配置国内镜像源
# pip设置配置
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip config set trusted-host pypi.tuna.tsinghua.edu.cn
创建虚拟环境
# 使用conda创建虚拟环境(具体内容请参考课件)
conda create -n py_spider python=3.9
删除虚拟环境
# 使用conda删除虚拟环境
conda remove --name py_spider --all
列出所有虚拟环境
conda info -e
-
包的导出
- 使用
pip list - 或者
pip freeze
- 使用
-
导入
- 使用
pip install -r ./requirements.txt
- 使用
异步与同步的理解
在网络框架中,同步(Synchronous)和异步(Asynchronous)是指处理任务和响应的两种不同方式。
同步:
- 阻塞式操作:任务一个接着一个执行,一个任务执行完成之前,会阻塞程序的执行,直到这个任务完全完成或者返回结果。
- 按顺序执行:任务按照它们被调用的顺序执行,一个任务的执行会等待另一个任务的结束。
- 易于理解:同步方式的代码流程简单,易于理解和编写。
异步:
- 非阻塞式操作:任务执行时不会等待结果返回,而是继续执行下一个任务,不会阻塞程序的运行。
- 并发执行:多个任务可以并发执行,不需要等待其他任务的完成。
- 回调机制:异步编程常常使用回调函数或者事件处理机制,当一个任务完成时会触发相应的回调函数来处理结果。
区别:
- 执行方式:同步是顺序执行,任务一个接着一个执行;异步是并发执行,任务不会等待其他任务完成。
- 阻塞行为:同步编程会阻塞程序执行,直到任务完成;异步编程不会阻塞程序执行,允许其他任务继续执行。
- 代码复杂度:异步编程可能会引入回调、事件处理等机制,使得代码复杂度增加,但在高并发场景下,异步能够提高系统的性能和响应速度。
在网络框架中,异步编程常用于需要处理大量并发请求的场景,比如Web服务器处理大量同时到达的HTTP请求时,异步方式能够更高效地利用系统资源,提高系统的吞吐量和响应速度。
自我理解:异步不一定是并发,但并发一定是异步。
问题:为什么并发是非堵塞。
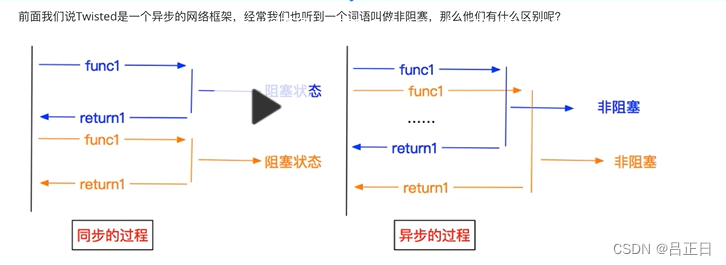
同步:发送一个请求,等待返回,然后再发送下一个请求。异步:发送一个请求,不等待返回,随时可以再发送下一个请求。
同步爬虫流程
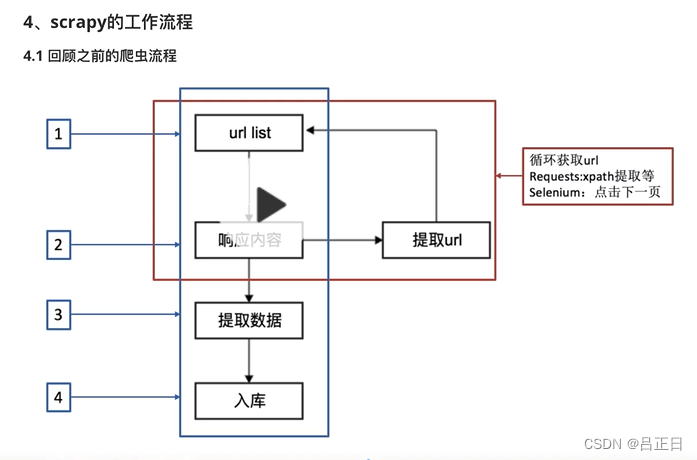
- 创建网站列表,发送request请求,得到响应内容。
- 对内容进行数据清洗。
- 数据提取。
- 存入数据表。
优化后的流程
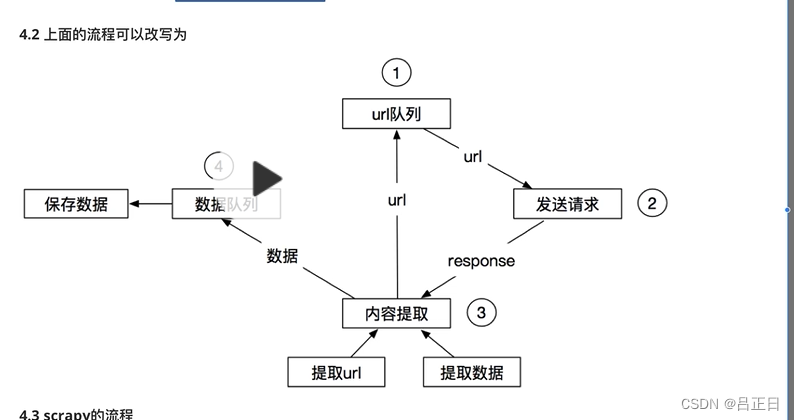
线程爬虫,如果都放在同一列表中,会有竞争。拿请求的代码是加锁,解锁。利用队列,线程安全。只多了数据队列部分。内容提取可能导致两个项目录入同一个库表中。如果存入队列,则读取时,直接pop。提取新的url后,重新放到url队列。
Scrapy流程
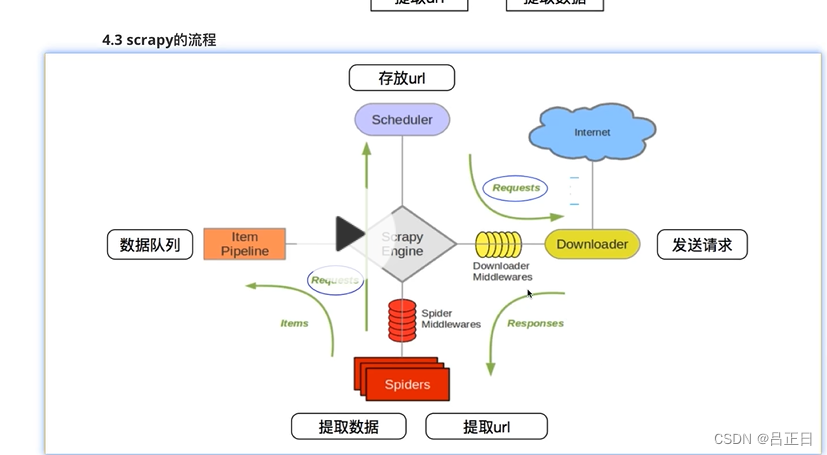
多了爬虫引擎负责调度任务。
模块作用
- 调度器:本质是队列,用来存放引擎的request请求。
- 下载器:返回响应给引擎发来的request请求。
(只需手写Spider、pipline管道)
Scrapy的应用
- 创建Scrapy项目:
scrapy startproject mySpider
- 生成一个爬虫:
scrapy genspider douban movie.douban.com
- 查看Scrapy版本:
pip show scrapy
项目结构说明:
- init.py:模块文件。
- items.py:movie_nameupdate_time。
- settings.py:设置headers、cookie、线程数、rebot。
列表分为单向列表和双向列表,它可以当做队列使用。
Hope this helps! 如果有其他需要,欢迎告诉我。