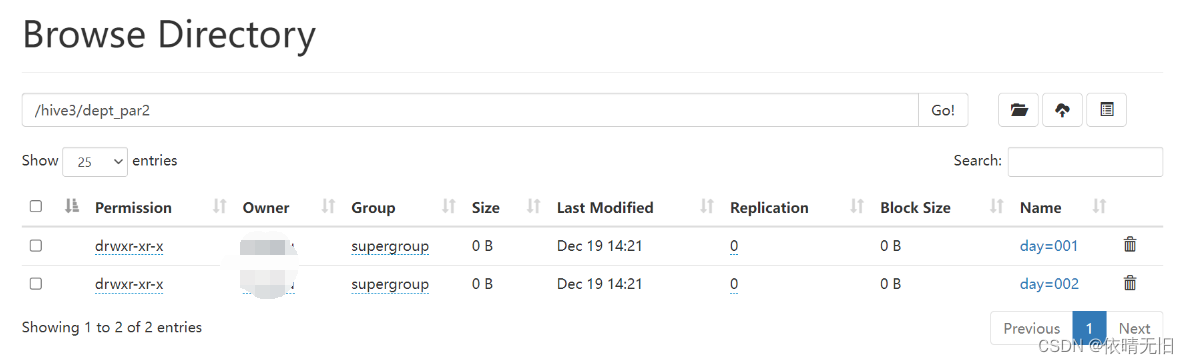
原理
离散余弦变换(DCT)和量化是图像压缩中的两个关键步骤,尤其是在JPEG压缩标准中。
离散余弦变换(DCT):DCT的目的是将图像从空间域(即像素表示)转换到频率域。这种转换后,图像的能量会集中在少数几个系数中,特别是低频系数中。
图像的大部分视觉信息都包含在低频成分中,而高频成分通常与图像细节(如边缘、纹理)相关。
**量化:**量化是压缩过程中降低DCT系数精度的步骤。它通过使用一个预定义的量化矩阵来完成,该矩阵决定了每个DCT系数被缩减的程度。
量化的过程实际上是一种有损压缩。较大的量化值导致更多的数据丢失,但也提供了更高的压缩比。量化矩阵通常设计为对高频成分进行更激烈的量化(因为人眼对高频细节的敏感度较低),而保留更多的低频成分。
图像质量与量化级别的关系:
低量化级别:使用较低的量化级别(或者说量化矩阵的缩放参数小)会保留更多的DCT系数,从而保留更多的图像细节和质量,但这会导致较低的压缩比。
高量化级别:较高的量化级别(量化矩阵的缩放参数大)会导致更多的DCT系数被减少或归零,从而提高压缩比,但同时会导致图像质量下降,表现为模糊和块状伪影(尤其在高频细节区域)。
视觉感知和压缩效率:
人眼对不同频率的细节有不同的敏感度。通过利用这一点,量化可以被设计成在保持相对较好的视觉质量的同时,实现有效的数据压缩。
在实际应用中,量化矩阵和量化级别的选择取决于目标压缩比和可接受的图像质量损失。
总结:DCT和量化是实现图像压缩的关键步骤。DCT帮助集中图像数据的能量,而量化则减少数据的精度以减小文件大小。量化级别的选择对压缩效率和图像质量有直接影响。较低的量化级别保留更多的细节但压缩率低,而较高的量化级别虽然提高压缩率,但会导致显著的图像质量下降。正确的平衡取决于特定应用的需求和对图像质量的容忍度。
python实现

提示
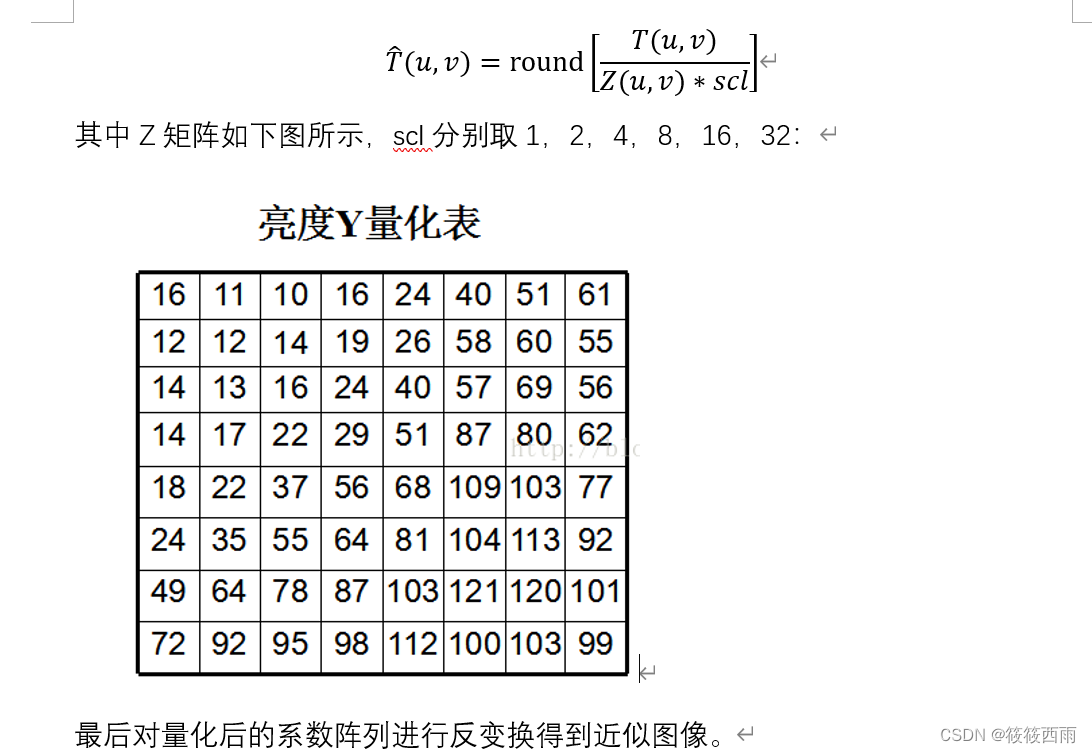
结果显示了用不同比例因子去乘标准化阵列后得到的DCT编解码结果。先将原图分割为大小为8×8的子图像,并对每个子图像进行DCT变换,之后对系数阵列进行如下运算来对其量化:
python代码
import cv2
import numpy as np
import matplotlib.pyplot as plt
img=cv2.imread("lena_gray_512.tif",0)
img=img.astype(np.float)
rows,cols=img.shape
img_list = []
img_name_list = []
Z = np.array([[16, 11, 10, 16, 24, 40, 51, 61],
[12, 12, 14, 19, 26, 58, 60, 55],
[14, 13, 16, 24, 40, 57, 69, 56],
[14, 17, 22, 29, 51, 87, 80, 62],
[18, 22, 37, 56, 68, 109, 103, 77],
[24, 35, 55, 64, 81, 104, 113, 92],
[49, 64, 78, 87, 103, 121, 120, 101],
[72, 92, 95, 98, 112, 100, 103, 99]])
scl_par=[1,2,4,8,16,32]
for scl in scl_par:
dct_inv_img = np.zeros(img.shape)
for i in range(0, rows, 8):
for j in range(0, cols, 8):
dct = cv2.dct(img[i:i+8, j:j+8])
dct = np.round(dct / (Z * scl))
dct_inv_img[i:i+8, j:j+8] = cv2.idct(dct)
img_list.append(dct_inv_img)
img_name_list.append('scl=' + str(scl))
_, axs = plt.subplots(2, 3)
for i in range(2):
for j in range(3):
axs[i, j].imshow(img_list[i*3+j], cmap='gray')
axs[i, j].set_title(img_name_list[i*3+j])
axs[i, j].axis('off')
plt.show()
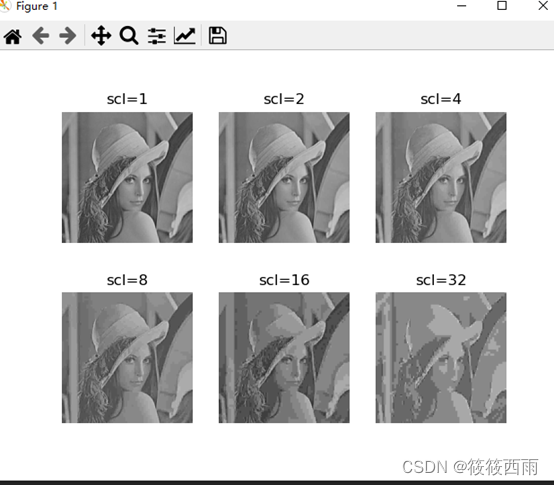
结果展示
总结
在JPEG压缩编码原理介绍中就知道整个JPEG压缩原理就是通过DCT变换去空间冗余来达到图片压缩的。经过DCT变换之后DCT系数只保留的左上角的数据(低频分量数据),右下角部分均变成0.因此,想要进一步压缩就可以从量化表下手。量化表的量化系数越大,得到的量化后的DCT系数就越小,高频信息消失的更多,图片容量就越小。




![[GXYCTF2019]Ping Ping Ping](https://img-blog.csdnimg.cn/img_convert/284afcfc6b9c9e40b1745d677c7d75f6.png)