前言
- 语言模型:LLama2 - 7B
- 视觉模型:Clip-L 0.3B
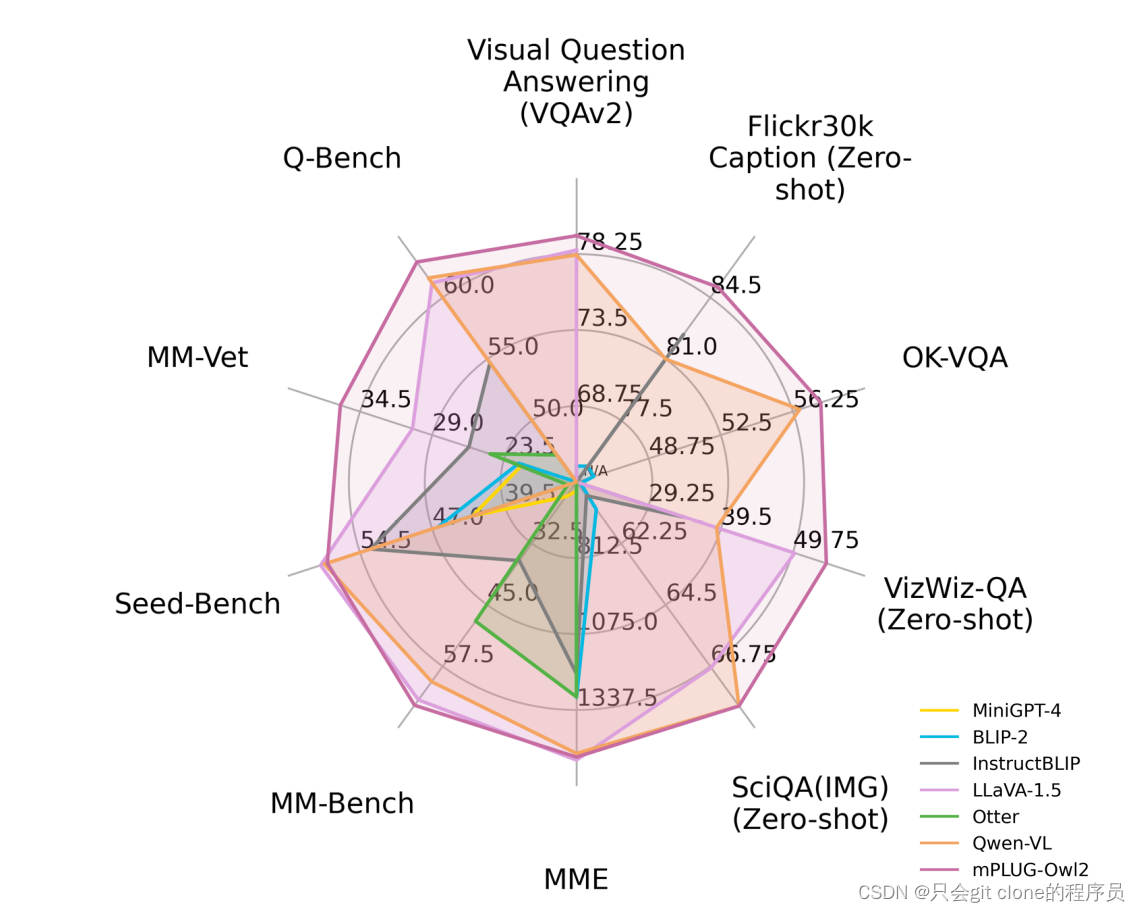
痛点
- 作者任务以往的方法(Qformer,linear层)直接将视觉编码器中的视觉特征映射到冻结的LLMs中,通过利用保留的语言能力执行多模态任务。这种策略限制了模态协作的潜力。
模型结构
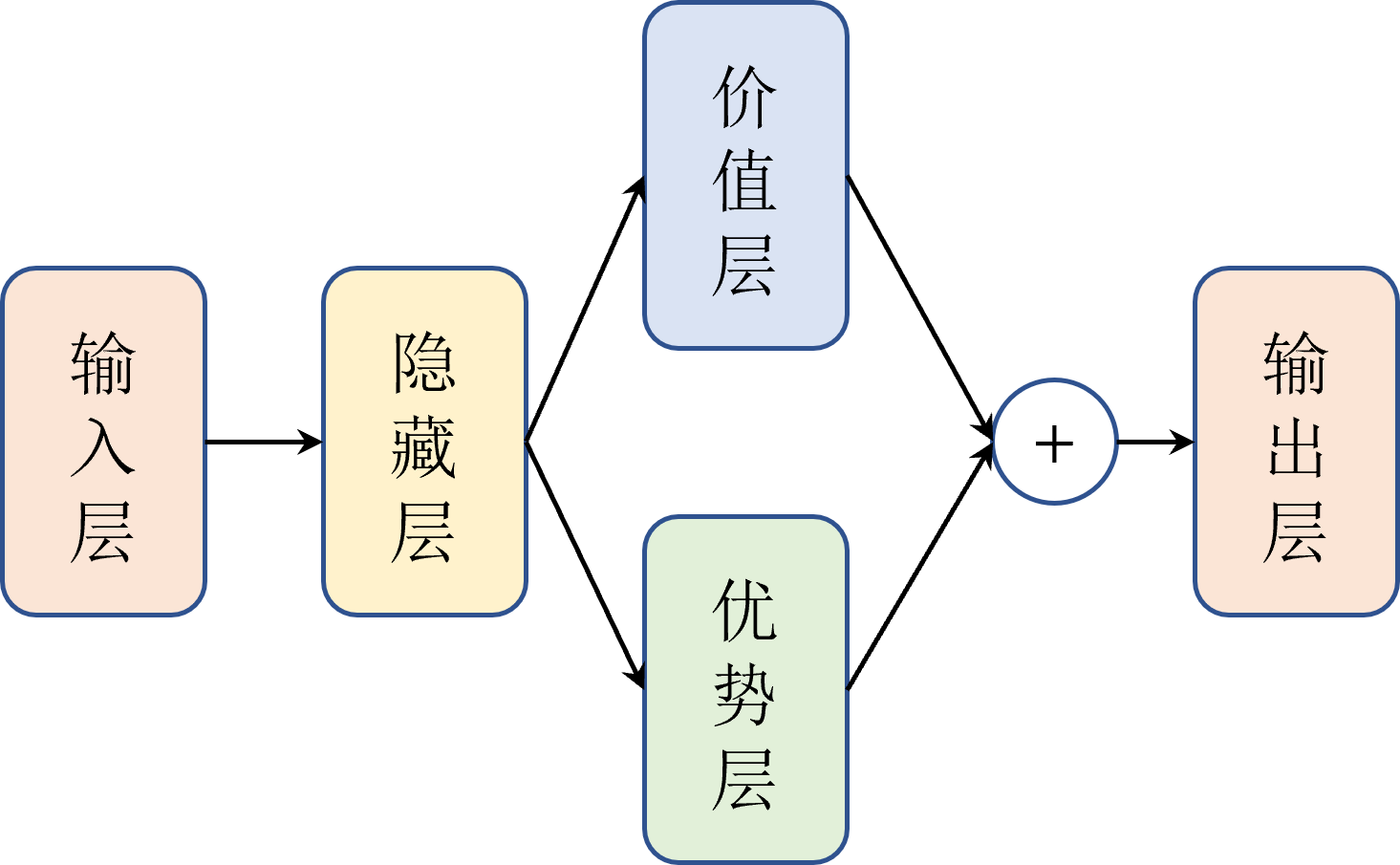
为了解决上述问题,作者设计了个多模态对齐的层,如图所示:
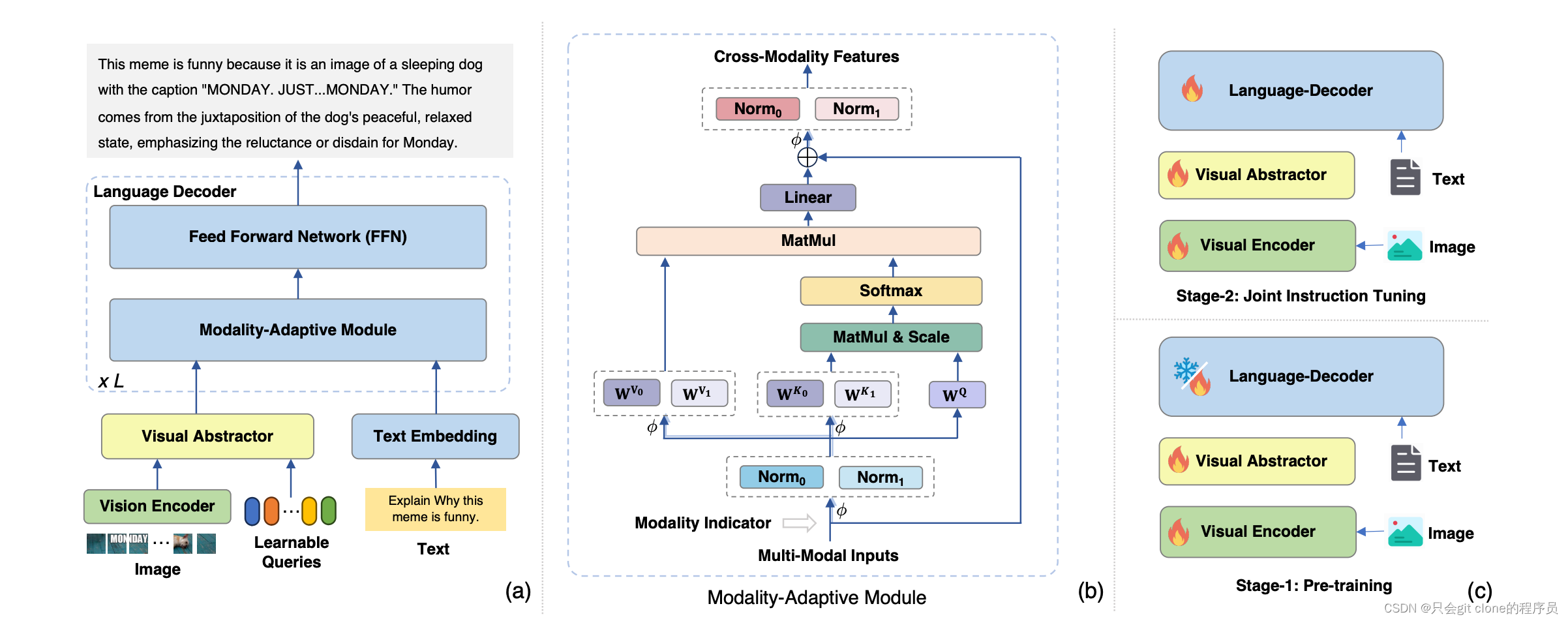
先看图a,整体模型结构包含以下几个部分:
- 视觉底座:clip-L
- 视觉抽象层:visual Abstractor,这层目的是把视觉底座出来的视觉token降纬,论文中视觉底座出来的token数是256,然后用visual Abstractor降维到64个token表示视觉特征。
- 语言模型:
- 本身基础是LLama2 7B。
- 作者把transformer结构里面FFN之前的multi head self attention改成了Modality-Adaptive Module。
再看图b:
- 看着多加了norm层,视觉和文本的token分别过对应的norm层,然后加了个FC层把视觉的特征也映射出KV,然后视觉的K和文本K拼接起来和Q算加权的attention分数加权到拼接的视觉的V和文本V,最后再过不同的norm给到FFN了。所以额外加的参数倒是不多,就实现了文本和视觉进行交互并且保留了原来的文本分支。
训练策略
预训练
- 视觉底座可训
- visual Abstractor可训
- Modality-Adaptive Module中视觉部分外加的层可训
- 语言模型部分整体不训练。
- 预训练数据量:3.48亿
SFT阶段
- 全参数可训
- 图像尺度翻倍224->448
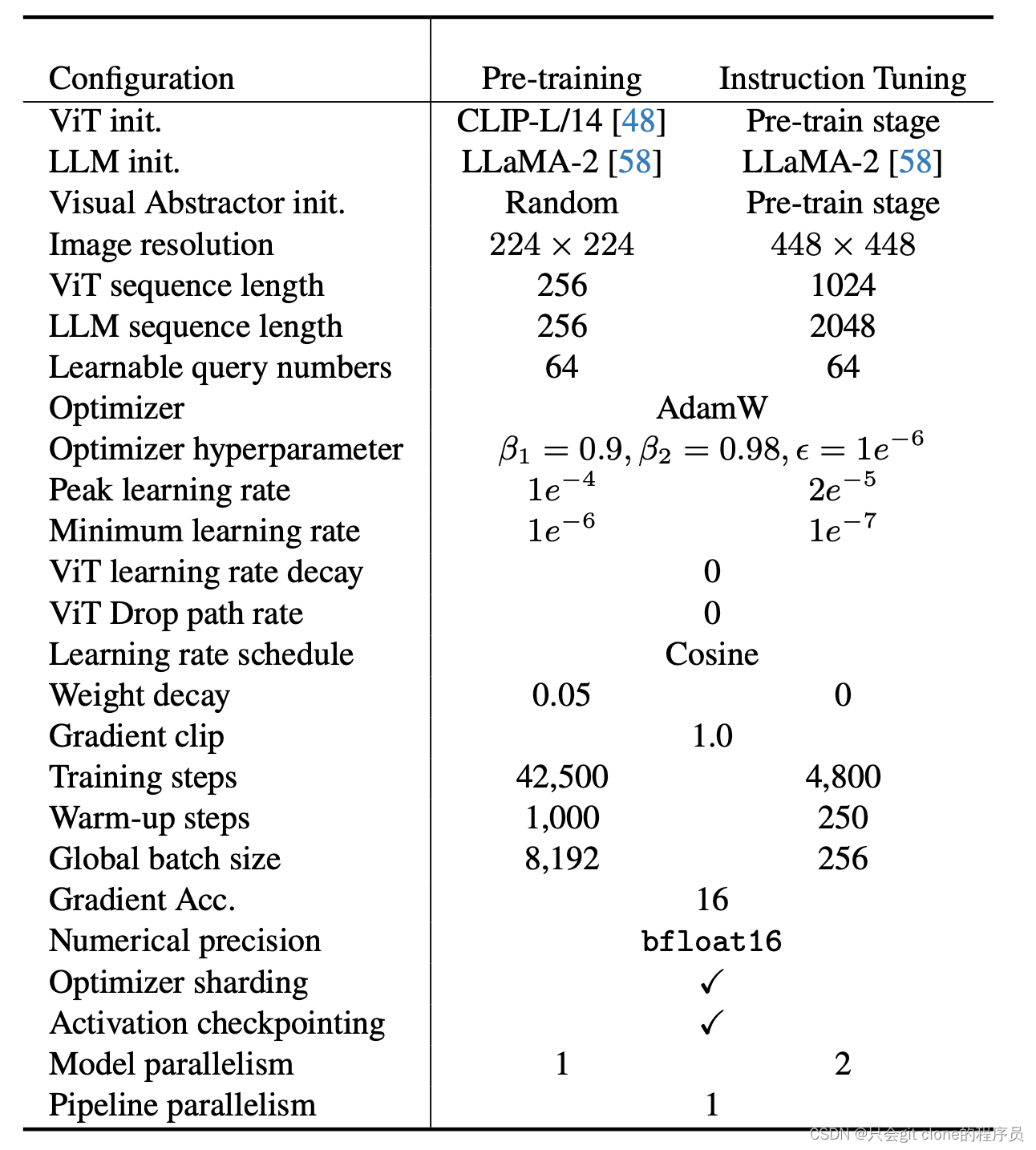
两个阶段训练参数对比
消融实验
Modality-Adaptive Module层的重要性
作者对比了加和不加这个层的时候语言模型的在语言数据集上的表现:
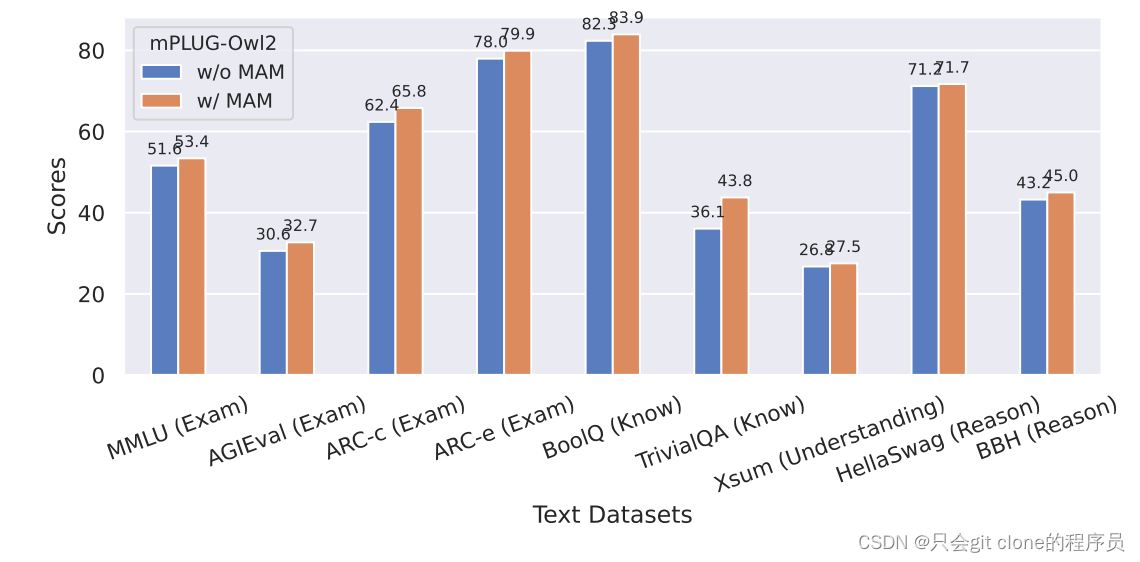
可以看到去掉这个模块,语言模型在语言的benchmark上都出现了性能损失。但是这里我感觉是不是应该放出llama2 7B本身在这上面评价的指标一起对比看看呢?如果加上了MAM对比原来的性能还是损失了很多说明这个方法也不是最优解。
视觉底座是不是要训呢?
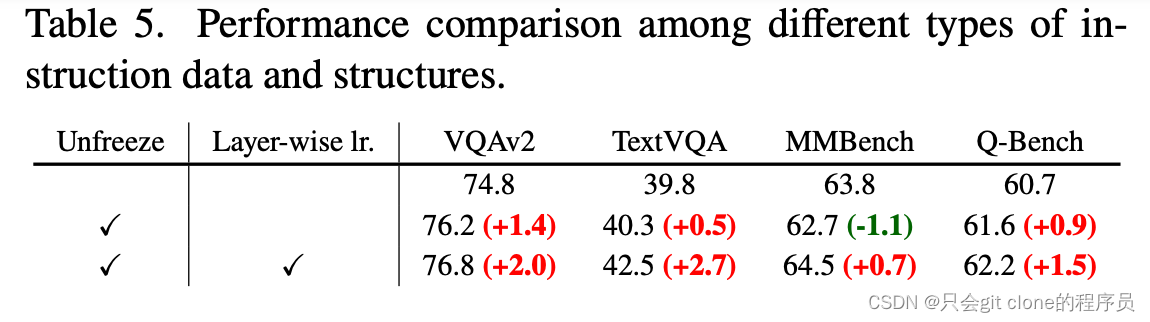
作者实验了几个数据集,发现放开视觉训练带来涨点的还是比较多。