目录
一、论文题目
二、背景与动机
三、创新与卖点
四、技术细节
模型结构
简易代码
clip实现zero shot分类
五、为什么是CLIP?为什么是对比学习?
六、一些资料
在人工智能领域,文本和图像是两个极其重要的数据形式。传统上,机器学习模型往往专注于其中一种形式的处理—要么是文本(自然语言处理),要么是图像(计算机视觉)。OpenAI 推出的 CLIP(Contrastive Language–Image Pre-training)模型在这两个领域之间架起了一座桥梁,为图像理解和文本图像交互提供了新的视角。
一、论文题目
Learning Transferable Visual Models From Natural Language Supervision![]() https://arxiv.org/pdf/2103.00020.pdf
https://arxiv.org/pdf/2103.00020.pdf
二、背景与动机
传统的视觉模型的限制。传统的计算机视觉模型通常需要大量的标注数据来训练,这些数据的获取成本非常高。此外,模型的泛化能力受限于训练数据集,对于训练集之外的新类别或新场景,模型的表现常常会大打折扣。
自然语言的表达力。自然语言以其丰富的表达力赋予了人类沟通的无限可能。若机器能理解丰富的语言描述,将能更好地理解和处理视觉信息。这一直是人工智能领域的一个追求。
对于以上问题,OpenAI 提出了一个问题:是否可以开发一种模型,利用大量的文本描述来学习视觉概念,从而减少对标注数据的依赖,并提高模型对新场景的适应能力?
三、创新与卖点
预训练和零样本学习。CLIP 的主要创新点在于它采用了大规模的预训练,学习图像与自然语言的关联。它可以从描述中识别出视觉概念,而不需要直接的图像标注。这种方法让 CLIP 具备了零样本(zero-shot)学习的能力,即在没有直接学习特定类别的情况下,识别出这些类别的图像。
对比学习。CLIP 通过对比学习将图像和文本嵌入到相同的空间中。模型预测图像描述的匹配程度,从而学习将视觉内容和语言描述联系起来。这种方法在不同的数据集和任务上都表现出了卓越的性能。
大规模数据。CLIP 的训练涉及到了超过 4 亿个图像文本对,这些数据的多样性大大提高了模型的泛化能力。
四、技术细节
模型结构
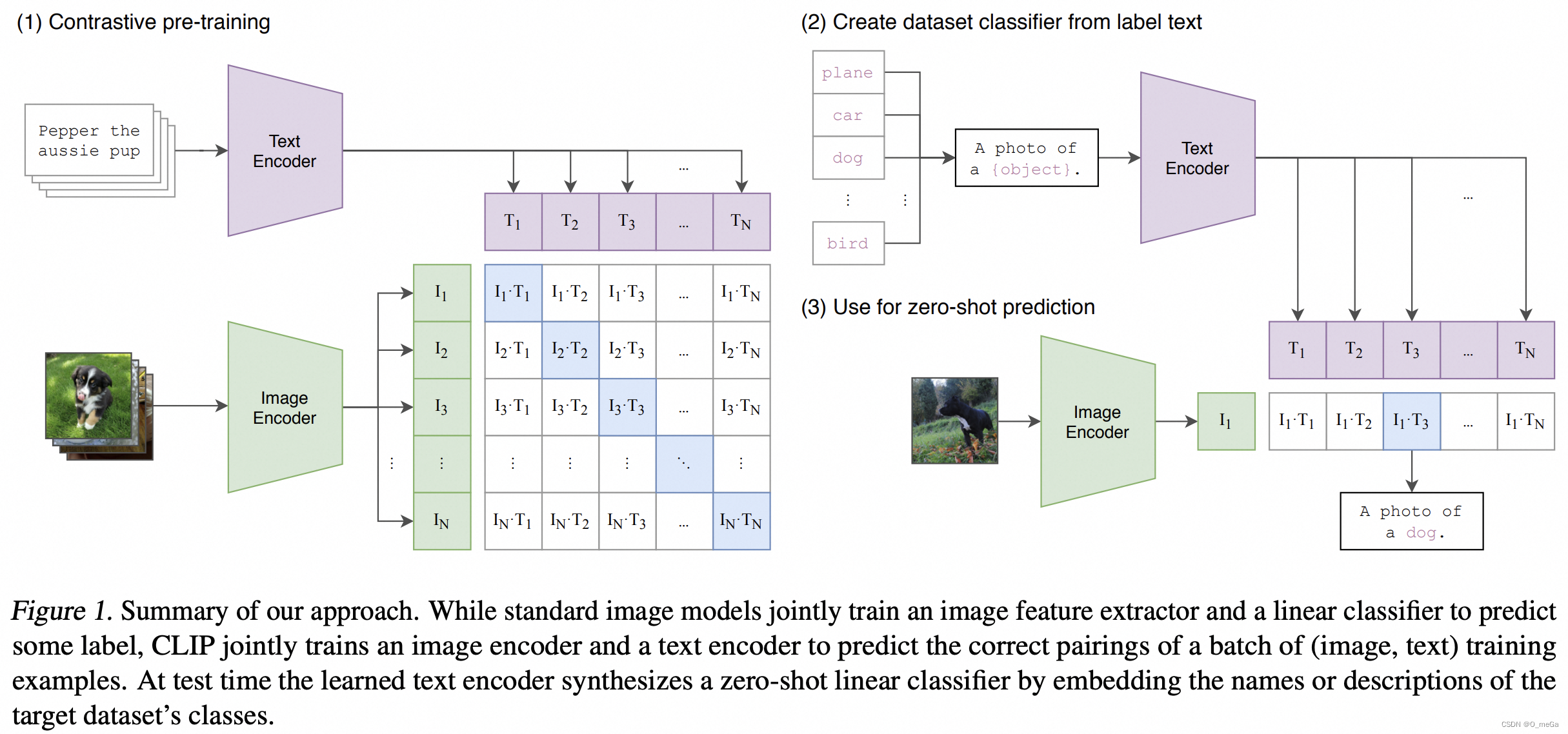
CLIP 包括两部分:视觉编码器和文本编码器。视觉编码器是基于卷积神经网络(CNN)的变体,如 ResNet 或 Vision Transformer(ViT)。文本编码器则是基于 Transformer 架构的。在训练过程中,CLIP 通过最大化图像与其对应描述的相似度来进行学习。同时,它最小化与不匹配描述的相似度。这一过程涉及到大量的负样本,为模型提供了区分力。
简易代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.models import resnet50
from transformers import BertTokenizer, BertModel
class SimpleCLIP(nn.Module):
def __init__(self):
super(SimpleCLIP, self).__init__()
# 图像分支 - 使用简化的 ResNet50 作为例子
self.visual_model = resnet50(pretrained=True)
# 文本分支 - 使用简化的 BERT 作为例子
self.text_model = BertModel.from_pretrained('bert-base-uncased')
def forward(self, images, text_tokens):
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = self.visual_model (I) #[n, d_i] # Extract visual features
T_f = self.text_model (T) #[n, d_t] # Extract text
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
return I_e, T_e
# 初始化模型
model = SimpleCLIP()
# 定义对比损失 - InfoNCE 损失的简化版本
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = optim.Adam(model.parameters(), lr=1e-5)
# 数据加载 - 伪代码,需替换为实际代码
image_loader = ...
text_loader = ...
# 训练循环
for epoch in range(num_epochs):
for images, texts in zip(image_loader, text_loader):
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
visual_features, text_features = model(images, texts)
# 计算损失函数
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(visual_features, text_features.T) * np.exp(t) # t为超参数
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
# Backward and optimize
loss.backward()
optimizer.step()
print("Training finished.")clip实现zero shot分类
首先请确保安装了必要的库:
pip install torch torchvision
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git简易实现
import torch
import clip
from PIL import Image
import urllib.request
import matplotlib.pyplot as plt
# 加载预训练的 CLIP 模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
# 准备输入数据
image_url = "https://raw.githubusercontent.com/openai/CLIP/main/CLIP.png"
image = Image.open(urllib.request.urlopen(image_url))
text = ["a diagram", "a dog", "a cat"]
# 使用 CLIP 预处理图像并将文本转换为张量
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = clip.tokenize(text).to(device)
# 通过模型前向传播
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# 计算图像和文本特征之间的余弦相似度
logits_per_image, logits_per_text = model(image_input, text_inputs)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
# 显示图像和预测
plt.imshow(image)
plt.title(f"Predicted label: {text[probs.argmax()]} with probability {probs.max() * 100:.2f}%")
plt.show()五、为什么是CLIP?为什么是对比学习?
一下引自神器CLIP:连接文本和图像,打造可迁移的视觉模型 - 知乎
在计算机视觉领域,最常采用的迁移学习方式就是先在一个较大规模的数据集如ImageNet上预训练,然后在具体的下游任务上再进行微调。这里的预训练是基于有监督训练的,需要大量的数据标注,因此成本较高。近年来,出现了一些基于自监督的方法,这包括基于对比学习的方法如MoCo和SimCLR,和基于图像掩码的方法如MAE和BeiT,自监督方法的好处是不再需要标注。但是无论是有监督还是自监督方法,它们在迁移到下游任务时,还是需要进行有监督微调,而无法实现zero-shot。对于有监督模型,由于它们在预训练数据集上采用固定类别数的分类器,所以在新的数据集上需要定义新的分类器来重新训练。对于自监督模型,代理任务往往是辅助来进行表征学习,在迁移到其它数据集时也需要加上新的分类器来进行有监督训练。但是NLP领域,基于自回归或者语言掩码的预训练方法已经取得相对成熟,而且预训练模型很容易直接zero-shot迁移到下游任务,比如OpenAI的GPT-3。这种差异一方面是由于文本和图像属于两个完全不同的模态,另外一个原因就是NLP模型可以采用从互联网上收集的大量文本。那么问题来了:能不能基于互联网上的大量文本来预训练视觉模型?
那么其实之前已经有一些工作研究用文本来作为监督信号来训练视觉模型,比如16年的工作Learning Visual Features from Large Weakly Supervised Data将这转化成一个多标签分类任务来预测图像对应的文本的bag of words;17年的工作Learning Visual N-Grams from Web Data进一步扩展了这个方法来预测n-grams。最近的一些工作采用新的模型架构和预训练方法来从文本学习视觉特征,比如VirTex基于transformer的语言模型,ICMLM基于语言掩码的方法,ConVIRT基于对比学习的方法。整体来看,这方面的工作不是太多,这主要是因为这些方法难以实现较高的性能,比如17年的那篇工作只在ImageNet上实现了11.5%的zero-shot性能,这远远低于ImageNet上的SOTA。另外,还有另外的是一个方向,就是基于文本弱监督来提升性能,比如谷歌的BiT和ViT基于JFT-300M数据集来预训练模型在ImageNet上取得SOTA,JFT-300M数据集是谷歌从互联网上收集的,通过一些自动化的手段来将web text来转化成18291个类别,但是存在一定的噪音。虽然谷歌基于JFT-300M数据集取得了较好的结果,但是这些模型依然采用固定类别的softmax分类器进行预训练,这大大限制了它的迁移能力和扩展性。
作者认为谷歌的弱监督方法和之前的方法的一个重要的区别在于规模,或者说算力和数据的规模不同。JFT-300M数据量达到了上亿级别,而且谷歌用了强大的算力来进行预训练。而VirTex,ICMLM和ConVIRT只在10万级别的数据上训练了几天。为了弥补数据上的差异,OpenAI从网上收集了4亿的数据来实验。但是新的问题来了:采用什么样的方法来训练。OpenAI首先尝试了VirTex模型,即联合训练一个CNN和文本transformer来预测图像的文本(image caption),但是发现这种方法的训练效率(用ImageNet数据集上的zero-shot性能来评估)还不如直接预测bag of words,如下图所示,两者的训练效率能相差3倍。如果进一步采用ConVIRT,即基于对比学习的方法,训练效率可以进一步提升4倍。之所出现这个差异,这不难理解,训练数据所包含的文本-图像对是从互联网收集来的,它们存在一定的噪音,就是说文本和图像可能并不完全匹配,这个时候适当的降低训练目标,反而能取得更好的收敛。而从任务难度来看:Transformer Language Model > Bag of Words Prediction > Bag of Words Contrastive (CLIP)。由于训练数据量和模型计算量较大,训练效率成为一个至关重要的因素。这就是作者最终选择对比学习的方法来训练的原因。
六、一些资料
神器CLIP:连接文本和图像,打造可迁移的视觉模型 - 知乎码字不易,勿忘点赞!2021年见证了vision transformer的大爆发,随着谷歌提出ViT之后,一大批的vision transformer的工作席卷计算机视觉任务。除了vision transformer,另外一个对计算机视觉影响比较大的工作就是O…![]() https://zhuanlan.zhihu.com/p/493489688GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an imageCLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image - GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image
https://zhuanlan.zhihu.com/p/493489688GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an imageCLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image - GitHub - openai/CLIP: CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image![]() https://github.com/openai/CLIPGitHub - OFA-Sys/Chinese-CLIP: Chinese version of CLIP which achieves Chinese cross-modal retrieval and representation generation.Chinese version of CLIP which achieves Chinese cross-modal retrieval and representation generation. - GitHub - OFA-Sys/Chinese-CLIP: Chinese version of CLIP which achieves Chinese cross-modal retrieval and representation generation.
https://github.com/openai/CLIPGitHub - OFA-Sys/Chinese-CLIP: Chinese version of CLIP which achieves Chinese cross-modal retrieval and representation generation.Chinese version of CLIP which achieves Chinese cross-modal retrieval and representation generation. - GitHub - OFA-Sys/Chinese-CLIP: Chinese version of CLIP which achieves Chinese cross-modal retrieval and representation generation.![]() https://github.com/OFA-Sys/Chinese-CLIP
https://github.com/OFA-Sys/Chinese-CLIP



![elasticsearch[一]-索引库操作(轻松创建)、文档增删改查、批量写入(效率倍增)](https://img-blog.csdnimg.cn/img_convert/1b338716cb0b190f857ea6d78c61b6d4.png)