1、写作动机:
对齐大型语言模型以执行指导性任务通常需要在大量人工标注的指令或偏好信息上进行微调,然而,使用此类高质量数据对指令遵循任务进行标注是难以扩展的。
2、贡献:
提出了一种可扩展的方法,通过自动标注人类编写的文本与相应的指令信息,构建高质量的指令遵行语言模型。
3、方法架构:
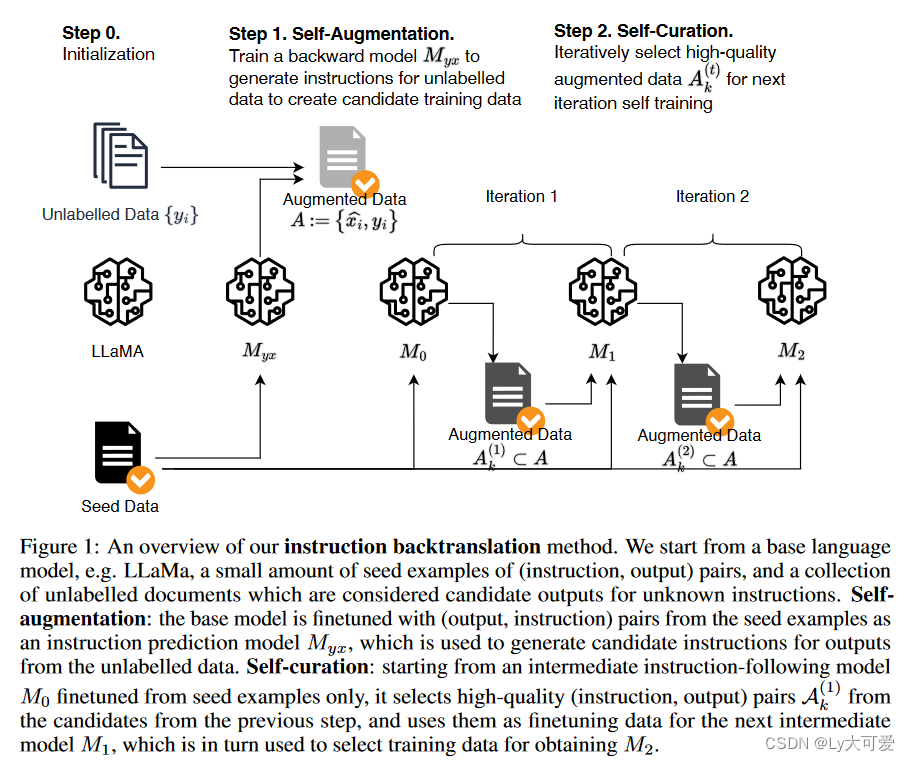
核心步骤:
- 自我增强:为未标记的数据,即网络语料库,生成指导信息,以产生用于指导微调的候选训练数据的(指导,输出)对。
- 自我筛选:自我选择高质量的演示示例作为训练数据,以微调基础模型以遵循指导。
4、实验:
4.1实验设置:
使用来自Open Assistant数据集 的3200个示例作为人工标注的种子数据来训练模型。
基础模型和微调:使用预训练的LLaMA模型,参数分别为7B、33B和65B,作为微调的基础模型。
未标记数据:使用Clueweb语料库的英语部分作为未标记数据的来源。
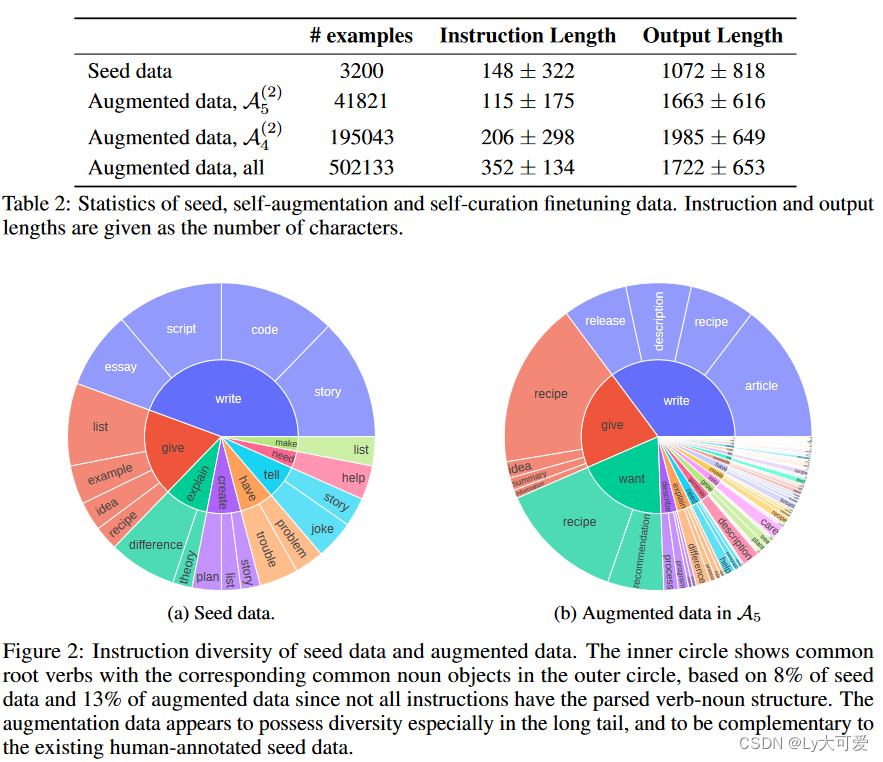
4.2种子和增强数据统计:
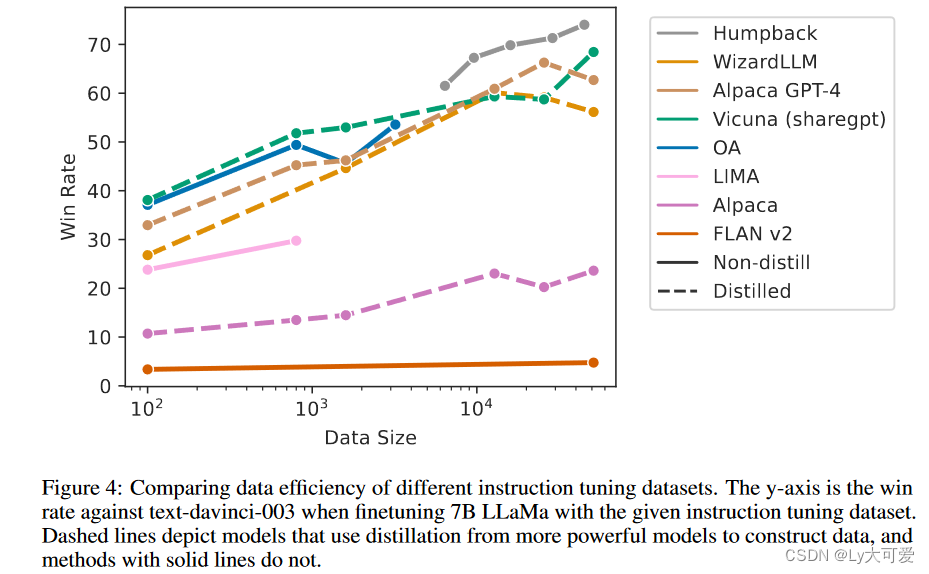
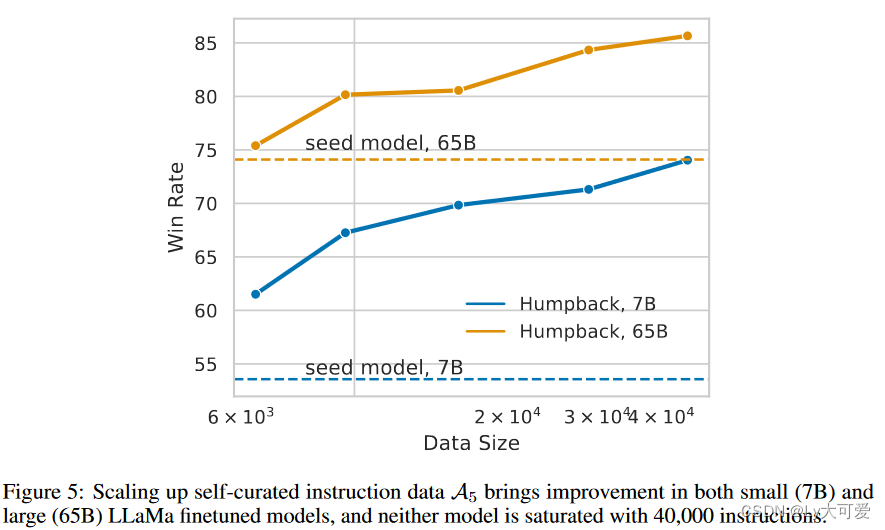
4.3数据规模效率:
4.4生成质量:
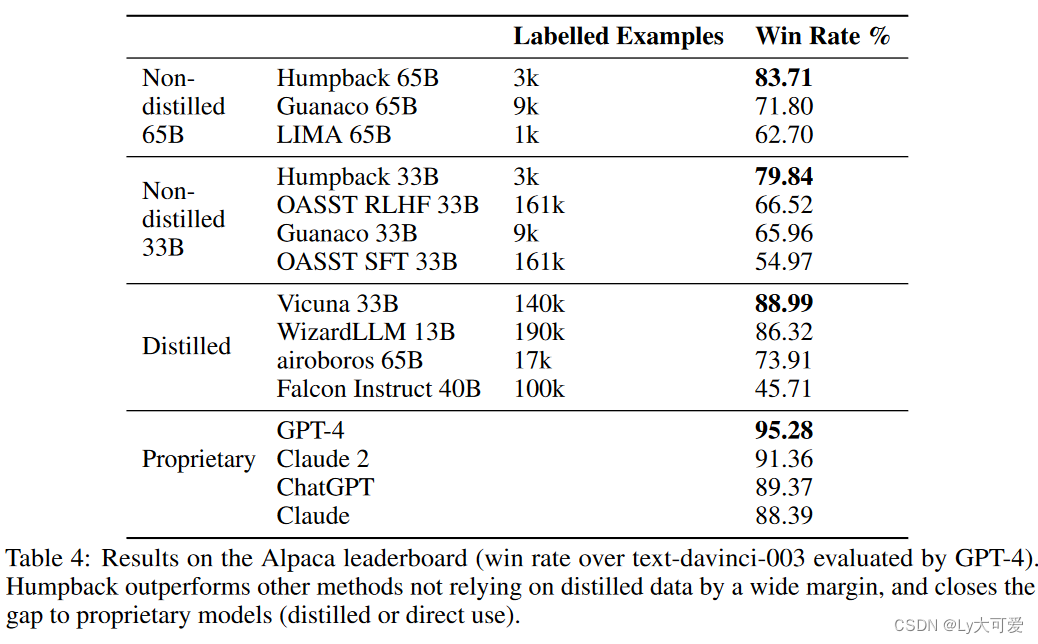
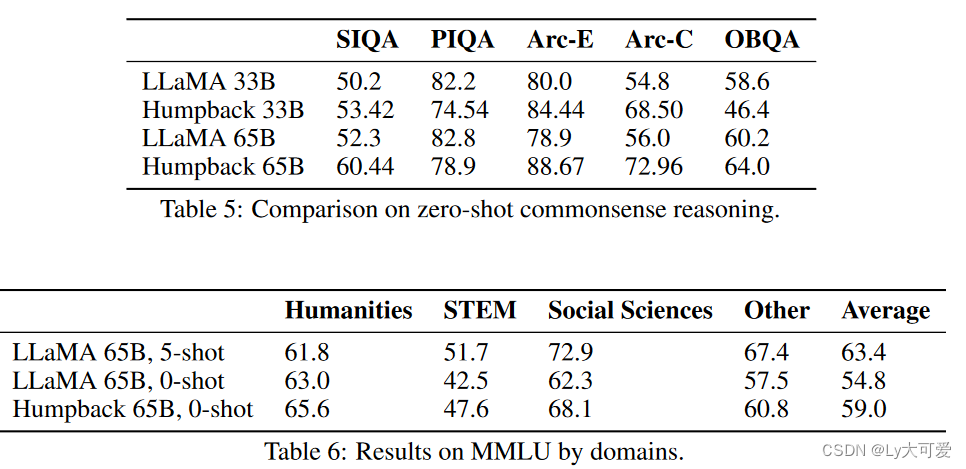
4.5NLP基准:(包括常识推理和大规模多任务语言理解)
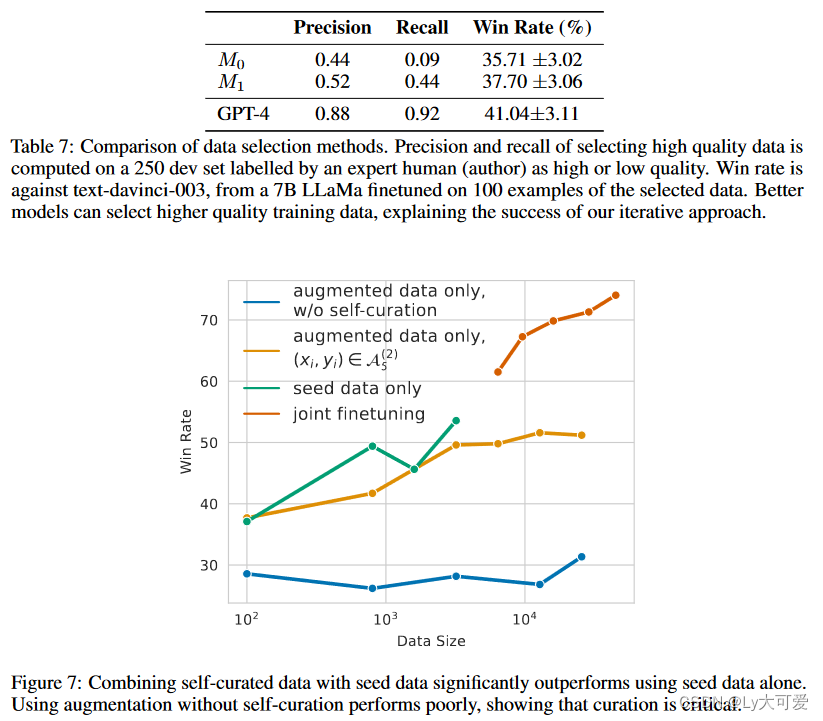
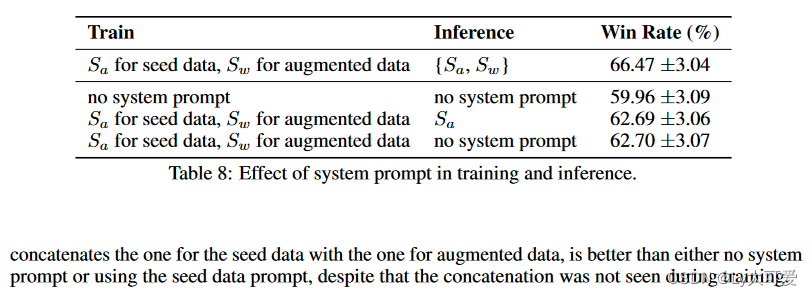
4.6消融实验:
5、局限性:
1、由于增强数据来自Web语料库,一个潜在的后果是微调后的模型可能会放大来自Web数据的偏见。
2、模型往往会产生谨慎的响应,甚至拒绝提供信息以履行指令。