 3 # 替换为您要为其生成推荐的用户ID
user_ratings = ratings.filter(ratings["userId"] == user_id)
# user_ratings.show()
user_unrated_movies = ratings.filter(ratings["userId"] != user_id).distinct()
# user_unrated_movies = ratings.filter(ratings["userId"] != user_id).select("movieId").distinct()
# user_unrated_movies.show()
recommendations = model.transform(user_unrated_movies)
# 获取前N个推荐电影
top_n_recommendations = recommendations.orderBy("prediction", ascending=False).limit(10)
# top_n_recommendations.show()
# for recommendation2 in top_n_recommendations.collect():
# print(recommendation2.movieId)
# 在视图中进行数据转换
recommendation_data = [{"movieId": row.movieId, "prediction": row.prediction} for row in top_n_recommendations.collect()]
# 将数据传递给模板
context = {
"user_id": user_id,
"recommendations": recommendation_data # 使用转换后的数据
}
return render(request, "recommendation.html", context)
1::3::3::978301968
1::4::4::978300275
1::5::5::978824291
1::6::3::978302268
1::7::5::978302039
1::8::5::978300719
2::7::7::978302037
2::8::8::978300718
3::1::5::978300760
3::2::3::978302109
4::7::5::178302039
4::8::5::178300719
html
<!DOCTYPE html>
<html>
<head>
<title>电影推荐</title>
</head>
<body>
<h1>电影推荐结果</h1>
<p>为用户 {{ user_id }} 推荐的电影:</p>
<ul>
{% for recommendation in recommendations %}
<li>电影ID: {{ recommendation.movieId }}, 推荐评分: {{ recommendation.prediction }}</li>
{% endfor %}
</ul>
</body>
</html>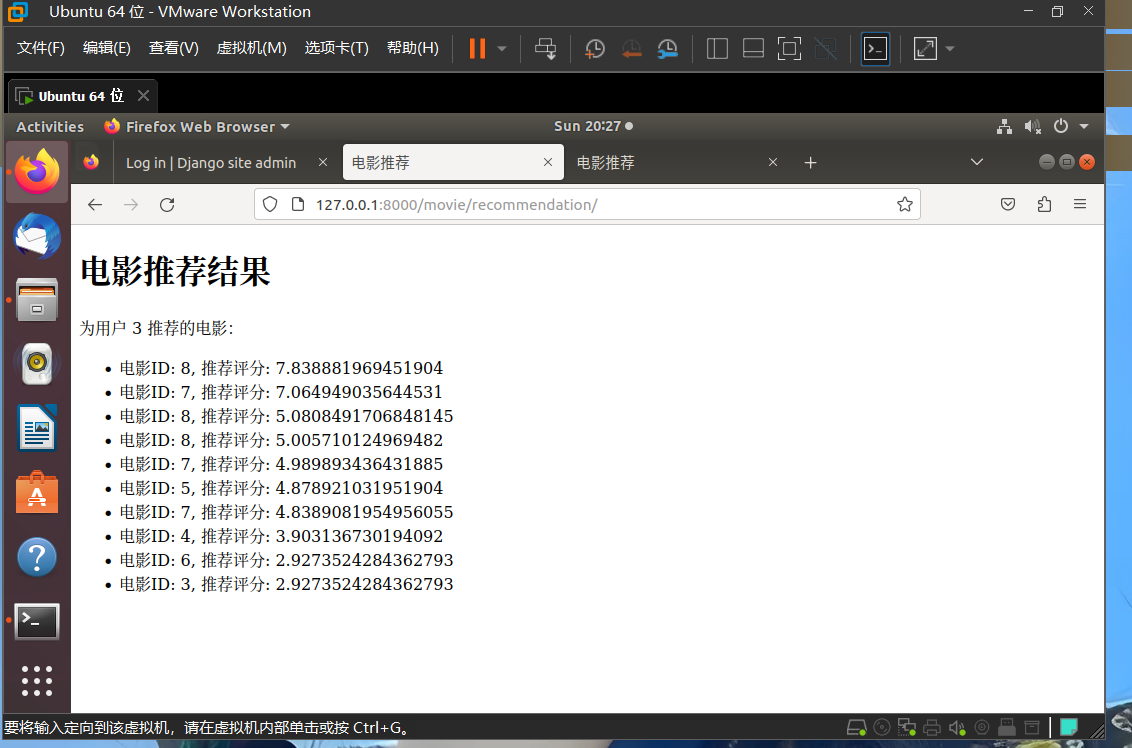
第三步
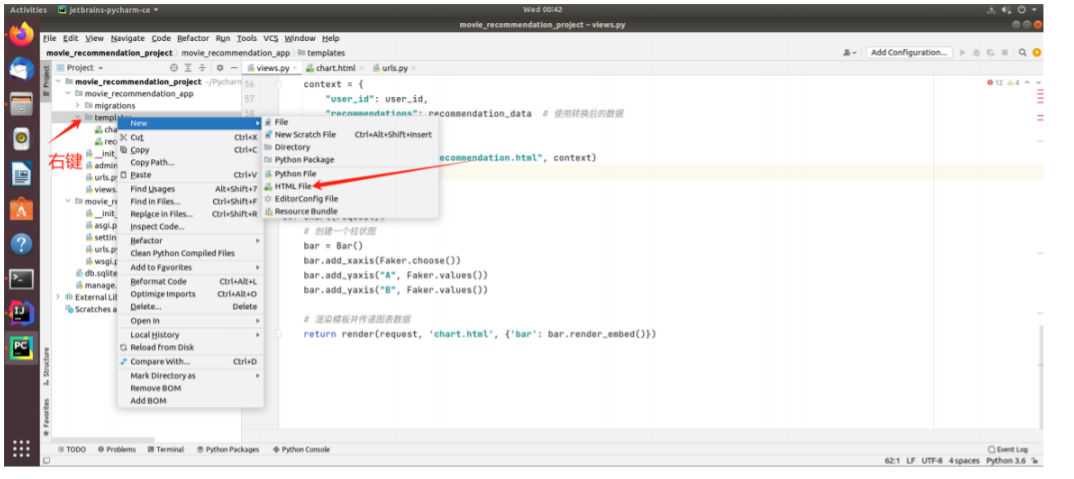
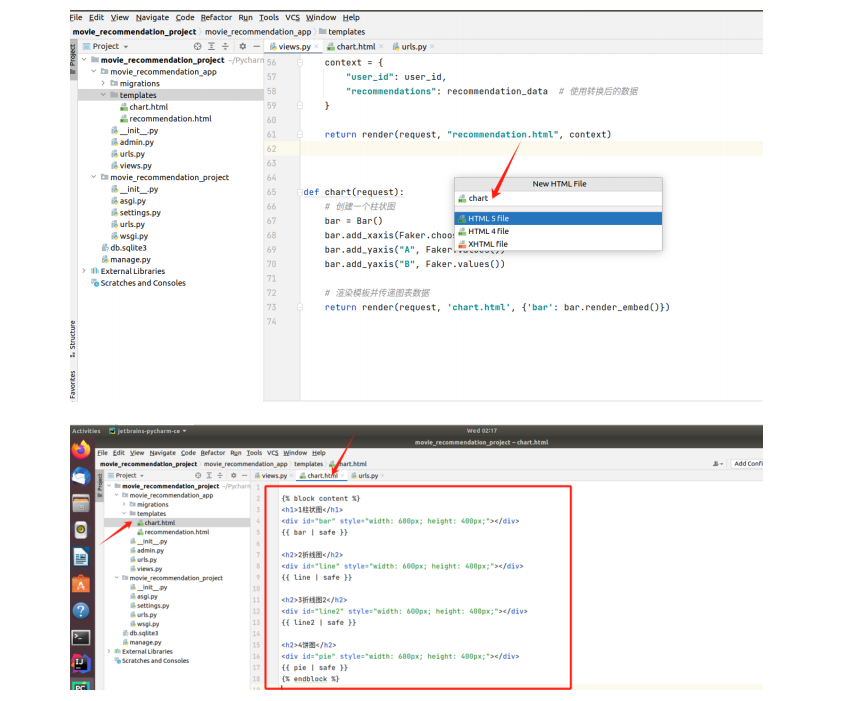

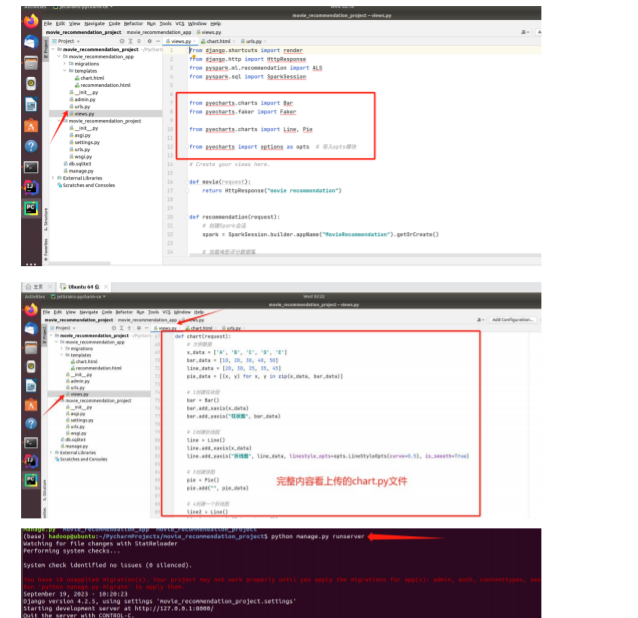
结课
DiVoMiner®-让研究更容易
Django(含 flask)框架下 web 软件任务分工(供参考)
:最多 5 个人一组(得分:100%、90%、
80%、70%、70%),最少 1 个人一组。最后一次实践课展示答辩软件。
1. 数据集导入功能(设置 csv、excel、txt 等格式文件导入按钮,点击可上传导入数据集),
数据集不少于 5000 条,选文本等非结构数据(新浪微博评论、抖音视频评论、领导留
言板数据、裁判文书数据等)加分
2. 数据集统计信息可视化:(
1)基本信息:数据量、行、列数目等(
2)类别数据的占比饼
图
等 等 ,
可 参 考 :
https://me.divominer.cn/projects3. 数据预处理选项按钮(可选择处理哪些列,预处理结果保存为新的列,设置缺失值处理,
数值型数据标准化,类别型数据编码等按钮,按后完成相应操作,文本数据预处理可以
自行增加更多按钮,实现更多预处理功能)
4. 实现如下功能之一即可:分类、聚类、回归、情感分析、主题挖掘等。设置模型选择下
拉菜单,可选择相应模型,选择后,对相应模型进行 分析,分析参考思路:
5. 设置数据分析报告模板(word 文件模板),分析完一键生成分析报告,对应的可视化图、
模型结果、模型评价等信息存入 word 模板,并对话框提示分析报告存放位置。(参考如
下图)。
6. 软件封装成 exe 文件
django
render函数通常需要三个参数,但也可以接受可选参数。这些参数的一般形式如下:
pythonCopy code
render(request, template_name, context, content_type=None, status=None, using=None)- request: 这是HTTP请求对象,通常是request参数。它包含有关用户请求的信息,如请求的URL、HTTP方法、用户的会话等。
- template_name: 这是要渲染的模板文件的名称。它通常是一个字符串,指定要使用的模板文件的路径,相对于您的Django应用中的模板目录。例如,如果您的模板文件位于应用的templates目录下,可以提供模板文件的相对路径。
- context: 这是一个字典,其中包含要传递到模板中以供渲染的数据。这些数据可以在模板中使用,以动态生成页面内容。
- content_type (可选): 这是响应的内容类型(Content Type),通常为字符串,用于指定响应的MIME类型。如果未指定,Django将使用默认的MIME类型。
- status (可选): 这是HTTP响应的状态码,通常是一个整数。如果未指定,Django将使用默认的200 OK状态码。
- using (可选): 这是一个字符串,用于指定要使用的模板引擎的名称。如果您使用的是Django的默认模板引擎,通常不需要指定此参数。如果您在项目中配置了多个模板引擎,可以使用此参数来指定要使用的模板引擎的名称。
urls
urlpatterns = [ path('', views.movie, name='movie'), path('recommendation/', views.recommendation, name='recommendation'), path('chart/', views.chart, name='chart'), ]解释一下这个
这是一个典型的Django应用中的URL映射(URL patterns)定义,它指定了不同URL路径与视图函数之间的映射关系。让我解释这个URL映射的每一部分:
- urlpatterns 是一个列表,其中包含了Django应用的所有URL模式。
- path('', views.movie, name='movie') 是一个URL模式定义。它包括以下三个部分:
-
- ' ':这是URL模式的路径部分。在这种情况下,它是空字符串,表示应用的根URL路径(例如,http://example.com/)。
- views.movie:这是与该URL路径关联的视图函数。在这里,它指定了名为movie的视图函数,通常位于views.py文件中。
- name='movie':这是该URL模式的名称,以便在代码中引用或生成URL时使用。它被设置为'movie',允许您在其他地方引用此URL模式,例如,从模板或其他视图函数中生成链接。
- 同样的逻辑适用于后续的两个URL模式:
-
- path('recommendation/', views.recommendation, name='recommendation'):这个URL模式将路径"/recommendation/"映射到名为recommendation的视图函数,并分配了名字'recommendation'。
- path('chart/', views.chart, name='chart'):这个URL模式将路径"/chart/"映射到名为chart的视图函数,并分配了名字'chart'。
总之,这个URL映射定义允许Django应用在根路径(空路径)、"/recommendation/"和"/chart/"路径上响应不同的视图函数,并为每个路径分配了一个独特的名称,以便在代码中引用和生成URL。这有助于管理应用中的不同URL路径和视图之间的关系。
diango项目创建
django==2.1
pylint
pylint-django
autopep8
pip install -r requirements.txt
pip config set global.index-url Simple Index
创建
django-admin startproject TradingMonitorcd
cd TradingMonitor/
python manage.py migrate
为这个系统添加管理员账户: python3 manage.py createsuperuser
python manage.py createsuperuser #配置用户
————————————————
版权声明:本文为CSDN博主「qq_47150350」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:如何使用虚拟环境搭建一个Django项目_虚拟环境中如何创建django项目-CSDN博客
python manage.py runserver

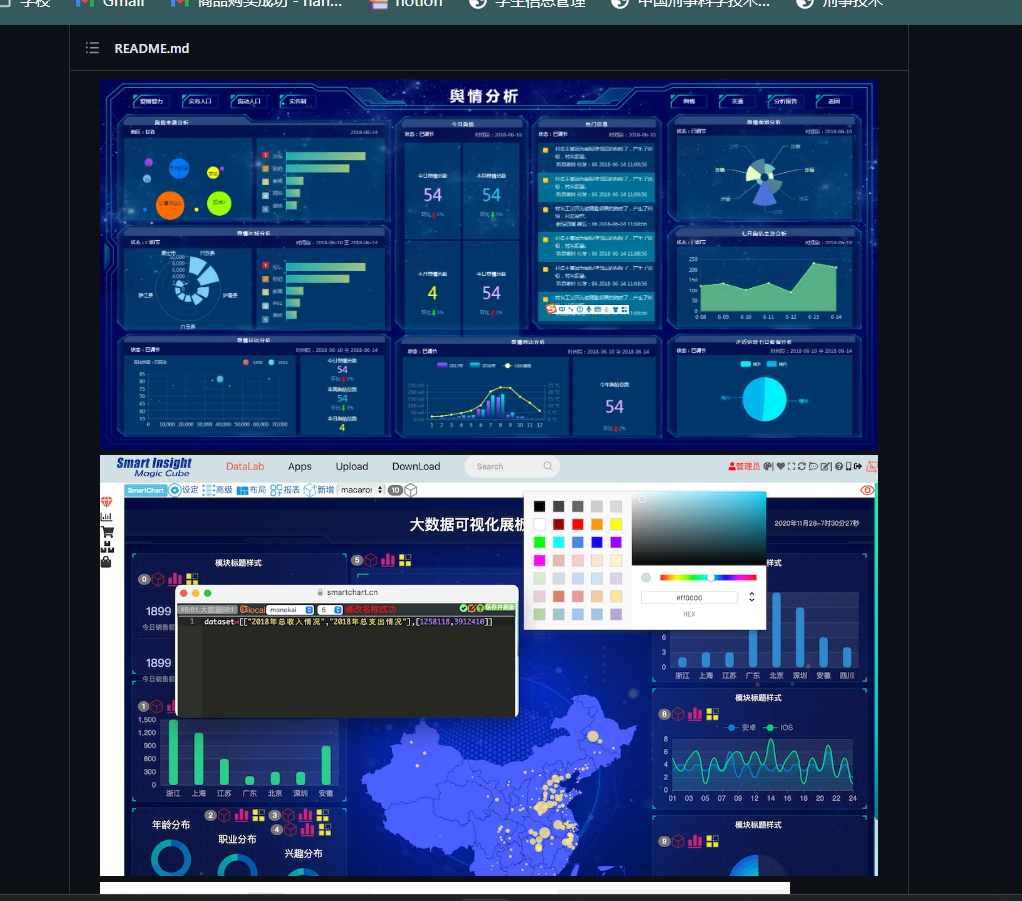
可视化大屏幕
https://github.com/CavalryZsl/Echarts-Django
开发一个整合了Django和PySpark的微博舆情分析软件需要进行一系列的步骤。以下是一个简要的计划,涵盖了主要的开发任务和步骤。请注意,这只是一个起点,实际的开发可能需要根据具体需求进行调整和扩展。
步骤一:环境准备
- 安装Python、Django和PySpark。
- 创建Django项目和应用程序。
步骤二:数据收集
- 使用Django创建一个爬虫或集成微博API,从微博获取舆情数据。
- 将数据存储到数据库中,例如使用Django的模型定义。
步骤三:数据清洗和预处理
- 使用PySpark进行数据清洗和预处理。
- 处理缺失值、去重、文本分词等。
- 将清洗后的数据保存回数据库。
步骤四:情感分析
- 使用PySpark MLlib或其他情感分析库对微博文本进行情感分析。
- 将分析结果与原始数据关联,存储到数据库中。
步骤五:创建Django视图和模板
- 创建Django视图处理用户请求,与数据库交互。
- 使用Django模板渲染前端页面,展示分析结果和可视化。
步骤六:用户认证和权限管理
- 实现用户认证和授权功能,确保只有授权用户可以访问敏感数据和功能。
步骤七:前端交互和可视化
- 使用前端框架(如Vue.js或React)创建交互式的用户界面。
- 利用图表库(如Plotly或Chart.js)展示舆情分析结果。
步骤八:部署
- 部署Django应用程序和PySpark分析任务。
- 使用Docker等工具容器化应用,简化部署过程。
补充建议:
- 性能优化: 对PySpark任务进行性能优化,考虑分布式计算等。
- 异常处理: 添加适当的异常处理机制,确保系统稳定性。
- 日志记录: 在关键部分添加日志记录,以便追踪和调试问题。
- 安全性: 考虑数据的加密、用户身份验证等安全性问题。
以上步骤是一个基本的框架,实际项目中可能需要根据具体需求和团队技能进行调整。在开发过程中,及时测试和迭代是非常重要的,以确保软件的质量和稳定性。