执行器(InitPlan)
- 概述
- InitPlan 函数
- 代码段解释
- ExecInitNode 函数
- 总结
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 postgresql-10.1 的开源代码和《OpenGauss数据库源码解析》和《PostgresSQL数据库内核分析》一书
概述
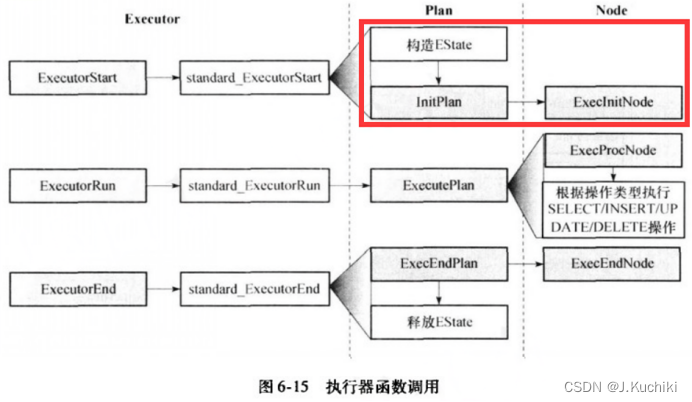
在【OpenGauss源码学习 —— 执行器(execMain)】一文中,我们学习了执行器中执行查询的核心函数和逻辑。在本文中,我们将深入研究 InitPlan 的内容。InitPlan 是数据库查询执行过程中的关键组成部分,它用于在查询计划的执行过程中初始化子查询或表达式的结果,以确保正确的查询执行顺序和结果。通过本文的学习,我们将深入了解 InitPlan 的原理和实现细节,从而更好地理解数据库查询的执行机制。具体学习的模块如下图红色框体所示:
InitPlan 函数
InitPlan 函数是数据库查询执行过程中的初始化函数,其作用和功能主要集中在准备和设置查询计划(Query Plan)的执行环境。在关系型数据库管理系统(如 PostgreSQL)中,这是执行数据库查询的关键步骤。函数的主要职责包括:
- 权限验证:检查对于涉及的表是否有足够的访问权限,确保查询的安全性。
- 设置执行状态:初始化查询的执行状态(
EState),包括设置查询涉及的表(range table)和计划语句(PlannedStmt)。- 处理结果关系:对数据库操作影响的表(如插入、更新、删除操作的目标表)进行初始化和锁定。这包括处理分区表的情况,确保正确处理表的分区结构。
- 锁定更新/共享关系:对于涉及
FOR UPDATE或FOR SHARE的表,提前进行锁定,以避免在执行计划树初始化过程中的锁升级。- 初始化元组表:创建和初始化元组表,这是用于在查询执行过程中临时存储和处理数据的结构。
- 子计划的初始化:对查询计划中的所有子计划(子查询)进行初始化,设置它们的私有状态。这对于处理复杂查询中的嵌套子查询非常关键。
- 初始化查询计划树的节点:对查询计划树中的每个节点进行初始化,这是查询执行的核心部分,涉及打开文件、分配资源等准备工作。
- 设置垃圾过滤器:对于 SELECT 查询,如果目标列表中包含“垃圾”属性(即不需要的数据),则初始化垃圾过滤器,以清理这些不需要的数据。
具体操作如下:
- 函数首先接收一个 QueryDesc 类型的参数,这包含了操作类型、计划的语句、执行状态等信息。
- 根据计划语句和操作类型,函数进行不同的初始化操作,这可能包括打开文件、分配内存、锁定表等。
- 函数处理可能存在的子计划,并初始化它们。这是重要的,因为子计划可能会影响主查询的执行。
- 最后,函数准备好执行计划树中的所有节点,以便执行实际的数据库查询。
总的来说,InitPlan 函数是数据库查询执行的重要部分,负责准备和初始化所有必要的结构和状态,以便数据库管理系统可以有效地执行一个查询计划。函数源码如下所示:(路径:src\backend\executor\execMain.c)
/* ----------------------------------------------------------------
* InitPlan
*
* 初始化查询计划: 打开文件、分配存储空间并启动规则管理器
* ----------------------------------------------------------------
*/
static void
InitPlan(QueryDesc *queryDesc, int eflags)
{
CmdType operation = queryDesc->operation; // 获取操作类型,例如 SELECT、UPDATE 等
PlannedStmt *plannedstmt = queryDesc->plannedstmt; // 获取已计划的语句
Plan *plan = plannedstmt->planTree; // 获取计划的查询树
List *rangeTable = plannedstmt->rtable; // 获取涉及的范围表(关系表)列表
EState *estate = queryDesc->estate; // 获取执行状态
PlanState *planstate; // 声明用于后续初始化的 PlanState 指针
TupleDesc tupType; // 声明用于描述元组的结构
ListCell *l; // 声明用于列表迭代的 ListCell 指针
int i; // 声明用于迭代的整型变量
/* 执行权限检查 */
ExecCheckRTPerms(rangeTable, true); // 检查对涉及的表的访问权限
/* 初始化节点的执行状态 */
estate->es_range_table = rangeTable; // 设置执行状态中的范围表
estate->es_plannedstmt = plannedstmt; // 设置执行状态中的已计划语句
/* 初始化结果关系,打开和锁定结果关联 */
if (plannedstmt->resultRelations)
{
List *resultRelations = plannedstmt->resultRelations; // 获取结果关系列表
int numResultRelations = list_length(resultRelations); // 计算结果关系的数量
ResultRelInfo *resultRelInfos; // 声明结果关系信息数组
ResultRelInfo *resultRelInfo; // 声明单个结果关系信息
/* 为结果关系信息数组分配内存 */
resultRelInfos = (ResultRelInfo *)
palloc(numResultRelations * sizeof(ResultRelInfo));
resultRelInfo = resultRelInfos;
foreach(l, resultRelations)
{
Index resultRelationIndex = lfirst_int(l); // 获取结果关系索引
Oid resultRelationOid; // 声明结果关系的 OID
Relation resultRelation; // 声明结果关系
/* 获取结果关系的 OID,并打开结果关系 */
resultRelationOid = getrelid(resultRelationIndex, rangeTable);
resultRelation = heap_open(resultRelationOid, RowExclusiveLock);
/* 初始化单个结果关系信息 */
InitResultRelInfo(resultRelInfo,
resultRelation,
resultRelationIndex,
NULL,
estate->es_instrument);
resultRelInfo++;
}
estate->es_result_relations = resultRelInfos; // 设置执行状态中的结果关系信息数组
estate->es_num_result_relations = numResultRelations; // 设置执行状态中的结果关系数量
estate->es_result_relation_info = NULL; // 初始化结果关系信息为 NULL
/* 对分区结果关系进行处理 */
estate->es_root_result_relations = NULL; // 初始化根结果关系为 NULL
estate->es_num_root_result_relations = 0; // 初始化根结果关系数量为 0
if (plannedstmt->nonleafResultRelations)
{
int num_roots = list_length(plannedstmt->rootResultRelations); // 获取根结果关系的数量
/* 为分区表的根建立 ResultRelInfos */
resultRelInfos = (ResultRelInfo *)
palloc(num_roots * sizeof(ResultRelInfo)); // 分配内存
resultRelInfo = resultRelInfos;
foreach(l, plannedstmt->rootResultRelations)
{
Index resultRelIndex = lfirst_int(l); // 获取结果关系索引
Oid resultRelOid; // 声明结果关系的 OID
Relation resultRelDesc; // 声明结果关系描述
/* 获取结果关系的 OID 并打开结果关系描述 */
resultRelOid = getrelid(resultRelIndex, rangeTable);
resultRelDesc = heap_open(resultRelOid, RowExclusiveLock);
/* 初始化根结果关系信息 */
InitResultRelInfo(resultRelInfo,
resultRelDesc,
lfirst_int(l),
NULL,
estate->es_instrument);
resultRelInfo++;
}
estate->es_root_result_relations = resultRelInfos; // 设置执行状态中的根结果关系信息
estate->es_num_root_result_relations = num_roots; // 设置执行状态中的根结果关系数量
/* 锁定非叶结果关系 */
foreach(l, plannedstmt->nonleafResultRelations)
{
Index resultRelIndex = lfirst_int(l);
/* 对不在根结果关系列表中的关系加锁 */
if (!list_member_int(plannedstmt->rootResultRelations,
resultRelIndex))
LockRelationOid(getrelid(resultRelIndex, rangeTable),
RowExclusiveLock);
}
}
}
else
{
/* 如果没有结果关系,则相应地设置状态 */
estate->es_result_relations = NULL;
estate->es_num_result_relations = 0;
estate->es_result_relation_info = NULL;
estate->es_root_result_relations = NULL;
estate->es_num_root_result_relations = 0;
}
/*
* 类似地,在初始化计划树之前,我们需要锁定被选为 FOR [KEY] UPDATE/SHARE 的关系,
* 否则可能会有锁升级的风险。同时,构建 ExecRowMark 列表。
* 这里忽略了分区的子表(因为 isParent=true),它们将被第一个引用它们的 Append 或 MergeAppend 节点锁定。
* (注意,对应于分区子表的 RowMarks 与其它的在同一个列表中,即 plannedstmt->rowMarks。)
*/
estate->es_rowMarks = NIL; // 初始化执行状态中的行标记列表为 NIL
foreach(l, plannedstmt->rowMarks) // 遍历行标记
{
PlanRowMark *rc = (PlanRowMark *) lfirst(l); // 获取当前行标记
Oid relid; // 声明关系的 OID
Relation relation; // 声明关系
ExecRowMark *erm; // 声明执行行标记
/* 忽略父级行标记,因为它们在运行时不相关 */
if (rc->isParent)
continue;
/* 获取关系的 OID(如果是子查询则为 InvalidOid) */
relid = getrelid(rc->rti, rangeTable);
/* 根据标记类型锁定关系 */
switch (rc->markType)
{
case ROW_MARK_EXCLUSIVE:
case ROW_MARK_NOKEYEXCLUSIVE:
case ROW_MARK_SHARE:
case ROW_MARK_KEYSHARE:
relation = heap_open(relid, RowShareLock); // 使用 RowShareLock 打开关系
break;
case ROW_MARK_REFERENCE:
relation = heap_open(relid, AccessShareLock); // 使用 AccessShareLock 打开关系
break;
case ROW_MARK_COPY:
/* 不需要访问物理表 */
relation = NULL;
break;
default:
elog(ERROR, "unrecognized markType: %d", rc->markType); // 无法识别的 markType
relation = NULL; /* 保持编译器安静 */
break;
}
/* 检查关系是否是合法的标记目标 */
if (relation)
CheckValidRowMarkRel(relation, rc->markType);
erm = (ExecRowMark *) palloc(sizeof(ExecRowMark)); // 分配执行行标记内存
erm->relation = relation; // 设置关系
erm->relid = relid; // 设置关系 ID
erm->rti = rc->rti; // 设置关系表索引
erm->prti = rc->prti; // 设置父关系表索引
erm->rowmarkId = rc->rowmarkId; // 设置行标记 ID
erm->markType = rc->markType; // 设置标记类型
erm->strength = rc->strength; // 设置强度
erm->waitPolicy = rc->waitPolicy; // 设置等待策略
erm->ermActive = false; // 设置为非激活状态
ItemPointerSetInvalid(&(erm->curCtid)); // 设置当前 TID 为无效
erm->ermExtra = NULL; // 设置额外信息为 NULL
estate->es_rowMarks = lappend(estate->es_rowMarks, erm); // 将执行行标记添加到列表中
}
/* 初始化执行器的元组表为空 */
estate->es_tupleTable = NIL; // 设置元组表为 NIL
estate->es_trig_tuple_slot = NULL; // 设置触发器元组槽为 NULL
estate->es_trig_oldtup_slot = NULL; // 设置旧触发器元组槽为 NULL
estate->es_trig_newtup_slot = NULL
/* 标记 EvalPlanQual 为非活动状态 */
estate->es_epqTuple = NULL; // 设置 EPQ 元组为 NULL
estate->es_epqTupleSet = NULL; // 设置 EPQ 元组集为 NULL
estate->es_epqScanDone = NULL; // 设置 EPQ 扫描完成标志为 NULL
/*
* 为每个子计划初始化私有状态信息。在执行主查询树的 ExecInitNode 之前必须做这个,
* 因为 ExecInitSubPlan 期望能找到这些条目。
*/
Assert(estate->es_subplanstates == NIL); // 断言确保子计划状态列表为空
i = 1; /* 子计划索引从 1 开始 */
foreach(l, plannedstmt->subplans) // 遍历所有子计划
{
Plan *subplan = (Plan *) lfirst(l); // 获取当前子计划
PlanState *subplanstate; // 声明子计划状态
int sp_eflags; // 声明子计划的执行标志
/*
* 子计划不需要执行向后扫描或标记/恢复。如果是无参数子计划(非 initplan),
* 我们建议它准备好高效处理 REWIND;否则就没必要了。
*/
sp_eflags = eflags
& (EXEC_FLAG_EXPLAIN_ONLY | EXEC_FLAG_WITH_NO_DATA); // 设置子计划执行标志
if (bms_is_member(i, plannedstmt->rewindPlanIDs))
sp_eflags |= EXEC_FLAG_REWIND; // 如果子计划需要 REWIND,添加标志
subplanstate = ExecInitNode(subplan, estate, sp_eflags); // 初始化子计划状态
estate->es_subplanstates = lappend(estate->es_subplanstates,
subplanstate); // 将子计划状态添加到列表
i++; // 子计划索引递增
}
/*
* 为查询树中的所有节点初始化私有状态信息。这将打开文件、分配存储空间,
* 并准备开始处理元组。
*/
planstate = ExecInitNode(plan, estate, eflags); // 初始化主查询树的节点
/*
* 获取描述返回元组类型的元组描述符。
*/
tupType = ExecGetResultType(planstate); // 获取结果类型的元组描述符
/*
* 如有必要,初始化垃圾过滤器。如果顶层目标列表中有任何垃圾属性,
* SELECT 查询就需要一个过滤器。
*/
if (operation == CMD_SELECT)
{
bool junk_filter_needed = false; // 声明是否需要垃圾过滤器的标志
ListCell *tlist; // 声明目标列表的迭代器
foreach(tlist, plan->targetlist) // 遍历目标列表
{
TargetEntry *tle = (TargetEntry *) lfirst(tlist); // 获取当前目标项
if (tle->resjunk) // 如果是垃圾属性
{
junk_filter_needed = true; // 标记需要垃圾过滤器
break;
}
}
if (junk_filter_needed) // 如果需要垃圾过滤器
{
JunkFilter *j; // 声明垃圾过滤器
j = ExecInitJunkFilter(planstate->plan->targetlist,
tupType->tdhasoid,
ExecInitExtraTupleSlot(estate)); // 初始化垃圾过滤器
estate->es_junkFilter = j; // 设置执行状态中的垃圾过滤器
/* 期望返回清理后的元组类型 */
tupType = j->jf_cleanTupType; // 设置清理后的元组类型
}
}
queryDesc->tupDesc = tupType; // 设置查询描述的元组描述符
queryDesc->planstate = planstate; // 设置查询描述的计划状态
}
代码段解释
PlanRowMark *rc = (PlanRowMark *) lfirst(l); // 获取当前行标记
这行代码的作用是从一个链表结构中提取出当前遍历到的元素,并将其转换为 PlanRowMark 类型的指针。这里,PlanRowMark 是一个结构体,用于存储与特定数据库表或查询中的行相关的标记信息。这种标记通常用于数据库查询计划中,以指示对特定行的特定操作或限制。
举个例子说明
假设你正在执行一个数据库查询,该查询包括对多个表的操作,并且一些操作需要特别标记(例如,更新或删除某些特定行时需要加锁)。在这种情况下,PlanRowMark 结构体将用于存储这些操作的相关信息。
例如,你有一个查询计划,它包含对两个表的操作:表 A 和表 B。在这个计划中,你想对表 A 中的某些行加上“FOR UPDATE”锁,而对表 B 中的某些行加上“FOR SHARE”锁。这样的锁定操作可以防止其他事务在当前事务完成之前修改或删除这些行。
在执行这个计划的初始化过程中,会创建一个包含 PlanRowMark 元素的列表,每个元素代表一个需要特殊处理的表及其行。当遍历到这个列表中的一个元素时,这行代码就会从列表中提取出一个 PlanRowMark 结构体,其中包含了如何处理与表 A 或表 B 相关行的信息。例如,对于表 A 的行,这个结构体可能会指示这些行应该被加上“FOR UPDATE”锁。
ExecInitNode 函数
ExecInitNode 函数是数据库查询执行过程中的一个关键函数,用于递归初始化查询计划树中的所有节点。它根据不同类型的节点(如扫描节点、连接节点、聚合节点等)执行相应的初始化操作。
ExecInitNode 函数对查询计划中的每个节点进行递归初始化。它根据节点类型(如结果节点、扫描节点、连接节点等)调用相应的初始化函数。这些函数为每种类型的节点设置特定的执行状态和行为。
- 节点初始化:对于每种节点类型(如结果节点、聚合节点、扫描节点等),函数通过调用特定的初始化函数(如
ExecInitResult、ExecInitSeqScan)来准备节点的执行。这包括为节点设置运行时所需的资源、数据结构和状态。- 检查栈深度:为了避免栈溢出,函数在开始节点的初始化之前检查栈深度。
- 初始化子计划:对于包含子计划的节点(如子查询),函数初始化这些子计划,并将它们的状态连接到主节点的状态上。
- 设置性能监控:如果启用了性能监控,函数将为节点分配监控工具。
通过这种方式,ExecInitNode 确保查询计划中的每个节点都被正确初始化,并且具备执行查询所需的全部信息和资源。这个过程是查询执行的基础,它确保了当查询被执行时,每个节点都能按照预期的逻辑和顺序工作,从而有效地完成整个查询任务。函数源码如下所示:(路径:src\backend\executor\execProcnode.c)
/* ------------------------------------------------------------------------
* ExecInitNode
*
* 递归初始化查询计划树的根节点及其子节点。
*
* 输入参数:
* 'node' 是由查询规划器产生的计划树中的当前节点
* 'estate' 是计划树的共享执行状态
* 'eflags' 是在 executor.h 中描述的标志位的位或运算结果
*
* 返回一个与给定计划节点对应的 PlanState 节点。
* ------------------------------------------------------------------------
*/
PlanState *
ExecInitNode(Plan *node, EState *estate, int eflags)
{
PlanState *result; // 声明返回的 PlanState 结构体
List *subps; // 子计划列表
ListCell *l; // 用于遍历列表的临时变量
/* 若节点为 NULL,则到达叶子节点的末端,无需进一步处理 */
if (node == NULL)
return NULL;
/* 确保有足够的栈空间可用。需要在这里以及 ExecProcNode()(通过 ExecProcNodeFirst())中检查,以确保在初始化节点树时不会超过栈深度。 */
check_stack_depth();
/* 根据节点类型选择相应的初始化函数 */
switch (nodeTag(node))
{
/* 控制节点 */
case T_Result:
result = (PlanState *) ExecInitResult((Result *) node, estate, eflags);
break;
/* ...其他节点类型的处理... */
/* 扫描节点 */
case T_SeqScan:
result = (PlanState *) ExecInitSeqScan((SeqScan *) node, estate, eflags);
break;
/* ...其他节点类型的处理... */
/* 连接节点 */
case T_NestLoop:
result = (PlanState *) ExecInitNestLoop((NestLoop *) node, estate, eflags);
break;
/* ...其他节点类型的处理... */
/* 材料化节点 */
case T_Material:
result = (PlanState *) ExecInitMaterial((Material *) node, estate, eflags);
break;
/* ...其他节点类型的处理... */
/* 默认情况下,报告无法识别的节点类型错误 */
default:
elog(ERROR, "unrecognized node type: %d", (int) nodeTag(node));
result = NULL; /* 避免编译器警告 */
break;
}
/* 添加一个包装器,用于在第一次执行时检查栈深度 */
result->ExecProcNodeReal = result->ExecProcNode;
result->ExecProcNode = ExecProcNodeFirst;
/* 初始化节点中存在的任何初始化计划(initPlans)。规划器将它们放在一个单独的列表中。 */
subps = NIL;
foreach(l, node->initPlan)
{
SubPlan *subplan = (SubPlan *) lfirst(l);
SubPlanState *sstate;
Assert(IsA(subplan, SubPlan));
sstate = ExecInitSubPlan(subplan, result);
subps = lappend(subps, sstate);
}
result->initPlan = subps;
/* 如果请求,为该节点设置监控工具 */
if (estate->es_instrument)
result->instrument = InstrAlloc(1, estate->es_instrument);
return result;
}
总结
ExecutorStart 在查询执行阶段之前调用,作为整个执行过程的入口点。它负责触发 InitPlan,然后继续进行查询执行的后续步骤。在 ExecutorStart 中,首先调用 InitPlan 来完成查询计划的初始化工作,然后设置好执行环境,准备好所有必要的数据结构和状态。这包括分配内存、准备执行环境等。
InitPlan 是数据库查询执行过程中的一个重要函数,主要负责初始化查询计划(Query Plan)。在执行数据库查询之前,InitPlan 函数设置和准备了所有必要的执行状态,包括但不限于权限检查、结果关系的初始化和锁定、子计划的初始化等。此外,它还负责为各种节点类型(如扫描节点、连接节点等)设置相应的执行状态和行为。简而言之,InitPlan 确保了查询计划的各个组成部分都准备就绪,可以进行高效的查询执行。