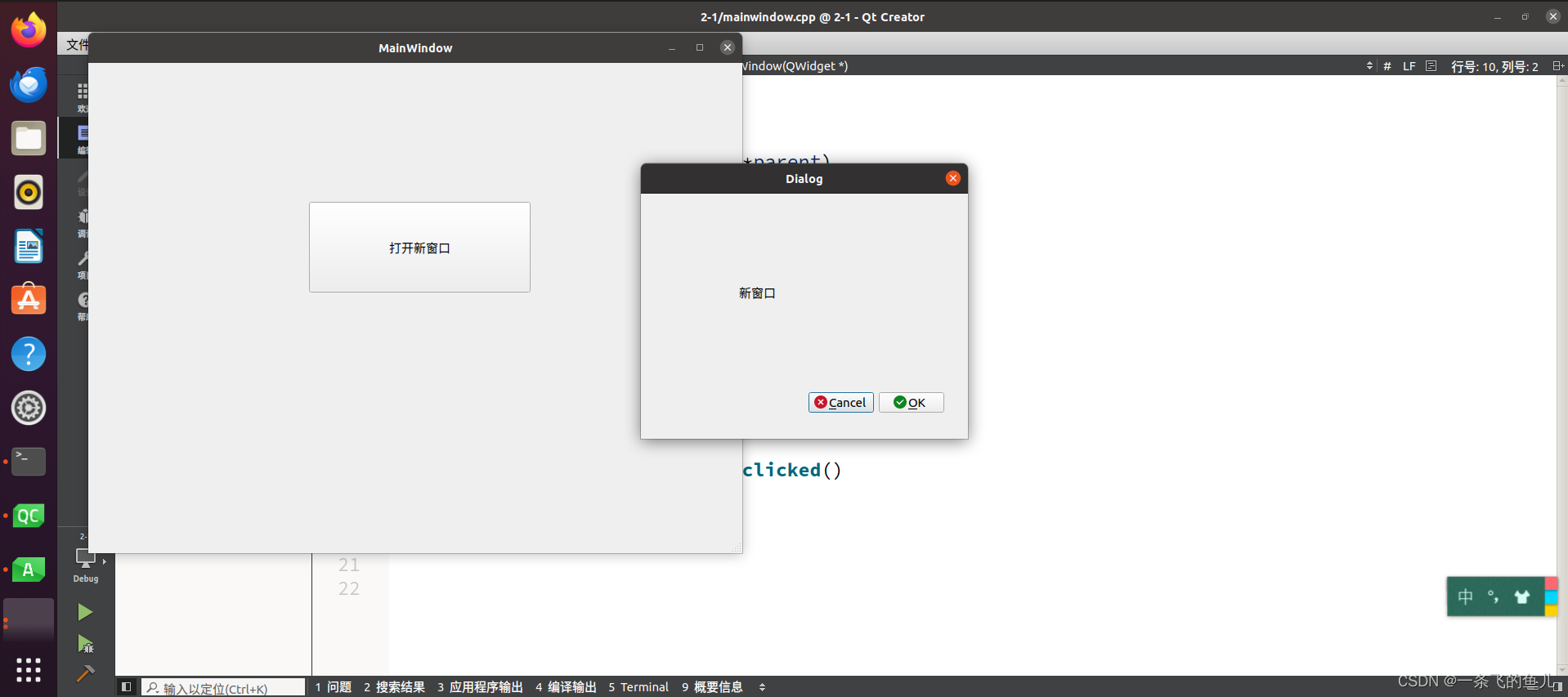
SparkSQL初体验
-
命令式的 API
RDD 版本的 WordCount
val conf = new SparkConf().setAppName("ip_ana").setMaster("local[6]") val sc = new SparkContext(conf) sc.textFile("hdfs://master:9000/dataset/wordcount.txt") .flatMap(_.split(" ")) .map((_, 1)) .reduceByKey(_ + _) .collect- RDD 版本的代码有一个非常明显的特点, 就是它所处理的数据是基本类型的, 在算子中对整个数据进行处理
命令式 API 的入门案例
pom.xml文件加
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.1.1</version> </dependency>-
code (dataset)
@Test def dsIntro(): Unit = { val spark = new SparkSession.Builder() .appName("ds intro") .master("local[6]") .getOrCreate() import spark.implicits._ // 导入隐式转换 val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15))) val persons = sourceRDD.toDS() val resultDS = persons.where('age > 10) .where('age < 20) .select('name) .as[String] resultDS.show() } case class Person(name: String, age: Int)
-
SparkSession
SparkContext 作为 RDD 的创建者和入口, 其主要作用有如下两点
- 创建 RDD, 主要是通过读取文件创建 RDD
- 监控和调度任务, 包含了一系列组件, 例如 DAGScheduler, TaskSheduler
为什么无法使用 SparkContext 作为 SparkSQL 的入口?
- SparkContext 在读取文件的时候, 是不包含 Schema 信息的, 因为读取出来的是 RDD
- SparkContext 在整合数据源如 Cassandra, JSON, Parquet 等的时候是不灵活的, 而 DataFrame 和 Dataset 一开始的设计目标就是要支持更多的数据源
- SparkContext 的调度方式是直接调度 RDD, 但是一般情况下针对结构化数据的访问, 会先通过优化器优化一下
所以 SparkContext 确实已经不适合作为 SparkSQL 的入口, 所以刚开始的时候 Spark 团队为 SparkSQL 设计了两个入口点, 一个是 SQLContext 对应 Spark 标准的 SQL 执行, 另外一个是 HiveContext 对应 HiveSQL 的执行和 Hive 的支持.
在 Spark 2.0 的时候, 为了解决入口点不统一的问题, 创建了一个新的入口点 SparkSession, 作为整个 Spark 生态工具的统一入口点, 包括了 SQLContext, HiveContext, SparkContext 等组件的功能
新的入口应该有什么特性?
- 能够整合 SQLContext, HiveContext, SparkContext, StreamingContext 等不同的入口点
- 为了支持更多的数据源, 应该完善读取和写入体系
- 同时对于原来的入口点也不能放弃, 要向下兼容
-
DataFrame & Dataset
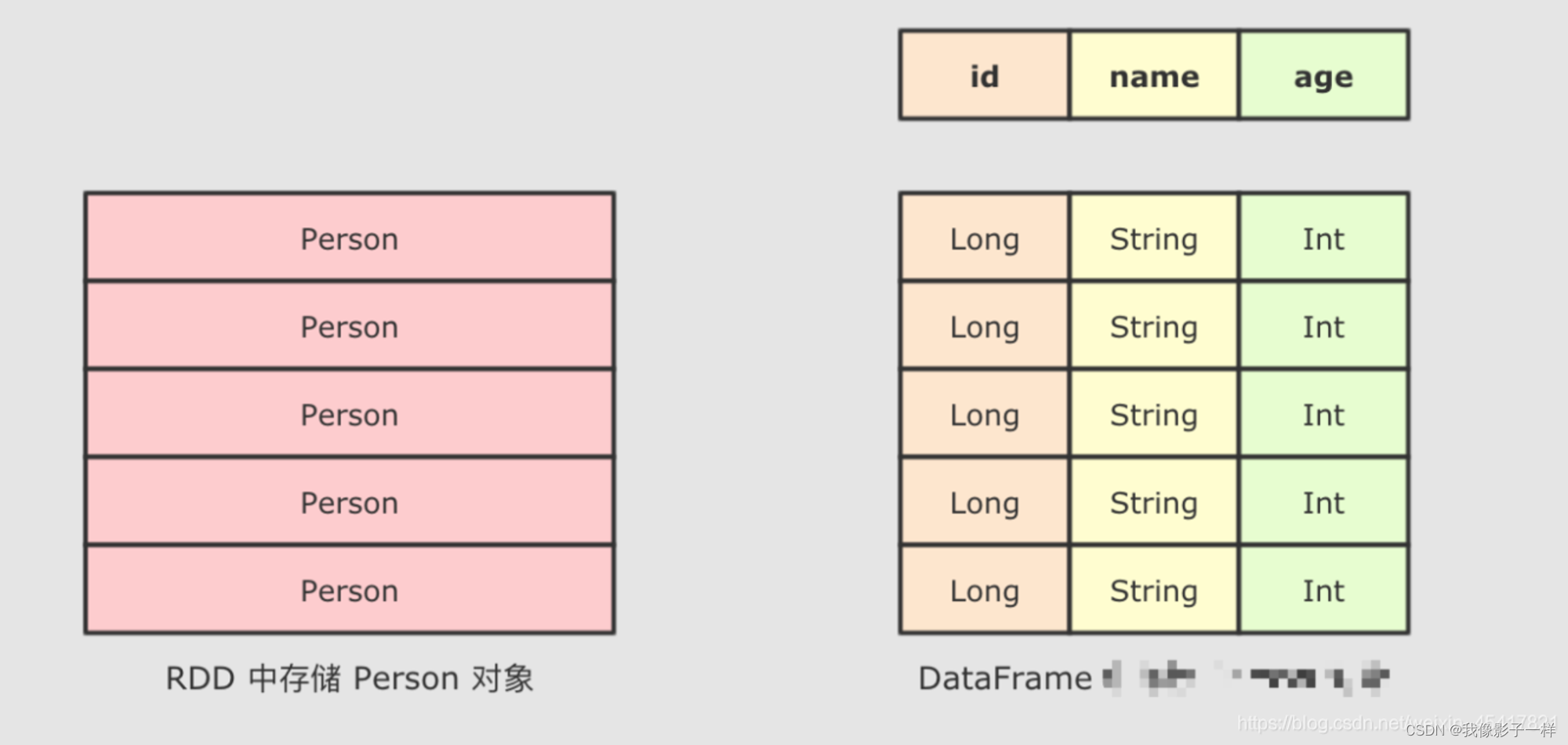
SparkSQL 最大的特点就是它针对于结构化数据设计, 所以 SparkSQL 应该是能支持针对某一个字段的访问的, 而这种访问方式有一个前提, 就是 SparkSQL 的数据集中, 要 包含结构化信息, 也就是俗称的 Schema
而 SparkSQL 对外提供的 API 有两类, 一类是直接执行 SQL, 另外一类就是命令式. SparkSQL 提供的命令式 API 就是 DataFrame 和 Dataset, 暂时也可以认为 DataFrame 就是 Dataset, 只是在不同的 API 中返回的是 Dataset 的不同表现形式
// RDD rdd.map { case Person(id, name, age) => (age, 1) } .reduceByKey {case ((age, count), (totalAge, totalCount)) => (age, count + totalCount)} // DataFrame df.groupBy("age").count("age")通过上面的代码, 可以清晰的看到, SparkSQL 的命令式操作相比于 RDD 来说, 可以直接通过 Schema 信息来访问其中某个字段, 非常的方便
-
声明式的API
SQL 版本 WordCount
@Test def dfIntro(): Unit = { val spark = new SparkSession.Builder() .appName("df intro") .master("local[6]") .getOrCreate() import spark.implicits._ val sourceRDD = spark.sparkContext.parallelize(Seq(Person("zhangsan", 10), Person("lisi", 15))) val df = sourceRDD.toDF() // 注册临时表 df.createOrReplaceTempView("person") val resultDF = spark.sql("select name from person where age > 10 and age < 20") resultDF.show() } // case class Person(name: String, age: Int)以往使用 SQL 肯定是要有一个表的, 在 Spark 中, 并不存在表的概念, 但是有一个近似的概念, 叫做 DataFrame, 所以一般情况下要先通过 DataFrame 或者 Dataset 注册一张临时表, 然后使用 SQL 操作这张临时表
总结
- SparkSQL 提供了 SQL 和 命令式 API 两种不同的访问结构化数据的形式, 并且它们之间可以无缝的衔接
- 命令式 API 由一个叫做 Dataset 的组件提供, 其还有一个变形, 叫做 DataFrame