准备多个数据库
首先准备多个数据库,主库smiling-datasource,其它库test1、test2、test3
接下来,我们在主库smiling-datasource中,创建表databasesource,用于存储多数据源相关信息。表结构设计如下

创建好表之后,向表databasesource中存储test1、test2、test3三个数据库的相关配置信息

在主库的表databasesource中存储好数据源信息后,接下来分别在test1、test2、test3以及主库smiling-datasource中都创建sys_user数据表,用于后续测试数据源切换是否正常。sys_user的表结构如下所示

创建好sys_user之后,分别向sys_user表中添加一条数据,添加的数据中分表用不同的内容表示属于哪个库,方便后续测试。
依赖
该实现主要用到JDK1.8、spring-boot-starter-parent的版本为2.2.0.RELEASE,除此之外需要用到mysql、druid以及mybatis-plus的依赖
配置
在配置文件application.yml中主要配置主库的数据源信息,配置如下
spring:
aop:
proxy-target-class: true #true为使用CGLIB代理
datasource:
url: jdbc:mysql://localhost:3306/smiling-datasource?useSSL=false&useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&zeroDateTimeBehavior=convertToNull
username: root
password: zhangpei@123
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
druid:
initial-size: 5 #初始化大小
min-idle: 5 #最小连接数
max-active: 20 #最大连接数
time-between-eviction-runs-millis: 60000 #配置间隔多久进行一次检测,检测需要关闭的空闲连接,单位毫秒
min-evictable-idle-time-millis: 300000 #配置一个连接在池中最小生存的时间,单位毫秒
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: false
test-on-return: false
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
filters: stat,wall,log4j #配置监控统计拦截的filters,去掉后监控界面sql无法统计,wall用于防火墙
connection-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000 #通过该属性打开mergeSQl功能:慢sql记录功能
use-global-data-source-stat: true #合并多个DruidDataSource的监控数据
max-wait: 60000 #配置获取连接等待超时时间
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
mapper-locations: classpath*:/mapping/*.xml基类DataSource
创建类DataSource,用于数据源信息的装配
@Data
@ToString
public class DataSource {
String datasourceId;
String url;
String username;
String password;
String code;
String databasetype;
String driverclass;
String key;
}DruidDBConfig配置类
该配置类主要用于配置默认的主数据源信息,配置Druid数据库连接池,配置sql工厂加载mybatis的文件,扫描实体类等
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.core.io.support.ResourcePatternResolver;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
/**
* 配置默认数据源
* 配置Druid数据库连接池
* 配置sql工厂加载mybatis的文件,扫描实体等
*
* @author smiling
* @date 2023/10/7 19:04
*/
@Slf4j
@Configuration
@EnableTransactionManagement
public class DruilDBConfig {
@Value("${spring.datasource.url}")
private String dbUrl;
@Value("${spring.datasource.username}")
private String username;
@Value("${spring.datasource.password}")
private String password;
@Value("${spring.datasource.driver-class-name}")
private String driverClassName;
// 连接池连接信息
@Value("${spring.datasource.druid.initial-size}")
private int initialSize;
@Value("${spring.datasource.druid.min-idle}")
private int minIdle;
@Value("${spring.datasource.druid.max-active}")
private int maxActive;
@Value("${spring.datasource.druid.max-wait}")
private int maxWait;
@Bean
@Primary
@Qualifier("mainDataSource")
public DataSource dataSource() throws SQLException {
DruidDataSource dataSource = new DruidDataSource();
// 基础连接信息
dataSource.setUrl(this.dbUrl);
dataSource.setUsername(username);
dataSource.setPassword(password);
dataSource.setDriverClassName(driverClassName);
// 连接池连接信息
dataSource.setInitialSize(initialSize);
dataSource.setMinIdle(minIdle);
dataSource.setMaxActive(maxActive);
dataSource.setMaxWait(maxWait);
dataSource.setPoolPreparedStatements(true); //是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。
dataSource.setMaxPoolPreparedStatementPerConnectionSize(20);
// datasource.setConnectionProperties("oracle.net.CONNECT_TIMEOUT=6000;oracle.jdbc.ReadTimeout=60000");//对于耗时长的查询sql,会受限于ReadTimeout的控制,单位毫秒
dataSource.setConnectionProperties("druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000");//对于耗时长的查询sql,会受限于ReadTimeout的控制,单位毫秒
dataSource.setTestOnBorrow(true); //申请连接时执行validationQuery检测连接是否有效,这里建议配置为TRUE,防止取到的连接不可用
dataSource.setTestWhileIdle(true);//建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
String validationQuery = "select 1 from dual";
dataSource.setValidationQuery(validationQuery); //用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
dataSource.setFilters("stat,wall");//属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有:监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall
dataSource.setTimeBetweenEvictionRunsMillis(60000); //配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
dataSource.setMinEvictableIdleTimeMillis(180000); //配置一个连接在池中最小生存的时间,单位是毫秒,这里配置为3分钟180000
dataSource.setKeepAlive(true); //打开druid.keepAlive之后,当连接池空闲时,池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作,即执行druid.validationQuery指定的查询SQL,一般为select * from dual,只要minEvictableIdleTimeMillis设置的小于防火墙切断连接时间,就可以保证当连接空闲时自动做保活检测,不会被防火墙切断
dataSource.setRemoveAbandoned(true); //是否移除泄露的连接/超过时间限制是否回收。
dataSource.setRemoveAbandonedTimeout(3600); //泄露连接的定义时间(要超过最大事务的处理时间);单位为秒。这里配置为1小时
dataSource.setLogAbandoned(true); //移除泄露连接发生是是否记录日志
return dataSource;
}
/**
* 注册一个statViewServlet druid监控页面配置
* 账号密码配置
*
* @return
*/
@Bean
public ServletRegistrationBean druidStatViewServlet() {
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
servletRegistrationBean.addInitParameter("loginUsername", "admin");
servletRegistrationBean.addInitParameter("loginPassword", "123456");
servletRegistrationBean.addInitParameter("resetEnable", "false");
return servletRegistrationBean;
}
/**
* 注册一个:filterRegistrationBean druid监控页面配置2-允许页面正常浏览
*
* @return filter registration bean
*/
@Bean
public FilterRegistrationBean druidStatFilter() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter());
// 添加过滤规则.
filterRegistrationBean.addUrlPatterns("/*");
// 添加不需要忽略的格式信息.
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
return filterRegistrationBean;
}
@Bean(name = "dynamicDataSource")
@Qualifier("dynamicDataSource")
public DynamicDataSource dynamicDataSource() throws SQLException {
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setDebug(false);
//配置缺省的数据源
// 默认数据源配置 DefaultTargetDataSource
dynamicDataSource.setDefaultTargetDataSource(dataSource());
Map<Object, Object> targetDataSources = new HashMap<Object, Object>();
//额外数据源配置 TargetDataSources
targetDataSources.put("mainDataSource", dataSource());
dynamicDataSource.setTargetDataSources(targetDataSources);
return dynamicDataSource;
}
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dynamicDataSource());
//解决手动创建数据源后字段到bean属性名驼峰命名转换失效的问题
sqlSessionFactoryBean.setConfiguration(configuration());
// 设置mybatis的主配置文件
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
// Resource mybatisConfigXml = resolver.getResource("classpath:mybatis/mybatis-config.xml");
// sqlSessionFactoryBean.setConfigLocation(mybatisConfigXml);
// 设置别名包
// sqlSessionFactoryBean.setTypeAliasesPackage("com.testdb.dbsource.pojo");
//手动配置mybatis的mapper.xml资源路径,如果单纯使用注解方式,不需要配置该行
sqlSessionFactoryBean.setMapperLocations(resolver.getResources("classpath:/mapping/*.xml"));
return sqlSessionFactoryBean.getObject();
}
/**
* 读取驼峰命名设置
*
* @return
*/
@Bean
@ConfigurationProperties(prefix = "mybatis-plus.configuration")
public org.apache.ibatis.session.Configuration configuration() {
return new org.apache.ibatis.session.Configuration();
}
}DBContextHolder类
该类主要用于手动切换数据源
import lombok.extern.slf4j.Slf4j;
/**
* @author smiling
* @date 2023/10/7 19:16
*/
@Slf4j
public class DBContextHolder {
//对当前线程的操作-线程安全的
private static final ThreadLocal<String> contextHolder = new ThreadLocal<>();
//调用此方法,切换数据源
public static void setDataSource(String dataSource){
contextHolder.set(dataSource);
log.info("已切换到数据源:{}",dataSource);
}
//获取数据源
public static String getDataSource(){
return contextHolder.get();
}
//删除数据源
public static void clearDataSource(){
contextHolder.remove();
log.info("已切换到主数据源");
}
}DynamicDataSource类
该类实现手动加载默认数据源、创建数据源连接、检查数据源连接、删除数据源连接等
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.stat.DruidDataSourceStatManager;
import com.smiling.datasource.model.DataSource;
import lombok.extern.slf4j.Slf4j;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.util.ObjectUtils;
import java.sql.Connection;
import java.sql.DriverManager;
import java.util.Map;
import java.util.Set;
/**
* 手动加载默认数据源
* 创建数据源连接
* 检查数据源连接
* 删除数据源连接等
*
* @author smiling
* @date 2023/10/8 11:03
*/
@Slf4j
public class DynamicDataSource extends AbstractRoutingDataSource {
private boolean debug = true;
private Map<Object, Object> dynamicTargetDataSources;
private Object dynamicDefaultTargetDataSource;
@Override
protected Object determineCurrentLookupKey() {
String datasource = DBContextHolder.getDataSource();
if (!ObjectUtils.isEmpty(datasource)) {
Map<Object, Object> targetDataSource = this.dynamicTargetDataSources;
if (targetDataSource.containsKey(datasource)) {
log.info("当前数据源:" + datasource);
} else {
log.info("不存在的数据源");
return null;
}
} else {
log.info("当前数据源:默认数据源");
}
return datasource;
}
@Override
public void setTargetDataSources(Map<Object, Object> targetDataSources) {
super.setTargetDataSources(targetDataSources);
this.dynamicTargetDataSources = targetDataSources;
}
//创建数据源
public boolean createDataSource(String key, String driveClass, String url, String username, String password, String databasetype) {
try {
try {
Class.forName(driveClass);
DriverManager.getConnection(url, username, password);
} catch (Exception e) {
return false;
}
@SuppressWarnings("resource")
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setName(key);
druidDataSource.setDriverClassName(driveClass);
druidDataSource.setUrl(url);
druidDataSource.setUsername(username);
druidDataSource.setPassword(password);
druidDataSource.setInitialSize(1); //初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时
druidDataSource.setMaxActive(20); //最大连接池数量
druidDataSource.setMaxWait(60000); //获取连接时最大等待时间,单位毫秒。当链接数已经达到了最大链接数的时候,应用如果还要获取链接就会出现等待的现象,等待链接释放并回到链接池,如果等待的时间过长就应该踢掉这个等待,不然应用很可能出现雪崩现象
druidDataSource.setMinIdle(5); //最小连接池数量
String validationQuery = "select 1 from dual";
druidDataSource.setTestOnBorrow(true); //申请连接时执行validationQuery检测连接是否有效,这里建议配置为TRUE,防止取到的连接不可用
druidDataSource.setTestWhileIdle(true);//建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
druidDataSource.setValidationQuery(validationQuery); //用来检测连接是否有效的sql,要求是一个查询语句。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
druidDataSource.setFilters("stat");//属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有:监控统计用的filter:stat日志用的filter:log4j防御sql注入的filter:wall
druidDataSource.setTimeBetweenEvictionRunsMillis(60000); //配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
druidDataSource.setMinEvictableIdleTimeMillis(180000); //配置一个连接在池中最小生存的时间,单位是毫秒,这里配置为3分钟180000
druidDataSource.setKeepAlive(true); //打开druid.keepAlive之后,当连接池空闲时,池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作,即执行druid.validationQuery指定的查询SQL,一般为select * from dual,只要minEvictableIdleTimeMillis设置的小于防火墙切断连接时间,就可以保证当连接空闲时自动做保活检测,不会被防火墙切断
druidDataSource.setRemoveAbandoned(true); //是否移除泄露的连接/超过时间限制是否回收。
druidDataSource.setRemoveAbandonedTimeout(3600); //泄露连接的定义时间(要超过最大事务的处理时间);单位为秒。这里配置为1小时
druidDataSource.setLogAbandoned(true); //移除泄露连接发生是是否记录日志
druidDataSource.init();
this.dynamicTargetDataSources.put(key, druidDataSource);
setTargetDataSources(this.dynamicTargetDataSources);// 将map赋值给父类的TargetDataSources
super.afterPropertiesSet();// 将TargetDataSources中的连接信息放入resolvedDataSources管理
log.info(key + "数据源初始化成功");
return true;
} catch (Exception e) {
log.error(e + "");
return false;
}
}
//删除数据源
public boolean delDatasources(String datasourceid) {
Map<Object, Object> targetDataSource = this.dynamicTargetDataSources;
if (targetDataSource.containsKey(datasourceid)) {
Set<DruidDataSource> druidDataSourceInstances = DruidDataSourceStatManager.getDruidDataSourceInstances();
for (DruidDataSource source : druidDataSourceInstances) {
if (datasourceid.equals(source.getName())) {
targetDataSource.remove(datasourceid);
DruidDataSourceStatManager.removeDataSource(source);
setTargetDataSources(targetDataSource);// 将map赋值给父类的TargetDataSources
super.afterPropertiesSet();// 将TargetDataSources中的连接信息放入resolvedDataSources管理
return true;
}
}
return false;
} else {
return false;
}
}
// 测试数据源连接是否有效
public boolean testDatasource(String key, String driveClass, String url, String username, String password) {
try {
Class.forName(driveClass);
DriverManager.getConnection(url, username, password);
return true;
} catch (Exception e) {
return false;
}
}
@Override
public void setDefaultTargetDataSource(Object defaultTargetDataSource) {
super.setDefaultTargetDataSource(defaultTargetDataSource);
this.dynamicDefaultTargetDataSource = defaultTargetDataSource;
}
public void setDebug(boolean debug) {
this.debug = debug;
}
public boolean isDebug() {
return debug;
}
public Map<Object, Object> getDynamicTargetDataSources() {
return dynamicTargetDataSources;
}
public void setDynamicTargetDataSources(Map<Object, Object> dynamicTargetDataSources) {
this.dynamicTargetDataSources = dynamicTargetDataSources;
}
public Object getDynamicDefaultTargetDataSource() {
return dynamicDefaultTargetDataSource;
}
public void setDynamicDefaultTargetDataSource(Object dynamicDefaultTargetDataSource) {
this.dynamicDefaultTargetDataSource = dynamicDefaultTargetDataSource;
}
public void createDataSourceWithCheck(DataSource dataSource) throws Exception {
String datasourceId = dataSource.getDatasourceId();
log.info("正在检查数据源:" + datasourceId);
Map<Object, Object> targetDataSources = this.dynamicTargetDataSources;
if (targetDataSources.containsKey(datasourceId)) {
log.info("数据源" + datasourceId + "之前已经创建,准备测试数据源是否正常...");
//DataSource druidDataSource = (DataSource) dynamicTargetDataSources2.get(datasourceId);
DruidDataSource druidDataSource = (DruidDataSource) targetDataSources.get(datasourceId);
boolean rightFlag = true;
Connection connection = null;
try {
log.info(datasourceId + "数据源的概况->当前闲置连接数:" + druidDataSource.getPoolingCount());
long activeCount = druidDataSource.getActiveCount();
log.info(datasourceId + "数据源的概况->当前活动连接数:" + activeCount);
if (activeCount > 0) {
log.info(datasourceId + "数据源的概况->活跃连接堆栈信息:" + druidDataSource.getActiveConnectionStackTrace());
}
log.info("准备获取数据库连接...");
connection = druidDataSource.getConnection();
log.info("数据源" + datasourceId + "正常");
} catch (Exception e) {
log.error(e.getMessage(), e); //把异常信息打印到日志文件
rightFlag = false;
log.info("缓存数据源" + datasourceId + "已失效,准备删除...");
if (delDatasources(datasourceId)) {
log.info("缓存数据源删除成功");
} else {
log.info("缓存数据源删除失败");
}
} finally {
if (null != connection) {
connection.close();
}
}
if (rightFlag) {
log.info("不需要重新创建数据源");
return;
} else {
log.info("准备重新创建数据源...");
createDataSource(dataSource);
log.info("重新创建数据源完成");
}
} else {
createDataSource(dataSource);
}
}
private void createDataSource(DataSource dataSource) throws Exception {
String datasourceId = dataSource.getDatasourceId();
log.info("准备创建数据源" + datasourceId);
String databasetype = dataSource.getDatabasetype();
String username = dataSource.getUsername();
String password = dataSource.getPassword();
String url = dataSource.getUrl();
String driveClass = "com.mysql.cj.jdbc.Driver";
if (testDatasource(datasourceId, driveClass, url, username, password)) {
boolean result = this.createDataSource(datasourceId, driveClass, url, username, password, databasetype);
if (!result) {
log.error("数据源" + datasourceId + "配置正确,但是创建失败");
}
} else {
log.error("数据源配置有错误");
}
}
}切换数据源使用的方法
首先获取主数据源的表databasesource里面的所有西悉尼,然后根据我们传入对应的数据源id进行数据源的切换
DataSourceMapper
@Mapper
public interface DataSourceMapper {
@Select("select * from databasesource")
List<DataSource> get();
}DBChangeService
public interface DBChangeService {
List<DataSource> get();
boolean changeDb(String datasourceId) throws Exception;
}DBChangeServiceImpl
@Service
public class DBChangeServiceImpl implements DBChangeService {
private DataSourceMapper dataSourceMapper;
private DynamicDataSource dynamicDataSource;
public DBChangeServiceImpl(DataSourceMapper dataSourceMapper,
DynamicDataSource dynamicDataSource){
this.dataSourceMapper = dataSourceMapper;
this.dynamicDataSource = dynamicDataSource;
}
@Override
public List<DataSource> get() { return dataSourceMapper.get(); }
@Override
public boolean changeDb(String datasourceId) throws Exception {
//默认切换到主数据源,进行整体资源的查找
DBContextHolder.clearDataSource();
List<DataSource> dataSourceList = dataSourceMapper.get();
for(DataSource source : dataSourceList){
if(source.getDatasourceId().equals(datasourceId)){
System.out.println("需要使用的数据源已经找到,datasourceId是:"+source.getDatasourceId());
//创建数据源连接&检查,若存在则不需要重新创建
dynamicDataSource.createDataSourceWithCheck(source);
//切换到该数据源
DBContextHolder.setDataSource(source.getDatasourceId());
return true;
}
}
return false;
}
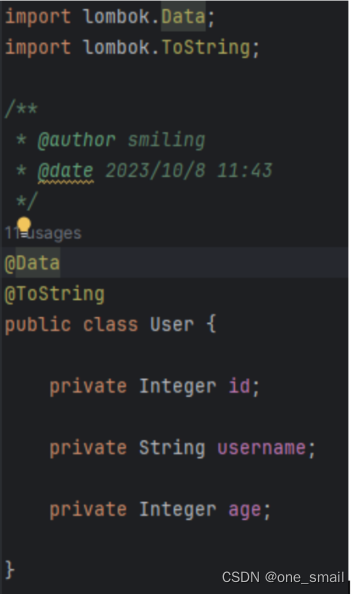
}实体类User
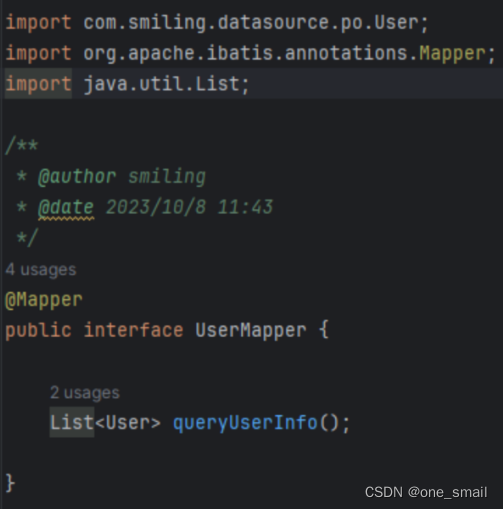
UserMapper
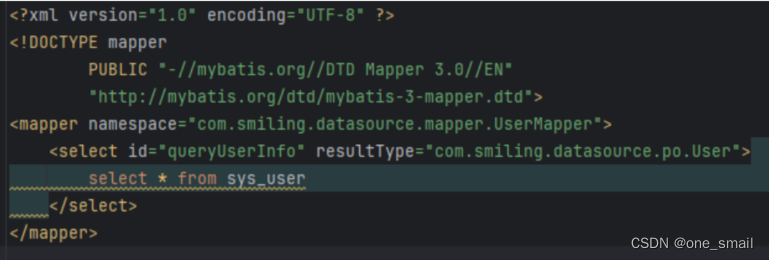
UserMapper.xml
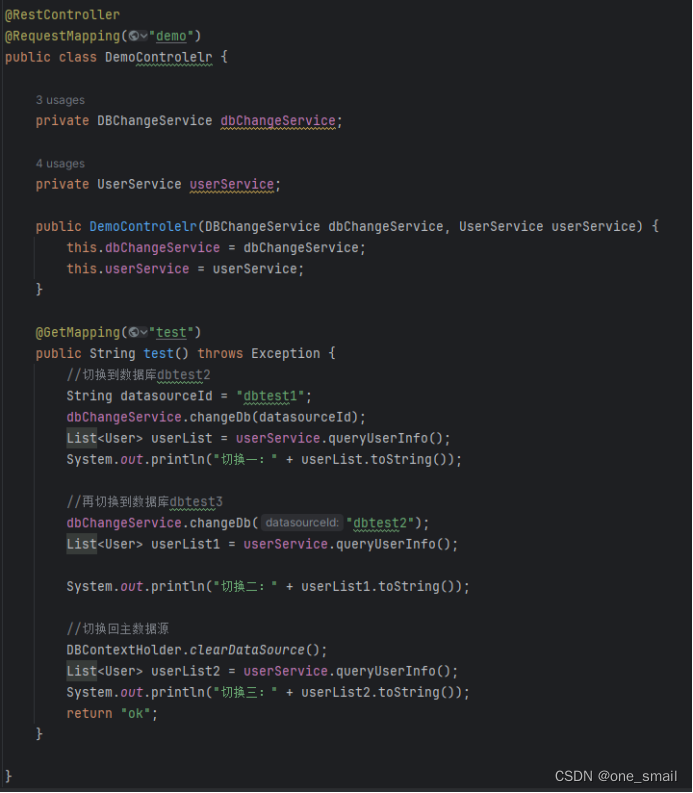
DemoController
通过请求接口,通过控制台日志打印可以看到数据源的切换信息
多数据源事务管理
实现动态数据源事务,在类DruidDBConfig配置类中将我们实现的动态数据源加载类DynamicDataSource添加到数据事务管理器中

上面配置还是单数据源事务生效,如果是多个数据源就不会生效。该句话的意思是,一个方法中,如果涉及到一个数据源,则事务生效,如果涉及到多个数据源,则事务不会在多个数据源中生效。
如果想要多个数据源事务一起生效,解决方案如下(注意是针对mybatis-plus框架)
找到DruidDBConfig配置类,将其中的SqlSessionFactoryBean调整为MybatisSqlSessionFactoryBean,如下





![[笔记]深度学习入门 基于Python的理论与实现(一)](https://img-blog.csdnimg.cn/direct/a2b26ac12c8f402fa94282dfd5b03d82.png)





![[笔记]深度学习入门 基于Python的理论与实现(二)](https://img-blog.csdnimg.cn/direct/3dd0953dbea34f1eade3d265406e9ad6.png)
