一.序列到序列模型的简介
序列到序列(Sequence-to-Sequence,Seq2Seq)模型是一类用于处理序列数据的深度学习模型。该模型最初被设计用于机器翻译,但后来在各种自然语言处理和其他领域的任务中得到了广泛应用。
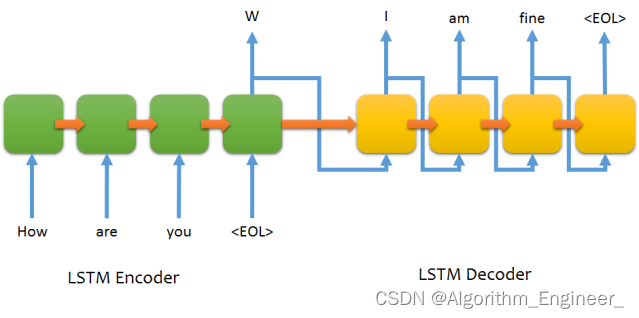
Seq2Seq模型的核心思想是接受一个输入序列,通过编码(Encoder)将其映射到一个固定长度的表示,然后通过解码(Decoder)将这个表示映射回输出序列。这使得Seq2Seq模型适用于处理不定长输入和输出的任务。
以下是Seq2Seq模型的基本架构:
编码器(Encoder):
接受输入序列,并将其转换成一个固定长度的表示。
这个表示通常是一个向量,包含输入序列的语义信息。
常见的编码器包括循环神经网络(RNN)、门控循环单元(GRU)、长短时记忆网络(LSTM)等。
解码器(Decoder):
接受编码器生成的表示,并将其解码为输出序列。
解码器通过逐步生成输出序列的元素,直到遇到终止标记或达到最大长度。
注意力机制(Attention)(可选):
用于处理长序列和对输入序列的不同部分赋予不同的重要性。
注意力机制允许解码器在生成每个输出元素时关注输入序列的不同部分,从而更好地处理长距离依赖关系。
Seq2Seq模型在许多任务中都表现出色,包括:
机器翻译
文本摘要
语音识别
图片描述生成
问答系统等
在训练过程中,通常使用教师强制(Teacher Forcing)方法,即将实际目标序列中的每个元素作为解码器的输入,而不是使用解码器自身生成的元素。在推断过程中,可以使用贪婪搜索或束搜索等策略来生成输出序列。
总体而言,Seq2Seq模型为处理序列数据提供了一种强大的框架,但也面临一些挑战,如处理长序列、处理稀疏数据等。近年来,一些改进和变体的模型被提出来应对这些挑战,例如Transformer模型。
二.基本原理
Seq2Seq模型的基本原理涉及到编码器-解码器结构,其中输入序列通过编码器被映射到一个固定长度的表示,然后解码器将这个表示映射回输出序列。下面是Seq2Seq模型的基本原理:
编码器(Encoder):
接受输入序列 X=(x1,x2,...,xT),其中 T 是序列的长度。
每个输入元素 xt通过嵌入层转换为向量表示(embedding)。
这些嵌入向量通过编码器网络,例如循环神经网络(RNN)、门控循环单元(GRU)、长短时记忆网络(LSTM)等,产生一个上下文表示(Context Vector)。
h=Encoder(X)
上下文表示 hh 包含了输入序列的语义信息,可以看作是输入序列的固定长度表示。
解码器(Decoder):
接受编码器生成的上下文表示 hh。
解码器以一个特殊的起始标记作为输入,开始生成输出序列 Y=(y1,y2,...,yT),其中 T′T′ 是输出序列的长度。
在每个时间步,解码器产生一个输出元素 ytyt,并更新其内部状态。
yt,st=Decoder(yt−1,st−1,h)
这里,st 是解码器的隐藏状态,yt−1 是上一个时间步的输出元素。在初始步骤,y0 为起始标记。
生成输出序列:
重复解码器的步骤,直到生成终止标记或达到最大输出序列长度。
Y=Decoder(yT′−1,sT′−1,h)
最终的输出序列 YY 包含了模型对输入序列的翻译或转换。
在训练时,通常使用教师强制(Teacher Forcing)方法,即将实际目标序列中的每个元素作为解码器的输入。在推断过程中,可以使用贪婪搜索或束搜索等策略来生成输出序列。
总体而言,Seq2Seq模型通过编码器-解码器结构实现了将不定长的输入序列映射到不定长的输出序列的任务,使其适用于多种序列到序列的问题。
三.序列到序列的注意力机制
注意力机制(Attention Mechanism)是一种允许神经网络关注输入序列中不同部分的机制。它最初被引入到序列到序列(Seq2Seq)模型中,以解决模型处理长序列时的问题。注意力机制使得模型能够在生成输出序列的每个元素时,对输入序列的不同部分分配不同的注意力权重。
基本的注意力机制包括三个主要组件:
查询(Query):用于计算注意力权重的向量,通常是解码器中的隐藏状态。
键(Key)和值(Value):用于表示输入序列的向量。键和值可以看作是编码器中的隐藏状态,它们将用于计算注意力分布。
注意力分数(Attention Scores):通过计算查询和键之间的相似性,得到表示注意力权重的分数。通常使用点积、加性(concatenative)、缩放点积等方法计算。
这样,模型在生成每个输出元素时,可以根据输入序列的不同部分分配不同的注意力,从而更好地捕捉长距离依赖关系。
注意力机制的引入不仅提高了模型的性能,而且也为处理更长序列和全局信息提供了一种有效的方式。在Seq2Seq模型中,Transformer模型的成功应用注意力机制,成为了自然语言处理领域的一个重要发展方向。
以下是使用PyTorch实现的基本的序列到序列模型(Seq2Seq)和注意力机制的代码。这个代码使用了一个简单的循环神经网络(RNN)作为编码器和解码器,并添加了注意力机制。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
class Encoder(nn.Module):
def __init__(self, input_size, hidden_size):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(input_size, hidden_size)
self.rnn = nn.GRU(hidden_size, hidden_size)
def forward(self, input):
embedded = self.embedding(input)
output, hidden = self.rnn(embedded)
return output, hidden
class Attention(nn.Module):
def __init__(self, hidden_size):
super(Attention, self).__init__()
self.hidden_size = hidden_size
self.attn = nn.Linear(hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.rand(hidden_size))
def forward(self, hidden, encoder_outputs):
seq_len = encoder_outputs.size(0)
hidden = hidden.repeat(seq_len, 1, 1)
energy = F.relu(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
energy = energy.permute(1, 2, 0)
v = self.v.repeat(encoder_outputs.size(0), 1).unsqueeze(1)
attention_scores = torch.bmm(v, energy).squeeze(1)
attention_weights = F.softmax(attention_scores, dim=1)
context_vector = torch.bmm(encoder_outputs.permute(1, 0, 2), attention_weights.unsqueeze(2)).squeeze(2)
return context_vector
class Decoder(nn.Module):
def __init__(self, output_size, hidden_size):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.rnn = nn.GRU(hidden_size * 2, hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
self.attention = Attention(hidden_size)
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input).view(1, 1, -1)
context = self.attention(hidden, encoder_outputs)
rnn_input = torch.cat((embedded, context.unsqueeze(0)), dim=2)
output, hidden = self.rnn(rnn_input, hidden)
output = output.squeeze(0)
output = self.fc(output)
return output, hidden
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.fc.out_features
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
encoder_outputs, hidden = self.encoder(src)
input = trg[0, :]
for t in range(1, trg_len):
output, hidden = self.decoder(input, hidden, encoder_outputs)
outputs[t] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[t] if teacher_force else top1
return outputs
四.序列到序列模型存在的问题和挑战
尽管序列到序列(Seq2Seq)模型在处理序列数据上取得了很多成功,但也面临一些问题和挑战,其中一些包括:
处理长序列:
Seq2Seq模型在处理长序列时可能面临梯度消失和梯度爆炸的问题,导致模型难以捕捉长距离依赖关系。
注意力机制是一种缓解这个问题的方法,但仍然存在一定的挑战。
稀疏性和OOV问题:
对于自然语言处理等任务,词汇表往往很大,而训练数据中的词汇可能很稀疏。这导致模型难以处理未在训练数据中见过的词汇,即Out-Of-Vocabulary(OOV)问题。
Subword分词和字符级别的建模等方法可以缓解这个问题。
过度翻译和生成问题:
Seq2Seq模型在训练时使用了教师强制,即将实际目标序列中的每个元素作为解码器的输入。这可能导致模型在生成时出现过度翻译的问题,即生成与目标不完全一致的序列。
在推断时采用不同的生成策略,如束搜索,可以部分缓解这个问题。
缺乏全局一致性:
Seq2Seq模型通常是基于局部信息的,每个时间步只关注当前输入和先前的隐藏状态。这可能导致生成的序列缺乏全局一致性。
Transformer模型引入的自注意力机制可以更好地处理全局信息,但仍然存在一些挑战。
对训练数据质量和多样性的敏感性:
Seq2Seq模型对训练数据的质量和多样性敏感。缺乏多样性的数据集可能导致模型泛化能力差。
数据增强和更复杂的模型架构可以帮助处理这个问题。
推断速度较慢:
一些Seq2Seq模型在推断时可能较慢,尤其是在处理长序列时。Transformer等模型在这方面有一些改进,但仍需要考虑推断效率。
对这些问题的研究和改进使得Seq2Seq模型不断演进,并推动了更先进的模型的发展,例如Transformer和其变体。



![c语言[]优先级大于*优先级](https://img-blog.csdnimg.cn/direct/d7ada21ccdfa44d99caf03abacdc56e0.png)