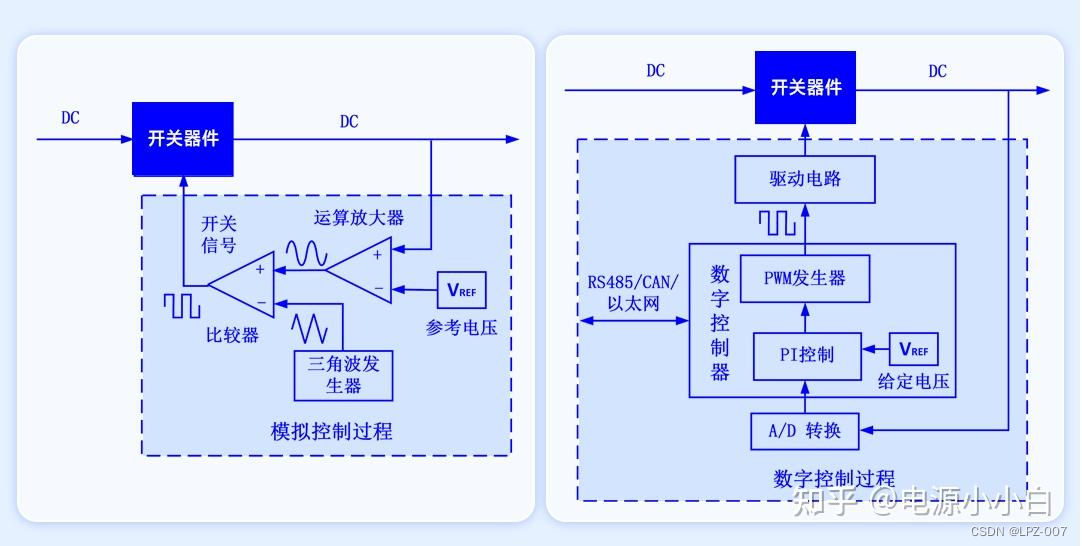
1、写作动机:
尽管将事件抽取任务转换为具有提示的序列生成问题越来越多,但基于生成的方法仍存在两个重大挑战,包括使用欠佳的提示和静态事件类型信息。
欠佳的提示:手动为每种事件类型设计提示,没有调优,在很大程度上影响模型性能。
静态事件类型信息:在抽取特定类型的事件时,最近的基于生成的方法将只接收有关正在运行的事件类型的相同事件类型信息,而不考虑其他可能的事件类型之间的关联。
2、概述:
提出了一种基于生成模板的动态前缀的事件提取,记作GTEE- D YNPREF。使用预训练的编码-解码器语言模型BART,按一种类型提取事件记录进行条件生成。对于每个事件类型,我们首先初始化一个特定于类型的前缀,它由一个可调向量序列组成,作为transformer 的历史值。特定于类型的前缀为单一类型提供了可调的事件类型信息。然后,我们将上下文信息与所有特定于类型的前缀集成起来,以学习特定于上下文的前缀,并动态地组合所有可能的事件类型信息。

3、基本模型架构:

对于句子中的每个事件类型ei,将事件填充到模板,构建序列,用于条件生成。若没有事件类型ei的事件记录,generation ground truth是Trigger <trg>,否则,事件类型被填充到模板中。如果几个论元被归类为相同的角色,那么这些论元按照span排序,然后由'and'连接。如果有多个事件类型,按触发词的span排序,并且填充的序列将由一个新的单独的标记<OUT_SEP>连接。
条件生成子任务由预训练的编码器-解码器语言模型BART或者T5建模。
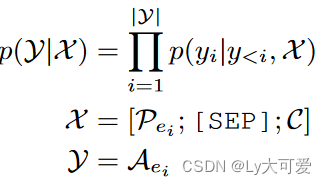
分析:根据事件本体O,通过模板匹配和插槽映射来解析事件记录,并不是所有生成的输出序列都是有效的,对于每个生成序列,首先尝试解析触发词,若失败了,跳过该序列;若不能匹配<IN_SEP>或模板![]() 的论元部分,将跳过论元解析,只保留一个触发词。
的论元部分,将跳过论元解析,只保留一个触发词。
发现:通过调查解析的事件时,作者发现模型即使对于不相关的事件类型也有生成事件记录的偏差。 当输入上下文不包含任何事件记录时,这将在很大程度上影响precision分数和 F1 分数。
解决方式:通过单独训练一个不相关分类器IC来缓解这个问题。以上下文C作为输入,我们通过将编码的[ CLS ] 向量作为二分类器提供给MLP来调整BERT模型,以查看上下文是否包含任何事件记录或与本体O \mathcal{O}O完全无关。
4、动态前缀微调:
用特定于任务的前缀和特定于上下文的前缀进行动态前缀调优,以缓解基于生成的事件抽取中的两个主要挑战。

4.1特定类型的静态前缀:
使用特定于事件类型的前缀STAPREF,它是一对两个transformer激活序列{ sp , sp ′ },每个序列分别包含L个连续D维向量作为编码器和解码器的历史值。从编码器和解码器输入的角度来看,在子任务Sei,C 中,编码器-解码器LM中序列X和Y 的前缀实际上是预先添加的。
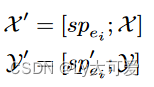
具体做法:先为本体O 中的每个事件类型ei 初始化一对特定于任务的前缀{ spei , spei ′ } ,然后在条件生成子任务Sei,C中,将相应的特定于任务的前缀{ spei , spei ′ }作为编码器和解码器的transformer activations。使用可训练的嵌入张量P ∈ R ∣ E ∣ × L × D 来建模特定的上下文前缀sp。对于事件类型ei,前缀向量在索引t的值为:

4.2特定于上下文的动态前缀:
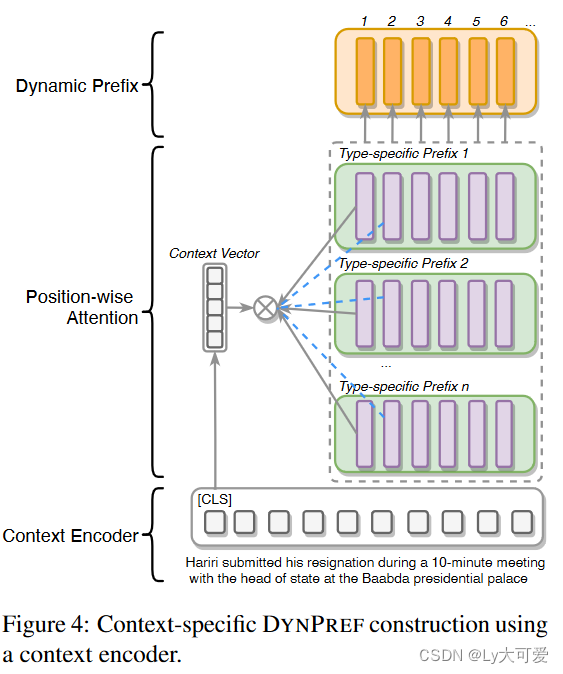
dpc与sp具有相同的序列长度L,对于每个位置t ,通过多头注意,根据上下文特定信息c,动态加入本体O中事件类型为ei的所有前缀向量,计算出前缀向量
。为了计算特定于上下文的信息c ,应用BERT模型作为上下文编码器,将上下文c 作为输入,并将[CLS]向量作为c 。

5、实验结果:
5.1监督学习:
 、
、
5.2迁移学习:

5.3消融实验:

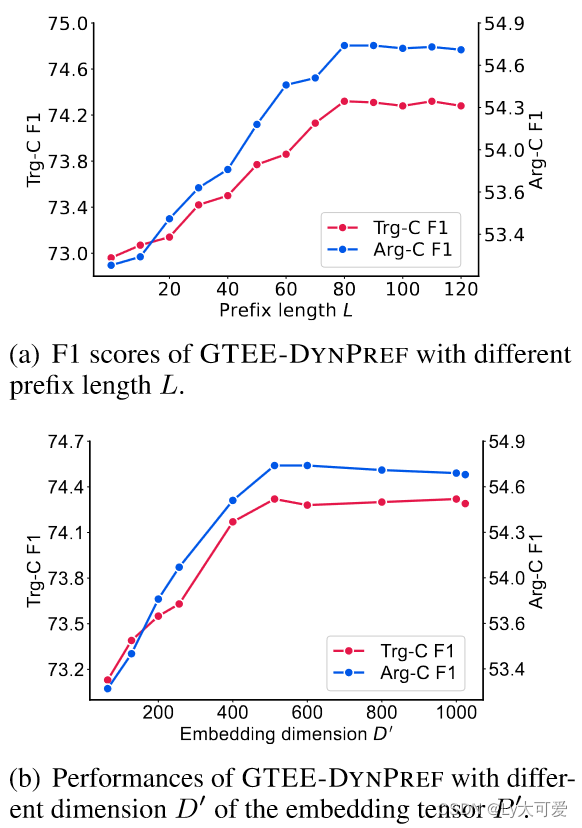
5.4内在评估:






![[Linux 进程(四)] 再谈环境变量,程序地址空间初识](https://img-blog.csdnimg.cn/direct/4bcaefb7d0b14eb086cfe87cbb72a9e0.png)
![[GN] nodejs16.13.0版本完美解决node-sass和sass-loader版本冲突问题](https://img-blog.csdnimg.cn/direct/041cbf30f6b54b13bdefb9e8dfa35530.png)