文章目录
- LinkedList简介
- LinkedList例子
- LinkedList继承结构
- LinkedList代码分析
- 成员变量
- 方法
- ArrayDeque简介
- ArrayDeque继承结构
- ArrayDeque代码分析
- 总结
- 参考链接
本人的源码阅读主要聚焦于类的使用场景,一般只在java层面进行分析,没有深入到一些native方法的实现。并且由于知识储备不完整,很可能出现疏漏甚至是谬误,欢迎指出共同学习
本文基于corretto-17.0.9源码,参考本文时请打开相应的源码对照,否则你会不知道我在说什么
LinkedList简介
从功能上看,LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
从内部实现来看,LinkedList其实只是对链表的封装,没什么特别之处,下面代码分析也会非常简短。与 ArrayList 相比,LinkedList 的增加和删除的操作效率更高,而查找和修改的操作效率较低,这些显然也是链表和数组的区别。
LinkedList例子
例子就不看了,都是些一眼懂的API
LinkedList继承结构
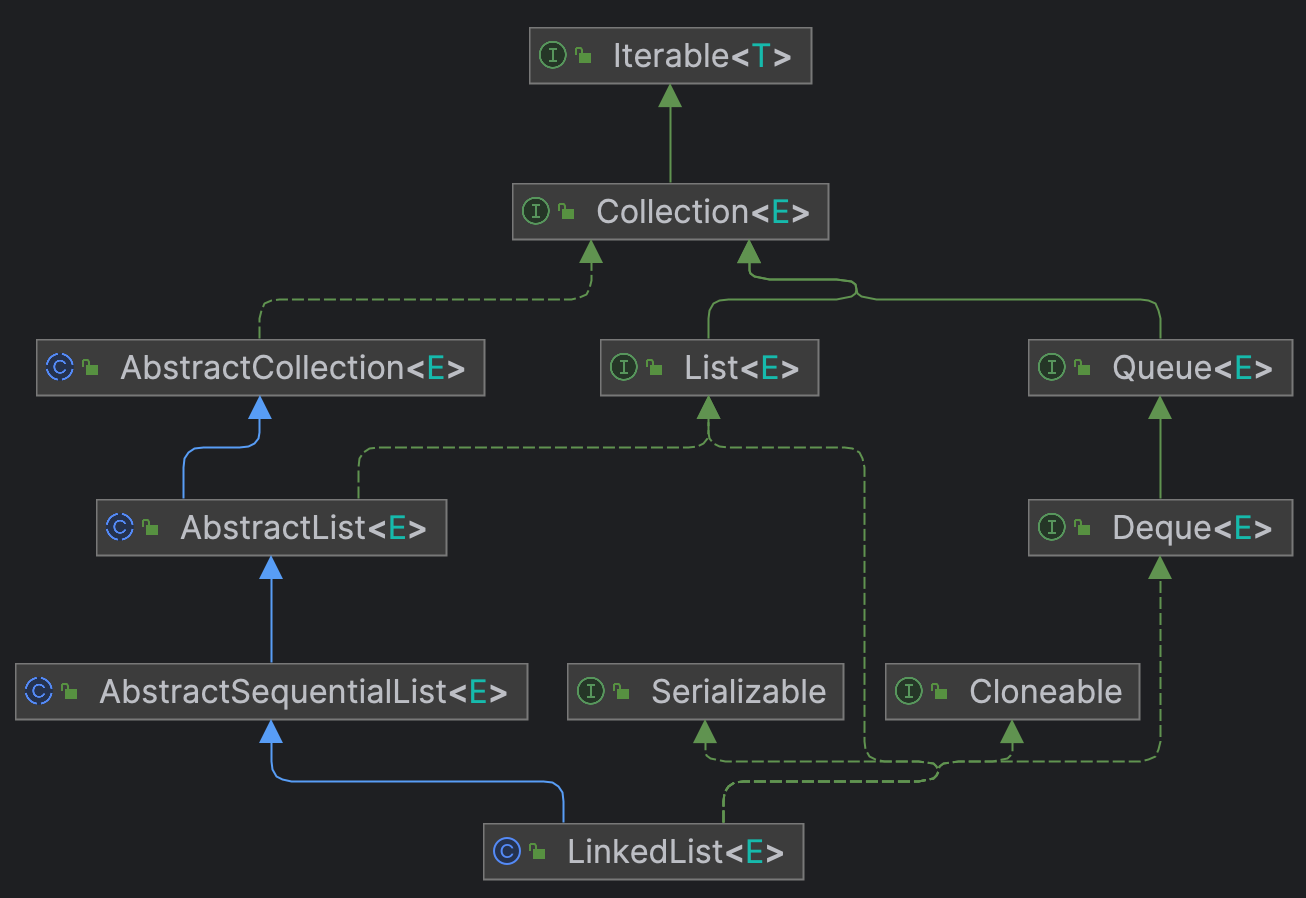
LinkedList,作为一个顺序列表继承于AbstractSequentialList,AbstractSequentialList与AbstractList的区别是,前者一般是不可随机访问的列表,或者说随机访问效率很低,而后者可以高效地基于下标随机访问,LinkedList作为链表的封装,众所周知链表无法随机访问元素,因此继承于AbstractSequentialList。
LinkedList作为List(Sequence),每个元素都对应着一个下标,链表头指针(first)指向的节点下标为0,尾指针(last)指向的节点下标为size-1。
其中JCF相关的接口和抽象类不了解的话,可以在参考「博客园」JCF相关基础类接口/抽象类源码阅读。
LinkedList代码分析
成员变量
LinkedList的成员变量也很少,了解链表的话一眼懂:
// 元素个数
transient int size = 0;
// 链表头指针
transient Node<E> first;
// 链表尾指针
transient Node<E> last;
// 链表节点类
private static class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
头和尾指针指向的都是真实元素节点,没有dummy node。注意到Node有next和prev指针,说明是LinkedList维护的是一个双向链表。
方法
首先是构造函数,没啥好说,一个无参构造对应空列表,一个根据Collection接口规范的用其他集合来初始化本集合的构造函数:
public LinkedList() {}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
下面看一下各个方法,一些链表操作或比较简单的方法就不分析了,只用注释说明功能,先看一下内部方法:
// 头插新节点
private void linkFirst(E e);
// 尾插新节点
void linkLast(E e);
// 在succ节点前插入新节点
void linkBefore(E e, Node<E> succ);
// 删除头节点
private E unlinkFirst(Node<E> f);
// 删除尾节点
private E unlinkLast(Node<E> l);
// 删除节点
E unlink(Node<E> x);
// 获取下标为index的节点
LinkedList.Node<E> node(int index) {
if (index < (size >> 1)) { // 如果节点在链表前半部分,则从first开始往后遍历
LinkedList.Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 否则从last开始往前遍历
LinkedList.Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
再看一下公有方法(太简单的公有方法略过)
// 按c的迭代器的顺序插入链表,最先遍历到的元素下标最小
public boolean addAll(int index, Collection<? extends E> c);
// 清空链表,不像ArrayList的置null,这个方法会删除所有节点
public void clear();
至此,实现Deque的方法已经介绍完。在JCF介绍一文中提到过继承AbstractSequentialList的类要么重写增删改查,要么重新实现列表迭代器,LinkedList两者都做了,增删改查方法很简单,略过,看一下迭代器:
private class ListItr implements ListIterator<E> {
// 相当于AbstractList.Itr的lastRet下标对应的节点
private Node<E> lastReturned;
// 相当于AbstractList.Itr的cursor下标对应的节点
private Node<E> next;
// 相当于Abstrac
private int nextIndex;
// 期望的修改次数,用于检测并发修改
private int expectedModCount = modCount;
}
可以发现LinkedList实现的这个ListIterator没什么特别的,也还是直接对链表进行操作,与AbstractList.ListIterator其实很类似,就不讲了。
java 1.6开始还提供了一个反向迭代器,一眼懂:
public Iterator<E> descendingIterator() {
return new DescendingIterator();
}
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
ArrayDeque简介
ArrayDeque是双端队列接口Deque的实现。出于性能上的考虑,如果你要用FIFO队列,可以优先考虑ArrayDeque而不是LinkedList;如果要使用栈,可以优先考虑ArrayDeque而不是LinkedList。ArrayDeque除了个别方法外,基本摊还时间复杂度都是O(1)。这个类的迭代器也是fail-fast的(这个概念在ArrayList那篇中讲过)。
ArrayDeque继承结构
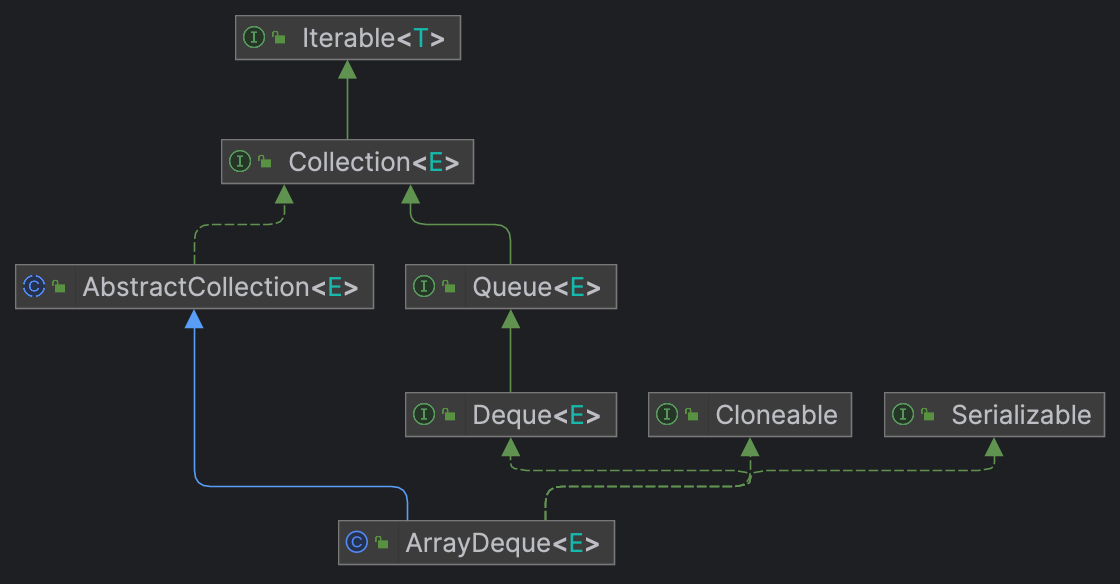
根据继承结构可以确定,ArrayDeque就是一个用数组实现的双端队列,并且由于是“双端”,我们可以进一步推测出应该是用循环数组来实现的。
ArrayDeque代码分析
按照惯例,先搞懂成员变量的含义:
public class ArrayDeque<E> extends AbstractCollection<E> implements Deque<E>, Cloneable, Serializable {
// 实际存储元素的数组,没有存元素的话为null
transient Object[] elements;
// 循环数组的头指针,指向头元素
transient int head;
// 循环数组的尾指针,指向下一个要入队的尾元素
transient int tail;
}
注意没有存元素的位置是null,因此ArrayDeque不能存值为null的元素,至于为什么,看完下面分析就知道了。
先复习一下循环数组,当调用addLast的时候,往尾部增加元素;当调用addFirst的时候往头部增加元素,画一张图帮助理解,其中数字代表元素下标,蓝色的代表该位置有元素,其他的不用多解释了:
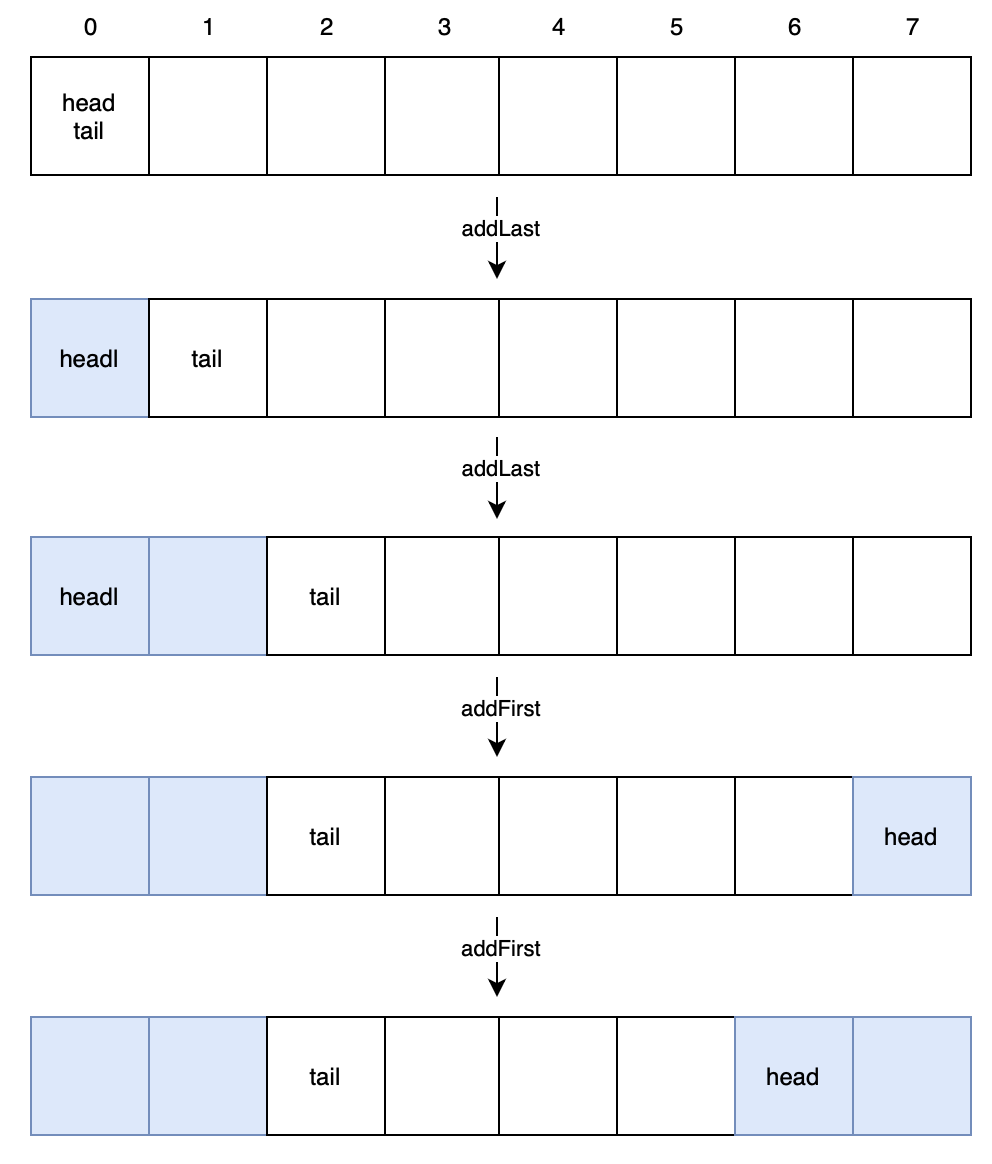
要注意的是,tail永远要指向null,意味着数组大小为n的话,最多只能存n-1个元素。否则如果存满数组的话,最终tail与head相等,此时无法判断是队空还是队满。
ArrayDeque没有设size变量保存元素个数,因为可以用head和tail计算得到。但是循环数组中tail可能大于head也可能小于head,因此设计一个概念:循环距离。首先tail入队时是递增的,head入队下标是递减的,因此head和tail的循环距离就是(结合图来理解):
- 当tail>=head,为tail-head
- 当tail<head,为tail-head+数组长度(相当于数组长度减去空白格子的个数,得到蓝色格子个数)
因此size就等于循环距离。ok,关于循环数组的原理以及元素出入队的细节都搞清楚了,那么由于循环数组是个数组(废话),总会有容量不够的时候,下一步就来分析数组的扩容。扩容的核心方法是grow:
// 最少要增加needed(ArrayList中的grow是最少增加到minCapacity)
private void grow(int needed) {
final int oldCapacity = elements.length;
int newCapacity;
// 这一段是计算扩容后的长度,总体策略是:
// 如果数组比较小(小于64)那么扩容到2倍,否则扩容到1.5倍
int jump = (oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1);
if (jump < needed
|| (newCapacity = (oldCapacity + jump)) - MAX_ARRAY_SIZE > 0)
newCapacity = newCapacity(needed, jump);
// 这一段是扩容
final Object[] es = elements = Arrays.copyOf(elements, newCapacity);
if (tail < head || (tail == head && es[head] != null)) {
int newSpace = newCapacity - oldCapacity;
System.arraycopy(es, head,
es, head + newSpace,
oldCapacity - head);
for (int i = head, to = (head += newSpace); i < to; i++)
es[i] = null;
}
}
grow的最后一段代码是为了处理tail<=head的情况,具体还是看图,假设从之前那张图中数组的最后一个状态开始扩容,大小+3(实际上不一定需要扩容,扩容的话也不一定是+3,这里只是为了方便说明这段代码的最后一个部分):
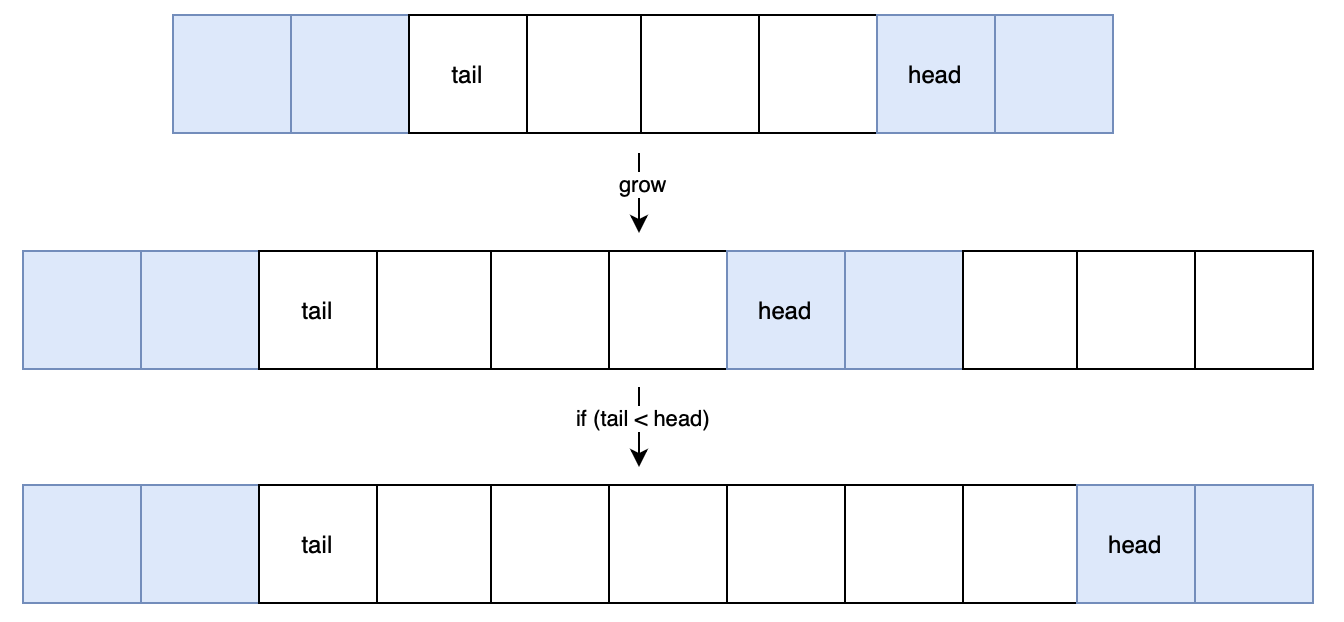
由于tail < head的情况下,元素是物理不连续的(循环数组嘛),因此最后一段 if 将后面那段移动到新数组的尾部,保持循环数组中元素的连续性。
Deque和Collection的一些方法就不说了,都很简单。挑一点看着相对需要分析的函数来看一下:
// 删除从头到尾的第i个元素
boolean delete(int i) {
final Object[] es = elements;
final int capacity = es.length;
final int h, t;
// 计算第i个元素与头的循环距离
final int front = sub(i, h = head, capacity);
// 计算第i个元素与尾的循环距离
final int back = sub(t = tail, i, capacity) - 1;
// 哪个循环距离小,就移动哪部分。这里意思是,因为是循环数组,删除一个元素之后,可以把前半部分的元素整体往后移动,也可以把后半部分的元素整体往前移动,因此选择需要移动元素少的那部分。
if (front < back) {
if (h <= i) {
System.arraycopy(es, h, es, h + 1, front);
} else { // Wrap around
System.arraycopy(es, 0, es, 1, i);
es[0] = es[capacity - 1];
System.arraycopy(es, h, es, h + 1, front - (i + 1));
}
es[h] = null;
head = inc(h, capacity);
return false;
} else {
tail = dec(t, capacity);
if (i <= tail) {
System.arraycopy(es, i + 1, es, i, back);
} else {
System.arraycopy(es, i + 1, es, i, capacity - (i + 1));
es[capacity - 1] = es[0];
System.arraycopy(es, 1, es, 0, t - 1);
}
es[tail] = null;
return true;
}
}
还有的函数比如bulkRemoveModified,其实跟ArrayList的removeIf很像了,也是先标记所有将要被删除的元素,然后再进行逐个删除,这种做法是为了filter进行逐元素进行判断时,保持遍历过程中列表是可重入读的,在实际进行删除时使用双指针法保持元素连续性。具体可以参考「博客园」ArrayList源码阅读。
最后看一眼迭代器吧,因为JCF前几篇都已经详细介绍过迭代器,ArrayDeque的迭代器实现也没什么特别的,就不展开讲了:
private class DeqIterator implements Iterator<E> {
int cursor;
int remaining = size();
int lastRet = -1;
}
总结
类似ArrayList是对数组的封装,LinkedList是对数组的封装,代码看起来也比较简单,适合编程新手学习一下“封装”的概念。(又水一篇)。
java 1.6新出了一个ArrayDeque,出于性能上的考虑,如果你要用FIFO队列,可以优先考虑ArrayDeque而不是LinkedList;如果要使用栈,可以优先考虑ArrayDeque而不是LinkedList。
参考链接
「博客园」JCF相关基础类接口/抽象类源码阅读
「博客园」ArrayList源码阅读
「Java全栈知识体系」Collection - LinkedList源码解析