10min速通FSCK、原子操作与VFS
- 文件系统检查器
- 1.检查inode表
- 1) 遍历所有inode
- 2) 修复多次引用数据块
- 2.检查目录结构
- 3.检查目录的连接
- 1) 检查根目录确保存在
- 2) 遍历所有目录的inode,有问题的连接到`/lost+found`
- 4.检查引用次数
- 5.检查位图一致性
- 日志
- 1.主要的数据结构
- 1) 原子操作描述符
- 2) 事务结构
- 3) 日志结构
- 2.原子操作的生成
- 1) 获取原子操作描述符
- 2) 将元数据缓冲区纳入管理
- 3) 获取原数据缓冲区的更新
- 4) 将更新操作加入当前原子操作描述符中
- 3.事务提交
- 4.崩溃的恢复
- 虚拟文件系统
- 简介
- 写了三天,理解了FSCK的底层原理,原子操作和VFS,所以就把笔记发了出来。
在不少的情况下,由于计算机软硬件或人为原因断电、崩溃(crash),如果此时系统正在更新硬盘数据,则可能出现数据一致性问题——崩溃一致性问题(crash-consistency problem)
图1 数据块 索引点 位图关系

然而,磁盘在同一时间只能进行一次I/O操作,硬件层面无法实现,所以文件系统需要在软件层面原子性的从一个状态更新到一个新的状态。
本节将介绍两种解决方案:文件系统检查器和日志。
文件系统检查器
F
i
l
e
S
y
s
t
e
m
C
h
e
c
k
e
r
=
F
S
C
K
File System Checker=FSCK
FileSystemChecker=FSCK
文件系统检查器(File System Checker,FSCK)是解决崩溃一致性问题的一种简单方案。
主要用于解决由于各种原因导致的文件系统不一致性问题,例如系统崩溃、断电、文件系统损坏等。
在处理崩溃一致性问题时,FSCK提供了一种简单而有效的方法来检查和修复文件系统。当文件系统遭受损坏或出现不一致性时,FSCK可以扫描整个文件系统并检测到潜在的错误。一旦检测到错误,FSCK会尝试自动修复它们,以便文件系统恢复到一致状态。
使用FSCK可以确保文件系统的完整性,从而避免数据丢失或文件损坏。它通常在操作系统启动时自动运行,或者可以手动启动以检查特定的文件系统。
在openEuler中,这个工具被称为 e2fsck(以下简称FSCK) ,可以用来检测Ext2/3/4文件系统。
e 2 f s c k e2fsck e2fsck
1.检查inode表
1) 遍历所有inode
这是检查inode表的第一步。inode是文件系统中的一个重要数据结构,用于存储文件或目录的元数据。遍历所有inode是为了检查它们的状态和完整性。
- 检查inode类型字段
i_mode是否合法 - 检查inode记录的文件大小(
i_size_lo与i_size_high) - 检查数据块是否被另一个inode重复引用
2) 修复多次引用数据块
如果一个数据块被多个inode引用,这可能会导致数据不一致或损坏。修复这种情况可以确保数据的一致性和完整性。
- 再次扫描所有inode指向的数据块
- 遍历文件系统树结构
- 对文件系统进行修复
2.检查目录结构
目录是文件系统中组织文件和子目录的方式。检查目录结构可以发现并修复任何目录相关的问题,例如丢失或重复的目录项。
rec_len的值至少为8B,并且不能大于该目录所在数据块中剩余空间大小name_len值小于rec_len-8- inode编号指定正在使用
- 目录第一项为
.(当前目录) - 目录第二项为
..(父目录) - 收集每个目录的inode编号
3.检查目录的连接
这涉及到检查目录项之间的连接关系,确保它们正确地链接在一起,没有断裂或循环引用。
1) 检查根目录确保存在
2) 遍历所有目录的inode,有问题的连接到/lost+found
4.检查引用次数
在文件系统中,某些数据结构或数据块可能被多个地方引用。检查引用次数可以确保这些数据结构或数据块被正确地使用和释放,避免内存泄漏或其他问题。
- 多数inode为未分配,引用次数为0
- 已分配引用次数为1
- 文件目录多链接引用次数大于1
5.检查位图一致性
位图是文件系统中用于跟踪空闲空间的数据结构。检查位图一致性可以确保文件系统能够正确地分配和回收空间。
- 非常耗时,特别是在检索文件系统中的所有索引节点
E x t 4 Ext4 Ext4 - Ext4 对未分配的 inode 做了标记,使 FSCK在检查磁盘时将其整块的忽略掉,大大缩短磁盘检测时间
日志
j
o
u
r
n
a
l
i
n
g
\textcolor{#4183c4}{journaling}
journaling
日志(journaling)机制是现代文件系统(如Linux Ext3/Ext4、Windows NTFS)解决崩溃一致性问题的主流解决方案,借鉴于数据库系统的设计思想,日志系统将将文件系统的更新组织为事务(transaction),使得文件系统的状态为完成或未完成,日志机制将文件系统的状态划分为三种状态:
- 1.日志的写入
- 2.事务的提交
- 3.检查点的添加

-
日志的写入:
- 在日志机制中,每次对文件系统的修改都会首先被写入到一个专门的日志文件中。这个日志文件记录了所有的更改操作,包括数据的读、写、删除等。即对元数据(索引节点、位图等)和数据块做待做更新以日志形式写入磁盘。 实质上,日志是一个无名字的文件,对应inode号为8
- 这种写入操作确保了即使在系统突然崩溃的情况下,文件系统也可以通过这个日志来恢复到一致的状态。因为即使某些修改尚未完全应用到实际的文件系统中,它们在日志中仍然被记录下来,从而可以在恢复过程中重新应用。
-
事务的提交:
t r a n s a c t i o n \textcolor{#4183c4}{transaction} transaction- 在数据库管理中,一个事务是一系列的操作,这些操作要么全部成功,要么全部失败,以确保数据的一致性。在文件系统中,日志机制同样支持 事务(transaction)的概念。
- 当一系列的修改操作被写入日志后,它们被组织成一个事务。只有当这个事务的所有修改都被成功记录到日志中时,才会被称为事务已提交(committed),意味着这些修改现在可以被应用到实际的文件系统中。
- 如果在事务提交之前系统崩溃,由于这些更改已经被记录在日志中,文件系统可以在重启后重新应用这些更改,确保数据的一致性。硬件扇区只保证单位(512B)写入为原子的,为了保证原子性,所以每一个事务结束标志的大小应小于512B。
-
检查点的添加:
c h e c k p o i n t \textcolor{#4183c4}{check point} checkpoint- 检查点(check point)是在文件系统中的某一特定时间点,所有的事务都已经被提交的状态。在日志机制中,检查点起到了一个重要的作用,因为它标记了一个时间点,从那时起,即使发生崩溃,文件系统也可以从这个检查点开始恢复,而不是从头开始。
- 当系统运行时,会定期添加检查点。这意味着如果系统在检查点之后崩溃,重启后恢复过程可以从这个检查点开始,而不是从头开始。这大大减少了恢复时间。
通过这三种状态的管理和操作,日志机制为现代文件系统提供了强大的崩溃一致性保护,确保了数据的完整性和可靠性。
j
b
d
2
=
J
o
u
r
n
a
l
i
n
g
B
l
o
c
k
D
r
i
v
e
r
\textcolor{#4183c4}{jbd2=Journaling Block Driver}
jbd2=JournalingBlockDriver
在Ext4文件系统中,日志机制在 jbd2(Journaling Block Driver) 模块中实现,该模块用于管理缓冲区。
Ext4 文件数据系统

引入jbd2之后,文件系统中的数据在内核、块缓冲区(buffer cache)、磁盘之间的流动如上Mermaid状态图所示。将内核对 缓冲(buffer) 的更新记录到磁盘中的日志空间中

jbd2在管理过程中,Ext4系统将日志系统分为三类:Journal、Ordered、Writeback三种模式。
- journal模式:用户数据、元数据(可靠、两次写入、较慢)
- Ordered模式:元数据更新,写入顺序(先写磁盘再写日志、高性能)
- Writeback模式:记录元数据更新,不保证顺序(可靠性最低、性能最高)
模式选择上,Ordered模式在性能和可靠性上取得了较好的平衡,所以Ordered模式是Ext4文件系统中的缺省模式。
1.主要的数据结构
1) 原子操作描述符
h
a
n
d
l
e
−
t
=
原子操作描述符
=
一个原子操作
\textcolor{#4183c4}{handle _ - t=原子操作描述符=一个原子操作}
handle−t=原子操作描述符=一个原子操作
文件系统需要保证其与更新相关的系统调用(如write)以原子的方式进行处理,而这些系统调用通常由多个I/O此操作组成——原子操作。
每个原子操作的大小到达(阈值)内核操作里的nblocks值时,后续I/O操作将添加到后i一个原子操作。
jbd2中,原子操作的数据结构为struct jbd2_journal_handle,主要成员如下图所示
//源文件:include/linux/jbd2.h
struct jbd2_journal_handle{
union{
transaction_t * h_transaction; /*属于哪个事务*/
journal_t *h_journal; /*属于哪个日志*/
};
int h_total_credits; /*允许添加到日志的剩余缓冲区数目*/
...
};
typedef struct jbd2_journal_handle handle_t; /*原子操作描述符*/
- struct jbd2_journal_handle的部分成员
jbd2_journal_handle_t是 Linux内核中用于处理日志块设备的结构。它是一个原子句柄,用于收集单个高级原子更新期间发生的所有低级更改。原子句柄确保高级更新要么发生,要么不发生,因为实际对文件系统的更改只有在将原子句柄记录在日志中后才会被刷新。此外jbd2_journal_handle_t
还可以将多个原子句柄分组成单个事务,然后在固定时间段后或者日志中没有足够的空间来容纳它时将事务写入日志。事务具有多种状态,包括运行中、锁定、刷新、提交和完成。基于事务状态,JBD能够确定需要重新应用到文件系统的事务。
2) 事务结构
s
t
r
u
c
t
t
r
a
n
s
a
t
i
o
n
−
s
\textcolor{#4183c4}{struct ~transation_-s}
struct transation−s
为了提高读写效率,确保数据的完整性和一致性,jbd2 将若干原子操作组成一个事务,以事务作为单位进行日志读写,具有生命周期性。这些操作要么全部完成,要么全部不完成,以确保数据的一致性。
在jbd2中,事务具有五个状态,分别是:
- 运行状态(Running):事务开始执行,尚未提交或回滚。
- 准备提交状态(Ready to commit):事务的所有操作都已完成,并准备好提交。
- 提交状态(Committing):事务正在被提交。一旦提交成功,事务就会从数据库中删除。
- 回滚状态(Rolling back):事务因为某种原因需要回滚,即撤销已经执行的操作。
- 完成状态(Done):事务已经成功提交或回滚,不再对数据库进行任何操作。
这种事务结构允许jbd2在处理大量数据时保持高效,同时确保数据的完整性和一致性。通过将多个原子操作组合成一个事务,jbd2可以减少日志的I/O操作次数,提高系统的性能。同时,事务的生命周期性使得jbd2可以有效地管理事务的状态和转换,以适应不同的情况和需求。
//源文件 : include/linux/jbd2.h
struct transaction_s {
int state; // 事务状态
// 其他成员变量
};
只有处于运行状态的事务可以进行原子操作

这些成员变量定义了struct transaction_s结构体的属性和行为。
3) 日志结构
s
t
r
u
c
t
j
o
u
r
n
a
l
−
s
\textcolor{#4183c4}{struct ~journal_-s}
struct journal−s
在Linux内核中,日志结构的主要数据结构是struct journal_s,定义在include/linux/jbd2.h文件中。在这个数据结构中,你可以找到关于日志的详细信息,包括日志的初始化、加载、清除、事务处理等操作。这个数据结构在Linux内核中扮演着非常重要的角色,用于管理文件系统的日志功能。
//源文件 : include/linux/jbd2.h
struct journal_s {
int timestamp;
char message[100];
int logLevel;
};
/*在这个示例中,struct journal_s 包含了一个整数类型的时间戳 timestamp,
一个长度为100的字符数组 message 用于存储消息内容,
以及一个整数类型的 logLevel 用于表示日志级别。这个结构体可以根据实际需求进行扩展和修改。*/
2.原子操作的生成
O
r
d
e
r
e
d
\textcolor{#4183c4}{Ordered}
Ordered
在 Ordered 模式下,一个原子操作涉及若干个缓冲区的更新,为了将元数据缓冲区中的数据及时更新生成一个原子操作,jbd2将对这些元数据缓冲区进行管理。内核在jbd2 中获取对将要更新的元数据缓冲区的写权限,以防止覆盖仍处于提交状态的事务中同一缓冲区中的内容。
由此,当内核更新元数据缓冲区时,jbd2 能及时地获取这些更新操作,并将这些更新操作加入原子操作描述符中,以生成新的原子操作。原子操作的生成过程如下图所示,具体分四个步骤。
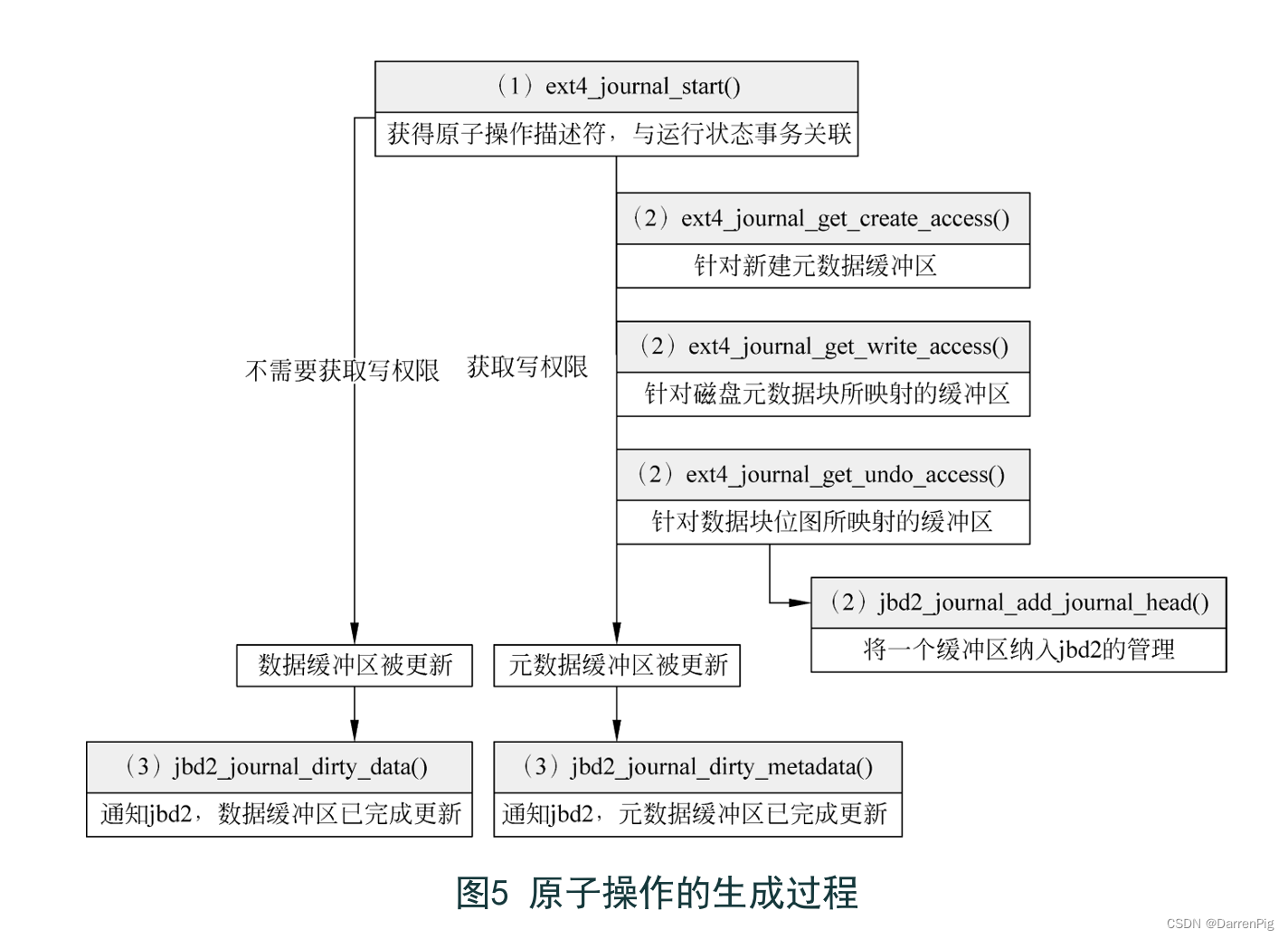
1) 获取原子操作描述符
调用 ext4_journal_start()
参数nblocks指定原子操作包含更新缓冲区域数阈值
2) 将元数据缓冲区纳入管理
e
x
t
4
−
j
o
u
r
n
a
l
−
g
e
t
−
w
r
i
t
e
−
a
c
c
e
s
s
(
)
\textcolor{#4183c4}{ext4_-journal_-get_-write_-access()}
ext4−journal−get−write−access()
内核通过调用函数ext4_journal_get_write_access ,获取磁盘元数据块(除数据位图外)所映射缓冲区的写权限。由于数据位图的更新涉及数据块的分配和释放,因此其所映射的缓冲区具有更严苛的写权限。内核通过调用函数ext4_journal_get_undo_access(),获取该类缓冲区的写权限。此外,内核通过调用函数ext4_journal_get_create_access(),获取新建元数据缓冲区的写权限。这三个函数在执行时,都先通过调用函数jbd2_journal_add_journal_head(),将当前元数据缓冲区纳人jbd2 的管理。
3) 获取原数据缓冲区的更新
在元数据缓冲区完成更新操作后,内核通过调用函数jbd2_journal_dirty_metadata(),通知jbd2 发生了元数据缓冲区更新操作。
4) 将更新操作加入当前原子操作描述符中
达到阈值,jbd2生成一个原子操作。
3.事务提交
当生成的原子操作数量达到阙值,jbd2将事务推人锁定状态,并将其加入等待提交的队列中。openEuler 专门维护了一个内核线程提交事务(每个Ext4 文件系统都对应一个kjournald 内核线程)。该线程每隔一定的时间在等待提交队列中选择一个事务,并通过调用函数 kjournald2(),把该事务提交到磁盘的日志区。事务提交主要由函数 kjournald2()调用的函数 jbd2_journal_commit_transaction()完成。
j
b
d
2
−
j
o
u
r
n
a
l
−
c
o
m
m
i
t
−
t
r
a
n
s
a
c
t
i
o
n
(
)
\textcolor{#4183c4}{ jbd2_-journal_-commit_-transaction()}
jbd2−journal−commit−transaction()
(1)调用函数 jbd2_journal_commit_transaction(),将当前事务中元数据所关联的数据缓冲区中的内容写人磁盘(第5行)。
(2)调用函数 jbd2_journal_write_metadata_buffer(),将元数据缓冲区中的数据写人磁盘的日志区中。具体地,jbd2先创建一个新的元数据缓冲区,然后将当前元数据缓冲区的内容复制至这个新的元数据缓冲区( 第28行),再将新的元数据缓冲区映射到日志区的某个数据块,最后完成写人。
源文件:fs/jbd2/commit.c
void jbd2_journal_commit_transaction(journal_t * journal) {
//将数据缓冲区的内容写人磁盘
err = journal_ submit_data_buffers(journal, commit_transaction);
while (commit_ transaction - › t_buffers) /
jh = commit_ transaction - > t_ buffers;
//将元数据缓冲区写人日志区
Flags = jbd2_ journal
_write_metadata_buffer(
commit_ transaction, jh, &wbuf [bufs], blocknr) ;
//源文件:Es/jbd2/journal.c
int jba2_ journal
_write_metadata_buffer(transaction_t * transaction,
struct journal
head
*jh_
in,struct buffer_head
** bh out,
sector_t blocknr) {
//创建新元数据缓冲区
new_bh = alloc_buffer_head (GEP_NOFS__GEP NOFAIL) ;
init_buffer(new_bh, NULL, NULL);
1/初始化新元数据缓冲区
new_jh = journal_add_journal_head(new_bh); //纳人 jbd2 的管理
new _page = jh2bh(jh_ in) - > b_ page;
//当前元数据缓冲区对应的物理页
mapped_data = kmap_atomic(new_page) ;
//获得该页起始地址
//页内容复制到 tmp
memcpy tmp, mapped_data + new_offset, bh_ in - > b_size) ;
new_page = virt_to_page (tmp) ;
//将 tmp 转换成新页 new_page
/将新页设为新元数据缓冲区对应页
set_bh_page( new_bh,new_page, new_offset);
//新元数据缓冲区映射到日志区中块号blocknr 的数据块new_bh->b_blocknr = blocknr;
set_ buffer_dirty (new_bh) ;
//将 new_bh 标记为脏
4.崩溃的恢复
d o − o n e − p a s s ( ) \textcolor{#4183c4}{ do_-one_-pass()} do−one−pass()
崩溃的恢复流程如下:
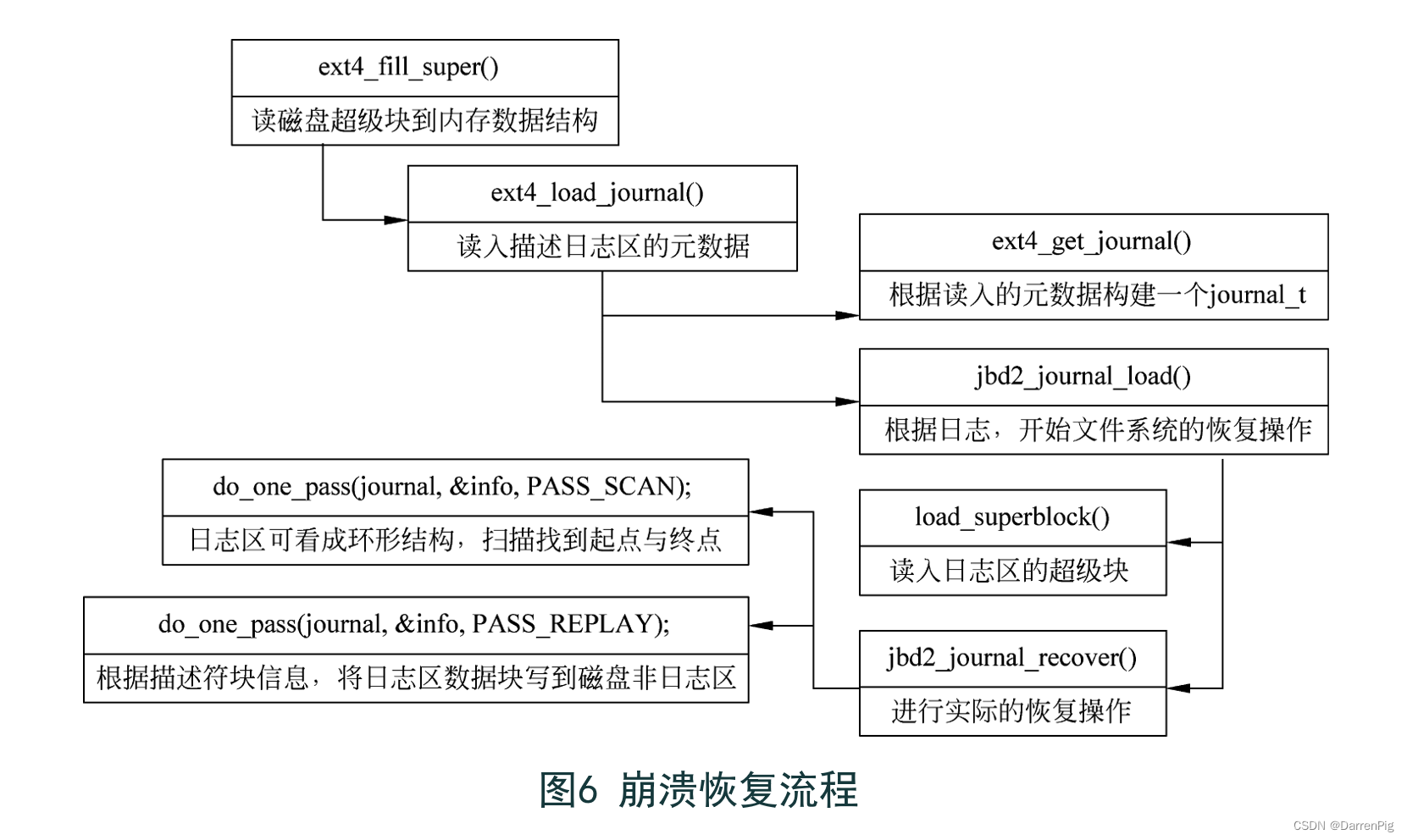
/源文件:fs/jbd2/recovery. c
1/当传人参数 PASS.
SCAN 时
unsigned int
first_commit_ ID, next_commit_ ID;
1/临时记录起点与终点
sb = journal ->j_superblock;
next_commit_ ID = be32_to_ cpu(sb - > s_ sequence) ;
first_commit_ ID = next_ commit_ID;
/起点为目志区超级块记录的起始数据失易
if(pass == PASS_SCAN)info->start_transaction = first_commit_ID;
//遍历日志区,查看哪些日志区数据块需要恢复到磁盘,以此找到日志区数据块的终点
done:
if (pass == PASS_SCAN)
info - > end
_transaction = next_commit_ ID;
//当传入参数 PASS_REPLAY 时
while (1) {
1/遍历日志区的数据块
err = jread(&bh, journal, next_log_ block) ;
//读下一个数据块到bh中
tagp = &bh - > b_ data[ sizeof (journal_header_t)];//找到描述符块
//根据描述符块记录的映射关系逐一处理数据块
while((tagp - bh->b_data + tag_bytes)
<= journal - > j_blocksize - descr_csum_size) /
/读其中一个日志区数据块到 obh 中
err = jread(&obh,journal,io_block);
1/从描述符块获得该日志区数据应被写入的磁盘数据块号
blocknr = read _tag_block(journal, tag)
函数 do_one_pass()将日志数据写回磁盘原始位置的关键代码
- jbd2 在首次调用函数 do_one_pass() 时,以PASS_SCAN 作为输入参数,用于方便日志区的回收和遍历。函数会读取超级块获取起点,并遍历日志区获取终点。
- 当 jbd2 再次调用函数 do_one_pass() 时,以PASS_REPLAY 作为输入参数。函数会遍历数据块并获取与磁盘中数据块的映射关系,然后将日志中的数据块内容读入缓冲区,并标记为 obh 。接着找到磁盘中该数据块在内存中对应的缓冲区,标记为 nbh,并将 obh 中的内容复制到 nbh 中。最后将 nbh 标记为脏,脏的缓冲区将被自动写回磁盘中。
- 日志机制相对于 FSCK 而言,可以大大缩短磁盘崩溃恢复时间,从而在崩溃并重新启动后加快恢复速度。
- 日志机制有效地保证了文件系统元数据的一致性。在更新元数据时,首先将元数据写入日志区域,然后再更改目标位置的元数据。这样,无论是在写入日志还是写入元数据时系统发生崩溃,都不会对文件系统造成严重影响。
6. 当传入参数为 `PASS_SCAN` 时:
* 获取日志区的起点和终点。
* 记录起点为日志区超级块记录的起始数据块。
* 如果传入的参数是 `PASS_SCAN`,则将起点设置为第一个提交的ID。
* 遍历日志区,查看哪些日志区数据块需要恢复到磁盘,以此找到日志区数据块的终点。如果传入的参数是 `PASS_SCAN`,则将终点设置为下一个提交的ID。
7. 当传入参数为 `PASS_REPLAY` 时:
* 遍历日志区的数据块。
* 读取下一个数据块到 `bh` 中。
* 找到描述符块,并根据描述符块记录的映射关系逐一处理数据块。
* 读取其中一个日志区数据块到 `obh` 中。
* 从描述符块获得该日志区数据应被写入的磁盘数据块号。
根据上述梳理,这段代码似乎是在处理文件系统日志的恢复过程,特别是当系统崩溃后,需要从磁盘中恢复数据时。它首先通过 `PASS_SCAN` 参数确定日志区的起点和终点,然后根据这些信息在 `PASS_REPLAY` 参数下恢复数据。
虚拟文件系统
简介
虚拟文件系统(
V
i
r
t
u
a
l
F
i
l
e
S
y
s
t
e
m
,
V
F
S
)
虚拟文件系统(Virtual File System,VFS)
虚拟文件系统(VirtualFileSystem,VFS)
现代操作系统支持同时使用多种文件系统。
在计算机科学中,虚拟文件系统(Virtual File System,VFS)是一个抽象层,它允许应用程序和操作系统与各种不同类型的物理文件系统进行交互。VFS 隐藏了物理文件系统的底层细节,使应用程序和操作系统能够以统一、标准化的方式来访问和管理文件和目录。
通过使用 VFS,操作系统可以同时支持多种不同的文件系统,例如EXT4、NTFS、FAT32等。这样做的目的是为了提供更大的灵活性和可扩展性,因为新的文件系统或对现有文件系统的改进可以很容易地添加到系统中,而无需对应用程序或操作系统进行任何修改。
此外,VFS 还提供了一些额外的功能和优点,包括:
- 可移植性:应用程序可以在不同的操作系统或平台上运行,只需进行少量修改或无需修改,因为 VFS 隐藏了底层文件系统的差异。
- 性能优化:VFS 可以根据需要缓存文件数据和元数据,从而提高访问速度。
- 安全性:VFS 可以提供额外的安全层,例如权限控制和加密,以确保文件系统的安全性和完整性。
- 集成和互操作性:VFS 可以与其他软件组件和服务集成,例如网络文件共享和分布式文件系统。
数据结构先欠着,等大家可以先投票~








![【C++入门到精通】智能指针 auto_ptr、unique_ptr简介及C++模拟实现 [ C++入门 ]](https://img-blog.csdnimg.cn/direct/ad0cc2887ce140ed8f11e8276788b498.png#pic_center)