目录
一、seq ---- 输出序列化参数
1、seq 数字 按照顺序打印
2、-s 使用指定字符串分割数字
3、计算1-20,并求和
4、-w 在每一列数字前加零 默认补全
二、tr、对数字进行处理
1、替换
2、删除
3、压缩
4、补集
三、cut 截取
四、sort 排序
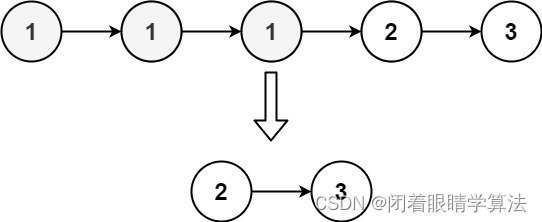
五、uniq 压缩连续的字符
小拓展
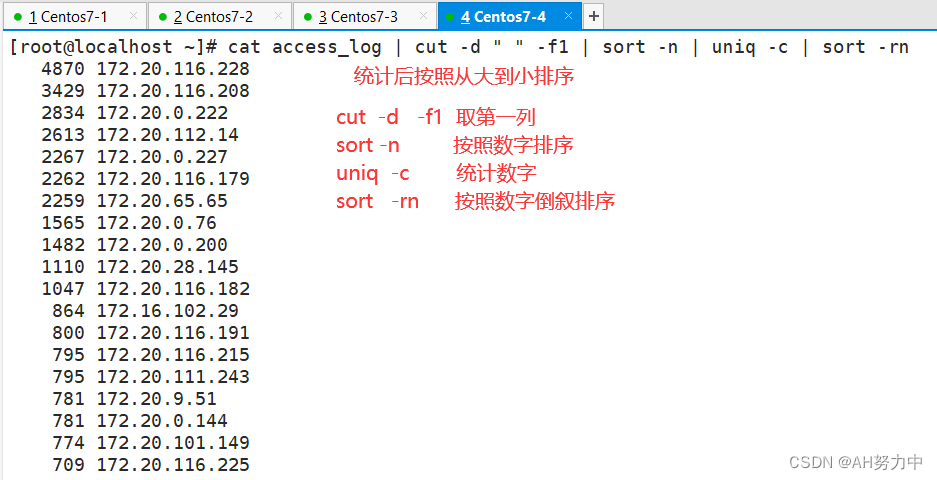
1、提取访问量最高的地址
一、seq ---- 输出序列化参数
1、seq 数字 按照顺序打印
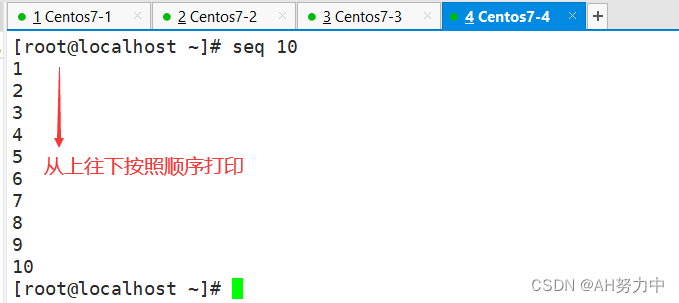
按照奇数打印1-10

按照偶数打印

2、-s 使用指定字符串分割数字
中间可以使用#或是空格隔开来显示

3、计算1-20,并求和

分别求奇数和偶数和

4、-w 在每一列数字前加零 默认补全

这儿只截取了几个数字
二、tr、对数字进行处理
tr 命令用于字符转换、替换和删除,主要用于删除文件中的控制符或进行字符串转换等。
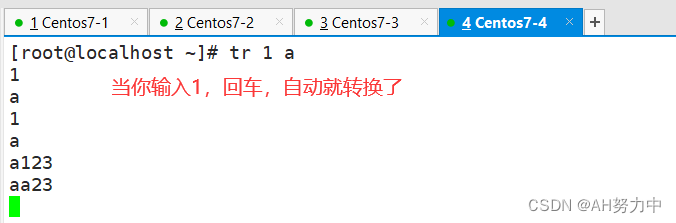
1、替换
格式: tr 输入当前字符 转换成需要的字符
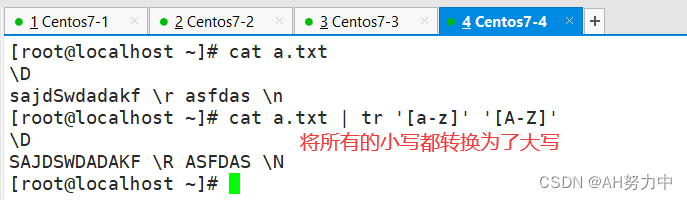
将所有的小写转换成大写
2、删除
格式:
tr -d

3、压缩
tr -s 输入字符


4、补集
用字符串中的字符集的补集替换此字符串
格式:
tr -c
例如:
随机密码

三、cut 截取
cut 选项 文件
- -d:分隔符,按照指定分隔符分割列。与 -f 一起使用
- -f:依据 -d 的分隔字符将一段信息分割成为数段,用 -f 取出第几段的意思(列号,提取第几列)
- -c:以字符 (characters) 的单位取出固定字符区间
- -b:以字节为单位进行分割

小实验
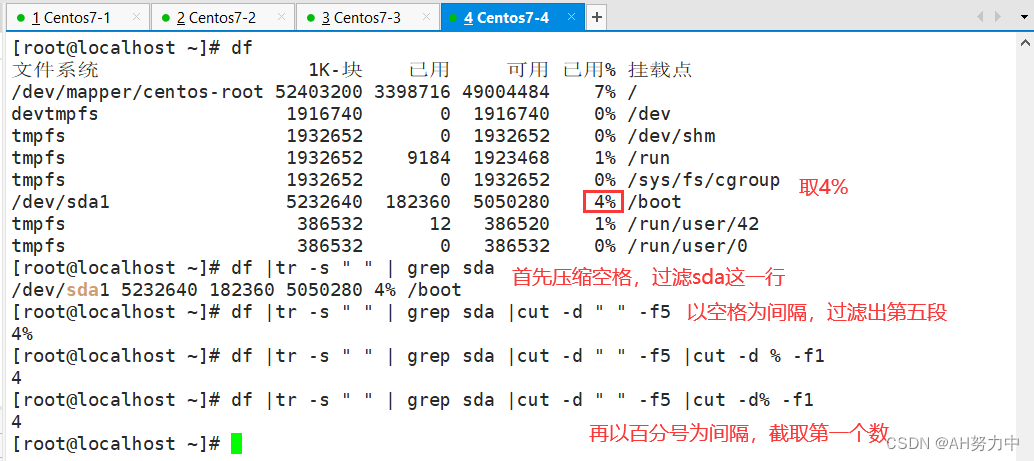
四、sort 排序
- --r: 降序排列,默认是升序
- -n: 以数字排序,默认按字符排序
- -u: 去除重复行
- -o: 将排序结果输出到文件中,类似重定向符号
- -t: 分隔符
- -k: 第N列
- -b: 忽略前导空格
- -R: 随机排序,每次运行的结果均不同
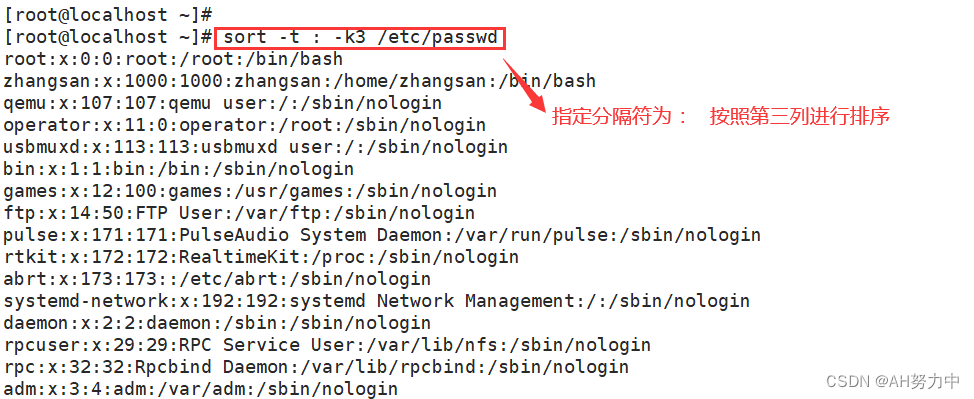
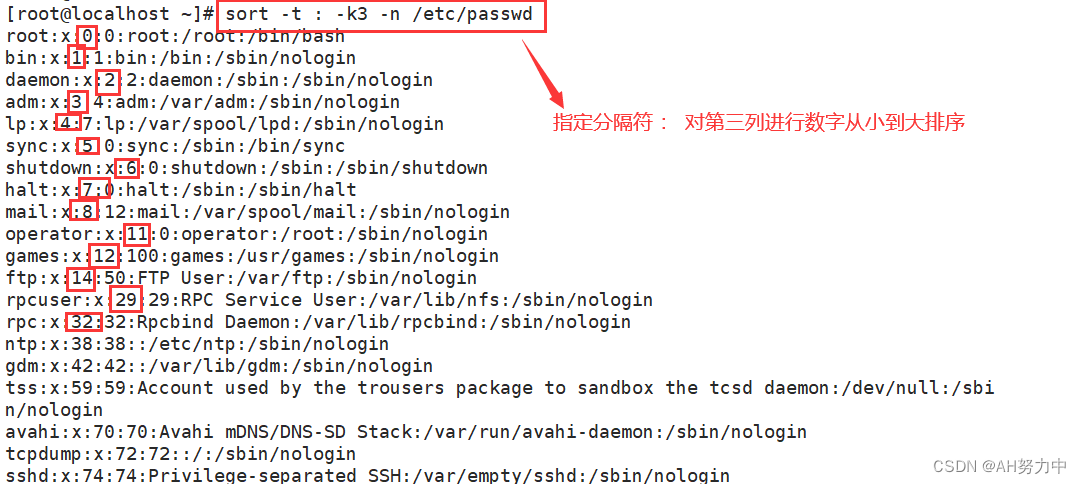
五、uniq 压缩连续的字符
选项:
- -c, --count 打印每行出现的次数
- -d, --repeated 只打印重复出现的行
- -D 打印所有重复行
- --all-repeated[=METHOD]
类似 -D,使用空行分隔每个组,METHOD=none,prepend,separate
- -f, --skip-fields=N 不比较前 N 个字段
- --group[=METHOD]
使用空行分隔每个组,METHOD=separate,prepend,append,both
- -i, --ignore-case 忽略大小写
- -s, --skip-chars=N 不比较前 N 个字符
- -u, --unique 只打印出现一次的行
- -z, --zero-terminated 行分隔符是 NUL 而不是换行符
- -w, --check-chars=N 比较不多于 N 个字符
- --help 帮助文档
- --version 版本信息


uniq -c 压缩并统计连续的字符数据信息


小拓展
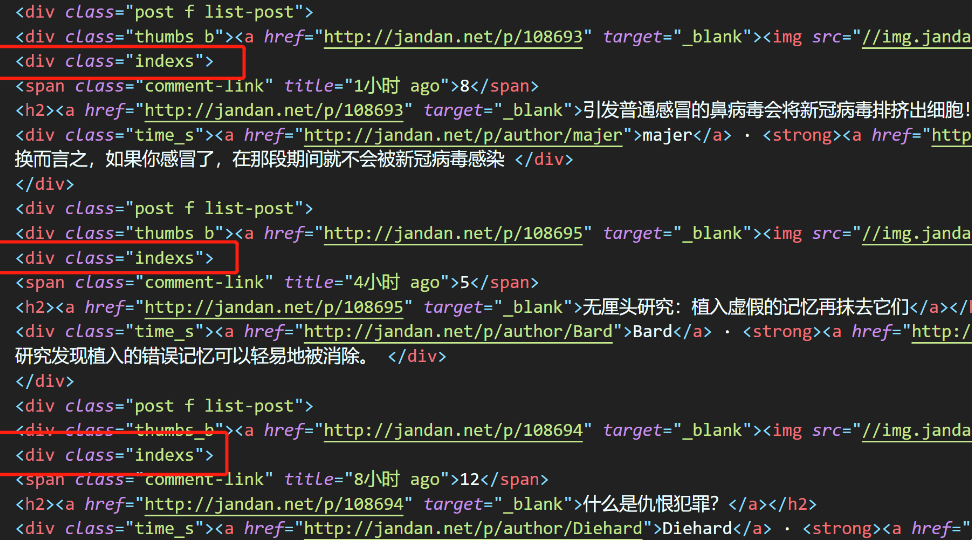
1、提取访问量最高的地址
先上传一个日志文件