文章目录
- 一. Linux软件包管理器-yum使用
- 1. Linux 安装软件的方式
- 2. yum 三板斧
- yum list
- yum install
- yum remove
- 二. Linux编辑器-vim使用
- 1. vim 的基本概念
- 2. vim 的基本操作
- 3. vim 的命令模式命令集
- 4. vim 底行模式命令集
- 三. Linux编译器-gcc/g++使用
- 1. 快速使用
- 2. 程序翻译过程
- 预处理
- 编译
- 汇编
- 链接
- 3. 函数库
- 四. Linux项目自动化构建工具-make/makefile
- 1. 认识 make 和 makefile
- 2. makefile 语法补充和工作原理
- `$@` 和 `$^`
- 工作原理
- 根据修改时间进行判断
- .PHONY
一. Linux软件包管理器-yum使用
1. Linux 安装软件的方式
在 Linux 下安装软件一共有三种方式:
-
源代码安装
有很多开源软件的源代码会被作者放在Github/Gitee 等网站上, 可以将这些源代码下载在本地.通过直接在本地将这些源代码进行编译链接生成可执行程序.
在嵌入式编程中, 经常用到交叉编译来处理不同平台的适配性. -
rpm包直接安装
Linux 下的安装包, 需要用到rpm命令进行安装, 同时需要自己解决软件依赖的环境. -
yum/apt-get
在 Centos 下的下载指令是yum, Ubuntu 下的下载指令是apt-get
yum是工具/指令/程序安装, 是 Linux 预装指令, 搜索,下载和安装对应软件.
2. yum 三板斧
yum 相当于手机上的应用软件市场, 只要是 yum 的远端服务器上面有的软件, 都可以通过 yum 指令进行安装.
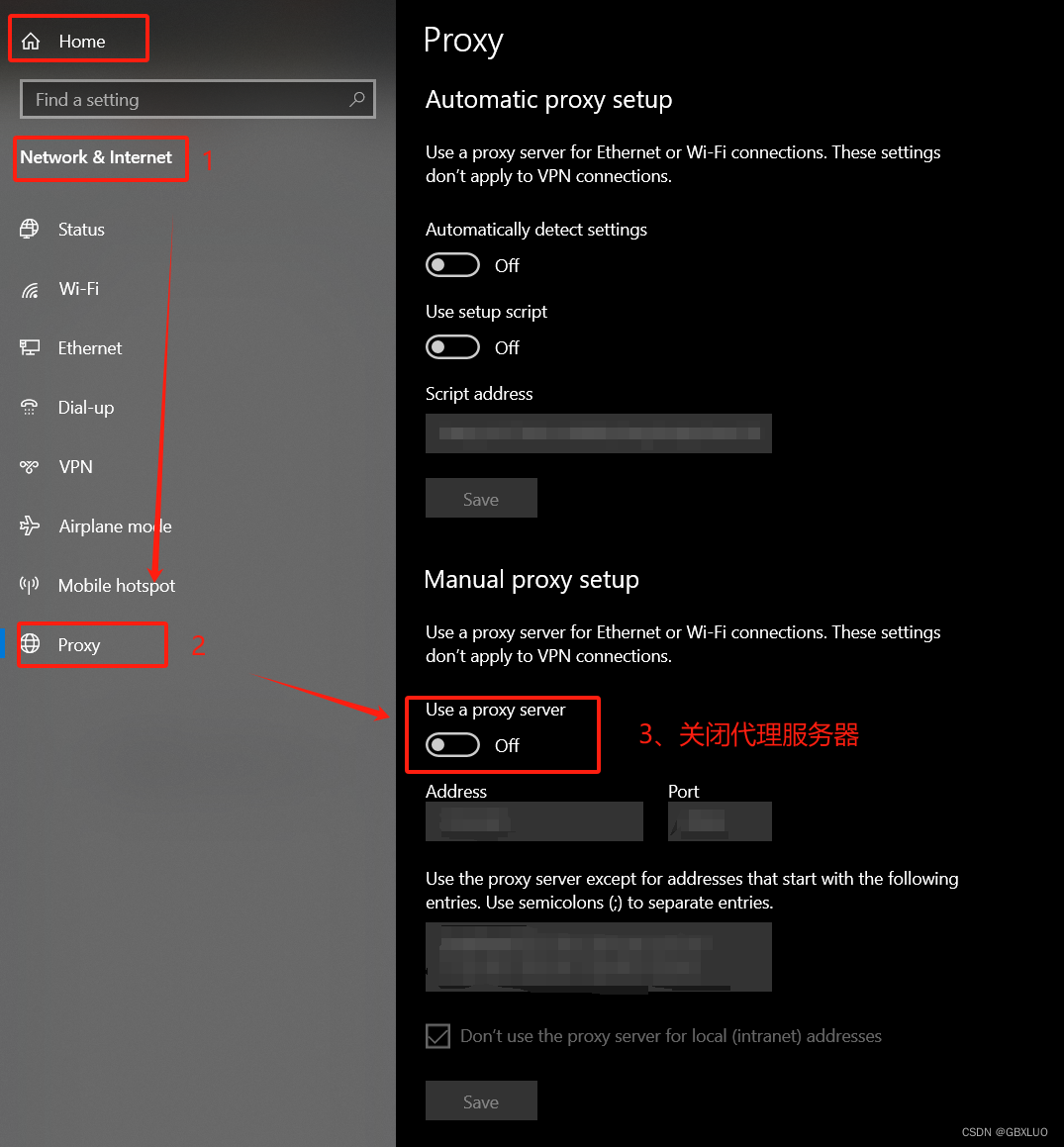
在使用 yum 之前, 如果是虚拟机, 需要将对应的 yum 源进行修改. 默认是官方源, 由于某些原因, 下载速度极慢.
国内有很多优秀的源, 例如阿里云源, 清华源, 中科大源等等.
源文件的路径为 /etc/apt/sources.list, 在网上查找相关源的地址, 将原来的文件进行备份后, 进行替换, 随后 update 即可.
确保机器联网, 并且用户为 root 或者 用户可以使用 sudo
yum list
yum list 查看软件列表
可以查看可通过 yum 下载的所有软件的列表
yum list | grep [软件名] 可以查找相关的软件
比如输入 yum list | grep sl 得到以下结果

yum install
yum install [软件名] 可以下载并安装指定软件, 可添加 -y 忽视确认, 安装前会评估安装包大小, 判断硬盘是否有足够大小
注意:要在 root 下下载, 或者 sudo 下载

提示完毕, 安装完毕.
直接运行 sl, 可以看到有个小火车运行出来了
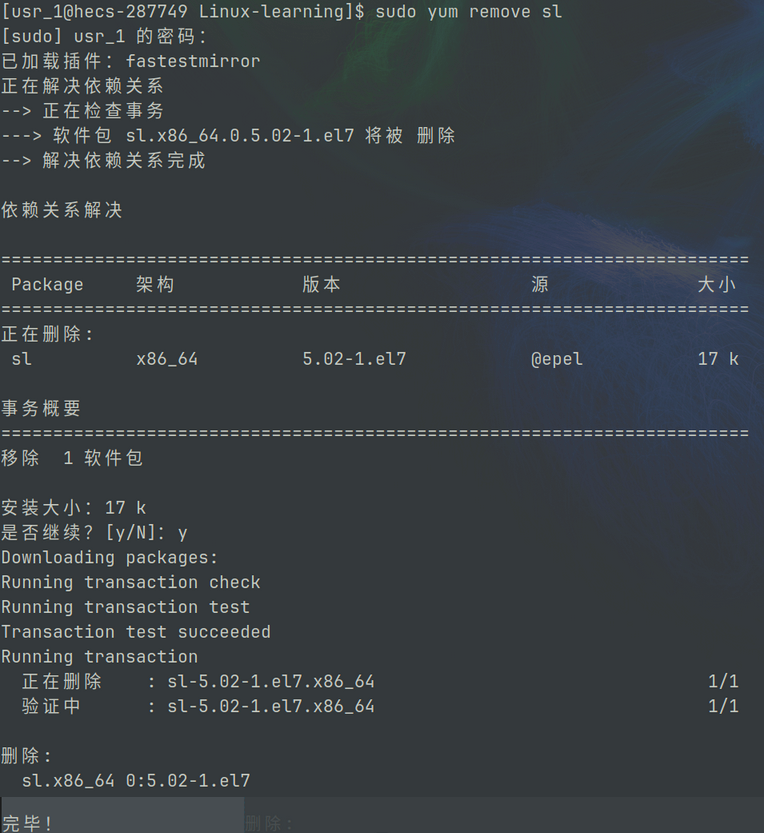
yum remove
通过 yum remove 可以卸载已经安装的软件
二. Linux编辑器-vim使用
vim 是多模式的编辑器, 本身只是一个记事本, 不能进行编译链接.
1. vim 的基本概念
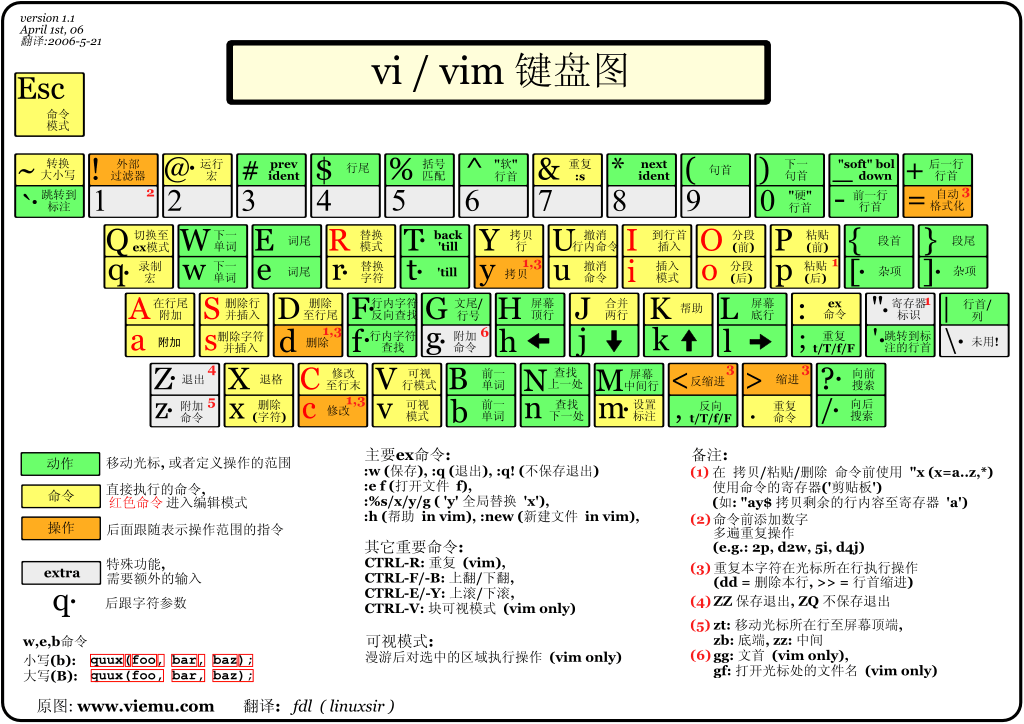
vim 有很多模式, 常用到的有三种: 命令模式(command mode), 插入模式(insert mode) 和底行模式(last line mode), 各模式的区分如下:

通过 vim 打开一个文件, 默认进入命令模式, 可以按照以下方式进行模式间的转换.
注意: 插入模式不能直接进入底行模式, 底行模式不能直接进入插入模式
2. vim 的基本操作
下面简单展示以下用 vim 写一个 c程序 的流程
-
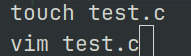
首先
touch test.c创建一个c源文件
vim test.c使用 vim 打开这个文件
-
进入默认是命令模式, 可以移动光标, 但是不可以输入
-
键盘按 i 可以进入插入模式, 随后将 c程序的代码进行输入

-
要想保存该文件, 需要进入底行模式, 按 [ESC] 先进入命令模式, 随后 [shift + ; + wq] 保存并退出
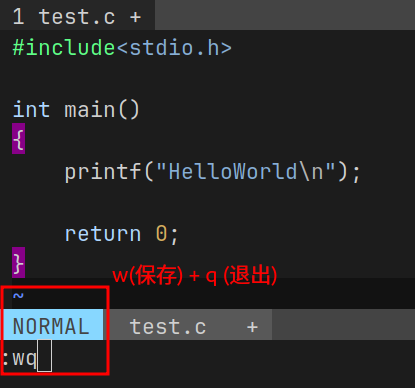
这就是使用 vim 的基本操作.
3. vim 的命令模式命令集

| 按键 | 操作 |
|---|---|
| 移动光标 | |
[h], [j], [k], [l] | 分别控制光标左, 下, 上, 右移一格 |
[G](shift + g) | 移动到文本的最后 |
[gg] | 移动到文本的开始 |
[nG](n + shift + g) | 移动到文本第n行 |
[^](shift + 6) | 移动到光标所在行的"行尾" |
[$](shift + 4) | 移动到光标所在行的"行首" |
[w] | 光标跳到下一个字的开头 |
[b] | 光标跳到上一个字的开头 |
| 复制 | |
[yw] | 光标所在之处到字尾的字符复制到缓冲区 |
[nyw] | 复制 n 个字符到缓冲区 |
[yy] | 复制光标所在行到缓冲区 |
[nyy] | 复制从改行往下数 n 个行到缓冲区 |
[p] | 将缓冲区内的字符粘贴到光标所在位置. 注意所有的y有关的指令都必须与p配合才能完成复制与粘贴功能 |
[np] | 将缓冲区内的字符粘贴 n 次 |
| 删除 | |
[x] | 删除光标所在位置的一个字符 |
[nx] | 删除光标所在位置开始后面 n 个字符 |
[X] | 删除光标所在位置前面一个字符 |
[nX] | 删除光标所在位置前面 n 个字符 |
[dd] | 删除光标所在行 |
[ndd] | 从光标开始删除 n 行 |
| 替换 | |
[r] | 替换光标所在的字符 |
[R](shift+r) | 替换光标所到之处的字符, 直到按下 [ESC] 为止 |
[~](shift + `) | 光标所在字符转换大小写; A->a, a->A |
| 撤销 | |
[u] | 回到上一命令, 可以多次撤销 |
[ctrl + r] | 撤销恢复 |
| 查找 | |
[#](shift + 3) | 查找光标所在单词, 按 n 可以跳转到下一个 |
4. vim 底行模式命令集
在使用底行模式之前, 确保自己已经按 [ESC] 进入命令模式, 再按 [:] 即可进入底行模式
| 按键 | 操作 |
|---|---|
[set nu] | 列出行号 |
[n] | 跳转到第 n 行 |
[/关键字] | 从光标开始向后查找关键字, 按 n 往后寻找 |
[?关键字] | 从光标开始向前查找关键字, 按 n 往前寻找 |
[w] | 保存文件 |
[q] | 退出vim, 无法离开可 [q!]强制退出 |
[wq] | 退出并保存文件 |
[!command] | 在bash命令行输入 command |
[vs filename] | 分割窗口打开 filename , [ctrl + w + h/j/k/l] 可移动至某个窗口 |
三. Linux编译器-gcc/g++使用
1. 快速使用
在 Linux 下, 使用 gcc/g++ 编译 C/C++ 程序
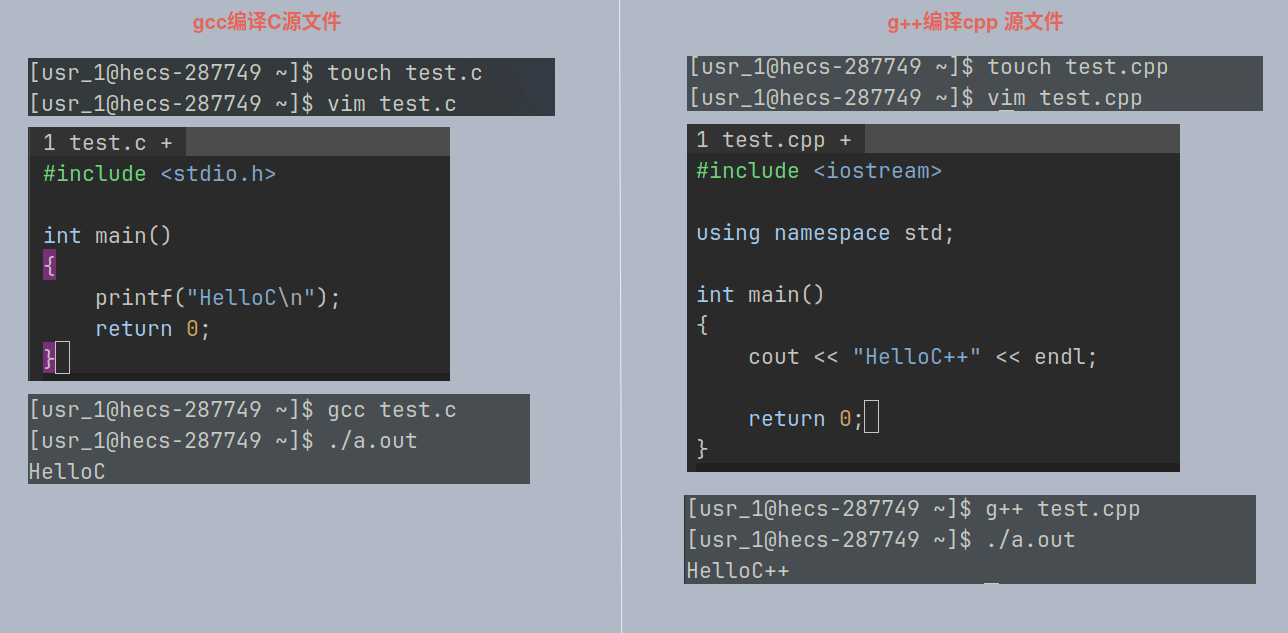
默认生成 a.out 文件, 可通过 -o 选项生成指定程序文件名, 与 -o 紧邻的是生成的可执行程序文件名

2. 程序翻译过程
程序翻译就是把高级语言翻译成二进制的过程
计算机语言大致是如下演绎过程
机器语言(二进制)->汇编语言->高级语言(C/C++/Python/Java)…
要将高级语言翻译成二进制, 就需要先翻译成汇编语言, 再将汇编语言翻译成二进制.
翻译一个C程序主要有四个步骤: 预处理, 编译, 汇编, 链接.

预处理
gcc -E test.c -o test.i
-E: 进行程序翻译, 到预处理阶段结束停止.预处理后生成的文件还是C源文件
预处理阶段主要做四件事:
- 头文件展开
- 去注释
- 宏替换
- 条件编译
这里我创建了一个 test.c 来进行程序翻译过程
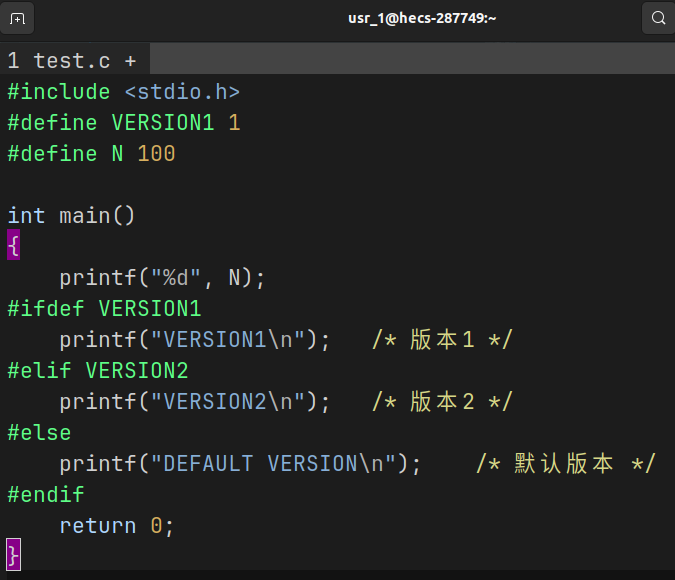
头文件展开
预处理后, 打开 test.i , 发现程序多了800行

多出来的就是 <stdio.h> 文件里的内容, 该文件存放在 /usr/include/stdio.h:
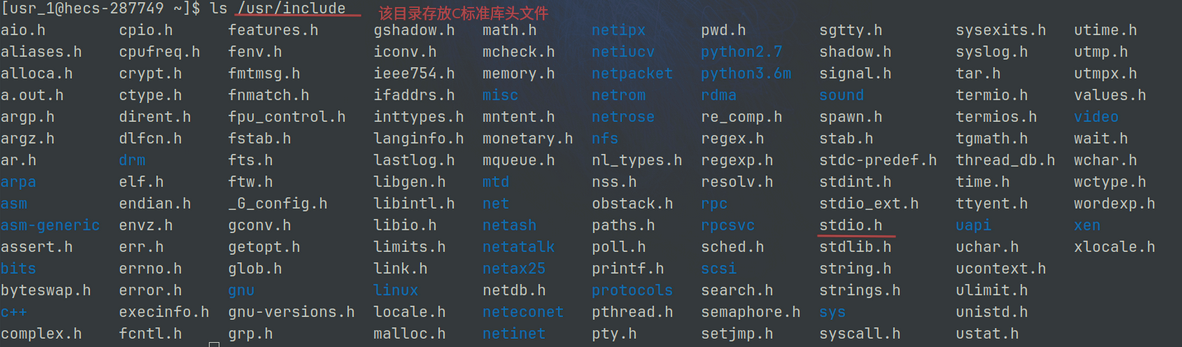
头文件展开就是将该文件拷贝到对应源文件中, 源程序中要用到的printf的函数声明就在该头文件中:

刨去头文件展开造成的差异, 继续到文件末, 检查有何不同.
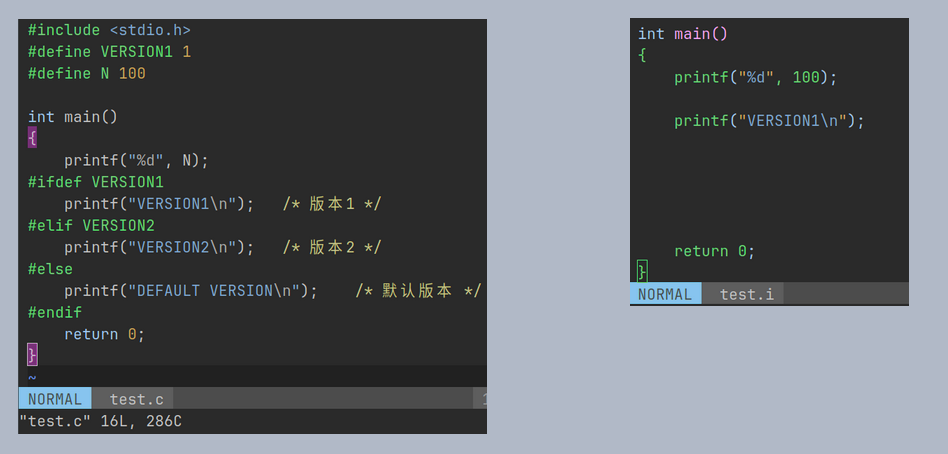
去注释
经过预处理阶段, 所有的注释都被去除了
宏替换
定义的宏 #define N 100, 预处理后, N 被直接替换成了 100
条件编译
由于定义了宏 VERSION1, 最终只保留了 printf("VERSION1\n");
可使用 -D 选项, 在翻译阶段指定宏
将源文件的 #define VERSION1 1 删去, 进行如下预处理

此时 test.i 只保留了 printf("VERSION2\n");
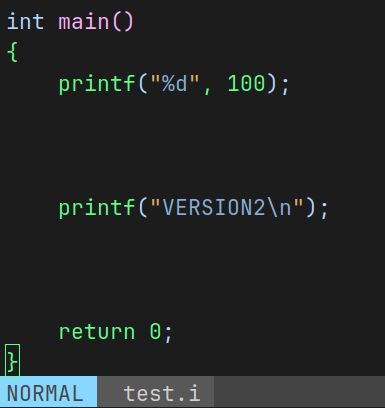
条件编译的本质是可以通过给编译器不同宏值达到动态裁减
例如 Visual Studio 有很多版本
那么是如何维护这些不同版本的代码呢?
本质上只有一份代码, 采用了类似条件编译的策略, 社区版就将专业版的代码进行裁减, 实现同一份代码对软件的多版本维护.
更多有关预处理的内容, 可见我之前的博客C语言程序环境及预处理
编译
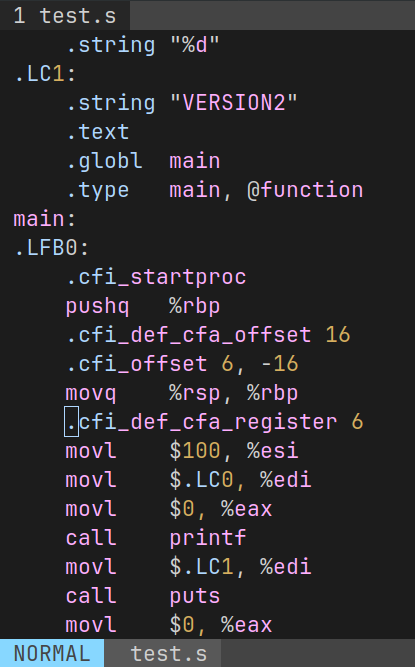
gcc -S test.i -o test.s
-S: 开始程序翻译, 编译阶段做完就停止.编译后生成的文件内容是汇编代码
打开 test.s, 都是助记符的格式
汇编
gcc -c test.s -o test.o
-c: 开始程序翻译, 汇编阶段做完就停止. 汇编后生成的文件是可重定位目标文件(.obj), 不可以执行
此时文件是二进制文件了, 但是没有符号重定位以及位段合并.

给该文件添加执行权限后, 仍然是运行不了

链接
预处理阶段有头文件展开的行为, 但是展开的只是头文件, 只有库函数声明, 没有库函数实现, 这就是为什么汇编后的文件不能执行的原因.
链接就是将.o文件与C标准库实现进行关联.
gcc -o test test.o
最后生成可执行文件

3. 函数库
头文件展开的时候, 之后库函数声明被拷贝到源文件中, 但是其函数定义却没有被拷贝进来.
程序翻译阶段最后一步链接, 就是让程序能找到这些库函数在库文件中的定义.
lld 命令可以看到可执行程序依赖的库文件, 不仅是自己写的程序, Linux 的指令也有依赖的库文件. 下面的 libc.so.6 就是动态库名称.
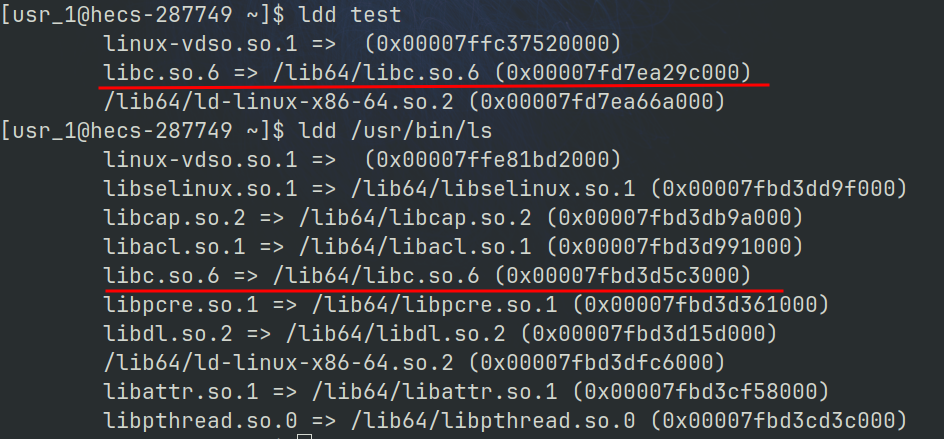
动态库和静态库
库文件分为两种: 动态库和静态库
动态库: .so(Linux) .dll(Windows)
静态库: .a(Linux) .lib(Windows)
Linux 系统默认已经提供了C语言的头文件和动态库文件
头文件在 /usr/include
库文件在 /lib64
上面看到的C标准库文件就在 /lib64 中, 这是动态库的文件

Linux默认不提供静态库文件, 若需要安装C/C++静态库库文件, 需要执行以下代码
sudo yum install glibc-static libstdc++-static
动态链接和静态链接
| 链接方式 | 操作 | 优点 | 缺点 |
|---|---|---|---|
| 动态链接 | 并不把代码实现拷贝到可执行程序中, 形成符号与动态库中实现进行链接, 是关联. | 节省资源(磁盘,网络,内存资源) | 对库的依赖性较强, 一旦库丢失, 所有使用这个库的程序都无法运行 |
| 静态链接 | 直接将库函数代码拷贝到可执行程序, 代码和库实现都要家再到内存中, 是拷贝 | 不依赖库, 同类型平台都可以使用运行 | 可执行程序体积比较大, 比较浪费资源 |
gcc/g++ 默认使用动态链接, 可以通过file指令, 查看可执行程序的文件属性进行验证

-static 选项可以在链接阶段进行静态链接

可以看到, 静态链接生成的可执行文件与动态链接形成的可执行文件相比, 体积大了不少

四. Linux项目自动化构建工具-make/makefile
在面对大型项目的时候, 就有了自动化构建进行编译的需求, 假设一个项目中有100个 .c 文件, 不可能手动进行 gcc 命令, 一个一个生成 .o 文件, 再进行链接. 这样子极其容易出错.
在 VisualStudio, 这样的操作一个按钮就可以实现, Linux 提供了 make 命令进行自动化构建.
makefile 带来的好处就是–“自动化编译”, 一旦写好, 只需要一个 make 命令, 整个工程完全自动编译, 极大的提高了软件开发的效率.
1. 认识 make 和 makefile
make 是命令, makefile 是命令依赖的文件, 文件内容是依赖关系和依赖方法.
语法规则如下:
target...:prerequisites...
command
...
- target 是目标文件, 可以是
.o,.s,.i; 也可以是最终生成的可执行文件名; 还可以是伪目标(涉及项目文件清理需要用到) - prerequisites: 要生成 target 所需要的文件或者目标
- command: make需要生成的命令, 通过 command 通过 prerequisites 生成 target. 注意换行前需要加[TAB]
假设现在只有一个源文件 test.c, 那么 最简单的 makefile 如下:
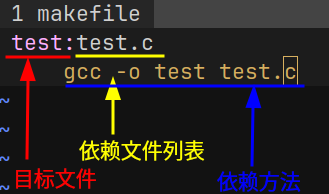
在 bash 使用 make 命令即可生成 test 可执行文件

现在来完善一下 makefile, 解释源文件推荐先生成.o文件, 再进行链接
同时, 可以添加 clean 伪目标文件, 实现项目的快速清理
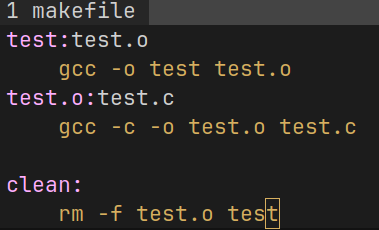
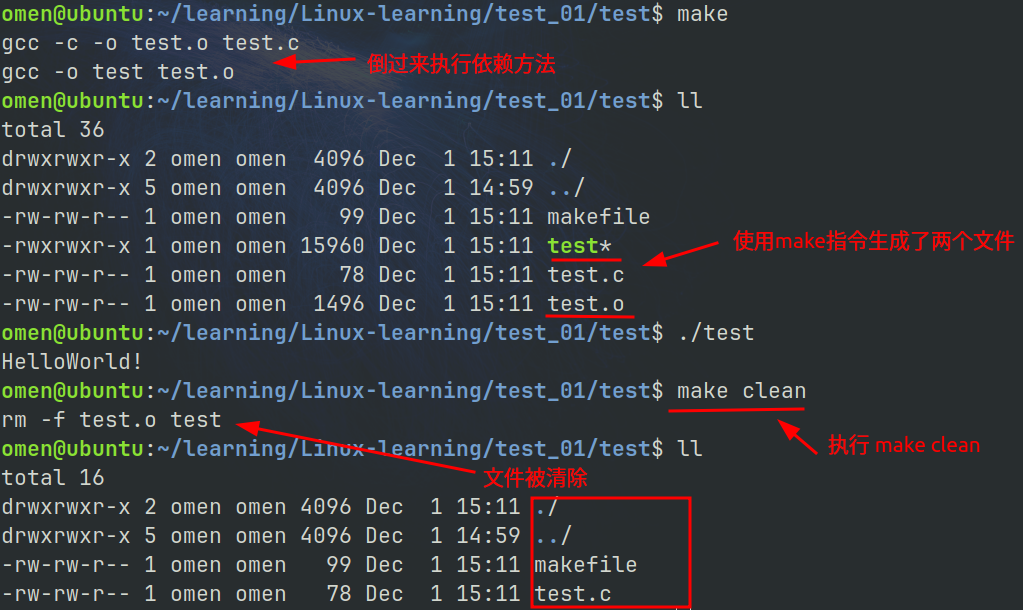
make命令默认生成第一个目标文件
所以上面默认生成了 test 目标文件
需要生成 clean 伪目标时就需要显式指定 make clean
2. makefile 语法补充和工作原理
这里给一个稍微复杂一点的项目: 该项目拥有一个头文件和两个源文件
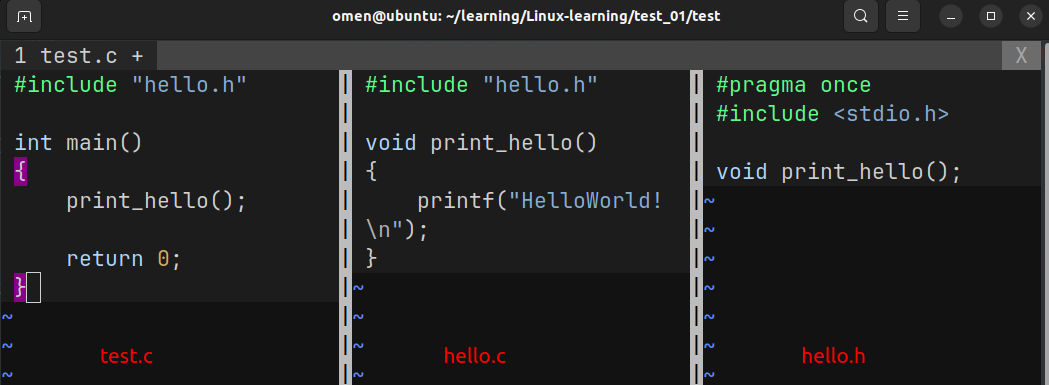
makefile 需要这样写:
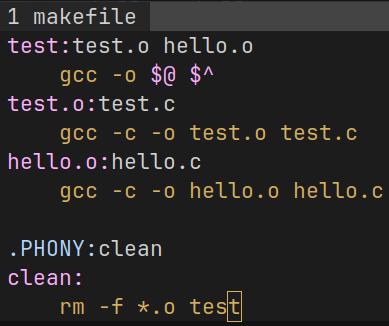
$@ 和 $^
$@: 目标文件
$^: 源文件
只可以在生成最后可执行文件的时候这样写.
工作原理
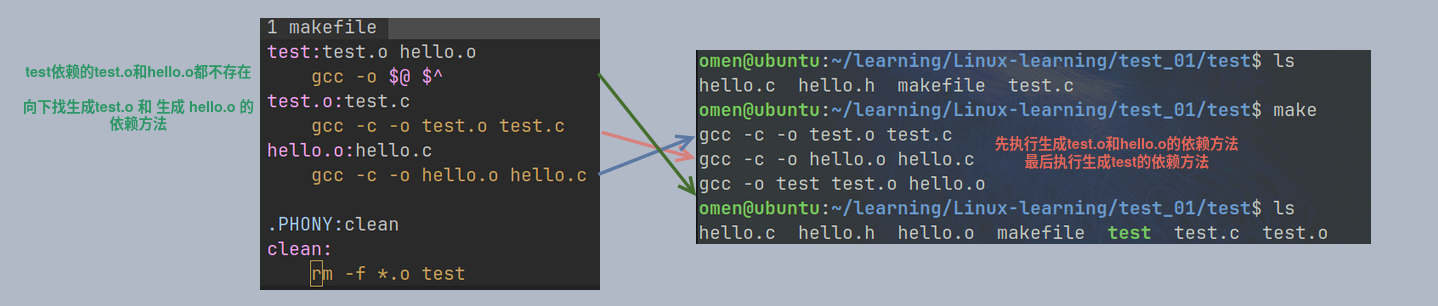
推导依赖关系, 逆向执行依赖方法
只输入 make 指令
make会在当前目录下找名字叫Makefile或makefile的文件- 如果找到, 它会找文件第一个目标文件, 在上述例子中, 他会找到
test这个文件, 并把test作为最终的目标文件爱你. - 如果
test文件不存在 或者test所依赖的后面的.o文件修改时间要比test这个文件新, 那么就会执行依赖方法. - 如果后面的
.o不存在 或者 其依赖的文件列表修改时间要比目标文件要新, 执行该依赖方法. - 直至找到源文件或者没找到报错, 从下往上执行依赖方法. 有点像堆栈的过程.
根据修改时间进行判断
怎么查看文件的修改时间呢?
通过 stat 文件名 可以查看文件的 ACM 时间
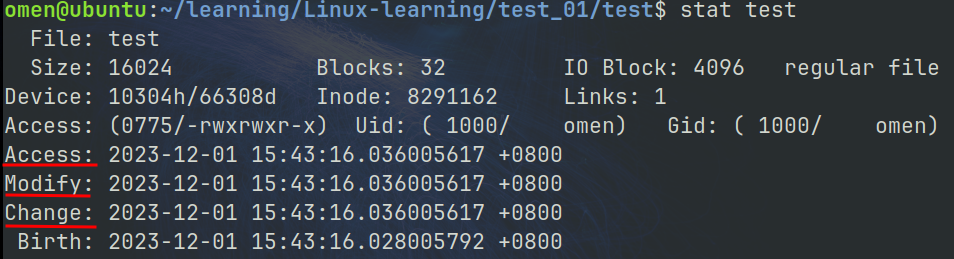
Access: 最后访问时间
Change: 更改文件属性的时间
Modify: 更改文件内容的时间
make 是将源文件与目标文件的 Modify 时间进行对比的.
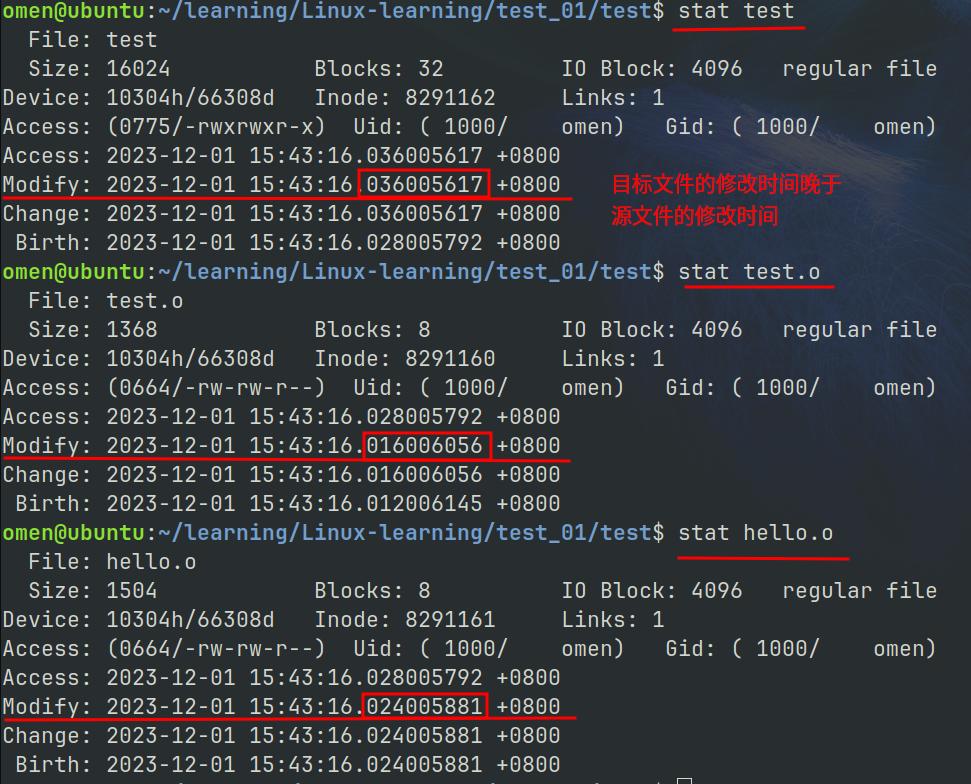
此时 使用 make 默认生成 test , 提示 test 已经是最新

使用 touch 命令对源文件的修改时间进行更新, 此时再 make , test 被更新

.PHONY
.PHONY后面跟着的目标文件, 为伪目标, 通过 make 生成一定会执行, 不会因为修改时间或是其他的原因而不执行.
推荐设置 clean 为伪目标, 这样每次都一定会将删除命令执行成功.