项目说明
本数据集是生成式模拟数据,本项目通过可视化分析对数据进行初步探索,再通过时间序列针对店铺的销售额进行分析,对时序图进行分解,发现数据存在季节性,并且通过auto_arima自动选择参数建立了SARIMA模型,对未来7天的销售额进行预测,并利用聚类分析将消费者分为不同的群体,再建立RFM模型,将消费者进一步划分为不同价值的客户,对于不价值的消费者,采取不同的方案,通过这些模型,可以针对不同的消费群体采取不同的营销方案,尽可能的保留重要价值客户,对于一些低价值的客户,可以降低投入成本。
数据说明
| 字段名称 | 描述 |
|---|---|
| 订单交易时间 | 交易时候的时间 |
| 订单编号 | 交易订单的编号 |
| 订单来源 | 订单的来源:直播下单,店铺下单 |
| 用户ID | 消费者的ID |
| 会员 | 判断该消费者是否为本店会员 |
| 首次下单用户 | 判断该消费者是否为首次下单的用户 |
| 性别 | 消费者的性别:男,女 |
| 品类 | 商品类型,共四类:A,B,C,D |
| 商品单价 | 商品的价格 |
| 购买数量 | 购买商品的数量 |
| 活动优惠 | 是否使用了活动优惠 |
| 换货 | 是否换货,0-否,1-是 |
| 退货 | 是否退货,0-否,1-是 |
| 已评价 | 是否已经评价,0-否,1-是 |
数据处理
Python库导入
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.tsa.statespace.sarimax import SARIMAX
from pmdarima import auto_arima # 自动选择参数
import statsmodels.api as sm
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
数据导入
data = pd.read_csv("./data/orders_data.csv")
数据预览
# 查看数据维度
data.shape
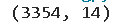
# 查看数据信息
data.info()

# 查看各列缺失值
data.isna().sum()

# 查看重复值
data.duplicated().sum()
数据逻辑性检查
# 检查用户会员状态是否一致
membership_inconsistency_count = sum(data.groupby('用户ID')['会员'].nunique() > 1)
print(f"会员状态不一致的用户数量: {membership_inconsistency_count}")
# 检查用户性别是否一致
gender_inconsistency_count = sum(data.groupby('用户ID')['性别'].nunique() > 1)
print(f"性别不一致的用户数量: {gender_inconsistency_count}")

first_order_flag = data.groupby('用户ID')['订单交易时间'].transform('min') == data['订单交易时间'] # 为了获取第一次交易的时间
# 计算那些在第一次订单之后仍标记为首次下单的情况数量
inconsistencies_count = sum((first_order_flag == False) & (data['首次下单用户'] == '是')) # 计算第一次交易后,判断后续交易中,是否还被定义为首次下单用户
print(f"首次下单状态不一致的用户数量: {inconsistencies_count}")
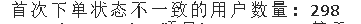
可以看到,虚拟出来的数据逻辑上存在一些错误,有的用户在某个订单中被定义成会员或者男性,但是在后面的订单中又被定义成非会员或者女性,以及有的用户以及下过单了,结果后续订单还被定义为首次下单用户,所以逻辑存在错误,需要在之后进行处理,使得数据变得合理。
数据处理
# 对性别不一致的数据进行处理
# 找出性别不一致的用户
gender_inconsistencies = data.groupby('用户ID')['性别'].nunique() > 1
inconsistent_gender_users = gender_inconsistencies[gender_inconsistencies].index
# 对每个性别不一致的用户进行处理
for user_id in inconsistent_gender_users:
user_data = data[data['用户ID'] == user_id]
# 计算性别的众数
mode_gender = user_data['性别'].mode()
if len(mode_gender) > 1: # 如果存在多个众数,使用第一个订单的性别
first_order_gender = user_data.sort_values('订单交易时间')['性别'].iloc[0]
data.loc[data['用户ID'] == user_id, '性别'] = first_order_gender
else: # 如果只有一个众数,使用这个众数替换所有不一致的性别
data.loc[data['用户ID'] == user_id, '性别'] = mode_gender.iloc[0]
# 检查处理后的数据中是否还存在性别不一致的情况
post_processing_inconsistencies = sum(data.groupby('用户ID')['性别'].nunique() > 1)
print(f"处理后性别不一致的用户数量: {post_processing_inconsistencies}")
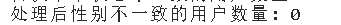
# 对会员状态不一致的数据进行处理
# 首先找出会员状态不一致的用户
membership_inconsistencies = data.groupby('用户ID')['会员'].nunique() > 1
inconsistent_membership_users = membership_inconsistencies[membership_inconsistencies].index
# 对每个会员状态不一致的用户进行处理
for user_id in inconsistent_membership_users:
user_data = data[data['用户ID'] == user_id]
# 计算会员状态的众数
mode_membership = user_data['会员'].mode()
if len(mode_membership) > 1: # 如果存在多个众数,使用第一个订单的会员状态
first_order_membership = user_data.sort_values('订单交易时间')['会员'].iloc[0]
data.loc[data['用户ID'] == user_id, '会员'] = first_order_membership
else: # 如果只有一个众数,使用这个众数替换所有不一致的会员状态
data.loc[data['用户ID'] == user_id, '会员'] = mode_membership.iloc[0]
# 检查处理后的数据中是否还存在会员状态不一致的情况
post_processing_membership_inconsistencies = sum(data.groupby('用户ID')['会员'].nunique() > 1)
print(f"处理后会员状态不一致的用户数量: {post_processing_membership_inconsistencies}")
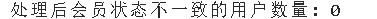
# 新增一个总价列,有助于后面的分析
data['总价'] = data['商品单价'] * data['购买数量']
# 删除订单编号列和首次下单用户,因为是否是首次下单用户意义不大,可以直接删除,还能减少处理的过程
data.drop(columns=['订单编号','首次下单用户'], inplace=True)
# 确保下单时间是日期时间格式
data['订单交易时间'] = pd.to_datetime(data['订单交易时间'])
data.head()

数据分析
订单数据趋势分析
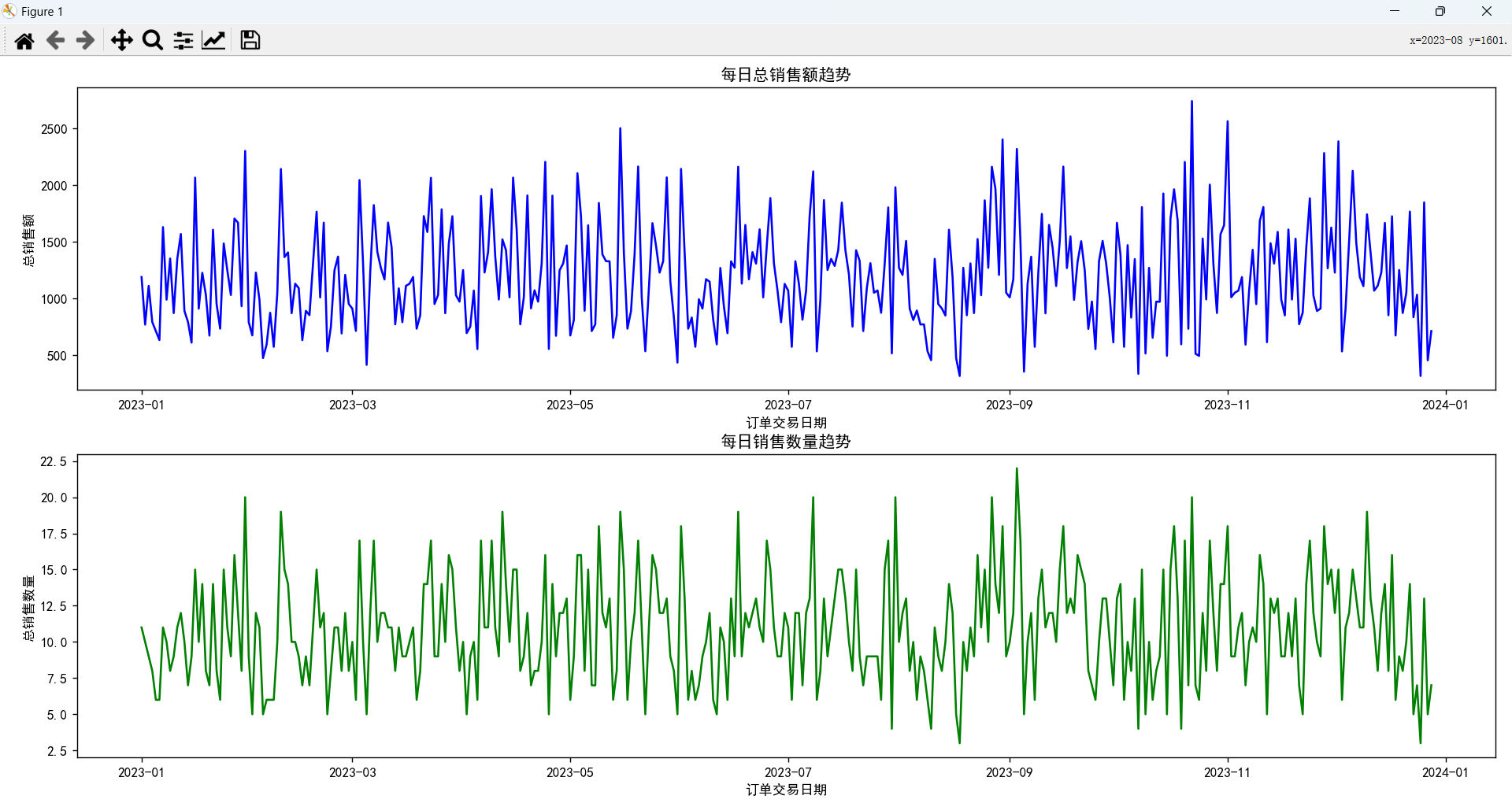
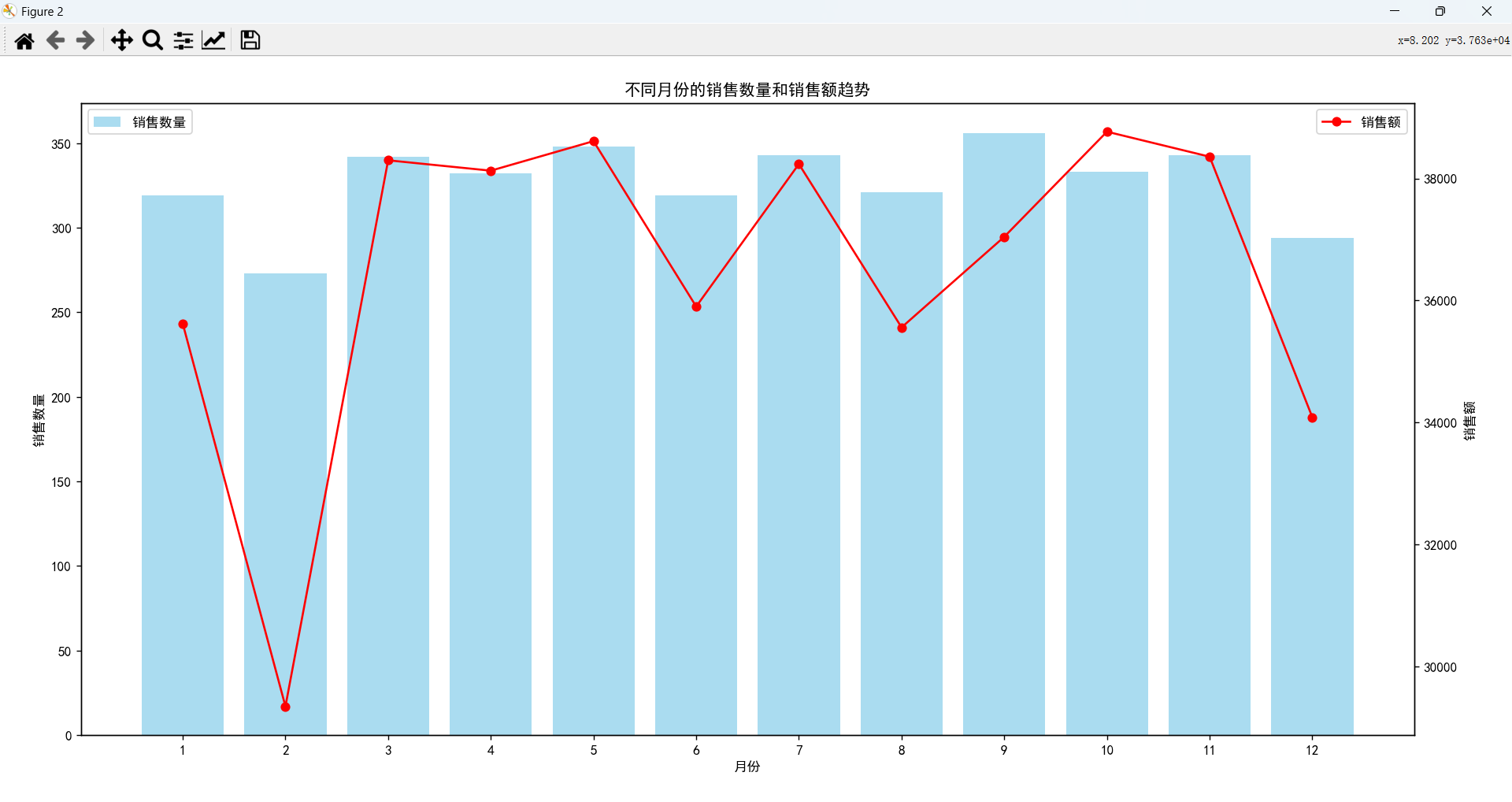
因为时序图不便于观察,这里主要分析每个月的销售情况,可以看到每个月的销售情况,2月的销售额和销售数量都是最少的。
订单特征分析
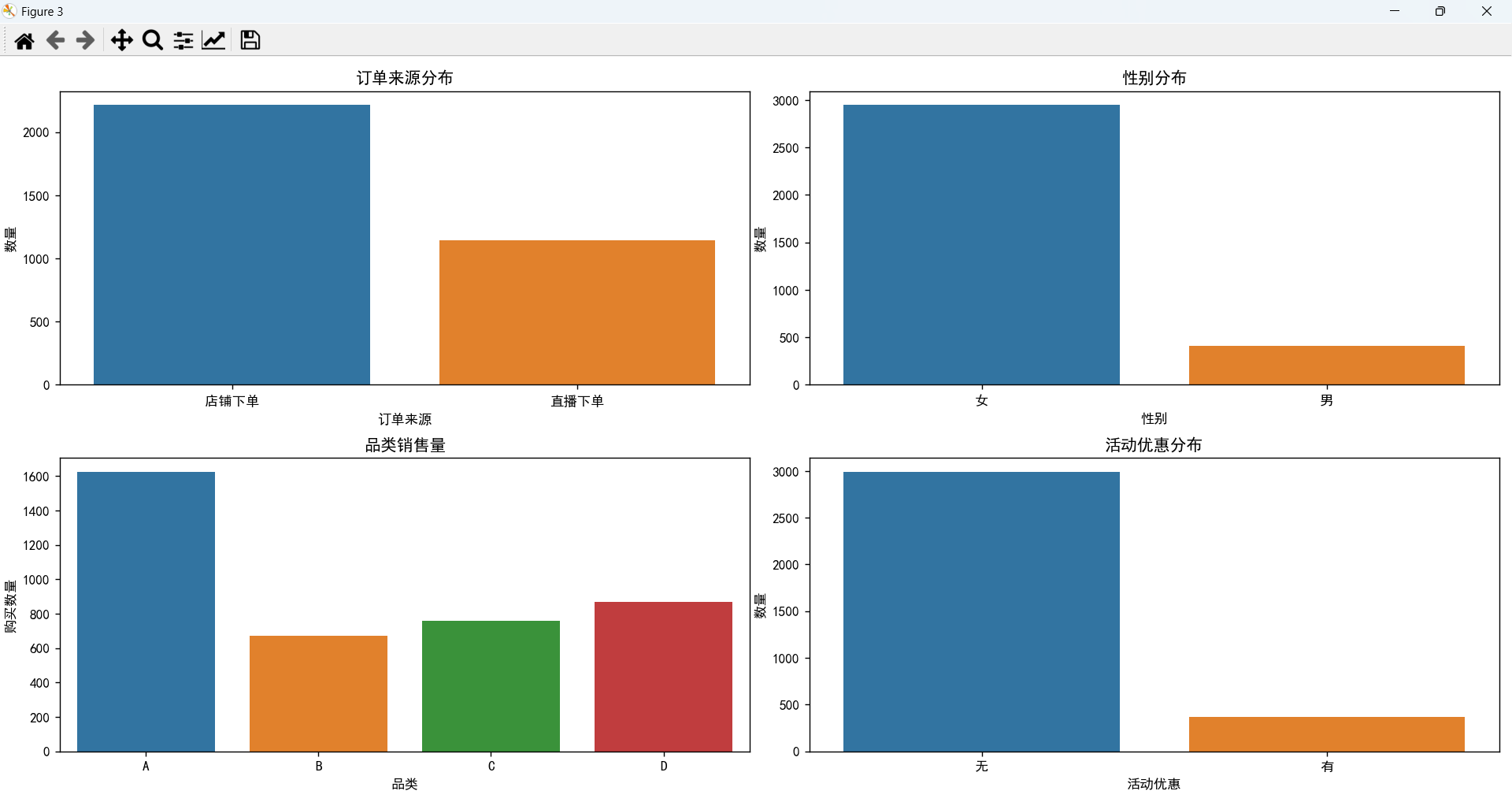
- 订单主要来源于店铺下单。
- 女性消费者远远高于男性消费者,这家店铺面向的主要对象就是女性。
- 购买A类的消费者最多,B类、C类、D类数量相差不大。
- 大多数订单是没有使用活动优惠的。
消费者反馈分析
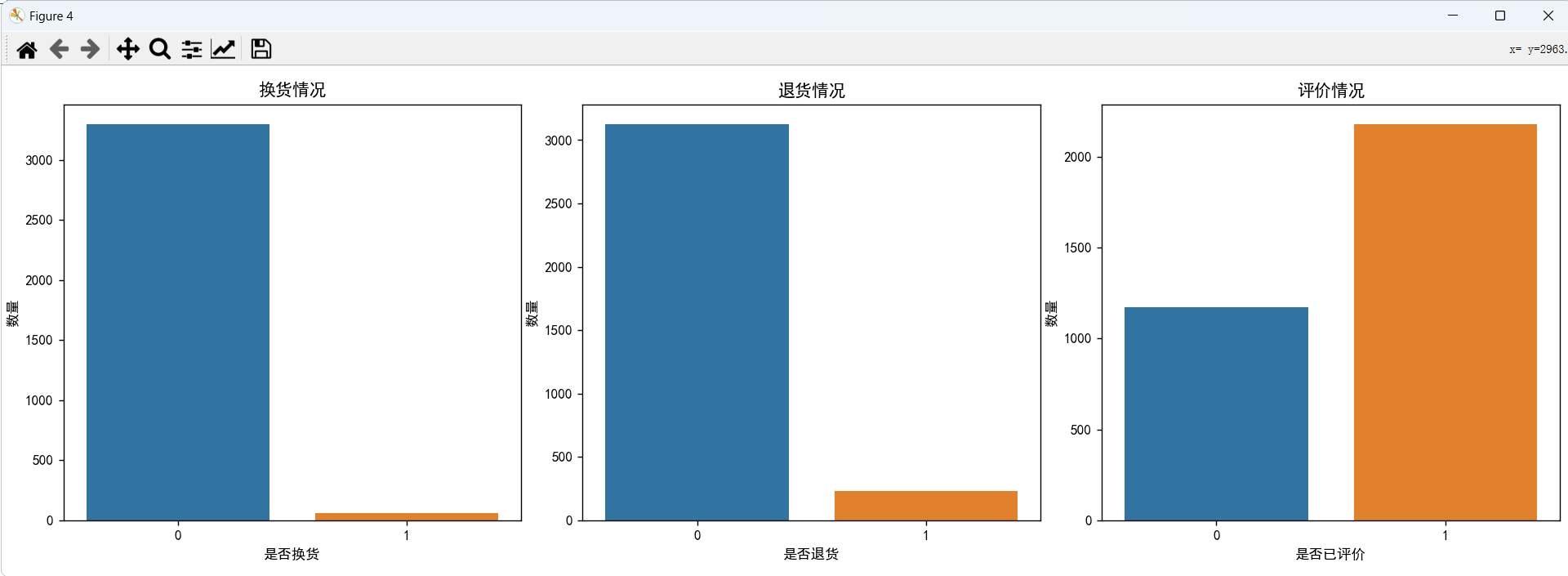
在所有的订单中,换货、退货情况比较少,有超过半数的订单是已经评价过的了。
时间序列分析
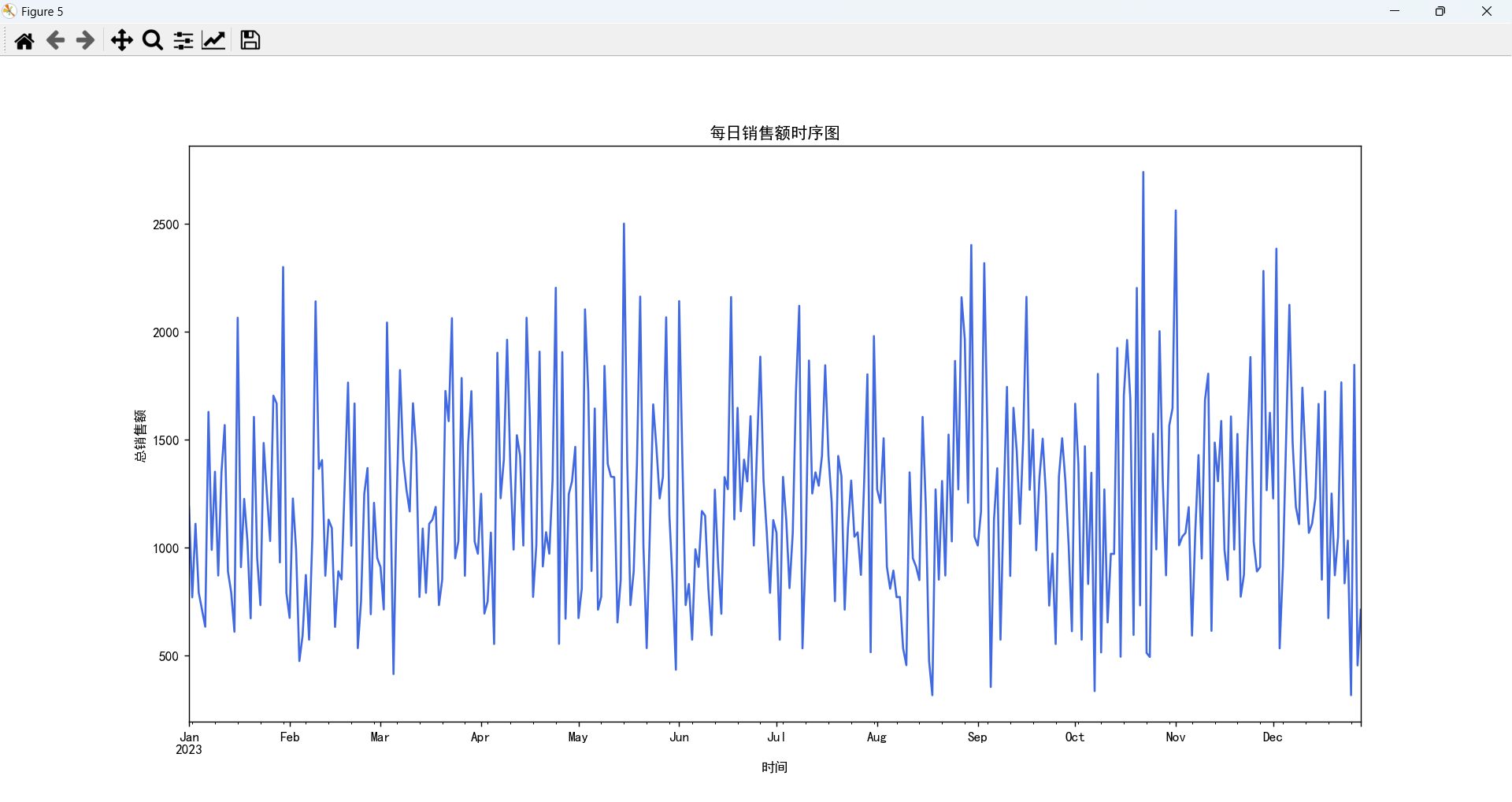
销售额时序图
时间序列分解结果
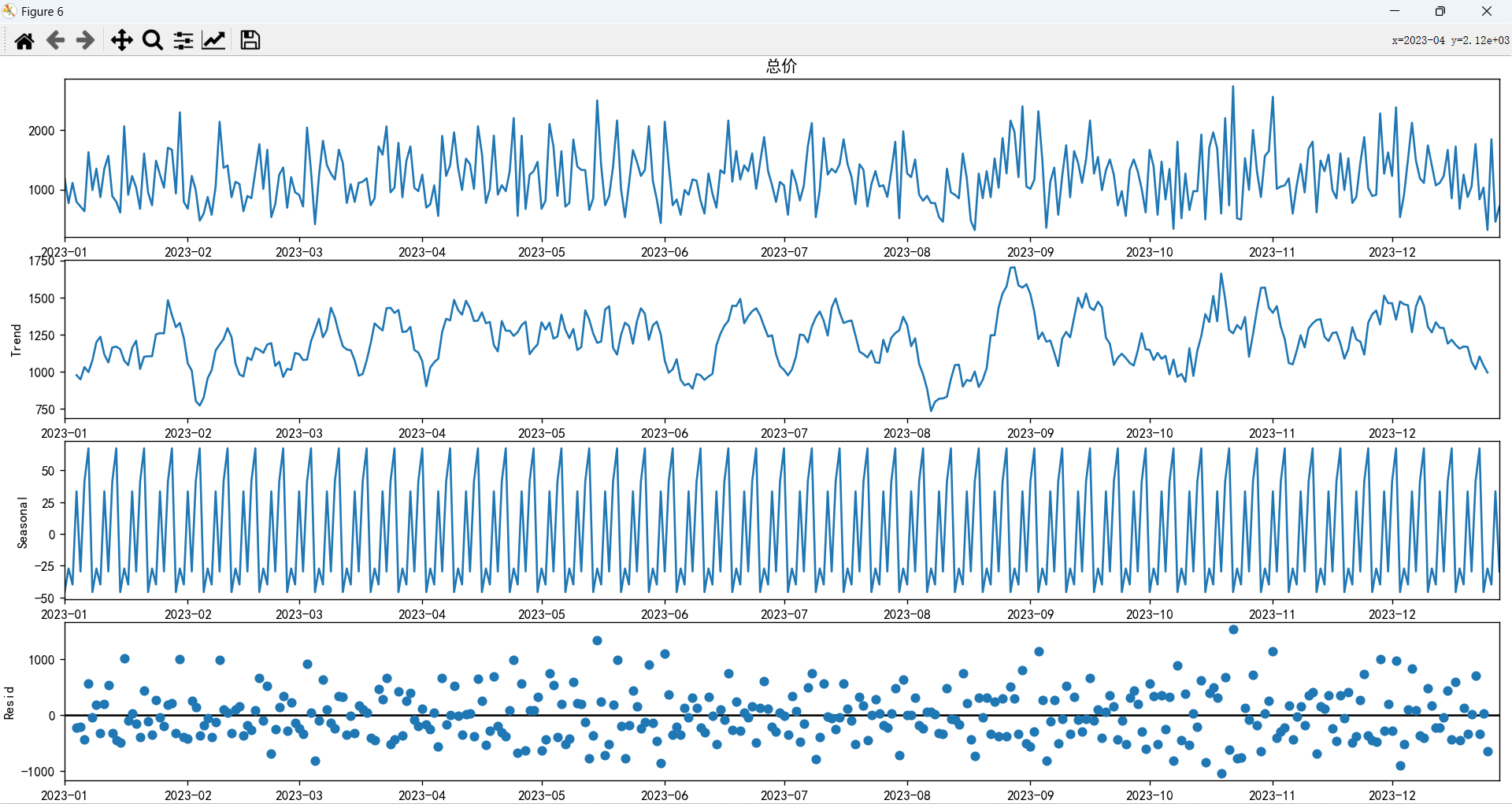
从趋势图中可以看出,销售数据的趋势组成部分在整个时间段内波动显著,没有显示出明显的长期上升或下降趋势,这表明尽管有短期的波动,但在一年内内,销售总体上没有强烈的长期增长或衰退。
季节性分量的图表显示出非常规律的模式,这表明销售数据受到周期性因素的强烈影响,这种规律性模式对于预测或规划销售活动非常重要,并且识别出了周期为7天,第一次达到峰值。
残差分量的图表显示了在趋势和季节性分量被剔除后,数据中剩余的不规则或随机波动,这些波动可能由不可预测的事件或其他非系统性因素引起。
建立SARIMA模型
model = auto_arima(daily_sales_complete, seasonal=True, m=7, trace=True,error_action='ignore', suppress_warnings=True)

model.summary()
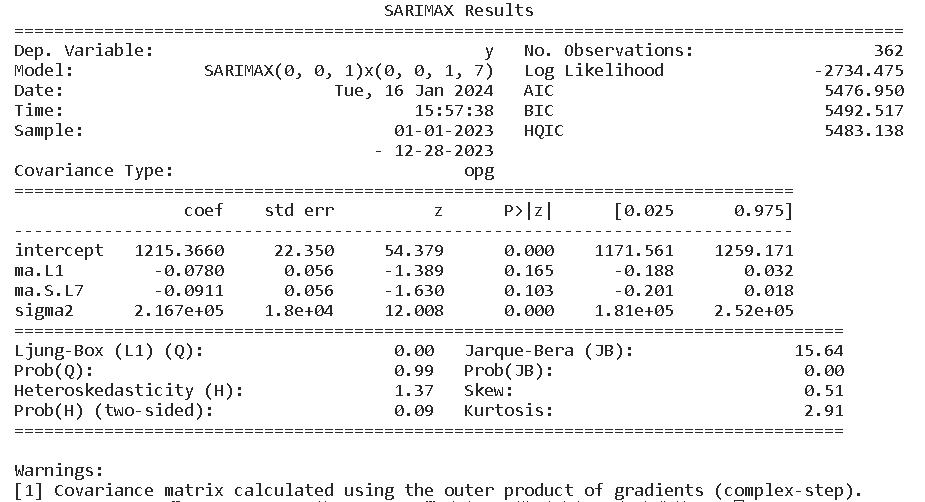
这里自动选择了SARIMAX(0, 0, 1)x(0, 0, 1, 7)模型,没有自回归项和差分,但有一个移动平均项和一个季节性移动平均项(周期为7)。该模型的AIC值为5476.950,BIC值为5492.517,截距项在统计上显著(P值几乎为0),而移动平均项和季节性移动平均项的P值则较高,说明它们在统计上不那么显著,但是残差方面,没有检测到显著的异方差性,可以勉强接受这个模型。
预测未来七天的销售额

这里预测了未来七天的一个销售额情况,可以看到,销售额主要集中在1157-1302之间,波动并不是很大,与时序图感觉还是存在许多差异,可能是自动选择的参数模型效果不理想,亦或者是受数据的影响,这里还是建议从检查白噪声等等步骤开始,我时间序列学的比较差,这里不做展开,读者可以自行去学习完成。
基于聚类分析构建用户画像
数据处理
new_data = data.copy()
# 计算总订单数
purchase_frequency = new_data.groupby('用户ID').size().reset_index(name='总订单数量')
new_data = pd.merge(data, purchase_frequency, on='用户ID')
user_features = new_data.groupby('用户ID').agg({
'性别': 'first',
'会员': 'first',
'品类': lambda x: x.mode()[0],
'订单交易时间': 'max',
'订单来源': lambda x: x.mode()[0],
'总价': 'sum',
'总订单数量': 'first',
'活动优惠': lambda x: x.mode()[0],
'退货': 'sum',
'换货': 'sum',
'已评价': 'sum'
}).reset_index()
# 重新命名dataframe,能够更好的理解数据
user_features = user_features.rename(columns={
'性别': '性别',
'会员': '会员状态',
'品类': '最常购买品类',
'订单交易时间': '最近购买日期',
'订单来源': '主要下单方式',
'总价': '总消费额',
'总订单数量': '总订单数',
'活动优惠': '是否经常使用优惠',
'退货': '总退货数',
'换货': '总换货数',
'已评价': '总评论数'
})
user_features['平均消费金额'] = user_features['总消费额'] / user_features['总订单数']
user_features.head()

确定聚类数
# 使用肘部法则来确定最佳聚类数
inertia = []
silhouette_scores = []
k_range = range(2, 11)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=10).fit(new_user_features)
inertia.append(kmeans.inertia_)
silhouette_scores.append(silhouette_score(new_user_features, kmeans.labels_))
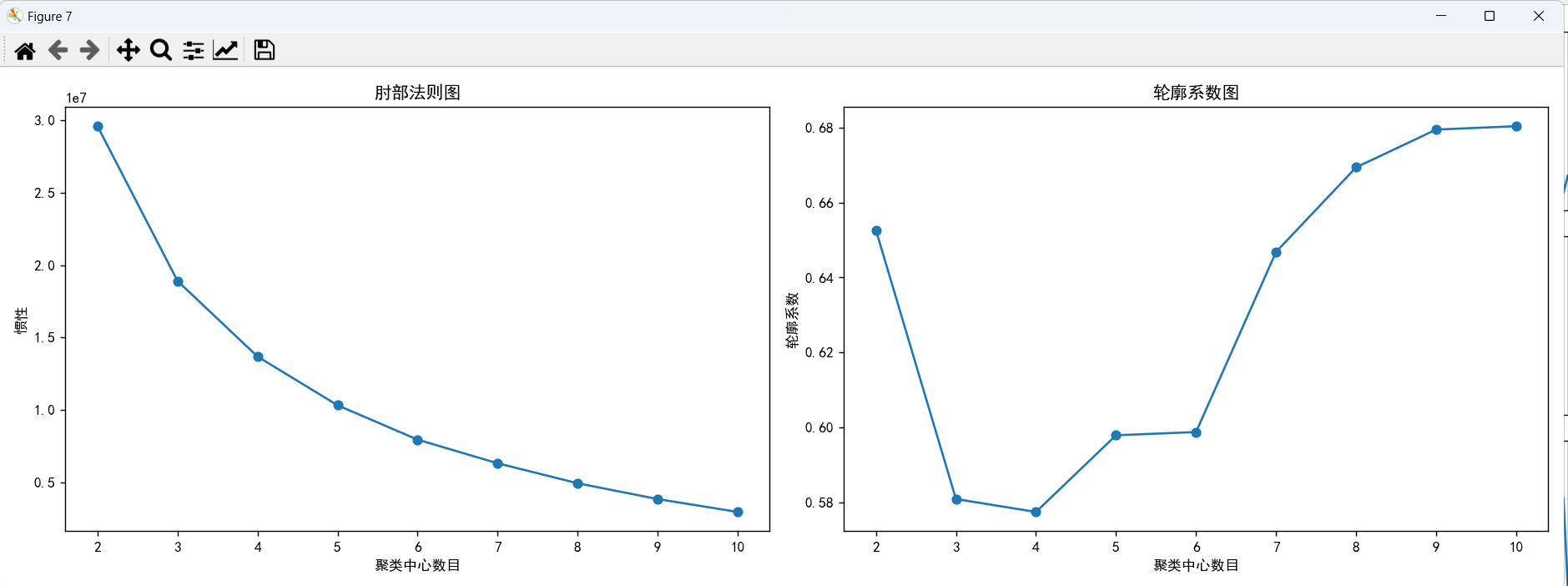
通过肘部法则图和轮廓系数图,可以看到,在4、5的时候,肘部法则图下降的趋势减缓,结合轮廓系数图,k取5的时候,轮廓系数比k取4的时候大,所以我们选择聚类数为5。
# 执行K-均值聚类,选择5个聚类
kmeans_final = KMeans(n_clusters=5, random_state=15)
kmeans_final.fit(new_user_features)
# 获取聚类标签
cluster_labels = kmeans_final.labels_
# 将聚类标签添加到原始数据中以进行分析
user_features['聚类标签'] = cluster_labels
user_features.head()

五类消费者对比
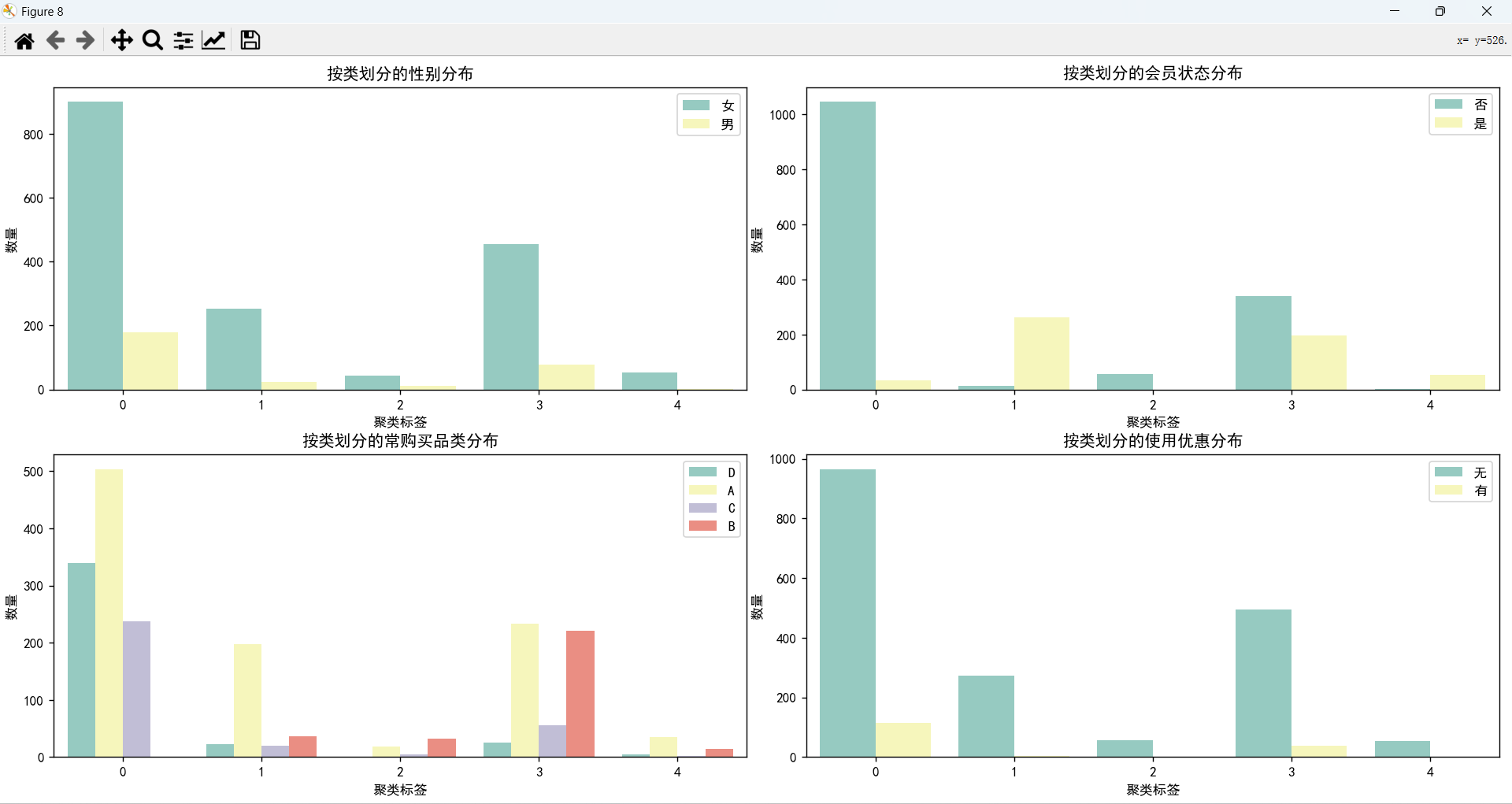
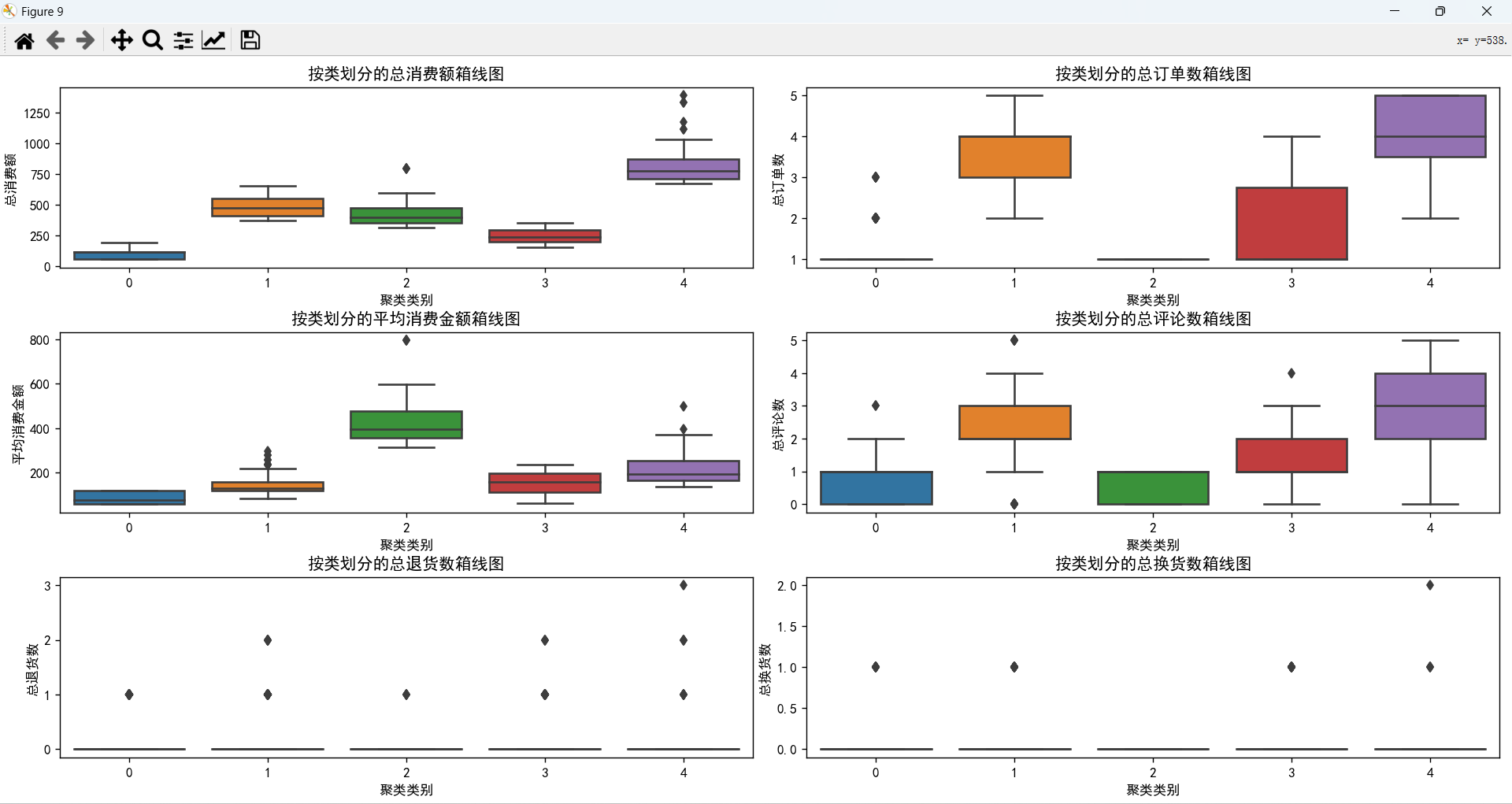
- 类型0:大多数消费者不是会员,没有购买过B类商品,大多数这一年里只购买过1单,评论数比较少,消费低,针对这一类消费者,可以针对他们推销A、D类的商品,并且考虑他们消费金额低,可以提供特殊折扣来重新吸引他们的兴趣。
- 类型1:大多数消费者是会员,主要购买的是A类商品,购买频率高,总消费金额位居第二,但是每次消费的金额都比较低,评论数量较多,针对这类消费者,可以提供一些会员专享优惠,优先投放A类商品的广告,吸引他们下单。
- 类型2:所有消费者都不是会员,但是都只购买过一次商品,不喜欢评论,最常购买的类型为B类商品,单次消费最高,这一类消费者是潜力群体,有一定的消费能力,但是他们的购买频率不高,针对这一类消费者,需要提出一些策略,使得他们转化为会员,并且设置一些激励活动,增加他们的购买频率。
- 类型3:不是会员的消费者的数量略高于是会员的消费者数量,他们主要购买A类商品和B类商品,购买频率高于类型0和类型2,但是购买金额低,评论数量适中,平均消费能力一般,针对这类消费者,主要推荐他们购买A类商品和B类商品,提供一些优惠活动。
- 类型4:全部都是会员,全是女性消费者,而且消费金额高,购买频率高,平均消费能力强,针对这一类消费者,需要与他们保持联系,并且赠送一些优惠券,开展一些激励活动,保持她们的忠诚度。
RFM模型
RFM模型是衡量客户价值和客户创造利益能力的重要工具。该模型通过客户在一定时间范围内的近期购买行为、购买总频率和购买总金额3项指标来描述该客户的价值状况。
R(Recency):最近一次消费的时间间隔,即客户最近一次与企业产生交易的时间间隔,一般已天为单位。
F(Frequency):消费总频次,即客户在一定时期范围内产生交易的累计频次。
M(Monetary):消费总金额,即客户在一定时期范围内产生交易的总累计金额。
R值越大,即客户与企业产生交易行为的周期越长,客户活跃度低,客户越容易流失。反之,客户与企业交易行为周期短,客户处于活跃状态。
F值越大,即客户与企业交易越频繁,客户与企业合作粘性强,忠诚度高。反之,客户与企业合作粘性差,忠诚度低。
M值越大,即客户与企业的交易金额大,侧面反映客户自身的经营规模大,市场份额多且资金能力强。反之,则客户的经营规模小,市场份额少且资金能力弱。
RFM模型通常将客户分成8类:重要价值客户、重要保持客户、重要发展客户、重要挽留客户、一般价值客户、一般保持客户、一般发展客户和一般挽留客户。
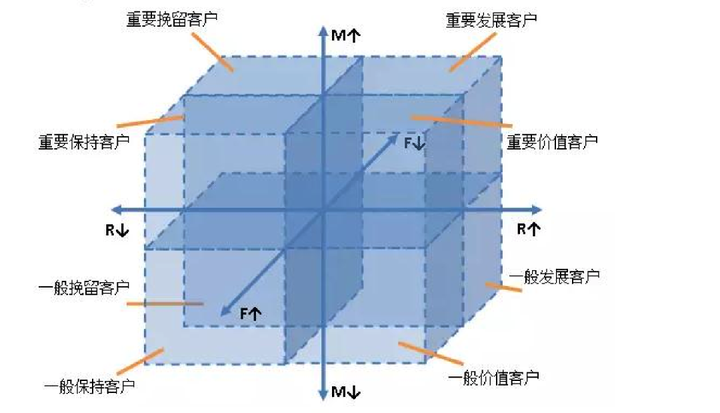
# 以2024年1月1日作为截止日期
current_date = pd.to_datetime('2024-01-01')
# 将日期字符串转换为日期对象
user_features['最近购买日期'] = pd.to_datetime(user_features['最近购买日期'])
# 计算RFM指标
rfm_data = user_features.groupby('用户ID').agg({
'最近购买日期': lambda x: (current_date - x.max()).days,
'总订单数': 'sum',
'总消费额': 'sum'
}).rename(columns={'最近购买日期': 'Recency', '总订单数': 'Frequency', '总消费额': 'Monetary'})
# 计算RFM分数
rfm_data['Recency_Score'] = pd.qcut(rfm_data['Recency'], 5, labels=False, duplicates='drop') + 1
rfm_data['Frequency_Score'] = pd.qcut(rfm_data['Frequency'].rank(method='first'), 5, labels=False, duplicates='drop') + 1
rfm_data['Monetary_Score'] = pd.qcut(rfm_data['Monetary'], 5, labels=False, duplicates='drop') + 1
rfm_data.head()

def assign_rfm_group(row):
if row['Frequency_Score'] >= 4 and row['Monetary_Score'] >= 4 and row['Recency_Score'] >= 4:
return '重要价值客户'
elif row['Frequency_Score'] >= 4 and row['Monetary_Score'] < 4 and row['Recency_Score'] >= 4:
return '重要保持客户'
elif row['Frequency_Score'] < 4 and row['Monetary_Score'] >= 4 and row['Recency_Score'] >= 4:
return '重要发展客户'
elif row['Frequency_Score'] < 4 and row['Monetary_Score'] >= 4 and row['Recency_Score'] < 4:
return '重要挽留客户'
elif row['Frequency_Score'] >= 4 and row['Monetary_Score'] < 4 and row['Recency_Score'] < 4:
return '一般价值客户'
elif row['Frequency_Score'] >= 4 and row['Monetary_Score'] < 4 and row['Recency_Score'] < 4:
return '一般保持客户'
elif row['Frequency_Score'] < 4 and row['Monetary_Score'] < 4 and row['Recency_Score'] >= 4:
return '一般发展客户'
else:
return '一般挽留客户'
rfm_data['客户类型'] = rfm_data.apply(assign_rfm_group, axis=1)
# 将RFM分析结果添加到用户数据中
user_features = user_features.join(rfm_data['客户类型'], on='用户ID')
user_features.head()

总结
本项目通过可视化分析对数据进行初步探索,再通过时间序列针对店铺的销售额进行分析,对时序图进行分解,发现数据存在季节性,并且通过auto_arima自动选择参数建立了SARIMA模型,对未来7天的销售额进行预测,然后利用特征构建一个新的数据,该数据主要包括各个消费者的情况,再利用聚类分析将消费者分为5类不同的群体,再建立RFM模型,将消费者进一步划分为不同价值的客户,对于不价值的消费者,采取不同的方案,通过这些模型,可以针对不同的消费群体采取不同的营销方案,尽可能的保留重要价值客户,对于一些低价值的客户,可以降低投入成本。